基于由粗到细粒度信息捕捉的时序动作检测方法及装置
文献发布时间:2023-06-23 06:30:03
技术领域
本发明属于时序动作检测技术领域,特别涉及一种基于由粗到细粒度信息捕捉的时序动作检测方法及装置。
背景技术
随着网络、互联网技术的迅速发展,视频在当今互联网已经是非常重要的信息传播和信息获取手段,并且视频的数量在近几年呈现爆发式的增长,因此对视频内容的分析理解技术至关重要。
基于深度学习的视频动作检测在2014年初提出CNN后开始展开研究,近年来由于在硬件算力、深度学习算法的日益先进化条件下,视频动作定位检测有了较为火热的发展。在安防监控、短视频推荐自动剪辑领域都有很大的用武之地。通常未裁切的视频包含较多复杂的背景视频段信息、不固定的动作实例片段,且动作发生的起始位置、动作类别标签都是未知的。视频动作检测方法是能够识别出未裁切视中多个动作起止位置的方法。该方法是目前视频内容分析理解的重要研究方向。为了处理无裁切的视频,视频动作定位算法不仅要求对视频的动作片段进行定位,更要对动作进行具体分类。目前来看,视频时序动作定位分类主要分为以下两种:
一阶算法:基于已经生成的整段视频的特征,一阶算法通过神经网络模型利用固定的几个尺寸的框提取出需要的动作提名,对提名进行拟合进而得到准确的视频动作的定位,并通过另一个分支网络对该提名进行分类。整个过程是利用视频特征作为输入,端到端的输出动作定位以及动作分类。这类算法由于是端到端的,那么可以使得模型更加容易训练,但相比于二阶算法,在动作提名时,对于提名边界的准确度会较低一些,提名准确度会较低一些。
多阶算法:多阶算法则是基于已经生成的整段视频特征,首先利用神经网络模型生成一维时序提名。再利用神经网络模型输入整段视频特征以及一维时序提名,最后定位分类视频动作。二阶算法也是端到端的,但是是基于每一帧的开始结束可能性,所以对于提名的准确度会更高一些。动作提名的意思是通过动作候选网络,排除视频中大量无关背景干扰片段,得到动作候选片段即提名。
现有研究中,利用多尺寸的滑动窗口对未裁切的视频进行分割,使用候选分类网络筛选出候选动作提名片段,在使用3D卷积网络来实现视频片段的动作分类。但是由于候选分类网络要求网络输入的视频片段长度一致,只能在不同下采样频率下获取不同时间长度的视频片段,但是缺点就是这样得到的视频片段差异性很大,时序上特征会遭到一定程度破坏,使得动作定位的准确率提升受到了限制。
如今在人工智能领域,计算机视觉中视频动作检测领域已经变得非常重要。动作检测在视频监控安防等领域有很大的应用潜力,那么提升现目前动作定位分类的准确度就是迫在眉睫的任务。现有的动作检测算法都可以应用于非裁切的长视频中,但是目前最大的难题就是定位准确率比较低。
发明内容
本发明是为解决上述问题而进行的,目的在于提供一种能够对视频中的动作进行高准确率的定位检测的时序动作检测方法及装置,本发明采用了如下技术方案:
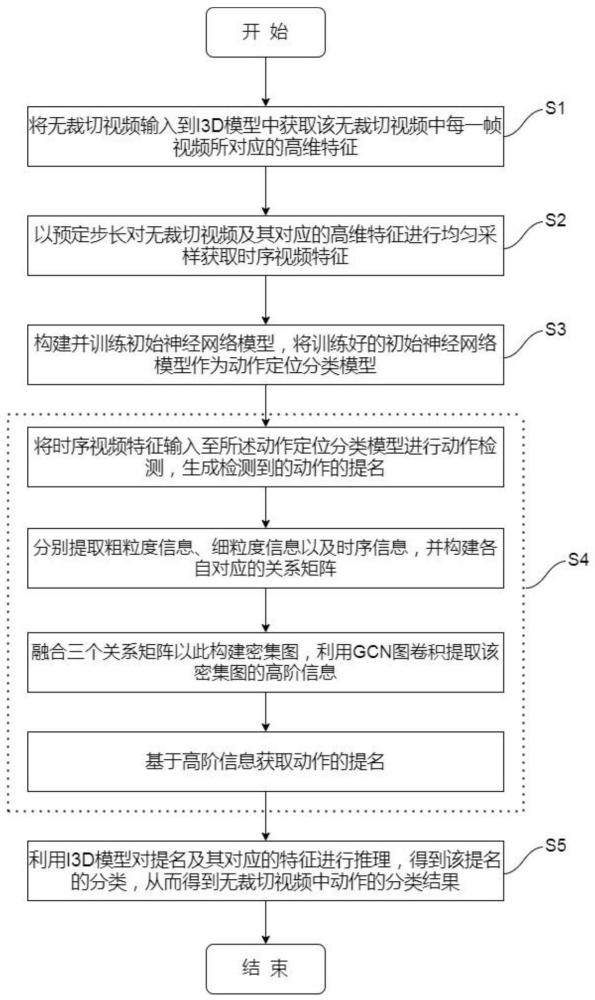
本发明提供了一种基于由粗到细粒度信息捕捉的时序动作检测方法,其特征在于,包括以下步骤:步骤S1,将无裁切视频输入到I3D模型中获取该无裁切视频中每一帧视频所对应的高维特征,其中,无裁切视频包含有至少一个动作;步骤S2,以预定步长对无裁切视频及其对应的高维特征进行均匀采样获取时序视频特征;步骤S3,构建并训练初始神经网络模型,将训练好的初始神经网络模型作为动作定位分类模型;步骤S4,将时序视频特征输入至动作定位分类模型进行动作检测,生成检测到的动作的提名;步骤S5,利用I3D模型根据提名及其对应的特征获取提名特征,通过动作定位分类模型对提名特征进行动作分类,从而得到无裁切视频中所有动作的分类结果,其中,动作定位分类模型具有多个多粒度信息捕捉模块和时序信息捕捉模块,多粒度信息捕捉模块用于捕捉并提取时序视频特征的粗粒度信息和细粒度信息,时序信息捕捉模块用于提取时序视频特征的时序信息,动作定位分类模型基于粗粒度信息、细粒度信息和时序信息的融合信息生成动作的提名。
本发明提供的基于由粗到细粒度信息捕捉的时序动作检测方法,还可以具有这样的技术特征,其中,步骤S4包括以下子步骤:步骤S4-1,利用基于金字塔结构的空间信息提取方法提取时序视频特征中每一帧的粗粒度信息,并根据帧与帧之间的粗粒度信息的相似性构建第一邻接矩阵;步骤S4-2,利用自注意力机制提取每一帧的细粒度信息,并根据帧与帧之间的细粒度信息的相似性构建第二邻接矩阵;步骤S4-3,基于时序信息,构建顺序帧与其对应的逆序帧之间的联系,得到第三邻接矩阵;步骤S4-4,将第一邻接矩阵、第二邻接矩阵和第三邻接矩阵相加并进行归一化,得到归一化的邻接矩阵;步骤S4-5,基于归一化的邻接矩阵建立密集图,图中,节点代表无裁切视频的帧,节点特征为该帧对应的帧特征,帧与帧之间的连接边权重对应邻接矩阵的具体值;步骤S4-6,利用GCN图卷积方式对密集图中的节点进行消息传递更新,从而得到高阶信息;步骤S4-7,利用sigmoid对高阶信息进行分类,并判断每一帧是动作开始或结束的概率,将大于预定概率值的帧作为该动作的提名,该提名的置信度为开始和结束得分的乘积;步骤S4-8,生成无裁切视频中包含的所有动作可能的提名,并利用全连接网络生成所有提名的全局置信度;步骤S4-9,将步骤S4-7得到的置信度与步骤S4-8得到的全局置信度的乘积作为每一个提名的总体置信度。
本发明提供的基于由粗到细粒度信息捕捉的时序动作检测方法,还可以具有这样的技术特征,其中,在步骤S4-6中,还包括利用可训练的提名矩阵ADR自适应地调整全局数据统计量的权重。
本发明提供的基于由粗到细粒度信息捕捉的时序动作检测方法,还可以具有这样的技术特征,其中,初始神经网络模型的训练过程如下:基于公开数据集构建训练用数据集;将训练用数据集输入至初始神经网络模型进行训练,利用多粒度信息捕捉模块进行由粗粒度到细粒度的信息提取,同时,以数据驱动为导向的自适应图结构在训练过程中捕捉候选提名节点之间的重要的关联信息。
本发明提供的基于由粗到细粒度信息捕捉的时序动作检测方法,还可以具有这样的技术特征,其中,训练用数据集的构建过程如下:将公开数据集Thumos14中的视频数据输入至I3D模型中,得到视频数据的高维特征,将高维特征和公开数据集Thumos14中对应的标签组成训练用数据集。
本发明还提供一种基于由粗到细粒度信息捕捉的时序动作检测装置,其特征在于,包括:输入数据处理部,用于获取原始无裁切视频的高维特征,并对该高维特征及对应的视频帧进行均匀采样从而得到时序视频特征;动作定位分类部,用于提取该时序视频特征的粗粒度信息、细粒度信息以及时序信息,并根据这三个信息生成原始无裁切视频中包含的动作的对应提名;以及提名分类部,用于根据动作定位分类部输出的动作的提名和对应的特征获取提名特征,并对提名特征进行动作分类,从而得到原始无裁切视频中动作的分类结果,其中,动作定位分类部是一个训练好的动作定位分类模型,该模型具有多个多粒度信息捕捉模块和时序信息捕捉模块,多粒度信息捕捉模块用于捕捉并提取时序视频特征的粗粒度信息和细粒度信息,时序信息捕捉模块用于提取时序视频特征的时序信息,动作定位分类模型基于粗粒度信息、细粒度信息和时序信息的融合信息生成动作的提名。
发明作用与效果
根据本发明的基于由粗到细粒度信息捕捉的时序动作检测方法及装置,在该时序动作检测方法中,由于采用性能更优秀的开源模型I3D作为视频特征提取,利用3D扩展卷积增加感受野,因此能够捕捉到更加丰富的视频特征信息。同时,本发明还建立了由粗到细粒度信息捕捉模块SGC,通过数据学习,由粗到细粒度的信息捕捉,可以更加全面的捕捉到视频中全局和局部的一些信息,从多个尺度去考虑动作的特征信息,能够提取出更加丰富的语义信息,能够达到目前最优秀的检测准确度。
附图说明
图1是本发明实施例中基于由粗到细粒度信息捕捉的时序动作检测方法的流程示意图;
图2是本发明实施例中采用I3D模型提取高维特征的过程示意图;
图3是本发明实施例中提取粗粒度信息的过程示意图;
图4是本发明实施例中三种信息卷积融合的示意图;
图5是本发明实施例中训练模型生成提名和动作检测示意图;以及
图6是本发明实施例中时序动作检测装置的结构示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的基于由粗到细粒度信息捕捉的时序动作检测方法及装置作具体阐述。
<实施例>
本实施例提供一种能够对视频中的动作进行高准确率的定位检测的基于由粗到细粒度信息捕捉的时序动作检测方法,其实现为软件运行在本实施例的平台上,本实施例的平台具体为:操作系统ubuntu16.04,使用Python3.7语言实现,神经网络框架使用pytorch1.3版本,CUDA版本为10.0,计算加速单元使用4张NVIDIA1080TiGPU。
本实施例的方法用于对一段视频进行多阶段视频动作检测,其中,视频为无裁切视频(未经剪辑的原始长视频),其中包含一个及以上的动作,供给内容以视频信息呈现。本实施例的方法是目的是对无裁切视频中发生动作的时间点进行定位,并对动作进行识别。
图1是本发明实施例中基于由粗到细粒度信息捕捉的时序动作检测方法的流程示意图。
如图1所示,基于由粗到细粒度信息捕捉的时序动作检测方法,主要包括如下步骤:
步骤S1,将原始的无裁切视频输入到开源模型I3D模型中,采用双流扩展3D卷积对该无裁切视频进行处理,从而得到每一帧视频对应的高维特征。
图2是本发明实施例中I3D方法流程示意图。
如图2所示,首先把包含一个或多个动作的无裁切的长视频,按照30FPS的帧率导出为RGB图片,并从得到的视频帧中每次取16帧利用TVL1算法计算对应的光流信息。其次将RGB图片输入到I3D网络,得到最后的视频特征即RGB视频特征和光流特征。最后采用双流扩展3D卷积对RGB视频信息以及光流信息进行处理,最终得到维度为T*2048的视频特征,包括光流特征以及RGB特征。其中T为时序帧个数。
本实施例中,由于I3D模型中用到8层3D卷积、利用扩展卷积增加感受野,因此能够更大范围的捕捉空间信息。
步骤S2,以预定步长对无裁切视频及其对应的高维特征进行均匀采样获取时序视频特征。
本实施例中,对于一段无裁切的视频,利用一个长度为T的窗口,设定重叠率为0.5,将无裁切视频分割为固定长的视频,以便能够在训练过程中并行加速。同时为了能够减小网络计算的开销,对于得到的固定帧数T的一段视频,本实施例以间隔a对视频帧进行均匀采样,以此来减小视频帧的长度,以便网络训练推理更加的高效,因此,本实施例的视频段最后T=T/a。
图3是本发明实施例中粗粒度信息提取方法流程示意图;图4是本发明实施例中三种信息卷积融合流程示意图;
步骤S3,构建并训练初始神经网络模型,将训练好的初始神经网络模型作为动作定位分类模型。
其中,动作定位分类模型具有多个多粒度信息捕捉模块SGC和时序信息捕捉模块,多粒度信息捕捉模块用于捕捉并提取时序视频特征的粗粒度信息和细粒度信息,时序信息捕捉模块用于提取时序视频特征的时序信息,动作定位分类模型基于粗粒度信息、细粒度信息和时序信息的融合信息生成动作的提名。
本实施案例中,利用公开数据集Thumos14构建模型训练的训练用数据集。将数据集中的视频输入到I3D模型中,利用I3D中的8个扩展3D卷积层处理后得到视频的高维特征,将高维特征和公开数据集Thumos14中对应的标签组成训练用数据集。
将训练用数据集作为初始神经网络模型的输入,利用由粗到细粒度的信息提取,并将该模块重叠几次,且设定两个分支。同时,以数据驱动为导向的自适应图结构会在训练过程中捕捉候选提名节点之间潜在的重要的联系信息。
步骤S4,将时序视频特征输入至动作定位分类模型进行动作检测,生成检测到的动作的提名。
本实施例中,通过提取不同粒度的特征,采用特征间的相似性来建立帧间关系矩阵,对于不同粒度得到的关系矩阵,采用普通的相加来对不同粒度下的信息做融合,基于这样的关系矩阵,采用GCN来捕捉流动信息,探索到更多有用的相互补充的信息。具体包括以下子步骤:
步骤S4-1,利用基于金字塔结构的空间信息提取方法提取时序视频特征中每一帧的粗粒度信息,并根据帧与帧之间的粗粒度信息的相似性构建第一邻接矩阵。
本实施例中,采用金字塔结构的空间信息提取粗粒度信息(CSR)提取,通过对帧特征进行多尺度的全局池化操作,形成多个不同尺度的池化后特征,利用U-Net的上采样以及级联方式来对粗粒度信息中包含的高阶信息进行捕捉和提取。对于每一帧提取到的信息,本实施例利用特征相似度来衡量帧与帧之间的特征相似性,并以此构建一个帧间联系的邻接矩阵,具体操作方法如图3所示,对于特征图输入TxC,利用全局平均池化为3种类型的特征,然后采用级联的方式,利用上采样,自上而下的进行连接,生成输出的高阶信息TxCo,最后利用自注意机制来构建邻接矩阵。
步骤S4-2,利用自注意力机制提取每一帧的细粒度信息(FSR),并根据帧与帧之间的细粒度信息的相似性构建第二邻接矩阵。
步骤S4-3,基于时序信息,构建顺序的以及逆序的帧与帧之间的联系,每一帧与下一帧和上一帧有联系,而和其他帧联系设置为0,得到第三邻接矩阵。
步骤S4-4,将第一邻接矩阵、第二邻接矩阵和第三邻接矩阵相加并进行归一化,得到归一化的邻接矩阵。
步骤S4-5,基于归一化的邻接矩阵建立密集图,图中,每个节点对应无裁切视频的每一帧,节点特征为该帧对应的帧特征,帧与帧之间的连接边权重对应邻接矩阵的具体值。
步骤S4-6,利用GCN图卷积方式对密集图中的节点进行消息传递更新,并且增加一个可训练的提名矩阵(ADR),用于自适应调整全局数据统计量的权重,从而得到高阶信息。
如图4所示,输入数据矩阵为168*2048,图卷积层的操作是将有连接边的节点的消息传递并更新,得到168*512的视频提名特征,利用非线性函数Relu处理后再用图卷积层变换特征维度到1024,从而得到视频帧的高阶信息。
步骤S4-7,如图5所示,在对动作进行无类别的定位时,利用sigmoid对高阶信息进行分类,并判断每一帧是动作开始或结束的概率,将大于0.52的概率的对应帧作为该动作的有效提名,该有效提名的置信度为开始和结束得分的乘积。
步骤S4-8,对于密集图的提名,生成无裁切视频中包含的所有动作可能的提名,并利用全连接网络生成所有提名的全局置信度;
步骤S4-9,将步骤S4-7得到的置信度与步骤S4-8得到的全局置信度的乘积作为每一个提名的总体置信度。
步骤S4-10,利用NMS非极大值抑制法减少冗余的提名,并采用IoU作为动作的起始位置的准确度的判断标准。
本实施例中,在得到上述预测的提名数据后,采用NMS非极大值抑制方法,改善动作检测提名的最后结果。对于起止位置的准确度采用IoU作为判断标准,即预测起止范围与标签起止范围的交并比。
步骤S5,利用I3D模型根据提名及其对应的特征获取提名特征,通过动作定位分类模型对提名特征进行动作分类,从而得到无裁切视频中所有动作的分类结果。
在本实施例中,依据提名的总体置信度排名来选取更加可靠的提名。一般选取置信度前100的提名来做分类,因为视频信息中,100个提名的获取是在视频计算开销承受范围的同时还拥有非常优秀的视频动作检测精确度。
图6是本发明实施例中时序动作检测装置的结构示意图。
如图6所示,时序动作检测装置100包括输入数据处理部10、动作定位分类部20以及提名分类部30。
输入数据处理部10用于获取原始无裁切视频的高维特征,并对该高维特征及对应的视频帧进行均匀采样从而得到时序视频特征。
动作定位分类部20是一个训练好的动作定位分类模型,动作定位分类部20用于将时序视频特征作为该模型的输入,对该时序视频特征进行由粗到细粒度信息以及时序信息的提取,并根据这三个信息生成动作的提名。
其中,动作定位分类模型具有多个多粒度信息捕捉模块和时序信息捕捉模块,多粒度信息捕捉模块用于捕捉并提取时序视频特征的粗粒度信息和细粒度信息,时序信息捕捉模块用于提取时序视频特征的时序信息,动作定位分类模型基于粗粒度信息、细粒度信息和时序信息的融合信息生成动作的提名。
提名分类部30用于根据动作定位分类部20输出的动作的提名和对应的特征获取提名特征,并对该提名特征进行动作分类,从而得到输入的原始无裁切视频中动作的分类结果。
实施例作用与效果
根据本实施例的基于由粗到细粒度信息捕捉的时序动作检测方法及装置,在该方法中,无裁切视频首先会经过I3D模型提取视频帧信息,由于采用性能更优秀的开源模型I3D作为视频特征提取,利用3D扩展卷积增加感受野,能够捕捉到更加丰富的视频特征信息。其次建立了由粗到细粒度信息捕捉模块SGC,通过数据学习,实现由粗到细粒度的信息捕捉,且加入了时序信息捕捉模块,因此可以更加全面的捕捉到视频中全局和局部的一些信息,从多个尺度去考虑动作的特征信息,能够提取出更加丰富的语义信息,使得在提名生成过程中提供准确的视频动作定位,能够达到目前最优秀的检测准确度。此外,在数据驱动的模型中,仅仅利用固定人工构建的无向图是完全不够的,本实施例采用了粗粒度、细粒度、时序三种关联信息来构建图,这样能够更加全面的捕捉到更多的有效的信息。
实施例中,还由于对视频帧进行了均匀采样,因此在减小了网络计算开销的同时保持了同样的精度,主要原因是视频帧在时序上的差异性是很小的,所以均匀采样能够保持一定差异性的同时还能能提高动作检测的准确率。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。