用于神经命名实体识别的共指感知表示学习
文献发布时间:2023-06-19 09:44:49
技术领域
本公开总体上涉及可以提供提高的计算机性能、特征和用途的计算机学习的系统和方法。更具体地,本公开涉及用于学习共指感知词表示的实施方式。
背景技术
命名实体识别(NER)是自然语言处理(NLP)中的基本任务之一,其对许多下游应用程序(包括关系提取、知识库完成和实体链接)具有巨大影响。给定输入文本,NER旨在从原始文本中找到命名实体并将其分类为预定义的语义类型,诸如人(PER)、组织(ORG)、位置(LOC)等。
NER的传统方式是将其视为序列标记任务,其中每个词被分配一个标签(例如,BIO标签架构中的“B-PER”(PERSON语义类型的起始词)、“I-PER”(PERSON语义类型的中间词)、“O”(“其他”词,其为不具有语义类型或对当前分析不感兴趣的语义类型的词)),该标签指示该词是否属于任何命名实体的一部分。为了提高NER的性能,最近的NLP研究人员通常会应用最新且复杂的神经序列标记模型,诸如BiLSTM-CRF架构,该模型首先使用双向长短期记忆(LSTM)来处理输入语句,然后使用条件随机场(CRF)共同地标记每个词。
虽然最近的神经网络模型提高了NER的最先进性能,但是它们只是将输入文本视为词的线性序列,而忽略了非顺序结构信息,诸如在原始上下文中位置可能相距遥远的实体之间的共指关系(即,两个或多个提及(mention)指示同一个人或事物)。这样的限制可能导致这些模型产生全局地不一致的语义类型预测。
图1示出了将著名的Ma和Hovy模型(2016)(Xuezhe Ma和Eduard Hovy,“通过双向LSTM-CNNs-CRF进行端到端序列标记”,载于ACL,第1064-1074页,2016年)应用于两个句子时的典型失败案例。如在图1中所示,实体“加拉迪队(Otelul Galati)”和“布加勒斯特国民队(National Bucharest)”都是组织名称,但是Ma和Hovy模型(2016)在第一句话中错误地将它们预测为位置实体。基于错误分析,Ma和Hovy(2016)犯下的错误中有20%至25%属于此类别。
因此,需要一种用于学习和获得命名实体识别(NER)的共指感知词表示的改进的系统和方法。
发明内容
在第一方面,本公开的实施方式提供了一种计算机实现方法,包括:将包括词的文档输入到共指感知命名实体识别(NER)网络中,所述网络包括:词嵌入层;附加特征嵌入层;字符级卷积神经网络(CNN),以字符嵌入层作为所述CNN的输入;词级双向长短期存储器(BLSTM)层;共指层;以及条件随机场(CRF)层;对于每个词,将所述词嵌入层、所述附加特征嵌入层以及所述字符级CNN的输出组合为组合表示;使用所述组合表示和所述词级BLSTM层获得对于所述文档中的每个词的隐藏表示;以及使用文档中的所述词的所述隐藏表示作为所述共指层的输入,以获得对于所述文档中的每个词的共指表示;以及使用所述共指表示作为所述CRF层的输入,确定所述文档的标记序列,所述CRF层共同地确定所述文档的所述标记序列。
在第二方面,本公开的实施方式提供了一种非暂时性计算机可读介质或媒介,包括一个或多个指令序列,所述指令序列,当由一个或多个处理器执行时,使得执行根据上述第一方面的方法。
在第三方面,本公开的实施方式提供了一种系统,包括:一个或多个处理器;以及一种非暂时性计算机可读介质或媒介,其包括一个或多个指令集,当由所述一个或多个处理器中的至少一个执行时,所述指令集,使得执行根据上述第一方面的方法。
附图说明
将参考本公开的实施方式,其示例可在附图中示出。这些图旨在为说明性的,而非限制性的。虽然一般在这些实施方式的上下文中描述了本公开,但是应理解,并不旨在将本公开的范围限制为这些特定的实施方式。在图中的项目可能未按比例绘制。
图1描述了由第三方模型产生的不一致错误的示例。
图2描述了根据本公开的实施方式的基础模型架构。
图3描述了根据本公开的实施方式的具有共指组件和正则化的文档级模型架构。
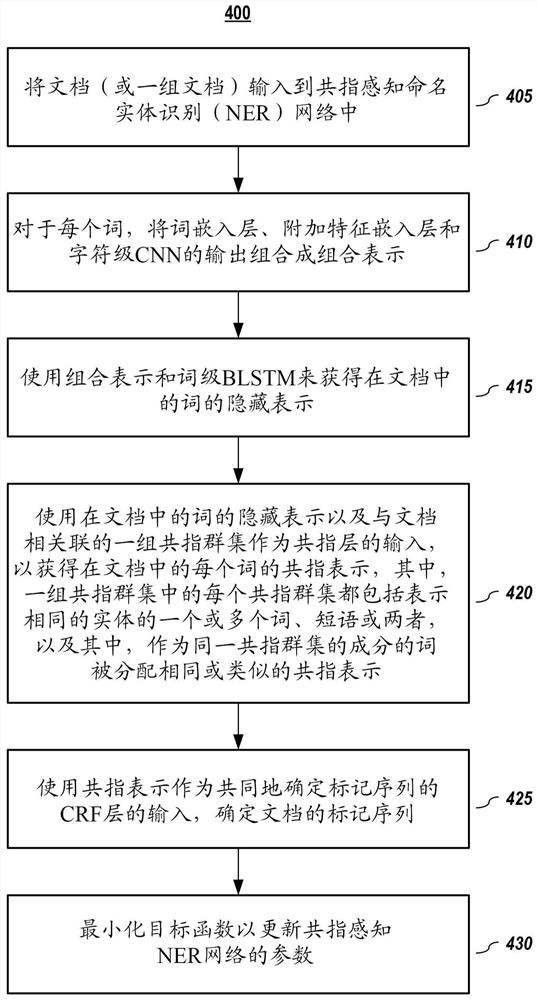
图4描述了根据本公开的实施方式的用于训练共指感知NER模型的方法。
图5描述了根据本公开的实施方式的具有共指组件的训练过的共指感知NER模型架构。
图6描述了根据本公开的实施方式的用于使用训练过的共指感知NER模型的方法。
图7包含表2,其总结了根据本公开的实施方式的用于实验的超参数。
图8包含表3,其示出了根据本公开的实施方式的在测试集上的NER性能。
图9包含表4,其示出了根据本公开的实施方式的在另一测试集上的NER性能。
图10描述了根据本公开的实施方式的共指知识质量对共指感知NER模型的影响。
图11描述了根据本公开的实施方式的计算设备/信息处理系统的简化框图。
具体实施方式
在以下描述中,出于说明的目的,阐述了具体细节以便提供对本公开的理解。然而,对于本领域技术人员显而易见的是,可以在没有这些细节的情况下实践本公开。此外,本领域技术人员将认识到,下面描述的本公开的实施方式可以以多种方式来实现,诸如在有形的计算机可读介质上的过程、装置、系统、设备或方法。
在图中所示的组件或模块是对本公开的示例性实施方式的说明,并且旨在避免模糊本公开。还应理解,在整个讨论中,组件可以被描述为单独的功能单元,其可以包括子单元,但是本领域技术人员将认识到,各种组件或其一部分可以被划分为单独的组件或者可以集成在一起,包括集成在单个系统或组件中。应注意,在本文中讨论的功能或操作可以被实现为组件。组件可以以软件、硬件或其组合来实现。
此外,附图中的组件或系统之间的连接不旨在限于直接连接。相反,中间组件可以修改、重新格式化或以其他方式更改这些组件之间的数据。另外,可以使用附加或更少的连接。还应注意,术语“联接”、“连接”或“通信联接”应理解为包括直接连接、通过一个或多个中间设备的间接连接以及无线连接。
在说明书中对“一个实施方式”、“优选实施方式”或“实施方式”的引用是指结合该实施方式描述的特定特征、结构、特性或功能包括在本公开的至少一个实施方式中,并且可以包括在一个以上的实施方式中。另外,上述提及的短语在说明书中各个地方的出现不一定都指相同的实施方式。
在说明书中的各个地方使用某些术语是为了说明,而不应解释为限制性的。服务、功能或资源不限于单个服务、功能或资源;这些术语的使用可以指相关服务、功能或资源的分组,它们可以是分布式的或聚合式的。
术语“包括(include)”、“包括(including)”、“包括(comprise)”和“包括(comprising)”应被理解为开放的术语,并且以下的任何列表都是示例,并不意味着限于所列出的项目。如在本文中使用的“文档”应被理解为是指句子、短语或两者的集合。“实体”应理解为是指人员、位置、组织、产品、事物等,但是在实施方式中也可能是指表示独特概念(无论是有形的还是无形的)的词。“层”可以包括一个或多个操作。
在本文中使用的任何标题仅用于组织目的,并且不应被用于限制描述或权利要求的范围。在本专利文件中提及的每个引用均通过引用整体并入本文。
此外,本领域技术人员将认识到:(1)可以可选地执行某些步骤;(2)步骤可能不限于在本文中阐述的特定顺序;(3)某些步骤可以以不同的顺序执行;(4)某些步骤可以同时进行。
应注意,在本文中提供的任何实验和结果均是以说明的方式提供,并且是在特定条件下使用特定的实施方式进行的;因此,这些实验及其结果均不应该用于限制当前专利文件的公开的范围。
A.一般介绍
如上所述,命名实体识别(NER)的传统方式将其视为序列标记任务。但是,只是将输入文本视为词的线性序列,而忽略了非顺序结构信息,诸如在原始上下文中位置可能相距遥远的实体之间的共指关系(即,两个或多个提及均表示同一个人或事物),往往会导致这些模型产生全局地不一致的语义类型预测。从概念上讲,如果两个实体属于同一个共指群集,则它们应具有相同的语义类型。注意,如在图1中所示,即使是相对较短的段落也包括对同一实体的多次引用,但是它们被分配了不同的实体类型。然而,如在图1中所示,结合了共指关系的NER模型将有助于修复标记错误。
近年来,用于共指解析的端到端神经网络模型已实现了越来越高的准确性,这使得从原始文本中自动地提取共指关系而无需依赖于人工注释的共指知识成为可能且实际。因此,一个关键的研究课题是如何将提取的共指关系合并到NER模型中,以跨共指实体提及预测一致的语义类型。
为了解决上述课题,在本文中提出了基于Ma and Hovy(2016)的“CNNBiLSTM-CRF”NER模型的共指感知表示学习框架的实施方式。具体地,在一个或多个实施方式中,在BiLSTM层的顶部添加了一个共指组件,以合并来自基础事实(ground truth)或外部共指解析器的、有关实体提及之间的共指关系的先验知识。此外,在一个或多个实施方式中,包括共指正则化术语以强制共指词/实体对于NER标签标记具有相似的表示。在一个或多个实施方式中,组合目标函数最大程度地提高给定输入文本的情况下解码标签序列的概率以及共指实体隐藏表示之间的共识。
在本专利文件中提出的一些主要贡献包括:
在本文中提出的是共指感知NER模型的实施方式,它们在文档级别操作,并且能够明确地利用共指关系的全局结构信息。通过将共指层组件和共指正则化引入基础模型,完整模型实施方式既具有深度神经网络模型的强大泛化性能,又具有共指指导的增强。就发明人所知,这些实施方式是首先有效地利用共指关系的神经NER模型。
模型的实施方式在两个数据集上进行基准测试。在两个基准上,即使第三方CoreNLP工具包生成共指关系,完整模型的实施方式也具有比在先的所有方式优于0.4-1.0%的绝对提升。
虽然重点在于通过使用共指知识来提高NER,但是模型实施方式为其他NLP任务提供了启示,其中存在可用的结构信息的外部知识库。例如,实体/事件关系也可以合并到神经网络中,以推进具有挑战性的NLP任务的性能,包括话语解析、问题回答和自然语言理解。
B.一些相关成果
1.神经命名实体识别(NER)
近来,基于神经网络的NER模型相对于早期基于特征的模型已取得了很大进步。那些神经网络使用不同的策略(例如,卷积神经网络(CNN)或递归神经网络(RNN))将字符和词编码为隐藏表示,然后将它们解码为具有CRF(或LSTM)层的命名实体标签。更好的NER性能的另一个趋势是,通过对字符或外部未标记句子进行深度语言模型预训练,来根据词的上下文改进具有隐藏表示的词嵌入。然而,大多数在先的成果主要将NER视为传统的序列标记课题,而忽略了上下文中的丰富结构信息,诸如在本专利文件中使用的共指关系。
利用外部知识来改进NER也已受到NLP研究人员的关注。其中一些使用相关性或选区解析树来指导NER,而其他一些则利用外部知识库来促进实体提取。还有其他一些提出了基于特征的共同模型来同时进行NER和共指推断。相反地,模型实施方式是端到端的深度神经网络模型,并且重点在于使用共指关系作为先验知识来学习NER的共指感知表示,而不是共同地建模NER和共指解析。
一些研究人员提出了一种深层多任务框架,以共同地进行NER、关系提取和共指解析,其中上述三个任务共享共同隐藏层。然而,这样的方式承受高计算复杂度O(L
2.将共指知识合并到神经网络模型中
作为语言结构信息的一种重要类型,已经探索了共指知识以改进许多NLP应用程序(诸如阅读理解和关系提取)的神经网络模型的性能。由于本文中的实施方式是首先在神经NER模型中利用共指知识的,因此目的还在于研究一种用于编码共指关系的特定于任务的方式。
一种在神经网络内编码共指关系的方法是使用在RNN(或存储器网络)中的外部门(或存储器)作为底层组件。然而,该方法最多只能隐性地利用共指知识,因为当处理具有增加了的大小的隐藏单元(例如,模型使用更多的隐藏单元来跟踪每个共指群集)的较长的输入序列时,在底层向前传播期间,共指信息很容易丢失。明确地介绍共指知识的另一种方法是在神经网络模型的顶层处构建共指感知词表示,该方法通常在词级RNN(或CNN)之上使用向量转换功能(包括前馈神经网络、神经张量网络、软注意力机制和/或其他机制),以提炼实体提及表示。在本文中的一个或多个实施方式中,在设计本文中的共指层组件的实施方式时采用了顶层方式,使得编码的共指关系能够直接并且明确地影响最终的词表示。
C.NER的神经网络模型实施方式
在本节中,首先介绍了用于神经命名实体识别的基础模型;然后,提出了共指层组件的实施方式,其中,共指层组件通过合并共指知识扩展了基础模型。最后,提出了合并共指正则化的实施方式,其能够用于指导共指感知词表示学习,以实现NER的一致标记预测。
1.基础模型(CNN-BiLSTM-CRF)实施方式
在一个或多个实施方式中,选择了Ma和Hovy(2016)的CNN-BiLSTM-CRF模型作为基础模型实施方式的起点,因为它是通过比较最近的神经NER模型架构的不同变体而被其他人广泛研究的最成功的NER模型。应注意,本领域技术人员将认识到,根据在本文中所示的实施方式,可以采用和适应不同的基础模型。
图2示出了根据本公开的实施方式的基础模型,其包括字符级CNN组件205、词级双向LSTM组件220,以及CRF层组件230,其共同地解码语义命名实体标签。
字符级CNN205。诸如词的前缀或后缀的字符级特征有助于减轻词汇不足问题并改进在神经网络模型中的词表示。在一个或多个基础模型实施方式中,具有最大池化操作的一个CNN层用于提取输入词序列中第i个词的字符级特征w
词级BiLSTM220。以一个词序列X=(x
序列标签230的CRF。对于NER任务,对标记相关性进行建模很重要(例如,BIOES(起始、中间、其他、结尾和单个词)标签架构中的“I-ORG”必须遵循“B-ORG”),并且共同地解码最佳标记序列。因此,在一个或多个实施方式中,CRF组件230为推断层的更好选择,因为它可以通过保持状态转换矩阵作为其参数来动态地解码标记链并且捕获相邻标记之间的相关性。
给定来自BiLSTM组件220的隐藏词表示,
L
在这里,条件概率p(y|H)可以采用以下形式:
其中,
2.共指组件模型实施方式
如在图1中所示和讨论的,因为基础模型实施方式不考虑共指关系,因此它们很可能预测共指实体的不一致命名实体标签。
图3描述了根据本公开的实施方式的具有共指组件和正则化的文档级模型架构。类似于与在图1中描述的基础模型实施方式,模型架构300包括词嵌入组件310、附加特征嵌入组件315和包括字符嵌入组件302作为对CNN的输入的字符级CNN 305。这些组件302/305、310和315接收一个文档,或文档集合(如果批量完成或连续地完成),并且它们的输出被组合为词级双向长短期存储器组件320的输入。
为了减轻这个问题,在一个或多个实施方式中,如在图3中所示,在词级BiLSTM组件320和CRF层组件330之间添加共指组件或网络325,成为基础模型实施方式。共指组件325的添加合并了共指关系,用于学习在模型架构300中的共指感知词表示。
在一个或多个实施方式中,假定以共指群集350的形式给出文档级共指关系,该共指群集是基础事实或由第三方共指解析器生成的。在实施方式中,在任何两个共指群集之间没有重叠,因为如果它们共享任何实体提及,则它们将被合并为一个群集。作为共指层325的输入,令
具体地,在一个或多个实施方式中,给定来自共指知识350的共指群集和来自BiLSTM层320的隐藏词表示326,共指网络325的输出向量328具有以下形式:
其中,W
共指向量328的目标类似于在软注意力机制中使用的“上下文向量”,但是可以使用最大池化取代计算不同词向量的权重。显然,来自共指组件325的输出词向量328通过共指向量受到同一共指集群中其他隐藏词表示的影响。
在一个或多个实施方式中,可以使用共指组件325的极端变体,其直接地将共指向量用作输出,具有以下形式:
在本可替代实施方式中,在一个共指群集(例如,群集352)中的所有词共享标记标签的相同表示。这些可替代的实施方式在E.2节中进行比较和讨论。
3.共指正则化实施方式
从概念上讲,在一个共指群集中的隐藏词表示应该是类似的,以便CRF层330能够跨不同的共指提及做出一致的预测。在一个或多个实施方式中,为了指导共指层的词表示学习,可以将正则化应用到共指层组件325的输出词向量。在模型训练期间,作为最终目标函数的一部分,可以将生成的正则化项最小化。
在一个或多个实施方式中,正则化是“欧几里得共指正则化”,其计算欧几里得距离以惩罚两个共指词向量之间的差异。共指正则化项可以采用以下形式:
在一个或多个可替代实施方式中,正则化是“余弦共指正则化”,其使用余弦相似度来测量两个词向量的相似度。共指正则化项如下所示:
因此,用于完整模型实施方式的整体目标函数的可以是:
L=L
在E.2节中,比较了两种类型的共指正则化,并提出了设置共指正则化参数λ的合理策略。
图4描述了根据本公开的实施方式的用于训练共指感知NER模型的方法。在一个或多个实施方式中,将包括词的文档(或包括多个文档的批处理)输入(405)到诸如在图3中描述的共指感知命名实体识别(NER)网络中。对于文档的每个词,将输入层(即,词嵌入层310、附加特征嵌入层315和字符级CNN 305)的输出组合(410)成组合表示。词级BLSTM320使用组合表示来获得(415)在文档中的每个词的隐藏表示。在文档中的词的隐藏表示是共指层325的输入,共指层325输出(420)对于文档中的每个词的共指表示,其中作为同一共指群集的成分的词被分配了相同或类似的共指网络表示。CRF层330使用共指表示共同地确定(425)文档的标记序列。最后,最小化(430)目标函数以更新共指感知NER网络300的参数。在一个或多个实施方式中,目标函数包括共指正则化项345。
一旦共指感知NER模型(诸如在图3中描述的)被训练完成,可以形成训练过的模型用于NER任务。图5描述了根据本公开的实施方式的具有共指组件的训练过的共指感知NER模型架构,以及图6描述了根据本公开的实施方式的用于使用训练过的共指感知NER模型(诸如在图5中描述的训练过的模型500)的方法。
在一个或多个实施方式中,训练过的模型架构500包括一组输入,这些输入接收(605)文档输入,并且包括:词嵌入层510;附加特征嵌入层515,以允许输入一个或多个附加特征;字符级卷积神经网络(CNN)505,其中字符嵌入层502作为CNN的输入。这些组件302/305、310和315接收一个文档,或一组文档(如果批量完成),并且它们的组合输出(610)是对词级双向长短期存储器的组件520的输入。
词级BLSTM网络520使用组合表示来获得(615)文档中的每个词的隐藏表示。文档中的词的隐藏表示是共指层525的输入,共指层525输出(620)对于文档中的每个词的共指表示,其中作为同一共指群集的成分的词被分配了相同或类似的共指表示。CRF网络530使用共指表示共同地确定(625)文档的标记序列,其为训练过的模型500的最终输出。
D.实验
应注意,这些实验和结果是作为说明提供的,并且是在特定条件下使用特定的实施方式进行的;因此,这些实验及其结果均不得用于限制当前本专利文件的公开的范围。
1.数据集
模型实施方式在两个数据集上进行了测试。表1给出了这两个数据集的概述和统计数据。
表1:以命名实体的数量统计的数据集统计数据。
数据集1标注有4个粗粒度实体类型,包括人(PER)、位置(LOC)、组织(ORG)和其他(MISC),而数据集2标注有18个细粒度命名实体类型。与数据集1相比,数据集2语料库要大得多,涵盖的文字种类也更广泛。由于共指关系未在数据集1上标注,标准CoreNLP工具包的最新版本(Christopher D.Manning,Mihai Surdeanu,John Bauer,Jenny Finkel,StevenJ.Bethard和David McClosky,2014年,“标准CoreNLP自然语言处理工具包”,在计算语言学协会第52届年度会以论文集:系统演示,第55至60页)用于提取每个文档中的共指群集,尽管该工具包只能实现约60%的F1得分共指分辨率。为了直接比较,将相同的训练/开发/测试集拆分用于数据集。
2.实验设置
预处理。移除了所有带有“0”的数字字符,并将标签架构从BIO转换为BIOES,BIOES附加地使用“E-”和“S-”分别表示实体和单个词实体的结尾。在测试实施方式中,每个词的词性(POS)标签和大写(Cap)标示被用作额外特征,其将与词嵌入结合(例如,级联)。对于测试期间的所有共指群集,人称代词(例如,他、她、它)的词索引被隐藏了,因为这些词不是命名实体,并且虽然在实施方式中它们可以不被隐藏,但是它们并不会有助于识别同一共指群集中的命名实体。
固定vs动态词嵌入。诸如GloVe的预训练词嵌入有一个局限性,即每个词的表示都是固定的,而不考虑其上下文,这与一个词在不同上下文中可能具有不同含义这一事实相冲突。最近的成果(包括AllenAI的ELMo和Google的BERT)显示,从深度语言模型中学到的上下文相关(动态)词表示能够使神经网络受益于挑战性的NLP任务,而NLP任务优于传统的固定词嵌入。在本文中的实验中,在NER模型训练期间冻结了GloVe词嵌入(100D)和动态ELMo嵌入(1024D)(其中从AllenAI的网站(allennlp.org/elmo)下载了经过5.5B令牌训练的预训练的ELMo嵌入)及其参数,以初始化测试实施方式的词嵌入。
超参数。图7包含表2,其总结了根据本公开的实施方式的用于实验中的超参数。另外,SGD优化器与下降的学习速率一起使用以更新参数。由于数据集2语料库比数据集1语料库大得多,因此使用较大的批处理大小以加快模型训练的速度。对于共指正则化参数λ,它是基于在dev集上的最佳性能进行调整的。为防止梯度爆炸,梯度L2-范数的阈值限制为5.0,并使用系数10
评估。标准实体级微观平均F1得分被用作主要评估指标。为了减少随机性对训练神经网络模型的影响并报告稳定的实验结果,运行10次模型实施方式、其变体以及基础模型,并报告在多次试验上的平均F1得分和标准差。为了公平地比较,所有模型实施方式均由Pytorch实现,并在Nvidia Titan X GPU上使用相同的随机种子进行评估。
3.实验结果
图8包含表3,其示出了关于测试数据集的与最近发布的模型相比模型实施方式的性能。应注意,“Train+Dev”表示对开发集调整超参数后,训练集和开发集均用于模型训练,并且带有*标记的模型利用来自深层语言模型的词嵌入。在表3中引用的文档如下:
[Huang等人,2015]。黄志恒(Zhiheng Huang,)、徐伟(Wei Xu)和于凯(Kai Yu),“序列标签的双向LSTM-CRF模型”,arXiv预印本arXiv:1508.01991,2015年。
[Strubell等人,2017]。Emma Strubell,Patrick Verga,David Belanger和Andrew McCallum,“通过迭代的膨胀卷积实现快速准确的实体识别”,载于EMNLP,2017年。
[Shen等人,2018]。沈艳瑶(Yanyao Shen),Hyokun Yun,Zachary Lipton,YakovKronrod和Animashree Anandkumar,“命名实体识别的深度主动学习”,载于ICLR,2018年。
[Lample等人,2016]。Guillaume Lample,Miguel Ballesteros,SandeepSubramanian,Kazuya Kawakami和Chris Dyer,“命名实体识别的神经架构”,载于NAACLHLT,第260-270页,2016年。
[Ma和Hovy,2016]。马雪哲(Xuezhe Ma)和Eduard Hovy,“通过双向LSTM-CNNs-CRF进行端到端序列标记”,载于ACL,第1064-1074页,2016年。
[Liu等人,2018]。刘丽媛(Liyuan Liu)、尚静波(Jingbo Shang)、任翔(XiangRen)、徐方正(Frank Fangzheng Xu)、桂环(Huan Gui)、彭剑(Jian Peng)和韩佳玮(JiaweiHan),“使用任务感知神经语言模型进行赋予序列标记”,载于AAAI,2018年。
[叶和凌,2018]。叶志秀(Zhixiu Ye)和凌振华(Zhen-Hua Ling),“神经序列标记的混合半马尔可夫CRF”,载于ACL,第235-240页,2018年。
[Chiu和Nichols,2016]。Jason Chiu和Eric Nichols,“使用双向LSTM-CNN进行命名实体识别”,载于TACL,4:357-370,2016年。
[Yang等人,2017]。杨志林(Zhilin Yang)、Ruslan Salakhutdinov和WilliamCohen,“使用递归网络进行序列标签的传送学习”,载于ICLR,2017年。
[Tran等人,2017]。Quan Tran,Andrew MacKinlay和Antonio Jimeno Yepes,“使用堆栈残差LSTM和可训练偏差解码进行命名实体识别,”载于IJCNLP,第566-575页,2017年。
[Peters等人,2017]。Matthew Peters,Waleed Ammar,Chandra Bhagavatula和Russell Power,“使用双向语言模型进行半监督序列标签”,载于ACL,第1756-1765页,2017年。
ELMo[2018]。Matthew Peters,Mark Neumann,Mohit Iyyer,Matt Gardner,Christopher Clark,Kenton Lee和Luke Zettlemoyer。深度上下文化的词表示。载于NAACLHLT,第2227-2237页,2018年。
BERT Base[2019]。Jacob Devlin,张明伟(Jing-Wei Chang)、Kenton Lee和Kristina Toutanova.Bert:为语言理解的深度双向转换器的预训练。载于NAACL-HLT,2019年。
CVT+多任务[2018]。Kevin Clark,Minh-Thang Luong,Christopher Manning和Quoc Le。使用交叉视图训练的半监督序列建模。载于EMNLP,第1914-1925页,2018年。
表格的第一部分列出了除了训练集和预训练的固定词嵌入以外不使用任何外部数据的模型,而在第二部分的模型则出于不同目的利用外部数据(例如,用于词嵌入的训练语言模型[Peters等人,2018]或进行传送学习[Yang等人,2017])。在第三部分中,复制的CNN-BiLSTM-CRF模型比Ma和Hovy(2016)中最初报告的模型稍差。一个可能的原因是,正在执行的是文档级NER标签,而不是原始句子级实验(复制的CNN-BiLSTM-CRF模型为获得91.24%的F1得分的句子级NER标签)。
与基础模型相比,具有共指层组件的实施方式平均将NER性能提高了0.65点(统计显著性t-测试,p<0.01)。使用共指正则化来指导共指感知词表示学习提高了结果(与不使用共指正则化相比,统计显著性t-测试,p<0.05),但是比例较小。如在上一栏中所示,引入上下文相关的ELMo嵌入提高了NER的性能,当与最新的词嵌入技术结合使用时,进一步验证了模型实施方式的实用性。注意,完整模型实施方式显著地优于ELMo基线(在第二部分中的第五行)(93.37-92.22=1.15)点,可以得出结论,具有共指层和共指正则化的实施方式可以有效地提高NER性能,并且在实现最佳性能方面发挥重要作用。
总体而言,当使用来自语言模型的动态词嵌入时(与在表3中带有*标记的模型相比),完整模型实施方式实现了93.19%的F1得分的最先进性能,并且实现了当仅使用固定词嵌入时,根据本公开的实施方式同时获得91.65%的最佳F1得分。该结果证明了模型实施方式能够在不依赖于黄金共指关系的情况下有效地工作。
图9包含表4,其报告了实验结果以及对数据集2进行评估的在先的方法。在表4中引用的文档如下:
[Chiu和Nichols,2016]。Jason Chiu和Eric Nichols,“使用双向LSTM-CNN进行命名实体识别”,载于TACL,4:357-370,2016年。
[Shen等人,2018]。沈艳瑶(Yanyao Shen),Hyokun Yun,Zachary Lipton,YakovKronrod和Animashree Anandkumar,“命名实体识别的深度主动学习”,载于ICLR,2018年。
[Strubell等人,2017]。Emma Strubell,Patrick Verga,David Belanger和Andrew McCallum,“通过迭代的膨胀卷积实现快速准确的实体识别”,载于EMNLP,2017年。
[Li等人,2017]。李鹏轩(Peng-Hsuan Li)、董若平(Ruo-Ping Dong)、王玉香(Yu-Siang Wang)、周菊捷(Ju-Chieh Chou)和马卫云(Wei-Yun Ma),“利用语言结构使用双向递归神经网络进行命名实体识别”,载于EMNLP,第2664-2669页,2017年。
[Ghaddar和Langlais,2018]。Abbas Ghaddar和Philippe Langlais,“改进的神经网络命名实体识别的鲁棒词汇特征”,载于COLING,第1896-1907页,2018年。
CVT+多任务[2018]。Kevin Clark,Minh-Thang Luong,Christopher Manning和Quoc Le。使用交叉视图训练的半监督序列建模。载于EMNLP,第1914-1925页,2018年。
JointNERCoref[Luan等人,2018]。栾意(Yi Luan)、何路衡(Luheng He),MariOstendorf和Hannaneh Hajishirzi,“用于科学知识图构建的实体、关系和共指的多任务识别”,载于EMNLP,第3219-3232页,2018年。注意,由于代码是从bitbucket.org/luanyi/scierc/src/master/下载的,并且rel weight=0设置为禁用关系推断任务,因此在验证集上的宽范围内仔细地调整了其他网络架构超参数。
类似于在数据集1上的结果,通过使用具有共指层或具有共指层和共指正则化的实施方式,可以实现更好的NER性能。因此,完整的NER模型实施方式在数据集上也达到了89.83%的最先进的F1得分,大幅度优于Clark等人(2018)在先的最佳发表结果(88.81%)。此外,证明了从外部系统提取的有噪声的共指知识仍然可以在用于提高NER性能的当前专利文献中公开的框架实施方式中使用。
值得一提的是,最新的多任务共同NER和共指解析模型[Luan等人,2018]的表现逊于我们的实施方式,甚至劣于那些传统的序列标记方式。一个可能的原因是,通过共享NER和共指解析任务的中间层而进行的隐式知识传送没有明确地强加共指正则化有效。此外,所有可能的跨度候选者的蛮力枚举忽略了实体的子块之间的内部相关性,其能够通过序列标记被更好地捕获。
E.一些分析和讨论
1.消融研究
为了理解完整模型实施方式的每个主要组件做出了多少贡献,进行了消融研究,如在表5中所示。
表5:对数据集1的消融研究。当从完整模型中移除每个组件时,报告NER性能。如果使用共指正则化,则将其设置为λ=1.0。
显然,移除共指正则化和共指层分别使模型性能显著地劣化0.3和0.9点(统计显著性t-测试,p<0.01)。在扩展的词向量的三个部分(包括GloVe、字符和ELMo)中,ELMo嵌入做出的贡献最大,并且将NER结果平均提高了1.5个点,这与Peters等人(2018)的观察一致。
2.共指层的选择和共指正则化
类似vs.相同共指表示。对在3.2节中引入的共指层的两个变体进行了评估。在相同设置下,(基础模型+不具有共指正则化和ELMo的共指层)的比较研究显示,作为CRF层的输入,由等式(1)生成的类似共指表示(91.53%F1得分)明显地好于与等式(2)的输出完全相同的共指表示(91.21%F1得分)。一种可能的解释是,如果在一个共指群集中强制所有实体共享在向量空间中的相同表示,则单个实体的重要上下文信息丢失。
余弦vs.欧几里得共指正则化。在3.3节中引入了两种类型的共指正则化。实验结果显示,“余弦共指正则化”明显优于“欧几里得共指正则化”,F1得分为91.65%vs.91.23%(为了公平比较,我们设置λ=0.1)。与向量空间中的欧几里得距离相比,余弦相似度可以更好地参数化两个向量之间的相似度,这符合预期。
共指正则化λ的影响。从表6中可以看出,共指正则化参数λ对模型实施方式的性能具有不小的影响。建议从[0.1,1.0]范围内选择λ,并根据在数据中共指关系的密度进行调整(例如,对于较高的共指关系密度,选择较小的λ)。
表6:共指正则化λ对基础模型+共指层+共指正则化的影响。
3.共指知识质量的影响
由于黄金共指知识是稀有且有价值的,因此对于在本文中公开的框架实施方式而言,作为先验知识容忍有噪声的共指关系是很重要的。为了研究共指质量对模型实施方式的影响,通过以一定的概率(即,噪声百分比)随机地删除或波动(±5)共指实体的索引,将噪声逐渐添加到数据集2的黄金共指群集中。如在图10中所示,F1得分以较少的噪声快速地增加,并且共指层组件实施方式仍能够在共指知识中以60%的噪声提高NER性能,这证明了模型实施方式的鲁棒性。
4.案例研究
为了研究模型实施方式的行为并且更好地理解Ma和Hovy(2016)犯下的哪些类型的错误已通过当前专利文件的共指感知方法得到了校正,对数据集进行了错误分析。为了使当前实施方式的贡献清楚,两个模型均未使用ELMo嵌入。
相对于先前的模型,测试实施方式校正的一些错误类型包括以下内容(注意:在
1)边界-相对于同一实体的另一实例,在一个实体的一个实例中错误地包括一个或多个词(例如,“[
2)混合实体-当词集是两个或多个实体的混合时,将一组词错误地分组为单个实体(例如,“在[加拿大]
3)不一致类型-对于同一实体错误地预测了不同的标记类型(例如,“[
4)不一致边界-无法正确地将词组合在一起以正确地识别实体(例如,“加拿大人赢得[
5)类似实体-无法正确地预测类似实体的标记(例如,“[
案例研究的结果显示,当前专利文献的方法不仅有助于正确地预测在共指群集中的共指实体的语义类型(第二个、第三个和第五个示例),而且可以找到共指命名实体的准确边界(第一个、第四个和第五个示例)。
F.一些结论
在本文中提出的是用于NER任务的新型神经网络模型的实施方式,其通过明确地利用具有共指层组件实施方式的共指关系来建立共指感知词表示。另外,在一个或多个实施方式中,引入了共指正则化实施方式以确保共指实体在同一共指集群中共享类似表示和一致的预测。在两个基准上进行的实验证明,即使将有噪声的共指信息作为先验知识,具有共指层和共指正则化的完整模型实施方式也明显地优于所有在先的NER系统。
G.计算系统实施方式
在一个或多个实施方式中,本专利文件的各方面可以针对、可以包括或可以在一个或多个信息处理系统/计算系统上实现。计算系统可以包括可操作为计算、估算、确定、分类、处理、传输、接收、检索、发起、路由、切换、存储、显示、通信、呈现、检测、记录、再现、处置或利用任何形式的信息、情报或数据的任何工具或工具集合。例如,计算系统可以是或可包括个人计算机(例如,膝上型计算机)、平板计算机、平板手机、个人数字助理(PDA)、智能电话、智能手表、智能包装、服务器(例如,刀片式服务器或机架式服务器)、网络存储设备,相机或任何其他合适的设备,并且其大小、形状、性能、功能和价格可能有所不同。计算系统可以包括随机存取存储器(RAM)、一个或多个处理资源,诸如中央处理单元(CPU)或硬件或软件控制逻辑、ROM和/或其他类型的存储器。计算系统的附加组件可以包括一个或多个磁盘驱动器、用于与外部设备以及各种输入和输出(I/O)设备(诸如键盘、鼠标、触摸屏和/或视频显示器)通信的一个或多个网络端口。计算系统还可以包括可操作为在各种硬件组件之间传输通信的一条或多条总线。
图11描述了根据本公开的实施方式的计算设备/信息处置系统(或计算系统)的简化框图。将理解的是,针对系统1100示出的功能可以操作为支持计算系统的各种实施方式——尽管应理解,计算系统可以被不同地配置并且包括不同的组件,包括具有如在图11中所描述的更少或更多的组件。
如在图11中所示,计算系统1100包括一个或多个中央处理单元(CPU)1101,其提供计算资源并控制计算机。CPU 1101可以以微处理器等实现,并且还可以包括一个或多个图形处理单元(GPU)1119和/或用于数学计算的浮点协处理器。系统1100还可以包括系统存储器1102,其可以是随机存取存储器(RAM)、只读存储器(ROM)或两者的形式。
如在图11中所示,还可以提供多个控制器和外围设备。输入控制器1103表示到各种输入设备1104的接口,诸如键盘、鼠标、触摸屏和/或触笔。计算系统1100还可以包括用于与一个或多个存储设备1108接合的存储控制器1107,每个存储设备1108包括诸如磁带或磁盘等的存储介质,或可以用于记录用于操作系统、实用程序和应用程序的指令程序的光学介质,其可以包括实现本公开的各个方面的程序的实施方式。根据本公开,存储设备1108也可以用于存储处理后的数据或待处理的数据。系统1100还可以包括用于向显示设备1111提供接口的显示控制器1109,显示设备可以是阴极射线管(CRT)、薄膜晶体管(TFT)显示器、有机发光二极管、电致发光面板、等离子面板或其他类型的显示器。计算系统1100还可以包括用于一个或多个外围设备1106的一个或多个外围控制器或接口1105。外围设备的示例可以包括一个或多个打印机、扫描仪、输入设备、输出设备、传感器等。通信控制器1114可以与一个或多个通信设备1115接口,这使得系统1100能够通过包括因特网、云资源(例如,以太网云、以太网上的光纤通道(FCoE)/数据中心桥接(DCB)云等)、局域网(LAN)、广域网(WAN)、存储区域网(SAN)或通过任何合适的电磁载波信号(包括红外信号)的各种网络中的任何一个连接到远程设备。
在所示的系统中,所有主要系统组件可以连接到总线1116,该总线1116可以表示一条以上的物理总线。然而,各种系统组件可能在物理上彼此接近或不彼此接近。例如,输入数据和/或输出数据可以从一个物理位置远程地传输到另一物理位置。另外,可以通过网络从远程位置(例如,服务器)访问实现本公开的各个方面的程序。可以通过各种机器可读介质中的任何一种来传送这样的数据和/或程序,所述机器可读介质包括但不限于:诸如硬盘、软盘和磁带等的磁性介质;光学介质,诸如CD-ROM和全息设备;磁光介质;以及专门配置用于存储或存储并执行程序代码的硬件设备,诸如专用集成电路(ASIC)、可编程逻辑设备(PLD)、闪存设备以及ROM和RAM设备。
本公开的各方面可以使用用于一个或多个处理器或处理单元的指令在一个或多个非暂时性计算机可读介质上进行编码来执行各步骤。应注意,一个或多个非暂时性计算机可读介质应包括易失性和非易失性存储器。应注意,可替代实施方式是可能的,包括硬件实施方式或软件/硬件实施方式。可以使用ASIC、可编程阵列、数字信号处理电路等来实现硬件实现的功能。因此,任何权利要求中的“手段”术语旨在涵盖软件和硬件实现。类似地,在本文中所使用的术语“计算机可读介质”包括其上包含指令程序的软件和/或硬件,或其组合。考虑到这些实现方式的可替代方式,应理解,附图和随附的描述提供了本领域技术人员用于编写程序代码(即软件)和/或制造电路(即硬件)所需要的功能信息以执行所需的处理。
应注意,本公开的实施方式可以进一步涉及具有非暂时性有形计算机可读介质的计算机产品,其上具有用于执行各种计算机实现的操作的计算机代码。介质和计算机代码可以是出于本公开的目的而专门设计和构造的那些,或者它们可以是相关领域技术人员已知或可获得的类型。有形的计算机可读介质的示例包括但不限于:诸如硬盘、软盘和磁带等的磁性介质;光学介质,诸如CD-ROM和全息设备;磁光介质;以及专门配置用于存储或存储并执行程序代码的硬件设备,诸如专用集成电路(ASIC)、可编程逻辑设备(PLD)、闪存设备以及ROM和RAM设备。计算机代码的示例包括机器代码,诸如由编译器生成的机器代码,以及包含由计算机使用解释器执行的更高级别代码的文件。本公开的实施方式可以全部或部分地实现为机器可执行指令,该机器可执行指令可以位于由处理设备执行的程序模块中。程序模块的示例包括库、程序、例程、对象、组件和数据结构。在分布式计算环境中,程序模块可以物理地位于本地、远程或两者的设置中。
本领域技术人员将认识到,没有任何计算系统或编程语言对于本公开的实践是必不可少的。本领域技术人员还将认识到,上述许多元件可以在物理和/或功能上分离为子模块或者组合在一起。
本领域技术人员将理解,前述示例和实施方式是示例性的,并且不限制本公开的范围。意图在于,对本领域技术人员而言,在阅读说明书和研究附图之后显而易见的所有排列、增强、等同、组合和改进都包括在本公开的真实精神和范围内。还应注意,任何权利要求的元素可以被不同地布置,包括具有多个相关性、配置和组合。
- 用于神经命名实体识别的共指感知表示学习
- 用于使用神经序列模型进行客户旅程事件表示学习和结果预测的系统和方法