电子装置及其控制方法
文献发布时间:2023-06-19 11:00:24
技术领域
本公开涉及一种电子装置及其控制方法,更具体地,涉及一种识别图像输入数据中包括的对象的动作的电子装置及其控制方法。
背景技术
为了接收图像数据并识别图像数据中包括的对象的动作,可以使用人工智能学习网络模型。在此,经过训练的模型可以确定输入图像中包括的对象正在采取何种动作。特别地,为了确定对象采取何种动作,需要复杂的计算过程。
另外,为了提供正确的识别结果,人工智能模型应该使用大量的学习数据。通常,可以使用直接用相机拍摄对象以生成学习数据的运动捕获方法。然而,在运动捕获方法中,可能不方便直接拍摄对象。例如,物体可以是太大而无法用相机拍摄的物体,或者是难以获取的物体。
因此,运动捕获方法具有以下问题:它可能具有用于生成大量学习数据的物理限制,并且成本可能很高。
发明内容
技术问题
本公开旨在改进上述问题,并且本公开的目的在于提供一种通过使用3D 人体模型来生成用于姿势识别的学习网络模型的电子装置及其控制方法。
问题的解决方案
根据本公开的实施例,用于实现上述目的的电子装置包括:显示器;处理器,所述处理器电连接到所述显示器以控制所述显示器;以及存储器,所述存储器电连接到所述处理器,其中所述存储器存储指令,所述指令使所述处理器控制所述显示器以显示通过将输入2D图像应用于被配置为将所述输入2D图像转换为3D建模图像的学习网络模型而获取的3D建模图像,以及其中所述学习网络模型是通过使用渲染虚拟3D建模数据而获取的3D姿势和与所述3D姿势相对应的2D图像来训练的学习网络模型。
在此,学习网络模型是基于数据将3D人体模型转换为多个3D姿势并获取与多个3D姿势中的每一个相对应的至少一个2D图像,并且通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来训练的学习网络模型。
此外,学习网络模型可以识别被包括在所述输入2D图像中的对象的轮廓信息,并获取与轮廓信息相对应的所述3D人体模型。
此外,学习网络模型可以转换3D人体模型的姿势,使得基于3D人体模型中包括的关节划分的多个身体部位基于3D建模数据在预定角度范围内移动,并且获取与转换后的姿势相对应的至少一个2D图像。
此外,学习网络模型可以基于3D建模数据将3D人体模型转换为3D 姿势,并且获取与关于3D姿势的不同方向相对应的多个2D图像。
同时,3D建模数据可以包括基于3D人体模型中包括的关节划分的多个身体部位之中的角度数据、每个身体部位的长度数据或每个身体部位的方向数据中的至少一个。
此外,学习网络模型可以通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来学习包括在学习网络模型中的神经网络的权重。
同时,处理器可以在输入用于改变用户视点的用户指令时,将与用户指令相对应的信息输入到学习网络模型中,并且基于与用户指令相对应的信息来输出3D建模图像。
此处,用户视点包括用户观看的方向或用户观看的距离中的至少一个。
此外,处理器可以提供用于接收输入的用于转换3D人体模型的姿势信息的UI。
根据本公开的实施例的电子装置的控制方法包括以下步骤:接收输入的2D图像;以及显示通过将所述输入2D图像应用于被配置为将所述2D 图像转换为3D建模图像的学习网络模型而获取的3D建模图像,其中学习网络模型是通过使用渲染虚拟3D建模数据而获取的3D姿势和与所述 3D姿势相对应的2D图像来训练的学习网络模型。
此处,学习网络模型是基于数据将3D人体模型转换为多个3D姿势并获取与多个3D姿势中的每一个相对应的至少一个2D图像,并且通过使用多个3D姿势和与所述多个3D姿势中的每一个相对应的至少一个2D 图像来训练的学习网络模型。
此外,学习网络模型可以识别被包括在输入2D图像中的对象的轮廓信息,并获取与轮廓信息相对应的3D人体模型。
此外,学习网络模型可以转换3D人体模型的姿势,使得基于3D人体模型中包括的关节而划分的多个身体部位基于3D建模数据在预定角度范围内移动,并获取与转换后的姿势相对应的至少一个2D图像。
此外,学习网络模型可以基于3D建模数据将3D人体模型转换为3D 姿势,并获取与关于3D姿势的不同方向相对应的多个2D图像。
此外,3D建模数据可以包括基于3D人体模型中包括的关节划分的多个身体部位之中的角度数据、每个身体部位的长度数据或每个身体部位的方向数据中的至少一个。
此外,学习网络模型可以通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来学习包括在学习网络模型中的神经网络的权重。
此外,电子装置的控制方法还可以包括以下步骤:在输入用于改变用户视点的用户指令时,将与用户指令相对应的信息输入到学习网络模型中,并且基于与用户指令相对应的信息来输出3D建模图像。
此处,用户视点包括用户观看的方向或用户观看的距离中的至少一个。
此外,电子装置的控制方法可以提供用于接收输入的用于转换3D人体模型的姿势信息的UI。
附图说明
图1是示出识别图像中包括的对象的动作的过程的图;
图2是示出通过运动捕获方法获取学习数据的方法的图;
图3是示出根据本公开的实施例的电子装置的框图;
图4是示出图3中电子装置的详细配置的框图;
图5是示出生成3D人体模型的操作的图;
图6是示出利用图5中生成的3D人模型来获取根据本公开的实施例的 2D图像的操作的图;
图7是示出利用图5中生成的3D人模型来获取根据本公开的另一实施例的2D图像的操作的图;
图8是示出基于由图7获取的2D图像获取学习数据的操作的图;
图9是示出适用于3D人体模型的多个姿势的图;
图10是示出基于由图9获取的2D图像获取学习数据的操作的图;
图11是示出3D人体模型关节点的图;
图12是示出根据图11的接触3D人体模型的关节点的身体部位的运动的图;
图13是示出改变3D人体模型的特定身体部位的操作的图;
图14是示出根据本公开的实施例的生成图像学习网络模型的方法的图;
图15至图17是示出学习部和识别部的操作的图;以及
图18是示出根据本公开的实施例的电子装置的控制方法的流程图。
具体实施方式
在详细描述本公开之前,将描述本说明书和附图的描述格式。
首先,作为在本说明书和权利要求书中使用的术语,考虑到本公开的各种实施例中的功能来选择通用术语。但是,术语可以根据本领域技术人员的意图,法律或技术解释或新技术的出现而变化。另外,存在一些由申请人任意指定的术语,并且在这种情况下,这些术语的含义可以按照本说明书中的定义来解释。在没有术语的特定定义的情况下,可以基于本说明书的整体内容和相关技术领域中的公知技术知识来解释术语的含义。
另外,在本说明书所附各附图中描述的相同附图标记或符号指代执行基本相同功能的组件或元件。为了便于解释和理解,在不同的实施例中,将通过使用相同的附图标记或符号来描述组件或元件。也就是说,即使在多个附图中示出了具有相同附图标记的所有元件,但是这些多个附图也不意味着实施例。
另外,在本说明书和权利要求书中,包括序数的术语例如“第一”,“第二”等可以用于区分元件。这些序号用于将相同或相似的元件彼此区分开,并且由于使用了这些序数,因此不以限制性方式解释术语的含义。这些术语仅用于将一个元素与另一个元素区分开的目的。例如,与这样的序数组合的元素的使用顺序或排列顺序等不受该数字的限制。另外,根据需要,每个序号可以互换使用。
此外,在本说明书中,单数表达式包括复数表达式,除非上下文中有明显不同的定义。此外,在本公开中,诸如“包括”和“包括”之类的术语应被解释为指明存在说明书中描述的特征、编号、步骤、操作、元件、组件或其组合,但不排除预先存在或可能添加一个或更多个其他特征、数字、步骤、操作、元素、组件或其组合。
另外,可以对本公开的实施例进行各种修改,并且可以存在各种类型的实施例。因此,将在附图中示出特定实施例,并且将在详细描述中详细描述实施例。然而,应当注意,各种实施例不用于将本公开的范围限制为特定的实施例,而是应当将它们解释为包括在此公开的思想和技术范围中包括的实施例的所有修改、等同形式或替代形式。在此,在确定在描述实施例中,相关的已知技术的详细解释可能不必要地混淆本公开的要旨的情况下,将省略该详细说明。
此外,在本公开的实施例中,诸如“模块”、“单元”和“部件”之类的术语是指执行至少一个功能或操作的元件,并且这些元件可以被实现为硬件或软件,或作为硬件和软件的组合。此外,可以将多个“模块”、“单元”和“部件”集成到至少一个模块或芯片中并实现为至少一个处理器,除非它们中的每一个都需要实现为独立的特定硬件时。
另外,在本公开的实施例中,一部分与另一部分连接的描述不仅包括直接连接的情况,还包括通过另一种介质间接连接的情况。而且,除非有特别的相反描述,否则对部件包括元件的描述意味着可以进一步包括另一元件,但是不排除另一元件。
本公开中的计算可以由基于机器学习的识别系统来执行,并且在本公开中,基于深度学习的识别系统是通过基于神经网络的一系列机器学习算法的分类系统,将被描述为示例。
基于深度学习的识别系统可以包括至少一个分类器,并且分类器可以对应于一个或更多个处理器。处理器可以实现为多个逻辑门的阵列,也可以实现为通用微处理器和存储可在微处理器中执行的程序的存储器的组合。
分类器可以实现为基于神经网络的分类器、支持向量机(SVM)、Adaboost 分类器、贝叶斯分类器、感知器分类器等。下文将描述本公开中的分类器实现为基于卷积神经网络(CNN)的分类器的实施例。基于神经网络的分类器是通过使用由连接线连接的大量人工神经元来模拟生物系统的计算能力的操作模型,并且它通过具有连接强度(权重)的连接线来执行人类的认知操作或学习过程。然而,本公开中的分类器不限于此,并且该分类器显然可以实现为前述各种分类器。
通用神经网络包括输入层、隐藏层和输出层,并且隐藏层可以根据需要包括一个或更多个层。反向传播算法可以用作训练这种神经网络的算法。
当某些数据被输入到神经网络的输入层时,分类器可以训练神经网络,使得用于输入学习数据的输出数据被输出到神经网络的输出层。当输入从所拍摄的图像中提取的特征信息时,分类器可以通过使用神经网络将特征信息的模式分类为若干类中的任何一类,并输出分类结果。
处理器是基于神经网络的一系列机器学习算法的分类系统,并且它可以使用基于深度学习的识别系统。
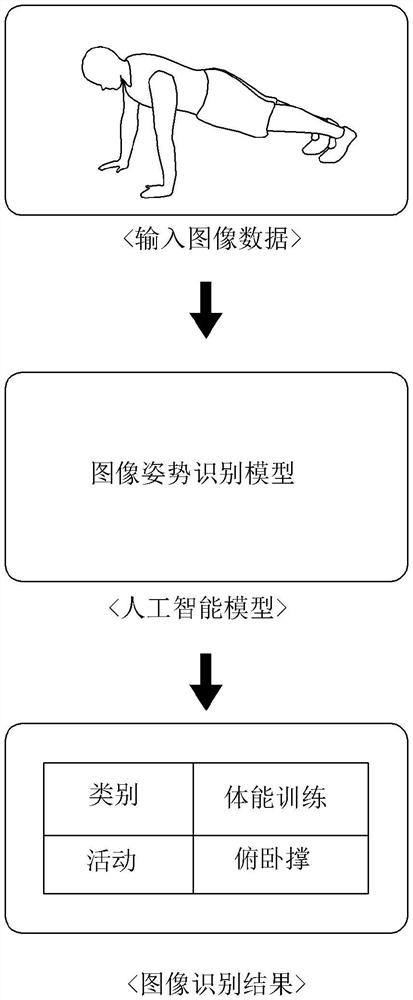
图1是用于示出识别图像中包括的对象的动作的过程的图。
用户可以使用人工智能模型来识别特定图像中包括的对象的姿势。例如,如果将图像作为输入数据输入到人工智能模型中,则人工智能模型可以分析输入图像。图像学习网络模型可以分析输入图像数据,并获取类别或操作中至少一个的结果值。在根据图1的实施例中,图像学习网络模型可以获取包括体能训练类别或俯卧撑操作之间的至少一个信息的结果值。
图2是用于示出通过运动捕获方法获取学习数据的方法的图。
为了生成图1中提到的图像学习网络模型,可能需要大量的数据。用于生成图像学习网络模型的数据将被称为学习数据。电子装置100可以生成图像学习网络模型,当存在更多学习数据时,该图像学习网络模型的识别率更高或者结果的可靠性更高。
同时,用户可以使用运动捕获方法来获取用于生成图像学习网络模型的学习数据。运动捕获方法可以是指通过使用相机拍摄对象并通过使用所拍摄的图像生成学习数据的方法。例如,可以通过在工作室中使用至少一个相机来拍摄特定对象。在此,在存在多个相机的情况下,可以存在多个所获取的 2D图像。然后,人可以直接输入关于拍摄对象的操作的信息。然后,电子装置100可以匹配拍摄对象的图像和人直接输入的拍摄对象的操作,并生成学习数据。
然而,通过图2中描述的运动捕获方法生成学习数据在时间和成本方面可能无效。由于图像学习网络模型必须直接拍摄要识别的所有姿势,因此成本可能很高,而且可能需要花费大量时间。此外,如果对象比工作室大,可能很难拍摄对象。此外,如果在工作室中直接拍摄像动物那样不容易,则可能很难生成学习数据。
图3是用于示出根据本公开的实施例的电子装置的框图。
电子装置100可以包括存储器110、显示器115和处理器120。
电子装置100可以是电视、台式PC、膝上型计算机、智能手机、平板电脑、服务器等。替代地,电子装置100可以实现为一个系统,其中云计算环境是自己构建的,即云服务器。具体地,电子装置100可以是包括基于深度学习的识别系统的装置。同时,上述示例仅仅是用于描述电子装置的示例,并且电子装置不一定限于上述装置。
存储器110可以电连接到处理器120,并且可以实现为各种形式的存储器。例如,在存储器嵌入到电子装置100中的情况下,存储器可以实现为易失性存储器(例如:动态RAM(DRAM)、静态RAM(SRAM)或同步动态 RAM(SDRAM)等)或非易失性存储器(例如:一次性可编程ROM (OTPROM)、可编程ROM(PROM)、可擦除可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)、掩模ROM、闪存ROM、闪存(例如:NAND 闪存或NOR闪存等)、硬盘驱动器(HDD)或固态驱动器(SSD))中的至少一个。在存储器可以附接到电子装置100或从电子装置100拆卸的情况下,存储器可以以诸如存储卡(例如,紧凑型闪存(CF)、安全数字(SD)、微型安全数字(Micro-SD)、小型安全数字(Mini-SD)、极限数字(xD)、多媒体卡(MMC)等)、可连接到USB端口(例如,USB存储器)的外部存储器等的形式实现。
存储器110可以存储与电子装置100的至少一个其他组件有关的指令或数据。例如,存储器110可以存储用于控制处理器120的操作的指令。根据本公开的实施例,存储器110可以存储指令,该指令使处理器120控制显示器以显示通过将输入2D图像应用于被配置为将2D图像转换为3D建模图像的学习网络模型而获取的3D建模图像。
此外,根据本公开的实施例,存储器110可以存储学习网络模型。这里,学习网络模型可以是使用通过渲染虚拟3D建模数据而获取的3D姿势和与该 3D姿势相对应的2D图像来训练的学习网络模型。
显示器115可以实现为各种形式的显示器,例如液晶显示器(LCD)、有机发光二极管(OLED)显示器、等离子显示面板(PDP)等。在显示器内部还可以包括驱动电路、背光单元等,该驱动电路可以以诸如a-si TFT、低温多晶硅(LTPS)TFT和有机TFT(OTFT)等的形式实现。同时,显示器可以实现为与触摸传感器、柔性显示器、3D显示器等组合的触摸屏。
此外,根据本公开的实施例的显示器115不仅可以包括输出图像的显示面板,而且可以包括容纳该显示面板的边框。具体地,根据本公开的实施例的边框可以包括用于检测用户交互的触摸传感器(未示出)。处理器120可以与存储器110电连接,并执行电子装置的整体控制操作。具体地,处理器执行控制电子装置的整体操作的功能。
处理器120可以实现为处理数字图像信号的数字信号处理器(DSP)、微处理器、时间控制器(TCON)等。然而,本公开不限于此,并且处理器120 可以包括中央处理单元(CPU)、微控制器单元(MCU)、微处理单元(MPU)、控制器、应用处理器(AP)或通信处理器(CP)以及ARM处理器中的一个或更多个,或可以由这些术语定义。而且,处理器可以实现为具有存储在其中的处理算法的片上系统(SoC)或大规模集成(LSI),或者以现场可编程门阵列(FPGA)的形式实现。
处理器120可以与显示器115电连接并且控制显示器。
此外,处理器120可以根据存储在存储器110中的指令将2D图像输入到学习网络模型中,并且将从学习网络模型输出的3D建模图像显示在显示器115上。在此,2D图像可以是拍摄的图像,例如,静止图像或运动图像中的至少一个。
在此,如上所述,学习网络模型可以是使用通过渲染虚拟3D建模数据而获取的3D姿势和与该3D姿势相对应的2D图像来训练的学习网络模型。在此,3D建模图像可以意味着虚拟3D角色图像。例如,假设通过相机拍摄了男孩正在踢足球的图像。通过相机拍摄的男孩的图像可以包括在2D图像中。当2D图像被输入到学习网络模型中时,学习网络模型可以分析2D图像并识别2D图像中包括的对象。学习网络模型可以识别2D图像中包括的对象是男孩,以及男孩正在踢足球的图像。然后,学习网络模型可以生成男孩正在踢足球的3D建模图像。2D图像可以包括正在踢足球的实际男孩的图像,并且3D建模图像可以包括虚拟3D角色(男孩的3D角色)正在踢足球的场景。
即,学习网络模型可以生成(获取)与输入2D图像相对应的3D建模图像。
根据本公开的实施例,处理器120可以执行控制以将3D建模数据应用于3D人体模型而生成用于学习的2D图像。然后,处理器120可以通过学习网络模型来转换用于输入的2D图像以生成3D建模图像。在此,3D建模数据可以包括用于获取3D建模图像的各种数据。即,可以根据不同的3D建模数据来获取不同的3D建模图像。
例如,假设存在女性形状的3D人体模型。在作为女性的3D人体模型采用图9所示的四种3D姿势的情况下,3D建模数据可以根据每个姿势而变化。当改变3D建模数据时,从学习网络模型输出的3D建模图像被改变,因此可以改变显示在显示器115上的3D人体模型的操作、大小、方向等。
同时,由于3D人体模型和3D角色是在虚拟空间中显示的虚拟模型,因此它们可以相同或相似。但是,在本说明书中,为了便于说明,将在生成学习数据的过程中使用的虚拟角色称为3D人体模型,并且将与对应于输入2D 图像的3D建模图像相对应的虚拟角色描述为3D角色。在此,在从一开始就使用与2D图像相对应的3D人体模型的情况下,显然3D人体模型和3D角色可以是相同的。
同时,学习网络模型可以基于数据将3D人体模型转换为多个3D姿势,并获取与多个3D姿势中的每一个相对应的至少一个2D图像,并且可以通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来对其进行训练。例如,假设3D人体模型正在采取与第一姿势相对应的3D姿势。3D人体模型可以在显示器115上表示为一个图像。然而,由于3D人体模型是立体的,因此可以以360度在任何方向上观看3D人体模型,并且3D 人体模型的尺寸可以根据观看位置而变化。采取第一姿势的3D人体模型可以根据观看位置、角度、距离信息(3D建模数据)等来获取多个2D图像。稍后将在图6和图7中描述获取多个2D图像的详细操作。
处理器120可以针对3D人体模型所采取的多个姿势中的每一个获取2D 图像。在这种情况下,可能存在与一个姿势相对应的多个2D图像。具体地,即使3D人体模型采取一个姿势,也可能存在与多个方向相对应的多个2D图像。在此,不同的方向可以表示在三维空间中观看3D人体模型的虚拟方向 (或相机的视点)可以不同。例如,假设3D人体模型存在于三维空间中。3D人体模型在从前表面观看的情况下和在从后表面观看的情况下可以显示完全不同的图像,并且处理器120可以在考虑方向信息的情况下获取完全不同的2D图像。在此,如果假设用户正在观看3D人体模型,则方向信息可以是观看位置。例如,如果假设用户正在从右侧观看3D人体模型,则处理器 120可以获取用户可以识别的2D图像。这并不意味着用户实际上可以从右侧观看3D人体模型,而是假定从虚拟空间的右侧观看在虚拟空间中生成的3D 人体模型。
此外,学习网络模型可以识别输入2D图像中包括的对象的轮廓信息,并获取与该轮廓信息相对应的3D人体模型。在此,轮廓信息可以表示输入 2D图像中包括的对象的信息。通常,对象可以对应于人或动物。另外,轮廓信息可以表示可以指定2D图像中包括的对象的外观(操作)的各种信息。例如,轮廓信息可以表示与性别、年龄、身高、脸型、发型或操作中的至少一个相对应的信息。在此,该操作可以是指示对象正在进行何种动作的信息。
此外,学习网络模型可以转换3D人体模型的姿势,使得基于3D人体模型中包括的关节划分的多个身体部位基于3D建模数据在预定角度范围内移动,并且获取与转换后的姿势相对应的至少一个2D图像。
在此,身体部位是指在关节之间连接的身体部位。例如,连接在腕关节和肘关节之间的身体的一部分可以是身体部位。
3D人体模型可以包括多个关节。在此,关节可以是指骨骼与骨骼基于人或动物而相连接的部位。通常,在人或动物身上,骨骼可以移动的范围根据特定的关节而受到限制。例如,颈部向上、下、左和右方向移动,但是颈部不会360度旋转。这是因为关节部位限制了骨骼可以移动的范围。学习网络模型可以通过将不同的角度应用于3D人体模型的每个关节来转换3D人体模型的姿势。然后,学习网络模型可以获取与转换后的姿势相对应的2D图像。在此,稍后将在图11和图12中进行关于关节的描述。
此外,学习网络模型可以基于3D建模数据将3D人体模型转换为3D姿势,并获取与关于3D姿势的不同方向相对应的多个2D图像。稍后将在图9 和图10中描述将3D人体模型转换为特定姿势的操作。另外,稍后将在图6 和图7中描述获取与不同方向相对应的多个2D图像的处理。
同时,3D建模数据可以包括基于3D人体模型中包括的关节而划分的多个身体部位之中的角度数据、每个身体部位的长度数据或每个身体部位的方向数据中的至少一个。稍后将在图11和图12中进行关于关节和多个身体部位的描述。
此外,学习网络模型可以通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来学习包括在学习网络模型中的神经网络的权重。
同时,如果输入了用于改变用户视点的用户指令,则处理器120可以将与该用户指令相对应的信息输入到学习网络模型中。学习网络模型可以基于与用户指令相对应的信息来输出3D建模图像。3D建模图像可以是显示3D 角色的图像,并且用户视点是从电子装置100的用户的立场观看的标准,并且其含义可以与相机的拍摄时间点相似。
在此,用户视点可以包括用户观看的方向或用户观看的距离中的至少一个。例如,在电子装置100的用户从虚拟空间中的前表面观看3D角色的情况下,在用户从侧表面观看3D角色的情况下以及在用户从后表面观看3D角色的情况下,视点可以变化。稍后将在图6和图7中描述可以根据用户视点来获取不同的2D图像的内容。
另外,处理器120可以提供用于接收姿势信息的输入的UI,以用于转换 3D人体模型。在此,UI可以包括类别信息或姿势信息。例如,在足球类别中,可以包括前进姿势、射门姿势、抽拉姿势、滑动姿势等。如果用户选择特定类别,则处理器120可以将与该类别相对应的信息输入到学习网络模型中,并且在显示器上提供从学习网络模型输出的3D建模图像。
同时,学习网络模型可以将3D人体模型转换为多个姿势,并获取与多个姿势中的每一个相对应的至少一个2D图像,并且通过使用多个姿势和与多个姿势中的每一个相对应的至少一个2D图像来执行学习。
例如,学习网络模型可以基于与第一姿势相对应的多个第一3D建模数据来获取与第一姿势相对应的多个2D图像,并且基于与第二姿势相对应的多个第二3D建模数据来获取与第二姿势相对应的多个2D图像。在此,第一姿势和第二姿势可以是彼此不同的姿势。
这里,第一3D建模数据可以包括基于3D人体模型中包括的关节而划分的多个身体部位中的第一角度数据、每个身体部位的第一长度数据或每个身体部位的第一方向数据中的至少一个。第二3D建模数据可以包括基于3D人体模型中包括的关节而划分的多个身体部位中的第二角度数据、每个身体部位的第二长度数据或每个身体部位的第二方向数据中的至少一个。
例如,对于伸展双臂的站立姿势,可以存在多个3D建模数据。例如,即使对于伸展双臂时站立的相同动作,3D建模数据也可以根据伸展双臂的角度差异或双脚的距离长度差异而有所不同。例如,尽管显示相同的姿势,但是每个3D建模数据在身体部位之间的角度数据、身体部位的长度数据或身体部位的方向数据中的至少一个方面可能不同。例如,对于伸展双臂时的站立姿势,可以存在双臂与躯干成90度角的情况和成85度角的情况。因此,学习网络模型可以针对一个姿势学习不同的3D建模数据。
此外,学习网络模型可以通过使用基于不同3D建模数据获取的多个姿势和与多个姿势中的每一个相对应的至少一个2D图像来学习神经网络的权重。例如,学习网络模型可以通过使用基于3D人体模型中包括的关节划分的多个身体部位中的角度、每个身体部位的长度或每个身体部位的方向中的至少一个而获取的多个姿势以及与多个姿势中的每一个相对应的至少一个 2D图像来学习神经网络的权重。
本公开公开了一种操作,该操作生成虚拟对象并在虚拟空间中转换该对象,并考虑各种方向信息来获取多个2D图像。根据本公开,不必拍摄实际对象,因此可以节省时间和成本。
在人工智能学习网络模型中,学习数据越多,识别率越高。由于可以通过本公开的方法生成各种学习数据,因此本公开有助于生成具有良好识别率的人工智能模型。
此外,使用实际模型(行动者)的运动捕获方法需要后处理工作,因此可能需要花费大量时间来生成学习数据。然而,根据本公开,不需要单独地进行后处理作业,并且程序自动获取2D图像,因此可以减少生成学习数据的时间。
同时,在根据本公开的方法中,使用了虚拟3D人体模型,因此与使用实际模型相比可能存在偏差。为了消除这种偏差,可以通过使用从3D人体模型获取的2D图像和从实际对象(由相机拍摄的对象)获取的2D图像两者来生成学习数据。
同时,在上述实施例中,描述了显示器包括在电子装置100中,但是在实际实现中,电子装置100可以仅执行与学习网络模型有关的操作以及可以在单独的显示装置中执行显示3D人体模型的操作。
另外,为了生成难以在工作室中拍摄的动作作为学习数据,在传统方法中可能存在很多限制。例如,在体育运动中,拍摄特定的动作可能非常困难。在静止不动的状态或模型(行动者)难以采取的姿势的情况下,可能很难生成学习数据。然而,根据本公开的方法,可以通过仿真容易地生成学习数据。另外,由于生成了针对各种角度和方向的学习数据,因此可以期待识别率反而提高的效果。
同时,在上述描述中,描述了3D角色,同时限制了它是3D人体模型,即人。然而,这仅是示例,并且3D角色可以是3D人体模型以外的动物。因此,根据本公开的学习网络模型可以是用于识别动物的外观或姿势的学习网络模型。根据本公开的另一实施例,学习网络模型可以是用于识别人或动物以外的对象的学习网络模型。
图4是用于示出图3中的电子装置的详细配置的框图。
参照图4,根据本公开实施例的电子装置100可以包括存储器110、显示器115、处理器120、通信接口130、用户接口140以及输入和输出接口150。
在存储器110和处理器120的操作中,关于与上述描述的操作相同的操作,将省略重复的说明。
处理器120通过使用存储在存储器110中的各种程序来控制电子装置100 的整体操作。
具体地,处理器120包括RAM 121、ROM 122、主CPU 123、第一至第 n接口124-1至134-n和总线125。
RAM 121、ROM 122、主CPU 123和第一至第n接口124-1至134-n可以通过总线125相互连接。
在ROM 122中,存储了用于系统启动等的一组指令。当输入接通指令并供电时,主CPU 123根据存储在ROM 122中的指令将存储在RAM 110中的存储器110中的O/S复制到RAM121中,并通过执行O/S来启动系统。当启动完成时,主CPU 123将存储在存储器110中的各种应用程序复制到RAM 121中,并通过执行复制在RAM 121中的应用程序来执行各种操作。
主CPU 123访问存储器110,并通过使用存储在存储器110中的O/S来执行引导。然后,主CPU通过使用存储在存储器110中的各种程序、内容数据等来执行各种操作。
第一接口124-1至第n接口134-n与上述各种组件连接。接口之一可以是通过网络与外部装置连接的网络接口。
同时,处理器120可以执行图形处理功能(视频处理功能)。例如,处理器120可以通过使用运算部(未示出)和渲染部(未示出)来生成包括诸如图标、图像和文本的各种对象的屏幕。在此,运算部(未示出)可以基于接收到的控制指令根据屏幕的布局来运算显示每个对象的诸如坐标值、形状、大小和颜色之类的属性值,并且,渲染部(未示出)可以基于在运算部(未示出)运算出的属性值来生成包括对象的各种布局的屏幕。而且,处理器120 可以执行各种图像处理,诸如视频数据的解码、缩放、噪声滤波、帧速率转换和分辨率转换。
同时,处理器120可以执行音频数据的处理。具体地,处理器120可以执行各种处理,诸如音频数据的解码或放大、噪声滤波等。
同时,处理器120可以包括图形处理单元(GPU)或神经处理单元(NPU)。 GPU可以对应于用于图形处理的高性能处理装置,并且NPU是AI芯片组,并且可以是AI加速器。同时,NPU可以对应于代替GPU或与GPU一起执行深度学习模型的处理装置。
通信接口130是根据各种类型的通信方法与各种类型的外部装置执行通信的组件。通信接口130包括Wi-Fi模块131、蓝牙模块132、红外通信模块 133和无线通信模块134等。处理器120可以通过使用通信接口130执行与各种外部装置的通信。在此,外部装置可以包括诸如电视的显示装置、诸如机顶盒的图像处理装置、外部服务器、诸如遥控器的控制装置、诸如蓝牙扬声器的音频输出装置、照明装置、诸如智能清洁器和智能冰箱的家用电器、诸如物联网家庭管理器的服务器等。
Wi-Fi模块131和蓝牙模块132分别通过Wi-Fi方法和蓝牙方法执行通信。在使用Wi-Fi模块131或蓝牙模块132的情况下,首先发送和接收诸如SSID 和会话密钥之类的各种类型的连接信息,并且通过使用该信息来执行通信连接,并且此后可以发送和接收各种类型的信息。
红外通信模块133根据红外数据协会(IrDA)技术执行通信,该技术通过使用可见光和毫米波之间的红外线将数据无线传输到近场。
除上述Wi-Fi模块131和蓝牙模块132之外,无线通信模块134是指根据诸如Zigbee、第三代(3G)、第三代合作伙伴计划(3GPP)、LTE(长期演进)、LTE高级(LTE-A)、第四代(4G)、第五代(5G)等的各种通信标准执行通信的模块。
除上述之外,通信接口130可以包括局域网(LAN)模块、以太网模块或有线通信模块中的至少一个,该有线通信模块通过使用双绞线、同轴电缆或光纤电缆等执行通信。
根据本公开的实施例,通信接口130可以使用相同的通信模块(例如, Wi-Fi模块)与诸如遥控器的外部装置和外部服务器进行通信。
根据本公开的另一实施例,通信接口130可以使用不同的通信模块(例如,Wi-Fi模块)与诸如遥控器的外部装置和外部服务器进行通信。例如,通信接口130可以使用以太网模块或Wi-Fi模块中的至少一个与外部服务器进行通信,并且可以使用BT模块与诸如遥控器的外部装置进行通信。然而,这仅是示例,并且在与多个外部装置或外部服务器进行通信的情况下,通信接口130可以使用各种通信模块中的至少一个通信模块。
同时,根据实现示例,通信接口130还可以包括调谐器和解调部。
调谐器(未示出)可以调谐在通过天线接收的射频(RF)信号中由用户选择的信道或所有预存的信道,并接收RF广播信号。
解调部(未示出)可以接收在调谐器处转换的数字IF(DIF)信号并解调该信号,并且执行信道解调等。
用户接口140可以实现为诸如按钮、触摸板、鼠标和键盘之类的装置,或者实现为可以一起执行上述显示功能和操作输入功能的触摸屏。在此,按钮可以是各种类型的按钮,例如机械按钮、触摸板、滚轮等。这些按钮形成在电子装置100的主体外部的任何区域中,例如前面部、侧面部、背面部等。
输入和输出接口150可以是高清多媒体接口(HDMI)、移动高清链接 (MHL)、通用串行总线(USB)、显示端口(DP)、Thunderbolt、视频图形阵列(VGA)端口、RGB端口、D超小型(D-SUB)或数字视频接口(DVI) 中任何一个接口。
HDMI是一种接口,可以为输入和输出音频和视频信号的AV装置传输高性能数据的接口。DP是一种接口,不仅可以实现1920×1080的全高清屏幕,还可以实现2560×1600或3840×2160等超高清屏幕和3D立体图像,并且还可以传输数字语音。Thunderbolt是用于传输和连接高速数据的输入和输出接口,可以用一个端口并行连接PC机、显示器、存储装置等。
输入和输出接口150可以输入和输出音频信号或视频信号中的至少一个。
根据实现示例,输入和输出接口150可以包括仅输入和输出音频信号的端口和仅输入和输出视频信号的端口作为单独的端口,或者实现为同时输入和输出音频信号和视频信号的一个端口。
用于与外部装置和外部服务器进行通信的通信模块可以被实现为一个。例如,用于与外部装置和外部服务器进行通信的通信模块可以与Wi-Fi模块相同。
此外,用于与外部装置和外部服务器进行通信的通信模块可以单独地实现。例如,可以通过使用蓝牙模块来执行与外部装置的通信,并且可以通过使用以太网模型或Wi-Fi模块来执行与外部服务器的通信。
图5是用于说明生成3D人体模型的操作的图。
为了生成图像学习网络模型,用户可以通过使用电子装置100来生成3D 人体模型(3D角色),并控制电子装置100以使3D人体模型采取特定姿势。在此,对于3D人体模型,可以根据用户的设置生成各种模型(角色)。然后,用户可以通过使用采取特定姿势的3D人体模型来控制电子装置100以获取 2D图像。上述操作可以被称为3D人体模型(3D角色)捕获方法。虽然图2 中描述的运动捕获方法是通过使用相机来拍摄实际对象的方法,但是图5中描述的3D人体模型(3D角色)捕获方法不使用相机。在3D人体模型捕获方法中,基于虚拟生成的3D人体模型来获取2D图像。稍后将在图6和图7 中描述获取2D图像的具体方法。
在此,根据本公开的实施例描述了3D人体模型,但是该模型不必限于人体模型。例如,模型可以是动物模型而不是人体模型。根据本公开的另一实施例,电子装置100可以使用各种对象模型。
图6是示出通过使用图5中生成的3D人模型来获取根据本公开的实施例的2D图像的操作的图。
电子装置100可以控制所生成的3D人体模型采取特定姿势。在此,特定姿势可以是根据用户设置的姿势。例如,如果用户将使3D人体模型采取伸展手臂的姿势的控制指令输入到电子装置100中,则电子装置100可以控制3D人体模型采取伸展手臂的姿势。在此,电子装置100可以包括显示器,并且电子装置100可以在显示器上显示3D人体模型正在伸展手臂的姿势。
同时,电子装置100可以基于采取特定姿势的3D人体模型来获取2D图像。具体地,电子装置100可以在三维空间中生成3D人体模型,并且电子装置100可以基于在三维空间中观看3D人体模型的方向来获取2D图像。
参照图6,电子装置100的显示器上有面向前方的3D人体模型。在此,电子装置100可以获取3D人体模型的前表面图像、左侧表面图像(从观看 3D角色的视点来看为左侧)、后表面图像和右侧表面图像(从观看3D角色的视点来看为右侧)。
前表面图像可以是从前表面观看在三维空间中生成的3D人体模型的图像。在此,从前表面观看3D人体模型的意义可以是获取当从用户的站姿从前表面(基于3D人体模型的前表面)观看时可以识别的2D图像的信息。左侧表面图像可以是指当使用电子装置100的显示器从用户的站姿从左侧表面 (基于3D人体模型的右侧表面)观看时可以识别的2D图像的信息。后表面图像可以是指当使用电子装置100的显示器从用户的站姿从后表面(基于3D人体模型的后表面)观看时可以识别的2D图像的信息。右侧表面图像可以是指当使用电子装置100的显示器从用户的站姿从右侧表面(基于3D人体模型的左侧表面)观看时可以识别的2D图像的信息。
在图6中,描述了根据四个方向获取2D图像的方法。然而,这仅是示例,并且可以在任何方向上获取在三维空间中观看3D人体模型的2D图像。即,电子装置100可以在360度的任何方向上获取基于3D人体模型的2D图像。
由于电子装置100包括用于3D人体模型的三维图像信息,电子装置100 可以获取当在特定方向上观看时可以识别的图像的信息。例如,为了获取在特定方向上观看的2D图像,电子装置100可以移除三维图像信息中的特定维度的信息,并且仅获取二维图像信息。然后,电子装置100可以针对由3D 人体模型通过图6中描述的方法采取的一个姿势获取多个2D图像。
图7是示出通过使用图5中生成的3D人模型来获取根据本公开的另一实施例的2D图像的操作的图。
参照图7,电子装置100可以以各种角度旋转所生成的3D人体模型。然后,电子装置100可以将以各种角度旋转的3D人体模型显示为好像在显示器上的三维空间中旋转一样。然后,电子装置100可以使用旋转的3D人体模型来获取2D图像。例如,电子装置100可以通过根据3D人体模型的旋转执行“打印屏幕功能”来获取3D人体模型的2D图像。“打印屏幕功能”可指捕获显示在显示器上的特定区域的图像。
参照图7,电子装置100可以通过“打印屏幕功能”获取根据用户设置或预定事件旋转的3D人体模型的2D图像。然后,电子装置100可以针对由 3D人体模型通过图7中描述的方法采取的一个姿势获取多个2D图像。
图8是示出基于由图7获取的2D图像来获取学习数据的操作的图。
假设电子装置100如图1所示获取了前表面、左侧表面、后表面和右侧表面图像(总共4种2D图像)。电子装置100可以通过使用2D图像来生成学习数据。电子装置100可以将所获取的2D图像与用于生成学习数据的特定姿势进行匹配。
例如,在图7中,3D人体模型可以采取伸展手臂的姿势。电子装置100 可以根据用户指令控制3D人体模型采取伸展手臂的姿势,并且电子装置100 可以在显示器上显示采取伸展手臂姿势的3D人体模型的屏幕。在此,伸展手臂的姿势(第一姿势)可以是姿势的名称。此外,姿势的类别可以由用户直接定义。图7中描述的伸展手臂的姿势可以对应于“基本姿势”的类别。
参照图7,电子装置100可以将2D图像与类别或姿势中的至少一个进行匹配。然后,电子装置100可以将匹配的信息用作学习数据。电子装置100 可以使用与一个姿势相对应的多个2D图像作为学习数据。电子装置100可以将多个2D图像发送到学习数据获取部。然后,电子装置100可以通过使用在学习数据获取部获取的2D图像来生成图像学习网络模型。稍后将在图 15到图17中对学习数据获取部进行详细描述。
在一个类别中,可以包括多个姿势。例如,基本姿势可以包括各种姿势,例如伸展手臂的姿势、收拢手臂的姿势、坐下并将手臂放在膝盖上的姿势、收拢手臂并放下手的姿势等。
此外,一个姿势可以包括在多个类别中。例如,踢脚姿势可以包括在各种类别中,例如足球类别、武术类别、橄榄球类别等。在此,如果输入到图像学习网络模型中的图像对应于踢脚姿势,则电子装置100可以获取将对应于足球类别、武术类别和橄榄球类别的概率值。此外,电子装置100可以将具有最高概率值的类别确定为最终识别的输出值。
图9是用于说明适用于3D人体模型的多个姿势的图。
参照图9,电子装置100可以使用3D人体模型并控制模型采取各种姿势。例如,电子装置100可以控制3D人体模型采取第一姿势、第二姿势、第三姿势和第四姿势中的任何一个姿势。第一姿势至第四姿势是彼此不同的姿势,并且电子装置100可以在显示器上显示与每个姿势相对应的3D人体模型的图像。
例如,电子装置100可以根据用户的输入显示与3D人体模型对应的图像,并采取多个姿势。然后,电子装置100可以通过图6或图7中描述的方法并使用采取多个姿势的3D人体模型来获取2D图像。然后,电子装置100 可以针对每个姿势(第一姿势到第四姿势)获取多个2D图像。
图10是示出基于由图9获取的2D图像获取学习数据的操作的图。
电子装置100可以通过使用与由图9获取的多个姿势中的每一个相对应的多个2D图像来生成学习数据。具体地,电子装置100可以将所获取的2D 图像与类别或姿势名称中的至少一个进行匹配。例如,假设第一姿势至第四姿势对应于瑜伽姿势的类别。电子装置100可以将瑜伽姿势(类别)或第一姿势(姿势名称)中的至少一个与对应于第一姿势的2D图像进行匹配。以相同的方式,电子装置100可以将瑜伽姿势(类别)或第二姿势(姿势名称)中的至少一个与对应于第二姿势的2D图像进行匹配。在这种情况下,对于每个姿势,可能存在与第一姿势(第二姿势)相对应的多个2D图像。然后,电子装置100可以将多个匹配的信息发送到学习数据获取部。学习数据获取部可以通过使用所获取的2D图像匹配信息来生成图像学习网络模型。
图11是用于说明3D人体模型的关节点的图。
参照图11,电子装置100可以根据用户设置获取3D人体模型的关节点。关节可以是指骨骼与骨骼基于人或动物而相连接的部位。通常,在人或动物身上,骨骼可以移动的范围根据特定的关节而受到限制。例如,颈部向上、下、左和右方向移动,但是颈部不会360度旋转。这是因为关节部位限制了骨骼可以移动的范围。
电子装置100可执行控制以显示图像,其中3D人体模型通过使用关节点采取特定姿势。具体地,3D人体模型的关节点可以是头部、肩部、颈部、胸部、胃、背部、骨盆、肘部、手腕、指关节、膝盖、脚踝、脚趾关节等。在此,电子装置100可以仅使用上述关节点中的特定关节点,使得3D人体模型采取特定姿势。在使用大量关节点的情况下,电子装置100的数据处理速度可能变慢。因此,电子装置100可以通过仅使用用于数据处理速度的一些关节点来控制(操纵)3D人体模型。可以根据用户设置来确定将使用哪些关节点。
根据本公开的另一实施例,电子装置100可以另外指定3D人体模型的关节点。
图12是示出根据图11的3D人体模型的与关节点接触的身体部位的运动的图。
电子装置100可以生成用于学习数据的各种姿势。在此,电子装置100 可以基于特定姿势来转换3D人体模型的姿势,以自动生成各种姿势。然后,电子装置100可以在显示器上显示采用转换后的姿势的3D人体模型的外观。
例如,为了转换采取第一姿势的3D人体模型,电子装置100可以在第一姿势中移动与某些关节点相对应的身体部位。然后,电子装置100可以捕获通过移动身体部位而获取的3D人体模型并获取2D图像。
在此,身体部位是指连接关节的身体部位。例如,连接在腕关节和肘关节之间的身体的一部分可以是身体部位。
如图11所述,对于每个关节点,可以限制连接到关节点的骨骼可以移动的范围。在操纵3D人体模型时,电子装置100可以进行限制,使得骨骼在特定关节点的特定角度内移动。
例如,可以设置颈部关节,使得颈部仅向左和向右移动180度。在图12 中,仅显示左侧和右侧的角度,但是在实际实现中,还可以设置上下方向的角度。此外,可以将肘关节设置为使得臂部仅移动180度。此外,可以对每个关节应用不同的角度。例如,可以将膝关节设置为使得腿部仅移动160度。而且,可以将踝关节设置为使得脚部仅移动140度。电子装置100可以对多个关节应用不同的角度,并且对于应用有不同角度的关节,电子装置100可以执行控制,使得连接到关节的身体部位仅移动到不同的角度。此外,考虑到应用于图12中描述的关节的角度限制,电子装置100可以生成3D人体模型的姿势。
同时,在图12中,仅以关节的任意一个方向为例进行描述,对于一个关节,可以根据轴设定多个角度限制。
图13是示出改变3D人体模型的特定身体部位的操作的图。
参照图13,电子装置100可以通过改变连接在特定关节和特定关节之间的身体部位的长度来生成新的3D人体模型。例如,假设踝关节和膝关节之间的身体部位被设置为40cm。为了生成各种学习数据,可能需要针对一个较高的人的学习数据。在这种情况下,电子装置100可以通过延长现有3D人体模型的高度来获取学习数据。为了生成高个子的3D人体模型,电子装置 100可以将踝关节和膝关节之间的身体部位从40cm转换为60cm。
电子装置100可以通过使用一个3D人体模型来获取2D图像,并且还可以通过使用多个3D人体模型来获取2D图像。可以通过各种方法使用诸如性别、体重、身高等身体信息来生成3D人体模型。在针对各种3D人体模型获取2D图像的情况下,识别率可能会更高。
根据本公开的电子装置100可以通过使用虚拟3D人体模型而无需使用各种实际模型来容易地获取采取特定姿势的各种3D人体模型的2D图像。通过使用虚拟3D人体模型,本公开可以达到节省时间和成本的效果。
图14是示出根据本公开的实施例的生成图像学习网络模型的方法的图。
电子装置100可以根据用户设置生成3D人体模型。然后,电子装置100 可以根据用户设置控制3D人体模型采取3D姿势。最终,电子装置100可以在显示器上显示采取特定3D姿势的3D人体模型,并且电子装置100可以根据图6或图7中描述的内容来获取2D图像。
然后,电子装置100可以通过匹配特定的3D姿势和与该特定的3D姿势相对应的2D图像来生成学习数据。然后,电子装置100可以通过使用所生成的学习数据来执行深度学习,并生成图像学习网络模型。
电子装置100可以通过使用生成的图像学习网络模型对输入数据执行姿势识别操作。电子装置100可以通过使用图像学习网络模型来分析存储在外部装置中或预先存储的输入数据,并且猜测(确定,推断)包括在输入数据中的对象的主体以及对象的主体正在采取什么样的姿势。
上述实施例中描述的由电子装置100执行的各种操作可以在根据本公开的实施例的学习网络中执行。
图15至图17是示出学习部和识别部的操作的图。
参照图15,处理器1500可以包括学习部1510和识别部1520中的至少一个。图15中的处理器1500可以对应于电子装置100的处理器120或数据学习服务器(未示出)的处理器。
学习部1510可以生成或训练具有用于确定特定情况的标准的识别模型。学习部1510可以通过使用收集的学习数据来生成具有用于确定的标准的识别模型。
作为示例,学习部1510可以生成、训练或更新对象识别模型,该模型具有通过使用包括对象的图像作为学习数据来确定图像中包括何种对象以及对象正在采取何种动作的标准。
作为另一示例,学习部1510可以生成、训练或更新环境信息识别模型,该模型具有通过使用包括对象的屏幕中包括的周围环境的信息作为学习数据来确定图像中包括的对象周围的各种附加信息的标准。
作为又一示例,学习部1510可以生成、训练或更新面部识别模型,该模型具有通过使用输入图像作为学习数据来确定图像中包括的用户的面部的标准。
识别部1520可以通过使用特定数据作为训练后的识别模型的输入数据来假设特定数据中包括的识别对象以及识别对象的动作(姿势)。
作为示例,识别部1520可以通过使用包括对象的对象区域(或图像)作为训练后的识别模型的输入数据来获取(或假设,推断)对象区域中包括的对象的对象信息。
作为另一示例,识别部1520可以通过将对象信息或上下文信息中的至少一个应用于训练后的识别模型来假设(或确定,推断)搜索类别以提供搜索结果。在此,可以根据优先级获取多个搜索结果。
作为另一示例,识别部1520可以通过将上下文信息(例如,对象的环境信息)应用到训练后的识别模型来假设与对象相关的上下文识别信息(例如,与对象相关的附加信息等)。
学习部1510的至少一部分和识别部1520的至少一部分可以实现为软件模块,或以至少一个硬件芯片的形式制造,并安装在电子装置上。例如,学习部1510和识别部1520中的至少一个可以以用于人工智能(AI)的专用硬件芯片的形式制造,或者作为常规通用处理器(例如:CPU或应用处理器) 或图形专用处理器(例如:GPU)的一部分制造,并安装在上述各种电子装置或对象识别装置上。在此,用于人工智能的专用硬件芯片是专门用于概率运算的处理器,与常规通用处理器相比,它在并行处理中具有更高的性能,并且能够快速处理诸如机器学习之类的人工智能领域中的运算工作。在学习部1510和识别部1520实现为软件模块(或包括指令的程序模块)的情况下,该软件模块可以被存储在非暂时性计算机可读介质中。在这种情况下,软件模块可以由操作系统(OS)或特定应用程序提供。替代地,软件模块的一部分可以由操作系统(OS)提供,而其他部分可以由特定应用程序提供。
在这种情况下,学习部1510和识别部1520可以安装在一个电子装置上,或者分别安装在单独的电子装置上。例如,学习部1510和识别部 1520中的一个可以包括在电子装置100中,而另一个可以包括在外部服务器中。另外,学习部1510和识别部1520可以通过有线或无线连接,并且由学习部1510构造的模型信息可以被提供给识别部1520,并且输入到识别部1520 的数据可以作为附加学习数据被提供给学习部分1510。
图16是根据本公开的各种实施例的学习部1510和识别部1520的框图。
参照图16(a),根据本公开的一些实施例的学习部1510可以包括学习数据获取部1510-1和模型学习部1510-4。而且,学习部1510可以选择性地进一步包括学习数据预处理部1510-2、学习数据选择部1510-3或模型评估部1510-5中的至少一个。
学习数据获取部1510-1可以获取用于推断待识别对象或待识别对象的动作(姿势)的识别模型所需的学习数据。根据本公开的实施例,学习数据获取部1510-1可以获取包括对象的整个图像、与对象区域相对应的图像、对象信息或上下文信息中的至少一个作为学习数据。学习数据可以是由学习部 1510或学习部1510的制造商收集或测试的数据。
模型学习部1510-4可以训练识别模型,使其具有关于如何通过使用学习数据来确定特定的识别对象或识别对象的动作(姿势)的确定标准。例如,模型学习部1510-4可以通过使用至少一些学习数据作为确定标准的监督学习来训练识别模型。替代地,例如,模型学习部1510-4可以通过无监督学习来训练识别模型,该无监督学习是通过使用学习数据在没有任何监督的情况下通过自学习来寻找确定情况的确定标准。另外,例如,模型学习部1510-4可以通过使用关于根据学习的情况的判断结果是否正确的反馈的强化学习,来训练识别模型。另外,模型学习部1510-4可以通过使用例如包括误差反向传播或梯度下降的学习算法等来训练识别模型。
此外,模型学习部分1510-4可以通过使用输入数据来学习关于使用哪些学习数据来假设识别对象的选择标准。
在存在预先构造的多个识别模型的情况下,模型学习部1510-4可以将输入学习数据与基本学习数据之间的相关性高的识别模型确定为要训练的识别模型。在这种情况下,可以针对每种类型的数据预先分类基本学习数据,并且可以针对每种类型的数据预先构造识别模型。例如,可以根据诸如生成学习数据的区域、生成学习数据的时间、学习数据的大小、学习数据的类型、学习数据的生成者、学习数据中的对象类型等各种标准来预先分类基本学习数据。
当训练识别模型时,模型学习部1510-4可以存储训练后的识别模型。在这种情况下,模型学习部1510-4可以将训练后的识别模型存储在电子装置A 的存储器1750中。替代地,模型学习部1510-4可以将训练后的识别模型存储在经由有线或无线网络与电子装置A连接的服务器的存储器中。
学习部1510还可包括学习数据预处理部1510-2和学习数据选择部 1510-3,用于改进识别模型的分析结果,或节省生成识别模型所需的资源或时间。
学习数据预处理部1510-2可以对所获取的数据进行预处理,使得所获取的数据可以用于学习中以确定情况。而且,学习数据预处理部1510-2可以以预定格式处理所获取的数据,使得模型学习部1510-4可以将所获取的数据用于学习以确定情况。
学习数据选择部1510-3可以从在学习数据获取部1510-1获取的数据或在学习数据预处理部1510-2预处理的数据中选择学习所需的数据。所选择的学习数据可以被提供给模型学习部1510-4。学习数据选择部1510-3可以根据预定的选择标准从所获取的或预处理的数据中选择学习所需的学习数据。而且,学习数据选择部1510-3可以根据预定标准选择学习数据,以便通过模型学习部1510-4的学习来进行选择。
学习部1510还可以包括用于改进数据识别模型的分析结果的模型评估部1510-5。
模型评估部1510-5可以将评估数据输入到识别模型中,并且在从评估数据输出的分析结果不满足预定标准的情况下,模型评估部1510-5可以使模型学习部1510-4重新学习。在这种情况下,评估数据可以是用于评估识别模型的预定义数据。
例如,在分析结果不正确的评价数据的数目或比率超过预定阈值的情况下,在针对评价数据的训练后的识别模型的分析结果中,模型评价部分1510-5 可以确定不满足预定标准。
同时,在存在多个训练后的识别模型的情况下,模型评价部1510-5可以确定每个训练后的识别模型是否满足预定标准,并且确定满足预定标准的模型作为最终识别模型。在这种情况下,如果存在满足预定标准的多个模型,则模型评估部1510-5可以确定以具有较高评估分数的顺序预先设置的任何一个或预定数目的模型作为最终识别模型。
参照图16中的(b),根据本公开的一些实施例的识别部1520可以包括识别数据获取部1520-1和识别结果提供部1520-4。
此外,识别部1520还可以选择性地包括识别数据预处理部1520-2、识别数据选择部1520-3或模型更新部1520-5中的至少一个。
识别数据获取部1520-1可以获取确定情况所需的数据。识别结果提供部1520-4可以将在识别数据获取部1520-1获取的数据作为输入值应用于经训练后的识别模型并确定情况。识别结果提供部1520-4可以根据分析数据的目的来提供分析结果。识别结果提供部1520-4可以将由将在下面描述的识别数据预处理部1520-2或识别数据选择部1520-3选择的数据作为输入值应用于识别模型,并获取分析结果。分析结果可以由识别模型确定。
作为示例,识别结果提供部1520-4可以将包括在识别数据获取部1520-1 获取的对象的对象区域应用于训练后的识别模型,并获取(或假设)与该对象区域相对应的对象信息。
作为另一示例,识别结果提供部1520-4可以将在识别数据获取部1520-1 获取的对象区域、对象信息或上下文信息中的至少一个应用于训练后的识别模型,并获取(或(假定)搜索类别以提供搜索结果。
识别部1520还可以包括识别数据预处理部1520-2和识别数据选择部 1520-3,用于改进识别模型的分析结果,或者节省用于提供分析结果的资源或时间。
识别数据预处理部1520-2可以对所获取的数据进行预处理,使得所获取的数据可以用于确定情况。另外,识别数据预处理部1520-2可以以预定格式处理所获取的数据,使得识别结果提供部1520-4可以使用所获取的数据来确定情况。
识别数据选择部1520-3可以在识别数据获取部1520-1获取的数据或在识别数据预处理部1520-2预处理的数据中选择确定情况所需的数据。所选择的学习数据可以被提供给识别结果提供部1520-4。识别数据选择部1520-3可以根据用于确定情况的选择的预定标准来选择所获取的或预处理的数据中的一些或全部。另外,识别数据选择部1520-3可以根据预定标准选择数据,以便通过模型学习部1510-4学习来进行选择。
模型更新部1520-5可以基于对由识别结果提供部1520-4提供的分析结果的评估来控制要更新的识别模型。例如,模型更新部1520-5可以将识别结果提供部1520-4提供的分析结果提供给模型学习部1510-4,从而请求模型学习部1510-4额外地训练或更新识别模型。
图17是示出根据本公开的实施例的电子装置A和服务器S通过相互联锁来学习和识别数据的实施例的图。
参照图17,服务器S可以学习用于确定情况的标准,并且电子装置A可以基于服务器S的学习结果来确定情况。
在这种情况下,服务器S的模型学习部1510-4可以执行图15所示的学习部分1510的功能。服务器S的模型学习部1510-4可以学习关于将使用哪个对象图像、对象信息或上下文信息来确定特定情况以及如何通过使用数据来确定情况的标准。
此外,电子装置A的识别结果提供部1520-4可以将由识别数据选择部 1520-3选择的数据应用于由服务器S生成的识别模型,并确定对象信息或搜索类别。替代地,电子装置A的识别结果提供部1520-4可以从服务器S接收由服务器S生成的识别模型,并且通过使用接收到的识别模型来确定情况。在这种情况下,电子装置A的识别结果提供部1520-4可以将由识别数据选择部1520-3选择的对象图像应用于从服务器S接收的识别模型,并且确定与对象图像相对应的对象信息。替代地,识别结果提供部1520-4可以通过使用上下文信息或上下文识别信息中的至少一个来确定搜索类别以获取搜索结果。
图18是示出根据本公开的实施例的电子装置的控制方法的流程图。
在根据本公开的实施例的电子装置100的控制方法中,在操作S1805中可以输入2D图像。另外,在控制方法中,在操作S1810中,可以显示通过将输入2D图像应用于被配置为将2D图像转换为3D建模图像的学习网络模型而获取的3D建模图像。在此,学习网络模型可以是通过使用渲染虚拟3D 建模数据而获取的3D姿势和与该3D姿势相对应的2D图像来训练的学习网络模型。
在此,学习网络模型可以是基于数据将3D人体模型转换为多个3D姿势并获取与多个3D姿势中的每一个相对应的至少一个2D图像,并且使用多个 3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来训练的学习网络模型。
此外,学习网络模型可以识别被包括在输入2D图像中的对象的轮廓信息,并获取与该轮廓信息相对应的3D人体模型。
另外,学习网络模型可以转换3D人体模型的姿势,使得基于3D人体中包括的关节划分的多个身体部位基于3D建模数据在预定角度范围内移动,并获取与转换后的姿势相对应的至少一个2D图像。
此外,学习网络模型可以基于3D建模数据将3D人体模型转换为3D姿势,并且获取与关于3D姿势的不同方向相对应的多个2D图像。
此外,3D建模数据可以包括基于3D人体模型中包括的关节而划分的多个身体部位中的角度数据、每个身体部位的长度数据或每个身体部位的方向数据中的至少一个。
此外,学习网络模型可以通过使用多个3D姿势和与多个3D姿势中的每一个相对应的至少一个2D图像来学习包括在学习网络模型中的神经网络的权重。
此外,在电子装置100的控制方法中,当输入用于改变用户视点的用户指令时,可以将与用户指令相对应的信息输入到学习网络模型中,并且学习网络模型可以基于与用户指令相对应的信息来输出3D建模图像。
在此,用户视点可以包括用户观看的方向或用户观看的距离中的至少一个。
此外,电子装置100的控制方法可以提供用于接收输入的用于转换3D 人体模型的姿势信息的UI。
同时,如图18所示的电子装置的控制方法可以在具有如图3或图4所示的配置的电子装置中执行,或者在具有其他配置的电子装置中执行。
同时,根据本公开的上述各种实施例的方法可以以能安装在常规电子装置上的应用的形式来实现。
此外,根据本公开的上述各种实施例的方法可以仅通过常规电子装置的软件升级或硬件升级来实现。
此外,本公开的上述各种实施例可以通过提供给电子装置的嵌入式服务器或者通过电子装置的外部服务器来实现。
同时,根据上述实施例的电子装置的控制方法可以实现为程序并提供给电子装置。具体地,可以将包括电子装置的控制方法的程序存储在非暂时性计算机可读介质中而提供。
此外,上述各种实施例可以通过使用软件、硬件或其组合在可由计算机或类似于计算机的装置读取的记录介质中实现。根据硬件实现,本公开中描述的实施例可以通过使用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理装置(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列 (FPGA)、处理器、控制器、微控制器、微处理器或执行各种功能的电子单元中的至少一个来实现。在一些情况下,本说明书中描述的实施例可以实现为处理器120本身。此外,根据软件实现,本说明书中描述的诸如过程和功能的实施例可以实现为单独的软件模块。每个软件模块可以执行本说明书中描述的一个或更多个功能和操作。
同时,根据本公开的上述各种实施例的用于在电子装置处执行处理操作的计算机指令可以存储在非暂时性计算机可读介质中。当存储在这种非暂时性计算机可读介质中的计算机指令由特定机器的处理器执行时,使得根据上述各种实施例的电子装置处的处理操作由特定机器执行。
非暂时性计算机可读介质是指半永久性地存储数据并可以由机器读取的介质,而不是诸如寄存器、高速缓存和存储器之类的短时间存储数据的介质。作为非暂时性计算机可读介质的具体示例,可以有CD、DVD、硬盘、蓝光盘、USB、存储卡、ROM等。
虽然已经示出并描述了本公开的优选实施例,但本公开并不限于上述具体实施例,并且显而易见,本公开所属技术领域的普通技术人员可以进行各种修改,在不脱离所附权利要求所要求保护的本公开的要点的情况下。此外,意图是不独立于本公开的技术思想或前景来解释此类修改。
- 电子装置控制方法以及应用电子装置控制方法的电子装置
- 电子装置、电子装置控制方法以及电子装置系统