语音数据处理方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 11:49:09
技术领域
本申请涉及计算机技术领域,特别是涉及一种语音数据处理方法、装置、计算机设备和存储介质。
背景技术
目前,车辆中的智能语音服务都是单任务工作模式,只能同时为单个人进行服务,并且对于用户服务定制仅仅依赖于登录账号。而硬件依赖于最基本的语音硬件结构(如一个显示器,一套单通道或者多通道mic)。然而,如果说多个人同时在一辆车上,该车辆中的单一设备则无法同时对多个人进行语音服务,并且也无法精准地按到不同人的特质(如性别,年龄),从而进行相应的语音服务。
发明内容
基于此,有必要针对上述技术问题,提供一种能够语音数据处理方法、装置、计算机设备和存储介质,存在多个语音服务实例,并单独绑定区域硬件和指定用户声纹,能够互不干扰地为多个用户提供语音服务。
一种语音数据处理方法,该方法包括:
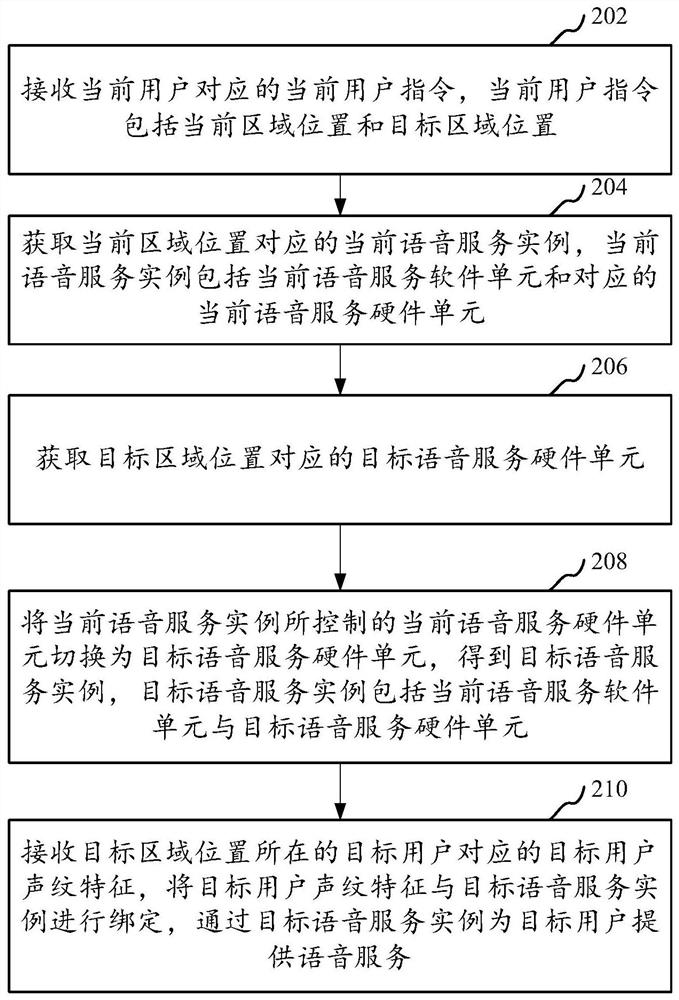
接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置;
获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元;
获取目标区域位置对应的目标语音服务硬件单元;
将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元;
接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
在其中一个实施例中,接收当前用户对应的当前用户指令之前,包括:在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元,接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
在其中一个实施例中,接收当前用户对应的当前用户指令,包括:接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在其中一个实施例中,接收当前用户对应的当前用户指令,包括:接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过所述当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在其中一个实施例中,语音数据处理方法还包括:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容,根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元,将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
在其中一个实施例中,语音数据处理方法还包括:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句,对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域,根据当前用户领域确定当前用户语句对应的目标反馈语句,通过目标语音服务硬件单元向目标用户响应目标反馈语句。
在其中一个实施例中,语音数据处理方法还包括:接收多个用户输入语句,对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征,根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例,通过用户语音服务实例对相应的用户输入语句进行响应。
一种语音数据处理装置,该装置包括:
用户指令接收模块,用于接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置;
当前语音服务实例获取模块,用于获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元;
语音服务硬件单元获取模块,用于获取目标区域位置对应的目标语音服务硬件单元;
目标语音服务实例生成模块,用于将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元;
目标语音服务实例处理模块,用于接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置;
获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元;
获取目标区域位置对应的目标语音服务硬件单元;
将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元;
接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置;
获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元;
获取目标区域位置对应的目标语音服务硬件单元;
将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元;
接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
上述语音数据处理方法、装置、计算机设备和存储介质,通过改变当前用户的当前语音服务实例所控制的当前语音服务硬件单元,重新绑定目标用户所在区域位置的目标语音服务硬件单元,且与目标用户的声纹进行绑定,使得改变后的当前语音服务实例能够单独为目标用户提供语音服务,而不受当前用户的影响。因此,通过多个语音服务实例,单独绑定区域硬件和指定用户的声纹,能够互不干扰地可以为多个用户提供语音服务。也可以通过改变当前语音服务实例所控制的区域硬件,从而切换语音服务对象,能够精准的识别出服务对象,提高语音服务对象识别准确性。
附图说明
图1为一个实施例中语音数据处理方法的应用环境图;
图2为一个实施例中语音数据处理方法的流程示意图;
图3为一个实施例中语音数据处理方法的流程示意图;
图4为一个实施例中当前用户指令接收步骤的流程示意图;
图5为一个实施例中当前用户指令接收步骤的流程示意图;
图6为一个实施例中语音数据处理方法的流程示意图;
图7为一个实施例中语音数据处理方法的流程示意图;
图8为一个实施例中语音数据处理方法的流程示意图;
图9为一个实施例中语音数据处理装置的结构框图;
图10为一个实施例中计算机设备的内部结构图。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本申请提供的语音数据处理方法,可以应用于如图1所示的应用环境中。其中,终端102通过网络与服务器104进行通信。其中,终端102可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备,服务器104可以用独立的服务器或者是多个服务器组成的服务器集群来实现。
具体地,终端102接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置,并通过网络通信将当前用户指令发送至服务器104。服务器104获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元,获取目标区域位置对应的目标语音服务硬件单元,将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元,接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
在一个实施例中,如图2所示,提供了一种语音数据处理方法,以该方法应用于图1中的终端为例进行说明,包括以下步骤:
步骤202,接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置。
其中,终端可以是当前车辆所在的车载终端,当前车辆包括前排驾驶位、前排副驾驶位以及后排左边位置、后排右边位置,当前车辆的每个区域位置都设置有相应的语音服务硬件单元,语音服务硬件单元包括区域位置的麦克风、扬声器和显示屏。
其中,这里的当前用户是当前车辆中目前正在说话的用户,当前用户可以与相应的语音服务硬件单元进行语音交互,当前用户所在的当前区域位置对应的当前语音服务硬件单元接收到当前用户指令,该当前用户指令包括当前区域位置和目标区域位置。其中,当前区域位置是指当前用户在当前车辆所处于的座位,目标区域位置是指当前车辆中指定的区域位置。
其中,当前用户与所在的当前区域位置对应的当前语音服务硬件单元能够进行语音交互,是预先将当前用户的当前用户声纹特征与当前语音服务硬件单元进行绑定,使得该当前语音服务硬件单元只能识别当前用户的语音。
步骤204,获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元。
其中,语音服务实例是由语音服务硬件单元和语音服务软件单元组成的,语音服务硬件单元是语音服务的硬件设备,而语音服务软件单元是语音服务的软件设备,语音服务软件单元用于对语音服务硬件单元采集到的音频数据进行处理,并提供语音服务的软件实体。
其中,当前车辆的每个区域位置都存在对应的语音服务实例,因此,可以根据当前区域位置获取对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元与相应的当前语音服务硬件单元。
步骤206,获取目标区域位置对应的目标语音服务硬件单元。
其中,目标区域位置是当前用户指定的区域位置,获取当前用户指定区域位置对应的目标语音服务硬件单元。
步骤208,将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元。
其中,通过切换语音服务实例服务的区域,则通过语音服务实例为新的服务区域提供语音服务。具体可以是,改变语音服务实例所控制的语音服务硬件单元,重新绑定新的服务区域的用户,为该用户提供语音服务。具体地,将当前语音服务实例所控制的当前语音服务硬件单元更改为目标语音服务硬件单元,即当前语音服务软件单元与目标语音服务硬件单元进行绑定,得到目标语音服务实例。通过目标语音服务实例为目标语音服务硬件单元所在的区域位置上的目标用户进行语音服务。其中,目标用户是目标语音服务硬件单元所在的区域位置上的用户。
步骤210,接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
其中,在得到目标语音服务实例后,需要将目标语音服务实例与目标用户进行绑定,绑定之后,目标语音服务实例就可以单独且只为目标用户进行服务。具体可以是,采集目标区域位置所在的目标用户对应的目标用户声纹特征,具体地,通过目标区域位置所在的目标语音服务硬件单元中的麦克风采集目标用户的目标用户音频信息,通过目标语音服务硬件单元关联的当前语音服务软件单元对该目标用户音频信息进行声纹识别,得到目标用户声纹特征,将该目标用户声纹特征与目标语音服务实例进行绑定,即目标语音服务实例只识别与目标用户声纹特征匹配的目标用户。最后,可以通过目标语音服务实例为目标用户提供语音服务,具体地,通过目标语音服务实例所控制的目标语音服务硬件单元采集目标用户发出的用户语句,通过目标语音服务实例所控制的当前语音软件单元对该用户语句进行语音识别,确定对应的用户反馈语句,并通过目标语音服务硬件单元响应。
上述语音数据处理方法中,通过改变当前用户的当前语音服务实例所控制的当前语音服务硬件单元,重新绑定目标用户所在区域位置的目标语音服务硬件单元,且与目标用户的声纹进行绑定,使得改变后的当前语音服务实例能够单独为目标用户提供语音服务,而不受当前用户的影响。因此,通过多个语音服务实例,单独绑定区域硬件和指定用户的声纹,能够互不干扰地可以为多个用户提供语音服务。也可以通过改变当前语音服务实例所控制的区域硬件,从而切换语音服务对象,能够精准的识别出服务对象,提高语音服务对象识别准确性。
在一个实施例中,如图3所示,接收当前用户对应的当前用户指令之前,包括:
步骤302,在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元。
步骤304,接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
其中,每辆车辆的硬件设备都包括车机,所谓车机是安装在汽车里面的车载信息娱乐产品的简称,车机在功能上能够实现人与车,车与外界(车与车)的信息通讯。首先,检测当前车辆对应的当前车机状态,在当前车机状态为启动时,说明该当前车辆的整个车机都已经启动了,此时,获取默认语音服务实例,默认语音服务实例可以提前从服务器中下载至车载终端,进而从本地获取默认语音服务实例,或者还可以是,默认语音服务实例从服务器中实时下载。其中,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元。
其中,这里的超级用户是当前车辆中具有最高权限的用户,当前车辆中具有最高权限的用户通常是主驾驶的用户,即司机为当前车辆的超级用户,接收超级用户对应的超级用户音频信息,通过默认语音服务软件单元对该超级用户音频信息进行声纹识别,得到超级用户声纹特征。将超级用户声纹特征与默认语音服务实例进行绑定,使得该默认语音服务实例单独且只为该超级用户提供语音服务。也就是说,该默认语音服务实例只认得出司机的声音。
其中,如果当前车辆具有多个用户,则确定离默认语音服务硬件单元距离最近的用户声音对应的用户为超级用户。也就是说,默认语音服务实例中的默认语音服务软件单元可以根据多个用户声音的分贝高低,来确定离默认语音服务硬件单元距离最近的用户声音。
在一个实施例中,如图4所示,接收当前用户对应的当前用户指令,包括:
步骤402,接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置。
步骤404,获取当前区域位置对应的当前语音服务硬件单元。
步骤406,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例。
其中,这里的第一超级用户指令是超级用户发出的指令,是用来绑定当前语音服务实例与当前用户之间的关系,使得当前语音服务实例只识别当前用户的语音。具体地,通过默认语音服务实例所控制的默认语音服务硬件单元采集超级用户对应的第一超级用户指令,该第一超级用户指令包括当前用户所在的当前区域位置。
进一步地,获取当前区域位置所在的当前语音服务硬件单元,也就是获取当前区域位置所在的语音服务硬件设备,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前区域位置所在的当前语音服务硬件单元进行绑定,得到当前语音服务实例。
步骤408,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务。
步骤410,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
其中,在得到当前语音服务实例,可以通过当前语音服务实例接收当前用户对应的当前用户声纹特征,具体可以是,当前语音服务实例中当前语音服务硬件单元接收当前用户对应的当前用户音频信息,通过当前语音服务软件单元对当前用户音频信息进行声纹识别,得到当前用户声纹特征。进一步地,可以将当前用户声纹特征与当前语音服务实例进行绑定,绑定之后,该当前语音服务实例只能为当前用户提供语音服务,不受其他用户的影响。因此,可以通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,如图5所示,接收当前用户对应的当前用户指令,包括:
步骤502,接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置。
步骤504,获取当前区域位置对应的当前语音服务硬件单元。
步骤506,根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例。
其中,这里的第二超级用户指令是超级用户发出的指令,是用来绑定当前语音服务实例与当前用户之间的关系,使得当前语音服务实例只识别当前用户的语音。具体地,通过默认语音服务实例所控制的默认语音服务硬件单元采集超级用户对应的第二超级用户指令,该第二超级用户指令包括当前用户所在的当前区域位置。
进一步地,获取当前区域位置所在的当前语音服务硬件单元,也就是获取当前区域位置所在的语音服务硬件设备,根据第二超级用户指令新增一个新的语音服务软件单元,将这个新的语音服务软件单元与当前语音服务硬件单元进行绑定,得到当前语音服务实例。
步骤508,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务。
步骤510,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
其中,在得到当前语音服务实例,可以通过当前语音服务实例接收当前用户对应的当前用户声纹特征,具体可以是,当前语音服务实例中当前语音服务硬件单元接收当前用户对应的当前用户音频信息,通过当前语音服务软件单元对当前用户音频信息进行声纹识别,得到当前用户声纹特征。进一步地,可以将当前用户声纹特征与当前语音服务实例进行绑定,绑定之后,该当前语音服务实例只能为当前用户提供语音服务,不受其他用户的影响。因此,可以通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,如图6所示,语音数据处理方法还包括:
步骤602,通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容。
步骤604,根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元。
步骤606,将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
其中,在将目标用户的目标用户声纹特征与目标语音服务实例进行绑定后,目标语音服务实例只为目标用户提供语音服务。具体地,可以通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容。也就是,目标用户可以分享内容给其他用户,当前用户分享内容是指目标用户需要分享的内容。
进一步地,获取被分享用户区域位置所在的第一语音服务实例,此时第一语音服务实例包括第一语音服务软件单元和关联的第一语音服务硬件单元。通过目标用户的语音请求,目标语音服务实例与第一语音服务实例进行交互,具体可以是将当前用户分享内容直接复制到第一语音服务实例中,因此,第一语音服务实例所控制的第一语音服务硬件单元会展示当前用户分享内容。实现不同区域位置的语音服务实例的分享。例如,后排左侧普通用户B正在浏览一件商品,想分享给后排右侧普通用户C,通过语音发起请求说分享给右后侧,然后商品出现在后排右侧普通用户B的显示器上。
在一个实施例中,如图7所示,语音数据处理方法还包括:
步骤702,通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句。
步骤704,对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域。
步骤706,根据当前用户领域确定当前用户语句对应的目标反馈语句。
步骤708,通过目标语音服务硬件单元向目标用户响应目标反馈语句。
其中,当前语句是目标用户发出的,目标语音服务实例只为目标用户提供语音服务,通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句。其中,可以通过目标语音服务硬件单元中的麦克风采集得到目标用户发出的当前用户语句,或者还可以是通过目标语音服务硬件单元中的屏幕采集得到目标用户输入的当前用户语句。
进一步地,对当前用户语句进行语音识别,得到当前用户领域。其中,这里的当前用户领域是指当前用户语句所在的知识领域。例如,当前用户语句为:“北京二环的路况如何”,对其进行语音识别,得到对应的当前用户领域为:导航。
其次,在得到当前用户语句对应的当前用户领域后,可以根据当前用户领域确定当前用户语句对应的目标反馈语句,可以预先建立各个用户领域对应的反馈语句之间的关系,根据该关系可以确定当前用户语句对应的目标反馈语句。例如,当前用户领域为:导航,目标反馈语句为:“是否需要为您提供最佳路线导航。”最后,可以通过目标语音服务硬件单元向目标用户响应目标反馈语句。
在一个实施例中,如图8所示,语音数据处理方法还包括:
步骤802,接收多个用户输入语句。
步骤804,对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征。
步骤806,根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例。
步骤808,通过用户语音服务实例对相应的用户输入语句进行响应。
其中,若当前车辆多个用户同时发出语音,即接收到多个用户输入语句。需要对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征。由于每个语音服务实例都与相应的用户声纹特征进行了绑定,因此,可以根据各个用户输入语句对应的用户声纹特征确定匹配的用户语音服务实例,最后通过用户语音服务实例对相应的用户输入语句进行响应。
在一个具体的应用场景中,当前车辆的车机启动后,车机处于初始状态,车机内运行了单一语音服务实例,代号super,全车处于单一语音服务单元状态,车机内运行唯一语音服务进程,该语音服务实例权限为超级服务员,控制语音服务硬件单元组(此时包含全车各个区域的最小语音服务硬件单元,包括前排,后排左,后排右所有区域的最小语音服务硬件单元。)为对全车进行收声,同时对所有用户,进行统一语音服务,同时只可以服务单个用户,(其中,区域位置前排,后排左,后排右多套麦克风mic,扬声器speaker,屏幕screen,当用户发起语音请求时,系统会判断用户方位,并调用最近的最小语音服务硬件单元与用户进行交互,并展开服务)。
进一步地,在单语音服务实例状态下,主驾驶用户A语音要求开启分身模式:语音唤醒,客户要求语音服务实例super,进行分身服务,语音服务实例要求用户A进行声纹绑定,用户A将成为超级用户A,并对车机语音服务实例super具有支配权限,声纹绑定完成后,即语音服务实例super绑定用户A的声音,只识别A的声音,不在被其他人唤醒并提供服务。此时,超级用户A被语音服务实例super询问,请为即将生成的新的语音服务实例-语音服务实例normal-1分身指定工作区域位置(例如:前排,后排左,后排右)。
假设超级用户A指派区域为后排左,车机系统会增加运行一个新的语音服务实例-语音服务实例normal-1,该语音服务实例normal-1将控制指定区域(后排左)的最小语音服务硬件单元,主要对该区域(后排左)的普通用户B提供语音服务。该区域的普通用户B,被语音服务实例normal-1要求进行声纹绑定,并只为普通用户B进行语音服务。这个过程完成后,语音服务实例super将控制前排和后排右共两个最小语音服务硬件单元所构成的最小语音服务硬件单元组,与超级用户A进行语音交互,并提供服务,而语音服务实例normal-1将控制指定区域(后排左)的最小语音服务硬件单元,与普通用户B进行语音交互,并提供服务。因为存在多个语音实例,并单独绑定区域硬件,和指定用户声纹,所以可以互不干扰地将独立同时为两个和用户服务。
例如:语音服务实例normal-1原本正在为后排左侧的普通用户B进行语音服务,这时后排左侧普通用户B语音提要求让语音服务实例normal-1去为后排右的普通用户C去提供服务,这时语音服务实例normal-1,开始切换所控制的语音服务硬件单元,将原本(后排左)的最小语音服务硬件单元的控制权还给语音服务实例super,转而开始控制(后排左)的最小语音服务硬件单元,并开始为后排右的普通用户C发起用户声纹绑定请求,并开始提供服务。
场景可以是:后排左侧用户妈妈的需求,想给位于后排右侧的儿子挑选一个动画片看,操作:后排左侧普通用户B妈妈和该位置的语音服务实例normal-1服务员发起语音查找动画片,动画片挑选好后,然后语音让语音服务实例normal-1服务员去为区域为后排右的孩子普通用户C播放,左侧孩子普通用户C被询问是否开始播放,用户回答确认,此时语音服务实例normal-1对普通用户C进行声纹绑定,并开始为其服务。
其中语音服务实例间可以进行分享,具体是,位于不同区域位置的语音服务实例进行分享当前正在进行的语音服务内容,例如,语音服务实例normal-1正在为后排左的普通用户B进行服务,此时语音服务内容为任务1,同时语音服务实例normal-2正在为后排右侧普通用户C进行语音服务,这时候普通用户B想将此进行的任务1分享同步给普通用户C,普通用户B通过语音提出请求后语音服务实例normal-1与语音服务实例normal-2进行交互,任务1被复制到语音服务实例normal-2,语音服务实例normal-2中有了与任务1一样的任务1副本,这时普通用户C就可以开始对语音服务内容为任务1副本进行操作。
场景可以是,后排左侧普通用户B正在浏览一件商品,想分享给后排右侧普通用户C,通过语音发起请求说分享给右后侧,然后商品出现在后排右侧普通用户B的显示器上。
在一个具体的实施例中,提供了一种语音数据处理方法,具体包括以下步骤:
1、在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元。
2、接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
3、接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置。
3-1-1、接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置。
3-1-2、获取当前区域位置对应的当前语音服务硬件单元。
3-1-3、根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例。
3-1-4、接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务。
3-1-5、通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
3-2-1、接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置。
3-2-2、获取当前区域位置对应的当前语音服务硬件单元。
3-2-3、根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例。
3-2-4、接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务。
3-2-5、通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
4、获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元。
5、获取目标区域位置对应的目标语音服务硬件单元。
6、将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元。
7、接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
8、通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容。
9、根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元。
10、将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
11、通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句。
12、对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域。
13、根据当前用户领域确定当前用户语句对应的目标反馈语句。
14、通过目标语音服务硬件单元向目标用户响应目标反馈语句。
15、接收多个用户输入语句。
16、对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征。
17、根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例。
18、通过用户语音服务实例对相应的用户输入语句进行响应。
应该理解的是,虽然上述流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,上述流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
在一个实施例中,如图9所示,提供了一种语音数据处理装置900,包括:用户指令接收模块902、当前语音服务实例获取模块904、语音服务硬件单元获取模块906、目标语音服务实例生成模块908和目标语音服务实例处理模块910,其中:
用户指令接收模块902,用于接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置。
当前语音服务实例获取模块904,用于获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元。
语音服务硬件单元获取模块906,用于获取目标区域位置对应的目标语音服务硬件单元。
目标语音服务实例生成模块908,用于将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元。
目标语音服务实例处理模块910,用于接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
在一个实施例中,语音数据处理装置900在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元,接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
在一个实施例中,语音数据处理装置900接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,用户指令接收模块902接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,语音数据处理装置900通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容,根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元,将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
在一个实施例中,语音数据处理装置900通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句,对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域,根据当前用户领域确定当前用户语句对应的目标反馈语句,通过目标语音服务硬件单元向目标用户响应目标反馈语句。
在一个实施例中,语音数据处理装置900接收多个用户输入语句,对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征,根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例,通过用户语音服务实例对相应的用户输入语句进行响应。关于语音数据处理装置的具体限定可以参见上文中对于语音数据处理方法的限定,在此不再赘述。上述语音数据处理装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
在一个实施例中,提供了一种计算机设备,该计算机设备可以是终端,其内部结构图可以如图10所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口、显示屏和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种语音数据处理方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
本领域技术人员可以理解,图10中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
在一个实施例中,提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现以下步骤:接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置,获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元,获取目标区域位置对应的目标语音服务硬件单元,将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元,接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
在一个实施例中,接收当前用户对应的当前用户指令之前,包括:在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元,接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容,根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元,将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句,对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域,根据当前用户领域确定当前用户语句对应的目标反馈语句,通过目标语音服务硬件单元向目标用户响应目标反馈语句。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收多个用户输入语句,对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征,根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例,通过用户语音服务实例对相应的用户输入语句进行响应。
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:接收当前用户对应的当前用户指令,当前用户指令包括当前区域位置和目标区域位置,获取当前区域位置对应的当前语音服务实例,当前语音服务实例包括当前语音服务软件单元和对应的当前语音服务硬件单元,获取目标区域位置对应的目标语音服务硬件单元,将当前语音服务实例所控制的当前语音服务硬件单元切换为目标语音服务硬件单元,得到目标语音服务实例,目标语音服务实例包括当前语音服务软件单元与目标语音服务硬件单元,接收目标区域位置所在的目标用户对应的目标用户声纹特征,将目标用户声纹特征与目标语音服务实例进行绑定,通过目标语音服务实例为目标用户提供语音服务。
在一个实施例中,接收当前用户对应的当前用户指令之前,包括:在检测到当前车辆对应的当前车机启动时,获取默认语音服务实例,默认语音服务实例包括默认语音服务软件单元和对应的默认语音服务硬件单元,接收超级用户对应的超级用户声纹特征,将超级用户声纹特征与默认语音服务实例进行绑定,通过默认语音服务实例为超级用户进行语音服务,超级用户为当前车辆中具有最高权限的用户。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收超级用户对应的第一超级用户指令,第一超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第一超级用户指令将默认语音服务实例所控制的默认语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收超级用户对应的第二超级用户指令,第二超级用户指令包括当前用户所在的当前区域位置,获取当前区域位置对应的当前语音服务硬件单元,根据第二超级用户指令增加新的语音服务软件单元,将新的语音服务软件单元与当前语音服务硬件单元建立关联关系,得到当前语音服务实例,接收当前用户对应的当前用户声纹特征,将当前用户声纹特征与当前语音服务实例进行绑定,通过当前语音服务实例为当前用户提供语音服务,通过当前语音服务实例所控制的当前语音服务硬件单元采集当前用户对应的当前用户指令。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户分享指令,当前用户分享指令包括被分享用户所在的被分享用户区域位置和当前用户分享内容,根据被分享用户区域位置获取对应的第一语音服务实例,第一语音服务实例包括第一语音服务软件单元和对应的第一语音服务硬件单元,将当前用户分享内容复制到第一语音服务实例,通过第一语音服务实例所控制的第一语音服务硬件单元为被分享用户展示当前用户分享内容。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:通过目标语音服务实例所控制的目标语音服务硬件单元接收目标用户对应的当前用户语句,对当前用户语句进行语音识别,得到与当前用户语句对应的当前用户领域,根据当前用户领域确定当前用户语句对应的目标反馈语句,通过目标语音服务硬件单元向目标用户响应目标反馈语句。
在一个实施例中,处理器执行计算机程序时还实现以下步骤:接收多个用户输入语句,对各个用户输入语句进行声纹识别,得到各个用户输入语句对应的用户声纹特征,根据各个用户声纹特征确定与各个用户输入语句对应的用户语音服务实例,通过用户语音服务实例对相应的用户输入语句进行响应。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双数据率SDRAM(DDRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 语音数据处理方法、装置、计算机设备和存储介质
- 语音数据处理方法、装置、计算机设备及存储介质