一种基于聚类的多模态大脑网络特征选择方法
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及医学信息处理技术领域,尤其涉及一种基于聚类的多模态大脑网络特征选择方法。
背景技术
大脑调节着体内生理活动的正常进行,是人体中结构最为复杂的器官之一;脑内神经元相互交错缠绕,形成高度复杂的神经系统,处理着各种问题。对于不同问题,大脑通过神经元将信息传递到不同脑区进行处理,脑区之间也存在信息交互,并对应不同的功能特异性。在现实中,对大脑疾病的诊断还是依靠医生的固有经验和主观判断,这种方式大大的降低了疾病诊断效率。引入机器学习和模式识别技术,能充分利用大脑数据与数据之间的内在信息,加强对大脑疾病致病因子的理解,辅助医生进行诊断,极大的提高诊断效率和分类准确率。因此,应用机器学习和模式识别在大脑网络领域的研究是一件十分有意义的事情。许多研究人员利用神经影像技术结合机器学习,应用于医学分类领域,辅助开展临床诊断治疗,取得了显著的成果;
研究人员在探索大脑连接模式时常常使用神经影像技术,利用非侵入性方法,通过不同的视角来分析大脑功能和结构特征。功能磁共振成像fMRI(functional MagneticResonance Imaging,fMRI)被广泛使用,通过测量不同脑区中血氧水平依赖(Blood,oxygen-level dependent,BOLD)计算时间序列相关性来度量脑区之间的连接强弱;最近,扩散峰度成像(Diffusion Kurtos Imaging,DKI)已被临床实践证实可以更加灵敏的反应微观组织结构,其基于非高斯水分子扩散模型,可以提供关于微观组织尤其是大脑白质的重要内在结构信息,峰度参数也可以用于提高对大脑疾病评估的敏感性和特异性;
随着技术的发展,在日常诊断中我们能够获取到大量结构类型各异的医学影像数据,帮助我们从不同视角观测同一被试,加强对疾病致病因子的理解。传统的大脑网络特征选择方法,仅从单种医学影像数据出发,从单个视角观测被试,进而特征选择,忽略了不同模态数据之间的信息互补,这势必会引起获取到的特征不充分,影响最终的分类结果。通过多模态数据观测被试,可以更加全面的理解疾病的致病因子,寻找被试脑部疾病特征,所以将多种模态大脑网络特征进行融合之后再分类成为了一种研究趋势。
聚类分析是一种定量方法,可以将相似特征聚集为一类,达到同时最小化社团内距离,而最大化社团间距离,有效的筛选出差异显著的特征。
发明内容
本发明的目的是为了解决传统大脑网络特征选择方法存在的不足之处,提供一种基于聚类的多模态大脑网络特征选择方法,采用以下技术方案:
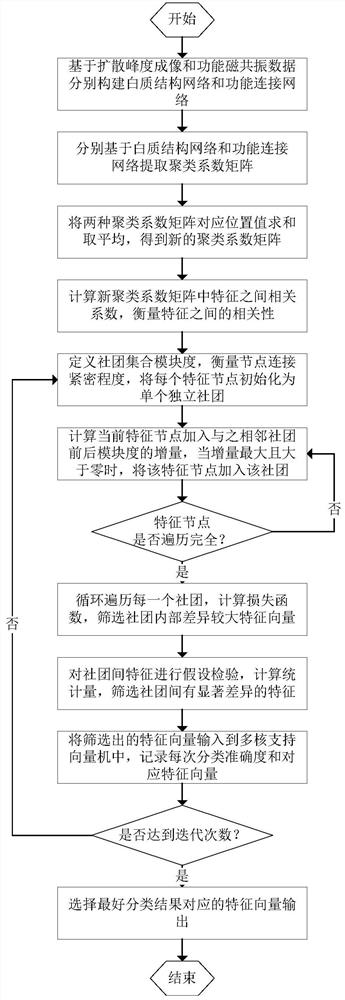
一种基于聚类的多模态大脑网络特征选择方法,其步骤包括:
步骤1:获取样本人群大脑的磁共振图像,磁共振图像包括磁共振扩散峰度成像(Diffusion Kurtos Imaging,DKI)和静息态功能磁共振成像(functional MagneticResonance Imaging,fMRI);基于磁共振扩散峰度成像和静息态功能磁共振成像构建白质结构网络和功能连接网络;
步骤2:基于白质结构网络和功能连接网络提取聚类系数矩阵;
步骤3:将两种聚类系数矩阵对应位置值求和取平均,得到新的聚类系数矩阵;
步骤4:计算新的聚类系数矩阵中特征之间的相关系数,得到相关系数矩阵;
步骤5:根据相关系数矩阵对特征进行聚类,得到若干社团;具体步骤为:
步骤5.1:定义社团集合模块度,将每个特征节点初始化为单个独立团体;
步骤5.2:分别计算当前特征节点加入与之相邻社团前后模块度的增量,当增量最大且大于零时,将当前特征节点加入当前社团;
步骤5.3:判断社团内特征节点是否遍历完全,若否,则返回步骤5.2,若是,则执行步骤6;步骤6:在社团内进行特征选择:循环遍历每一个社团,计算损失函数,筛选社团内部差异大的特征向量;
步骤7:在社团间进行特征选择,选择差异大的特征向量;
步骤8:得到用于分类的特征向量。
进一步的,所述步骤1具体为:
步骤1.1:基于磁共振扩散峰度成像构建白质结构网络:采用标准大脑分区模板,将大脑的磁共振扩散峰度成像划分为若干个脑区,利用概率性纤维追踪方法重构白质纤维束,使用纤维连接数目作为连接边加权,进而构建白质结构网络;
步骤1.2:基于静息态功能磁共振成像构建功能连接网络:使用标准大脑分区模板,将大脑的静息态功能磁共振成像划分为若干个脑区,计算得到每个脑区的静息态功能磁共振成像时间序列;以每个脑区为节点,进而计算节点之间的相关系数矩阵得到功能连接网络。
进一步的,所述步骤1中,将大脑的磁共振扩散峰度成像划分为若干个脑区的步骤前还包括对磁共振扩散峰度成像进行预处理的步骤,对磁共振扩散峰度成像进行预处理的步骤具体为:对原始的磁共振扩散峰度成像数据转换后进行剥脑处理、头动校正及涡流校正、去除头动参数、时间校正和平滑滤波操作;去除头动参数为去除由头动造成偏差较大的数据,时间校正为校正由头动造成的时间点不齐的问题,保证数据间的一致性,平滑滤波操作用于消除不相干噪声;
所述步骤1中,将大脑的静息态功能磁共振成像划分为若干个脑区的步骤前还包括对静息态功能磁共振成像进行预处理的步骤,对静息态功能磁共振成像进行预处理的步骤具体为:对原始的静息态功能磁共振成像进行时间层校准、去除头动参数、空间标准化和滤波操作;去除静息态功能磁共振成像头部数据带来的不稳定影响。
进一步的,所述步骤2具体为:提取白质结构网络和功能连接网络所有被试脑区的聚类系数,定义矩阵
式中,
进一步的,所述步骤3具体为:将两种网络对应的聚类系数矩阵F
其中,
进一步的,所述步骤4具体为:计算V中任意两个特征向量之间的皮尔逊相关系数,得到特征之间的相似性矩阵即相关系数矩阵
进一步的,所述步骤5具体为:
步骤5.1:定义社团集合模块度,将每个特征节点初始化为单个独立团体,具体为:
定义社团集合模块度,用模块度来描述社团内部节点之间连接的紧密程度,目标是使整个集合的模块度最大化,其中模块度M表示为:
式中,
初始化所有特征为单个独立社团对计算得到的特征之间的相关系数矩阵,每列特征向量作为一个特征节点,依次将记录所有特征节点所属社团编号的列向量
步骤5.2:分别计算当前特征节点加入与之相邻社团前后模块度的增量,当增量最大且大于零时,将当前特征节点加入当前社团,具体为:
分别计算特征节点A
式中,a
定义数组Q=[ΔM
步骤5.3:判断社团内特征节点是否遍历完全,若否,则返回步骤5.2,若是,则执行步骤6;具体为:定义n维列向量
进一步的,所述步骤6具体为:遍历向量I,选择属于同一社团的特征向量,在社团内部,使用Lasso方法,计算损失函数,筛选社团内差异大的特征向量,所述损失函数表示为:
式中,Y={y
进一步的,所述步骤7具体为:定义矩阵Z,遍历社团间特征,利用单样本T检验评估特征是否在统计学上彼此不同,两两特征向量计算检验统计量的观测值p,确定显著性水平α,若计算出两特征向量p值小于显著性水平α,则判定两个特征具有显著差异,将特征向量加入矩阵Z。
进一步的,所述步骤8具体为:将筛选出的特征向量输入到多核支持向量机中,记录每次分类准确度和对应的特征向量;判断是否达到预设的最大迭代次数τ,若没有达到,则返回步骤5;否则结束迭代,输出最好分类结果所对应的特征向量。
本发明具有如下有益效果:本发明提供了一种基于聚类的多模态大脑网络特征选择方法,克服以往单模态下忽略特征相似性的做法,从不同模态数据提取所有被试的大脑网络特征,并且基于聚类方法,从局部到整体,分层计算网络特征之间的相似性,筛选出差异显著的特征用于大脑网络特征分类,弥补了传统单模态特征选择只从单个视角对整体特征进行选择的缺陷,提高大脑网络特征分类的准确率。
附图说明
图1为本发明实施例整体流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明作进一步详细说明。
请参考图1,本发明为一种基于聚类的多模态大脑网络特征选择方法,其步骤包括:步骤1:获取样本人群大脑的磁共振图像,磁共振图像包括磁共振扩散峰度成像和静息态功能磁共振成像;基于磁共振扩散峰度成像和静息态功能磁共振成像构建白质结构网络和功能连接网络;本实施例中,被试的样本人群为28例,男性女性各14人;
步骤1.1:基于磁共振扩散峰度成像构建白质结构网络:
步骤1.1a:对获取的原始磁共振扩散峰度成像进行数据转换,剥脑处理、头动校正、涡流校正,去除由头动造成偏差较大的数据,校正由头动造成的时间点不齐,保证数据间的一致性;之后进行平滑滤波操作,消除不相干噪声;
步骤1.1b:采用AAL(Anatomical Automatic Labeling)标准大脑分区模板,将大脑的磁共振扩散峰度成像划分为90个脑区(左右半脑各45个脑区),利用概率性纤维追踪方法重构白质纤维束,使用纤维连接数目作为连接边加权,进而构建白质结构网络;
步骤1.2:基于静息态功能磁共振成像构建功能连接网络:
步骤1.2a:去除静息态功能磁共振成像(functional Magnetic ResonanceImaging,fMRI)头部数据带来的不稳定影响,进行时间层校准和去头动,将静息态功能磁共振成像配准到MNI(Montreal Neurological Institute)标准空间后滤波,信号低频滤波范围取0.01Hz~0.08Hz;
步骤1.2b:使用AAL标准大脑分区模板,将大脑划分为90个脑区(左右半脑各45个脑区),计算得到每个脑区的fMRI时间序列;以每个脑区为节点,进而计算节点之间的皮尔逊相关系数矩阵得到功能连接网络;
步骤2:基于白质结构网络和功能连接网络提取聚类系数矩阵,具体为:
提取白质结构网络和功能连接网络所有被试脑区的聚类系数,定义矩阵
式中,
步骤3:将两种聚类系数矩阵对应位置值求和取平均,得到新的聚类系数矩阵,具体为:
将两种网络对应的聚类系数矩阵F
步骤4:计算新的聚类系数矩阵中特征之间的相关系数,得到相关系数矩阵;具体为:
计算V中任意两个特征向量之间的皮尔逊相关系数,得到特征之间的相似性矩阵即相关系数矩阵
步骤5:根据相关系数矩阵对特征进行聚类,把相似特征聚为一类,得到若干社团;具体步骤为:
步骤5.1:定义社团集合模块度,将每个特征节点初始化为单个独立团体,具体为:
定义社团集合模块度,用模块度来描述社团内部节点之间连接的紧密程度,目标是使整个集合的模块度最大化,其中模块度M可表示为:
式中,
初始化所有得到的90个特征为单个独立社团为单个独立社团对计算得到的特征之间的相关系数矩阵,每列特征向量作为一个特征节点,依次记录所有特征节点所属社团编号的列向量
步骤5.2:分别计算当前特征节点加入与之相邻社团前后模块度的增量,当增量最大且大于零时,将该特征节点加入该社团,具体为:
分别计算特征节点A
式中,a
定义数组Q=[ΔM
步骤5.3:判断社团内特征节点是否遍历完全,若否,则返回步骤5.2,若是,则执行步骤6;具体为:定义n维列向量
步骤6:在社团内进行特征选择迭代,循环遍历每一个社团,计算损失函数,筛选社团内部差异较大的特征向量,具体为:
遍历向量I,选择属于同一社团的特征向量,在社团内部,使用Lasso(Leastabsolute shrinkage and selection operator)方法,计算损失函数,筛选社团内差异大的特征向量,所述损失函数表示为:
式中,Y={y
步骤7:在社团间进行特征选择,选择差异大的特征,具体为:
定义矩阵Z,遍历社团间特征,利用单样本T检验(One sample T-test)评估特征是否在统计学上彼此不同,两两特征向量计算检验统计量的观测值p,确定显著性水平α(α取0.05),若计算出两特征向量p值小于显著性水平α,则判定两个特征具有显著差异,将特征向量加入矩阵Z;
步骤8:将筛选出的特征向量,分为训练集、测试集和验证集,输入到多核支持向量机中,记录每次分类准确度和对应的特征向量;判断是否达到人为预设的最大迭代次数τ=50,若没有达到,则返回执行步骤5;否则结束迭代,输出最好分类结果所对应的特征向量。
本发明未涉及部分均与现有技术相同或采用现有技术加以实现。
以上内容是结合具体的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 一种基于聚类的多模态大脑网络特征选择方法
- 一种基于多任务学习的多模态脑网络特征融合方法