医疗数据近似查询方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于数据库查询技术领域,具体涉及一种基于GPT-3模型的医疗数据近似查询方法。
背景技术
近似查询处理是数据库中的一个关键问题,近似查询处理是指在可接受的查询误差下,为快速响应用户查询的加速查询效率的优化技术,和传统数据库查询相比,近似查询可以在少量牺牲查询精度的情况下,极大的提升数据库查询速度,通常应用在数据量较大的商业数据库中,主要针对包含“count,sum, avg”等聚合操作的查询语句。
在近似查询领域,现有技术关注于改进数据库中的查询优化器,以确保针对近似查询语句能够编译出执行效率更高的执行计划,从而加速整个数据查询的过程。然而,在实现本发明过程中,发明人发现现有技术中至少存在如下问题:
1.查询效率仍然难以做到毫秒级。虽然现有近似查询技术可以通过采样等方法缩小需要查询的数据范围,但在数据量较大的情况下,这个过程仍然极其耗时。其次,现有技术关注于改进数据库内部的查询优化器来加速查询,但仍然需要在数据库中执行标准查询语句,这无法避免数据扫描和传输等耗时操作;
2.无法回答自然语言形式的近似查询。通常数据库提供商需要用户有一定的SQL编写能力,甚至有些用户及时掌握了简单SQL的编写,仍然会因为编写的SQL不够标准而导致执行速度过慢。这导致数据库提供商对用户的专业知识要求过高。
发明内容
本发明旨在至少在一定程度上解决上述技术问题。为此,本发明目的在于提供一种医疗数据近似查询方法。
本发明所采用的技术方案为:
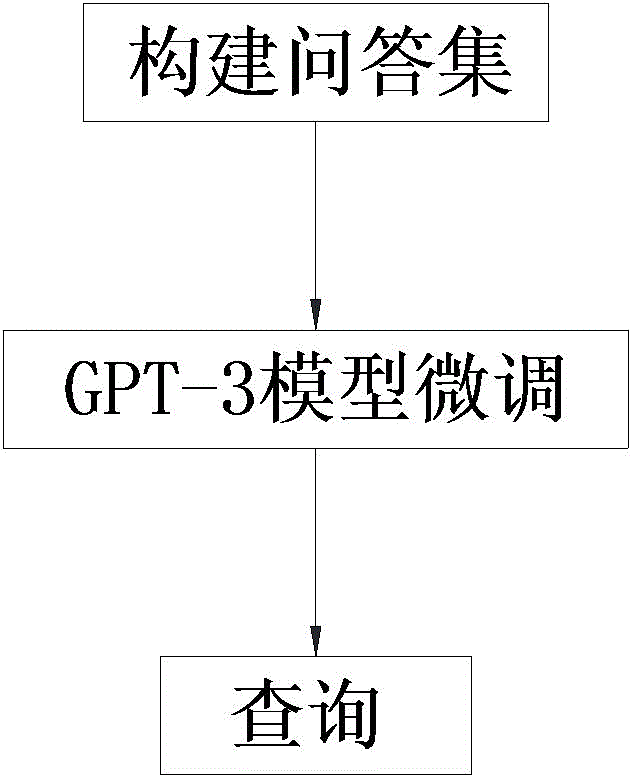
医疗数据近似查询方法,包括以下步骤:
S1、将近似查询记录通过Transformer模型转化为自然语言形式的表示,对自然语言形式的近似查询记录中的查询问题运用同义词替换的方式进行数据增强;对自然语言形式的近似查询记录中的查询结果进行自然语言形式的丰富化;将经过数据增强后的查询问题及对应的查询结果组合为多条问答对,以多条问答对组成问答集;
S2、将问答集处理为包括提示和结论的数据格式,使用处理后的问答集调用GPT-3模型的fine-tuning API对GPT-3模型进行微调;
S3、将自然语言查询输入到微调后的GPT-3模型,输出GPT-3模型的回答结果。
优选地,步骤S1中的近似查询记录包括历史近似查询记录和随机生成近似查询记录,随机生成近似查询记录通过固定查询模版的方式随机生成。
优选地,步骤S1中Transformer模型将查询语言表示为二维矩阵X
;
其中,MatMul表示线性矩阵相乘,
优选地,GPT-3模型微调过程的目标函数通过极大似然函数来构建:
;
其中,
优选地,步骤S3中GPT-3模型接受表示自然语言查询的矩阵
本发明的有益效果为:
本发明所提供的医疗数据近似查询方法,使用GPT-3模型实现超低访问延迟的医疗数据查询,通过对查询问题进行数据增强,对查询结果进行自然语言形式的丰富化;使得GPT-3模型更好地适用于数据库的近似访问,提升近似访问的准确度。
该医疗数据近似查询方法还通过固定查询模版的方式随机生成的随机生成近似查询记录解决了历史近似查询记录不足的问题。
附图说明
图1是本发明医疗数据近似查询方法的流程图。
具体实施方式
下面将结合本发明中的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应当理解,还应当注意到实施例中,所出现的功能/动作可能与附图出现的顺序不同。例如,取决于所涉及的功能/动作,实际上可以实质上并发地执行,或者有时可以以相反的顺序来执行连续示出的两个图。
如图1所示,本实施例的医疗数据近似查询方法,包括以下步骤:
S1、将近似查询记录通过Transformer模型转化为自然语言形式的表示,Transformer模型相比序列模型的优势在于它可以将输入表示为矩阵进行并行计算,从而提升训练和推理效率。Transformer模型将输入表示为二维矩阵X
;
其中,MatMul表示线性矩阵相乘,
近似查询记录包括历史近似查询记录和随机生成近似查询记录,目标医疗数据库中没有足够的历史近似查询记录,即历史近似查询记录不足以覆盖各种数据范围(属性以及属性值)以及查询类型(“count,sum,avg”),则需要通过固定查询模版的方式随机生成的随机生成近似查询记录来补充。比如已经有大量历史近似查询记录的数据范围是“病人的数量”,那么需要随机生成数据范围是“病人住院天数”或其它数据范围的随机生成近似查询记录,通过结合随机生成近似查询记录以及历史近似查询记录,可以组成充足的微调数据,用于后续步骤使用。
对自然语言形式的近似查询记录中的查询问题运用同义词替换的方式进行数据增强,以加强GPT-3模型微调后的泛化能力。该过程根据开源的同义词表(比如哈工大同义词表)对查询问题中的字或词进行检索并替换,从而存储为一条新的查询。比如针对查询问题“大于50岁的病人的数量有多少”,使用“数量”在同义词表中查询到同义词“总量”,则替换后的新的查询为“大于50岁的病人的总量有多少”。
对自然语言形式的近似查询记录中的查询结果进行自然语言形式的丰富化,以配合自然语言形式的查询问题一起微调GPT-3模型。比如查询问题为“大于50岁的病人的数量有多少”,查询结果为“2003”,那么将查询结果丰富为“数量为2003”。该过程根据查询的聚合操作的类型(SUM、COUNT...),以及被查询的属性名称(比如“病人”)自动将查询结果转化为自然语言。具体的,首先需要用正则表达式捕捉到查询中的“SUM(病人)”,接着将“SUM”翻译为“总数”,并抽取出“病人”这一属性名称。最后与查询结果“2003”按照“属性(病人)”+“的”+“聚合操作(总数)”+“是”+“查询结果(2003)”+“。”的顺序组合为自然语言“病人的总数是2003。”即可。
将经过数据增强后的每条查询问题及对应的查询结果组合为多条问答对,以多条问答对组成问答集。
S2、将问答集处理为包括提示和结论的数据格式,数据格式具体为{"prompt":"
GPT-3模型的公式为:
;
;
其中,Q代表输入信息,为输入文本存在的信息。K代表内容信息,为语义信息,则Attention(Q,K)表示Query和Key的匹配程度,而V代表信息本身,主要作用是对匹配程度进行加权;
;
其中,
S3、将用户的自然语言查询输入到微调后的GPT-3模型,将GPT-3模型的回答结果返回给用户。具体的,GPT-3模型接受自然语言查询
该医疗数据近似查询方法可以不需要用户掌握高效的SQL的编写技术,只需用自然语言描述一条近似查询就可以得到对应的回答,减少了医疗数据库提供商对于用户的专业知识要求;同时可以实现超低访问延迟的医疗数据查询。当用户输入自然语言查询时,不实际在数据库中执行标准的SQL查询,而是将自然语言查询和历史记录做匹配,并快速返回相似自然语言查询的查询结果。这极大提升了查询的回复效率(提升至毫秒ms级别)。
本发明不局限于上述可选实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是落入本发明权利要求界定范围内的技术方案,均落在本发明的保护范围之内。
- 一种WMSN区块链的多媒体混合数据近似近邻二元查询方法
- 医疗数据查询方法、医疗数据平台及相关装置
- 医疗系统数据查询方法和医疗系统数据查询系统