通过实时代理评估反馈增强的深度神经网络模型设计
文献发布时间:2023-06-19 19:28:50
技术领域
本文描述的实施例概括而言涉及人工智能(artificial intelligence,AI)、机器学习(machine learning,ML)和神经体系结构搜索(Neural Architecture Search,NAS)技术,具体而言涉及用于深度神经网络(Deep Neural Network,DNN)模型工程的技术。
背景技术
机器学习(ML)是对计算机算法的研究,这些算法通过经验和并且通过使用数据而自动改进。执行机器学习涉及创建统计模型(或者简称为“模型”),它被配置为处理数据以进行预测和/或推理。ML算法使用样本数据(称为“训练数据”)和/或基于过去的经验来构建模型,从而在没有被明确编程的情况下做出预测或决策。
ML模型设计是一个漫长的过程,它涉及到高度迭代的训练和验证循环,以调整给定模型的结构、参数和/或超参数。对于诸如深度神经网络(DNN)之类的较大ML体系结构,训练和验证可能是尤其耗费时间并且资源密集的。传统的ML设计技术也可能要求相对大量的计算资源,超出许多用户的能力范围。
代理任务可用于ML模型设计,以便减少时间长度和资源消耗。代理任务可包括例如在比完整训练会话更少的历时(epoch)中进行训练,用更少的块学习,或者用完整训练数据集的子集(即,“训练子集”)进行训练。使用代理任务,可以减少训练/验证迭代的数目,这应当减少用于训练的时间和资源消耗。然而,使用代理任务训练ML模型可得到准确度较低的模型。此外,对于较大的最先进的DNN模型而言,使用代理任务仍然可能是非常漫长和资源密集的。事实上,对于非常大的模型而言,使用数据子集进行训练,对于无法获得大型计算资源的用户而言仍然是令人望而却步的,而且会以预测的准确度为代价。
取代手动设计ML模型,神经体系结构搜索(NAS)算法可以用于为特定的任务自动发现理想的ML模型(参见例如Abdelfattah等人,“Zero-Cost Proxies for LightweightNAS(用于轻量型NAS的零成本代理)”,ArXiv abs/2101.08134(2021年1月20日)(“[Abdelfattah]”),特此通过引用将该文献整体并入在此)。NAS是自动化体系结构工程的过程。然而,NAS也可能是耗时和计算密集的;通常使用NAS可能需要许多小时或许多天来完整训练单一神经网络(参见[Abdelfattah])。
在传统的基于样本的NAS中,可以使用代理训练制度来预测模型的准确度,而不是全面训练(参见[Abdelfattah])。这涉及到使用代理函数来产生代理得分,该代理得分对模型的性能给出粗略的估计。然而,代理函数并不总是与它们所近似的度量有很好的相关性(参见例如Mellor等人,“Neural Architecture Search without Training(在无训练的情况下进行神经体系结构搜索)”,国际机器学习会议,PMLR,第7588-7598页(2021年7月1日)(“[Mellor]”),特此通过引用将该文献整体并入在此),这就是为什么代理函数仍然是一个活跃的研究领域。
发明内容
本公开的一方面提供了一种用于为机器学习(ML)模型预测性能度量的方法。该方法包括:为各个用户生成一组ML模型;对于一组ML模型中的每个ML模型,操作代理反馈引擎以为一组ML模型中的相应ML模型生成代理得分,其中,该相应ML模型的代理得分是基于该相应ML模型的一个或多个预测性能度量的;训练来自一组ML模型的ML模型的子集以为ML模型的子集中的相应ML模型获得一个或多个实际性能度量;操作半监督学习(SSL)机制以学习一个或多个实际性能度量与ML模型的子集中的相应ML模型之间的关系;并且利用学习到的关系更新代理反馈引擎来为另一组ML模型生成代理得分。
本公开的另一方面提供了一种非暂态计算机可读存储介质,包括用于为机器学习模型预测性能度量的指令,其中指令被计算系统的一个或多个处理器执行将使得计算系统执行上述方法。
本公开的另一方面提供了一种用于提供机器学习模型开发环境(MDE)的装置。该装置包括:接口电路,被配置为从客户端设备获得机器学习(ML)输入;以及与接口电路通信地耦合的处理器电路,其中,处理器电路响应于从客户端设备接收到ML输入中的个体输入,而被配置为:基于个体输入获得ML模型,从代理反馈引擎为ML模型获得代理得分,其中:ML模型的代理得分是基于ML模型的一组预测性能度量的,ML模型和代理得分中的至少一者被半监督学习(SSL)机制用来学习实际性能度量和经训练的ML模型之间的关系,并且学习到的关系被代理反馈引擎用来为其他ML模型生成代理得分,并且经由接口电路将ML模型和代理得分提供给客户端设备。
本公开的又一方面提供了一种被用作机器学习(ML)计算系统的代理反馈引擎的装置。该装置包括:接口电路,被配置为经由ML模型开发环境(MDE)获得ML模型配置(MLMC);以及与接口电路通信地耦合的处理器电路,其中,处理器电路被配置为针对所获得的MLMC中的个体MLMC:基于个体MLMC中的信息从一组代理函数中选择一个或多个代理函数,利用所选择的一个或多个代理函数为与个体MLMC相对应的ML模型确定代理得分,其中,代理得分是基于ML模型的一组预测性能度量的,经由接口电路将所确定的代理得分提供给模型分析引擎,并且从模型分析引擎获得至少部分基于所确定的代理得分的实际ML性能度量到ML模型的更新后映射,以生成更新后的代理得分。
附图说明
在不一定按比例绘制的附图中,相似的标号在不同视图中可描述相似的组件。具有不同字母后缀的相似标号可表示相似组件的不同实例。在附图中以示例而非限制方式图示了一些实施例,在附图中:
图1描绘了根据各种实施例的机器学习(ML)模型工程系统的概况。
图2描绘了根据各种实施例的半监督学习机制的示例操作。
图3描绘了根据各种实施例的示例人工神经网络(ANN)。
图4a图示了示例加速器体系结构。
图4b图示了计算系统的示例组件。
图5和图6描绘了可用于实现本文论述的各种实施例的示例过程。
具体实施方式
本公开涉及人工智能(AI)、机器学习(ML)和神经体系结构搜索(NAS)技术,具体而言涉及用于使用代理评估反馈来设计深度神经网络(DNN)模型的技术。本文论述的DNN模型设计方法经由低成本的代理得分提供对模型性能近乎实时的反馈,而不要求持续的训练和/或验证循环、迭代、历时,等等。与基于代理的评分相结合,半监督学习(semi-supervised learning,SSL)机制被用来将代理得分映射到各种模型性能度量(例如,延时、准确度,等等)。
具体地,不是执行传统的训练验证迭代来确定已提出的模型体系结构的性能,而是使用代理函数来对神经网络的性能给出估计。此外,一种SSL机制被附加到代理函数,以将代理得分转换成有意义的度量。SSL机制增强了代理得分,以提高度量相关性,或者将代理得分映射成有意义的模型性能值。如前所述,现有的代理函数产生的代理得分对模型的性能给出粗略的估计。这些现有的代理函数经常在神经体系结构搜索(NAS)框架内被以一次性的方式使用。与这些现有的方法不同,本文论述的代理函数是在模型工程过程期间被交互性使用的。
此外,本文论述的模型工程系统可以考虑到特定的硬件平台属性,以给出硬件知晓的性能估计。此外,该模型工程系统适用于DNN的各个应用领域(例如,分类、自然语言处理(natural language processing,NLP)和/或自然语言理解(natural languageunderstanding,NLU)、图像、分割、推荐,等等)。
对于训练DNN模型,尤其是较大的DNN(例如,那些高网络参数计数),通常需要相对较长的时间来为每个参数配置获得对模型性能的训练/验证反馈。与典型的训练/验证系统相比,本文论述的模型工程系统极为快速地(就运行时间或者执行时间而言)提供ML模型性能反馈。本文论述的模型工程系统是第一种DNN模型调整方法,它使用SSL整体性地集成了代理评分函数和目标映射,这可能是以硬件知晓的方式完成的。与现有技术相比,使用这样的系统可以极大地减少有效设计ML模型所需要的时间和计算资源消耗。此外,通过减少ML模型工程的时间消耗和计算复杂度,模型工程系统可以使得AI/ML技术更广泛地可用于传统上无法获得执行传统ML模型设计所需要的大量资源的用户和社区。
1.机器学习模型工程系统
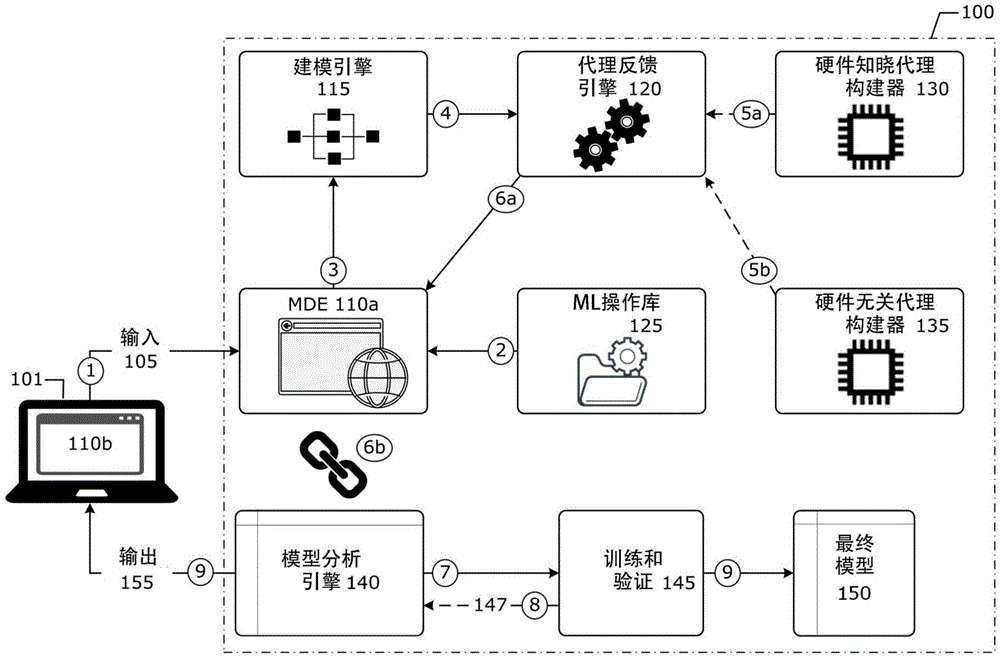
图1示出了根据各种实施例的示例ML模型工程系统100。ML模型工程系统100包括模型开发环境(model development environment,MDE)110a、建模引擎115(或者“建模器115”)、代理反馈引擎120、ML操作库125、硬件知晓代理构建器130、硬件无关代理构建器135、模型分析引擎140、训练和验证引擎145、以及最终模型输出150。系统100的操作可以是如下的。
在步骤1,客户端设备101向MDE 110a提供输入105。在图1中,客户端设备101被示为膝上型计算机,然而,客户端设备101可以是任何其他类型的客户端或用户设备,例如本文论述的那些。为了与MDE 110a交互,客户端设备101操作MDE客户端应用(app)110b(以下称为“MDE110b”),它可以是适当的客户端,例如web浏览器、桌面app、移动app、web app和/或其他类似元素,其被配置为经由适当的通信协议(例如,超文本传送协议(hypertexttransfer protocol,HTTP)(或者其变体)、消息队列遥测传输(Message Queue TelemetryTransport,MQTT)、实时流送协议(Real Time Streaming Protocol,RTSP),等等)与MDE110a进行操作。MDE 110a允许了客户端设备101的用户管理ML模型如何由系统100构建。MDE110a是服务器侧app或者类似的东西,其允许用户使用其MDE 110b向系统100提供输入105。例如,MDE 110a和MDE 110b(统称为“MDE 110”)提供了一种平台或框架,其允许ML模型设计者、开发者和/或其他类型的用户创建、编辑和/或操纵ML模型和/或ML应用。MDE 110包括图形用户界面(graphical user interface,GUI),其中包括各种图形元素/对象,这些图形元素/对象允许了用户添加、更新和/或改变各种ML模型操作、参数、超参数和/或其他类似的ML模型方面。在一些实现方式中,MDE 110b可以与用于app开发的软件开发环境(softwaredevelopment environment,SDE)、集成开发环境(integrated development environment,IDE)、软件开发工具包(software development kit,SDK)、软件开发平台(softwaredevelopment platform,SDP)等等相同或相似。此外,MDE 110a包括应用编程接口(application programming interface,API)以访问系统100的其他子系统,管理库依赖性和ML后端(例如,PyTorch、TensorFlow、Apache
输入105包括(一个或多个)AI/ML任务、AI/ML领域、(一个或多个)适当的数据集、支持的库(例如,张量库,等等)、初始ML模型、期望的硬件平台和/或配置、参数和/或超参数和/或其他类似参数中的一个或多个。AI/ML任务可以描述想要解决的问题,而AI/ML领域可以描述想要实现的目标。ML任务的示例包括聚类、分类、回归、异常检测、数据清理、自动化ML(autoML)、关联规则学习、强化学习、结构化预测、特征工程、特征学习、在线学习、监督学习、半监督学习(SSL)、无监督学习、机器学习排名(machine learned ranking,MLR)、语法归纳,等等。ML领域包括推论和问题解决、知识表示和/或本体论、自动化规划、自然语言处理(NLP)、感知(例如,计算机视觉、语音识别,等等)、自主运动和操纵(例如,定位、机器人运动/旅行、自主驾驶,等等)、以及社会智能。输入105可包括为AI/ML领域执行AI/ML任务的指令/命令,其形式为,例如,“为计算机视觉执行对象识别”。在这个示例中,“对象识别”是AI/ML任务,并且“计算机视觉”是AI/ML领域。另一个示例可以是“为NLP执行寻找准确度的回归”,其中“寻找准确度的回归”是AI/ML任务,并且“NLP”是AI/ML领域。
输入105还可包括适当格式化的数据集(或者对这种数据集的引用)。这里,适当格式化的数据集是指与指定的AI/ML任务和/或AI/ML领域相对应的数据集。例如,将会用于NLP领域的数据集可能会与用于计算机视觉领域的数据集不同。在一些实现方式中,输入105可包括,或者可以是,任何适当的形式或格式的信息对象、文件、电子文档,等等,例如,适当的标记语言文档(例如,超文本标记语言(HyperText Markup Language,HTML)、可扩展标记语言(Extensible Markup Language,XML)、AI标记语言(AI Markup Language,AIML)、JavaScript对象表示法(JavaScript Object Notation,JSON),等等)、柱状文件格式(例如,层次化数据格式(Hierarchical Data Format,HDF),包括HDF4、HDF5,等等;Hadoop分布式文件系统(Hadoop distributed file system,HDFS);
在步骤2,ML操作被提供给MDE 110a和/或建模器115。ML操作库125被包括来提供与指示的(一个或多个)AI/ML任务和AI/ML领域兼容的ML操作。这是因为不是所有的代理函数都能与所有的ML操作类型一起工作。在一些实现方式中,由ML操作库125指示的ML操作可以是或者包括张量操作、卷积、激活函数(例如,线性激活、修正器或者修正线性单元(rectified linear unit,ReLU)、参数化ReLUs(parametrics ReLU,PReLU)、高斯误差线性单元(Gaussian error linear unit,GELU)、指数线性单元(exponential linear unit,ELU)、缩放ELU(scaled ELU,SELU)、Sigmoid线性单元(Sigmoid linear unit,SiLU)、Heaviside激活、逻辑激活,等等)。兼容的操作可以经由MDE 110被提供给用户,作为与初始起点ML模型兼容的ML操作的列表。
在步骤3(可在步骤2之前、之后或者同时执行),MDE 110a将输入105提供给建模器115,该建模器基于提供的输入105生成或者以其他方式获得初始ML模型。在一些实现方式中,ML模型可以被设计/生成为张量操作层的高级别抽象。在其他实现方式中,ML模型是以计算图的形式以精细的细节设计/生成的。额外地或者替代地,用户可以经由MDE 110选择ML模型设计的细节水平。
此外,建模器115可以使用例如用户提供的模型配置来生成模型。在一些实现方式中,用户提供的模型配置可以是用户对理想或者最优ML模型的最佳猜测,并且建模器115可以基于其他提供的输入105来更新模型。额外地或者替代地,建模器115可以从仓库或者数据存储库获得适当的模型,例如当用户不提供初始ML模型配置时。在这些实现方式中,建模器115可以根据输入105修改获得的模型。
在一些实现方式中,当初始ML模型由建模器115生成或获得时,MDE 110a可以经由MDE 110b向客户端设备101输出155初始ML模型。初始模型可以由用户使用MDE 110b进行编辑、调整或者更改,然后其可以被提交回到MDE 110a以进行进一步更新/完善。这些步骤/操作可以以这种方式重复,直到模型被提交以用于由训练和验证引擎145运行的完整或部分训练和测试为止。例如,在用户没有提供ML模型配置的情况下,系统100基于AI/ML任务和AI/ML领域输入105提供基线示例模型。这可能是基本的ML模型配置,它可以被用作起始点,这然后可以由用户使用MDE 110b来更改或调节。
在ML模型设计阶段(例如,步骤1、2和3)期间发生的体系结构变化被自动更新为后端AI/ML语言/格式(例如,Torch、PyTorch、TensorFlow、Keras、OpenNN、AI标记语言(AImarkup language,AIML),等等)并且在步骤4被发送到代理反馈引擎120。代理反馈引擎120针对一组客观性能度量(例如,性能适配度和误差度量(performance fitness and errormetric,PFEM))确定ML模型的代理得分。代理反馈引擎120可以采用适当的代理函数,例如,经训练的预测器、查找表(look up table,LUT)、梯度之和,等等。关于代理反馈引擎120可以使用的代理函数的更多细节将在下文第1.1节中论述,并且性能度量的示例将在下文第1.2节中论述。起初,可以基于映射生成代理得分,并且随着时间的推移,可以使用SSL机制来改进原始代理得分及其映射(例如参见第1.3节和图2)。
在步骤5a,硬件知晓代理构建器130向代理反馈引擎120提供硬件性能基准或者性能估计得分。这允许了系统100考虑到硬件平台属性来给出硬件知晓的性能估计。硬件平台细节/规格可以由用户输入105或者从客户端设备101中挖掘出来。例如,如果用户希望有用于先前提到的客观性能度量的吞吐量、延时、功率估计,则硬件知晓代理构建器130可以在要在其上部署ML模型的所指示的硬件平台上运行基准或性能得分,这然后被提供给代理反馈引擎120。该基准或性能得分可以是查找表、指标、预测器或者一些其他适合代理反馈引擎120的数据结构的形式。额外地或者替代地,在步骤5b,硬件无关代理构建器135可以确定硬件性能的其他近似,例如通过使用模型中的参数和/或超参数的数目来确定硬件性能代理得分,这然后被提供给代理反馈引擎120。使用硬件知晓代理构建器130和/或硬件无关代理构建器135是用户可选择的。通过这些方式,用户可以选择为特定的硬件平台构建特定的ML模型。在一个示例中,用户可以为IoT设备或者自主传感器(例如图像传感器)输入105各种硬件(技术)细节,以用于对象识别模型。在另一个示例中,用户可以为NLP模型(例如,为聊天机器人之类的)输入105或者以其他方式指示出特定的云计算平台/服务(以及可选的,基于其云服务预订或账户细节的可用资源)。在这些示例中,硬件(技术)细节可包括关于(一个或多个)处理器、存储器设备、芯片组、传感器类型等等的信息。
在一些实现方式中,代理反馈引擎120响应于接收到用户输入(例如,在用户按压UI 105中的“提交按钮”时)被触发,而不是被自动触发。在任一实现方式中,代理反馈引擎120分析由建模引擎115提供的计算图和由代理构建器130和/或135(如果有的话)提供的性能得分,并且基于AI/ML任务和AI/ML领域,将基于适用于AI/ML任务和AI/ML领域的若干个客观度量(例如本文提到的那些)提供代理得分。在步骤6a,代理得分被提供给MDE 110a和/或模型分析引擎140,以进行排名或者以其他方式被分析和/或输出155到客户端设备105。额外地或者替代地,然后可以将各种得分与各种模型(或者在ML模型库中对这种模型的引用)关联地存储起来,用于未来的ML模型分析。
随着ML模型变体的列表由建模引擎115创建并且代理得分由代理反馈引擎120收集,在步骤6b,模型分析引擎140开始基于依AI/ML任务/领域而定的性能度量对模型进行排序和排名。在一些实现方式中,模型分析引擎140在建模引擎115和代理反馈引擎120的操作期间作为后台进程操作。
在步骤7,由训练和验证引擎145进行的训练和测试使用生成的ML模型开始。在一些实现方式中,训练和验证引擎145可以使用完整的训练数据集来训练ML模型(例如,“完整训练”),而在其他实现方式中,训练和验证引擎145可以使用部分训练数据集(训练子集)训练ML模型(例如,“部分训练”)。在一些实现方式中,用户或系统100可以决定何时开始训练和测试以应用半监督反馈机制(这在下文第1.3节中以及参考图2更详细论述)。在用户指导的实现方式中,用户可以选择或激活MDE 110b中的图形控制元素(例如,“开始完整训练”按钮之类的)以开始训练和测试145。在系统指导的实现方式中,系统100可以响应于一些事件或标准而被触发以激活训练和测试145,所述事件或标准例如是为用户生成一定数目的模型(例如,10个模型),在使用MDE 110b的一定时间之后,等等。额外地或者替代地,系统100可以仅基于代理得分向用户提供生成的ML模型150,而不执行测试和训练145。在步骤8,训练和验证引擎145向模型分析引擎140提供SSL反馈147,以改进代理函数和/或性能度量到ML模型方面的映射。在步骤9,训练和测试145操作的结果提供最终的模型输出150,该最终模型输出150然后作为输出155被提供给客户端设备101。
模型性能总结是以代理得分的形式出现的直到SSL机制启动为止。为了启动和启用半监督反馈147,可以通过随机选择、用户指导或输入105、和/或通过距离度量界限来给出对于要在其上执行完整训练/验证145的模型建议。例如,在生成了一大组具有代理得分的模型之后,可以通过完整训练/验证145运行这些模型的一个小子集。然后,完整训练/验证运行145的结果可以与半监督预测模型(例如参见第1.3节和图2)一起使用,这要求一些训练本身,以将代理得分映射到实际性能度量。按照SSL的性质,在代理到性能映射期间,模型之间的排名变得更加准确。
在一些实现方式中,ML模型工程系统100的元素110-150中的一些或全部由个体计算节点操作。例如,ML模型工程系统100可以是云计算服务的一部分,其中MDE 110a由一个或多个应用服务器操作,而建模器115、代理反馈引擎120、张量操作库125、硬件知晓代理构建器130、硬件无关代理构建器135、模型分析引擎140以及训练和验证引擎145由各个云计算节点操作。在另一个实现方式中,ML模型工程系统100的元素110-150中的一些或全部是由单个计算节点(例如,应用服务器、边缘计算服务、内容交付网络(content deliverynetwork,CDN)节点,等等)操作的软件元素。
1.1.代理反馈引擎
如前所述,代理反馈引擎120实现了一个或多个代理函数,以生成代理得分来预测ML模型性能。就本公开的目的而言,“代理函数”是指任何这样的函数:该函数将一个或多个变量、参数(例如,模型参数和/或超参数)、数据、ML模型体系结构方面(例如,NN层类型(例如,卷积层、多层感知(multilayer perception,MLP)层,等等)、NN层配置等等作为输入,并且产生作为输入的替换、代替、替身、替代或者表示的输出。与用于NAS技术的代理函数不同,代理反馈引擎120使用的代理函数用于为ML模型设计/工程近似模型性能,而不是用于为特定任务发现ML模型(像NAS的情况那样)。
此外,至少在一些实现方式中,用于近似ML模型性能的代理函数可以被分类为标准代理和低成本代理。标准代理函数的示例包括将键映射到值的函数和/或数据结构(例如,关联阵列、映射函数、字典、散列表、LUT、链接列表,等等)、ML分类器,等等。在示例LUT实现方式中,标准代理函数可以是用于延时预测的张量级式LUT。在ML分类器实现方式中,ML分类器可以是用于分类准确度的经训练的性能预测器。使用标准代理函数的一个缺点是,它们可能要求自己进行前期训练(例如,>1000个训练示例)才能做到准确。
低成本代理函数允许了快速近似ML模型性能,而没有预测器需要被训练的要求(参见例如[Abdelfattah]、[Mellor])。一般而言,低成本代理函数是利用未经训练的ML模型来获得性能的近似的函数。通常,低成本代理函数通过未经训练的ML模型发送非常小的一批数据(“迷你批次”),而不是执行完整的训练验证周期。这些类型的代理函数可以被视为“低成本”(就资源消耗而言),因为这种代理函数不要求任何前期ML训练,而是可以在任意的未训练的ML模型上运行。
低成本代理函数的一些示例包括参数计数、计算吞吐量度量、雅可比(Jacobian)协方差、显著性修剪、通道修剪、以及试探和/或超试探功能。参数计数包括对ML模型中的网络参数的数目计数,这可以被用作延时代理。计算吞吐量度量,例如每秒浮点运算(floating point operations per second,FLOPs)、乘法及累加(multiply andaccumulate,MAC)以及乘法加法(multiply add,MAdd)运算,也可以被用作延时代理。雅可比协方差捕捉了当受制于迷你批次数据内的不同输入时网络内的激活的相关性(参见例如[Mellor])。对于雅可比协方差,迷你批次数据被发送过未经训练的ML模型,然后ML模型内的不同激活被读出并且被用作(一个或多个)代理得分。
显著性修剪涉及基于显著性度量去除特定的参数,这改变梯度范数(参见例如Lee等人,“SNIP:Single-Shot Network Pruning based on Connection Sensitivity(SNIP:基于连接敏感性的单步网络修剪)”,国际学习表示会议(ICLR)2019(2019年5月6日)(“[Lee]”),特此通过引用将该文献整体并入在此)。换句话说,显著性修剪涉及在ML模型内搜索激活或梯度的高级别特性。通道修剪可以被认为是显著性修剪的子集。通道修剪涉及用参数损失估计来预测性能的修剪(参见例如Turner等人,“BlockSwap:Fisher-guidedBlock Substitution for Network Compression on a Budget(BlockSwap:用于预算内网络压缩的费雪引导的块替换)”,arXiv:1906.04113v2(2020年1月23日)(“[Turner]”),特此通过引用将该文献整体并入在此)。
试探函数(或者简称为“试探”)是指这样的函数:该函数在搜索算法中,在每个分支步骤中基于可用信息对备选方案进行排名以决定遵循哪个分支。超试探方法包括寻求使如下过程自动化的搜索方法:选择、组合、生成和/或调适几个更简单的试探(或者这种试探的组成部分)以高效地解决计算搜索问题,经常是通过纳入其他ML技术。
此外,代理反馈引擎120所使用的代理函数被视为灵活的和模块化的,以使得不同的代理函数可以基于AI/ML任务、要评估的指定性能度量等等被换入和换出。这种模块化还允许在发现新的ML模型时将新的或不同的代理函数添加到系统100。代理引擎120可以接受硬件知晓设置(例如,图1中的步骤5a处的硬件知晓代理构建器130)或者硬件无关设置(例如,
图1中的步骤5b处的硬件无关代理构建器135)以告知性能估计(例如,对于延时、吞吐量和/或功率消耗性能度量)。
在一些实现方式中,如果硬件平台细节被包括在输入105中,那么可以为ML操作库125操作采取一组前期级式测量,然后将其用于更新代理反馈引擎120。例如,如果用户指出将使用特定的7纳米(nm)工艺图形处理单元(graphics processing unit,GPU)来操作ML模型,那么张量操作在该GPU设备上的分布方式具有更好的延时、功率消耗和/或吞吐量度量,与如果同一ML模型由22nm工艺中央处理单元(central processing unit,CPU)操作的延时、功率消耗和/或吞吐量有所不同。这里,硬件知晓代理构建器130可以在所指示的硬件设备/平台上运行基准,这可以与一个或多个代理函数一起使用,以更好地近似ML模型的整体性能。
此外,不同的代理函数可以被应用到不同的AI/ML任务和/或用于评估不同的性能度量。例如,雅可比协方差可用于评估ML模型的第1(Top-1)准确度(具有最高概率的模型答案是否是预期答案),并且应用通道修剪来评估ML模型的前5准确度(例如,ML模型的五个最高概率答案中是否有任何一个与预期答案匹配)。此外,多个代理函数(例如本文提到的那些)的任意组合可用于提供不同性能度量的预测。可以使用每个代理函数提供的代理得分的加权平均,或者使用集总平均和/或集总学习,来完成代理函数的组合。
在一些实现方式中,用户可以选择特定的(一个或多个)代理函数来用于预测ML模型的性能度量。额外地或者替代地,SSL机制可用于识别用于特定AI/ML任务和其他输入105的(一个或多个)最优代理函数。
1.2.性能度量
将被预测的性能度量可以基于特定的AI/ML任务和其他输入105。该性能度量可包括基于模型的度量和基于平台的度量。基于模型的度量是与模型本身的性能有关和/或不考虑底层硬件平台的度量。基于平台的度量是与操作ML模型时底层硬件平台的性能有关的度量。
基于模型的度量可以基于特定类型的AI/ML模型和/或AI/ML领域。例如,可以为基于回归的ML模型预测与回归有关的度量。与回归有关的度量的示例包括误差值、平均误差、平均绝对误差(mean absolute error,MAE)、平均倒数排名(mean reciprocal rank,MRR)、均方误差(mean squared error,MSE)、根MSE(root MSE,RMSE)、相关系数(R)、确定系数(R
在另一个示例中,可以为与相关性有关的度量预测与相关性有关的度量。与相关性有关的度量包括准确度、精度(也称为阳性预测值(positive predictive value,PPV))、均值平均精度(mean average precision,mAP)、阴性预测值(negative predictivevalue,NPV)、召回(也称为真阳性率(true positive rate,TPR)或者敏感性)、特异性(也称为真阴性率(true negative rate,TNR)或者选择性)、假阳性率、假阴性率、F得分(例如,F
也可以预测额外的或者替代的基于模型的度量,例如,累积增益(cumulativegain,CG)、贴现CG(discounted CG,DCG)、归一化DCG(normalized DCG,NDCG)、信噪比(signal-to-noise ratio,SNR)、峰值信噪比(peak SNR,PSNR)、结构相似性(structuralsimilarity,SSIM)、并集上的交集(Intersection over Union,IoU)、复杂度(perplexity)、双语评估替补(bilingual evaluation understudy,BLEU)、初始得分、Wasserstein度量、Fréchet初始距离(Fréchet inception distance,FID)、字符串度量、编辑距离、Levenshtein距离、Damerau-Levenshtein距离、评估实例的数目(例如,迭代、历时或者发作)、学习速率(例如,算法达到(收敛到)最优权重的速度)、学习速率衰减(或者权重衰减)、计算数目、和/或与ML模型性能有关的其他类似的性能度量。
基于平台的度量的示例包括延时、响应时间、吞吐量(例如,处理器或平台/系统的处理工作的速率)、可用性和/或可靠性、功率消耗(例如,每瓦特的性能,等等)、晶体管计数、执行时间(例如,获得预测、推理等等的时间量)、存储器占用、存储器利用率、处理器利用率、处理器时间、计算数目、每秒指令(instructions per second,IPS)、每秒浮点运算(FLOPS)、和/或与ML模型和/或用于操作ML模型的底层硬件平台的性能有关的其他类似的性能度量。额外地或者替代地,基于平台的度量可以进一步被分类为硬件无关的度量和硬件知晓的度量。例如,硬件无关的度量可包括计算数目、参数计数、乘法累加(multiplyaccumulate,MAC)运算的数目,等等,而硬件知晓的度量可包括存储器占用、存储器利用率、处理器利用率、处理器时间、延时、吞吐量,等等。
额外地或者替代地,代理度量(例如,被用作另一个度量或属性的替身或代替的度量或属性)可用于预测ML模型性能。对于任何上述性能度量,可以使用任何适当的数据收集和/或(一个或多个)测量机制来预测和/或测量这种度量的总和、均值和/或一些其他分布。
1.3.半监督学习(SSL)机制
如前所述,SSL机制被用于改进模型与模型之间的排名,并且允许将排名/得分映射回到实际度量(例如,准确度、延时、功率消耗,等等)。与需要标记数据来进行训练的传统监督机器学习技术不同,SSL在最低限度的标记数据和大量未标记数据的组合上工作。SSL介于监督学习和无监督学习之间,其中SSL机制被提供了(未标记的)测试数据集和(标记的)训练数据集,但不一定是对于所有示例。SSL机制包括归纳学习和直推学习技术。归纳学习技术输出在整个空间
在第一种(归纳)实现方式中,SSL机制包括包装方法,它涉及使用标记数据集来训练一个或多个预测器模型(也称为“预测器”)。这可能涉及训练预测器以将实际性能度量映射到相应的ML模型(或者相应ML模型的组件或方面)。然后在未标记的数据上使用所得到的预测,以生成额外的标记数据集(称为“伪标记数据”之类的)。然后可以在伪标记数据上重训练(一个或多个)预测器,以改进(一个或多个)预测器的整体准确度。包装方法可以是自我训练包装方法、共同训练包装方法、或者提升包装方法,如van Engelen等人,“A surveyon semi-supervised learning(关于半监督学习的调查)”,机器学习,第109卷,第2期,第373-440页(2020年2月)(“[vanEngelen]”)中所论述,特此通过引用将该文献整体并入在此。
在第二种(归纳)实现方式中,SSL机制包括无监督的预处理方法,它在不同的阶段中使用未标记和标记的数据。无监督阶段包括从未标记数据自动提取或变换样本特征(特征提取),对数据进行无监督聚类(聚类-然后-标记),或者对学习过程的参数的初始化(预训练)。与第一种实现方式不同,在第二种实现方式中,监督预测器只被提供了最初标记的数据。这些无监督预处理方法的其他方面在[vanEngelen]中更详细论述。
在第三种(直推)实现方式中,SSL机制包括一种基于图的半监督方法,其中在所有标记的和未标记的数据点上定义了图,并且用加权边缘对按对相似性进行编码。一种目标函数被用来确保,对于标记的数据点,预测与标签相匹配,并且相似的点(在构造的图中定义)具有相似的预测。这种实现方式的示例包括图卷积网络(graph convolutionalnetwork,GCN),例如在Kipf等人,“Semi-Supervised Classification with GraphConvolutional Networks(利用图卷积网络的半监督分类)”,arXiv:1609.02907v4(2017年2月22日)(“[Kipf]”)中论述的那些,特此通过引用将该文献整体并入在此。
作为上述实现方式的附加或替代,可以使用其他SSL方法来实现SSL机制,例如在[vanEngelen]和/或Chapelle等人(编者注),“Semi-Supervised Learning(半监督学习)”,麻省理工学院出版社,剑桥,马萨诸塞州,伦敦,英国(2006年)(“[Chapelle]”)中论述的那些(特此通过引用将该文献整体并入在此),例如,生产式方法、判别方法、内在半监督方法、可缩放的直推学习方法、直推式支持向量机(Transductive Support Vector Machines,TSVM),等等。
图2示出了SSL机制200的示例,该机制被应用来映射和改进原始代理得分。SSL机制200首先从代理反馈引擎120获得各种ML模型的代理得分,并且根据其代理得分在图201中对ML模型进行排名。
图201(也被称为“代理得分空间201”)示出了基于准确度代理得分与代理反馈引擎120产生的延时代理得分的模型代理得分/排名。图201中的节点210可以表示个体ML模型和/或其代理得分(注意,为了清晰起见,图2中没有标注所有节点210)。为了绘制/排名ML模型,节点210可以是数据结构,这些数据结构包括准确度代理得分分量和延时代理得分分量。虽然图2示出了图201是2D图,但在其他实现方式中,图201可具有比所示出的更多的维度,其中每个维度表示不同的代理得分度量。例如,3D图201可包括准确度代理得分轴、延时代理得分轴和功率消耗代理得分轴,并且每个节点210可包括准确度代理得分、延时代理得分和功率消耗代理得分分量。如前所述,可以使用相同或不同的代理函数来产生每个代理得分。
从图201,选择节点210(或者其相应ML模型)的子集用于训练和验证145。如前所述,用于训练和验证145的模型的选择可以是随机的、用户指导的或者模型-距离指导的。在图2的示例中,图201中填充的(即,黑色)节点210对应于为训练和验证145选择的模型,而未填充的(即,白色)节点210对应于未选择的模型。
接下来,由训练和验证引擎145对所选的模型执行训练和验证。这里,使用完整的训练集合对所选模型进行完整训练/验证,虽然在一些实现方式中可以使用部分训练数据集(训练子集)进行训练/验证。训练和验证引擎145为所选模型产生实际的客观度量值,这在图2的示例中包括准确度和延时度量。所选模型的实际客观度量值被用作标记数据的子集,该子集然后被用于训练半监督模型220。
在训练和验证145之后,生成了代理评分模型的完整集合的表示220。在这个示例中,SSL机制200包括使用GCN 220,其中每个模型(包括来自图201的所选模型和未选择模型)由GCN 220中的节点表示。此外,GCN 220中的每条边缘由模型与模型之间的相似度度量(例如,计算图Damerau-Levenshtein距离和/或一些其他的图形相似度度量)加权。
在训练GCN 220之后,学习到的节点/边缘嵌入可以用来预测实际的客观性能度量值,从而在图203中产生更可用且更准确得多的ML模型排名输出。图203(也被称为“性能空间203”)示出了由GCN 220在推理/预测阶段之后产生的一组改进的模型排名。图203中的节点230可以表示个体ML模型和/或其改进的排名/得分(注意,为了清晰起见,图2中没有标注所有的节点230)。为了绘制/排名ML模型,节点230可以是数据结构,这些数据结构包括准确度分量和延时分量。与图201类似,图203可具有比所示更多的维度,并且图203中的维度/轴的数目可以与图201中的维度/轴的数目相同,并且节点230可具有与每个轴相对应的分量。在图203中,填充的(黑色)节点230对应于从训练/验证145(例如,从选自图201的模型)产生的实际值,而未填充的(白色)节点230是来自GCN220的增强预测值。
然后,来自图203的改进的排名/得分被映射到相应ML模型(和/或其方面),这些ML模型(和/或其方面)然后被反馈到代理反馈引擎120以产生更准确的代理得分。这些更新/改进的映射比先前存在的代理得分更准确,至少在期望的目标方面是如此。
在一些实现方式中,每次模型(或者一组模型)通过SSL机制200被运行时,就可以测量不同节点230之间的距离和/或可以为不同的代理函数测量个体节点230与代理得分的关系。在若干次通过SSL机制200之后,对于每个AI/ML任务/领域,可以基于这些度量对不同的代理函数(和/或代理函数的组合)进行排名(例如,由模型分析引擎140)。这样,代理函数排名随后可以被用于以后的迭代,以产生更好的代理得分。
此外,随着使用系统100为不同的AI/ML任务和领域设计/策划更多的ML模型,将产生更多的代理得分,然后将其反馈到SSL机制200中,从而产生更加改进的代理函数和/或改进的代理评分机制(在速度、准确度和减少资源消耗方面)。在一些情况下,SSL机制200可以产生更快、更准确和/或使用更少资源的(一个或多个)代理函数,超越当前存在的那些,并且有可能超越人类头脑所能想象的。
1.4.交互式用例示例
系统100的示例用例包括教导参考图1-图2描述的AI/ML概念的交互式教育应用。在这个用例中,MDE app 110b可以被设计为交互式命令行或者GUI,它可由最终用户(例如,使用客户端设备101)访问。用户通过定义问题AI/ML任务、AI/ML领域开始,并且加载关联的数据集(例如,输入105)。例如,用户可以从简单的图像分类任务开始,并且使用修改后的国家标准和技术研究所(Modified National Institute of Standards and Technology,MNIST)数据库作为数据集。然后,将向用户展示基于AI/ML任务和/或AI/ML领域的建议起始点(初始)ML模型(例如,DNN或者类似的),并且将向用户示出系统100支持的可用ML操作(例如,张量操作、卷积操作、激活函数,等等)(例如,(一个或多个)代理函数用来工作的操作)的列表。
接下来,用户将使用来自支持的操作125的(张量)库中的组件交互地开始构建其ML模型。例如,MDE 110a可以提供基于可用/支持的操作125的图形对象,并且用户可以开始从库125中拖放和/或连接图形张量组件。随着ML模型被修改,系统100将迭代地向用户反馈ML模型的每个特定迭代对某些度量(例如,准确度、延时、FLOP,等等)的性能如何。例如,响应于与MDE 110a的个体交互,MDE 110a将提供性能反馈,这可以继续迭代,直到用户对模型感到满意为止。
后台进程(例如,模型分析引擎140)将对所有测试的模型进行排名,提供统计数据,并且为SSL机制200建议模型。在半监督反馈阶段147之后,整组代理得分将得到更好的排名,并且被映射到实际性能度量。如果用户找到其喜欢的模型作为“最终模型”,则系统将完全训练145并且输出这个模型150。
2.人工智能和机器学习方面
“机器学习”(machine learning,ML)涉及使用编程计算系统来利用示例(训练)数据和/或过去的经验优化性能标准。ML指的是使用和开发计算机系统,这些计算机系统通过使用算法和统计模型来分析数据中的模式并从中作出推理,能够学习和适应,而无需遵循明确的指令。ML涉及使用算法来执行(一个或多个)特定任务,而不使用明确的指令来执行该(一个或多个)特定任务,而是依靠学习到的模式和/或推理。ML使用统计学来构建(一个或多个)数学模型(也称为“ML模型”或简称为“模型”),从而基于样本数据(例如,训练数据)作出预测或决策。模型被定义为具有一组参数,并且学习是执行计算机程序,以利用训练数据或过去的经验来优化该模型的参数。经训练的模型可以是基于输入数据集作出预测的预测性模型,从输入数据集获得知识的描述性模型,或者既是预测性的也是描述性的。一旦模型被学习(训练),它就可以被用来作出推理(例如,预测)。
ML算法在训练数据集上执行训练过程,以估计底层的ML模型。ML算法是一种计算机程序,它从关于某个(或某些)任务的经验和某个(或某些)性能测量/度量中学习,并且ML模型是在用训练数据训练ML算法之后创建的对象或数据结构。换言之,术语“ML模型”或“模型”可以描述用训练数据训练的ML算法的输出。在训练之后,ML模型可被用于在新的数据集上作出预测。此外,在推理或预测生成期间,分开训练的AI/ML模型可以在AI/ML管线中被链接起来。虽然术语“ML算法”指的是与术语“ML模型”不同的概念,但这些术语对于本公开而言可以被互换使用。本文论述的任何ML技术可以全部或部分地被利用,以及其变体和/或组合,用于本文论述的任何示例实施例。
除其他事项外,ML可能要求获得和清理数据集,执行特征选择,选择ML算法,将数据集划分为训练数据和测试数据,训练模型(例如,使用所选择的ML算法),测试模型,优化或调整模型,以及确定模型的度量。取决于用例和/或使用的实现方式,这些任务中的一些可能是可选的或者省略的。
ML算法接受模型参数(或者简称为“参数”)和/或超参数,这些模型参数和/或超参数可用于控制训练过程和所得到的模型的某些属性。模型参数是在训练期间学习到的参数、值、特性和/或属性。额外地或者替代地,模型参数可包括模型内部的配置变量,其值可以从给定的数据估计出来。模型参数经常是模型在作出预测时所需要的,并且其值定义了模型在特定问题上的技能。这种模型参数的示例包括权重(例如,在NN中);约束;支持向量机(support vector machine,SVM)中的支持向量;线性回归和/或逻辑回归中的系数;用于自然语言处理(NLP)和/或自然语言理解(NLU)的词频、句子长度、每个句子的名词或动词分布、每个词的特定字符n元语法数目、词汇多样性,等等;和/或类似的。
超参数至少在一些实施例中是指在训练过程期间无法学习的ML过程的特性、属性和/或参数。超参数经常在训练发生之前被设置,并且可在过程中用于帮助估计模型参数。超参数的示例包括模型大小(例如,在存储器空间、字节、层数等方面);训练数据置乱(例如,是否置乱和置乱程度);评估实例、迭代、历时(例如,在训练数据上的迭代或道次的数目)或者发作(episode)的数目;学习速率(例如,算法达到(收敛到)最优权重的速度);学习速率衰减(或者权重衰减);隐藏层的数目;个体隐藏层的大小;权重初始化方案;退出和梯度剪裁阈值;SVM的C值和sigma值;k最近邻居中的k;向量大小;NLP和NLU的词向量大小;和/或类似的。
ML技术一般分为以下主要类型的学习问题范畴:监督学习、无监督学习以及强化学习。监督学习是一种ML任务,其旨在在给定标记数据集的情况下,学习从输入到输出的映射函数。监督学习算法从既包含输入也包含期望输出的一组数据中构建模型。例如,监督学习可涉及学习一种函数(模型),该函数(模型)基于示例输入-输出对或某种其他形式的标记训练数据(包括一组训练示例)将输入映射到输出。每个输入-输出对包括输入对象(例如,向量)和期望的输出对象或值(被称为“监督信号”)。监督学习可以被分组分量类算法、回归算法和基于实例的算法。
术语“无监督学习”是一种ML技术,其旨在学习一种函数来从未标记的数据描述隐藏结构。无监督学习算法从只包含输入而不包含期望的输出标签的一组数据中构建模型。无监督学习的一些示例包括K均值聚类、主分量分析(principal component analysis,PCA)以及主题建模,等等。
半监督学习(semi-supervised learning,SSL)算法从不完整的训练数据开发ML模型的ML算法,其中样本输入的一部分不包括标签。SSL可包括直推学习(例如,为一组未标记的数据推理出正确的标签)或者归纳学习(例如,推理出从第一值到第二值的正确映射)。无监督学习的示例包括主题建模、直推式SVM(transductive SVM,TSVM)、生产式建模、自我训练、共同训练,和/或类似的。
强化学习(reinforcement learning,RL)是一种基于与环境的交互的目标导向的学习技术。在RL中,代理旨在基于试错过程通过与环境的交互来优化长期目标。RL算法的示例包括马尔科夫决策过程、马尔科夫链、深度RL(deep RL,DRL)、Q学习、深度Q学习、多臂匪徒问题。
AI和ML的一些实现方式以模仿生物大脑工作的方式使用数据和神经网络(neuralnetwork,NN)。图3示出了这种实现方式的示例。
图3图示了示例NN 300,它可能适合由本文论述的各种实现方式的一个或多个计算系统(或子系统)使用,部分由硬件加速器实现,等等。NN 300可以是深度神经网络(deepneural network,DNN),其被用作计算节点或者计算节点的网络的人工大脑,以处理非常大且复杂的观察空间。额外地或者替代地,NN 300可以是一些其他类型的拓扑结构(或者拓扑结构的组合),例如卷积NN(convolution NN,CNN)、深度CNN(deep CNN,DCN)、递归NN(recurrent NN,RN)、长短期记忆(Long Short Term Memory,LSTM)网络、解卷积NN(Deconvolutional NN,DNN)、门控递归单元(gated recurrent unit,GRU)、深度信念NN、前馈NN(feed forward NN,FFN)、深度FNN(deep FNN,DFF)、深度堆叠网络、马尔科夫链、感知NN、贝叶斯网络(Bayesian Network,BN)或者贝叶斯NN(Bayesian NN,BNN)、动态BN(Dynamic BN,DBN)、线性动力系统(Linear Dynamical System,LDS)、切换LDS(SwitchingLDS,SLDS)、光学NN(Optical NN,ONN)、用于强化学习(RL)和/或深度RL(DRL)的NN,等等。NN通常被用于监督学习,但也可被用于无监督学习和/或RL。
NN 300可包含各种ML技术,其中连接的人工神经元310的集合(松散地)对生物大脑中的神经元建模,这些神经元将信号传递给其他神经元/节点310。神经元310也可被称为节点310、处理元件(processing element,PE)310,等等。节点310之间的连接320(或者边缘320)是在生物大脑的突触上(松散)建模的,并且在节点310之间传达信号。注意,为了清晰起见,图3中没有标注所有的神经元310和边缘320。
每个神经元310具有一个或多个输入,并且产生输出,该输出可被发送到一个或多个其他神经元310(输入和输出可被称为“信号”)。输入层L
在ML的上下文中,“ML特征”(或者简称为“特征”)是正被观察的现象的个体可测量属性或特性。特征通常是用数字/数值(例如,整数)、字符串、变量、序数、实值、种类等等来表示的。额外地或者替代地,基于可以量化和记录的可观察现象,ML特征是个体变量,其可以是独立变量。ML模型使用一个或多个特征来进行预测或推理。在一些实现方式中,可以从旧的特征得出新的特征。一组特征可以被称为“特征向量”。向量是被称为标量的一个或多个的值的元组,并且特征向量可包括一个或多个特征的元组(例如,包含实例的已知属性的数据结构)。与这些向量相关联的向量空间经常被称为“向量空间”或者“特征空间”。
神经元310可具有阈值,以使得仅当聚集信号越过该阈值时才会发送信号。节点310可包括激活函数,该激活函数定义了该节点310在给定一输入或者一组输入时的输出。额外地或者替代地,节点310可包括传播函数,该传播函数从其前任神经元310的输出以及其连接320以加权和的形式计算对神经元310的输入。偏置项也可以被添加到传播函数的结果。
NN 300还包括连接320,其中一些连接提供至少一个神经元310的输出作为至少另一个神经元310的输入。每个连接320可以被赋予表示其相对重要性的权重。随着学习的进行,权重也可以被调整。权重增大或减小了连接320处的信号的强度。
神经元310可以被聚集或者分组为一个或多个层L,其中不同的层L可以对其输入执行不同的变换。在图3中,NN 300包括输入层L
3.示例硬件和软件配置和布置
图4a是根据各种实施例的示例加速器体系结构400。加速器体系结构400向应用逻辑412提供神经网络(NN)功能,因此,可被称为NN加速器体系结构400、DNN加速器体系结构400,等等。
应用逻辑412可包括用于执行规范功能的应用软件和/或硬件组件。应用逻辑412将数据414转发给推理引擎416。推理引擎416是运行时元件,它提供统一的应用编程接口(application programming interface,API),该接口将ANN(例如,(一个或多个)DNN之类的)推理与应用逻辑412集成,以向应用逻辑412提供结果418(或输出)。
为了提供推理,推理引擎416使用模型420,该模型控制如何在数据414上进行DNN推理以生成结果418。具体而言,模型420包括DNN的层的拓扑结构。该拓扑结构包括接收数据414的输入层,输出结果418的输出层,以及在输入和输出层之间的提供数据14和结果418之间的处理的一个或多个隐藏层。该拓扑结构可被存储在适当的信息对象中,例如可扩展标记语言(extensible markup language,XML)、JavaScript对象表示法(JavaScriptObject Notation,JSON)和/或其他适当数据结构、文件,等等。模型420还可包括对于任何层的结果的权重和/或偏差,同时在使用DNN的推理中处理数据414。
推理引擎416可以使用(一个或多个)硬件单元422来实现和/或连接到(一个或多个)硬件单元422。推理引擎416至少在一些实施例中是这样的元素:它将逻辑规则应用于知识库以推断出新的信息。知识库至少在一些实施例中是用于存储计算系统(例如,图4的计算系统450)使用的复杂结构化和/或非结构化信息的任何技术。知识库可包括存储设备、仓库、数据库管理系统和/或其他类似元素。
此外,推理引擎416包括一个或多个加速器424,这些加速器使用一个或多个硬件单元422为DNN推理提供硬件加速。(一个或多个)加速器424是为AI/ML应用和/或AI/ML任务专门定制/设计作为硬件加速的(一个或多个)软件和/或硬件元素。一个或多个加速器424可包括一个或多个处理元件(processing element,PE)阵列和/或采取多个突触结构425的形式的乘法及累加(multiply-and-accumulate,MAC)体系结构。(一个或多个)加速器424可以对应于下文所述的图4的加速电路464。
(一个或多个)硬件单元422可包括一个或多个处理器和/或一个或多个可编程设备。作为示例,处理器可包括中央处理单元(central processing unit,CPU)、图形处理单元(graphics processing unit,GPU)、专用AI加速器专用集成电路(ApplicationSpecific Integrated Circuit,ASIC)、视觉处理单元(vision processing unit,VPU)、张量处理单元(tensor processing unit,TPU)和/或边缘TPU、神经计算引擎(NeuralCompute Engine,NCE)、像素视觉核心(Pixel Visual Core,PVC)、光子集成电路(photonicintegrated circuit,PIC)或者光学/光子计算设备,等等。可编程设备可包括例如逻辑阵列、可编程逻辑器件(programmable logic device,PLD)(例如复杂PLD(complex PLD,CPLD))、现场可编程门阵列(field-programmable gate array,FPGA)、可编程ASIC、可编程片上系统(System-on-Chip,SoC),等等。(一个或多个)处理器和/或可编程设备可以对应于图4的处理器电路452和/或加速电路464。
图4b图示了可能存在于用于实现本文描述的技术(例如,操作、过程、方法和方式)的计算系统450中的组件的示例。计算系统450提供了当作为计算设备(例如,作为移动设备、基站、服务器计算机、网关,器具,等等)实现或者作为其一部分实现时节点400的各个组件的更靠近视图。计算系统450可包括本文提到的硬件或逻辑组件的任意组合,并且它可包括可用于边缘通信网络或者这种网络的组合的任何设备或者可与这种设备耦合。这些组件可以作为适配在计算系统450中的IC、其一些部分、分立电子设备、或者其他模块、指令集、可编程逻辑或算法、硬件、硬件加速器、软件、固件或者其组合来实现,或者作为以其他方式被包含在更大系统的机壳内的组件来实现。对于一个实施例,至少一个处理器452可以与计算逻辑482被封装在一起并且被配置为实现本文描述的各种示例实施例的一些方面以形成系统级封装(System in Package,SiP)或片上系统(System on Chip,SoC)。
系统450包括采取一个或多个处理器452的形式的处理器电路。处理器电路452包括诸如以下电路(但不限于此):一个或多个处理器核心以及以下各项中的一个或多个:缓存存储器、低压差(low drop-out,LDO)电压调节器、中断控制器、诸如SPI、I2C或通用可编程串行接口电路之类的串行接口、实时时钟(real time clock,RTC)、包括间隔和看门狗定时器在内的定时器-计数器、通用I/O、诸如安全数字/多媒体卡(secure digital/multi-media card,SD/MMC)之类的存储卡控制器、接口、移动工业处理器接口(mobile industryprocessor interface,MIPI)接口以及联合测试访问组(Joint Test Access Group,JTAG)测试访问端口。在一些实现方式中,处理器电路452可包括一个或多个硬件加速器(例如,与加速电路464相同或相似),这些加速器可以是微处理器、可编程处理设备(例如,FPGA、ASIC,等等)之类的。该一个或多个加速器可包括例如计算机视觉和/或深度学习加速器。在一些实现方式中,处理器电路452可包括芯片上存储器电路,其可包括任何适当的易失性和/或非易失性存储器,例如DRAM、SRAM、EPROM、EEPROM、闪存、固态存储器、和/或任何其他类型的存储器设备技术,例如本文论述的那些。
处理器电路452可包括例如一个或多个处理器核心(CPU)、应用处理器、GPU、RISC处理器、Acorn RISC机器(Acorn RISC Machine,ARM)处理器、CISC处理器、一个或多个DSP、一个或多个FPGA、一个或多个PLD、一个或多个ASIC、一个或多个基带处理器、一个或多个射频集成电路(radio-frequency integrated circuit,RFIC)、一个或多个微处理器或控制器、多核处理器、多线程处理器、超低电压处理器、嵌入式处理器,或者任何其他已知的处理元件,或者这些的任意适当组合。处理器(或核心)452可与存储器/存储装置相耦合或者可包括存储器/存储装置并且可被配置为执行存储在存储器/存储装置中的指令481以使得各种应用或操作系统能够在平台450上运行。处理器(或核心)452被配置为操作应用软件,以向平台450的用户提供特定服务。在一些实施例中,(一个或多个)处理器452可以是被配置为(或者可配置为)根据本文的各种实施例来进行操作的(一个或多个)专用处理器/控制器。
作为示例,(一个或多个)处理器452可包括
系统450可包括或耦合到加速电路464,该加速电路可由以下所列项来实现:一个或多个AI/ML加速器、神经计算棒、神经形态硬件、FPGA、GPU的布置、一个或多个SoC(包括可编程SoC)、一个或多个CPU、一个或多个数字信号处理器、专用ASIC(包括可编程ASIC)、PLD(比如复杂PLD(complex PLD,CPLD)或高复杂度PLD(high complexity PLD,HCPLD)),和/或被设计为实现一个或多个专门任务的其他形式的专门处理器或电路。这些任务可包括AI/ML处理(例如,包括训练、推理和分类操作)、视觉数据处理、网络数据处理、对象检测、规则分析,等等。在基于FPGA的实现方式中,加速电路464可包括逻辑块或逻辑架构和其他互连的资源,这些资源可以被编程(配置)为执行各种功能,例如本文论述的各种实施例的过程、方法、功能,等等。在这样的实现方式中,加速电路464还可包括用于在LUT等等中存储逻辑块、逻辑架构、数据等等的存储器单元(例如,EPROM、EEPROM、闪存、静态存储器(例如,SRAM、反熔丝,等等))。
在一些实现方式中,处理器电路452和/或加速电路464可包括专门为机器学习功能定制的硬件元素,例如用于操作执行ANN操作,例如本文论述的那些。在这些实现方式中,处理器电路452和/或加速电路464可以是或者可以包括AI引擎芯片,这种芯片一旦被加载以适当的加权和训练代码,则可以运行许多不同种类的AI指令集。额外地或者替代地,处理器电路452和/或加速电路464可以是或者可以包括(一个或多个)AI加速器,该加速器可以是为AI应用的硬件加速而设计的上述硬件加速器中的一个或多个。作为示例,这些处理器或加速器可以是以下所列项的集群:人工智能(AI)GPU、
系统450还包括系统存储器454。可以使用任意数目的存储器设备来提供给定量的系统存储器。作为示例,存储器454可以是或者可以包括易失性存储器,例如随机访问存储器(random access memory,RAM)、静态RAM(static RAM,SRAM)、动态RAM(dynamic RAM,DRAM)、同步DRAM(synchronous DRAM,SDRAM)、
存储电路458提供诸如数据、应用、操作系统等等之类的信息的持久性存储。在一示例中,存储装置458可以经由固态盘驱动器(solid-state disk drive,SSDD)和/或高速电可擦除存储器(通常被称为“闪存”)来实现。可用于存储装置458的其他设备包括闪存卡,比如SD卡、microSD卡、XD图片卡,等等,以及USB闪存驱动器。在一示例中,存储器设备可以是或者可以包括使用硫属化合物玻璃的存储器设备,多阈值级别NAND闪存,NOR闪存,单级别或多级别相变存储器(Phase Change Memory,PCM),电阻性存储器,纳米线存储器,铁电晶体管随机访问存储器(ferroelectric transistor random access memory,FeTRAM),反铁电存储器,包含忆阻器技术的磁阻式随机访问存储器(magnetoresistive randomaccess memory,MRAM)存储器,相变RAM(phase change RAM,PRAM),包括金属氧化物基底、氧空位基底和导电桥随机访问存储器(conductive bridge Random Access Memory,CB-RAM)的电阻性存储器,或者自旋转移力矩(spin transfer torque,STT)-MRAM,基于自旋电子磁结存储器的设备,基于磁隧道结(magnetic tunneling junction,MTJ)的设备,基于畴壁(Domain Wall,DW)和自旋轨道转移(Spin Orbit Transfer,SOT)的设备,基于半导体闸流管的存储器设备,硬盘驱动器(hard disk drive,HDD)、微型HDD,或者这些的组合,或者任何其他存储器。存储器电路454和/或存储电路458也可以包含来自
存储器电路454和/或存储电路458被配置为以软件、固件、微代码或硬件级指令的形式存储计算逻辑483,以实现本文描述的技术。计算逻辑483可被采用来存储编程指令的工作拷贝和/或永久拷贝,或者用于创建编程指令的数据,以用于操作系统400的各种组件(例如,驱动器、库、应用编程接口(application programming interface,API),等等)、系统400的操作系统、一个或多个应用,和/或用于实现本文论述的实施例。计算逻辑483可以作为指令482或用于创建指令482的数据被存储或加载到存储器电路454中,然后被处理器电路452访问以执行,以实现本文描述的功能。处理器电路452和/或加速电路464通过IX456访问存储器电路454和/或存储电路458。指令482指导处理器电路452执行特定的动作序列或流程,例如,如参考先前描绘的操作和功能的(一个或多个)流程图和(一个或多个)框图所描述。各种要素可由处理器电路452支持的汇编指令或高级别语言来实现,这些指令可被编译成指令481,或者用于创建指令481的数据,以由处理器电路452执行。编程指令的永久拷贝可以通过例如分发介质(未示出)、通过通信接口(例如,来自分发服务器(未示出))、通过空中(OTA)或者这些的任意组合,被放入到工厂或现场的存储电路458的持久性存储设备中。
IX 456将处理器452耦合到通信电路466,用于与其他设备(例如远程服务器(未示出)等等)的通信。通信电路466是一种硬件元素,或者硬件元素的集合,用于通过一个或多个网络463和/或与其他设备通信。在一个示例中,通信电路466是或者包括收发器电路,该收发器电路被配置为使用任意数目的频率和协议来实现无线通信,所述协议例如是电气与电子工程师学会(Institute of Electrical and Electronics Engineers,IEEE)802.11(和/或其变体),IEEE 802.15.4,
IX 456还将处理器452耦合到接口电路470,该接口电路用于将系统450与一个或多个外部设备472相连接。外部设备472可包括例如传感器、致动器、定位电路(例如,全球导航卫星系统(global navigation satellite system,GNSS)/全球定位系统(GlobalPositioning System,GPS)电路)、客户端设备、服务器、网络器具(例如,交换机、集线器、路由器,等等)、集成光子学设备(例如,光神经网络(optical neural network,ONN)集成电路(integrated circuit,IC)之类的),和/或其他类似的设备。
在一些可选的示例中,各种输入/输出(I/O)设备可存在于系统450内或者与之相连接,这些设备在图4中被称为输入电路486和输出电路484。输入电路486和输出电路484包括被设计为使得用户能够与平台450交互的一个或多个用户接口,和/或被设计为使得外围组件能够与平台450交互的外围组件接口。输入电路486可包括用于接受输入的任何物理或虚拟装置,尤其包括一个或多个物理或虚拟按钮(例如,重置按钮)、物理键盘、小键盘、鼠标、触摸板、触摸屏、麦克风、扫描仪、耳麦,等等。输出电路484可被包括来示出信息或以其他方式传达信息,例如传感器读数、(一个或多个)致动器位置、或者其他类似的信息。数据和/或图形可被显示在输出电路484的一个或多个用户接口组件上。输出电路484可包括任意数目和/或组合的音频或视觉显示器,尤其包括一个或多个简单视觉输出/指示器(例如,二元状态指示器(例如,发光二极管(light emitting diode,LED))和多字符视觉输出,或者更复杂的输出,比如显示设备或触摸屏(例如,液晶显示器(Liquid Chrystal Display,LCD)、LED显示器、量子点显示器、投影仪,等等),其中字符、图形、多媒体对象等等的输出是从平台450的操作生成或产生的。输出电路484也可包括扬声器和/或其他音频发出设备、(一个或多个)打印机,等等。额外地或者替代地,(一个或多个)传感器可被用作输入电路484(例如,图像捕捉设备、运动捕捉设备,等等)并且一个或多个致动器可被用作输出设备电路484(例如,致动器,来提供触觉反馈等等)。外围组件接口可包括但不限于非易失性存储器端口、USB端口、音频插孔、电力供应接口,等等。在本系统的背景下,显示器或控制台硬件可被用于提供边缘计算系统的输出和接收输入;管理边缘计算系统的组件或服务;识别边缘计算组件或服务的状态;或者进行任何其他数目的管理或管控功能或服务用例。
系统450的组件可以通过互连(IX)456进行通信。IX 456可包括任意数目的技术,包括ISA、扩展ISA、I2C、SPI、点对点接口、功率管理总线(PMBus)、PCI、PCIe、PCIx、
系统450的元件的数目、能力和/或容量可以有所不同,这取决于计算系统450是被用作固定计算设备(例如,数据中心中的服务器计算机、工作站、桌面型计算机,等等)还是移动计算设备(例如,智能电话、平板计算设备、膝上型计算机、游戏机、IoT设备,等等)。在各种实现方式中,计算设备系统400可包括数据中心的一个或多个组件、桌面型计算机、工作站、膝上型电脑、智能电话、平板设备、数码相机、智能家电、智能家庭中枢、网络器具、和/或处理数据的任何其他设备/系统。
4.示例实现方式
图5描绘了用于为ML模型预测性能度量的示例过程500,其可由ML模型工程系统100执行。过程500开始于操作501,其中为各个用户(例如,每个操作相应的客户端设备101)生成一组ML模型。在操作502,系统100确定是否已从任何用户接收到任何ML模型配置(MLmodel configuration,MLMC)更新。如果没有,则系统100循环回来继续检查MLMC更新。对于每个获得的MLMC,在操作503,系统100操作代理反馈引擎120,以为相应的MLMC/ML模型生成代理得分。相应的MLMC/ML模型的代理得分是基于相应的MLMC/ML模型的一个或多个预测性能度量的。同时,在操作505,系统100确定是否已接收到训练触发(例如,用户输入或者预定的事件/标准)。如果没有,则系统100循环回来继续监视训练触发。如果检测到训练触发,则系统100在操作506处操作训练和验证引擎145,以从具有代理得分的一组ML模型/MLMC训练ML模型的子集。执行该训练以获得ML模型的子集中的ML模型的一个或多个实际性能度量。在操作507,系统100操作SSL机制以学习该一个或多个实际性能度量与ML模型的子集中的ML模型之间的关系。一个或多个实际性能度量和ML模型的子集中的ML模型之间的“关系”可以指实际性能度量和ML模型之间的“映射”、实际性能度量和ML模型之间的“关系”、和/或实际性能度量和ML模型之间的任何其他对应关系,或者这些的组合。在操作508,系统100用学习到的关系更新代理反馈引擎120,以便为未来的ML模型/MLMC生成改进的代理得分。在操作508之后,系统100循环回到操作501,以继续为各种用户生成ML模型。
图6描绘了用于操作MDE 110a的示例过程600a。过程600a开始于操作601,其中MDE110a从客户端设备101(或者客户端侧MDE app110b)获得MLMC作为ML输入105。ML输入可包括ML任务、ML领域、对数据集的引用、和/或初始/起始ML模型。在操作602,MDE 110a从建模引擎115获得ML模型。所获得的模型可以是初始/起始ML模型的更新/修订版本(如果提供的话),或者可以是初始/起始ML模型(如果MLMC中不包括的话)。在操作603,MDE 110a从代理反馈引擎120获得ML模型的代理得分。在操作604,MDE 110a向客户端设备101提供代理得分和所获得的ML模型。在操作605,MDE 110a确定是否已触发了训练,并且如果没有,则MDE110a循环回到操作601以获得新的或者更新的MLMC。如果已触发了训练,那么在操作606,MDE 110a将获得的ML模型提交给训练和验证引擎145以训练ML模型,然后操作607将经训练的ML模型150提供给客户端设备101(或者MDE 110b)。在操作607之后,MDE 110a循环回到操作601以获得新的或者更新的MLMC。
图6还描绘了用于操作代理反馈引擎120的示例过程600b。过程600b开始于操作610,其中代理反馈引擎120从MDE 110a接收个体MLMC。在操作611,代理反馈引擎120基于个体MLMC中的信息从一组代理函数中选择一个或多个代理函数。在操作612,代理反馈引擎120使用所选择的一个或多个代理函数来确定和/或生成与个体MLMC相对应的ML模型的代理得分。在操作613,代理反馈引擎120将所确定的代理得分提供给模型分析引擎140。在操作614,代理反馈引擎120从模型分析引擎140获得至少部分基于所确定的代理得分的、实际ML性能度量到ML模型的更新映射,以用于为其他MLMC(例如,这些其他MLMC可以由客户端设备101在未来提交,或者由操作其他客户端设备101的其他用户提交)生成额外的/更新的代理得分。在操作614之后,代理反馈引擎120循环回到操作610获得另一个MLMC。
当前描述的方法、系统和设备实施例的其他示例包括以下非限制性实现方式。以下非限制性示例中的每一个可独立存在,或者可与下文提供的或者贯穿本公开内容的其他示例中的任何一个或多个按任何排列或组合方式进行组合。
示例1包括一种用于为机器学习(ML)模型预测性能度量的方法,包括:为各个用户生成一组ML模型;对于所述一组ML模型中的每个ML模型,操作代理反馈引擎以为所述一组ML模型中的相应ML模型生成代理得分,其中,该相应ML模型的代理得分是基于该相应ML模型的一个或多个预测性能度量的;训练来自所述一组ML模型的ML模型的子集以为所述ML模型的子集中的相应ML模型获得一个或多个实际性能度量;操作半监督学习(SSL)机制以学习所述一个或多个实际性能度量与所述ML模型的子集中的相应ML模型之间的关系;并且利用学习到的关系更新所述代理反馈引擎来为另一组ML模型生成代理得分。
示例2包括如示例1和/或这里的某个(某些)其他示例所述的方法,其中,所述代理反馈引擎的操作是在不训练所述一组ML模型中的ML模型的情况下发生的。
示例3包括如示例1-2和/或这里的某个(某些)其他示例所述的方法,其中,操作所述代理反馈引擎包括:为所述一组ML模型中的第一ML模型从多个代理函数中选择第一代理函数;操作所述第一代理函数以为所述第一ML模型产生第一代理得分;为所述一组ML模型中的第二ML模型从多个代理函数中选择第二代理函数;并且操作所述第二代理函数以为所述第一ML模型产生第二代理得分。
示例4包括如示例1-3和/或这里的某个(某些)其他示例所述的方法,其中,操作所述代理反馈引擎包括:为所述一组ML模型中的至少一个ML模型从多个代理函数中选择两个或更多个代理函数;单独操作所述两个或更多个代理函数中的每一者以为所述至少一个ML模型产生对应代理得分;并且基于所述对应代理得分的组合、所述对应代理得分的加权平均、使用所述各个代理得分的集总平均或者使用基于所述各个代理得分的集总学习方法,为所述至少一个ML模型确定最终代理得分。
示例5包括如示例1-5和/或这里的某个(某些)其他示例所述的方法,其中,个体ML模型是基于由对应用户提供的一个或多个输入为该对应用户生成的。
示例6包括如示例5和/或这里的某个(某些)其他示例所述的方法,其中,由对应用户提供的一个或多个输入包括ML领域中的ML任务,并且其中,操作所述代理反馈引擎包括:为所述一组ML模型中的每个ML模型,基于由对应用户提供的ML任务和ML领域从多个代理函数中选择代理函数。
示例7包括如示例6和/或这里的某个(某些)其他示例所述的方法,其中,由对应用户提供的一个或多个输入还包括硬件平台规格,并且为每个ML模型选择代理函数还基于所述硬件平台规格。
示例8包括如示例3-7和/或这里的某个(某些)其他示例所述的方法,其中,所述多个代理函数包括以下各项中的一个或多个:关联阵列、映射函数、字典、散列表、查找表(LUT)、链接列表、ML分类器、参数计数、计算吞吐量度量、雅可比协方差函数、显著性修剪函数、通道修剪函数、试探函数、和超试探函数。
示例8.5包括如示例1-8和/或这里的某个(某些)其他示例所述的方法,其中,操作所述SSL机制包括:利用实际性能度量的标记数据集训练预测器;在未标记性能度量上操作经训练的预测器以生成伪标记的性能度量数据集;并且在所述伪标记的性能度量数据集上重训练所述预测器。
示例9包括如示例1-8.5和/或这里的某个(某些)其他示例所述的方法,其中,所述SSL机制包括归纳SSL方法或者直推SSL方法。
示例10包括如示例1-9和/或这里的某个(某些)其他示例所述的方法,其中,所述SSL机制包括从包括以下各项的群组中选择的SSL方法:自我训练包装方法、共同训练包装方法、提升包装方法、无监督预处理特征提取方法、无监督预处理预训练方法、无监督预处理聚类然后标记方法、以及内在半监督方法、图卷积网络(GCN)、以及直推式支持向量机(TSVM)。
示例11包括一种用于提供机器学习模型开发环境(MDE)的方法,该方法包括:从客户端设备获得机器学习(ML)输入;并且响应于从所述客户端设备接收到所述ML输入中的个体输入:基于所述个体输入获得ML模型,从代理反馈引擎为所述ML模型获得代理得分,其中,所述ML模型的代理得分是基于所述ML模型的一组预测性能度量的,所述ML模型和所述代理得分中的至少一者被半监督学习(SSL)机制用来学习实际性能度量和经训练的ML模型之间的关系,并且学习到的关系被所述代理反馈引擎用来为其他ML模型生成代理得分,并且经由接口电路将所述ML模型和所述代理得分提供给所述客户端设备。
示例12包括如示例11和/或这里的某个(某些)其他示例所述的方法,还包括:操作服务器侧MDE应用来使得能够从所述客户端设备接收所述ML输入;并且提供所述ML模型和所述代理得分以在客户端侧MDE应用内渲染。
示例13包括如示例12和/或这里的某个(某些)其他示例所述的方法,还包括:响应于从所述客户端设备接收到所述ML输入中的个体输入,从ML操作库获得与所述ML模型兼容的一组ML操作;并且经由所述接口电路提供所述一组ML操作来在所述客户端侧MDE应用内进行渲染。
示例14包括如示例11-13和/或这里的某个(某些)其他示例所述的方法,其中,所述ML输入包括ML任务和ML领域,并且被所述代理反馈引擎用来产生所述代理得分的代理函数是基于所述ML任务和所述ML领域的。
示例15包括如示例14和/或这里的某个(某些)其他示例所述的方法,其中,所述ML输入还包括硬件平台规格,并且被所述代理反馈引擎使用的所述代理函数还基于所述硬件平台规格。
示例16包括如示例11-15和/或这里的某个(某些)其他示例所述的方法,还包括:从所述客户端设备获得训练命令;基于接收到所述训练命令,将所述ML模型提供给训练和验证引擎以训练所述ML模型;并且在所述ML模型的训练完成之后将所述ML模型的完全训练的版本提供给所述客户端设备。
示例17包括一种操作机器学习(ML)工程系统的代理反馈引擎的方法,该方法包括:经由ML模型开发环境(MDE)获得ML模型配置(MLMC);基于个体MLMC中的信息从一组代理函数中选择一个或多个代理函数;利用所选择的一个或多个代理函数为与所述个体MLMC相对应的ML模型确定代理得分,其中,所述代理得分是基于所述ML模型的一组预测性能度量的;经由接口电路将所确定的代理得分提供给模型分析引擎;并且从所述模型分析引擎获得至少部分基于所确定的代理得分的实际ML性能度量到ML模型的更新后映射,以为其他MLMC生成代理得分。
示例18包括如示例17和/或这里的某个(某些)其他示例所述的方法,其中,所述个体MLMC包括ML任务和ML领域,并且对所述代理函数的选择是基于所述ML任务和所述ML领域的。
示例19包括如示例18和/或这里的某个(某些)其他示例所述的方法,其中,所述代理得分包括ML模型性能分量,该ML模型性能分量包括与所述ML模型的操作有关的一个或多个预测性能度量。
示例20包括如示例19和/或这里的某个(某些)其他示例所述的方法,其中,所述ML模型性能分量的一个或多个预测性能度量包括以下各项中的一个或多个:准确度、精度、阴性预测值(NPV)、召回、特异性、假阳性率、假阴性率、F得分、标记度、接收者操作特性(ROC)、ROC曲线下的面积(AUC)、误差值、平均绝对误差(MAE)、平均倒数排名(MRR)、均方误差(MSE)、根MSE(RMSE)、相关系数(R)、确定系数(R
示例21包括如示例18-20和/或这里的某个(某些)其他示例所述的方法,其中,所述个体MLMC还包括硬件平台规格,并且对所述代理函数的选择还基于所述硬件平台规格。
示例22包括如示例21和/或这里的某个(某些)其他示例所述的方法,其中,所述代理得分包括平台性能分量,该ML模型性能分量包括要操作所述ML模型的硬件平台的一个或多个预测性能度量。
示例23包括如示例22和/或这里的某个(某些)其他示例所述的方法,其中,所述平台性能分量的一个或多个预测性能度量包括以下各项中的一个或多个:延时,吞吐量,功率消耗,执行时间,存储器占用,存储器利用率,处理器利用率,处理器时间,计算数目,每秒指令(IPS),以及每秒浮点运算(FLOPS)。
示例24包括如示例17和/或这里的某个(某些)其他示例所述的方法,还包括:从所述一组代理函数中选择至少两个代理函数;单独操作所述至少两个代理函数中的每一者以为所述个体MLMC产生对应代理得分;并且基于所述对应代理得分的组合、所述对应代理得分的加权平均、使用所述对应代理得分的集总平均或者使用基于所述对应代理得分的集总学习方法,为所述个体MLMC确定最终代理得分。
示例25包括如示例17和/或这里的某个(某些)其他示例所述的方法,其中,所述多个代理函数包括以下各项中的一个或多个:关联阵列、映射函数、字典、散列表、查找表(LUT)、链接列表、ML分类器、参数计数、计算吞吐量度量、雅可比协方差函数、显著性修剪函数、通道修剪函数、试探函数、和超试探函数。
示例Z01包括一个或多个计算机可读介质,包括指令,其中,所述指令被处理器电路执行将使得所述处理器电路执行如示例1-25和/或本文论述的任何其他方面中的任何一者所述的方法。示例Z02包括一种计算机程序,其中包括如示例Z01所述的指令。示例Z03包括一种应用编程接口,其定义用于如示例Z02所述的计算机程序的函数、方法、变量、数据结构和/或协议。示例Z04包括一种装置,其包括加载有如示例Z01所述的指令的电路。示例Z05包括一种装置,其包括可操作来运行如示例Z01所述的指令的电路。示例Z06包括一种集成电路,其包括如示例Z01所述的处理器电路和如示例Z01所述的一个或多个计算机可读介质中的一个或多个。示例Z07包括一种计算系统,其包括如示例Z01所述的一个或多个计算机可读介质和处理器电路。示例Z08包括一种装置,其包括用于执行如示例Z01所述的指令的组件。示例Z09包括一种信号,它是由于执行如示例Z01所述的指令而生成的。示例Z10包括一种数据单元,它是由于执行如示例Z01所述的指令而生成的。示例Z11包括如示例Z10所述的数据单元,所述数据单元是数据报、网络封包、数据帧、数据段、协议数据单元(PDU)、服务数据单元(SDU)、消息、或者数据对象。示例Z12包括用如示例Z10或Z11所述的数据单元编码的信号。示例Z13包括一种电磁信号,其携带如示例Z01所述的指令。示例Z14包括一种装置,其包括用于执行如示例1-25中的任何一者所述的方法的组件。
术语
如本文所使用的,单数形式“一”、“一个”和“该”打算也包括复数形式,除非上下文明确地另有指示。还要理解,术语“包括”当在本说明书中被使用时指明了所记述的特征、整数、步骤、操作、元素和/或组件的存在,但并不排除一个或多个其他特征、整数、步骤、操作、元素、组件和/或其群组的存在或添加。短语“A和/或B”的意思是(A)、(B)或者(A和B)。就本公开的目的而言,短语“A、B和/或C”的意思是(A)、(B)、(C)、(A和B)、(A和C)、(B和C)或者(A、B和C)。描述可以使用短语“在一实施例中”或者“在一些实施例中”,其每一者可以指一个或多个相同或不同的实施例。此外,对于本公开使用的术语“包括”、“包含”、“具有”等等,是同义的。
本文使用了术语“耦合”、“通信地耦合”及其衍生词。术语“耦合”可以意指两个或更多个元素与彼此发生直接物理或电接触,可以意指两个或更多个元素与彼此间接接触,但仍与彼此合作或交互,和/或可以意指一个或多个其他元素耦合或连接在据称与彼此耦合的元素之间。术语“直接耦合”可以意指两个或更多个元素与彼此直接接触。术语“通信地耦合”可以意指两个或多个元素通过通信手段与彼此接触,包括通过导线或其他互连连接,通过无线通信信道或链路,等等。
术语“建立”(动词或名词形式)至少在一些实施例中是指(部分或全部)与主动或被动地使某事物成立或者使其准备好成立(例如,暴露设备身份或者实体身份)有关的行为、任务、操作,等等。额外地或者替代地,术语“建立”(动词或名词形式)至少在一些实施例中是指(部分或全部)与启动、开始或者预热通信或者启动、开始或者预热两个实体或元素之间的关系(例如,建立会话、建立会话,等等)有关的行为、任务、操作,等等。额外地或者替代地,术语“建立”(动词或名词形式)至少在一些实施例中是指启动某事物到工作准备就绪的状态。术语“建立的”至少在一些实施例中是指正在运作或者准备好使用的状态(例如,完全建立)。此外,在任何规范或标准中定义的术语“建立”的任何定义都可用于本公开的目的,并且这种定义不被上述任何定义所否定。
术语“获得”至少在一些实施例中是指(部分或全部)对原始封包流或者封包流的拷贝(例如,新的实例)(例如,从存储器、接口或者缓冲器)进行拦截、移动、拷贝、取回或者获取的行为、任务、操作,等等。获得或接收的其他方面可涉及实例化、启用或者控制获得或接收封包流(或者以下参数和模板或者模板值)的能力。
术语“元素”至少在一些实施例中是指在给定的抽象水平上不可分割并且具有明确定义的边界的单元,其中元素可以是任何类型的实体,包括例如一个或多个设备、系统、控制器、网络元件、模块,等等,或者这些的组合。
术语“测量”至少在一些实施例中是指对物体、事件或者现象的属性进行观察和/或量化。
术语“准确度”至少在一些实施例中是指一个或多个测量值与特定值的接近程度。术语“精度”至少在一些实施例中是指两个或更多个测量值彼此之间的接近程度。
术语“信号”至少在一些实施例中是指质量和/或数量的可观察的变化。额外地或者替代地,术语“信号”至少在一些实施例中是指传达关于物体、事件或现象的信息的功能。额外地或者替代地,术语“信号”至少在一些实施例中是指任何时间变化的电压、电流或电磁波,它可以携带或不携带信息。术语“数字信号”至少在一些实施例中是指一种信号,其由物理量的离散波形集合构成以便表示离散值的序列。
术语“电路”至少一些实施例中是指被配置为在电子设备中执行特定功能的电路或多个电路的系统。电路或电路系统可以是一个或多个硬件组件的一部分,或者包括一个或多个硬件组件,例如逻辑电路、处理器(共享的、专用的或群组的)和/或存储器(共享的、专用的或群组的)、ASIC、FPGA、可编程逻辑控制器(programmable logic controller,PLC)、SoC、SiP、多芯片封装(Multi-Chip Package,MCP)、DSP,等等,它们被配置为提供所描述的功能。此外,术语“电路”也可以指一个或多个硬件元素与程序代码的组合,用于执行该程序代码的功能。一些类型的电路可以执行一个或多个软件或固件程序来提供所描述的功能中的至少一些。硬件元素和程序代码的这种组合可被称为特定类型的电路。
应当理解,本说明书中描述的功能单元或能力可能已被称为或标记为组件或模块,以便更具体地强调其实现独立性。这样的组件可以由任意数目的软件或硬件形式来体现。例如,组件或模块可被实现为硬件电路,包括定制超大规模集成(very-large-scaleintegration,VLSI)电路或门阵列,诸如逻辑芯片晶体管、或者其他分立组件之类的现成半导体。组件或模块也可被实现在可编程硬件设备中,例如现场可编程门阵列、可编程阵列逻辑、可编程逻辑器件,等等。组件或模块也可被实现在软件中,供各种类型的处理器执行。所识别的可执行代码的组件或模块可例如包括计算机指令的一个或多个物理或逻辑块,它们可例如被组织为对象、过程或函数。然而,所识别的组件或模块的可执行文件不需要物理上位于一起,而是可包括存储在不同位置中的迥异指令,这些指令当在逻辑上被接合在一起时构成该组件或模块并且实现该组件或模块的声明用途。
实际上,可执行代码的组件或模块可以是单个指令,或者许多指令,并且甚至可分布在若干个不同的代码段上、分布在不同的程序间、以及分布在若干个存储器设备或处理系统上。具体地,所描述的过程的一些方面(例如代码重写和代码分析)可以在与部署代码的那个处理系统(例如,在嵌入在传感器或机器人中的计算机中)不同的处理系统(例如,在数据中心中的计算机中)上发生。类似地,操作数据在这里可在组件或模块内被识别和图示,并且可体现为任何适当的形式并且被组织在任何适当类型的数据结构内。操作数据可被聚集为单个数据集合,或者可分布在不同位置上,包括分布在不同存储设备上,并且可至少部分只作为系统或网络上的电子信号存在。组件或模块可以是被动的或者主动的,包括可操作来执行期望功能的代理。
术语“处理器电路”至少在一些实施例中是指如下的电路、是如下电路的一部分或者包括如下的电路:该电路能够顺序地且自动地执行算术或逻辑运算的序列,或者记录、存储和/或传送数字数据。术语“处理器电路”至少在一些实施例中是指一个或多个应用处理器、一个或多个基带处理器、物理CPU、单核处理器、双核处理器、三核处理器、四核处理器、和/或任何其他能够执行或以其他方式操作诸如程序代码、软件模块和/或功能过程之类的计算机可执行指令的设备。术语“应用电路”和/或“基带电路”可被认为与“处理器电路”同义,并且可被称为“处理器电路”。
术语“存储器”和/或“存储器电路”至少在一些实施例中是指用于存储数据的一个或多个硬件设备,包括RAM、MRAM、PRAM、DRAM和/或SDRAM、核心存储器、ROM、磁盘存储介质、光存储介质、闪存设备或者其他用于存储数据的机器可读介质。术语“计算机可读介质”可包括但不限于存储器、便携式或者固定式存储设备、光存储设备、以及能够存储、包含或者携带指令或数据的各种其他介质。
术语“接口电路”至少在一些实施例中是指使能实现两个或更多个组件或设备之间的信息交换的电路、是这种电路的一部分或者包括这种电路。术语“接口电路”至少在一些实施例中是指一个或多个硬件接口,例如,总线、I/O接口、外围组件接口、网络接口卡,等等。
术语“设备”至少在一些实施例中是指这样一种物理实体:其嵌入在其附近的另一物理实体内或者附着到其上,具有从该物理实体或者向该物理实体传达数字信息的能力。
术语“实体”至少在一些实施例中是指体系结构或设备的独特组件,或者作为有效载荷传送的信息。
术语“控制器”至少在一些实施例中是指有能力影响物理实体的元素或实体,例如通过改变其状态或者使得物理实体移动。
术语“计算节点”或“计算设备”至少在一些实施例中是指实现计算操作的一方面的可识别的实体,无论是更大系统的一部分、系统的分布式集合,还是独立的装置。在一些示例中,计算节点可被称为“计算设备”、“计算系统”之类的,不管是作为客户端、服务器还是中间实体在操作。计算节点的具体实现方式可以被包含到服务器、基站、网关、路边单元、场内单元、用户设备(user equipment,UE)、最终消费设备、器具等等中。
术语“计算机系统”至少在一些实施例中是指任何类型的互连电子设备、计算机设备或者其组件。此外,术语“计算机系统”和/或“系统”至少在一些实施例中是指计算机的与彼此通信地耦合的各种组件。此外,术语“计算机系统”和/或“系统”至少在一些实施例中是指与彼此通信地耦合并且被配置为共享计算和/或联网资源的多个计算机设备和/或多个计算系统。
术语“体系结构”至少在一些实施例中是指计算机体系结构或网络体系结构。“计算机体系结构”是计算系统或平台中的软件和/或硬件元素的物理和逻辑设计或布置,包括用于其间的交互的技术标准。“网络体系结构”是网络中的软件和/或硬件元素的物理和逻辑设计或布置,包括通信协议、接口和媒体传输。
术语“器具”(appliance)、“计算机器具”之类的至少在一些实施例中是指具有被具体设计为提供特定计算资源的程序代码(例如,软件或固件)的计算机设备或计算机系统。“虚拟器具”是要由虚拟化或模拟计算机器具或者以其他方式专用于提供特定计算资源的配备有超级监督者的设备实现的虚拟机器映像。
术语“用户设备”或“UE”至少在一些实施例中是指具有无线电通信能力的设备并且可以描述通信网络中的网络资源的远程用户。术语“用户设备”或“UE”可被认为与以下术语同义,并且可被称为以下术语:客户端、移动电话、移动设备、移动终端、用户终端、移动单元、台站、移动台、移动用户、订户、用户、远程站、接入代理、用户代理、接收器、无线电设备、可重配置无线电设备、可重配置移动设备,等等。另外,术语“用户设备”或“UE”可包括任何类型的无线/有线设备或者包括无线通信接口的任何计算设备。UE、客户端设备等等的示例包括桌面型计算机、工作站、膝上型计算机、移动数据终端、智能电话、平板计算机、可穿戴设备、机器对机器(machine-to-machine,M2M)设备、机器类型通信(machine-typecommunication,MTC)设备、物联网(Internet of Things,IoT)设备、嵌入式系统、传感器、自主车辆、无人机、机器人、车内信息娱乐系统、仪表组、车载诊断设备、仪表盘移动设备、电子引擎管理系统、电子/引擎控制单元/模块、微控制器、控制模块、服务器设备、网络器具、抬头显示(head-up display,HUD)设备、头盔安装显示设备、增强现实(augmentedreality,AR)设备、虚拟现实(virtual reality,VR)设备、混合现实(mixed reality,MR)设备、和/或其他类似系统或设备。
术语“网络元件”至少在一些实施例中是指用于提供有线或无线通信网络服务的物理或虚拟化设备和/或基础设施。术语“网络元件”可被认为与以下术语同义和/或被称为以下术语:联网计算机、联网硬件、网络设备、网络节点、路由器、交换机、集线器、网桥、无线电网络控制器、网络接入节点(network access node,NAN)、基站、接入点(access point,AP)、RAN设备、RAN节点、网关、服务器、网络器具、网络功能(network function,NF)、虚拟化VNF(virtualized NF,VNF),等等。
术语“应用”至少在一些实施例中是指这样的计算机程序:该计算机程序被设计为执行特定任务,而不是与计算机本身的操作有关的任务。额外地或者替代地,术语“应用”至少在一些实施例中是指一种完整的、可部署的封装环境,用来在操作环境中实现某种功能。
术语“算法”至少在一些实施例中是指对如何通过执行计算、输入/输出操作、数据处理、自动化推理任务等等来解决一个问题或者一类问题的明确规范。
术语“实例化”(动词或名词形式)之类的至少在一些实施例中是指实例的创建。“实例”至少在一些实施例中也指的是对象的具体发生,这可例如发生在程序代码的执行期间。
术语“引用”至少在一些实施例中是指可用于定位其他数据的数据,并且可通过各种方式实现(例如,指针、索引、句柄、键、标识符、超链接,等等)。
术语“人工智能”或“AI”至少在一些实施例中是指机器所表现出的任何智能,这与人类和其他动物所展示的自然智能不同。额外地或者替代地,术语“人工智能”或“AI”至少在一些实施例中是指对“智能代理”和/或感知其环境并且采取使得其成功实现目标的机会最大化的动作的任何设备的研究。
术语“智能代理”至少在一些实施例中是指一种软件代理或其他自主实体,它作出行动,利用通过传感器进行的观察和随之而来的致动器,在环境上指导其活动以实现目标(即,它是智能的)。智能代理也可以学习或者使用知识来实现其目标。
术语“优化”至少在一些实施例中是指使得某事物(例如,设计、系统或决策)尽可能地完全完美、实用或有效的动作、过程或方法。优化通常包括数学过程,例如找到函数的最大或最小值。术语“最优”至少在一些实施例中是指最合乎需要或者最令人满意的结局、结果或者输出。术语“最佳”至少在一些实施例中是指对某种结局最有利的数量或程度的事物。术语“最佳状态(optima)”至少在一些实施例中是指产生最佳可能结果的条件、程度、数量或者折中。额外地或者替代地,术语“最佳状态”至少在一些实施例中是指最良好的或有利的成果或结果。
术语“集总平均”至少在一些实施例中是指创建多个模型(或者多个代理函数)并且将其组合起来以产生期望输出的过程,而不是只创建一个模型。术语“集总学习”或“集总方法”至少在一些实施例中是指使用多个学习算法(或者多个代理函数)来获得比单独使用任何组成学习算法所能获得的更好的预测性能。
术语“协方差”至少在一些实施例中是指对两个随机变量的联合可变性的测量,其中,如果一个变量的较大值主要与另一个变量的较大值相对应,则协方差为正值(对于较小的值也同样成立,从而使得变量倾向于显示出相似的行为),而当一个变量的较大值主要与另一个变量的较小值相对应时,协方差为负值。
术语“关系”至少在一些实施例中是指两个或更多个概念、对象、元素等等相互连接的方式。额外地或者替代地,术语“关系”至少在一些实施例中是指一种数据结构,它包括一组属性和一组共享相同(数据)类型的元组。
术语“映射”(动词或名词形式)至少在一些实施例中是指包括一个或多个属性-值对(attribute-value pair,AVP)、键-值对(key-value pair,KVP)、元组和/或其他类似的数据表示的数据项或数据结构。“映射”可以采取如下形式:关联阵列、符号表、字典、映射函数、散列表、查找表、链接列表、搜索树、数据库对象(例如,数据库记录、数据库字段、属性、数据和/或数据库实体之间的关联(也称为“关系”),等等)、区块链实现方式中的区块和/或区块之间的链接、和/或一些其他适当的数据结构。
虽然已参考具体的示范性方面描述了这些实现方式,但将会明白,在不脱离本公开的更宽范围的情况下,可对这些方面做出各种修改和改变。本文描述的许多布置和过程可以被组合使用或者在并行实现方式中使用来提供更好的带宽/吞吐量以及支持可提供给被服务的边缘系统的边缘服务选择。因此,说明书和附图应被认为是说明性的,而不是限制性的。形成本文一部分的附图以图示而非限制方式示出了其中可实现主题的具体方面。图示的方面被充分详细地描述以使得本领域技术人员能够实现本文公开的教导。可从其利用和得出其他方面,从而可在不脱离本公开的范围的情况下做出结构上和逻辑上的替代和改变。这个具体实施方式部分因此不应当被从限制意义上来理解,而各种方面的范围仅由所附权利要求以及这种权利要求被授权的完全等同范围来限定。
发明性主题的这种方面在本文中可被单独和/或集体地提及,这只是为了方便,而并不打算主动将本申请的范围限制到任何单个方面或发明构思,如果实际上公开了多于一个方面或发明构思的话。从而,虽然本文已图示和描述了具体方面,但应当明白,任何经计算实现相同目的的布置都可替代所示出的具体方面。本公开打算覆盖各种方面的任何和所有适应性改变或变化。本领域技术人员在阅读以上描述后将清楚上述方面以及本文没有具体描述的其他方面的组合。
- 基于深度自编码神经网络模型的网络安全态势评估方法
- 基于EM的图像分类深度神经网络模型鲁棒性评估方法