一种基于注意力机制的实时手部追踪方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及计算机技术领域,具体为一种基于注意力机制的实时手部追踪方法。
背景技术
虚拟现实VR((Virtual Reality)和增强现实AR(Augmented Reality)技术是近年来新兴的多媒体技术。虚拟现实技术是一种可以创建和体验虚拟世界的计算机仿真系统,增强现实技术是一种可以将虚拟现实和真实世界叠加并进行互动的技术。在VR或AR场景中,裸手交互为用户提供在VR/AR场景中的娱乐、社交和工作等提供极佳的使用体验。
现有技术中,依赖深度摄像头/sensor,毫米波等价格高的设备追踪手势,成本大,应用于头戴式虚拟现实/增强现实设备极大增加硬件成本,使得价格偏高;依赖通用注意力卷积网络,虽然对双手接近/交叉时的手势追踪有较好准确度,但是延迟大,无法应用在主流移动端头戴式虚拟现实/增强现实设备中。
所以我们提出了一种基于注意力机制的实时手部追踪方法,以便于解决上述中提出的问题。
发明内容
本发明的目的在于提供一种基于注意力机制的实时手部追踪方法,以解决上述背景技术提出的目前市场上的问题。
为实现上述目的,本发明提供如下技术方案:一种基于注意力机制的实时手部追踪方法,包括以下步骤:
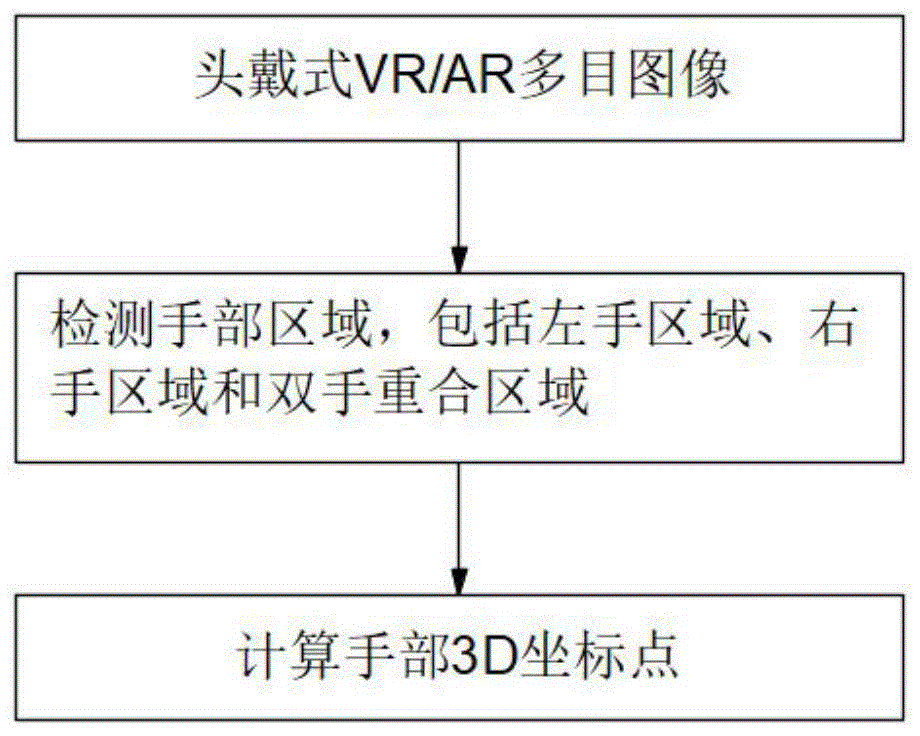
S1:可视化设备多目图像
S2:检测手部区域,包括左手区域、右手区域和双手重合区域
基于卷积神经网络CNN,自注意力融合模块把特征提取器提取的图片特征A1做特征还原和增强,还原被遮挡的双手的特征,增强没有被遮挡的单手的特征和还原特征的融合,使得经过自注意力融合模块的特征具有没有被遮挡的手的特征和被遮挡的手的特征,并且将这两种特征经过融合,得到全部手的特征;
自注意力融合过程为:
S21:使用卷积神经网络CNN,例如mobilenet/shufflenet作为特征提取器,将2D图片编码成10x10x512向量A;
S22:使用注意力机制,将S21中输出10x10x512向量A乘以自身注意力10x10x512向量B得到融合后的自注意力10x10x512向量C,具体方法为:
S221:将10x10x512的向量A转换为100x 512的向量A1;
S222:将100x 512的向量A1转置得到512x100的向量A2;
S223:将向量A2通过全连接神经网络MLP卷积转换为512x10的向量AK1,全连接神经网络MLP卷积的参数为100x10;
S224:将向量A2通过全连接神经网络MLP卷积转换为512x10的向量AP1,全连接神经网络MLP卷积的参数为100x10;
S225:将向量A1通过全连接神经网络MLP卷积转换为100x512的向量AQ1,全连接神经网络MLP卷积的参数为100x512;
S226:将向量AK1和向量AP1点乘得到512x10的向量AKP;
S227:将向量AKP经过softmax计算得到512x10向量B;
S228:将向量B和向量AQ1数乘得到100x512的向量ABQ;
S229:将向量ABQ转换成10x10x512的向量C;
S23:使用卷积神经网络CNN,解码器将S22的输出解码成1x7向量D,D由x,y,w,h,c1,c2,c3构成,其中,x,y表示BBOX中心点坐标,w,h表示长宽,c1表示左手,c2表示右手,c3表示分别表示双手接近/交叉的得分;
S24:使用S23的输出D,将头戴式VR/AR多目图像截取BBOX的图像,并且转换为大小128x128的图像IM;计算c1、c2和c3的最大值,若最大值为c1,那么IM类别为IMC=1,代表左手,若最大值为c2,那么IM类别为IMC=2,代表右手,若最大值为c3,那么IM类别为IMC=3,代表双手交叉/接近;
S3:计算手部3D坐标点
S31:使用卷积神经网络CNN,将S2的输出128x128x1向量IM转换为64x64x32的向量E,卷积的参数为4x4x32;
S32:使用注意力机制,将S31的输出转换为16x16x32的向量F,若IMC=1或IMC=2时,进入S33中单手自注意力计算,若IMC=3时,进入S34双手自注意力计算,S32中的注意力机制和S22注意力机制原理一样;
S33:单手自注意力计算,将S32的输出转换为256x32的向量HL或256x32的向量HR;S53的注意力机制和S22的注意力机制原理一样;
S34:双手自注意力计算,将S32的输出转换为256x32的向量HL和256x32的向量HR,具体计算方法为:
S341:将S32的输出转换为256x32的向量S2;
S342:将向量S2通过全连接神经网络MLP卷积转换为256x32的向量HL1,全连接神经网络MLP卷积的参数为32x32;
S343:将向量S2通过全连接神经网络MLP卷积转换为256x32的向量HR1,全连接神经网络MLP卷积的参数为32x32;
S344:将向量HL1转置为32x256的向量HL2;
S345:将向量HR1转置为32x256的向量HR2;
S346:将向量HL2通过全连接神经网络MLP卷积转换为32x16的向量HLK,全连接神经网络MLP卷积的参数为32x16;
S347:将向量HL2通过全连接神经网络MLP卷积转换为32x16的向量HLP,全连接神经网络MLP卷积的参数为32x16;
S348:将向量HL2通过全连接神经网络MLP卷积转换为32x256的向量HLQ,全连接神经网络MLP卷积的参数为32x256;
S349:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRK,全连接神经网络MLP卷积的参数为32x16;
S3410:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRP,全连接神经网络MLP卷积的参数为32x16;
S3411:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRQ,全连接神经网络MLP卷积的参数为32x256;
S3412:将向量HLK和HKP点乘得到向量HLKP;
S3413:将向量HRK和HRP点乘得到向量HRKP;
S3414:将向量HLKP经过softmax计算得到32x1向量HLB;
S3415:将向量HRKP经过softmax计算得到32x1向量HRB;
S3416:将向量HLB和向量HRQ数乘得到的32x256向量HLS;
S3417:将向量HRB和向量HLQ数乘得到的32x256向量HRS;
S3418:将向量HLS转置得到向量256x32,然后转换成16x16x32的向量HL;
S3419:将向量HRS转置得到向量256x32,然后转换成16x16x32的向量HR;
S35:将S3得到输出向量单手HL、向量单手HR、双手交叉/接近HL或双手交叉/接近HR通过多层全连接神经网络MLP/神经网络GCN得到左手或右手的单手3D关键点坐标(N,x,y,z)或双手关键点坐标(N,x,y,z);
S36:训练模型
S361:初始化网络参数
随机初始化S2、S3和S4步骤中全连接神经网络MLP/神经网络GCN和卷积神经网络CNN的网络参数,即这些网络的参数取值为随机;
S362:梯度下降训练
每一次训练时计算每一个样本和目标的误差梯度,其中步骤S2中网络为训练过程1,其目标为标注好的手的可视化设备和类别,其中S3和S4中网络为训练过程2,其目标为标好的左右手的3D关键点坐标;
S363:训练截止
每次数据集所有样本经过一次完整训练后,得到数据集中所有样本的平均分数,当第N次和第N+1次训练之后,所得数据集的平均分数均大于95分,并且保持不变后,即停止训练,停止更新网络参数。优选的,所述。
优选的,所述S1中可视化设备包括但不限于头戴式AR/VR眼镜、网络电视、PC屏幕、XBOX、手机、车载屏幕。
与现有技术相比,本发明的有益效果是:
本发明一种基于注意力机制的实时手部追踪方法,提高单手,双手重合两种情况的跟踪和识别的准确率;灵活切换单手,双手重合两种情况的跟踪和识别;降低双手重合最新技术方案(注意力机制技术方案)的功耗,计算量和延迟,使得可以在现有的可视化设备上实时跑起来。
说明书附图
图1为本发明一种基于注意力机制的实时手部追踪方法整体流程图;
图2为本发明自注意力融合流程图;
图3为本发明S3计算手部3D坐标点流程图;
图4为本发明双手跨注意力计算流程图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明提供一种技术方案:一种基于注意力机制的实时手部追踪方法,包括以下步骤:
S1:可视化设备多目图像
可视化设备包括但不限于头戴式AR/VR眼镜、网络电视、PC屏幕、XBOX、手机、车载屏幕等;
S2:检测手部区域,包括左手区域、右手区域和双手重合区域
基于卷积神经网络CNN,自注意力融合模块把特征提取器提取的图片特征A1做特征还原和增强,还原被遮挡的双手的特征,增强没有被遮挡的单手的特征和还原特征的融合,使得经过自注意力融合模块的特征具有没有被遮挡的手的特征和被遮挡的手的特征,并且将这两种特征经过融合,得到全部手的特征,从而提高手的检测的准确率,尤其是提高手被遮挡情况下的检测准确率。
自注意力融合过程为:
S21:使用卷积神经网络CNN,例如mobilenet/shufflenet作为特征提取器,将2D图片编码成10x10x512向量A;
S22:使用注意力机制,将S21中输出10x10x512向量A乘以自身注意力10x10x512向量B得到融合后的自注意力10x10x512向量C,具体方法为:
S221:将10x10x512的向量A转换为100x 512的向量A1;
S222:将100x 512的向量A1转置得到512x100的向量A2;
S223:将向量A2通过全连接神经网络MLP卷积转换为512x10的向量AK1,全连接神经网络MLP卷积的参数为100x10;
S224:将向量A2通过全连接神经网络MLP卷积转换为512x10的向量AP1,全连接神经网络MLP卷积的参数为100x10;
S225:将向量A1通过全连接神经网络MLP卷积转换为100x512的向量AQ1,全连接神经网络MLP卷积的参数为100x512;
S226:将向量AK1和向量AP1点乘得到512x10的向量AKP;
S227:将向量AKP经过softmax计算得到512x10向量B;
S228:将向量B和向量AQ1数乘得到100x512的向量ABQ;
S229:将向量ABQ转换成10x10x512的向量C;
S23:使用卷积神经网络CNN,解码器将S22的输出解码成1x7向量D,D由x,y,w,h,c1,c2,c3构成,其中,x,y表示可视化设备中心点坐标,w,h表示长宽,c1表示左手,c2表示右手,c3表示分别表示双手接近/交叉的得分;
S24:使用S23的输出D,将头戴式VR/AR多目图像截取BBOX的图像,并且转换为大小128x128的图像IM;计算c1、c2和c3的最大值,若最大值为c1,那么IM类别为IMC=1,代表左手,若最大值为c2,那么IM类别为IMC=2,代表右手,若最大值为c3,那么IM类别为IMC=3,代表双手交叉/接近;
S3:计算手部3D坐标点
单手注意力融合模块把特征提取器提取的图片特征做特征还原和增强,还原被物体遮挡的单手的特征,增强没有被遮挡的单手的特征和还原特征的融合,使得经过此模块的特征具有没有被遮挡的手的特征和被遮挡的手的特征,并且将这两种特征经过融合,得到全部手的特征,从而提高手的关键点检测的准确率,尤其是提高手被遮挡情况下的检测准确率;
S31:使用卷积神经网络CNN,将S2的输出128x128x1向量IM转换为64x64x32的向量E,卷积的参数为4x4x32;
S32:使用注意力机制,将S31的输出转换为16x16x32的向量F,若IMC=1或IMC=2时,进入S33中单手自注意力计算,若IMC=3时,进入S34双手自注意力计算,S32中的注意力机制和S22注意力机制原理一样;
S33:单手自注意力计算,将S32的输出转换为256x32的向量HL或256x32的向量HR;S53的注意力机制和S22的注意力机制原理一样;
S34:双手自注意力计算,将S32的输出转换为256x32的向量HL和256x32的向量HR,具体计算方法为:
S341:将S32的输出转换为256x32的向量S2;
S342:将向量S2通过全连接神经网络MLP卷积转换为256x32的向量HL1,全连接神经网络MLP卷积的参数为32x32;
S343:将向量S2通过全连接神经网络MLP卷积转换为256x32的向量HR1,全连接神经网络MLP卷积的参数为32x32;
S344:将向量HL1转置为32x256的向量HL2;
S345:将向量HR1转置为32x256的向量HR2;
S346:将向量HL2通过全连接神经网络MLP卷积转换为32x16的向量HLK,全连接神经网络MLP卷积的参数为32x16;
S347:将向量HL2通过全连接神经网络MLP卷积转换为32x16的向量HLP,全连接神经网络MLP卷积的参数为32x16;
S348:将向量HL2通过全连接神经网络MLP卷积转换为32x256的向量HLQ,全连接神经网络MLP卷积的参数为32x256;
S349:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRK,全连接神经网络MLP卷积的参数为32x16;
S3410:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRP,全连接神经网络MLP卷积的参数为32x16;
S3411:将向量HR2通过全连接神经网络MLP卷积转换为32x16的向量HRQ,全连接神经网络MLP卷积的参数为32x256;
S3412:将向量HLK和HKP点乘得到向量HLKP;
S3413:将向量HRK和HRP点乘得到向量HRKP;
S3414:将向量HLKP经过softmax计算得到32x1向量HLB;
S3415:将向量HRKP经过softmax计算得到32x1向量HRB;
S3416:将向量HLB和向量HRQ数乘得到的32x256向量HLS;
S3417:将向量HRB和向量HLQ数乘得到的32x256向量HRS;
S3418:将向量HLS转置得到向量256x32,然后转换成16x16x32的向量HL;
S3419:将向量HRS转置得到向量256x32,然后转换成16x16x32的向量HR;
S35:将S3得到输出向量单手HL、向量单手HR、双手交叉/接近HL或双手交叉/接近HR通过多层全连接神经网络MLP/神经网络GCN得到左手或右手的单手3D关键点坐标(N,x,y,z)或双手关键点坐标(N,x,y,z),N通常取值21,778等。
S36:训练模型
S361:初始化网络参数
随机初始化S2、S3和S4步骤中全连接神经网络MLP/神经网络GCN和卷积神经网络CNN的网络参数,即这些网络的参数取值为随机;
S362:梯度下降训练
每一次训练时计算每一个样本和目标的误差梯度,其中步骤S2中网络为训练过程1,其目标为标注好的手的可视化设备和类别,其中S3和S4中网络为训练过程2,其目标为标好的左右手的3D关键点坐标;
S363:训练截止
每次数据集所有样本经过一次完整训练后,得到数据集中所有样本的平均分数,当第N次和第N+1次训练之后,所得数据集的平均分数均大于95分,并且保持不变后,即停止训练,停止更新网络参数。
本发明改进原有卷积神经网络CNN计算为左右双手自注意力计算,如图2所示,通过计算手的自注意力,还原出手遮挡/不可见部分的特征,跟踪不可见/遮挡的双手,提高不可见/遮挡双手的跟踪和识别准确率;计算手自注意力的简化注意力,降低注意力计算的功耗和计算量。
单手机双手注意力计算流程如图3所示,使用单手自注意力的计算提高单手情况下跟踪和识别的准确率;使用双手跨注意力的计算提高双手交叉情况下跟踪和识别的准确率;使得单手和双手交叉两种情况下的跟踪和识别的准确率提高,并且可以灵活切换单手,和双手交叉两种情况下的跟踪和识别。
双手跨注意力计算如图4所示,使用双手跨注意力的简化计算。
综上所述,本发明一种基于注意力机制的实时手部追踪方法,提高单手,双手重合两种情况的跟踪和识别的准确率;灵活切换单手,双手重合两种情况的跟踪和识别;降低双手重合最新技术方案(注意力机制技术方案)的功耗,计算量和延迟,使得可以在现有的可视化设备上实时跑起来。
尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于注意力机制的目标追踪方法
- 一种基于注意力机制的两阶段层位自动追踪方法及系统