层级可扩展的云网络流分析方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及网络流分析技术领域,具体地,涉及层级可扩展的云网络流分析方法及系统。
背景技术
网络流分析是网络分析管理中常用的手段。这种方法首先基于网络数据包(也称为“网络报文”或者“报文”)的五元组和其他所选字段,建立网络流(Flow)。然后按Flow,对数据包进行分组,基于Flow做个各种数据统计和分析。最后,按Flow,组织数据结构输出数据。常见的Netflow和Ipfix是这种技术的典型代表。
随着容器技术和云技术日趋成熟,被广泛采用,网络架构也日益复杂,出现了多层级(tier)网络,也就是基于底层网络(underlay网络)承载上层网络(overlay网络)的部署方式。underlay网络和overlay网络可以是完全不同的IP地址布局。常见的层级有物理网络、(软件定义的)虚拟机网络、(Kubernetes等技术构建的)容器网络等三个层级,所以有物理网络承载虚拟机网络、虚拟机网络承载容器网络、物理网络承载容器网络等不同的两层级或者三层级的承载方式。承载一般使用VXLAN、GRE、IPinIP等隧道技术来实现。如图1所示使用VXLAN隧道封装的数据包。其中内层(inner)“原始数据包”是被封装的数据包,也就是overlay网络数据包,外层(outer)VXLAN封装数据包是underlay网络数据包。使用不同的隧道技术,报文格式会有所不同,但同样都有内层overlay和外层underlay两个层级。这是一个两层级报文的例子,三层级就是在两层级报文上再封装一个层级。两层级或三层级方式主要在是一个数据中心内的部署方式。如果是“端边云”的复杂分布式环境,或者多地多中心环境,或者基于隧道的采集转发场景,那么层级可能还会增加。
传统的网络流分析方法,实际上是一种宽表的分析方法。宽表可以是扁平结构,使用Key和Value表示的字段集合,Netflow采用这种方式。宽表也可以是嵌套结构,譬如按协议来嵌套组织信息;但实际上,这种方法可以将嵌套结构展开为唯一的Key,譬如使用“.”来连接嵌套结构的字段名(Json Object的结构读取方式)。所以,两种结构实际上都是一系列字段的集合,而将嵌套结构展开的结构可以形象地称为“大宽表”。对于这些Flow的字段信息,虽然不同方法的表述可能不同,但实际都可以将其分为两类:
第一类:维度信息(Dimension),用于定义Flow和区别不同Flow的信息,包括(但不限于)五元组(IP地址、IP层协议、传输层端口)、VLAN ID、MPLS Tag、GRE Key、VXLAN、IPv4Tos、IPv6 Priority/Traffic class等。使用这些信息可以区分不同的TCP会话,或者区分不同的IP主机通信等。
第二类:度量信息(Measure),按Flow计算和统计获得的各种Flow的相关数据数值,譬如报文总数、字节总数、传输速率、交易量、响应率、成功率、响应时间等等。
网络流分析实际上就是按一组选定的Dimensions将数据包分组到不同的Flow中,然后计算和统计各种Measures。这组选定用于划分Flow的Dimens ions,称为Flow Key。
传统的网络流分析因为宽表设计,在云网络环境中有以下几个缺陷。
第一个缺陷是层级增加带来的扩展性问题。当使用两层级网络时,实际增加几乎一倍的Dimens ions(outer中基本的Dimensions都有了),增加了1/4~1/3的Measures(outer中没有TCP和TCP之上信息,只有相关协议的Measures)。如果增加层级时,Dimensions和Measures会进一步增加。需要指出的是,网络环境中的层级往往是不固定的,如果三层级网路,那么可能同时存在一个层级到三个层级的报文。这时候如何设计宽表存储Dimension和Measure是个巨大的挑战:如果按最大层级,设计包含所有Dimensions和Measures的“大宽表”,那么对于没达到最大层的报文来说,存在大量的空字段的浪费;如果只按一层级设计,那么没有明显浪费,但对于多层级报文,只能分析某一个层级的网络Flow,缺失其他层级的Flow。一种实际的方法是以最内层的Dimens ions和Measures为主,固定增加若干外层Dimens ions和Measures。如果没有外层,那么增加的存储为空字段。如果有外层,则处理外层的Dimensions和Measures。如果有多个外层,则按配置选某一层(譬如最外层,譬如最内的外层)做处理。显然这种方法是个例化的处理,没有通用性:对于Dimens ions和Measures都需要指定,而且不同层级的数据的计算和处理存在关联性。而对整个网络来说,underlay网络的Flow是大量缺失的,不能全面覆盖物理underlay网络和虚拟机underlay网络。
上述方法还有第二个缺陷,维度爆炸问题。Dimens ion区别于Measure的一个重要方面是:Dimension作为Flow的分组依据(Flow Key),实际决定了数据的存储量。每增加一个Dimension,实际上增加了更精细的数据视角,需要使用更多的宽表中的“行”来存储数据。譬如使用IP Pair(IP地址对)作为Flow来统计主机A和B之间的通信,那么只需要1行记录。但如果增加A的端口作为Flow Key的组成部分,而A有10个端口参与通信,那么就需要10行记录。如果再增加B的端口也作为Flow Key的组成部分,B也有10个端口参与,和A的10个端口进行交叉通讯,那么就需要100行记录了。由此可见,随着维度的增加,维度空间的规模(随着维度可取值的数量)呈指数增加,实际上就是维度的“笛卡尔积”。那么基于宽表设计,增加外层的若干Dimensions作为Flow Key的组成部分,产生数据行数将急剧膨胀。如果实际需要增加若个外层的若干Dimensions,那么内存开销和存储开销都将急剧上升。
是否能仅仅对最内层做Flow分析,而忽略各外层的维度来回避这个问题呢?实际在云网Flow分析中,答案是否定的。这是由于云网络尤其灵活和复杂,最需要分析的就是数据报文如何在不同层级的网络和网络设备间流转和传输,以监控各层级网络的运行状态,所以,云网Flow分析不但需要underlay的维度,而且最好是对每一层的underlay都做Flow分析。所以,因为扩展性问题和维度爆炸问题,
基于宽表设计的第三个缺陷是数据处理的复杂性问题。因为不同层级的数据存储在一行中,此时的Flow Key可以认为是跨层级的维度(Inter-tier Dimens ions)。但实际使用还是要回到不同的层级来分析数据,譬如分析三个层级(络物理网络、虚拟机网络,或者容器网络)网络中的某一个,也就是Inner-tier Dimensions。所以,在使用时,需要知道各层级的Inner-tier Dimensions,然后按Inner-tier Dimens ions先做一遍数据聚合,去掉其他层级的Dimens ions,再来使用。而如前文所述,传统Flow分析中,外层Dimension和Measure的选择时个性化,因此采集、计算和存储时的Inter-tier Dimens ions与(查询)使用时的Inner-tier Dimensions带来诸多额外的处理复杂性和特殊性,使得缺陷一更为明显:难以扩展和难以维护。
专利文献CN112272123B(申请号:202011112363.6)公开了一种网络流量分析方法。所述方法包括:接收批量的数据报文和批量需进行网络流量分析的五元组规则,其中,所述五元组规则是至少一个DPI业务卡基于接收的所述数据报文所生成的;基于所述数据报文和所述五元组规则,确定需添加标识字符的目标数据报文;基于所述五元组规则,对所述目标数据报文添加标识字符,并将添加标识字符后的目标数据报文输出给至少一个DPI业务卡,以使所述至少一个DPI业务卡对添加标识字符后的目标数据报文进行处理。该专利是传统网络流量分析方法,而本发明是针对于云网多层级网络的Flow分析。
专利文献CN106100999B(申请号:201610744511.3)公开了一种虚拟化网络环境中基于软件定义的镜像网络流量控制协议,其特征在于,该协议能够适应功能上解耦合且分布式部署的镜像流量采集、镜像流量分发和镜像流量控制的系统结构,镜像流量采集器节点/虚拟机被部署在用户的业务网络环境中,其主要功能是捕获虚拟化环境中的镜像流量,在根据协议所指定的目的进行转发;镜像流量分发器部署在非业务网络环境中,即不需要考虑网络负载对用户业务网络环境正常网络通信的影响,其功能是根据协议所指定的多目的的流量分析设备进行流量复制和分发;镜像流量中心控制器对整个镜像网络流量的转发逻辑进行统一的控制,提供软件定义的接口。该专利是对虚拟网络环境中镜像数据的控制,而本发明是针对于云网多层级网络的Flow分析。
专利文献CN107483507B(申请号:201710916063.5)公开了一种会话分析方法、设备及存储介质。所述方法包括:提取当前输入报文的原始特征值;其中,所述原始特征值包括:源IP地址、源端口号、目的IP地址、目的端口号和协议类型;根据所述原始特征值和第一会话分析表判断所述当前输入报文是否满足预先设置的分析条件;当所述当前输入报文满足所述预先设置的分析条件时,将所述当前输入报文统计到第二会话分析表中;按照预先设置的分析方法对所述第二会话分析表中的会话进行分析。该专利是通过两个会话提高会话分析的方法,而本发明是针对于云网多层级网络的Flow分析,实际是基于一个数据表的森林结构(一组树状结构)。
专利文献CN102045363B(申请号:201010619761.7)公开了一种网络流量特征识别规则的建立方法,包括:分析中心服务器接收网络流量样本,获取所述网络流量样本的载荷数据,从所述载荷数据中提取流量特征,当所述流量特征包含的特征参量达到相应阈值时,确定该网络流量属于所述相应阈值对应的类别,将所述流量特征与类别对应存储,以生成特征识别规则,将所述特征识别规则下发给网络流量设备。该专利是网络特征的提取方法,可以使用在本发明的Flow Key或者Flow ID中,与本法的对于云网多层级网络的Flow分析不相关。
专利文献CN112671600A(申请号:202011451447.2)公开了一种网络流的特征提取方法、网络流异常检测方法及相关装置,其中,该网络流的特征提取方法包括:获取待处理的网络流,对网络流的空间特征进行提取,以得到网络流的空间特征表示;对空间特征表示的时序特征进行提取,以得到网络流的时空特征表示。该专利是网络特征的提取方法,可以使用在本发明的Flow Key或者Flow ID中,与本法的对于云网多层级网络的Flow分析不相关。
因此,本发明提出了“层级可扩展的云网络流分析方法”(或“层级云网Flow方法”)的来解决以上缺陷,旨在通用化地处理多层级的Flow,解决多层级带来的扩展性问题、维度问题和复杂性问题。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种层级可扩展的云网络流分析方法及系统。
根据本发明提供的一种层级可扩展的云网络流分析方法,包括:
步骤S1:构建按层级的网络流Flow分析结构,并初始化构建的各层级的Flow分析维度信息;
步骤S2:将数据报文解析为链式层级信息;
步骤S3:链式层级信息按层级进行流分析,生成每个层级的流分析结果FlowRecord,并进行全局存储。
优选地,所述步骤S1采用:对于多层级报文,设置每一层级的Flow Key,以满足分析需求并将报文分组。
优选地,所述步骤S2采用:对数据报文进行数据解码,并将其组成层级信息链表。
优选地,所述流分析结果Flow Record中包含作为唯一标识Flow ID;所述Flow ID是根据Flow Key计算得到的唯一标识。
优选地,使用Outer Flow ID或inner Flow ID将同一数据包的不同层级的FlowRecord进行关联。
根据本发明提供的一种层级可扩展的云网络流分析系统,包括:
模块M1:构建按层级的网络流Flow分析结构,并初始化构建的各层级的Flow分析维度信息;
模块M2:将数据报文解析为链式层级信息;
模块M3:链式层级信息按层级进行流分析,生成每个层级的流分析结果FlowRecord,并进行全局存储。
优选地,所述模块M1采用:对于多层级报文,设置每一层级的Flow Key,以满足分析需求并将报文分组。
优选地,所述模块M2采用:对数据报文进行数据解码,并将其组成层级信息链表。
优选地,所述流分析结果Flow Record中包含作为唯一标识Flow ID;所述Flow ID是根据Flow Key计算得到的唯一标识。
优选地,使用Outer Flow ID或inner Flow ID将同一数据包的不同层级的FlowRecord进行关联。
与现有技术相比,本发明具有如下的有益效果:
1、本发明通过采用基于层级的Flow ID、Flow Key和他们组成的Flow Record结构,解偶了各层级的Dimensions和Measures的处理和存储,解决的云网络中层级增加和变化带来的扩展性问题;
2、本发明通过采用统一的数据包层级信息结构和Flow Record结构,使得复杂的云网络多层级Flow分析可以按层级采用通用的Flow分析过程进行,消除了传统方法对数据处理的复杂性;
3、本发明通过迭代数据包的链式层级信息,采用Outer Flow ID或inner Flow ID关联Flow Record,消除了维度爆炸问题,从而可以对所有层级网络做Flow分析;进而,可以使用Flow ID做跨层级的Flow关联分析。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为使用VXLAN封装的两层级数据包。
图2为层级可扩展的云网络流分析方法流程图。
图3为本发明层级信息结构图。
图4为本发明按层级Flow分析的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
实施例1
本发明提供了一种层级可扩展的云网络流分析方法及系统,如图1至4所示,将数据包解析为链式层级信息,然后迭代这些信息,采用通用的分析过程,按层级进行流(Flow)分析,生成每个层级的Flow分析结果Flow Record,进行全局存储。Flow Record中包含作为唯一标识Flow ID。这个过程解偶了云网络中各层级的Flow分析处理和存储,解决了云网络中层级增加和变化带来的扩展性问题和处理的复杂性问题。与此同时,使用Outer Flow ID或inner Flow ID将同一数据包的不同层级的Flow Record关联起来,消除了传统方法的维度爆炸问题,进而可以进行跨层级的Flow关联分析。
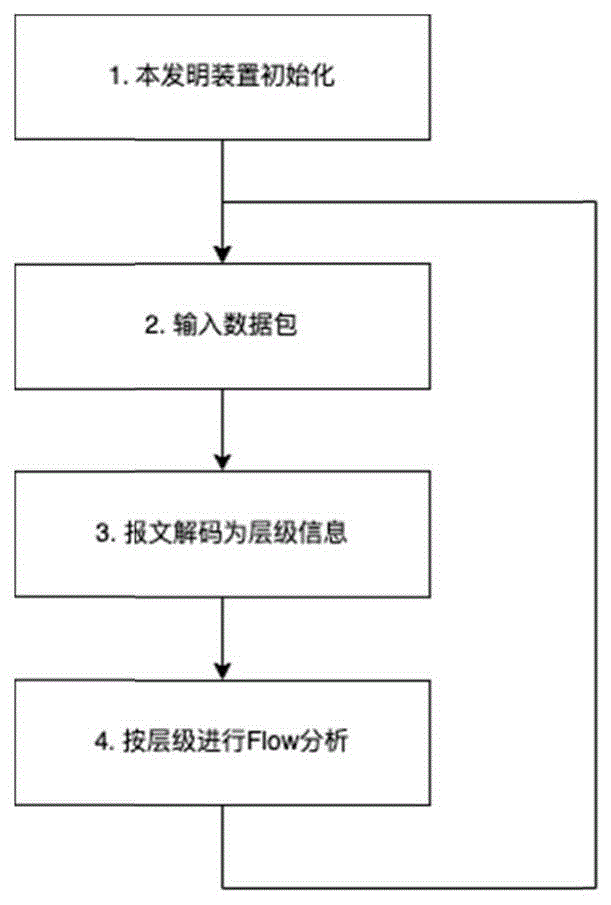
所述层级可扩展的云网络流分析方法,如图2所示,包括:
步骤1:本发明装置初始化。对于多层级报文,本发明可以设置每一层级的FlowKey,以满足分析需求将报文分组,然后进行计算和分析。譬如对于三层级网络,最外层物理层使用VLAN id作为Flow Key构建Flow进行数据统计分析,虚拟网络层使用IP Pair作为Flow Key来构建Flow进行通信VM进行分析,最内层容器网络层则使用五元组作为Flow Key构建Flow进行业务网络数据统计分析。除了Dimension外,对于TCP通道重用等场景,可以增加Flow的起始时间Time作为维度,以进行区分。
步骤2:输入数据包。本发明可以使用其他系统采集后输入的数据包,也可以使用通用的数据包采集技术自行采集数据报文。
步骤3:报文解码为层级信息。数据解码是种通用技术,本发明对数据报文解码,然后将其组成层级信息链表,如图3所示。
步骤4:按层级进行Flow分析。对步骤3的报文层级信息按步骤1的配置构建Flow,然后对每个层级进行通用的Flow分析。每一层级的分析结果都是结构一致的一组FlowMeasures,譬如采用Netflow结构。与此同时,对同一个数据包的不同层级的Flow使用FlowId进行关联,以进行不同层级间Flow的关联分析。
所述步骤3中报文解码为层级信息包括:将数据报文解码的信息组织成层级信息链表,如图3所示。tier0 info,tier1 info,tier2 info……表示解码后按从外向内的层级顺序依次连接的层级信息。每一层级的包含了完整的协议信息,包括(但不限于)具体如下:
L2 info表示二层协议信息,譬如Ethernet II等。
L2L3 info表示二层三层间协议信息,譬如MPLS和VLAN等。
L3 info表示三层协议信息,譬如IPv4和IPv6等。
L4 info表示四层协议信息,譬如TCP和UDP等。
Tunnel info表示隧道协议信息,譬如VXLAN、GRE、IPinIP等。
App info表示应用层系信息,譬如HTTP、DNS等。
所述步骤4中按层级进行Flow分析的流程子流程如图4所示。具体说明如下:
步骤4.1:输入层级信息。输入步骤3的解码后的一组层级信息。
步骤4.2:从最外层开始迭代信息。从最外层也就是tier1开始迭代,直至所有层级的Flow分析都完成为止。
步骤4.3:计算本层Flow Key和Flow ID。Flow Key是步骤1初始化中指定的构建各层级Flow的Dimensions(还可能包括时间)。Flow ID是根据Flow Key计算得到的的标识,用于唯一标记一个Flow。
步骤4.4:获取本层Flow存储单元。使用Flow ID,可以在全局Flow数据中(譬如HashMap或者数据库数据表中)查询获得Flow。如果Flow已存在,同时处于active状态,那么获取存储单元Flow Record。如果Flow不存在,或者已经关闭,那么创建新的Flow Record,并存储到全局Flow数据中。Flow Record一般包括部分内容:Flow ID,Outer Flow ID,FlowKey,Flow State和一组Flow Measures。
Flow ID为本层的Flow ID,作为本层数据的唯一标识。在步骤4.3中计算得到。
Flow Key为本层的Flow Key,是一组Dimensions的具体取值。在步骤1中配置,在步骤4.3中计算得到。
Outer Flow ID,是外层的Flow ID,用以关联到外层Flow ID,进行层级间的Flow关联分析。一般仅存储直接外层的Flow ID即可,外层的外层可以递归查询获取。同时,FlowID和Outer Flow ID将相关的Flow结构组织成为一个树状结构;而整个Flow数据则因此组织成为一个森林结构(一系列树状结构)。从而,使用Flow ID和Outer Flow ID可以进行自上而下或者自相而上的跨层级Flow关联分析。如果为了加速关联查询,也可以扩展OuterFlow ID结构,直接存储所有的外层的Flow ID。
Flow State,指Flow的状态机,譬如IP重组和TCP分析都需要使用的维护上下文的状态机。
一组Flow Measures,是一组通用的Flow度量信息,在步骤4.5中计算和更新。FlowMeasures一般包含L2、L2L3、L3、L4和Tunnel的度量信息,因为这些信息在各层级普遍存在。App度量信息因为只在最内层的存在,可以使用单独的结构存储,以免underlay中的数据浪费。
步骤4.5:进行本层级Flow分析。本步骤的输入是步骤3的(某一个)层级信息和步骤4.4.获取的Flow Record。本步骤的输出是更新后的Flow Record。对于多有层级来说,这些结构都是一致的,因此可以采用通用的Flow分析,而不需要对于不同的层级有特殊处理。本步骤更新的是Flow Record中的Flow State和Flow Measures,对于Flow ID、Outer FlowID和Flow Key在Flow创建后,不需要再重复更新。此外,由于各层级的Dimensions是各自维护的,因此不会因为层级增加带来维度爆炸问题。
步骤4.6:结束Flow分析。
所述层级可扩展的云网络流分析系统,包括:
模块1:本发明装置初始化。对于多层级报文,本发明可以设置每一层级的FlowKey,以满足分析需求将报文分组,然后进行计算和分析。譬如对于三层级网络,最外层物理层使用VLAN id作为Flow Key构建Flow进行数据统计分析,虚拟网络层使用IP Pair作为Flow Key来构建Flow进行通信VM进行分析,最内层容器网络层则使用五元组作为Flow Key构建Flow进行业务网络数据统计分析。除了Dimension外,对于TCP通道重用等场景,可以增加Flow的起始时间Time作为维度,以进行区分。
模块2:输入数据包。本发明可以使用其他系统采集后输入的数据包,也可以使用通用的数据包采集技术自行采集数据报文。
模块3:报文解码为层级信息。数据解码是种通用技术,本发明对数据报文解码,然后将其组成层级信息链表,如图3所示。
模块4:按层级进行Flow分析。对模块3的报文层级信息按模块1的配置构建Flow,然后对每个层级进行通用的Flow分析。每一层级的分析结果都是结构一致的一组FlowMeasures,譬如采用Netflow结构。与此同时,对同一个数据包的不同层级的Flow使用FlowId进行关联,以进行不同层级间Flow的关联分析。
所述模块3中报文解码为层级信息包括:将数据报文解码的信息组织成层级信息链表,如图3所示。tier0 info,tier1 info,tier2 info……表示解码后按从外向内的层级顺序依次连接的层级信息。每一层级的包含了完整的协议信息,包括(但不限于)具体如下:
L2 info表示二层协议信息,譬如Ethernet II等。
L2L3 info表示二层三层间协议信息,譬如MPLS和VLAN等。
L3 info表示三层协议信息,譬如IPv4和IPv6等。
L4 info表示四层协议信息,譬如TCP和UDP等。
Tunnel info表示隧道协议信息,譬如VXLAN、GRE、IPinIP等。
App info表示应用层系信息,譬如HTTP、DNS等。
所述模块4中按层级进行Flow分析的流程子流程如图4所示。具体说明如下:
模块4.1:输入层级信息。输入模块3的解码后的一组层级信息。
模块4.2:从最外层开始迭代信息。从最外层也就是tier1开始迭代,直至所有层级的Flow分析都完成为止。
模块4.3:计算本层Flow Key和Flow ID。Flow Key是模块1初始化中指定的构建各层级Flow的Dimensions(还可能包括时间)。Flow ID是根据Flow Key计算得到的的标识,用于唯一标记一个Flow。
模块4.4:获取本层Flow存储单元。使用Flow ID,可以在全局Flow数据中(譬如HashMap或者数据库数据表中)查询获得Flow。如果Flow已存在,同时处于active状态,那么获取存储单元Flow Record。如果Flow不存在,或者已经关闭,那么创建新的Flow Record,并存储到全局Flow数据中。Flow Record一般包括部分内容:Flow ID,Outer Flow ID,FlowKey,Flow State和一组Flow Measures。
Flow ID为本层的Flow ID,作为本层数据的唯一标识。在模块4.3中计算得到。
Flow Key为本层的Flow Key,是一组Dimensions的具体取值。在模块1中配置,在模块4.3中计算得到。
Outer Flow ID,是外层的Flow ID,用以关联到外层Flow ID,进行层级间的Flow关联分析。一般仅存储直接外层的Flow ID即可,外层的外层可以递归查询获取。同时,FlowID和Outer Flow ID将相关的Flow结构组织成为一个树状结构;而整个Flow数据则因此组织成为一个森林结构(一系列树状结构)。从而,使用Flow ID和Outer Flow ID可以进行自上而下或者自相而上的跨层级Flow关联分析。如果为了加速关联查询,也可以扩展OuterFlow ID结构,直接存储所有的外层的Flow ID。
Flow State,指Flow的状态机,譬如IP重组和TCP分析都需要使用的维护上下文的状态机。
一组Flow Measures,是一组通用的Flow度量信息,在模块4.5中计算和更新。FlowMeasures一般包含L2、L2L3、L3、L4和Tunnel的度量信息,因为这些信息在各层级普遍存在。App度量信息因为只在最内层的存在,可以使用单独的结构存储,以免underlay中的数据浪费。
模块4.5:进行本层级Flow分析。本模块的输入是模块3的(某一个)层级信息和模块4.4.获取的Flow Record。本模块的输出是更新后的Flow Record。对于多有层级来说,这些结构都是一致的,因此可以采用通用的Flow分析,而不需要对于不同的层级有特殊处理。本模块更新的是Flow Record中的Flow State和Flow Measures,对于Flow ID、Outer FlowID和Flow Key在Flow创建后,不需要再重复更新。此外,由于各层级的Dimensions是各自维护的,因此不会因为层级增加带来维度爆炸问题。
模块4.6:结束Flow分析。
本领域技术人员知道,除了以纯计算机可读程序代码方式实现本发明提供的系统、装置及其各个模块以外,完全可以通过将方法步骤进行逻辑编程来使得本发明提供的系统、装置及其各个模块以逻辑门、开关、专用集成电路、可编程逻辑控制器以及嵌入式微控制器等的形式来实现相同程序。所以,本发明提供的系统、装置及其各个模块可以被认为是一种硬件部件,而对其内包括的用于实现各种程序的模块也可以视为硬件部件内的结构;也可以将用于实现各种功能的模块视为既可以是实现方法的软件程序又可以是硬件部件内的结构。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。