结合Unet和Transformer的遥感图像语义分割方法
文献发布时间:2023-06-19 19:35:22
技术领域
本发明属于遥感图像语义分割技术领域,特别是涉及一种结合Unet和Transformer的遥感图像语义分割方法。
背景技术
图像分割是指将图像分成若干具有相似性质的区域的过程,分割的区域不仅包含分类信息,还包含这些类的空间位置的附加信息。图像语义分割是通过对每个像素进行密集预测来实现的细粒度推理,因此每个像素都需要被标记为相应的类,进而在图像上分成不同的区域。
更具体的说,图像语义分割技术是将给定图像中的每个像素都贴上对应的一类所代表的内容的标签,最终达到分割图像的目的。因为要对图像进行逐像素的密集预测,图像语义分割技术相比与传统的图像分割技术更具挑战性,一直是计算机视觉(CV)领域的重要研究方向。
近年来,随着深度学习的发展,遥感图像语义分割的效果越来越好,但多类别的精细分割仍然是一个难题。主要是遥感图像由于获取方式等的不同,相比于普通自然图像有更多的特殊性,主要表现在以下三个方面:1.自然图像数据集中包含的目标很少,相反在遥感图像中每幅图像中包含的目标很多,并且目标之间排列密集;2.遥感图像具有更高的场景复杂性,主要表现为类间方差小,类内方差大;3.遥感图像数据集中同类目标尺度变化较大,颜色纹理差异较大,且包含很多小目标。由于存在上述特殊性,从分割效果上看,遥感图像的多类别精细分割任务还存在着不同地物边界分类精度低、多尺度目标识别效果差的主要问题。因此,深度语义分割网络还需要加强对全局上下文信息、多尺度信息的理解,以提高遥感图像语义分割的精度。
卷积神经网络(CNN),特别是全卷积神经网络(FCN)是目前遥感图像语义分割的主流技术手段,SegNet、Deeplab、PSPNet、Unet、ResUnet以及Unet的更多变体等都在遥感图像语义分割任务中取得了较好的效果。它们大都采用编码器-解码器结构(Encoder-DecoderArchitecture),编码器中CNN用于特征提取,随后解码器中利用编码器编码的特征作为输入,解码出最后的分割预测结果。基于全卷积的深度语义分割方法相比于传统的图像分割方法,能够提取高级的语义特征,具有更加精确的分割效果。然而,由于特征提取主要依靠卷积运算,而卷积核的大小一般小于输入图片的大小,所以模型只能利用局部信息理解输入图像,这难免影响到编码器最后提取特征的可区分性,进而导致遥感图像在不同地物边界分类精度低等问题的产生。
Transformer模型是完全基于自注意力机制的模型,主要应用于计算机自然语言处理(NLP)领域。由于Transformer天然就具备从全局的角度去理解上下文信息的能力,也逐渐被应用于计算机视觉领域,Vision Transformer(VIT)是其中的代表之作。VisionTransformer打破了NLP与CV的隔离,通过将输入图片Token化后组合成序列,将组合后的结果传入自注意力结构进行全局特征提取。虽然VIT有强大的全局特征提取能力,但在局部信息的理解上目前来说还远不及CNN。
基于上述对遥感图像特点以及语义分割技术的分析,针对遥感图像的语义分割技术还有进一步的改进和优化空间。该研究具有较强的理论研究价值和实际应用价值。因此,本发明设计了一种结合Unet和Transformer的遥感图像语义分割方法,通过结合两者的优势,以实现更好的语义分割效果。
发明内容
本发明的目的是为解决目前遥感图像语义分割方法存在不同地物边界分类精度低、多尺度目标识别效果差的问题,而提出了一种结合Unet和Transformer的遥感图像语义分割方法。
一种结合Unet和Transformer的遥感图像语义分割方法,获取遥感图像数据,利用深度语义分割模型对遥感图像数据进行预测分类;
所述的深度语义分割模型是通过以下步骤获得的:
S1、获取遥感图像并构建遥感图像数据集,并按比例划分为训练集和验证集;
S2、搭建深度语义分割模型,所述的深度语义分割网络包括编码器、解码器和辅助上采样结构,深度语义分割网络整体保留Unet的U型结构;
所述编码器包括深度卷积模块和Transformer模块;输入数据首先进入深度卷积模块,深度卷积模块包括多层子模块,最后一层子模块提取的特征送入Transformer模块;
所述的Transformer模块使用ViT-B/16网络结构,并对ViT-B/16网络结构进行改进,包括重写Embedding模块和删除全连接层;Embedding模块重写为直接将输入特征变形为序列,然后将位置信息与特征序列进行求和;
编码器提取的高级特征变形后传入辅助上采样结构和解码器;解码器和辅助上采样结构与编码器中深度卷积模块的子模块层数相同;
辅助上采样结构中的每层子模块只包含一个上采样单元,上采样单元采用反卷积;每层子模块的上采样单元上采样后与对应的深度卷积模块同层子模块的特征求和,记为add特征;
解码器的每层子模块包括一个上采样单元和一个卷积单元;上采样单元上采样后,与同层的add特征进行特征连接,记为Concatenation特征;Concatenation特征再送入卷积单元处理;
解码器最后一层子模块的输出再经过1*1的卷积层得到最终分割结果;
S3、将训练样本作为深度语义分割网络的输入数据进行深度语义分割模型的训练,在训练过程中,取在验证集上效果最好的模型为最终的深度语义分割模型。
进一步地,加载训练样本的过程中,通过设置固定的batch_size读取训练样本数据。
进一步地,加载训练样本的过程中,随机对部分训练样本进行数据增强处理。
进一步地,进行深度语义分割模型的训练的过程中,深度语义分割网络采用的损失函数为Lov′asz-Softmax Loss。
进一步地,所述深度卷积模块包括四层子模块,每层子模块均包括一个残差单元和一个池化单元,残差单元计算特征后,送入池化单元;残差单元通过跳层连接的形式实现,每层子模块的残差单元都包含两个卷积层,卷积层中使用批量归一化和ReLU激活函数。
进一步地,所述每层子模块中残差单元中的卷积层为步长为1的3*3卷积层,池化单元采用步长为1的2*2最大池化。
进一步地,深度卷积模块包括的四层子模块中,第一层子模块的残差单元卷积层通道数为64、64,第二层子模块的残差单元卷积层通道数为128、128,第三层子模块的残差单元卷积层通道数为256、256,第四层子模块的残差单元卷积层通道数为512、512。
进一步地,所述解码器每层子模块中的卷积单元包含两个卷积层,卷积层中使用批量归一化和ReLU激活函数。
进一步地,解码器每层子模块中的卷积单元包含的两个卷积层采用步长为1的3*3卷积。
进一步地,与编码器中深度卷积模块的子模块层数相同的解码器中,第四层子模块卷积单元的卷积层通道数为512、512,第三层子模块卷积单元的卷积层通道数为256、256,第二层子模块卷积单元的卷积层通道数为128、128,第一层子模块卷积单元的卷积层通道数为64、64。
本发明为解决上述技术问题采取的技术方案是:
(1)本发明提出了在编码器部分将UNet和Transformer结合,先通过深度卷积结构主要提取局部特征,再通过Transformer结构主要提取全局特征。两者的结合能整合各自优势,使网络在具备强大的局部特征提取能力的同时还能拥有强大的全局特征提取能力。
(2)解码器部分在UNet解码器基础上在增加了一个只包含上采样单元的辅助上采样结构,通过跳跃连接结构与编码器编码的特征进行求和。这种结构既能建立远程残差连接,又能促进全局上下文信息融合,提高多尺度信息获取能力。
因此与现有技术相比,本发明整合了Unet和Transformer的各自优势,用于遥感图像,能充分利用图像的全局上下文信息,从而有效地提高不同地物边界分类精度,提高多尺度目标识别效果。
附图说明
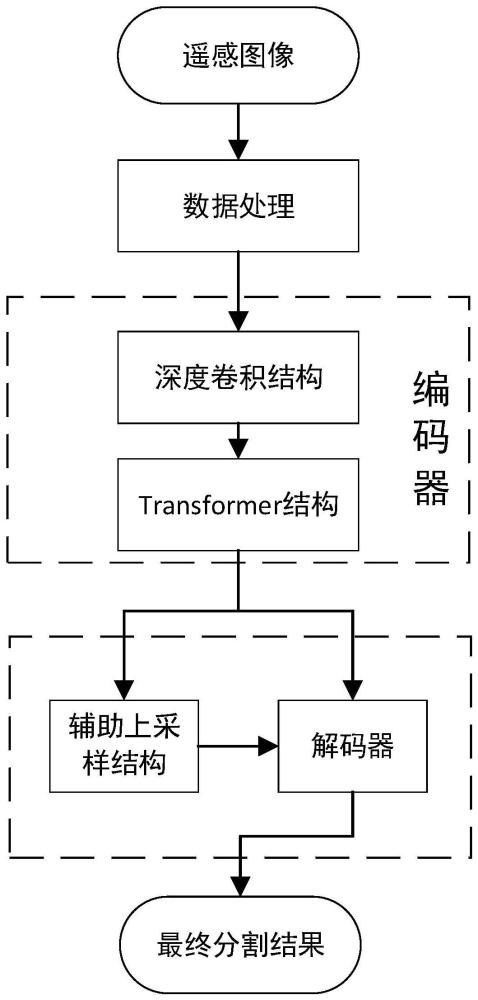
图1为本发明的流程图。
图2为实施例的开源遥感图像数据集的图像和标签。
图3为结合Unet和Transformer的深度语义分割整体网络结构图。
图4为TransformerBlock的网络结构图。
图5为实施例的地物分类结果示意图。
具体实施方式
为了本领域的普通技术人员理解和实施本发明,下面结合附图和实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅为详细地说明和解释本发明,而并非是对本发明的限定。
具体实施方式一:结合图1说明本实施方式,
本实施方式为一种结合Unet和Transformer的遥感图像语义分割方法,包括以下步骤:
步骤一、首先,将遥感图像数据集按比例划分为训练集和验证集;
然后进行数据加载,通过设置固定的batch_size读取数据,并对读取的数据进行数据增强,包括随机水平、垂直翻转以及随机旋转等。
最后,将加载的数据作为训练样本。
本实施方式中的遥感图像数据集为开源的多类别遥感图像数据集,数据加载环节设置为30%的概率对读取的数据进行随机数据增强。
步骤二、将步骤一得到的训练样本作为深度语义分割网络的输入数据进行训练。
所述的深度语义分割网络为编码器-解码器结构,网络结构如图3所示,该网络整体保留了Unet的U型结构,主要由编码器、解码器和跳跃连接结构三部分组成。
编码器包括深度卷积模块和Transformer模块。输入数据首先进入深度卷积模块,主要进行局部特征提取;然后将深度卷积模块提取的特征送入Transformer模块,主要进行全局特征提取;最后得到局部性和全局性均优异的高级特征。
深度卷积模块包括四层子模块,每层子模块均包括一个残差单元和一个池化单元,残差单元计算特征后,送入池化单元,逐层增加感受野。
所述残差单元通过跳层连接的形式实现,使用步长为1的3*3卷积层,卷积层中使用批量归一化和ReLU激活函数;池化单元采用步长为1的2*2最大池化。每层子模块的残差单元都包含两个卷积层,第一层子模块的残差单元卷积层通道数为64、64,第二层子模块的残差单元卷积层通道数为128、128,第三层子模块的残差单元卷积层通道数为256、256,第四层子模块的残差单元卷积层通道数为512、512。
Transformer模块使用ViT-B/16,为了与Unet实现结合,本发明对其进行了改进,包括重写Embedding模块和删除了全连接层。Embedding模块重写为直接将输入特征变形为序列,然后将位置信息与特征序列进行求和。TransformerBlocks模块与ViT-B/16保持一致,包含多个TransformerBlock单元,是Transformer模块的核心,TransformerBlock单元结构如图4所示,它使用了Transformer特有的多头自注意力机制结构(Multi-head Self-attention),通过多头注意力机制,关注图像特征的重要程度。最后,直接将提取的高级特征变形后传入解码器。
编码器提取的高级特征进入辅助上采样结构和解码器,逐层通过跳跃连接结构与编码器编码的特征求和实现上下文信息融合,然后逐层与Unet解码器进行拼接;
解码器在原UNet解码器基础上增加了一个辅助上采样结构,Unet解码器和辅助上采样结构与编码器中深度卷积模块的子模块层数相同,本实施方式中均包括四层子模块。
辅助上采样结构中的每层子模块只包含一个上采样单元,上采样单元采用反卷积(Transposed Convolution);每层子模块的上采样单元上采样后与对应的深度卷积模块同层子模块的特征求和,记为add特征;
Unet解码器的每层子模块包括一个上采样单元和一个卷积单元;上采样单元上采样后,与同层的add特征进行特征连接,记为Concatenation特征;Concatenation特征再送入卷积单元处理;
辅助上采样结构中,上采样单元的反卷积层的输出通道数从第四层到第一层分别为512、256、128、64。
Unet解码器每层子模块中的卷积单元包含两个卷积层,卷积层采用步长为1的3*3卷积,卷积层中使用批量归一化和ReLU激活函数;第四层子模块卷积单元的卷积层通道数为512、512,第三层子模块卷积单元的卷积层通道数为256、256,第二层子模块卷积单元的卷积层通道数为128、128,第一层子模块卷积单元的卷积层通道数为64、64。
解码器最后一层子模块的输出再经过1*1的卷积层得到最终分割结果。
深度语义分割网络采用的损失函数为Lov′asz-Softmax Loss。在训练过程中,取在验证集上效果最好的模型为最终的深度语义分割模型。
训练过程采用迁移学习的方式进行模型训练,上述TransformerBlocks模块直接加载ViT-B/16模型参数。训练过程先冻结TransformerBlocks模块的参数,对模型进行冻结训练,后解冻TransformerBlocks模块的参数,对模型进行解冻训练。最终得到训练好的深度语义分割模型。
步骤三、最后利用步骤二中最终得到的深度语义分割模型对测试的遥感图像数据进行预测分类并输出最终分类结果。
实施例:
本发明实施例包括以下步骤:
步骤一、遥感图像数据处理。本实施例采用的WHDLD开源遥感图像数据集的图像和标签如图2所示,包含4940张图像及对应的标签,类别分别为裸土(bare soil)、建筑物(building)、人行道(pavement)、道路(road)、植被(vegetation)、水体(water)共六类。将数据集按4:1的比例随机划分为训练集和验证集,其中3952张图像用于训练,988张图像用于测试。对划分好的数据集进行简单的数据增强,设置为30%的概率随机地对遥感图像进行数据增强操作,包括随机水平、垂直翻转以及随机旋转等。
步骤二、深度语义分割模型训练。以步骤一所述的遥感图像数据集作为深度语义分割网络的输入数据进行训练,深度语义分割网络中的损失函数为Lov′asz-SoftmaxLoss,使用Adam优化算法并采用cos学习率下降法,学习率根据batch_size自适应调整。模型一共训练140个epoch,Transformer模块采用迁移学习加载ViT-B/16模型参数,前60个epoch冻结Transformer模块参数进行训练,后80个epoch解冻模型参数并训练。训练完成后,取在验证集上效果最好的模型作为最终模型。
步骤三、遥感图像预测分类。利用步骤二得到的最终模型对测试的遥感图像数据进行预测分类并输出最终分类结果。
与AttUnet模型相比,本发明方法在WHDLD数据集训练得到的模型在mPA和mIoU上分别提升了0.58%和3.56%,分类结果见图5。由分类结果图可知,由于结合了Transformer结构,本发明误检、错检更少,不同地物边界更加明晰;同时,由于辅助上采样结构有效地融合了上下文信息,本发明对不同尺度的目标识别效果更好,尤其是对小尺度目标的识别效果得到了明显提升。
本发明方法通过结合Unet和Transformer构建深度语义分割网络,这样做可以整合Unet和Transformer的各自优势,使模型在具备强大的局部信息理解能力的同时还能拥有全局上下文信息理解能力。从分割效果上看,本发明能有效地解决目前存在的不同地物边界分类精度低、多尺度目标识别效果差的问题,从而提升了遥感图像语义分割精度。
本发明的上述算例仅为详细地说明本发明的计算模型和计算流程,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动,这里无法对所有的实施方式予以穷举,凡是属于本发明的技术方案所引伸出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 融合改进UNet和SegNet的遥感图像语义分割方法
- 融合改进UNet和SegNet的遥感图像语义分割方法