一种基于关系感知的动作时序定位方法
文献发布时间:2024-04-18 19:58:21
技术领域
本发明涉及计算机视觉和计算机图形学领域,特别是涉及一种基于视频内关系建模的弱监督动作时序定位方法。
背景技术
运动是人类维持生命、完成任务、改造客观世界的基础,也是人类在图像等信息媒体中的主要表现形式,使计算机获取并分析场景中人物的运动是模式识别与自动化领域的一项重要内容。人体运动数据较好地保持了真实人体运动细节,并详细记录了其运动轨迹,被广泛应用在体育仿真、医学理疗、机器人模拟、工厂监控等领域。在此背景下,以获取和利用人体运动数据为目的的人体运动监测研究已经成为近年来研究热点,其中三维连续人体运动通过人体运动序列时序定位、人体运动在线检测与姿态估计等方面对运动数据进行获取与分析,构建有效的人体运动数据集;在此基础上通过人体动作识别、人体动作质量评估对得到的运动数据进行有效利用,从而实现人体运动智能化监测。
随着对人体运动监测的研究逐渐深入并应用到各个领域,以及运动数据传感器设备的逐渐普及,利用机器学习技术自动化地获取并分析运动数据中承载的人体运动信息,实现人体运动在线监测,越来越受到研究人员的关注。随着各种媒体数据捕获设备的发展与普及,人体运动信息被广泛记录在监控、影视、日常摄像等媒体数据中,具有来源广、自然性强、内容丰富、成本低等特点。然而,从海量媒体资源中高效地、准确地获取用户所需要的人体运动信息是难点。因此,如何从海量媒体数据中,在尽可能抑制样本失真干扰与减少监督信息依赖的前提下,高效率地获取到高准确率的人体运动数据,进而学习具有良好泛化能力的人体运动检测模型与动作质量评估指标,是目前亟需解决的关键科学问题。围绕上述问题,有必要深入探索弱监督学习范式在人体运动监测任务中的机理,研究基于弱监督学习的人体运动时序定位、三维人体姿态估计、复杂人体动作识别,以及人体动作质量评估等研究内容。
在基于弱监督学习的人体运动时序定位方面,从一段长视频中定位出所有动作的起始与终止位置,是人体运动监测的基础。传统的事件监测或异常行为检测往往高度依赖人工标注,需要花费大量的人力与时间成本。现有基于学习的视频动作定位方法主要是以全监督的方式训练网络。虽然这些精确的时序标注可以缓解动作模型学习的困难,但由于存在一些客观约束,使得全监督的方式难以适应现实更具挑战性场景下的定位需求。一方面,为每一个视频规范的、精准的时序动作位置是昂贵且耗时的;另一方面,与图像识别相比,人们对行为的确切时间方位往往没有统一的标准,导致不同的人工标注存在不一致的现象。因此,有必要研究更加高效的弱监督时间动作定位方法。
发明内容
本发明主要解决的技术问题:针对现有弱监督视频运动定位面临的运动预测离散化问题,拟分别构建基于视频内关系建模的弱监督运动定位与基于视频间关系建模的弱监督运动定位网络,在上述预测的结果基础上,设计级联的关系感知弱监督人体运动视频时序定位网络。
本发明解决上述的技术问题采用的技术方案为:一种基于关系感知的弱监督人体运动视频时序定位方法,实现步骤如下:
步骤(1)、基于视频内关系建模的弱监督动作定位,通过对视频经过I3D网络提取的特征进行基于图卷积的视频特征更新操作,实现了对视频片段相邻关系的建模,并使用自上而下的注意力机制同时考虑前景和背景对时序定位过程的增益;
步骤(2)、基于视频间关系建模的弱监督动作定位,首先通过跨注意力机制的利用视频间的关系进行建模,将视频内关系模块与视频间关系模块级联,构建出基于关系感知的弱监督时序动作定位网络。
进一步的,所述步骤(1)基于视频内关系建模的弱监督动作定位的步骤具体如下:
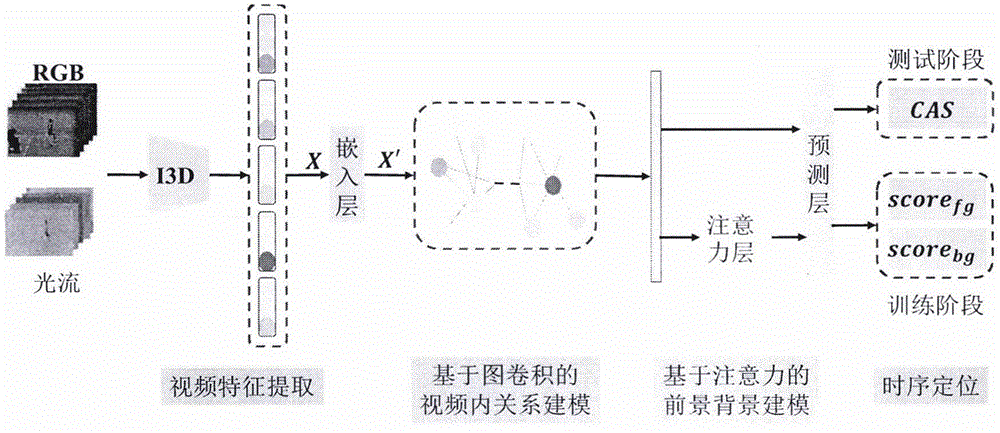
步骤(A1)、视频特征提取。受I3D网络在视频分类任务上的启发,使用其在Kinetics数据集上预训练的网络作为视频特征提取器。设有一组训练视频及其对应的视频级别的类别标签。对每一个视频进行采样操作。对采样后的RGB视频片段,计算其内部相邻帧的光流,得到光流片段。将RGB和光流片段分别送入I3D网络,提取出对应的特征。最终融合两个分支网络提取到的特征,作为视频片段的特征。
步骤(A2)、基于图卷积的视频内关系建模。对提取到的视频特征,通过在网络中嵌入基于图卷积的视频特征更新模块,使得视频内部的信息关系聚集性更高。将每一个动作片段看做图中的某一个节点,而对于边集合则需要考虑结点之间的连接关系构建。通过图卷积网络,依据邻域内的结点来更新自身的特征,实现对视频片段相邻关系的建模。同时,该模块可以直接嵌入到现有弱监督时序定位网络中。
步骤(A3)、基于注意力的前景背景建模。针对现有方法仅仅注重前景建模,忽略背景对动作定位的增益,设计基于自上而下注意力方式的前景背景建模方法。对经过图卷积后的视频特征,首先通过一个注意力层对视频的每一个片段产生片段前景注意力权重参数。接着通过注意力权重对视频特征序列加权得到前景视频特征表示,根据前景背景互补的原则,得到背景的注意力权重。由此得到加权的背景视频特征表示,最后将前后背景特征送入预测层产生视频级别的分类结果,以前景与背景得分表示。
步骤(A4)、时序定位。使用在有标注数据上训练好的网络,对于测试视频产生动作定位,即对每一个视频片段建立一个类别序列图(Class Activation Sequence,CAS)。得到CAS后,使用一个两阶段的模型生成最终的动作区间。
进一步的,所述步骤(2)基于视频间关系建模的弱监督动作定位的步骤具体如下:
步骤(B1)、基于跨注意力机制的视频间关系建模。结合无参考图像质量度量的思想,设计基于对抗生成网络的质量预测网络。对任意视频对,将它们映射到同一个特征嵌入空间,使得动作与动作之间的视频特征尽可能接近,背景或者与背景高度相关的上下文片段之间相似度尽可能的高,而与动作片段之间的相似性尽可能的低。通过跨注意力层,每个视频片段的特征更新将利用另一个视频的关系信息,网络将会更关注动作本身而不是高度关联的背景。
步骤(B2)、基于关系感知的弱监督时序动作定位网络。由于所提出的视频内关系模块与视频间关系模块分别从不同的角度来解决长视频时序定位中存在的问题,并不是互斥的关系,因此,可以将这两个模块级联,构建出基于关系感知的弱监督时序动作定位网络。该网络不仅包含了解决动作完整性建模的视频内关系建模模块,也包含了解决动作-上下文混淆的视频间关系建模模块。由于引入了新的融合模块,网络的损失函数由视频对共同构成。其中,每个视频又包含了基于跨注意力关系建模的前景背景损失,以及基于视频间关系建模的前景背景损失,总的损失函数是视频对损失的平均值。
附图说明
图1为本发明的基于视频内关系建模的弱监督动作定位具体实现过程示意图;
图2为本发明中基于视频间关系建模的弱监督动作定位具体实现过程示意图;
图3为本发明中级联的关系感知弱监督人体运动视频时序定位网络示意图。
具体实施方式
下面结合附图和具体实施方式对本发明进行描述。
本发明在视频内与视频间提取视频特征,分别解决长视频动作时序定位中动作完整性建模问题及动作-上下文混淆问题。通过将两个从不同角度理解动作时序关系的网络级联,建立关系感知弱监督人体运动视频时序定位网络。
步骤一:基于视频内关系建模的弱监督动作定位方法共分为三个阶段。首先,对待处理的一段长视频,提取视频特征;接着,利用图卷积网络构建视频内的关系模型,学习视频内部相邻片段之间的关系;最后,通过分类与定位模块得到准确的动作定位结果。如图1所示,具体步骤如下:
步骤(A1):本发明使用其在Kinetics数据集上预训练的网络作为视频特征提取器,设有一组训练视频及其对应的视频级别的类别标签。对每一个视频V∈{f
步骤(A2):对提取到的视频特征,通过在网络中嵌入基于图卷积的视频特征更新模块,使得视频内部的信息关系聚集性更高。在网络中,设对一个视频,通过I3D特征提取的视频特征维度为,表示该视频可以划分为段不重叠的16帧的视频块,且每个视频端提取的视频特征维度为1024。为减少计算开销,网络首先通过一个嵌入层。嵌入层由1×1卷积核一个ReLU激活函数组成,旨在对输入的特征降维,减少关系建模的计算开销。
X′=f
上式中表示嵌入层中可训练的参数,是降维后的数据,将其送入图卷积网络中。具体地,将每一个动作片段看做图中的某一个节点,而对于边集合则需要考虑结点之间的连接关系构建。考虑到动作在被划分为视频片段后,往往具有局限性,即对每一个视频片段,只需考虑当前片段的左右两端各个连续的相邻结点。设图卷积网络通过层卷积来更新视频之间的特征,这里使用ChebNect-GCN,利用一阶近似ChebNet简化卷积公式:
上式中是图的邻接矩阵,是图的度矩阵,是可学习的参数。为抑制参数过拟合,设。同时,为防止图卷积层反复叠加导致数值发散或梯度爆炸,引入重整化,即为图中加入自环:
最终得到从层到层的快速卷积公式:
上式中W是图网络的可学习参数。经过层图卷积后,得到特征大小为H′=x
步骤(A3):针对现有方法仅仅注重前景建模,忽略背景对动作定位的增益,设计基于自上而下注意力方式的前景背景建模方法。对经过上述图卷积后的视频特征,首先通过一个注意力层对视频的每一个片段产生片段前景注意力权重参数λ=[λ
score
步骤(A4):最终,使用在有标注数据上训练好的网络,对于测试视频产生动作定位,即对每一个视频片段建立一个类别序列图(Class Activation Sequence,CAS)。具体生成方法为,对每一个视频片段,通过网络分别产生对应的类别激活序列得分。所有序列得分构成对应的CAS。得到CAS后,使用一个两阶段的模型生成最终的动作区间。首先设置一个参数阈值τ,在CAS上对对应的类别得分进行筛选,舍弃置信度低于τ的类别的分信息。对保留下的类别,使用第二个阈值生成对应的检测提议(proposals)。设预测的动作区间为[t
式中λ
步骤二:基于视频间关系建模的弱监督动作定位。步骤一基于视频内关系建模方法通过图卷积的方式聚合来自邻域的信息,解决了动作完整性建模问题,但依旧不能解决动作-上下文混淆问题。因此,通过基于跨注意力机制的视频间关系建模,将相同标签的视频嵌入到相同的特征空间,学习视频对(pairs)之间的片段对应性,将动作从上下文中分离出来。具体步骤如图二所示:
步骤(B1):基于跨注意力机制,视频中某一动作片段的特征将完全由来自视频的特征加权表示更新。由于网络输入是视频对,因此假设网络随机抽取包含相同动作类别标签的视频对{X
X′
所得到的输入通过点积来计算视频对之间的片段相似度,相似度矩阵为:
注意到点积产生的相似度可能存在负数,分别从X
步骤(B2):由于所提出的视频内关系模块与视频间关系模块分别从不同的角度来解决长视频时序定位中存在的问题,并不是互斥的关系,因此,可以将这两个模块级联,构建出基于关系感知的弱监督时序动作定位网络,具体如图3所示。该网络不仅包含了解决动作完整性建模的视频内关系建模模块,也包含了解决动作-上下文混淆的视频间关系建模模块。由于引入了新的融合模块,网络的损失函数由视频对共同构成。其中,每个视频又包含了基于跨注意力关系建模的前景背景损失,以及基于视频间关系建模的前景背景损失,因此,视频的损失函数为:
总的损失函数是视频对的平均值:
本发明说明书中未作详细描述的内容属于本领域专业技术人员公知的现有技术。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 基于全局感知与提名关系挖掘的时序动作定位方法
- 基于对偶关系网络的时序动作定位方法、系统、设备及介质