一种鉴定完整糖肽上N-糖链分支结构的方法
文献发布时间:2023-06-19 09:49:27
技术领域
本申请主要涉及一种鉴定完整糖肽上N-糖链分支结构的方法。
背景技术
质谱技术是规模化鉴定位点特异性的蛋白质糖基化修饰的主要手段。作为广泛存在的糖基化修饰之一,N-糖基化中的糖链通常为非线性结构,并存在微不均一性,这也成为其结构鉴定中的难点。通常情况下,研究人员首先通过预先设定的参数进行氧鎓离子的匹配以筛选完整糖肽的谱图,之后进一步通过蛋白质和糖链数据库搜索的方式,鉴定完整糖肽中的多肽序列及糖链分子量,最后通过糖链的分子量推断糖链组成。在糖链中,分支结构包含了很多重要的生物学信息并在疾病相关研究中具有重要应用。比如,唾液酸化是糖链分支结构中常见的一种修饰,含有唾液酸的分支结构糖链的异常表达是多种恶性肿瘤的标志。目前已有多种糖蛋白被批准作为临床癌症标记物,其中大部分为唾液酸化糖蛋白。同时,唾液酸糖链在人类对病毒的免疫应答和感染中也发挥着重要作用,比如禽流感病毒需通过识别细胞表面特定的唾液酸化N-连接糖链感染上呼吸道细胞。因此,糖链分支结构的准确鉴定对其生物学功能的研究及其临床应用都有着重要的意义。
目前,已有多种完整糖肽的鉴定软件,常见的如Byonic和pGlyco2.0等。这些软件主要通过糖链组成/多肽数据库与实验获得的谱图进行匹配并通过打分挑选最优结果,以实现完整糖肽的鉴定。但现有软件通常只能获得糖链组成而无法确定具体糖链结构特别是分支结构。而为实现N-糖链结构的鉴定,糖链的分支结构鉴定至关重要,通常需要足够数量的糖链碎片离子(B离子与Y离子)。但由于现有完整糖肽分析过程中,糖肽分支结构鉴定所需的B离子与Y离子通常丰度较低,或谱图中B/Y离子混杂在一起无法区分识别,因此现有技术无法确定糖链的具体分支结构,完整糖肽上N-糖链分支结构鉴定方法目前尚未有报道。
发明内容
本申请的目的是解决现有技术通常只能获得糖链组成而无法确定具体糖链分支结构的问题。
本申请的技术方案如下:
一种鉴定完整糖肽上N-糖链分支结构的方法,包括如下步骤:
(1)目标完整糖肽的质谱分析
获取目标完整糖肽的串联质谱数据,预处理得到包含糖肽数据的二级质谱谱图;
(2)构建候选糖链分支结构的理论碎片离子集合
根据预先建立的糖链分支结构的数据库,构建已知多肽序列和全部糖链分支结构的理论完整糖肽,在其糖链部分进行理论碎裂,得到每一种候选糖链分支结构对应的完整糖肽的理论Y离子集合(连接在多肽上的糖链碎片离子)、理论B离子集合(从糖链分支结构末端碎裂得到的碎片离子)和可能的B离子进一步理论碎片离子集合;
(3)目标二级质谱数据与理论数据进行匹配
(3a)针对每一张二级质谱谱图,将所述理论B离子集合和所述进一步碎片离子集合分别与二级质谱谱图在预设误差范围内进行分子量匹配(根据谱峰进行对照);若二级质谱谱图中的某一谱峰与理论B离子集合或所述进一步理论碎片离子集合中的某一分子量在误差范围内,则认为对应的B离子或进一步碎片离子匹配成功;
(3b)针对每一张二级质谱谱图,将所述理论Y离子的分子量集合与二级质谱谱图在预设误差范围内进行匹配(根据谱峰进行对照);若二级质谱谱图中的某一谱峰与理论Y离子集合中的某一分子量在误差范围内,则认为对应的Y离子匹配成功;
(4)根据匹配结果鉴定每个糖链分支结构
对于每一张二级质谱谱图,结合(3a)与(3b)的匹配结果,基于匹配成功的B离子、Y离子以及可能的B离子进一步碎片离子,若能够组成确定的某一种或多种候选糖链分支结构(这些B离子、Y离子以及B离子进一步碎片离子的全部或部分进行随机组合),则表明该张二级质谱谱图鉴定得出相应的一种或多种糖链分支结构;否则,表明该张二级质谱谱图鉴定失败;
(5)根据鉴定得到的糖链分支结构的集合,推定得出若干可能的糖链分支结构(因为有的糖链分支结构会存在包含关系,导致此时通常不能唯一确定其真实糖链分支结构);
(6)根据糖链类型确定完整糖肽的糖链分支结构
确定完整糖肽上连接的糖链所属的糖链类型;
根据特定糖链类型的固有特点,对二级质谱谱图鉴定得到的若干可能的糖链分支结构进行特定组合,最终得出鉴定结论,即目标完整糖肽包含哪些糖链分支结构。
可选地,步骤(2)中,所述候选糖链分支结构的数据由以下方式获得:
基于预先建立的N-糖链数据库,从理论完整糖肽中提取候选糖链分支结构,即取N-糖链上除去核心结构外的部分,认定为糖链分支结构;
或者,根据糖链生物合成的规律进行理论构建得到候选糖链分支结构的数据。
可选地,步骤(2)中,所述预先建立的糖链分支结构的数据库,为已知的数据库,或者按照以下方式构建:
2.1)模拟生成N-连接糖链中所有理论分支结构的糖链组成,并构建理论B离子数据库,其中包含理论B离子组成及对应的B离子分子量;
2.2)获取待测糖肽二级质谱谱图(包含所有谱峰的质荷比、强度和电荷信息等),将理论B离子数据库中的B离子分子量与待测谱图匹配,根据匹配情况初步确定待测谱图中的B离子组成;
2.3)根据匹配得到的每一种B离子,分别生成对应的理论可能的分支结构,以及每一种候选分支结构对应的全部理论B离子和全部理论Y离子;
2.4)B离子的验证:将待测糖肽二级质谱谱图与所述全部理论B离子进行匹配,对所述理论可能的分支结构进行初步筛选;
2.5)Y离子的验证:将待测糖肽二级质谱谱图与所述全部理论Y离子进行匹配,对步骤2.4)初步筛选后的结果进一步筛选,确定唯一的分支结构;
2.6)重复步骤2.3)至2.5),最终构建得到涵盖待测样本N-连接糖链分支结构的数据库。
进一步可选地,步骤2.1)中所述的理论B离子数据库由以下五种单糖自由组合而成,五种单糖分别是:N-乙酰己糖胺、己糖、N-乙酰神经氨酸、N-羟乙酰神经氨酸和岩藻糖。
进一步可选地,步骤2.4)中B离子的验证方法具体如下:
2.4.1)记需要验证的结构为C;
2.4.2)生成C对应的理论B离子的分子量,记为G
2.4.3)遍历G
2.4.4)如果G
进一步可选地,步骤2.5)中Y离子的验证方法具体如下:
2.5.1)记需要验证的结构为C;
2.5.2)获得C对应的理论Y离子的分子量,记为G
2.5.3)遍历G
2.5.4)如果G
进一步可选地,步骤2.5.2)中,获得C对应的理论Y离子的分子量的方法具体是:
基于已经获取的多肽以及核心糖链结构信息,设多肽+五糖核心结构即peptide+HexNAc*2+Hex*3的分子质量为m;假如还存在特定修饰,则将m重新定义为peptide+HexNAc*2+Hex*3+特定修饰;假定对应的分支结构与核心结构相连接,使之在多肽完整的前提下理论碎裂,所有分子量大于m的理论碎片的分子量即为分支结构的理论Y离子的分子量。所述特定修饰为核心岩藻糖修饰和/或平分型糖修饰。
可选地,步骤(6)中,所述确定完整糖肽上连接的糖链所属的糖链类型,按照以下步骤进行:
6.1)根据已知的多肽碎片信息数据库,确定二级质谱谱图中的多肽分子质量和多肽的准确序列;
6.2)基于多肽分子质量,在二级质谱谱图中搜索相应的多肽+糖链的分子质量;
假设多肽+五糖核心结构即peptide+HexNAc*2+Hex*3的分子质量为m;根据分子质量确定多肽+五糖核心结构是否存在特定修饰,假如存在特定修饰,则将m重新定义为peptide+HexNAc*2+Hex*3+特定修饰;
6.3)通过判断低能量碎裂条件下的二级质谱谱图中是否存在m+Hex、m+Hex*2、m+HexNAc、m+HexNAc+Hex谱峰来判断糖链类型;
如果只存在m+Hex或m+Hex*2谱峰,即为高甘露糖型;
如果只存在m+HexNAc或m+HexNAc+Hex谱峰,即为复杂型;
如果既存在m+Hex或m+Hex*2又存在m+HexNAc或m+HexNAc+Hex谱峰,即为杂合型。
可选地,步骤(6)中,根据特定糖链类型的固有特点,对二级质谱谱图鉴定得到的糖链分支结构的集合进行特定组合,具体是:
将完整糖肽(母离子,一级质谱谱图中对应谱峰)质量记为M,多肽加上N-糖链核心结构质量(包含可能存在的核心岩藻糖或平分型N-乙酰葡糖胺的分子量变化)记为m;
(6a)如果糖链类型为复杂型糖链,则将步骤(5)得出的若干可能的糖链分支结构进行任意组合,使之组合后的分子量与M-m在误差范围内匹配,如果有多个组合的分子量均匹配成功,则取Y离子匹配数量最多的一种组合作为鉴定结果;
(6b)如果糖链类型为杂合型糖链,在二级质谱谱图中寻找m+162(甘露糖分子量)的峰,如果存在则继续寻找m+162*2的峰,直至找到m+162*x的峰,即表明甘露糖分支的甘露糖数量为x;将步骤(5)得出的若干可能的糖链分支结构进行任意组合,使之组合后的分子量与M-(m+162*x)在误差范围内匹配,如果有多个组合的分子量均匹配成功,则取Y离子匹配数量最多的一种组合,确定该杂合型糖链的一侧分支结构;对于另一侧分支结构,根据x的值查询已知的杂合型糖链结构予以唯一匹配确定;
(6c)如果糖链类型为高甘露糖型糖链,则分支的高甘露糖数量为y=(M-m)/162,根据y的值查询已知的高甘露糖型糖链结构予以唯一匹配确定。
基于以上方案,本申请还提供一种智能终端,包括处理器和存储器,所述存储器存储有程序,所述程序被处理器加载运行时实现上述一种鉴定完整糖肽上N-糖链分支结构的方法所列的各个步骤。
基于以上方案,本申请还提供一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器加载运行时实现上述一种鉴定完整糖肽上N-糖链分支结构的方法所列的各个步骤。
与现有技术相比,本发明具有以下有益效果:
本发明根据糖链候选分支结构生成理论B离子与对应碎片离子分子量集合,通过与质谱实测谱图中的B、Y离子匹配,能准确地解析出糖链的分支结构信息。
本发明中,针对待测样本构建N-连接糖链分支结构数据库,能够实现N-糖链分支结构的全面构建,找到现有糖链数据库中不存在的分支结构,从而有助于更准确地鉴定完整糖肽信息。
本发明中,关于对完整糖肽上N-连接糖链类型的鉴定,基于多肽分子质量,在二级质谱谱图中搜索相应的多肽+糖链的分子质量;并通过确定糖链核心结构,根据核心结构之外的四个峰作为判断糖链类型的特征性离子,进行识别匹配来实现了对N-连接糖链类型的规模化的准确判断。
附图说明
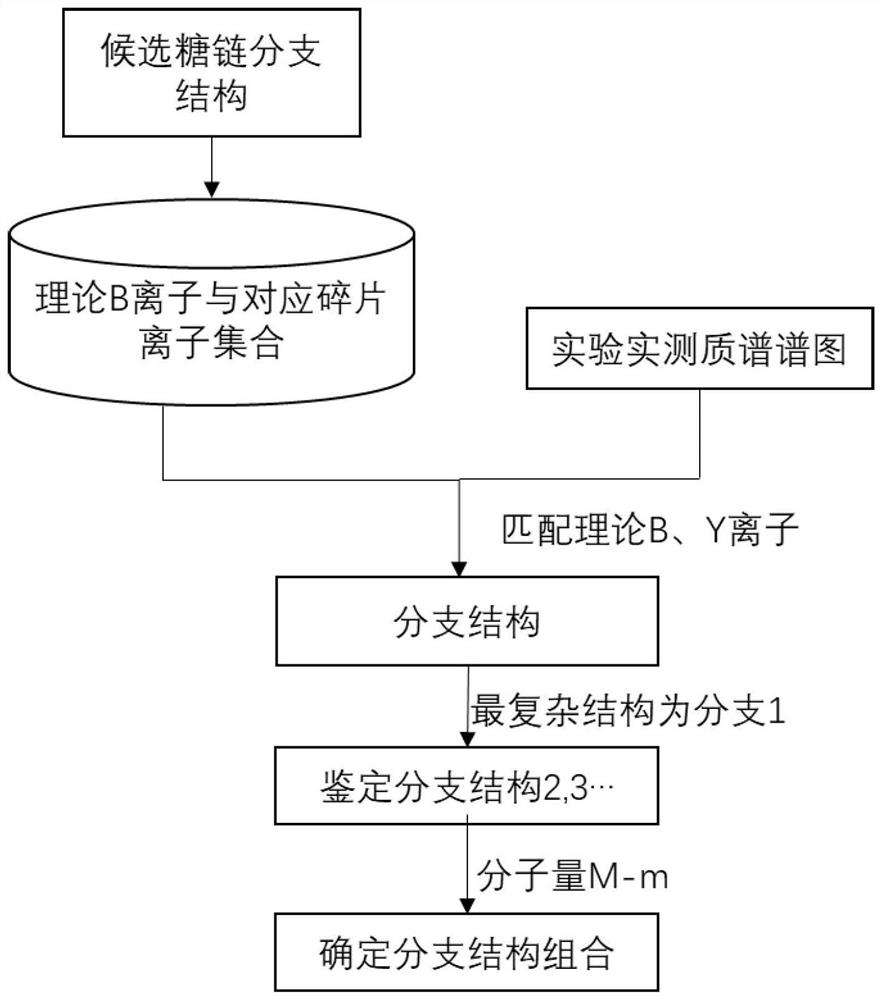
图1为本申请的一个实施例的主体流程示意图(以复杂型为例)。
图2为本实施例中针对待测样本构建N-连接糖链分支结构数据库的方法流程示意图。
图3为分支结构对应的Y离子结构及其理论分子量示例。
图4为本实施例中确定糖链类型的原理示例。
图5为本实施例中确定糖链类型的方法流程示意图。
图6为本实施例的分支结构鉴定结果。
图7为对小鼠组织分析获得的部分N-糖链分支结构。
具体实施方式
以下结合附图以及实施例,对本申请作进一步详述。应当理解,这些实施例只用于更充分地解释说明本申请的特点,而并非对本申请权利要求的限制。
如图1所示,一种鉴定完整糖肽上N-糖链分支结构的方法,包括如下步骤:
(1)目标完整糖肽的质谱分析
获取目标完整糖肽的串联质谱数据,预处理得到包含糖肽数据的二级质谱谱图。具体是:
获得一级质谱数据和二级质谱数据(特定完整糖肽-一级质谱某一谱峰-二级质谱具有对应关系),筛选出有效质谱数据,即包含糖肽数据的所有一级质谱谱图及其从属的二级质谱谱图(二级质谱谱图含有肽段碎片信息和糖链碎片信息);其中,对于当前一级质谱数据和二级质谱数据,根据预设的氧鎓离子谱峰判断二级质谱数据是否包含糖肽数据;如果包含,则保留对应的一级质谱谱图及其从属的全部二级质谱谱图;如果不包含,则排除对应的一级质谱谱图及其从属的全部二级质谱谱图;根据同位素峰簇的特点,可计算出每一张二级质谱谱图中的所有单同位素峰的m/z和电荷,进而得出相应的各个分子量(分子量为两者相乘)。
(2)构建候选糖链分支结构的理论碎片离子集合
根据预先建立的糖链分支结构的数据库,构建已知多肽序列和全部糖链分支结构的理论完整糖肽,在其糖链部分进行理论碎裂,得到每一种候选糖链分支结构对应的完整糖肽的理论Y离子集合(连接在多肽上的糖链碎片离子)、理论B离子集合(从糖链分支结构末端碎裂得到的碎片离子)和可能的B离子进一步理论碎片离子集合;
这里,候选糖链分支结构的数据由以下方式获得:基于预先建立的N-糖链数据库,从理论完整糖肽中提取候选糖链分支结构,即取N-糖链上除去核心结构外的部分,认定为糖链分支结构;或者,也可以根据糖链生物合成的规律进行理论构建得到候选糖链分支结构的数据。
而糖链分支结构的数据库,可以采用现有的数据库,不过目前N-糖链数据库还不够完善,依靠手工解谱的方式虽然可以一定程度上能发现一些新的分支糖链结构,但是受限于解谱速度以及由于没有统一可靠的解析标准,解析的可靠性也存在一定的问题。为此,本申请还提供了一种针对待测样本的N-连接糖链分支结构数据库构建方法,如图2所示:
2.1)模拟生成N-连接糖链中所有理论分支结构的糖链组成,,构建理论B离子数据库;具体由以下五种单糖自由组合而成:N-乙酰己糖胺、己糖、N-乙酰神经氨酸、N-羟乙酰神经氨酸和岩藻糖;
2.2)获取待测糖肽二级质谱谱图,谱图包含所有谱峰的质荷比、强度和电荷信息;将理论B离子数据库中的B离子分子量与待测谱图匹配,根据匹配情况初步确定待测谱图中的B离子组成;
2.3)根据匹配得到的每一种B离子,分别生成对应的理论可能的分支结构,以及每一种候选分支结构对应的全部理论B离子和全部理论Y离子;
2.4)B离子的验证:将待测糖肽二级质谱谱图与所述全部理论B离子进行匹配,对所述理论可能的分支结构进行初步筛选;
2.4.1)记需要验证的结构为C;
2.4.2)生成C对应的理论B离子的分子量,记为G
2.4.3)遍历G
2.4.4)如果G
2.5)Y离子的验证:将待测糖肽二级质谱谱图与所述全部理论Y离子进行匹配,对步骤2.4)初步筛选后的结果进一步筛选,确定唯一的分支结构;
2.5.1)记需要验证的结构为C;
2.5.2)获得C对应的理论Y离子的分子量,记为G
2.5.3)遍历G
2.5.4)如果G
2.6)重复步骤2.3)至2.5),最终构建得到涵盖待测样本N-连接糖链分支结构的数据库。
上述步骤2.5.2)中,获得C对应的理论Y离子的分子量的方法具体是:
基于已经获取的多肽以及核心糖链结构信息,设peptide+HexNAc*2+Hex*3设为第一类核心结构(m);
若谱图中糖链核心结构包含核心岩藻糖修饰,则将peptide+HexNAc*2+Hex*3+Fucose设为第二类核心结构(m);
若谱图中糖链核心结构包含平分型糖修饰,则将peptide+HexNAc*2+Hex*3+HexNAc设为第三类核心结构(m);
若谱图中糖链核心结构既包含核心岩藻糖修饰又包含平分型糖修饰,则将peptide+HexNAc*2+Hex*3+Fucose+HexNAc设为第四类核心结构(m);
假定对应的分支结构与核心结构相连接,使之在多肽完整的前提下理论碎裂,所有分子量大于m的理论碎片的分子量即为分支结构的理论Y离子的分子量。
(3)目标二级质谱数据与理论数据进行匹配
(3a)针对每一张二级质谱谱图,将所述理论B离子集合和所述进一步碎片离子集合分别与二级质谱谱图在预设误差范围内进行分子量匹配(根据谱峰进行对照);若二级质谱谱图中的某一谱峰与理论B离子集合或所述进一步理论碎片离子集合中的某一分子量在误差范围内,则认为对应的B离子或进一步碎片离子匹配成功;
(3b)针对每一张二级质谱谱图,将所述理论Y离子的分子量集合与二级质谱谱图在预设误差范围内进行匹配(根据谱峰进行对照);若二级质谱谱图中的某一谱峰与理论Y离子集合中的某一分子量在误差范围内,则认为对应的Y离子匹配成功;
其中,计算过程如下:二级质谱数据与B离子及对应碎片离子集合进行匹配并给定匹配误差,如20ppm(ppm表示为百万分之一),并且二级质谱数据中匹配上的强度必须大于所设定的编码离子最小强度。
(4)根据匹配结果鉴定每个糖链分支结构
对于每一张二级质谱谱图,结合(3a)与(3b)的匹配结果,基于匹配成功的B离子、Y离子以及可能的B离子进一步碎片离子,若能够组成确定的某一种或多种候选糖链分支结构(这些B离子、Y离子以及B离子进一步碎片离子的全部或部分进行随机组合),则表明该张二级质谱谱图鉴定得出相应的一种或多种糖链分支结构;否则,表明该张二级质谱谱图鉴定失败;
(5)根据鉴定得到的糖链分支结构的集合,推定得出若干可能的糖链分支结构(因为有的糖链分支结构会存在包含关系,导致此时通常不能唯一确定其真实糖链分支结构);
(6)根据糖链类型确定完整糖肽的糖链分支结构
确定完整糖肽上连接的糖链所属的糖链类型;
根据特定糖链类型的固有特点,对二级质谱谱图鉴定得到的若干可能的糖链分支结构进行特定组合,最终得出鉴定结论,即目标完整糖肽包含哪些糖链分支结构。
这里,对于糖链类型的判定可以采用现有的判定方法,不过现有的糖链类型判定方法是基于糖链组成进行推测,并没有实现对糖链类型的准确判定。根据组成,通常会认为仅含有两个N-乙酰己糖胺的N-连键糖链为高甘露糖型;含有三个N-乙酰己糖胺为杂合型;含有四个及以上N-乙酰己糖胺为复杂型。但是仅通过统计N-乙酰己糖胺的个数来粗略判断糖链类型的方法是不正确的,存在很多的错误判断。例如,HexNAc4Hex5通过统计HexNAc个数会认为该糖链为复杂型糖,但是实际情况下该糖链也是有可能为杂合型。为此,本申请还提供了一种鉴定完整糖肽上N-连接糖链类型的方法,如图4、图5所示:
6.1)根据已知的多肽碎片信息数据库,确定二级质谱谱图中的多肽分子质量和多肽的准确序列;
6.2)基于多肽分子质量,在二级质谱谱图中搜索相应的多肽+糖链(单糖或者多个单糖)的分子质量;
假设多肽+五糖核心结构即peptide+HexNAc*2+Hex*3的分子质量为m;根据分子质量确定多肽+五糖核心结构是否存在特定修饰(含核心岩藻糖或平分型糖修饰,或者二者皆有),假如存在特定修饰,则将m重新定义为peptide+HexNAc*2+Hex*3+特定修饰(的质量);
6.3)通过判断低能量碎裂条件下的二级质谱谱图中是否存在m+Hex、m+Hex*2、m+HexNAc、m+HexNAc+Hex谱峰来判断糖链类型;图4中主要标注了五种特征峰,每个峰依次代表糖链核心结构(m),核心结构+Hex,核心结构+HexNAc,核心结构+Hex+Hex,核心结构+Hex+HexNAc,核心结构之外的四个峰是判断糖链类型的特征性离子,本实施例就是通过对四个特征离子识别匹配来实现对糖链类型的准确判断;
如果只存在m+Hex或m+Hex*2谱峰,即为高甘露糖型;
如果只存在m+HexNAc或m+HexNAc+Hex谱峰,即为复杂型;
如果既存在m+Hex或m+Hex*2又存在m+HexNAc或m+HexNAc+Hex谱峰,即为杂合型。
上述根据特定糖链类型的固有特点,对二级质谱谱图鉴定得到的糖链分支结构的集合进行特定组合,具体是:
将完整糖肽(母离子,一级质谱谱图中对应谱峰)质量记为M,多肽加上N-糖链核心结构质量(包含可能存在的核心岩藻糖或平分型N-乙酰葡糖胺的分子量变化)记为m;
(6a)如果糖链类型为复杂型糖链,则将步骤(5)得出的若干可能的糖链分支结构进行任意组合,使之组合后的分子量与M-m在误差范围内匹配,如果有多个组合的分子量均匹配成功,则取Y离子匹配数量最多的一种组合作为鉴定结果;
(6b)如果糖链类型为杂合型糖链,在二级质谱谱图中寻找m+162(甘露糖分子量)的峰,如果存在则继续寻找m+162*2的峰,直至找到m+162*x的峰,即表明甘露糖分支的甘露糖数量为x;将步骤(5)得出的若干可能的糖链分支结构进行任意组合,使之组合后的分子量与M-(m+162*x)在误差范围内匹配,如果有多个组合的分子量均匹配成功,则取Y离子匹配数量最多的一种组合,确定该杂合型糖链的一侧分支结构;对于另一侧分支结构,根据x的值查询已知的杂合型糖链结构予以唯一匹配确定;
(6c)如果糖链类型为高甘露糖型糖链,则分支的高甘露糖数量为y=(M-m)/162,根据y的值查询已知的高甘露糖型糖链结构予以唯一匹配确定。
图6是分支结构鉴定的一个实例(二级质谱谱图及标记)。其中,绿色部分代表B离子及其碎片离子,红色部分代表Y离子,通过对实验谱图中的B离子与/或Y离子的分析,可以完成N-连接糖链的分支结构的鉴定。
按照本实施例的方法,我们还对小鼠组织进行了分析,部分分支糖链结构及其碎片离子及其分子量,如图7所示。其中蓝色方形代表N-乙酰葡糖胺(N-Acetylglucosamine),黄色圆形代表甘露糖(Mannose),菱形代表唾液酸,其中紫色菱形代表Neu5Ac,白色菱形代表Neu5Gc。
另外,本申请的方案可以通过智能终端、计算机可读存储介质等形式实施或形成商业化产品,例如:
一种智能终端,包括处理器和存储器,所述存储器存储有程序,所述程序被处理器加载运行时实现上述一种鉴定完整糖肽上N-糖链分支结构的方法的各个步骤。
一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器加载运行时实现上述一种鉴定完整糖肽上N-糖链分支结构的方法的各个步骤。
- 一种鉴定完整糖肽上N-糖链分支结构的方法
- 一种鉴定完整糖肽上N-连接糖链类型的方法