一种基于深度学习的摄像头寻物方法
文献发布时间:2023-06-19 10:35:20
技术领域
本发明涉及深度学习及图像处理技术领域,具体地说是一种基于深度学习的摄像头寻物方法。
背景技术
当前物联网概念盛行,无论在社会上还是家庭中都有数目庞大的监控摄像头,覆盖人们生活的大部分时间和区域。而这种无处不在的视频数据不但可以用于监控,还能扩展出很多其他应用。例如视频寻物,目前也有一些基于摄像头的寻物算法,但是多数是基于传统的图像比对方式,这种算法物体检出率不高,检测的准确率较低。
发明内容
本发明的技术任务是针对以上不足之处,提供一种基于深度学习的摄像头寻物方法,可以将物体检出率大幅提升,提高检测的准确率和检测物品的类别数。
本发明解决其技术问题所采用的技术方案是:
一种基于深度学习的摄像头寻物方法,通过目标检测或本地特征提取对实时录像或历史录像进行视频分析,定位到待寻物品的当前位置或最后一次出现的位置。
部署目标检测和特征提取算法,调取监控摄像头的数据,从使用者处获取到待寻物品的类别或样例图像,视频分析进行物品的检测或匹配,给出当前物品位置或历史记录中物品最后出现的位置。
优选的,所述目标检测,基于通用目标检测算法在实时监控录像或已存储的监控录像中指定物品进行视频分析和定位。
进一步的,所述目标检测算法包括efficientDet、YOLO和/或SSD。
优选的,所述目标检测算法,在需要时可以使用自己的数据进行微调,所述数据来源于使用者对易丢失物品的标注。
优选的,所述本地特征提取,基于深度学习,通过给定物品的样例图在视频中进行特征提取和对比进行定位。
进一步的,本地特征提取使用的特征提取网络包括GeoDesc和/或Hardnet,只需要给出待寻物品的图像样例,生成特征点集,再给出监控图像生成特征点集,在两个点集之间使用FLANN或BruteForce方法进行匹配即可,不需要监督信息。
优选的,当实时定位失败时给出物品最后一次出现的视频片段。
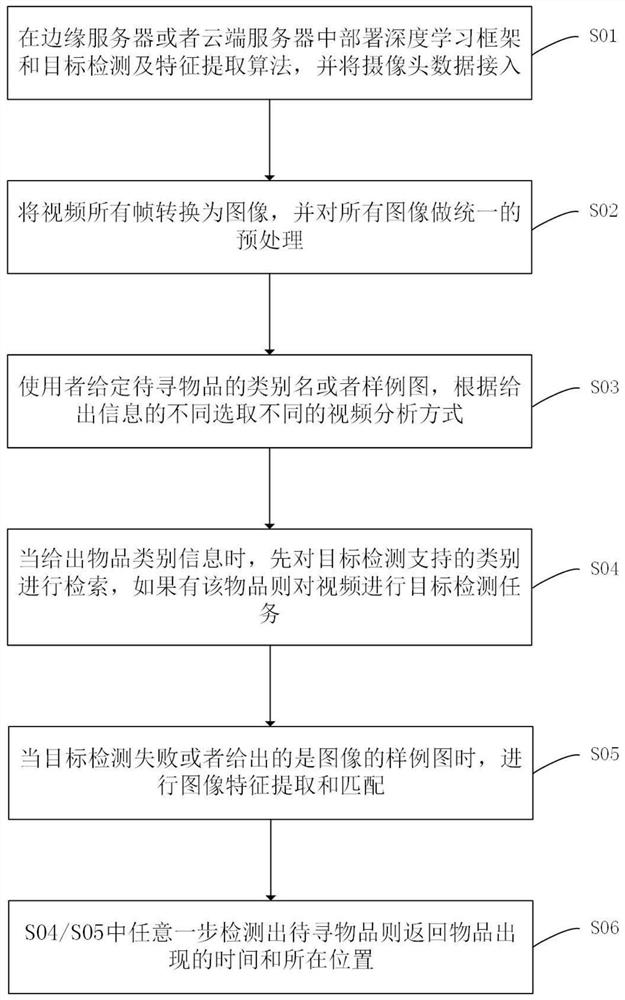
优选的,该方法的具体实现过程如下:
1)、在边缘服务器或者云端服务器中部署深度学习框架和目标检测及特征提取算法,并将摄像头数据接入;
2)、将视频所有帧转换为图像,并对所有图像做统一的预处理;
3)、使用者给定待寻物品的类别名或者样例图,根据给出信息的不同选取不同的视频分析方式;
4)、当给出物品类别信息时,先对目标检测支持的类别进行检索,如果有该物品则对视频进行目标检测任务;
5)、当目标检测失败或者给出的是图像的样例图时,进行图像特征提取和匹配;
6)、以上两步中任意一步检测出待寻物品则返回物品出现的时间和所在位置。
本发明还要求保护一种基于深度学习的摄像头寻物装置,包括:至少一个存储器和至少一个处理器;
所述至少一个存储器,用于存储机器可读程序;
所述至少一个处理器,用于调用所述机器可读程序,执行上述的方法。
本发明还要求保护一种计算机可读介质,所述计算机可读介质上存储有计算机指令,所述计算机指令在被处理器执行时,使所述处理器执行上述的方法。
本发明的一种基于深度学习的摄像头寻物方法与现有技术相比,具有以下有益效果:
该方法使用深度学习目标检测和特征提取的方法可以将物体检出率大幅提升,包括检测的准确率和检测物品的类别数;而作为系统冗余,本方法还使用了基于深度学习的本地特征提取,相较于传统的SIFT、SURF等方法,基于学习的特征提取器更加鲁棒,特征点数量和特征描述的区分度也都更优。
附图说明
图1是本发明实施例提供的基于深度学习的摄像头寻物方法的流程图;
具体实施方式
下面结合具体实施例对本发明作进一步说明。
人们在丢失东西时绝大多数时间会在脑海中回忆蛛丝马迹,往往一个恰到好处的提醒就会让人瞬间想起物品所在的位置。而通过利用深度学习中的目标检测或者特征提取进行视频分析,定位到物品当前或最后出现的位置从而给人们提供线索进行寻物。
本发明实施例提供一种基于深度学习的摄像头寻物方法,
通过目标检测或本地特征提取对实时录像或历史录像进行视频分析,定位到待寻物品的当前位置或最后一次出现的位置。
该基于深度学习的摄像头寻物方法有两种方式,
所述目标检测,基于通用目标检测算法在实时监控录像或已存储的监控录像中指定物品进行视频分析和定位;
所述本地特征提取,基于深度学习,通过给定物品的样例图在视频中进行特征提取和对比进行定位。
当实时定位失败时给出物品最后一次出现的视频片段。
目标检测可以使用efficientDet、YOLO、SSD等先进的目标检测算法。在必要的时候可以使用自己的数据进行微调,所述数据来源于使用者对易丢失物品的标注。
EfficientDet是google在2019年11月发表的一个目标检测算法系列,分别包含了从D0-D7总共八个算法,对于不同的设备限制,能给到SOTA的结果,在广泛的资源约束下始终比现有技术获得更好的效率。特别是在单模型和单尺度的情况下,EfficientDet-D7在COCO测试设备上达到了最先进的52.2AP,具有52M参数和325B FLOPs,相比与之前的算法,参数量缩小了4到9倍,FLOPs缩小了13到42倍。
YOLO将物体检测这个问题定义为bounding box和分类置信度的回归问题;将整张图像作为输入,划分成SxS grid,每个cell预测B个bounding box(x,y,w,h)及对应的分类置信度(class-specific confidence score),分类置信度是bounding box是物体的概率及其与真实值IOU相乘的结果。
SSD将物体检测这个问题的解空间,抽象为一组预先设定好(尺度,长宽比)的bounding box,在每个bounding box,预测分类label,以及box offset来更好的框出物体,对一张图片,结合多个大小不同的feature map的预测结果,以期能够处理大小不同的物体。
基于深度学习的本地特征提取可以使用GeoDesc、Hardnet等特征提取网络,他们不需要监督信息,只需要给出待寻物品的图像样例,生成特征点集,再给出监控图像生成特征点集,在两个点集之间使用FLANN或BruteForce方法进行匹配即可。
部署目标检测和特征提取算法,调取监控摄像头的数据,从使用者处获取到待寻物品的类别或样例图像,视频分析进行物品的检测或匹配,给出当前物品位置或历史记录中物品最后出现的位置。
本发明实施例提供一种基于深度学习的摄像头寻物方法,该方法的实现过程如下:
1)、在边缘服务器或者云端服务器中部署深度学习框架和目标检测及特征提取算法,并将摄像头数据接入;
2)、将视频所有帧转换为图像,并对所有图像做统一的预处理;
3)、使用者给定待寻物品的类别名或者样例图,根据给出信息的不同选取不同的视频分析方式;
4)、当给出物品类别信息时,先对目标检测支持的类别进行检索,如果有该物品则对视频进行目标检测任务;
5)、当目标检测失败或者给出的是图像的样例图时,进行图像特征提取和匹配;
6)、以上两步中任意一步检测出待寻物品则返回物品出现的时间和所在位置。
本发明实施例还提供了一种基于深度学习的摄像头寻物装置,包括:至少一个存储器和至少一个处理器;
所述至少一个存储器,用于存储机器可读程序;
所述至少一个处理器,用于调用所述机器可读程序,执行上述实施例中描述的基于深度学习的摄像头寻物的方法。
本发明实施例还提供了一种计算机可读介质,所述计算机可读介质上存储有计算机指令,所述计算机指令在被处理器执行时,使所述处理器执行本发明上述实施例中所述的基于深度学习的摄像头寻物的方法。具体地,可以提供配有存储介质的系统或者装置,在该存储介质上存储着实现上述实施例中任一实施例的功能的软件程序代码,且使该系统或者装置的计算机(或CPU或MPU)读出并执行存储在存储介质中的程序代码。
在这种情况下,从存储介质读取的程序代码本身可实现上述实施例中任何一项实施例的功能,因此程序代码和存储程序代码的存储介质构成了本发明的一部分。
用于提供程序代码的存储介质实施例包括软盘、硬盘、磁光盘、光盘(如CD-ROM、CD-R、CD-RW、DVD-ROM、DVD-RAM、DVD-RW、DVD+RW)、磁带、非易失性存储卡和ROM。可选择地,可以由通信网络从服务器计算机上下载程序代码。
此外,应该清楚的是,不仅可以通过执行计算机所读出的程序代码,而且可以通过基于程序代码的指令使计算机上操作的操作系统等来完成部分或者全部的实际操作,从而实现上述实施例中任意一项实施例的功能。
此外,可以理解的是,将由存储介质读出的程序代码写到插入计算机内的扩展板中所设置的存储器中或者写到与计算机相连接的扩展单元中设置的存储器中,随后基于程序代码的指令使安装在扩展板或者扩展单元上的CPU等来执行部分和全部实际操作,从而实现上述实施例中任一实施例的功能。
上文通过附图和优选实施例对本发明进行了详细展示和说明,然而本发明不限于这些已揭示的实施例,基与上述多个实施例本领域技术人员可以知晓,可以组合上述不同实施例中的代码审核手段得到本发明更多的实施例,这些实施例也在本发明的保护范围之内。
- 一种基于深度学习的摄像头寻物方法
- 一种基于高清摄像头的记忆寻物方法、装置及系统