一种基于YOLO系列的目标检测和视觉定位方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于机器视觉、视觉定位、目标检测和深度学习领域,尤其涉及一 种基于YOLO系列的目标检测和视觉定位方法。
背景技术
近年来,随着深度学习的技术越来越成熟,目标检测的模型更新速度也在 加快,现有的目标检测模型可分为两大类,一类one-stage检测算法,例如SSD、 YOLO等;因为其不需要region proposal阶段,可直接产生物体的类别概率和 位置坐标值,经过单次检测即可直接得到最终的检测结果,特点是具有更快的 检测速度;另一类是two-stage检测算法,例如Faster-RCNN、Fast-RCNN等; 这类检测算法将检测问题划分为两个阶段,首先产生候选区域,然后对候选区 域分类,特点是错误率低、漏检率低,但是速度相对较慢。
现有的基于深度学习的目标检测和视觉定位系统,如中国专利申请“基于 YOLOv3和OpenCV的目标检测与定位方法(CN111563458A)”仅能采用YOLO系 列的YOLOv3算法进行目标检测,适用性较低。
发明内容
针对现有技术存在的缺陷和不足,为了提高基于深度学习的目标检测算法的 泛化性、适应性和降低目标检测算法在视觉定位中的开发成本,本申请提供一 种基于YOLO系列的目标检测和视觉定位方法,利用darknet框架上部署的YOLO 系列目标检测算法对深度摄像头采集的RGB彩色图像进行二维定位,结合摄像 头特殊位置获取的深度信息实现三维定位。
为了实现上上述目的,本发明所采用的技术方案是:
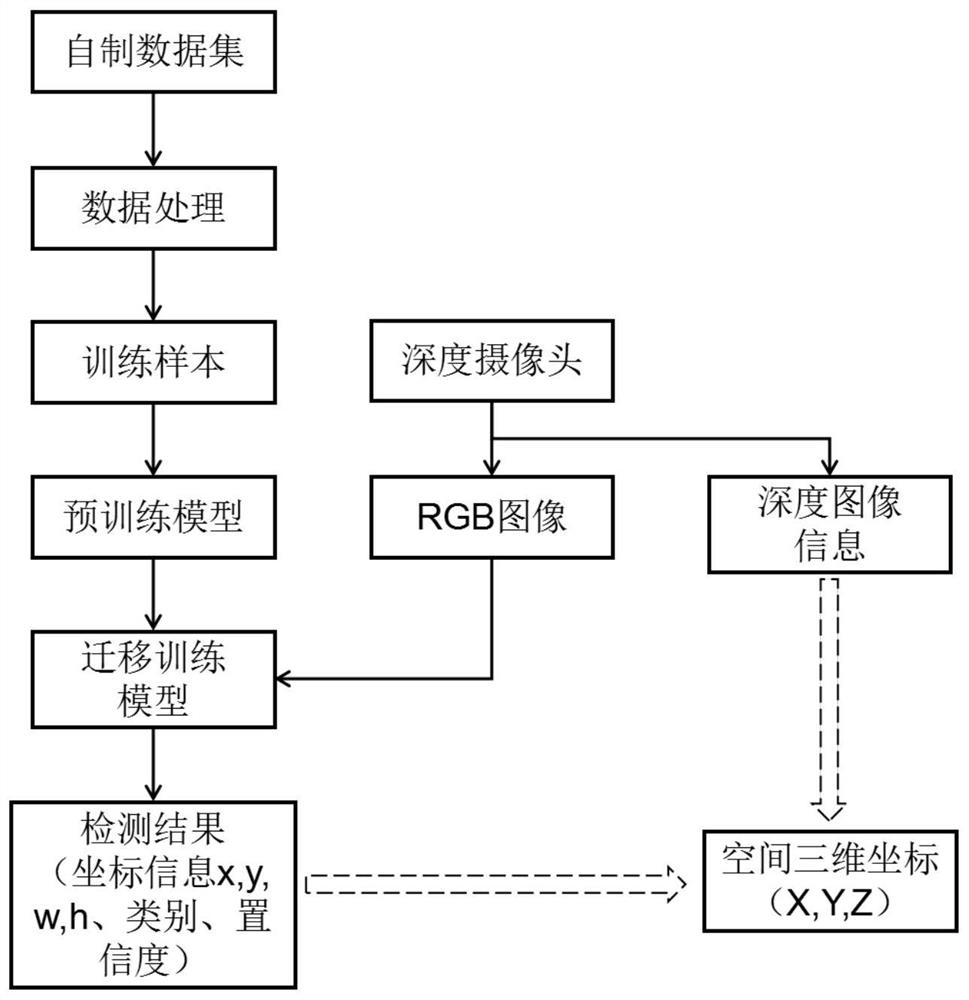
一种基于YOLO系列的目标检测和视觉定位方法,所述方法包括以下步骤:
(1)采集待检测目标的RGB彩色图像,制做待检测目标图像集;
(2)标注图像集,进行数据处理,分别定义训练样本、测试样本和验证样 本;
(3)上传训练样本到服务器,下载预训练权重,配置模型训练参数,权重 载入YOLO系列模型进行迁移训练;
(4)封装训练好的迁移训练模型,并嵌入ROS系统中;
(5)采集待检测目标的RGB彩色图像和深度图像,将采集到的待检测目标 的RGB彩色图像输入训练好的迁移训练模型,计算出待检测目标的二维坐标信 息、类别及置信度;
(6)结合待检测目标的深度图像,经坐标转换获得待检测目标中心的空间 三维坐标。
进一步的,步骤(1)中的RGB彩色图像由固定在待检测目标正上方的D435i 深度摄像头采集;所述D435i深度摄像头具备IMU、双目相机和红外发射器模块, 通过配置ROS环境使用。
进一步的,步骤(2)中的标注图像的工具是Labelimg,以长方形框标注出 待检测目标的坐标和类别,以VOC格式输出;每张待检测图像生成一个对应的 XML文件;XML文件信息包括图像名字、路径、宽度、标注框的左上角坐标和右 下角坐标,所述坐标以待检测目标图像的左上角为原点(0,0),向下为y轴正 方向,向右为x轴正方向。
进一步的,所述数据处理包括数据增强和数据整理,数据增强技术包括裁剪、 平移、旋转、镜像、改变亮度、加噪声,扩展原有数据集,增强模型的泛化能 力;数据处理包括将数据集制作成VOC数据集格式,所有图像文件存放在 JPEGImages文件夹中,所有xml文件存放在Annotations文件夹中,经处理得 到的四个txt文件:test.txt、train.txt、trainval.txt、val.txt存放在 ImageSets/Main文件夹下。
进一步的,所述步骤(3)中的服务器安装darknet深度学习框架;配置模 型训练参数包括修改“cfg/voc.data”文件和YOLO系列所对应的cfg文件,根 据自己训练样本的种类和硬件的条件修改种类参数、训练文件路径、测试文件 路径、训练批次、anchors大小、卷积核大小等。所述预训练权重为YOLO系列 在Imagenet数据集和COCO数据集下进行预训练得到的权重,自制的训练样本 在预训练模型上进行迁移训练。
进一步的,所述步骤(4)中的封装模型为将模型封装成ROS的一个节点, 提供数据接口,以便被其他节点使用,可嵌入其他基于机器视觉的研究中;把 之前训练好的yolo系列模型文件里面的cfg文件和weights文件分别放到基于 ROS搭建的系统的对应的文件夹下面;通过修改ros.yaml定义订阅的话题和发 布的话题,定义发布图像数据的话题叫“/camera/image”作为yolo_ros节点 的输入,定义目标物体类别名称“/darknet_ros/found_object”、预测框坐标 信息“/darknet_ros/bounding_boxes”、检测结果图片“/darknet_ros/detec tion_image”三个话题作为输出。
进一步的,所述步骤(5)中的二维坐标信息包括预测框的左上角坐标 (xmin,ymin)和右下角的坐标(xmax,ymax),与标注的训练样本坐标定义相同,以 图片左上角为原点,向下为y轴正方向,向右为x轴正方向;所述类别为识别 的分类,置信度有两重定义,一为预测框是否含有对象的概率,二为表示当前 的预测框含有对象时,预测框与标定框可能的IOU值。
进一步的,所述步骤(6)中的检测目标中心由步骤S5封装的ROS节点输出 信息坐标计算获得,待检测目标中心在彩色图片的像素点为 ((xmax-xmin)/2,(ymax-ymin)/2)。
进一步的,将深度图像的像素点还原到深度摄像头坐标系下;深度图像的 像素点为(u
将深度摄像头坐标系下的空间点还原到世界坐标系下;定义P
将世界坐标系的空间点转换到彩色摄像头坐标系下;定义
将彩色摄像头坐标系下的空间点映射到Z=1的彩色平面上;定义
进一步的,欧式变换矩阵T形式如下:
相比现在有的技术,本发明在darknet深度学习框架可以进行待检测目标 RGB彩色图像的目标检测,具有较大的可定制型、可拓展性、可维护性,很好地 匹配多样的检测要求,将目标检测和视觉定位结合,具有更高灵活性、抗干扰 性,其中:
1、本发明通过darknet深度学习框架下的目标检测算法对目标物体准确定 位,可以降低目标检测技术的门槛,加快开发周期。
2、本发明基于主流机器人操作系统ROS开发,具有较强的扩展性,利用ROS 的darknet深度学习框架,将封装的YOLO系列目标检测算法模块嵌入ROS中, 结合深度摄像头进行视觉定位,提高了目标检测速度,缩短了待检测目标的定 位时间。
3、本发明将目标检测模型进行迁移学习得到迁移模型,在小数据集上训练 也可以得到很好的检测效果;目标检测模型训练基于darknet框架,darknet框 架下有定义好的cfg文件和预训练相关文件,官方提供YOLO系列预训练权重, 降低深度学习的门槛,简化了目标检测训步骤,减小了目标检测模型训练的难 度。将训练好的模型封装成ROS节点,并提供输入和输出信息,可将训练好的 模型成果应用于更多的应用场景,具有很高的封装性、拓展性、泛化性。将目 标检测算法和深度摄像头结合起来,实现目标检测和视觉定位,这样的方法优 势在于不需要人为的设定图像特征,可直接获取待检测目标的三维坐标,抗干扰性极强。
4、本申请可通过改变算法对应的训练文件使用所有YOLO系列算法进行目标 检测。可以根据实际情况的要求引用不同的YOLO算法,该方法具有高适应性和 灵活性,针对不同的环境进行开发,满足大部分目标检测要求,对后续的开发 具有很大的参考价值。
附图说明
图1为一种基于YOLO系列的目标检测和视觉定位方法流程示意图。
图2为待检测目标彩色图像目标检测结果中心点计算示意图。
图3为世界坐标系、彩色摄像头坐标系与深度摄像头坐标系。
具体实施方式
下面结合附图对本发明进一步说明。
如图1所示,一种基于YOLO系列的目标检测和视觉定位方法,包括以下步 骤:
(1)采集待检测目标的RGB彩色图像,自制待检测目标图像集;
具体的,步骤(1)中的RGB彩色图像由固定在待检测目标正上方的D435i 深度摄像头采集;所述D435i深度摄像头具备IMU、双目相机和红外发射器模块, 通过配置ROS环境使用。
(2)标注图像集,进行数据处理,定义训练、测试、验证样本;
具体的,步骤(2)中的标注图像的工具是Labelimg,以长方形框标注出待 检测目标的坐标和类别,以VOC格式输出;每张待检测图像生成一个对应的XML 文件;XML文件信息包括图像名字、路径、宽度、标注框的左上角坐标和右下角 坐标,所述坐标基于的坐标系为以待检测目标图像的左上角为原点(0,0),向 下为y轴正方向,向右为x轴正方向。所述数据处理包括数据增强和数据整理, 数据增强技术包括裁剪、平移、旋转、镜像、改变亮度、加噪声,扩展原有数 据集,增强模型的泛化能力;数据整理包括将数据集制作成VOC数据集格式, 所有图像文件存放在JPEGImages文件夹中,所有xml文件存放在Annotations 文件夹中,经处理得到四个txt文件:test.txt、train.txt、trainval.txt、 val.txt存放在ImageSets/Main文件夹下。test.txt保存的是测试所用的样本 名、train.txt保存的是训练所用的样本名、trainval.txt保存的是以上两个 文件的总和样本名、val.txt保存的是验证所用的样本名。
(3)上传训练样本到服务器,下载预训练权重,配置模型训练参数,权重 载入YOLO系列模型进行迁移训练;
具体的,步骤(3)中的服务器安装darknet深度学习框架;配置模型训练 参数包括修改“cfg/voc.data”文件,voc.data中保存了目标检测种类的名称, 修改YOLO系列所对应的cfg文件,cfg文件包含了YOLO系列目标检测算法的网 络结构和网络训练参数、测试参数。根据自己训练样本的种类和硬件的条件修 改种类参数、训练文件路径、测试文件路径、训练批次、anchors大小、卷积核 大小等。所述预训练权重为YOLO系列在Imagenet数据集和COCO数据集下进行 预训练得到的权重,自制的训练样本在预训练模型上进行迁移训练。
(4)封装训练好的迁移训练模型,嵌入ROS系统中。
具体的,将模型封装成ROS的一个节点,提供数据接口,以便被其他节点使 用,可嵌入其他基于机器视觉的研究中;把之前训练好的yolo系列模型文件里 面的cfg文件和weights文件,即yolo系列模型的网络模型和权重文件,分别 放到基于ROS搭建的系统的对应的文件夹下面;通过修改ros.yaml定义订阅的 话题和发布的话题,定义发布图像数据的话题叫“/camera/image”作为yolo_ros 节点的输入,定义目标物体类别名称“/darknet_ros/found_object”、预测框 坐标信息“/darknet_ros/bounding_boxes”、检测结果图片“/darknet_ros/detection_image”三个话题作为输出。
(5)深度摄像头置于待抓取目标上方,深度摄像头采集待检测目标的RGB 彩色图像和深度图像,将采集到的待检测目标的RGB彩色图像输入训练好的迁 移训练模型,计算出待检测目标的二维坐标信息、预测框的大小、类别及置信 度;
具体的,所述步骤(5)中的二维坐标信息包括预测框的左上角坐标 (xmin,ymin)和右下角的坐标(xmax,ymax),与标注的训练样本坐标定义相同,以 图片左上角为原点,向下为y轴正方向,向右为x轴正方向;类别为识别的分 类,置信度有两重定义,一为预测框是否含有对象的概率,二为表示当前的预 测框含有对象时,预测框与标定框可能的IOU值。
(6)结合待检测目标的深度图像信息,经坐标转换计算出待检测目标中心 在彩色摄像头坐标系下的三维坐标。
具体的,如图2所示,检测目标中心由步骤S5封装的ROS节点输出信息坐 标计算获得,待检测目标中心在RGB彩色图像的像素点为 ((xmax-xmin)/2,(ymax-ymin)/2)。
具体的,如图3所示,世界坐标系、彩色摄像头坐标系、深度摄像头坐标系, 世界坐标系用于描述摄像机在环境中的位置,并用它描述环境中的任何物体。 彩色摄像头内参、深度摄像头内参、世界坐标系到深度摄像头坐标系和世界坐 标系到彩色摄像头坐标系的欧式转换矩阵由相机标定所得,相机标定方法采用 最常用的张正友标定法。
步骤(6)中的深度图像素和彩色图像素坐标转换如下步骤:
S1、将深度图像的像素点还原到深度摄像头坐标系下;深度图像的像素点为 (u
S2、将深度摄像头坐标系下的空间点还原到世界坐标系下;定义P
S3、将世界坐标系的空间点转换到彩色摄像头坐标系下;定义
S4、将彩色摄像头坐标系下的空间点映射到Z=1的彩色平面上,映射到z=1 为将各轴的数值按照z轴的值缩放,使z为1;定义
因为彩色图像摄像头和深度摄像头安装位置不同,所以需要转换坐标系使 RGB图像与深度图像坐标信息重合,将目标检测算法识别的中心点的二维信息结 合深度图像的深度值得到待检测目标在彩色坐标系下的三维坐标。定义从深度 摄像头坐标系到彩色摄像头坐标系的欧氏变换矩阵T
以上仅说明给出了详细的实施方式和具体操作过程,旨在对本发明进行详细 说明,但本发明的保护范围不限于此实施方式。
- 一种基于YOLO系列的目标检测和视觉定位方法
- 一种基于改进YOLOV4的密集小目标检测方法