一种图像去雾方法及生成器网络
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及单幅图像去雾技术领域,具体的说,设计了一种图像去雾方法及生成器网络。
背景技术
信息时代,图像处理技术被广泛应用于人脸识别、步态追踪、道路监控、自动驾驶、目标检测、无人机航拍以及空间探索等方面,但图像信息处理系统的性能极易受气候变化的影响。雾霾的存在是因为空气中存在大量的灰尘、水蒸气和大直径悬浮颗粒,这些悬浮粒子的散射作用,使得摄像设备获取的图像对比度降低、颜色失真、细节特征模糊。对户外图像制造了大量噪声,使户外图像出现明显降质。这些退化现象,直接影响了后续的目标检测等任务。
图像去雾可以分为多幅图像去雾和单幅图像去雾。多幅图像去雾根据同一场景在不同时刻、不同天气条件下的多幅图像或同一场景在不同偏振条件下的多幅图像提供的特征信息,对有雾图像进行图像去雾处理。这类算法简单、运行速度快,不仅可以得到更多的有效信息,有利于病态问题的求解,还可以处理一些特殊情况下的图像,例如夜间图像。但是多幅图像去雾需要同一场景的多幅图像信息,在实践中较难获得所需的附加信息或多个图像,所以实用性较低。因此,该类算法在实际生活中不能广泛使用。由于多幅图像去雾局限性较大,所以单幅图像去雾得到了研究者的广泛关注。单幅图像去雾就是通过一定的图像处理技术对单幅图像进行图像增强或图像复原,去除有雾图像中的雾,恢复图像的细节信息,得到视觉效果较好的图像。
目前,图像去雾算法主要可以分为三类:第一类是基于图像增强,基于图像增强的去雾算法有针对的突出图像的有用信息,提高图像质量。这类算法在本质上就是颜色校正和对比度增强,复原后的图像可能发生颜色失真现象。第二类是基于图像复原,基于图像复原的去雾算法通过建立有雾图像的退化模型,反推出图像复原模型。这类算法去雾效果较好,但是要准确估计图像退化模型的中间参数。第三类为基于深度学习的图像去雾算法,例如卷积神经网络应用于图像去雾。
发明内容
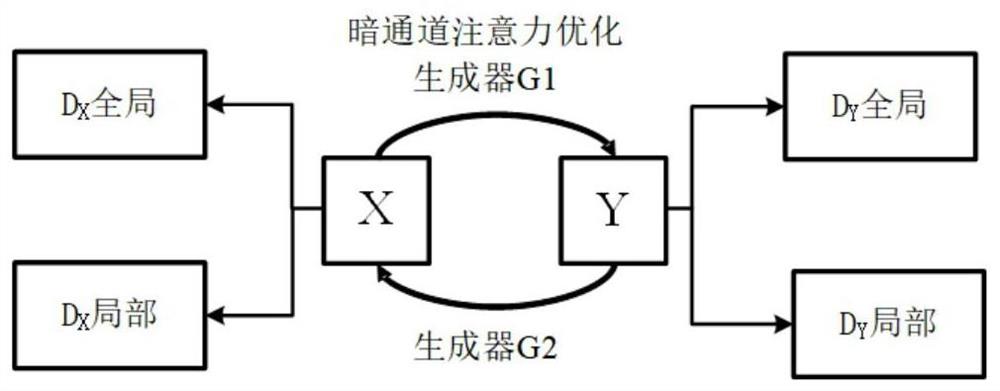
本发明的目的在于针对现有技术的不足,提出一种暗通道注意力优化循环生成对抗网络的图像去雾方法及生成器网络,该方法能去除图像中的雾霾,增加图像视觉性,有效解决雾天条件下图像模糊不清的问题。
为实现上述目的,本发明提出的一种图像去雾方法,通过采用生成器网络实现图像去雾过程,所述方法包括如下步骤:
将输入图像调整为256×256分辨率,有雾图像输入判别器D
将有雾图像、无雾图像分别随机裁剪出四个128×128小块,输入判别器D
获取所述有雾图像的RGB三通道中每个像素位置像素值最低的像素,以得到灰度图,然后以每一个像素为中心,取15x15大小的矩形窗口,将矩形窗口中像素最小值代替中心像素,得到有雾图像暗通道;
将暗通道输入暗通道注意力子网络,得到注意力图;
将有雾图像输入去雾生成器G1,
在生成器与暗通道注意力子网络相同位置,将注意力对生成器输出特征图进行加权处理;
生成器G1输出去雾图像;
其中,所述生成器网络包括去雾生成器G1、加雾生成器G2、判别器D
一种实现方式中,所述去雾生成器G1包括暗通道注意力子网络,编码器结构,中间转换层结构和解码器结构;
所述暗通道注意力子网络含有二十四个卷积层,每层均含有一组64个3×3×1的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个3×3×64的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个1×1×64的卷积核,步幅为1,填充为0,一个Sigmoid激活函数;输入有雾图像暗通道,经过暗通道注意力子网络处理后输出注意力图;
所述编码器结构为三层卷积网络结构包括:第一层卷积层含有64个7×7×3的卷积核;第二层卷积层含有128个3×3×64的卷积核;第三层卷积层含有256个3×3×128的卷积核,步幅为2,填充为1;
所述中间转换层结构为二十四层卷积网络结构,卷积层每层网络结构均串联两组256个3×3×256的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,所得输出与输入相加,然后与暗通道注意力子网络输出的注意力图通过元素乘法进行融合;
所述解码层为五层卷积网络结构,第一层含有256个4×4×256的转置卷积核,第二层含有128个1×1×256的卷积核;第三层含有128个4×4×128的转置卷积核;第四层含有64个1×1×128的卷积核;并在每一个卷积网络后均连接一个BatchNormalizaiton层和ReLU激活函数;第五层含有64个4×4×64的转置卷积核,后接Tanh激活函数,每层转置卷积的输入为前一层网络的输出与对应编码器网络层输出的叠加。
一种实现方式中,所述去雾生成器G1的循环一致损失函数的具体表达为:
L
所述去雾生成器G1的对抗损失函数的具体表达为:
其中,L
一种实现方式中,判别器D
第一层卷积层包含64个4×4×3的卷积核,后接LeakeyReLU激活函数;
第二到第五层网络结构一致,均由4×4尺寸的卷积核以及BatchNormalizaiton层,LeakryReLU激活函数组成,其中卷积核步长为2,填充为1,卷积核个数依次为128-256-512,第六层网络、七层网络结构一致,均由4×4尺寸的卷积核以及BatchNormalizaiton层,LeakryReLU激活函数组成,卷积核个数均为512,第八层为1个4×4×512的卷积层。
一种实现方式中,所述去雾生成器G1的代价函数L计算公式为:
L=αL
其中α,β,γ表示可调参数,L
一种实现方式中,所述去雾生成器G1的输入端为有雾图像X,输出端为无雾图像Y;
所述加雾生成器G2的输出端为有雾图像Y,输入端为无雾图像X;
所述去雾生成器G1的输入端与所述判别器D
所述去雾生成器G1的输出端与所述判别器D
所述加雾生成器G2的输出端与所述判别器D
所述加雾生成器G2的输入端与所述判别器D
此外,本发明还公开了一种生成器网络,其特征在于,包括:
去雾生成器G1、加雾生成器G2、判别器D
所述去雾生成器G1的输入端为有雾图像X,输出端为无雾图像Y;
所述加雾生成器G2的输出端为有雾图像Y,输入端为无雾图像X;
所述去雾生成器G1的输入端与所述判别器D
所述去雾生成器G1的输出端与所述判别器D
所述加雾生成器G2的输出端与所述判别器D
所述加雾生成器G2的输入端与所述判别器D
一种实现方式中,所述去雾生成器G1包括暗通道注意力子网络,编码器结构,中间转换层结构和解码器结构;
所述暗通道注意力子网络含有二十四个卷积层,每层均含有一组64个3×3×1的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个3×3×64的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个1×1×64的卷积核,步幅为1,填充为0,一个Sigmoid激活函数;输入有雾图像暗通道,经过暗通道注意力子网络处理后输出注意力图;
所述编码器结构为三层卷积网络结构包括:第一层卷积层含有64个7×7×3的卷积核;第二层卷积层含有128个3×3×64的卷积核;第三层卷积层含有256个3×3×128的卷积核,步幅为2,填充为1;
所述中间转换层结构为二十四层卷积网络结构,卷积层每层网络结构均串联两组256个3×3×256的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,所得输出与输入相加,然后与暗通道注意力子网络输出的注意力图通过元素乘法进行融合;
所述解码层为五层卷积网络结构,第一层含有256个4×4×256的转置卷积核,第二层含有128个1×1×256的卷积核;第三层含有128个4×4×128的转置卷积核;第四层含有64个1×1×128的卷积核;并在每一个卷积网络后均连接一个BatchNormalizaiton层和ReLU激活函数;第五层含有64个4×4×64的转置卷积核,后接Tanh激活函数,每层转置卷积的输入为前一层网络的输出与对应编码器网络层输出的叠加。
一种实现方式中,所述去雾生成器G1的循环一致损失函数的具体表达为:
L
所述去雾生成器G1的对抗损失函数的具体表达为:
其中,L
一种实现方式中,判别器D
第一层卷积层包含64个4×4×3的卷积核,后接LeakeyReLU激活函数;
第二到第五层网络结构一致,均由4×4尺寸的卷积核以及BatchNormalizaiton层,LeakryReLU激活函数组成,其中卷积核步长为2,填充为1,卷积核个数依次为128-256-512,第六层网络、七层网络结构一致,均由4×4尺寸的卷积核以及BatchNormalizaiton层,LeakryReLU激活函数组成,卷积核个数均为512,第八层为1个4×4×512的卷积层。
本发明与现有技术相比,具有如下优点和有益效果:
1.生成器网络模型直接在有雾图像和无雾图像上进行训练,避免了对合成数据集的需要,且真实图像对模型训练效果更佳。
2.暗通道注意力子网络能够有效引导模型学习,使得到的清晰图像更加真实,同时提高了峰值信噪比,使得去雾后的图像具有很好的视觉效果。
3.本发明具有设计科学、实用性强、操作简便和去雾效果好的优点。
附图说明
图1为本发明图像去雾方法框架;
图2为本发明提出的生成器网络结构;
图3为残差块网络结构;
图4为本发明提出的判别器网络结构;
图5(a)为有雾图像I;
图5(b)为有雾图像I的去雾图像;
图6(a)为有雾图像II;
图6(b)为有雾图像II的去雾图像;
图7(a)为有雾图像III;
图7(b)为有雾图像III的去雾图像;
图8(a)为有雾图像III;
图8(b)为有雾图像III的去雾图像;
图9(a)为有雾图像III;
图9(b)为有雾图像III的去雾图像;
图10(a)为有雾图像III;
图10(b)为有雾图像III的去雾图像;
图11(a)为有雾图像III;
图11(b)为有雾图像III的去雾图像;
图12(a)为有雾图像III;
图12(b)为有雾图像III的去雾图像;
图13为图像去雾方法的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明技术方案作进一步详细描述,所描述的具体实施例仅对本发明进行解释说明,并不用以限制本发明。
本发明所提出的一种图像去雾方法的具体步骤如下:
首先建立暗通道注意力子网络,生成器G1、G2,判别器D
其中生成器G网络模型如图2所示,包括暗通道注意力子网络,编码器结构,中间转换层结构和解码器结构;
暗通道注意力子网络含有二十四个卷积层,每层均含有一组64个3×3×1的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个3×3×64的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个1×1×64的卷积核,步幅为1,填充为0,一个Sigmoid激活函数;输入有雾图像暗通道,经过暗通道注意力子网络处理后输出注意力图;
编码器结构为三层卷积网络结构,每层网络结构之后设置BatchNormalizaiton层和ReLU激活函数;第一层卷积层含有64个7×7×3的卷积核,步幅为1,填充为3;第二层卷积层含有128个3×3×64的卷积核,步幅为2,填充为1;第三层卷积层含有256个3×3×128的卷积核,步幅为2,填充为1;
中间转换层结构为二十四层卷积网络结构,卷积层每层网络结构均串联两组256个3×3×256的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,如图3所示,所得输出与输入相加,然后与经过Sigmoid激活后的暗通道注意分支相同网络层的输出进行元素乘法。
解码器为五层卷积网络结构,第一层含有256个4×4×256的转置卷积核,步幅为2,填充为1;第二层含有128个1×1×256的卷积核;第三层含有128个4×4×128的转置卷积核,步幅为2,填充为1;第四层含有64个1×1×128的卷积核;以上四层卷积网络后均连接一个BatchNormalizaiton层和ReLU激活函数;第五层含有64个4×4×64的转置卷积核,步幅为2,填充为1,后接一个Tanh激活函数。每层转置卷积的输入为前一层网络的输出与对应编码器网络层输出的叠加。
考虑到暗通道注意力输出特征图感受野应与主网络保持一致,因此设计暗通道分支网络结构与主网络编码器、中间转换层结构一致:暗通道注意力子网络共包含二十七层卷积网络结构,每层网络结构之后设置BatchNormalizaiton层和ReLU激活函数;第一层卷积层含有64个7×7×1的卷积核,步幅为1,填充为3;第二层卷积层含有64个3×3×64的卷积核,步幅为2,填充为1;第三层卷积层含有1个3×3×64的卷积核,步幅为2,填充为1;后二十四层网络每层均含有一组64个3×3×1的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数,一组1个3×3×64的卷积核,步幅为2,填充为1,一个BatchNormalizaiton层,一个ReLU激活函数;
生成器G2网络模型无暗通道注意力子网络,其余与生成器G1网络结构一致。
判别器D
结合上图,如图13所示,将输入图像调整为256×256分辨率,有雾图像输入判别器D
对有雾图像计算暗通道:取有雾图像RGB三通道中每个像素位置像素值最低的像素,得到灰度图,然后以每一个像素为中心,取15x15大小的矩形窗口,将矩形窗口中像素最小值代替中心像素,得到有雾图像暗通道;
取有雾图像RGB三通道中每个像素位置像素值最低的像素,得到灰度图,然后以每一个像素为中心,取15x15大小的矩形窗口,将矩形窗口中像素最小值代替中心像素,得到有雾图像暗通道;
将暗通道输入暗通道注意力子网络,得到注意力图;
将有雾图像输入生成器;
在生成器与暗通道注意力子网络相同位置,将注意力对生成器输出特征图进行加权;
生成器输出去雾图像;
将去雾图像输入生成器G2,得到复原图像;
计算循环一致损失函数:
L
计算对抗损失函数:
L
其中α,β,γ表示可调参数,α∈[5,15],β∈[1,2],γ∈[1,2],L
对生成器、判别器进行更新;
判断当前模型是否为最优模型,若否,则继续训练模型;若是,则保存模型;
将有雾图像输入最优生成器模型,得到去雾后的图像。如图5(a)-12(a)所示为输入有雾图像,如图5(b)-12(b)所示为对应去雾后的图像。可以观察到,本发明提出的图像去雾方法去雾彻底,尤其对于浓雾有较好的去除效果,且保留了图像的细节。
最后需要说明的是,以上具体实施方式仅用以说明本专利技术方案而非限制,尽管参照较佳实施例对本专利进行了详细说明,本领域的普通技术人员应当理解,可以对本专利的技术方案进行修改或者等同替换,而不脱离本专利技术方案的精神和范围,其均应涵盖在本专利的权利要求范围当中。
- 一种图像去雾方法及生成器网络
- 一种基于半训练生成器的复杂场景图像去雾方法