一种基于深度学习的橡胶密封圈缺陷检测方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及自动化视觉检测技术领域,特别是涉及一种基于深度学习的橡胶密封圈缺陷检测方法。
背景技术
橡胶密封圈作为一种重要的工业用品,已经是多个行业的基础零部件。橡胶密封圈具备防水、防油、防气、减震等功能,其质量的好坏直接影响到产品的性能和使用寿命,甚至威胁人身财产安全。在所有橡胶圈中,使用最多的为O型橡胶密封圈,其几何形状简单、生产方便、成本低廉,但由于生产技术水平的限制,所生产的橡胶密封圈均会存在一些缺陷,比如尺寸不一、切割不平、表面破损、凹槽等,这些缺陷会直接影响到密封圈的性能,同时也会造成安全问题,给使用客户和生产企业造成巨大的经济损失,因此密封圈出厂前和使用前都必须进行严格的检测。
针对密封圈的上述缺陷检测,目前采用的只是检测毛边缺口等缺陷,极少有检测橡胶密封圈表面破损、凹槽、划痕等相关缺陷的技术,以往通常采用目测法对密封圈进行缺陷检测,通过找到可疑缺陷区域后进一步借助于显微镜等进行复查,这样的检测方法对人的体力提出较高要求,容易出现眼睛疲劳等,而利用目测法来检测相关缺陷则存在较差的稳定性及效率低等问题。
发明内容
本发明目的就是针对现有技术中的不足,提供一种基于深度学习的橡胶密封圈缺陷检测方法,解决现有技术利用人工检测所造成的检测压力大、眼睛易疲劳及目测法存在稳定性差及效率低等问题。为实现以上目的,本发明通过以下技术方案予以实现:
一种基于深度学习的橡胶密封圈缺陷检测方法,包括以下步骤:
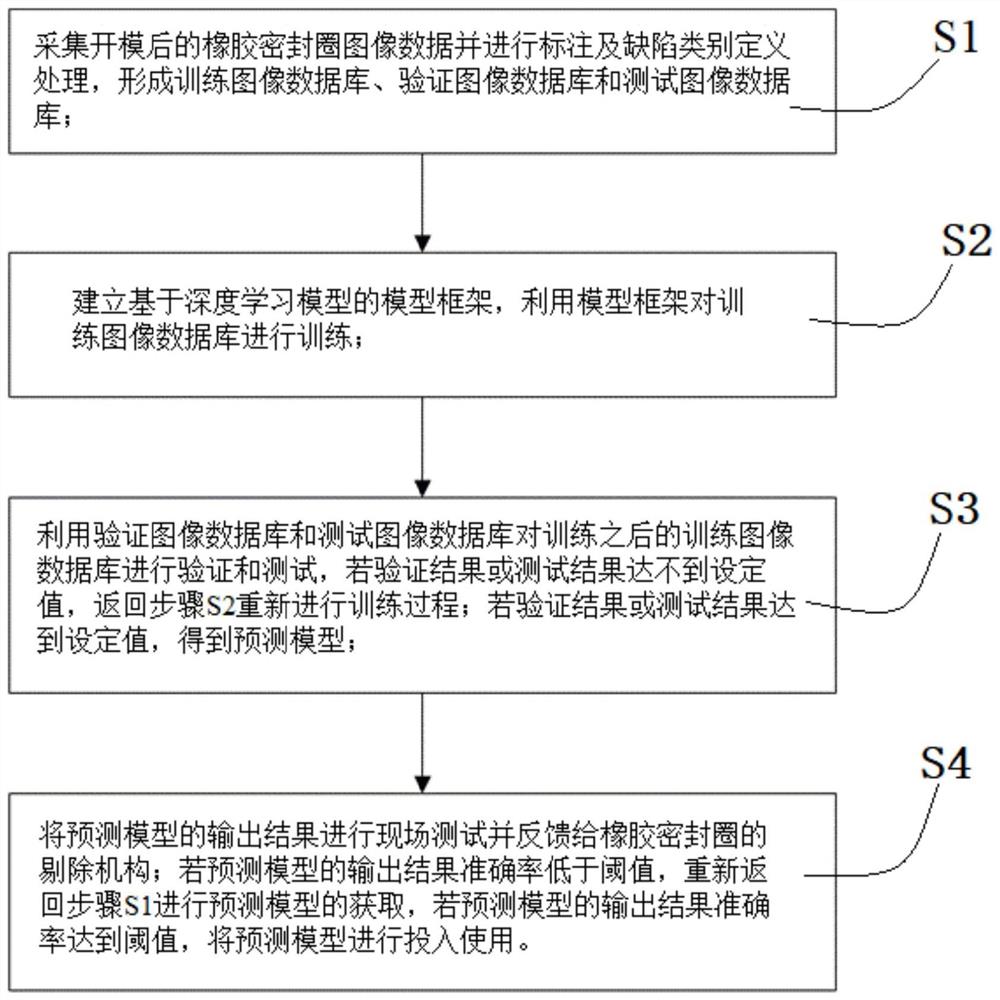
S1、采集开模后的橡胶密封圈图像数据并进行标注及缺陷类别定义处理,形成训练图像数据库、验证图像数据库和测试图像数据库;
S2、建立基于深度学习模型的模型框架,利用模型框架对训练图像数据库进行训练;
S3、利用验证图像数据库和测试图像数据库对训练之后的训练图像数据库进行验证和测试,若验证结果或测试结果达不到设定值,返回步骤S2重新进行训练过程;若验证结果或测试结果达到设定值,得到预测模型;
S4、将预测模型的输出结果进行现场测试并反馈给橡胶密封圈的剔除机构;若预测模型的输出结果准确率低于阈值,重新返回步骤S1进行预测模型的获取,若预测模型的输出结果准确率达到阈值,将预测模型进行投入使用。
优选的,所述步骤S1的具体实施方式为:利用工业相机采集开模后的橡胶密封圈的图像数据,利用labelImg软件对采集到的橡胶密封圈图像数据进行标注和缺陷类别定义处理获得xml文件,对标注和缺陷类别定义处理之后的图像数据xml文件进行分类,形成训练图像数据库、验证图像数据库和测试图像数据库,并生成与训练图像数据库、验证图像数据库和测试图像数据库三者所对应数据库中包含图像文件名的文本train.txt、val.txt及test.txt。
优选的,所述训练图像数据库、验证图像数据库和测试图像数据库中的图像个数比例为7:2:1或6:2:2。
优选的,所述步骤S2中的深度学习模型包括主分支网络、预测分支网络和修正分支网络;所述深度学习模型采用RepPointsV2模型,所述主分支网络为anchor-free目标预测模型。
优选的,所述主分支网络包括特征提取部分和定位部分,所述预测分支网络和修正分支网络嵌入在特征提取部分和定位部分之间。
优选的,所述深度学习模型的损失函数为L=L
本发明的有益效果:
1、本发明的检测方法可解决橡胶密封圈检测效率低稳定性差等问题,提高密封圈产品质量,为企业降低人工成本,并且采用非接触式检测进行橡胶密封圈的缺陷检测,避免了工作环境中刺激性气味、高温等对人员带来的身体伤害,实现在线检测,提高橡胶密封圈的生产效益。
2、传统橡胶密封圈检测采用人工目视检测,误检率较高且效率低下,在开模后温度较高气味较重,本发明检测方法通过深度学习进行训练识别有缺陷的橡胶密封圈,之后对缺陷的产品进行自动剔除,整个装置能够集中化、高效率的完成橡胶密封圈的检测工作,大大减少劳动强度;
3、本发明方法中的预测模型较一般的回归预测模型,添加了预测分支和修正分支,使得模型识别更加精准,回归更有效,并且适用于连续目标变量;通过多任务学习获得更好的功能,通过包含验证提示来增强功能以及通过两种方法进行联合推理,故检测精度更加好。
4、本发明方法中采用anchor-free目标预测模型作为主分支网络,能够达到比anchor-based的目标检测算法更好的识别精度,并且求解回归问题比求解验证问题效率更高;并可以改进FCOS等回归检测器,从而应用到更多的其它模型上协助推理出更好的模型精度,具有广泛的适用性。
附图说明
图1为本发明方法的流程示意图;
图2为本发明主分支网格的定位部位结构示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述:
实施例1:
如图1至图2所示,一种基于深度学习的橡胶密封圈缺陷检测方法,包括以下步骤:
S1、采集开模后的橡胶密封圈图像数据并进行标注及缺陷类别定义处理,形成训练图像数据库、验证图像数据库和测试图像数据库。
其中,上述步骤S1的具体实施方式为:利用工业相机采集开模后的橡胶密封圈的图像数据,利用labelImg软件对采集到的橡胶密封圈图像数据进行标注和缺陷类别定义处理获得xml文件,对标注和缺陷类别定义处理之后的图像数据xml文件进行分类,形成训练图像数据库、验证图像数据库和测试图像数据库,并生成与训练图像数据库、验证图像数据库和测试图像数据库三者所对应数据库中包含图像文件名的文本train.txt、val.txt及test.txt,优选的,训练图像数据库、验证图像数据库和测试图像数据库中的图像个数比例需设置为7:2:1或6:2:2。特别的,本发明上述步骤S1中的分类采用随机分类方法对训练图像数据库、验证图像数据库和测试图像数据库进行分类,且每个数据库中的图像都包含标注和类别。
S2、建立基于深度学习模型的模型框架,利用模型框架对训练图像数据库进行训练。
上述步骤S2中的深度学习模型包括主分支网络、预测分支网络和修正分支网络;其中,深度学习模型采用RepPointsV2模型,主分支网络为anchor-free目标预测模型;主分支网络包括特征提取部分和定位部分,需要将预测分支网络和修正分支网络嵌入在特征提取部分和定位部分之间。
上述深度学习模型的损失函数为L=L
特别的,为更好的理解本发明,具体对步骤S2进行技术解析:
建立深度学习模型,采用训练图像数据库对深度学习模型进行训练;深度学习模型包括主分支网络、预测分支和修正分支。其中,主分支网络包括特征提取部分和定位部分,预测分支和修正分支嵌入在特征提取部分和定位部分之间,训练图像数据库中的图像输入至深度学习模型中,特征提取部分输出特征图;特征图同时进入定位部分、预测分支和修正分支;特征图进入定位部分形成预测框;特征图进入预测分支中的共享卷积层后得到用于预测前景的分热图;特征图进入修正分支中进行角点池化,输出值用于指导预测框的修正。本发明中深度学习模型可以采用RepPointsV2模型,主分支网络可以为anchor-free目标预测模型。
采用RepPointsV2模型作为深度学习模型时,其主分支网络是一个纯回归的anchor-free的目标预测模型,分为用Feature Pyramid Networks(特征金字塔网络)进行多尺度特征提取,然后利用卷积和全连接层进行回归得到目标候选框的左上角点和右下角点的坐标值。为了融合验证方法来增强基于纯回归的模型,添加两个分支,一个分支是利用前景区域的强烈提示来帮助目标候选框的生成,另一个分支是通过conner关角点位置的信息来修正候选框的准确性,前者融合作用在特征层提取后面,后者融合作用在结果层,以此提高模型的精准度。
具体的模型处理流程包括:首先将图像数据转化成224×224大小并输入到网络模型的特征提取部分,利用基于ResNet50残差神经网路的Feature Pyramid Networks提取多尺度的特征,参见图2所示的定位部分结构图,其目的是为了改进CNN网络的特征提取方式,从而使最终输出的特征更好的表示出输入图片各个维度的信息;它的基本过程有三个,分别为自下至上的通路,即自下至上的不同维度特征生成,每个阶段利用卷积和池化,特征图尺度减半,获得更深层的语义信息,conv2到conv5的的维度分别是64,128,256,512;自上至下的通路,即自上至下的特征补充增强,通过融合深层的语音信息,CNN网络层特征与最终输出的各维度特征之间的关联表达,获得P2,p3,p4,p5四个不同尺度的特征图输出,他们拥有相同的维度,都是256;在得到特征图后,特征图会进入定位部分,定位部分需要完成定位任务和分类任务,定位任务实施过程特征图即经过三个共享3×3卷积,维度256,然后通过一个3×3×256和1×1×18的卷积得到分类任务的可变形卷积的卷积核索引点的偏移量offsets1,对偏移后的每组reppoints1生成预测框,利用SmoothL1Loss公式计算和真值之间的损失:
其中,σ
分类任务则将三个共享卷积的输出和offsets1输入到预测分支,经过一个3×3×256的可变形卷积,然后经过1×1×18的卷积降为成18个维度,分别代表每个卷积核对应点的x和y轴的索引点偏移量,输出得到offsets2,然后加上offsets1的偏移量,得到最后的reppoints2,以9个点为一组候选框预测点的特征点,然后通过前两个点设置为左上和右下两个极值点,进而可以转化成预测候选框,转换函数为:
同样利用SmoothL1Loss来计算预测框和真值之间的损失值,用于反向传播;至此,是主分支网络的训练结构步骤。
本发明中预测分支利用前景区域的强烈提示来帮助目标候选框的生成,通过将Feature Pyramid Networks特征提取后的多尺度特征图结果经过一个共享3×3的支路共享卷积操作,然后再经过一个1×1的卷积操作得到用于预测前景得分热图,嵌入到主分支过程的FPN特征提取之后,用于加强前景的预测。
本发明中修正分支利用角点验证的操作将一个分数与特征图中的每个点关联起来,表明它是一个角点的概率,做法是同样和分支一一样的输入,通过将FPN特征提取后的多尺度特征图结果作为输入,经过一个角点池化,然后经过一个1×1的卷积,最后将输出和主分支网络的offset1进行concat指导预测框的进一步修正,用于预测热图得分和亚像素偏移量,以修正预测框的准确性。
鉴于本发明中深度学习模型包含主分支网络、预测分支和修正分支,所以在训练中,我们设置深度学习模型的损失函数L=L
S3、利用验证图像数据库和测试图像数据库对训练之后的训练图像数据库进行验证和测试,若验证结果或测试结果达不到设定值,返回步骤S2重新进行训练过程;若验证结果或测试结果达到设定值,得到预测模型。
特别的,对上述步骤S3进行技术解析:
在训练过程中,网络的训练参数如下:Batch size=32,num_classes=9,Learning rate=lr=0.0025,total_epochs=20,Iteration=5000,score_thr=0.05;通过指令python tools/train.py${CONFIG_FILE}[optional arguments]可开始训练。训练完成之后得到学习到数据的pth权重文件,可通过指令python tools/test.py${CONFIG_FILE}${CHECKPOINT_FILE}[--out${RESULT_FILE}][--eval${EVAL_METRICS}][--show]测试模型的训练实际效果,观察输出的预测图像可检查训练时有待优化的地方。
预测模型在正式应用之前需要进行测试,将之前准备的测试图像数据库中的图像输入到训练完成之后的模型中进行预测,然后查看所有的预测效果,检查是否有出现没有预测到的目标,或是预测框出现重叠,又或是预测框的精度不高等问题,当出现问题时,可对应的增加数据集样本数据量或检查数据标注文件的信息是否出现错误或检查数据增强是否影响了模型的学习。
S4、将预测模型的输出结果进行现场测试并反馈给橡胶密封圈的剔除机构;若预测模型的输出结果准确率低于阈值,重新返回步骤S1进行预测模型的获取,若预测模型的输出结果准确率达到阈值,将预测模型进行投入使用。
上述预测模型的输出结果即为存在缺陷的橡胶密封圈,之后在剔除机构中对这些有缺陷的橡胶密封圈进行剔除,通过将预测模型加载在剔除机构中并进行现场测试,如果现场测试的预测效果比较差就需要重新检查现场环境是否发生变化而导致数据的环境和训练的数据库有差异,或预测阈值是否需要调整等问题,直到现场预测稳定之后,该预测模型才能用以进行橡胶密封圈缺陷检测。
对本领域的技术人员来说,可根据以上描述的技术方案以及构思,做出其它各种相应的改变以及形变,而所有的这些改变以及形变都应该属于本发明权利要求的保护范围之内。
- 一种基于深度学习的橡胶密封圈缺陷检测方法
- 一种基于深度学习的预制棒外观缺陷自动化检测方法