一种兼容实时和离线数据处理的存储架构方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及数据处理技术领域,具体的,本发明涉及一种兼容实时和离线数据处理的存储架构方法。
背景技术
在大数据应用中,数据存储底层系统需要高效的进行实时数据处理、离线计算处理以及数据分析等多功能应用,同时对数据访问时效、数据访问量及数据并发能力承载亦需提供强有力的支撑,随着数据的大量积累,会出现诸如数据质量不高、数据处理时效低等问题,如何高效解决数据的实时增量更新、满足实时数据的聚合计算性能需求和离线储存,成为急需解决的问题。
发明内容
为了克服现有技术的不足,本发明提供了一种兼容实时和离线数据处理的存储架构方法,以解决上述的技术问题。
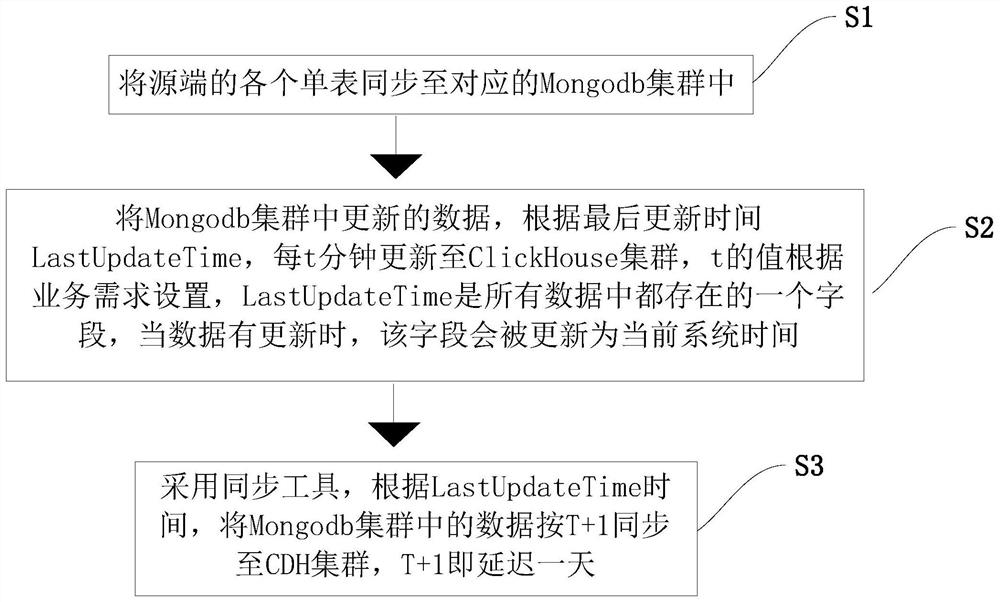
本发明解决其技术问题所采用的技术方法是:一种兼容实时和离线数据处理的存储架构方法,其改进之处在于:包括以下的步骤:S1、将源端的各个单表同步至对应的Mongodb集群中;S2、将Mongodb集群中更新的数据,根据最后更新时间LastUpdateTime,每t分钟更新至ClickHouse集群,t的值根据业务需求设置,LastUpdateTime是所有数据中都存在的一个字段,当数据有更新时,该字段会被更新为当前系统时间;S3、采用同步工具,根据LastUpdateTime时间,将Mongodb集群中的数据按T+1同步至CDH集群,T+1即延迟一天。
在上述方法中,所述Mongodb集群中的数据生命周期,根据业务需求设置。
在上述方法中,所述单表包括但不限于流水表、维表和宽表。
在上述方法中,所述Mongodb集群包括但不限于流水表集群、维表集群和宽表集群,
流水表集群即ods层数据存储集群,该数据与数据源端一致;
维表集群即dim层数据存储集群,是维度层;
宽表集群即dwd层数据存储集群,由ods层数据和dim层数据关联生成的业务聚合宽表。
在上述方法中,所述单表中的流水表和宽表,采用Kafka消息服务器,通过ETL消费的处理后,落地至相应的流水表集群和宽表集群,ETL消费是对数据进行抽取Extract、清洗Cleaning、转换Transform和装载Load的过程。
在上述方法中,所述流水表,落地至相应的流水表集群,包括以下的步骤:
S401、在Kafka消息服务器的消费端,将流水表数据做实时的ETL处理;
S402、Kafka消息服务器的消费程序每消费一条数据即落地至对应的流水表集群,生成ods层数据。
在上述方法中,所述宽表,落地至相应的宽表集群,包括以下的步骤:
S501、在Kafka消息服务器的消费端,将ods层数据和dim层的数据做实时的ETL处理;
S502、kafka消息服务器的消费程序每消费一条数据即完成一个业务sql,sql即数据库标准语言,生成一条业务宽表,即dwd层数据。
在上述方法中,所述CDH集群存储于大磁盘空间服务器。
本发明的有益效果是:本发明通过实时拉取增量数据,满足实时数据的聚合计算性能需求,实现了实时增量数据的存储,并且通过将数据按T+1同步至CDH集群,实现了离线数据的存储;并且数据生命周期随业务需求调整,有效提升了明细数据查询处理的能力。
附图说明
附图1为本发明的一种兼容实时和离线数据处理的存储架构方法的流程图。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参照图1,本发明的一种兼容实时和离线数据处理的存储架构方法,包括以下的步骤:
S1、将源端的各个单表,单表包括流水表、维表和宽表等等,使用同步工具同步至对应的Mongodb集群中,Mongodb集群包括流水表集群、维表集群和宽表集群等等,流水表落地至相应的流水表集群,维表落地至相应的维表集群,宽表落地至相应的宽表集群,比如Oracle可采用Ogg同步,Mysql可采用Canal同步;
流水表集群即ods层数据存储集群,也叫ods贴源层,是跟数据源端一致的数据,在ODS层的主要数据为交易系统订单流水详情,这些数据未经处理,是最原始的数据;维表集群即dim层数据存储集群,是维度层,由各项维度表构建的数据层,一般为比较固定的数据,如城市信息、商户信息和库存信息等等;宽表集群即dwd层的数据存储集群,由ods层数据和dim层经过ETL生成的数据,这层是至少一张ods层数据和dim层关联生成的业务聚合宽表,将相同主题的数据汇集到一张表中,提高数据的可用性。
进一步的,流水表中的部分对数据实时要求高的流水表,以及需进一步加工处理的宽表,可采用高吞吐量的Kafka消息服务器,通过ETL消费的方式处理后,落地至相应的流水表集群和宽表集群,ETL消费是对数据进行抽取Extract、清洗Cleaning、转换Transform和装载Load的过程,
具体地,将流水表通过ETL消费,落地至流水表集群,包括以下步骤:
S401、在Kafka消息服务器的消费端,将流水表数据做实时的ETL处理;
S402、Kafka消息服务器的消费程序每消费一条数据即落地至对应的流水表集群,生成ods层数据。
将宽表通过ETL消费,落地至宽表集群,包括以下的步骤:
S501、在Kafka消息服务器的消费端,将ods层数据和dim层的数据做实时的ETL处理;
S502、kafka消息服务器的消费程序每消费一条数据即完成一个业务sql,sql即数据库标准语言,生成一条业务宽表,即dwd层数据。
进一步的,为确保数据实时更新及数据质量问题,可根据业务特点确定Mongodb集群中的数据生命周期,如支付行业可设置180天,减少数据生命周期,自然数据会随之减少,结合分集群的特点,可进一步提升明细数据查询处理能力。
S2、将Mongodb集群中更新的数据,根据最后更新时间LastUpdateTime,每t分钟更新至ClickHouse集群,t的值根据业务需求设置,比如t=5时,则为5分钟,LastUpdateTime是所有数据中都存在的一个字段,当数据有更新时,该字段会被更新为当前系统时间,用于拉取增量数据,实现了实时增量数据的存储;
具体的,将流水表集群、维表集群和宽表集群的数据通过增量字段即LastUpdateTime,每隔5分钟一次,拉取5分钟的增量数据同步至clickhouse集群中,clickhouse集群保存1年的数据生命周期。如此,一方面可以保障数据实时聚合的需要,满足实时数据的聚合计算性能需求;另一方面可保存近1年的历史数据,供用户查询数据信息。
S3、采用同步工具,比如Sqoop和Data X等,根据LastUpdateTime时间,将Mongodb集群中的数据按T+1同步至CDH集群,T+1即延迟一天,保证数据的稳定性,满足离线计算需求,且CDH中可保留历年历史数据,保留数据周期根据业务确定,也可保留所有历史数据,实现了离线数据的存储。
进一步的,由于CDH集群保留数据量大,将CDH集群存储在大磁盘空间服务器。进一步的,对时间比较久远的数据的查询需求,提供专门的查询平台去受理。
本发明通过实时拉取增量数据,满足实时数据的聚合计算性能需求,实现了实时增量数据的存储,并且通过将数据按T+1同步至CDH集群,实现了离线数据的存储;并且数据生命周期随业务需求调整,有效提升了明细数据查询处理的能力。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 一种兼容实时和离线数据处理的存储架构方法
- 一种实时和离线大数据处理系统、方法、存储介质及终端