一种基于多智能体强化学习的无人机集群高效通信方法
文献发布时间:2023-06-19 12:16:29
技术领域
本发明涉及一种基于多智能体强化学习算法的无人机集群学习方法和无人机集群信息交互方法,属于无人机集群通信协作技术领域。
背景技术
随着科技的迅猛发展,无人机越来越小型化、智能化,因此被广泛应用于战场侦查、联合攻击、应急救援等行动。无人机集群较单架无人机具有明显的规模优势、协同优势等,有效地解决了单架无人机在效率、续航方面的局限性。目前大部分无人机集群的解决方案都是依赖于深度强化学习。深度强化学习是机器学习的一个分支,是一种通过与环境进行交互试错学习的学习范式。强化学习具有很强的鲁棒性,其核心是与环境交互进行迭代学习,他的两大基本特征是:与环境不断交互进行试错探索、在与环境交互后得到延迟回报。强化学习的目的是在迭代过程中获取新的知识,以此改进状态-动作函数来适应环境。
无人机集群无论是协同训练还是共同部署,各无人机之间的通信方案都是无人机集群解决方案的重要组成部分。现有的无人机集群信息交互的控制策略中,一般有集中式控制、分布式控制和分散式控制三种方式,各种方式各有优缺点。其中集中式控制效果最好,但是需要进行大量的信息交互,计算量大,通信效率低,并且无人机集群在该方法下往往缺乏灵活性和自治性。
为了提升无人机集群间的通信效率,学界提出了诸多方法,例如中心化训练去中心化执行的框架,但该方法忽略了物理层的安全性。中心化训练去中心化执行的框架包括Actor网络和Critic网络,对每个agent的强化学习都考虑其他agent的动作策略,进行集中式训练、分布式执行,在训练过程中,Critic网络可获得全局信息,执行过程中Actor的输入包含单个智能体的局部信息。将中心化训练去中心化执行的框架应用在无人机集群控制能避免无人机集群失去自治性,各无人机能根据自己传感器所获取的局部信息进行决策,实现一定的自治能力。然而在基于中心化训练去中心化执行的框架的无人机集群中,若每架无人机都要将自己的位置、速度、姿态和运动目标等信息和编队中所有无人机进行交互,这不仅浪费带宽,而且信息容易被敌人获取。
发明内容
发明目的:为了解决基于中心化训练去中心化执行的框架的无人机集群中采用集中式信息交互方式通信效率低、通信不安全的缺点,基于前述提到的多智能体强化学习算法在无人机集群中的背景,本发明提出一种基于多智能体深度强化学习框架的无人机集群高效通信方法。在集群中,采取“队长-队友”模式,为队长设计特定的奖励机制,保证队长存活时间最长,随后对无人机集群进行编号并选取一名队长,每架无人机通过自身传感器获取并维护本机的局部观测值。为降低信息维度,每架无人机对本机观测值进行embedding编码,队长收集队友的本机观测值并维护成全局观测值;为减少搜索空间,提高全局观测值信息间的紧密性,队长根据每架无人机的自身观测值对全局观测值进行注意力机制处理,将计算好的观测值发送给每个队友,作为队友的全局观测值。本发明方案将通信次数由N(N-1)降低为2(N-1)(N为无人机架数),大大减少通信链路和通信量,从而可以较好的解决通信效率和安全的问题。
技术方案:一种基于多智能体强化学习的无人机集群高效通信方法,包括:(1)构建无人机飞行环境模拟器;(2)在无人机集群中,随机选取一架无人机作为队长并标记,其余无人机为队友;(3)队长为观测值中转站,队长收集队员自身局部观测值并维护成全局观测值,发送给队友进行信息交互;(4)基于中心化训练去中心化执行的框架进行,例如MADDPG算法、QMIX算法MADDPG框架进行无人机动作的训练和执行,训练阶段以全局观测值作为训练数据,直到策略网络收敛;执行阶段以分布式的方式进行,即每个无人机将自身的局部观测值送到策略执行网络中,得到相应的动作;(5)为了维护队长不被针对攻击,通过奖励函数对队长的存活给一个额外的奖励。
所述(1)中,基于仿真环境引擎构建基于空气动力学的无人机飞行环境模拟器。
所述(3)中,每架无人机获取并维护本机的局部观测值,将自身局部观测值进行编码并发送给队长;由于无人机自身观测值构成的全局观测值中信息的重要程度是不一致的,队长根据每架无人机的自身局部观测值,分别对全局观测值进行attention注意力机制处理,根据信息的重要程度来决定信息的权重,继而将计算好的观测值发送给每个队友,作为队友的全局观测值,减少探索空间,从而提高学习效率,构建联系更加紧密的全局观测值。
同时为进一步降低带宽消耗,每架无人机对自身局部观测值o
初始阶段,无人机信息匮乏,此时无人机可根据自身的局部观测值o
在训练阶段,为保障无人机集群通信的安全性,整个协作过程中队长需要存活到最后,从而设计特定的奖励函数,所述奖励函数包括:过程奖励函数
注意力机制功能包含三个基本元素:query,key,value,其中query代表给定的元素,
在无人机飞行环境模拟器中,无人机集群与环境交互,获取训练数据。每个无人机获取局部观测值,根据自身的动作策略采取动作,获得奖励值。将以上获得的全局观测值、动作、奖励组成的元组存储到经验回放池
在训练阶段,对评价网络Critic网络进行中心化训练,其联合Q值函数定义为
在训练阶段,通过梯度下降法训练建议策略,最大化累计奖励
优化目标为:
在执行阶段,通过将本机的局部观测值送到策略执行网络中,得到相应的动作。
有益效果:与现有技术相比,本发明提供的基于多智能体强化学习的无人机集群高效通信方法,采用深度强化学习算法使无人机获得来自环境的奖励,具备自主决策能力,实现比传统基于规则的控制方式更高的无人机集群飞行控制;
本发明通过多智能体深度强化学习算法实现无人机集群自主控制,能有效解决集中式信息交互方式带来的问题,使无人机具备自治能力;
本发明将集中式信息交互中控制中心的决策权剥离出来,交由每架无人机自主决策,并采用基于中心化训练去中心化执行的框架,集中式训练、分布式执行,有效解决无人机集群通信计算量、自治等问题。
本发明对局部观测值进行编码处理,有效降低信息的维度,从而可以减少带宽消耗;对全局观测值进行注意力机制处理,体现出不同信息的重要程度,减少探索空间,从而提高学习效率。
附图说明
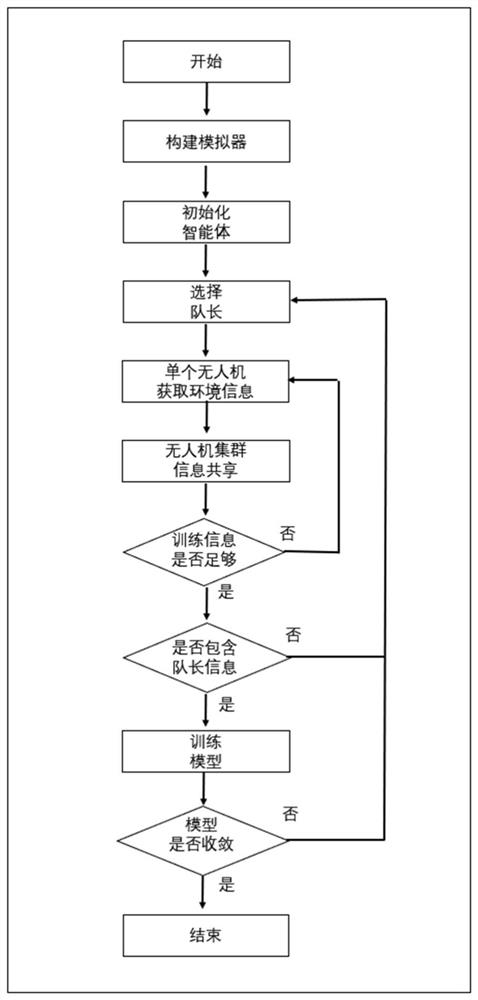
图1是本发明方法的流程图;
图2是无人机集群与环境交互示意图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
首先结合图1简述本发明方法的主要流程。实验开始,构建无人机飞行环境模拟器,同时对智能体无人机进行初始化,之后选择队长并进行标记。起始每架无人机获取环境信息,再与无人机集群进行信息共享,之后判断训练信息是否足够。如果信息不足够则每架无人机继续获取环境信息,如果足够则判断信息中心是否包含队长信息;如果没有队长信心则重新选择队长,如果包含队长信息则训练模型;继而判断模型是否收敛,如果没有收敛则重新选择队长,如果模型收敛则本次训练结束。
同时根据图2描述无人机集群与环境交互的过程。每架无人机与环境进行交互,无人机获得环境信息,并在环境中施加动作,之后无人机将获得环境信息进行embedding嵌入编码,队员将编码后的信息发送给队长,队长将训练信息放入注意力机制中,给信息加上权重,之后放入模型中进行训练,模型将训练后的数据部署在智能体(即无人机),智能体和环境进行交互,进行下一轮的训练,如此循环。
在具体实施例中,通过伪代码进一步详细介绍本发明方法。
算法1基于多智能体强化学习的无人机集群协作算法
输入:智能体结构,注意力网络,环境信息,其他模型训练参数
输出:每个智能体策略网络的结构和权重
1:根据无人机飞行物理环境构建模拟器
2:初始化各智能体
3:while策略模型尚未收敛do
4:按照一定策略从各智能体中选出队长
5:while训练信息积累未达阈值do
6:智能体与环境模拟器进行交互,积累交互信息
7:各队员将自身积累的交互信息做embedding
8:各队员将embedding后的数据发送给队长
9:队长收集并处理数据,通过attention机制赋予信息不同的权重
10:end while
11:校验队长相关信息是否合法
12:if队长信息不合法then
13:放弃本轮迭代积累的训练数据
14:continue
15:end if
16:利用新增数据训练策略模型
17:按照优化目标
18:end while
首先,构建环境模拟器。基于仿真环境引擎构建基于空气动力学的无人机飞行环境模拟器。本实施例包含三架合作无人机,可以方便的拓展到多架无人机集群中。设计奖励函数。三架合作无人机中包含的角色有队长和队员,为保障无人机集群通信的安全性,整个协作过程中队长需要存活到最后,从而设计特定的奖励函数为:过程奖励函数
其次,对三架合作无人机进行初始化并进行编号
步骤1:
在训练阶段,无人机x、y、z与环境进行交互,通过自身传感器(传感器组合)获取局部观测值,然后将自身观测值作为embedding层的输入,输出编码后的自身观测值
步骤2:
队长收集队友编码后的自身观测值,将自己的局部观测值与来自队友的局部观测值整合成全局观测值
步骤3:
设计神经网络结构、选择神经网络超参数,搭建神经网络。
例如,一个策略网络可以包括5层全连接神经网络,每层神经网络使用relu函数作激活函数。
步骤4:
依据中心化训练去中心化执行框架的训练流程,使用当前飞行控制策略在模拟器中训练飞行控制策略,直到模型收敛。
步骤5:
按照中心化训练去中心化执行框架的执行流程,通过将获取的局部观测值送到策略执行网络(收敛之后获得的模型)中,得到相应的动作。
在无人机飞行环境模拟器中,无人机集群与环境交互,获取训练数据。每个无人机获取局部观测值,根据自身的动作策略
步骤4中,对Critic网络进行中心化训练,其联合Q值函数定义为
梯度下降法训练建议策略,最大化累计奖励
- 一种基于多智能体强化学习的无人机集群高效通信方法
- 一种基于多智能体强化学习的无人机集群协同学习方法