一种融合双语词典的蒙汉神经机器翻译方法
文献发布时间:2023-06-19 13:26:15
技术领域
本发明属于神经机器翻译技术领域,特别涉及一种融合双语词典的蒙汉神经机器翻译方法。
背景技术
机器翻译技术是研究如何利用计算机高效便捷的实现源语言到目标语言的自动转换,是计算语言学的重要研究领域之一。我国是一个多民族国家,各民族都有自己的语言,因此打破语言之间的交流障碍、促进民族交流尤为重要。内蒙古自治区使用蒙古语的人数较多,对于蒙古语文字与汉语文字之间的翻译有着迫切地需求,因此蒙汉翻译具有十分重要的意义。相对于其它语种,蒙汉机器翻译研究起步较晚,且蒙古语汉语分属于不同语系,机器翻译的译文质量不尽如人意。
随着深度学习的不断发展,基于深度学习的神经网络机器翻译模型成为机器翻译的研究热点。神经网络翻译模型是基于词、短语和句子的连续表示,连续的词向量可以更准确的表示词的形态、语义和语法信息,能够精确地刻画近义词之间的关系。由于神经网络本身结构的复杂性,通常编解码端的词汇表大小都不宜过大,否则会使得模型过于庞大,大大降低模型的训练速度。此外,低频词的加入反而可能降低网络的性能表现。规模受限的词表引入了大量的罕见词或未登录词,导致其在翻译对理解句子意义至关重要的低频内容词时经常出错。
发明内容
(一)解决的技术问题
针对现有技术的不足,本发明的目的在于提供一种融合双语词典的蒙汉神经机器翻译方法,通过在NMT系统中增加离散的翻译词典,有效地编码低频词的翻译。
(二)技术方案
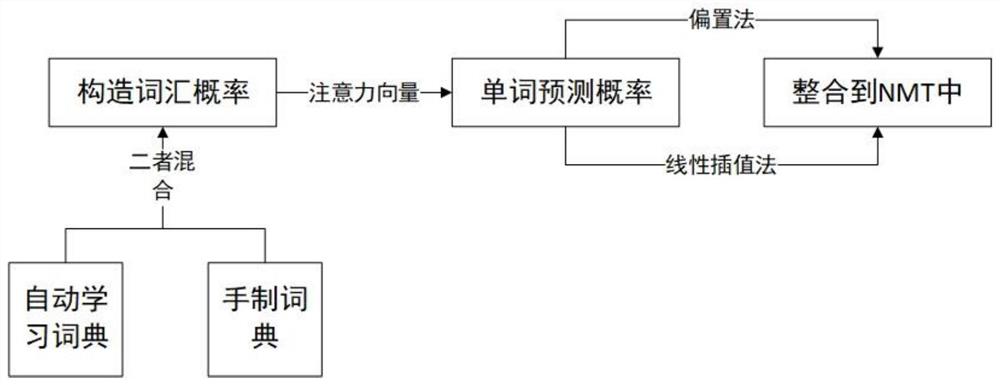
为实现以上目的,本发明通过以下技术方案予以实现:一种融合双语词典的蒙汉神经机器翻译方法,通过在NMT系统中增加离散的翻译词典,有效地解决NMT在翻译低频实词时经常出错的问题。本发明包括以下步骤:步骤一、对训练数据、其他外部并行数据资源(如手制字典)或两者结合,使用传统的单词对齐方法来构造这些词汇概率;步骤二、使用注意力NMT模型中的注意力向量,将词典翻译概率转换为下一个单词的预测概率;步骤三、通过NMT概率的线性插值,或者将其作为NMT预测分布的偏差,将该概率纳入NMT。
步骤一中使用三种方式构造词典概率,分别为自动学习词典,手制词典与混合词典。自动学习词典的词典概率直接使用IBM之类的翻译模型从平行语料库中通过无监督的方式进行学习。这些模型可以使用期望最大化(EM)算法估计两种语言标记之间的词对齐和词法转换概率p
NMT受训练速度与内存的约束,导致许多罕见词未被目标词表V
手制词典不包含翻译概率,为构造概率p
未登录源词将其概率质量分配给
手制词典的词汇覆盖率更高,但其概率不如自动学习词典的精确。故构造一种混合方法,将手制词典补充到自动学习词典中,默认使用自动学习词典p
步骤二中,神经机器翻译的目标是将源单词序列
其中W
步骤二中的神经机器翻译选用注意力模型。注意力模型在计算y
注意力机制的步骤一中,注意力模型在计算y
其中,embed()函数将单词映射为一个表示(通常使用向量进行表示),enc()是一个堆栈式LSTM神经网络。最后将
注意力机制的步骤二参考编码后的输入句子一次生成一个输出单词,并使用解码器LSTM跟踪整个过程。解码器的隐藏状态h
α
sim()为任一相似度函数,此处使用向量的点积。之后将α
a
然后,使用注意力向量a
c=Ra
注意力机制的步骤三通过连接先前的隐藏状态h
η
将上式代入方程(1),便可计算出
h
若将所有参数定义为θ,则可通过最小化训练数据的负对数似然来训练本模型
本发明的步骤三包含两个步骤:步骤一、将词典概率转换为条件预测概率;步骤二、合并预测概率。
将词典整合到NMT中的步骤一首先将源句子X中单个单词的词典概率p
由于仅需要源句子X的信息,上述矩阵可以在编码阶段预先计算出来。接下来将这个矩阵转换为下一个单词的预测概率
计算词汇预测概率
第一种整合方式:偏置方法,使用p
对p
第二种整合方式通过在标准NMT模型概率p
其中λ为插值系数,
(三)有益效果
本发明提供了一种融合双语词典的蒙汉神经机器翻译方法,其有益效果为,该融合双语词典的蒙汉神经机器翻译方法,NMT系统的一个特点是,其将词汇表中的每个单词视为连续值数字的向量,这与传统的SMT模型相反,连续表示的使用是一个主要优势,它允许NMT在相似的单词或上下文之间共享统计权重,但它的缺点为容易产生流畅但不充分的翻译,相反,基于短语的机器翻译和其他传统统计机器翻译方法很少出现这种错误,这是因为它们的翻译基于离散短语映射,这确保源单词将被翻译成至少在训练数据中观察到一次翻译的目标单词,此外,由于离散映射是显式记忆的,因此只需一个实例就可以有效地学习它们(排除单词对齐中的错误),故将离散的双语词典信息合并到NMT中,可以缓解低频实词产生的致命错误。
附图说明
图1为本发明的方法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明实施例提供一种技术方案:一种融合双语词典的蒙汉神经机器翻译方法,通过在NMT系统中增加离散的翻译词典,有效地编码低频词的翻译。
为实现上述目的,本发明采用的技术方案是:
一种融合双语词典的蒙汉神经机器翻译方法,通过在NMT系统中增加离散的翻译词典,有效地解决NMT在翻译低频实词时经常出错的问题。本发明包括以下步骤:步骤一、对训练数据、其他外部并行数据资源(如手制字典)或两者结合,使用传统的单词对齐方法来构造这些词汇概率;步骤二、使用注意力NMT模型中的注意力向量,将词典翻译概率转换为下一个单词的预测概率;步骤三、通过NMT概率的线性插值,或者将其作为NMT预测分布的偏差,将该概率纳入NMT。
步骤一中使用三种方式构造词典概率,分别为自动学习词典,手制词典与混合词典。自动学习词典的词典概率直接使用IBM之类的翻译模型从平行语料库中通过无监督的方式进行学习。这些模型可以使用期望最大化(EM)算法估计两种语言标记之间的词对齐和词法转换概率p
通过交替使用这两个步骤,EM算法逐步改进模型的参数,使参数和训练样本的似然概率逐渐增大,最后终止于一个极大点。
NMT受训练速度与内存的约束,导致许多罕见词未被目标词表V
手制词典不包含翻译概率,为构造概率p
未登录源词将其概率质量分配给
手制词典的词汇覆盖率更高,但其概率不如自动学习词典的精确。故构造一种混合方法,将手制词典补充到自动学习词典中,默认使用自动学习词典p
步骤二中,神经机器翻译的目标是将源单词序列
其中W
步骤二中的神经机器翻译选用注意力模型。注意力模型在计算y
注意力机制的步骤一中,注意力模型在计算y
其中,embed()函数将单词映射为一个表示(通常使用向量进行表示),enc()是一个堆栈式LSTM神经网络。最后将
注意力机制的步骤二参考编码后的输入句子一次生成一个输出单词,并使用解码器LSTM跟踪整个过程。解码器的隐藏状态h
α
sim()为任一相似度函数,此处使用向量的点积。之后将α
a
然后,使用注意力向量a
c=Ra
注意力机制的步骤三通过连接先前的隐藏状态h
η
将上式代入方程(1),便可计算出
h
若将所有参数定义为θ,则可通过最小化训练数据的负对数似然来训练本模型
本发明的步骤三包含两个步骤:步骤一、将词典概率转换为条件预测概率;步骤二、合并预测概率。
将词典整合到NMT中的步骤一首先将源句子X中单个单词的词典概率p
由于仅需要源句子X的信息,上述矩阵可以在编码阶段预先计算出来。接下来将这个矩阵转换为下一个单词的预测概率
计算词汇预测概率
第一种整合方式:偏置方法,使用p
对p
第二种整合方式通过在标准NMT模型概率p
其中λ为插值系数,
- 一种融合双语词典的蒙汉神经机器翻译方法
- 一种基于融合统计机器翻译模型的蒙汉神经机器翻译方法