一种基于随机森林回归的农田氮淋失预测方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及氮淋失预测技术领域,具体涉及一种基于随机森林回归的农田氮淋失预测方法。
背景技术
随着以高水肥投入为主要特征的农业集约化进程的发展,我国农田氮淋失现象逐步加重,面源污染问题日渐突出。氮淋失是土壤中氮素随土壤水分向下运移直至进入到作物根区无法到达的区域,最终不能被作物吸收所导致的损失,农田氮淋失会造成地下水硝酸盐含量不断上升,对地下水及饮用水安全构成威胁。因此对氮淋失量进行预测是一项极其重要的工作,可为区域面源污染防控及管理工作提供决策依据,有利于推动农业绿色发展和生态文明建设。
目前,常见的氮淋失量预测模型主要包括指数模型、线性模型、DNDC模型(农业生态系统中碳和氮生物地球化学的计算机模拟模型)等。其中,基于指数模型、线性模型的预测方法常选取单个氮淋失的影响因素(例如施氮量、水分投入量)进行模拟,实际生产中氮素淋失还会受到耕作措施、种植制度、土壤性状、农作物种类及气象条件等的影响,预测效果并不理想;而基于DNDC模型的预测方法是将氮素转化与水文过程相结合模拟氮素淋溶,建模时需要进行校准验证、敏感性分析等操作,预测流程更为复杂且结果容易受到不同深度土壤异质性的影响。
因此,为了解决上述模型的不足,本申请设计了一种基于随机森林回归的农田氮淋失预测方法,实现预测精度高、简单、有效的农田氮淋失预测方法。
发明内容
本发明的目的是填补现有技术的空白,提供了一种基于随机森林回归的农田氮淋失预测方法,实现预测精度高、简单、有效的农田氮淋失预测方法。
为了达到上述目的,本发明提供一种基于随机森林回归的农田氮淋失预测方法,包括以下步骤:
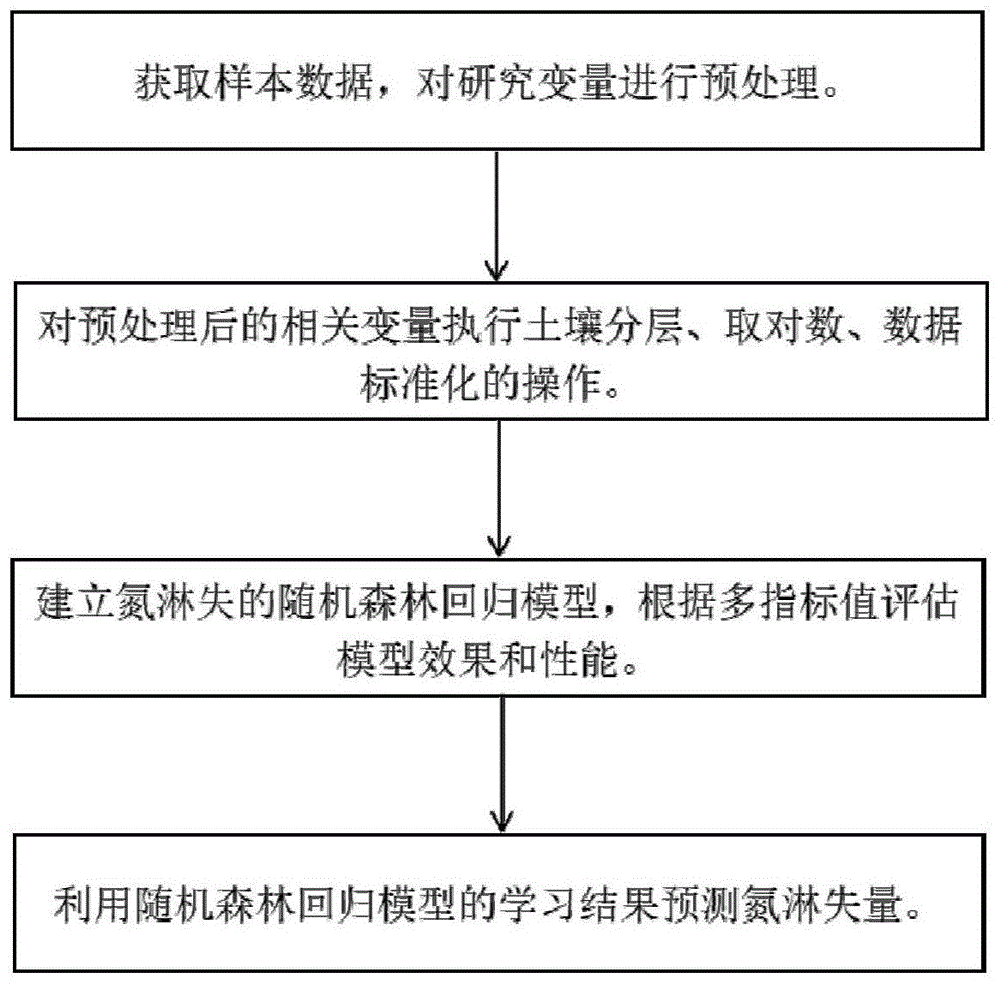
S1,获取样本数据,对研究变量进行预处理;
S2,对预处理后的相关变量执行土壤分层、取对数、数据标准化的操作;
S3,建立氮淋失的随机森林回归模型,根据多指标值评估模型效果和性能;
S4,利用随机森林回归模型的学习结果预测氮淋失量。
S1中的研究变量包括作物生产过程中水、肥、土的特征属性。
特征属性包括但不限于土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、总施氮量、氮盈余、水分投入量、水平衡和水分渗漏量。
S1中的预处理包括缺失值处理、异常值处理、数据归一化和标准化中任意一种或多种,整个算法运用了NumPy、Pandas、SkLearn库的方法。
S2的具体步骤如下:
S21,土壤分层:基于土层深度数据分布直方图观察原始数据土壤断层情况,利用R语言数据索引功能将土壤分层;
S22,取对数:采用R语言中Log函数分别基于土壤分层后的数据集对总氮淋失量进行取对数操作;
S23,数据标准化:在数据集取对数的基础上采用标准差标准化的方式对各预测变量进行处理,所用函数为Scale函数,标准化处理后数据均值为0,标准差为1。
S3中建立氮淋失随机森林回归模型,使用Bootstraping自助法随机从原始样本集中采集多个不同的样本来依次训练生成多个不同的决策树,由多个不同的决策树构成随机森林,模型训练过程具体步骤如下:
S31,设原始样本集为T={x,y},x为作物生产过程中水、肥、土的特征值组成的训练数据集合,y为总氮淋失量;
S32,从原始样本集T中进行随机采样,生成多个训练集n,每个训练集包含m个训练集样本;
S33,确定决策树数量Ntree和叶子节点个数Mtry;
S34,将生成的多个决策树组成随机森林。
S33具体为:控制各叶子节点个数Mtry保持恒定,逐步对决策树数量Ntree进行调节,当模型均方误差较小且趋于稳定时,则认为Ntree最佳;控制决策树数量Ntree取值保持恒定,逐步对叶子结点个数Mtry进行调节,进而判断Mtry的最佳值。
S3中随机森林模型的评估指标包括拟合优度(R2)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE),并用来评估随机森林模型的预测精度和性能。
拟合优度(R2)的计算式如下:
均方误差(MSE)的计算式如下:
均方根误差(RMSE)的计算式如下:
平均绝对误差(MAE)的计算式如下:
平均绝对百分比误差(MAPE)的计算式如下:
R2为拟合优度,MSE为均方误差,RMSE为均方根误差,MAE为平均绝对误差,MAPE为平均绝对百分比误差,均可作为模型的回归评价指标。Y
S4中利用随机森林回归模型的学习结果预测氮淋失量,具体步骤如下:
S41,针对某一输入样本,从决策树的根节点开始,判断当前节点是否为叶子节点,如果是则返回叶子节点的预测值,如果不是则进入下一步;
S42,对比样本变量值与当前节点阈值,如果样本变量值小于当前节点阈值,则访问左节点,如果样本变量值大于当前节点阈值,则访问右节点;
S43,循环步骤S42,直至访问到叶子节点,并返回预测值;
S44,循环步骤S41、S42和S43,直至所有决策树都输出了预测值,再将所有预测值取平均得到最终的结果。
本发明的有益效果在于:
1、本发明将随机森林回归模型应用于前人研究涉及较少的农田氮淋失预测领域,其相比于常规的回归模型预测精度更高、泛化能力更强。这是由于随机森林算法的实质是基于决策树的分类器集成学习算法,其通过构建分类回归树并进行组合达到对数据的分类和回归作用,从而克服了传统的数据模拟方法精确度不高、反映信息量较少及过拟合等问题。
2、本发明通过土壤分层、取对数、数据标准化的操作来对模型进行优化,算法设计上具有创新性。首先根据土层深度对原始数据进行分层,以减轻断层对模型建立产生的影响,然后分别基于分层后的数据集对总氮淋失量进行取对数操作,最后在数据集取对数的基础上采用标准差标准化的方式对各预测变量进行处理,标准化处理后数据均值为0,标准差为1。
3、基于多因素进行拟合,更加符合实际情况。农田氮素淋失受多种环境因素的影响,且不同因素对氮淋失量的影响权重不同,过去的研究常用单个或部分氮淋失的影响因素建立预测模型,实际生产中氮素的淋失与很多因素都存在着相关关系,往往效果并不理想。本发明选取了水、氮、土等多个特征属性进行氮淋失模型建立与定量预测,与实际情况更加吻合。
附图说明
图1为本发明的方法流程示意图。
图2为本发明的算法示意图。
具体实施方式
现结合附图对本发明做进一步描述。
参见图1~2,本发明提供一种基于随机森林回归的农田氮淋失预测方法,包括以下步骤:
S1,获取样本数据,对研究变量进行预处理;
S2,对预处理后的相关变量执行土壤分层、取对数、数据标准化的操作;
S3,建立氮淋失的随机森林回归模型,根据多指标值评估模型效果和性能;
S4,利用随机森林回归模型的学习结果预测氮淋失量。
具体步骤为:
S1、获取样本数据,对研究变量进行预处理;
本实施例以夏玉米生产中氮淋失量预测为例,基于氮淋失大田试验,通过列表法、作图法与经验公式法收集夏玉米生产过程中水、肥、土的特征值数据,包括土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、总施氮量、氮盈余、水分投入量、水平衡、水分渗漏量。
其中,总施氮量为无机肥施氮量、秸秆还田量和有机肥施氮量之和;氮盈余量为总施氮量减去地上部吸收氮量;水分投入量为灌溉量与降水量之和;水平衡量为水分投入量减去水分蒸散量;水分渗漏量为降雨量或灌溉水量过大时,土壤水分向根系活动层以下土层迁移的量。
进一步地,分别对总氮淋失量与总施氮量、氮盈余、水分投入量、水平衡、水分渗漏量进行简单回归分析,基于拟合优度将与氮淋失相关性较差的变量去除,这里删除的变量为水分投入量和水平衡,最终剩下的研究变量有11个。
为了避免预测时重复,将总施氮量与氮盈余分开进行组合,得到两个变量组合,分别为预测变量组合1(土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、总施氮量、水分渗漏量)和预测变量组合2(土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、氮盈余、水分渗漏量),预测变量组合1和2分别执行步骤1-4的操作,相互独立、互不干扰。
进一步地,对研究变量进行预处理,具体过程如下:(1)数据异常值处理:大田试验中测定氮淋失量的方法主要有淋溶盘法、渗漏池法、陶土头法等,剔除掉数据集中不是利用田间氮淋失测量方法得到的异常淋失量数据。(2)数据缺失值处理:使用均值进行填充(连续型特征),使用中位数、0进行填充(连续型特征),使用众数进行填充(离散型特征),KNN填充,除此之外,还可以使用拉格朗日插值和回归等方法进行填充,本实施例中采用均值进行填充。
S2、对预处理后的相关变量执行土壤分层、取对数、数据标准化的操作;
步骤S2的具体过程如下:
S21、土壤分层:基于土层深度数据分布直方图观察原始数据土壤断层情况,利用R语言数据索引功能将土壤分层。
本实施例中将土层深度为200cm以上的分为一类,即数据集a,将土层深度为200cm及以下的分为一类,即数据集b,分别进行随机森林模型建立。其中,数据集a建立的随机森林回归模型记为RFa,数据集b建立的随机森林回归模型记为RFb。
S22、取对数:采用R语言中Log函数分别基于分层后的数据集a和b对总氮淋失量进行取对数操作。
S23、数据标准化:在数据集取对数的基础上采用标准差标准化的方式对各预测变量进行处理,所用函数为Scale函数,标准化处理后数据均值为0,标准差为1。
S3、建立氮淋失的随机森林回归模型,根据多指标值评估模型效果和性能;
步骤S3中建立氮淋失随机森林回归模型的具体过程如下:
S31、设原始样本集为T={x,y},其中x为作物生产过程中水、肥、土的特征值组成的训练数据集合,y为总氮淋失量;
预测变量组合1的反应变量为总氮淋失量,预测变量为土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、总施氮量、水分渗漏量;预测变量组合2的反应变量为总氮淋失量,预测变量为土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、氮盈余、水分渗漏量。
S32、从原始样本集T中进行随机采样,生成多个训练集n,每个训练集包含m个训练集样本;
如图2所示,随机森林回归算法采用Bootstraping(有放回采样)的方式随机从原始样本集T中采集m个样本来训练生成n棵决策树,每一棵决策树均会输出一个预测值,随机森林最终的预测值为所有决策树预测值的均值。在建立每棵决策树时,需随机抽取一定数量的特征属性Fj,然后从这Fj个特征属性中采用某种策略(如信息增益等)来选择1个特征作为该节点的分裂属性,每个节点均通过此方式来分裂,一直到不能再分裂为止,整个决策树形成过程中没有剪枝。
S33、确定决策树数量Ntree和叶子节点个数Mtry;
步骤S33的具体过程如下:控制各叶子结点个数Mtry保持恒定,逐步对决策树数量Ntree进行调节,当模型均方误差较小且趋于稳定时,则认为Ntree最佳;控制决策树数量Ntree取值保持恒定,逐步对叶子结点个数Mtry进行调节,进而判断Mtry的最佳值。
所得决策树数量Ntree为100,叶子节点个数Mtry为6。
S34、将生成的多个决策树组成随机森林。
随机森林由很多的决策树构成,且森林中每一棵决策树之间没有关联,模型的最终输出结果由每一棵决策树共同决定。
需要说明的是,在从原始样本集中随机采样时,存在部分样本数据没有被选中过的情况,对于这些没有被选中过的数据称之为袋外数据(简称OOB),可基于袋外数据来验证模型。
进一步地,对随机森林模型进行评估,模型评估指标包括拟合优度(R2)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE),通过这五个指标来评估随机森林模型的预测精度和性能。
根据如下公式计算上述指标:
/>
其中,R2为拟合优度,MSE为均方误差,RMSE为均方根误差,MAE为平均绝对误差,MAPE为平均绝对百分比误差,均可作为模型的回归评价指标。Y
S4、利用随机森林回归模型的学习结果预测氮淋失量。
步骤S4的具体过程如下:
S41、针对某一输入样本,从决策树的根节点开始,判断当前节点是否为叶子节点,如果是则返回叶子节点的预测值,如果不是则进入下一步;
S42、对比样本变量值与当前节点阈值,如果样本变量值小于当前节点阈值,则访问左节点,如果样本变量值大于当前节点阈值,则访问右节点;
S43、循环步骤S42,直至访问到叶子节点,并返回预测值;
S44、循环步骤S41、S42、S43,直至所有决策树都输出了预测值,再将所有预测值取平均得到最终的结果。
本实施例以夏玉米生产中氮淋失量预测为例,Ntree=100,Mtry=6,循环运行400次,所得预测变量组合1的预测精度及性能优于预测变量组合2,故选用预测变量组合1建模,即预测变量为土壤类型、有机质含量、土壤全氮、粘粒含量、砂粒含量、土壤pH、土层深度、秸秆是否还田、总施氮量、水分渗漏量。当有新的样本输入时,基于土层深度选择随机森林回归模型RFa(土层深度<200m),或者随机森林回归模型RFb(土层深度≥200m),得到氮淋失量预测值,预测所用函数为Predict函数。
以上仅是本发明的优选实施方式,只是用于帮助理解本申请的方法及其核心思想,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
本发明从整体上解决了现有技术中常选取单个氮淋失的影响因素,实际生产中氮素淋失还会受到耕作措施、种植制度、土壤性状、农作物种类及气象条件等的影响,导致预测效果并不理想;以及建模时需要进行校准验证、敏感性分析等操作,预测流程更为复杂且结果容易受到不同深度土壤异质性的影响的技术问题。本发明通过将随机森林回归模型应用于前人研究涉及较少的农田氮淋失预测领域,并通过土壤分层、取对数、数据标准化的操作来对模型进行优化,基于多因素进行拟合,更加符合实际情况,实现了精度高、简单、有效的农田氮淋失预测效果。