一种基于查询路径排序的领域知识图谱问答方法及系统
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉知识图谱领域,尤其是涉及一种基于查询路径排序的领域知识图谱问答方法及系统。
背景技术
现有多数领域知识图谱问答方法存在实体间关系的语义信息利用不足,多跳问题处理能力弱的问题:(1)领域知识图谱覆盖范围小,节点字面相似度较高,同类型节点属性较为一致,造成查询路径区分度不高,易发生歧义;(2)相比于通用知识图谱,领域知识图谱具有关系网络深,推理链条长、复杂度高的特点,随着查询路径的增加,问答模型的答案预测能力变弱。以上问题难以满足用户对专业知识深度查询的需求,导致领域知识图谱多跳问题回答困难。
发明内容
有鉴于此,本申请提出一种基于查询路径排序的领域知识图谱问答方法及系统。
第一方面,本申请提出一种基于查询路径排序的领域知识图谱问答方法,包括:
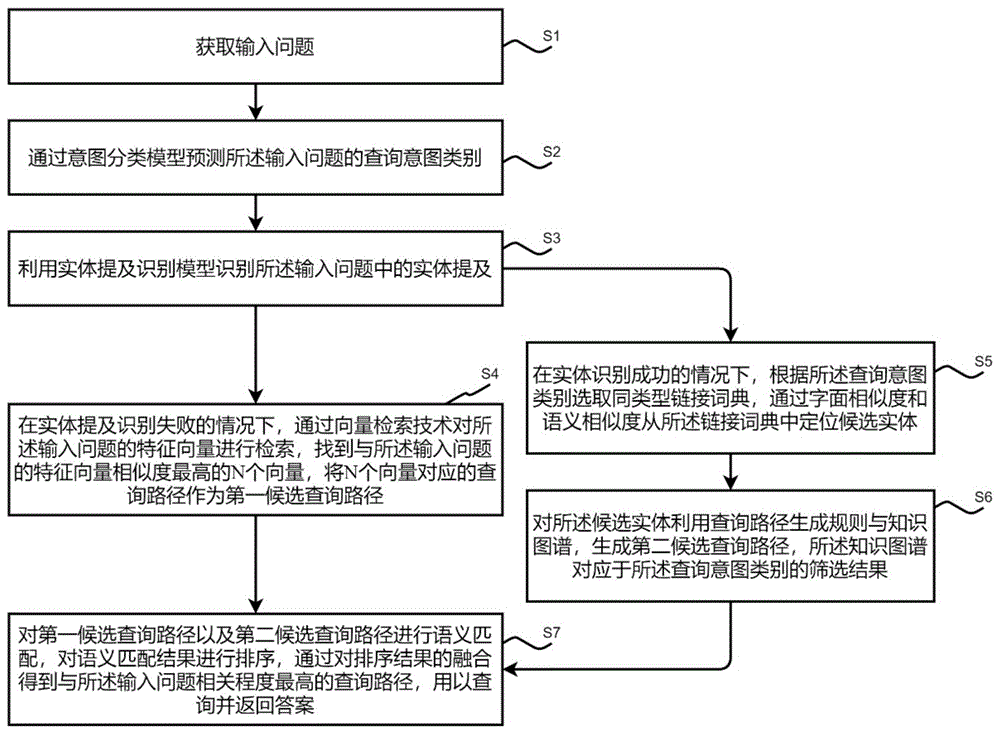
获取输入问题;
通过意图分类模型预测所述输入问题的查询意图类别;
利用实体提及识别模型识别所述输入问题中的实体提及;
在实体提及识别失败的情况下,通过向量检索技术对所述输入问题的特征向量进行检索,找到与所述输入问题的特征向量相似度最高的N个向量,将N个向量对应的查询路径作为第一候选查询路径;
在实体识别成功的情况下,根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体;
对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,所述知识图谱对应于所述查询意图类别的筛选结果;
对第一候选查询路径以及第二候选查询路径进行语义匹配,对语义匹配结果进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,用以查询并返回答案。
所述通过意图分类模型预测所述输入问题的查询意图类别,包括:
将所述输入问题对应的文字向量输入到BERT模型,得到第一输出向量;
将所述第一输出向量输入到双向长短期记忆网络模型,得到前向特征向量和后向特征向量;
分别取所述前向特征向量的最后一个向量与所述后向特征向量的最后一个向量进行拼接;
将拼接后的结果输入到全连接层,并得到全连接层的输出结果;
根据所述全连接层的输出结果,通过Softmax回归模型得到每个意图类别的概率,将概率最大的意图类别作为意图预测结果。
所述利用实体提及识别模型识别所述输入问题中的实体提及,包括:
将所述输入问题对应的文字向量输入序列标注模型的BERT层,得到预测序列的标签概率矩阵,所述实体提及识别模型包括:序列标注模型以及全局指针网络,所述序列标注模型包括:BERT层以及CRF层;
以所述标签概率矩阵作为序列标注模型的CRF层的输入,将所述标签概率矩阵映射为标签序列;
通过将所述标签序列拼接获取所述输入问题的第一实体提及;
对于任一类型的实体,采用全局指针网络通过线性变换将所述预测序列的标签概率矩阵分别生成头指针序列向量和尾指针序列向量;
将所述头指针序列向量和尾指针序列向量进行内积,将内积的结果作为内积序列;
对于任意内积序列,通过定义打分函数判断所述内积序列属于任一类型的所述输入问题的实体提及的概率,将概率最高的内积序列的连续片段作为所述输入问题的第二实体提及;
将所述输入问题的第一实体提及和第二实体提及,按照预设定规则进行融合,得到候选实体提及集合,作为实体提及的识别结果。
所述将所述输入问题的第一实体提及和第二实体提及,按照预设定规则进行融合,得到候选实体提及集合,作为实体提及的识别结果,包括:
若第一实体提及和第二实体提及完全相同,则将第一实体提及或第二实体提及加入到候选实体提及集合中;
若第一实体提及和第二实体提及部分相同,则将第二实体提及加入到所候选实体提及集合中;
舍弃第一实体提及和第二实体提及中的单字实体;
若第一实体提及和第二实体提及完全不同,则舍弃所述第一实体提及和第二实体提及。
所述根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体,包括:
将实体链接词典按照实体类型分类储存,并使用与所述候选实体提及集合中实体的类型相同类型的实体链接词典;
利用Jaccard算法分别计算所述候选实体提及集合中每一元素与实体链接词典中任一实体的字面相似度,保留字面相似度前M1个排名的实体,得到实体提及对应的候选实体排序集合。
通过采用语义匹配模型计算所述选实体提及集合与对应的候选实体排序集合各个实体之间的语义相似度,将语义相似度前M2个排名对应的实体作为最终的候选实体。
所述对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,包括:
当所述候选实体为单个实体时,以所述单个实体为中心,召回三跳范围内的链式查询路径,所述链式查询路径作为第二候选查询路径;
当所述候选实体为两个实体时,所述两个实体为第一实体与第二实体,利用Cypher查询语言查询第一实体与第二实体间关系,若所述第一实体与第二实体为父子节点关系则将第一实体与第二实体进行拼接,得到第一拼接结果,将所述第一拼接结果与子节点的三跳范围内对应关系的实体进行拼接,得到第二拼接结果,将得到的第二拼接结果作为第二候选查询路径,若第一实体与第二实体存在共同子节点,则将第一实体与第二实体的共同的子节点进行拼接,得到第三拼接结果,将所述第三拼接结果与所述共同子节点的三跳范围内对应关系的实体进行拼接,得到第四拼接结果,将得到的第四拼接结果作为第二候选查询路径;若所述第一实体与第二实体之间无关系时则将所述第一实体与第二实体记为并列关系,以第一实体或第二实体中的单实体召回三跳范围内的链式查询路径,所述链式查询路径作为第二候选查询路径;
当所述候选实体为三个实体时,用Cypher查询语言查询第一实体、第二实体以及第三实体之间的关系,若所述第一实体、第二实体、第三实体为链式关系则对所述第一实体、第二实体以及第三实体进行拼接,得到第五拼接结果,将所述第五拼接结果与召回关系链条中尾部实体对应的三跳范围内对应关系的实体进行拼接,得到第六拼接结果,将所述第六拼接结果作为第二候选查询路径;若所述三个实体中的任两个实体同时为另一实体的子节点,则将召回所述两个实体的三跳范围内对应关系的实体进行拼接,得到第七拼接结果,将所述第七拼接结果作为第二候选查询路径;若两个实体皆为另一实体的父节点,则将召回所述父节点的三跳范围内对应关系的实体进行拼接,得到第八拼接结果,将所述第八拼接结果作为第二候选查询路径;若所述三个实体为其它关系,则分别召回三个实体的三跳范围内的链式查询路径,所述链式查询路径作为第二候选查询路径。
所述通过向量检索技术对所述输入问题的特征向量进行检索,包括:
对于每类预设定的查询路径数据集利用Sentence-BERT模型生成特征向量并通过FAISS引擎构建所述特征向量的索引,生成索引文件;
计算第一输出向量与索引文件中查询路径的特征向量之间的相似度。
所述通过语义匹配对第一候选查询路径以及第二候选查询路径进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,包括:
对第一候选查询路径、第二候选查询路径进行首尾实体拼接得到首尾实体拼接结果;
分别计算所述输入问题与任一候选查询路径、任一首尾实体拼接结果的字面相似度和语义相似度,并得到字面相似度和语义相似度排序结果;
对所述字面相似度和语义相似度排序结果进行融合,得到与所述输入问题相关程度最高的查询路径,将所述相关程度最高的查询路径作为最终的查询路径,用以查询并返回答案。
所述对所述字面相似度和语义相似度排序结果进行融合,为采用排序平均法对所述字面相似度和语义相似度排序结果进行融合,包括:
按照所述字面相似度和语义相似度的数值大小赋予排序序号,得到排序结果;
对所述排序结果中任一查询路径对应排序序号求均值并归一化得到最终排序结果;
将所述最终排序结果中数值最小的对应查询路径作为与所述输入问题相关程度最高的查询路径。
第二方面,本申请提出一种基于查询路径排序的领域知识图谱问答系统,包括:
问题输入模块,用于获取输入问题;
意图识别模块,用于通过意图分类模型预测所述输入问题的查询意图类别;
实体提及模块,用于利用实体提及识别模型识别所述输入问题中的实体提及;
第一路径生成模块,用于在实体提及识别失败的情况下,通过向量检索技术对所述输入问题的特征向量进行检索,找到与所述输入问题的特征向量相似度最高的N个向量,将N个向量对应的查询路径作为第一候选查询路径;
候选实体定位模块,用于在实体识别成功的情况下,根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体;
第二路径生成模块,用于对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,所述知识图谱对应于所述查询意图类别的筛选结果;
路径排序模块,用于对第一候选查询路径以及第二候选查询路径进行语义匹配,对语义匹配结果进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,用以查询并返回答案。
有益效果:
1.通过构建BERT-BiLSTM模型实现用户查询意图类别的预测,提高了意图类别预测的准确性。
2.通过BERT-CRF序列标注模型全局指针网络组成的实体提及识别模型,能够避免传统序列标注模型中边界识别错误的发生,提高实体识别的准确性,减少流水线式问答方法的误差累积。
3.通过同时使用语义匹配与字面匹配,并使用Sentence-BERT语义匹配模型,避免了仅采用字面相似度进行评价可能带来的错误,提高了语义匹配准确率。
4.在实体提及识别失败时,通过向量检索技术对所述输入问题的特征向量进行检索,进而生成可能为输入问题的答案的候选答案,使得系统能够具备较好的回复问题的能力。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请实施例的基于查询路径排序的领域知识图谱问答方法流程图;
图2为本申请实施例的基于查询路径排序的领域知识图谱问答方法流程示意图;
图3为本申请实施例的知识图谱示意图;
图4为本申请实施例的BIO标注示意图;
图5为本申请实施例的基于查询路径排序的领域知识图谱问答系统原理框图;
图6为本申请实施例的路径召回规则示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:
本实施例提出一种基于查询路径排序的领域知识图谱问答方法,如图1、图2所示,包括:
步骤S1:获取输入问题;
步骤S2:通过意图分类模型预测所述输入问题的查询意图类别;
意图分类的目的是预测用户的查询意图,即最终要返回给用户的答案节点类型。相对于通用知识图谱而言,领域知识图谱覆盖范围往往有限,对应的用户查询意图可以归纳为数量有限的几类,对问题分类处理能够更有针对性地获取和筛选答案。如地震灾害防治知识图谱中将知识划分为建筑抗震设防类、避难场所类、震后易发疾病类、抗震减灾措施类,那么相应的将用户查询意图划分为查询建筑抗震设防知识、查询避难场所知识、查询震后易发疾病防治和查询抗震减灾措施,基于这种特性,本实施例构建意图分类模型,预测问题查询意图的类别,根据查询意图预测结果查询对应类型的知识图谱。如问句“什么是避难场所”,通过意图分类模型对其查询类别进行预测,得到查询类别为知识图谱类,则只对地震灾害防治知识图谱中类别为避难场所的知识进行查询即可得到候选答案。本实施例引入意图分类环节,对问答方法流程中的实体链接环节、查询路径召回环节做约束。考虑到意图分类环节的准确率直接影响到系统回复问题的准确性,采用预训练模型BERT(BERT,Bidirectional Encorder Representations from Transformers,基于Transformer的双向编码器)和双向长短期记忆网络(BiLSTM,Bi-directional Long Short-Term Memory双向长短期记忆网络)构建文本分类模型BERT-BiLSTM实现用户查询意图类别的预测,采用拥有12层双向Transformers的BERT_base模型作为特征表示层获取字符级别表示向量,然后通过BiLSTM模型整合文本信息和句子顺序信息,从而提取问句深度特征信息,双向长短期记忆网络通过两个方向相反的长短期记忆网络构成,通过双向的编码学习输入问题的全文信息。
所述通过意图分类模型预测所述输入问题的查询意图类别,包括:
步骤S2.1:将所述输入问题对应的文字向量输入到BERT模型,得到第一输出向量;
BERT模型接收所述输入问题对应的文字向量并通过Transformer结构生成字符级表示向量:
其中BERT模型接收所述输入问题对应的文字向量,所述文字向量由文本中每个字的词向量(Token Embeddings)、段向量(Segment Embeddings)和位置向量叠加得到。
英文文本中每一个词由空格分隔开来,故可以按照空格进行分词,然而中文文本没有明显的标识符可以将一句话分隔开,即将一个字作为一个词,进行分词处理后,将每一个词转化为相应的索引,根据索引查词向量表就可以获得每一个词的词向量(TokenEmbedding)表示。词向量为文本中每个字在词表中对应的索引值,开头结尾为unk和cls对应索引值,如文本“避难场所的类别”,对应得到词向量序列[101, 6912, 7410, 1767,2792, 4638, 5102, 1166,102,0,0,…0],0为填充字符,词向量序列长度为自行设定的最大文本长度,本实施例中将最大文本长度设置为128段向量用于区分两个句子。将第一个句子中词的索引全部为0,第二个句子中词的索引全部为1,在本实施例中不涉及到此类情况,第二个句子,将第一个句子的段落向量以字符0进行表示,即[0,0,0,0,0,0,…0],序列长度为128。位置向量Position Embedding为BERT通过训练得到的位置编码,不需要人为输入。BERT模型会对其位置信息随机初始化,通过对数据的训练来更新位置编码的参数。
步骤S2.2:将所述第一输出向量输入到双向长短期记忆网络模型,得到前向特征向量
步骤S2.3:分别取所述前向特征向量的最后一个向量
步骤S2.4:将拼接后的结果输入到全连接层,并得到全连接层的输出结果;
全连接层作用为在双向长短期记忆网络模型中的分类器,即将BERT-BiLSTM模型学习到的分布式特征表示映射到样本标记空间,全连接层的输入层维度为
步骤S2.5:根据所述全连接层的输出结果,通过Softmax回归模型得到每个意图类别的概率,将概率最大的意图类别作为意图预测结果;
Softmax回归模型用于多分类的过程,将多个神经元的输出映射到[0,1]之间的数值,所述数值可以被当作概率分布,用来作为多分类的目标预测值。Softmax函数作为神经网络的最后一层,接受全连接层传来的输入值,将其转化为概率,全连接层的输出有正有负,在用指数函数可以将其第一步都变成大于0的值,然后再算概率分布,Softmax计算式如下:
其中,y
通过意图分类模型能够约束实体指称词典的选择,减少歧义的发生,缩减查询路径召回空间,减少无关查询路径召回数量,提高语义匹配的准确率。
步骤S3:利用实体提及识别模型识别所述输入问题中的实体提及;
实体提及识别旨在识别问句中的实体提及。构建基于预训练模型的BERT-CRF序列标注模型(序列标注模型包括:BERT层(BERT层实质为BERT模型)以及CRF层(CRF,Conditional Random Field,条件随机场)和全局指针网络(Globalpointer)组成的实体提及识别模型,对用户问句进行实体提及识别,对模型的预测结果进行融合,构成候选实体提及集合。该模型能够避免传统序列标注模型中边界识别错误的发生,提高实体识别的准确性,减少流水线式问答方法的误差累积。
全局指针网络可以无差别的识别嵌套实体和非嵌套实体,非嵌套情况下全局指针网络的效果可以媲美序列标注模型CRF的效果,嵌套情况下也可以取得相当不错的效果,因此常被用于嵌套实体的实体识别中,在本实施例中并不涉及嵌套实体的情况,仅通过全局指针网络在实体识别时将候选实体视为整体的特性,识别简单实体,减少边界预测错误的问题。
领域知识图谱中实体间具有字面相似度高的特点,如实体“避难场所”和实体“避难场地”。而常用序列标注模型常常会出现实体提及边界识别错误的现象,如对于问句“避难场所如何选址”,序列标注模型可能会出现仅识别出“避难场”而漏识别了“所”这一关键字符,造成实体链接环节发生歧义,进而无法正确回复用户问题。因此为获取用户问题中完整的实体提及,引入全局指针网络参与实体提及识别,不同于序列标注模型对中文文本中的每个字的对应标签进行预测(以问句“避难场所如何选址”为例,序列标注模型输出为标签集合“B I I I O O B I”),全局指针网络将实体识别任务转化为实体提及边界预测问题和实体分类问题,能够更加准确的获取完整的实体提及。通过BERT-CRF序列标注模型和全局针网络这两种模型的预测结果融合能够避免边界预测错误的发生,减少系统误差累计。
序列标注模型旨在将句子中的每个词映射为相应标签,由各类神经网络后接CRF(条件随机场)构成,如BiLSTM-CRF、IDCNN-CRF等。本实施例引入预训练模型BERT,构建BERT-CRF序列标注模型,通过BIO标注数据训练模型,完成序列标注任务。
所述利用实体提及识别模型识别所述输入问题中的实体提及,包括:
步骤S3.1:将所述输入问题对应的文字向量
全局指针网络将命名实体识别问题转化为实体边界预测问题和实体分类问题,可以更精确的预测实体边界,保证模型获取完整的实体提及,提高实体链接准确率。全局指针网络将实体首尾视作一个整体进行判别,当仅有一种实体需要识别,可以生成多个子序列,将实体识别问题转换为一种二分类问题,判断子序列是否为实体,若有多种实体需要识别,则转换成多分类问题。
步骤S3.2:以所述标签概率矩阵作为序列标注模型的CRF层的输入,将所述标签概率矩阵映射为标签序列
步骤S3.3:通过将所述标签序列拼接获取所述输入问题的第一实体提及;
例如:“什么是避难场所”,预测结果为“O,O,O,B-ENT,I-ENT,I-ENT,I-ENT”,将关键内容B-ENT和I-ENT标签对应的字进行拼接得到“避难场所”这个实体,作为第一实体提及。
步骤S3.4:对于任一类型的实体,采用全局指针网络通过线性变换将所述预测序列的标签概率矩阵分别生成头指针序列向量
步骤S3.5:将所述头指针序列向量和尾指针序列向量进行内积,将内积的结果作为内积序列;
步骤S3.6:对于任意内积序列,通过定义打分函数判断所述内积序列属于任一类型的所述输入问题的实体提及的概率,将概率最高的内积序列的连续片段作为所述输入问题的第二实体提及;
所述打分函数为:
其中,
步骤S3.7:将所述输入问题的第一实体提及和第二实体提及,按照预设定规则进行融合,得到候选实体提及集合,作为实体提及的识别结果。
所述将所述输入问题的第一实体提及和第二实体提及,按照预设定规则进行融合,得到候选实体提及集合,作为实体提及的识别结果,包括:
若第一实体提及和第二实体提及完全相同,则将第一实体提及或第二实体提及加入到候选实体提及集合中;
若第一实体提及和第二实体提及部分相同,则将第二实体提及加入到所候选实体提及集合中;
舍弃第一实体提及和第二实体提及中的单字实体;
若第一实体提及和第二实体提及完全不同,则舍弃所述第一实体提及和第二实体提及。
步骤S4:在实体提及识别失败的情况下,通过向量检索技术对所述输入问题的特征向量进行检索,找到与所述输入问题的特征向量相似度最高的N个向量,将N个向量对应的查询路径作为第一候选查询路径;本实施例中N为三十;
作为实体识别环节失败时的策略。传统基于知识图谱的问答方法普遍存在过于依赖实体识别结果的问题,若实体识别失败则无法回答用户问题,本申请根据制定的查询路径生成规则,提前遍历知识图谱,生成单跳和双跳问题的查询路径,利用训练后的Sentence-BERT模型生成语义向量,并通过FAISS向量搜索引擎构建索引,在实体识别失败时由FAISS(FAISS,Facebook AI Similarity Search Facebook人工智能相似搜索)向量检索直接召回索引库中与问题特征向量相似度最高的N个查询路径,作为候选查询路径输入语义匹配模块进行精排序。使得本申请的问答方法在即使无法有效识别用户问句中的实体提及时也能够具备较好的回复问题的能力。
领域知识图谱的用户常常为领域相关从业人员,用户提问意图与领域知识图谱内容具有较高的相关度,因此即使未从问句中识别出相关实体,问句也具备较高的回复价值。为保证问答方法的健壮性,本申请基于FAISS向量搜索引擎构建查询路径的向量索引,对未识别出实体的问句统一处理。
FAISS是Facebook团队开源的向量搜索引擎,拥有多种索引类型,本实施例采用indexFlatL2索引类型。首先利用Cypher查询语句依照主题类型对领域知识图谱分类查询,构造查询路径数据集。然后对于每类查询路径数据集利用构建的Sentence-BERT模型生成特征向量并通过FAISS引擎构建向量索引,生成index文件。在向量召回时通过计算用户问题与向量索引中查询路径特征向量的相似性,保留相似度排名前三十的查询路径,作为候选查询路径进行下一步精排序。
所述通过向量检索技术对所述输入问题的特征向量进行检索,包括:
步骤S4.1:对于每类预设定的查询路径数据集利用Sentence-BERT模型生成特征向量并通过FAISS引擎构建所述特征向量的索引,生成索引文件;
本实施例中Sentence-BERT是表示型语义匹配模型,BERT是交互型语义匹配模型,二者是不同的。表示型的模型会在最后一层对参与语义匹配的两个句子进行相似度计算,交互型语义匹配模型会尽早让两个句子进行交互,充分利用交互信息,但这也造成交互型语义匹配模型速度较慢,Sentence-BERT模型主要是解决BERT语义相似度检索的巨大时间开销和其句子表征不适用于非监督任务如聚类,句子相似度计算等而提出的。而Sentence-BERT模型使用鉴孪生网络结构,获取句子对的向量表示,然后进行相似度模型的预训练即为Sentence-BERT模型。Sentence-BERT模型首先通过两个参数共享的BERT模型生成问句和查询路径字符级的语义向量,通过平均池化操作生成固定维度的句子级特征向量。最后通过余弦相似度计算两个特征向量间的相似程度。
步骤S4.2:计算第一输出向量与索引文件中查询路径的特征向量之间的相似度;
步骤S5:在实体识别成功的情况下,根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体;
候选实体召回环节对候选实体提及集合,根据意图分类结果选择实体链接词典,通过字面相似度算法从实体链接词典中召回每个实体提及对应的候选实体。领域知识图谱中的实体具有较高的相似性,本申请将实体链接词典按照意图分类环节设置的类别分类储存,以意图分类模型结果决定使用哪一种类型的实体链接词典,减少歧义问题发生。
本申请将领域知识图谱按主题类型分类构造,并根据知识图谱主题类型划分对应的查询意图,进而训练意图分类模型,意图分类模型预测结果为用户查询知识的类别,即最终要返回给用户的知识图谱节点类型。实体链接环节是将用户问题中的实体提及链接到知识图谱中标准实体的过程,因此首先按照知识图谱节点类型分类构造了实体链接词典,然后在实体链接时按照意图分类结果选择对应类型的链接词典能够缩小实体链接范围。避免了后续Jaccard(杰卡德算法)相似度引入过多无关干扰项,更有针对性的获取候选实体,减少实体链接环节歧义的发生。
所述根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体,包括:
步骤S5.1:将实体链接词典按照实体类型分类储存,并使用与所述候选实体提及集合中实体的类型相同类型的实体链接词典;对于实体ENT与其对应的实体别名ent
步骤S5.2:利用Jaccard算法分别计算所述候选实体提及集合中每一元素与实体链接词典
步骤S5.3:通过采用语义匹配模型计算所述选实体提及集合与对应的候选实体排序集合各个实体之间的语义相似度,将语义相似度前M2个排名对应的实体作为最终的候选实体;
本实施例中语义匹配模型采用Sentence-BERT语义匹配模型,为了提升查询路径召回率,本实施例对于每个实体提及保留语义相似度排名前三名的候选实体作为最终的候选实体。
领域知识图谱问答中实体提及与标准实体之间的字面相似度差异往往不大,一般为标准实体的错字、漏字、同义词、同音词,因此首先通过Jaccard算法从链接词典中召回与实体提及字面相似度排名前三十的标准实体作为候选实体集。Jaccard相似度定位候选实体效果:大大缩减了候选实体范围,从而提升了候选实体排序的计算速度。
步骤S6:对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,所述知识图谱对应于所述查询意图类别的筛选结果;
在知识图谱中,互相关联的节点呈现一种路径效果,如三元组(避难场所)-<类别>-(临时避难场所),将这些与主题实体相关三元组的组合称为查询路径。通过统计发现,三跳路径已能够覆盖多数主题实体的子图,三跳之外的查询路径由于路径过长,引入的无关关系过多,不具备实际使用意义,分析互联网爬取的地震防治相关问句发现用户问句中的实体提及绝大多数为三个以内的情形,因此本申请将查询路径召回范围约束在三跳以内,根据问句中实体提及的数量分别针对单实体、双实体、三实体情形设计了共十类查询路径生成规则,即查询路径召回规则。
所述对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,如图6所示,包括:
当所述候选实体为单个实体时,以所述单个实体为中心,召回三跳范围内的链式查询路径,所述链式查询路径作为第二候选查询路径;
当所述候选实体为两个实体时,所述两个实体为第一实体与第二实体,利用Cypher查询语言查询第一实体e
当所述候选实体为三个实体e
举例说明本步骤的实施过程:回复用户输入的问题时,首先经过实体识别和意图分类,得到用户问题中的实体和知识查询类别,如问句“避难所有哪些种类?”,经过实体识别和意图分类得到实体“避难场所”,和知识查询类别“避难场所类”,由于实体数量为一则对应单实体三条内查询路径生成规则,在知识图谱中查询类别为“避难场所类”且实体名称为“避难场所”的节点三条内关系,如图3所示,将实体“避难场所和”三跳内关系进行拼接后生成候选查询路径为:1.避难场所的类别、2.避难场所的开放时间、3.避难场所的启用、4.避难场所的启用的条件、5.避难场所的类别的供水设施、6.避难场所的类别的供水设施的要求。
步骤S7:对第一候选查询路径以及第二候选查询路径进行语义匹配,对语义匹配结果进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,用以查询并返回答案。
所述通过语义匹配对第一候选查询路径以及第二候选查询路径进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,包括:
步骤S7.1:对第一候选查询路径、第二候选查询路径进行首尾实体拼接得到首尾实体拼接结果
步骤S7.2:分别计算所述输入问题query与任一候选查询路径p
所述字面相似度:采用Jaccard相似度和编辑距离评估路径计算与问题的字面相似度。对于输入问题query,与候选查询路径
,其中/>
所述语义相似度:采用Sentence-Bert模型。Sentence-Bert采用孪生网络架构,相比于同类型模型具备更快的推理速度。模型首先通过两个参数共享的BERT模型生成问句和查询路径字符级的语义向量,通过平均池化操作生成固定维度的句子级特征向量。最后通过余弦相似度计算两个特征向量间的相似程度,计算式如下。
其中,A为问句query的特征向量,B为候选查询路径的特征向量。两个特征向量间的余弦值越接近于1则向量之间的夹角越小,对应的认为两个文本具有更加相似的语义。对输入问题query与p
领域知识图谱间的实体在字面上具有一定的相似性,因此不能仅从字面相似度的角度衡量实体提及与候选实体之间的相似性,所以本实施例使用Sentence-BERT语义匹配模型从语义相似度的角度计算问题中的实体提及与候选实体之间的语义相似度从而实现候选实体的排序实现候选实体的精排序,避免了仅采用字面相似度进行评价可能带来的错误。
步骤S7.3:对所述字面相似度和语义相似度排序结果进行融合,得到与所述输入问题相关程度最高的查询路径,将所述相关程度最高的查询路径作为最终的查询路径,用以查询并返回答案;
所述对所述字面相似度和语义相似度排序结果进行融合,为采用排序平均法对所述字面相似度和语义相似度排序结果进行融合,包括:
步骤S7.3.1:按照所述字面相似度和语义相似度的数值大小赋予排序序号,得到排序结果;
步骤S7.3.2:对所述排序结果中任一查询路径对应排序序号求均值并归一化得到最终排序结果;
步骤S7.3.3:将所述最终排序结果中数值最小的对应查询路径作为与所述输入问题相关程度最高的查询路径。
本实施例采用排序平均法对上述两种相似度计算结果进行融合。对于融合后的Jaccard相似度J、编辑距离D和语义相似度S,按照数值大小赋予排序序号,得到排序结果SortJ、SortD、SortS。对于排序结果SortJ、SortD和SortS中查询路径p
其中,l
对每一候选查询路径的三类排序结果分别进行融合得到
举例说明步骤S7的具体实施过程:
Jaccard相似度指问题与查询路径相似度和查询路径与首尾实体拼接结果的相似度。以图3为例,用户问题为“避难场所有哪些种类?”对应的查询路径和分字、分词结果为:
path1.避难场所的类别;
path2.避难场所的开放时间;
Jaccard相似度计算过程如下:
j
j
j
j
j
j
j
j
;
j
j
j
path1.避难场所的类别,对应首尾实体拼接结果为避难场所-固定避难场所;
path2.避难场所的开放时间,对应首尾实体拼接结果为避难场所-避难场所开放时间;
j
j
j
j
path1的Jaccard相似度使用算术平均法进行融合:
j
path2的Jaccard相似度使用算术平均法进行融合:
j2=j
编辑距离计算结果如下:
d
d
其中,d
编辑距离融合后结果:
d
d
语义相似度计算结果:
s
s
s
s
其中,s
算术平均法对语义相似度结果进行融合:s
s
对于融合后的Jaccard相似度J、编辑距离D和语义相似度S,按照数值大小赋予排序序号,得到排序结果SortJ、SortD、SortS:
SortJ=[path1,path2]
SortD=[path1,path2]
SortS=[path1,path2]
path1的排序结果求平均:(0+0+0)/2=0;
path2的排序结果求平均:(1+1+1)/2=1.5;
归一化得到最终结果:L
基于以上实施例中基于查询路径排序的领域知识图谱问答方法的详细描述,为了更加清楚其具体效果,将上述方法应用在地震灾害防治领域列举一示例如下:
1、构建地震灾害防治知识图谱
为验证本示例设计的知识图谱问答框架有效性,本示例构建地震防治领域知识图谱,从实际地震防治工作出发,梳理防治工作重点,结合专家经验对地震防治知识体系进行分类,将知识体系分为避难场所构建类、建筑抗震设防类、个人防护类、震后处置类四个大类。对四类知识逐类构建本体,最终得到避难场所设施、避难场所种类、依法疾病防治、地震预防手段、震时避难方法、震后营救震后安置水源保障、建筑结构、建筑构件、建筑种类十一个二级类,部分知识类别信息如表1所示。为保障数据来源权威性与准确性,结合设计的知识本体,本示例采用地震防治领域相关法律作为知识抽取数据来源,抽取三元组,经过人工检查与融合最终形成地震防治知识图谱。
表1地震防治图谱知识类别
2、模型训练数据集
为训练上文构建的意图分类模型、实体识别模型、语义匹配模型,本示例以地震知识防治知识图谱中的实体、关系信息为数据采集关键词,利用爬虫技术爬取百度知道、知乎等问答社区上的地震防治相关问句,进而分别针对意图分类模型、实体识别模型、语义匹配模型构建训练所需数据集。
意图分类数据集:将原始数据集按照地震防治知识一级类别划分为避难场所、个人防震、震后处置、建筑抗震四类,分别按照类别名称做标注,采用随机实体替换、相似问句生成的数据增强方式弥补样本数量差异。最终意图分类数据集共包含43643条。
实体识别数据集:序列标注训练数据采用BIO(BIO,B-begin,I-inside,O-outside三位标注)标注方式,其中B表示实体指称开头,I表示实体指称中间位置或结尾位置,O表示非实体指称部分,标注格式如图4所示,通过随机实体替换的方式进行数据增强,得到43619条训练数据。全局指针网络训练数据通过拼接BIO标注数据得到,标注样式如表2所示:
表2全局指针网络训练数据
语义匹配数据集:语义匹配训练数据集如表3所示,构造语义匹数据集时首先将意图分类数据按类输入实体识别模型,根据实体识别结果召回查询路径,然后通过人工判别的方式将语义相似度最高的查询路径设置1标签作为正例,其余设置为0标签意图识别作为负例,最终语义匹配数据集包含41000对数据。
表3路径召回示例
3、实验设置
采用Windows系统下完成实验,选用RTXA5000显卡完成模型训练,采用python编程语言使用pytorch,transformers库构建模型,以Neo4j图数据库及相应的Cypher查询语言实现地震防治知识图谱的储存与增删改查。
本示例使用的Bert预训练模型均为12层编码器的Bert-base版本,意图分类模型、实体识别模型、语义匹配模型的句子最大长度均为128,模型训练时三个模型均采用AdamW优化策略对模型参数进行更新和微调,初始学习率均为2e-5,Drpout比率设置为0.1,迭代次数为十次。
4、意图分类模型效果评估
测评Bert-BiLSTM模型的同时对文本分类经典模型FastText模型和BiLSTM模型做对比实验,结果如表4所示,采用准确率对模型进行评估,可以看出,FastText模型和BiLSTM模型在本示例数据集上也达到了90%以上,其中BiLSTM模型考虑了序列问题,而FastText模型丢失了文本结构信息,所以BiLSTM模型的表现优于FastText模型,Bert-BiLSTM文本分类模型的准确率接近98%,明显优于其余两个模型,预BiLSTM模型相比,在引入与训练模型Bert后文本分类准确率从94.5%提升到97.8%,提升了约3个百分点,可见引入Bert模型能够更为有效的识别地震防治领域的用户查询意图。
表4 意图分类实验对比结果
5、实体识别模型效果评估
实体识别模型采用准确率(Precision)、召回率(Recall)、F1值进行评估,如表5所示:在实体识别结果中,通过对比可以看出,四个模型的准确率都较高,均在94%以上,但本示例构建的Bert-CRF模型在召回率上达到97%,远高于BiLSTM-CRF模型的89%和IDCNN-CRF模型的87%,可见预训练模型相比于BiLSTM模型和IDCNN模型能够更有效的识别词的边界信息,因此本示例构建的Bert-CRF模型可以更好的完成序列标注任务。
表5实体识别模型对照实验
6、语义匹配模型效果评估
表6反映了本示例构建的语义匹配数据集在Sentence-Bert、ESIM、pairCNN上的准确率,Sentence-BERT相较于pairCNN语义匹配模型准确率提高了近8%,相较于经典语义匹配模型ESIM提升了约24%之多。根据实验可以看出,Sentence-BERT模型可以有效的提高语义匹配环节的准确率。
表6语义匹配模型对照实验
为测试问答方法中不同模块对系统性能的影响,设置不同条件对系统进行测试,采用随机抽取的方式从原始问题数据集中随机抽取100条自然问句作为测试样例输入查询系统,以准确率作为系统查询评价指标,采用人工判别的方式判断返回答案正确性,测试结果如表7所示。
表7系统性能对比
系统去除意图分类环节时准确率下降到79%,说明本示例设计的意图分类环节能有效提高实体链接的准确率和减少无关查询路径的生产,只保留实体链接环节排名第一的实体时,系统准确率下降了5%,说明本示例的实体链接策略能够有效减少误差累积,提高系统召回率,系统仅进行单跳问答时系统准确率下降到62%,可见考虑多跳问题的能够有效提升系统准确率,去除向量召回模块系统准确率下降了4%,说明了本示例构建的向量召回模块能够有效地提升系统性能,同时也从侧面反映了本示例设计的实体识别模块具有相当的可靠性。
实施例2:
本实施例提出一种基于查询路径排序的领域知识图谱问答系统,如图5所示,包括:问题输入模块、意图识别模块、实体提及模块、候选实体定位模块、第一路径生成模块、第二路径生成模块以及路径排序模块;
所述问题输入模块分别与所述意图识别模块以及实体提及模块相连接,所述意图识别模块与所述第二路径生成模块相连接,所述实体提及模块分别与所述第一路径生成模块和所述候选实体定位模块相连接,所述候选实体定位模块与所述第二路径生成模块相连接,所述第二路径生成模块与所述路径排序模块相连接,所述第一路径生成模块与所述路径排序模块相连接;
问题输入模块,用于获取输入问题;
意图识别模块,用于通过意图分类模型预测所述输入问题的查询意图类别;
实体提及模块,用于利用实体提及识别模型识别所述输入问题中的实体提及;
第一路径生成模块,用于在实体提及识别失败的情况下,通过向量检索技术对所述输入问题的特征向量进行检索,找到与所述输入问题的特征向量相似度最高的N个向量,将N个向量对应的查询路径作为第一候选查询路径;
候选实体定位模块,用于在实体识别成功的情况下,根据所述查询意图类别选取同类型链接词典,通过字面相似度和语义相似度从所述链接词典中定位候选实体;
第二路径生成模块,用于对所述候选实体利用查询路径生成规则与知识图谱,生成第二候选查询路径,所述知识图谱对应于所述查询意图类别的筛选结果;
路径排序模块,用于对第一候选查询路径以及第二候选查询路径进行语义匹配,对语义匹配结果进行排序,通过对排序结果的融合得到与所述输入问题相关程度最高的查询路径,用以查询并返回答案。
所述意图识别模块,包括:
第一向量计算单元,用于将所述输入问题对应的文字向量输入到BERT模型,得到第一输出向量;
特征计算单元,用于将所述第一输出向量输入到双向长短期记忆网络模型,得到前向特征向量和后向特征向量;
向量拼接单元,用于分别取所述前向特征向量的最后一个向量与所述后向特征向量的最后一个向量进行拼接;
记忆网络计算单元,用于将拼接后的结果输入到全连接层,并得到全连接层的输出结果;
预测结果输出单元,用于根据所述全连接层的输出结果,通过Softmax回归模型得到每个意图类别的概率,将概率最大的意图类别作为意图预测结果。
所述实体提及模块,包括:
概率矩阵输出单元,用于将所述输入问题对应的文字向量输入序列标注模型的BERT层,得到预测序列的标签概率矩阵,所述实体提及识别模型包括:序列标注模型以及全局指针网络,所述序列标注模型包括:BERT层以及CRF层;
标签序列输出单元,用于以所述标签概率矩阵作为序列标注模型的CRF层的输入,将所述标签概率矩阵映射为标签序列;
序列拼接单元,用于通过将所述标签序列拼接获取所述输入问题的第一实体提及;
向量生成单元,用于对于任一类型的实体,采用全局指针网络通过线性变换将所述预测序列的标签概率矩阵分别生成头指针序列向量和尾指针序列向量;
内积计算单元,用于将所述头指针序列向量和尾指针序列向量进行内积,将内积的结果作为内积序列;
实体提及输出单元,用于任意内积序列,通过定义打分函数判断所述内积序列属于任一类型的所述输入问题的实体提及的概率,将概率最高的内积序列的连续片段作为所述输入问题的第二实体提及;
提及融合单元,用于将所述输入问题的第一实体提及和第二实体提及,按照预设定规则进行融合,得到候选实体提及集合,作为实体提及的识别结果。
所述第一路径生成模块,包括:
索引生成单元,用于对于每类预设定的查询路径数据集利用Sentence-BERT模型生成特征向量并通过FAISS引擎构建所述特征向量的索引,生成索引文件;
相似度计算单元,用于计算第一输出向量与索引文件中查询路径的特征向量之间的相似度。
所述候选实体定位模块,包括:
词典选择单元,用于将实体链接词典按照实体类型分类储存,并使用与所述候选实体提及集合中实体的类型相同类型的实体链接词典;
实体排序单元,用于利用Jaccard算法分别计算所述候选实体提及集合中每一元素与实体链接词典中任一实体的字面相似度,保留字面相似度前M1个排名的实体,得到实体提及对应的候选实体排序集合;
候选实体生成单元,用于通过采用语义匹配模型计算所述选实体提及集合与对应的候选实体排序集合各个实体之间的语义相似度,将语义相似度前M2个排名对应的实体作为最终的候选实体。
所述路径排序模块,包括:
首尾实体拼接单元,用于对第一候选查询路径、第二候选查询路径进行首尾实体拼接得到首尾实体拼接结果;
字面语义相似度计算单元,用于分别计算所述输入问题与任一候选查询路径、任一首尾实体拼接结果的字面相似度和语义相似度,并得到字面相似度和语义相似度排序结果;
相似度融合单元,用于对所述字面相似度和语义相似度排序结果进行融合,得到与所述输入问题相关程度最高的查询路径,将所述相关程度最高的查询路径作为最终的查询路径,用以查询并返回答案。
所述相似度融合单元,包括:
相似度排序子单元,用于按照所述字面相似度和语义相似度的数值大小赋予排序序号,得到排序结果;
均值归一化计算子单元,用于对所述排序结果中任一查询路径对应排序序号求均值并归一化得到最终排序结果;
查询路径确定子单元,用于将所述最终排序结果中数值最小的对应查询路径作为与所述输入问题相关程度最高的查询路径。
本发明申请人结合说明书附图对本发明的实施示例做了详细的说明与描述,但是本领域技术人员应该理解,以上实施示例仅为本发明的优选实施方案,详尽的说明只是为了帮助读者更好地理解本发明精神,而并非对本发明保护范围的限制,相反,任何基于本发明的发明精神所作的任何改进或修饰都应当落在本发明的保护范围之内。