基于深度学习的轻量级高精度时空视频超分辨率方法
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及数据处理技术领域,具体地说是一种基于深度学习的轻量级高精度时空视频超分辨率方法。
背景技术
视频有两个重要的属性,即时间分辨率(又称帧率)和空间分辨率。时空视频超分辨率技术能够同时提升视频的时间分辨率和空间分辨率。而近几年基于深度学习的时空视频超分辨率技术发展迅速。
中国发明专利申请 “基于跨帧自注意力变换网络的时空视频超分辨率重建方法”(申请号 202210076937 .1)提供了一种跨帧自注意力的时空视频超分辨技术方法。该专利文献将低分辨率低帧率的连续图片序列输入所述训练完成的基于跨帧自注意力变换网络,获得高帧率高分辨率的连续图片序列。
中国发明专利申请“一种时空视频超分辨率方法、装置、设备及存储介质”(申请号202310092691 .1)提供了一种时空视频超分辨率方法。此专利将连续的四帧作为时空视频超分辨率模型的输入,然后根据输出的生成结果确定与待处理视频帧序列对应的时空视频超分辨率结果;其中的时空视频超分辨率模型中至少包括两个视频帧对齐模块,视频帧对齐模块用于提取输入视频帧序列的空间局部特征信息和时间全局特征信息,并根据空间局部特征信息和时间全局特征信息对输入视频帧序列进行对齐。
也就是说,基于深度学习的时空视频超分辨率技术方法最开始通过两个不同的模型(时间维度-帧插值技术模型,空间维度-视频超分辨率技术模型)进行组合来实现时间分辨率和空间分辨率的提升,例如可以将视频先输入到帧插值模型中来提升视频的帧率,随后将所得到的结果输入到视频超分辨率模型中提升空间分辨率。很明显这是在两个模型中依次执行,注意到每个模型的结果都是会有误差的,将会导致误差累积问题,使得最终的高分辨率高帧率视频出现模糊、伪影等问题,播放出现抖动等现象。另外很重要的一点是两个模型的带来的模型冗余太大,参数量过高,占用内存较高,使得这种方法难以在低性能设备上部署运行。
上述专利文献“一种时空视频超分辨率方法、装置、设备及存储介质”所提的方法采用了四个连续的帧作为模型的输入,那么相比于两个输入帧,其将会使得模型在运行过程中需要存储两倍的中间变量,这将会占用更多的内存(显存),难以在低显存的GPU上运行,显然不利于技术的传播。而此专利通过使用四个连续帧主要为了提供更多的时空信息以保持结果的准确度,由此取得一个权衡。
基于深度学习的时空视频超分辨率技术方法需要经历获取数据集、模型构建、模型训练、参数优化、模型部署等过程。模型部署时一般需要使用的平台为带有GPU的Windows或Linux操作系统,对于大型服务器或高性能主机完全没有问题,但是难以在广大普通消费者的低性能设备或老旧设备上普及。这就需要构建并训练一个轻量化的且不失准确率的时空视频超分辨率模型。对于低性能设备也可以正常运行。
发明内容
本发明是针对背景技术中提到的技术问题,提供一种基于深度学习的轻量级高精度时空视频超分辨率方法。本发明的目的是通过轻量化的模型设计和结构以及处理流程的优化,使得本发明的模型具有高准确性和轻量化的优势,达到节省内存空间的目的,因为能够部署在低性能设备上,便于技术的应用和传播。
为实现上述目的,本发明采用的技术方案是:一种基于深度学习的轻量级高精度时空视频超分辨率方法,其特征在于,具体包括下列步骤:
(1)获取视频资源;
(2)通过ffmpeg软件将步骤(1)的视频资料分解为帧序列;
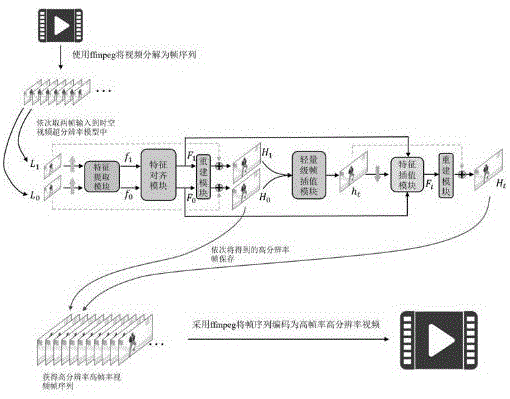
(3)从帧序列的首部开始,依次取连续的两帧作为模型的输入帧;
(4)模型接收两帧图像信息,在这两帧中插值一帧;同时又将两帧和插值的一帧图像重建为指定倍数的高分辨率图像;
(5)将所得到的高分辨率图像存储在硬件中,按照视频播放的顺序排序;
(6)采用ffmpeg将高分辨率连续帧根据帧率要求编码为新的高分辨率高帧率视频;
(7)发布新的视频。
作为优选的技术方案:步骤(1)中所述的视频资源为低分辨率视频和低帧率视频;其中低分辨率视频为720p以下的视频,低帧率视频为30fps以下的视频。
作为优选的技术方案:步骤(1)中视频资源为通过手机、摄像机、监控等终端设备获取离线视频资源;或通过互联网获取在线视频资源。
作为优选的技术方案:步骤(4)中所述的模型为基于深度学习模式且训练好的时空视频超分辨率模型,其使用了公开数据集Vimeo90K作为模型训练的数据集,并经过多次参数调整所达到的最优的模型。
作为优选的技术方案:所述模型给定低分辨率图像L
所述模型中的网络架构是先针对空间维度进行处理得到H
所述模型的处理流程如下:
(11)网络通过一个特征提取模块提取输入帧的特征;
(22)随后通过特征对齐模块对齐相邻帧特征信息;
(33)重建模块得到残差信息,从而重建出H
(44)使用一个轻量级的帧插值模块得到粗糙的高分辨率帧h
(55)通过提出利用经过对齐的F
(66)经过同样的重建过程得到高分辨率中间帧H
作为优选的技术方案:所述特征提取模块由5个级联的标准残差块构成。
作为优选的技术方案:所述的轻量级帧插值模块主要由一个精简的HRNet构成,主要作用是对图像扭曲的孔洞进行填补和细化。
作为优选的技术方案:所述的特征插值模块与特征对齐模块拥有一样的网络结构;所述的特征插值模块有15个标准残差块。
与现有技术相比,本发明的有益效果在于:
1、本发明仅采用了两个输入帧作为模型的输入,相比于采用三个连续输入帧或四个连续输入帧的方法,可有效防止模型推理过程中过多的内存占用,降低对设备性能的要求。
2、本发明的模型架构中采用了先处理空间维度(提升空间分辨率)然后处理时间维度(插帧)的策略,可以有效提升时空超分辨率的准确性;
3、本发明的模型架构中采用轻量级帧插值模块有效处理视频中的大运动,有效降低对内存的占用。
4、本发明中的模型采用全局残差连接的方式,简洁且高效,没有过多复杂的计算,有效提高处理效果。
附图说明
图1为本发明的处理过程流程图。
图2为本发明的模型中特征对齐模块网络结构图。
图3为本发明的模型中精简的HRNet结构图。
具体实施方式
下面结合附图和说明书对本发明的技术方案做具体说明。
本发明所公开的这种基于深度学习的轻量级高精度时空视频超分辨率方法,具体包括下列步骤。
(1)获取视频资源。
通过手机、摄像机、监控等终端设备获取离线视频资源,或通过互联网获取在线视频资源。这种视频资源为低分辨率视频和低帧率视频。其中低分辨率视频为720p以下的视频,低帧率视频为30fps以下的视频。这些视频具有空间分辨率低、帧率低等特性,需要提升其空间分辨率和帧率来满足用户流程平滑的视频体验,充分发挥高分辨率高帧率硬件资源(例如4K&120hz显示器,4K&120Hz VR眼镜, 2K&120Hz手机)的优势。
(2)通过ffmpeg软件将步骤(1)的视频资料分解为帧序列。
(3)从帧序列的首部开始,依次取连续的两帧作为模型的输入帧。
(4)模型接收两帧图像信息,在这两帧中插值一帧;同时又将两帧和插值的一帧图像重建为指定倍数的高分辨率图像。
先将两个输入帧图像重建为高分辨率图像,然后基于这两张高分辨率图像插值出中间帧的图像,最终得到三帧高分辨率图像。在两帧中插值一帧,目的是提升帧率;同时又将两帧和插值的一帧图像重建为指定倍数的高分辨率图像,目的是提升空间分辨率,从而获得时空超分辨率后的帧序列。采用了两个输入帧作为模型的输入,相比于采用三个连续输入帧或四个连续输入帧的方法,可有效防止模型推理过程中过多的内存占用,降低对设备性能的要求。
(5)将步骤(4)所得到的高分辨率图像存储在硬件中,按照视频播放的顺序排序。
(6)采用ffmpeg将高分辨率连续帧根据帧率要求编码为新的高分辨率高帧率视频。
(7)发布新的视频。
本发明的方法所介绍的为时间分辨率扩大一倍(帧率×2),空间分辨率扩大4倍(空间分辨率×4),其他时空倍数的组合本发明也可以实现。
步骤(4)中的模型为基于深度学习模式且训练好的时空视频超分辨率模型,其使用了公开数据集Vimeo90K作为模型训练的数据集,并经过多次参数调整所达到的最优的模型。模型给定低分辨率图像L
见图1,模型的处理流程如下:
(11)网络通过一个特征提取模块提取输入帧的特征,特征提取模块由5个级联的标准残差块构成;
(22)随后通过特征对齐模块对齐相邻帧特征信息;
(33)重建模块(包含pixel Shuffle layer)得到残差信息,从而重建出H
下表为单个标准残差块网络结构,单个标准的残差块结构如下表所示,首先通过一个Conv2d卷积层,然后使用ReLU函数激活,然后再经过Conv2d卷积层。
公式1
(44)此时,使用一个轻量级的帧插值模块得到粗糙的高分辨率帧h
(55)因此,通过提出利用经过对齐的F
(66)经过同样的重建过程得到高分辨率中间帧H
特征插值模块与特征对齐模块拥有一样的网络结构,特征插值模块有15个标准残差块。
特征对齐模块用来利用相邻帧的信息提升空间超分辨率结果的准确性。特征对齐模块首先获取对齐的特征fa 0和fa 1(使用光流信息进行扭曲),其获取方式采用上述公式1, 然后通过两个卷积层和30个标准残差块进行信息融合,得到融合的特征F
模型中轻量级帧插值模块主要由一个精简的HRNet构成,主要作用是对图像扭曲的孔洞进行填补和细化,见图3为精简的HRNet结构图。其是一种高分辨率表示网络, 适用于对位置敏感的任务, 可以提供较精准的空间特征, HRNet 在整个流程中保持 1/4 输入分辨率的特征表示,而特征宽度依次为 32、64 和 128。HRNet 将估计出一个用于混合两个扭曲帧的掩码 M 以及一个残差图像△ht, 通过下面的公式2可以得到粗糙的高分辨率中间帧 h
公式2
模型中所述的特征插值模块与图2所示的特征对齐模块拥有一样的网络结构,但仅有15个标准残差块。此特征插值模块可以获得时空相关的特征,提高重建效果。模型中的最后的重建模块可以依据时空相关的特征,重建出高质量的高分辨率中间帧结果H
下面以具体实施例介绍本发明。
上表中列出了本发明中的模型与现有技术在Vimeo90K上的对比。对比结果分为两种,一种是帧率×2,空间分辨率×2的结果对比; 另外一种是帧率×2,空间分辨率×4的结果对比。
对比指标为峰值信噪比Peak Signal-to-Noise Ratio(PSNR)和结构相似度Structural Similarity Index(SSIM), 其值越高代表结果越准确。同时采用了STARnet中使用的插值误差the average Interpolation Error (IE)衡量插值误差的准确性, 其值越低表示误差越小。
具体的,前16种技术方案为视频插帧技术和视频超分辨率技术的简单组合。其结果在精确度上不如本发明中的方案,同时模型的参数量远高于本发明中的6.57M。而STARnet、Zooming Slow-Mo、TMNet以及CycMu-Net为时空视频超分率方案,但其结果在准确度和模型参数量上都不如本发明的方案。
本发明的方案是轻量化的,仅拥有6.57M的参数量,其不会占有过多的存储。本发明在针对256×512的低分辨率和低帧率视频进行帧率×2,空间分辨率×4的时空超分辨率推理时,仅占用2.5G的内存。而其他方法通常需要超过10G的内存方可进行模型推理。这使得本发明方法可以在大多数的低性能设备或老设备上运行时空视频超分辨率模型。
- 一种基于深度学习的高效时空超分辨率视频压缩复原方法
- 一种基于深度学习的轻量级图像超分辨率重建方法