一种基于帧差法和语义分割结合的道路抛洒物识别方法
文献发布时间:2024-04-18 20:01:23
技术领域
本发明涉及道路上抛洒物识别技术领域,特别涉及一种基于帧差法和语义分割结合的道路抛洒物识别方法。
背景技术
随着经济和公路建设的发展,车辆成为商业运输以及人们出行的主要方式之一,道路上一旦发生交通事故,会造成重大人员伤亡和财产损失,抛洒物的出现,目前是道路交通事故原因之一,其危险程度较高,尤其在隧道、公路上,车流量大、车速较快,抛洒物的影响更为明显,因而,道路安全问题成了人们关注的焦点。抛洒物检测是目标检测领域的一个重要部分。通过道路监控图像进行抛洒物检测能够尽可能地减少道路安全隐患,提升高速公路行驶的安全性。
目前高速公路抛洒物识别方面,检测算法大多还是采取深度学习神经网络对场景进行深度学习,利用学习的成果再对实际场景中的抛洒物进行识别。这种解决方案的思路在于将抛洒物识别任务转化为目标识别,在对深度学习网络或算法进行大量训练后使用在学习中得到的经验和一系列参数对陌生的场景进行识别。常见的深度学习网络包括resnet等,常见的目标识别算法包括yolo,R-CNN系列等。目前这种技术有存在以下问题。
1、抛洒物种类多种多样,利用传统的目标识别算法(如yolo)的现有识别方案难以对抛洒物进行有效识别。
2、传统的深度学习网络难以对多种不同背景和环境下的抛洒物进行有效识别,如隧道,夜间和不良天气的环境背景。
3、传统的目标识别算法容易受到视频噪声的不利影响,在实际应用场景中,由于监控摄像头不会永远保持在最佳工作状态,这样就不时会出现噪声的影响,而这种影响对于传统的解决方案会造成很大的麻烦。
4、在传统的算法将熟悉环境的学习成果和系统参数转移到多种多样的陌生环境时,学习成果的正确性会打折扣。
5、交通意外事件属于偶发性事件,当交通意外发生时,由于各种客观原因限制,能采集到的清晰地视频或图片数量有限,清晰度也难以保证,现有利用深度学习的识别方法往往很依赖于数据的多样性和可靠性,在数据集不足或者数据的多样性不足的情况下,往往很难达到指标要求。
发明内容
为解决上述问题,本发明提供了一种基于帧差法和语义分割结合的道路抛洒物识别方法,采用了帧差法和语义分割结合的模式对高速公路抛洒物进行识别,先通过对视频流数据进行帧读取,利用相邻帧的背景差图像进行抛洒物的一次识别,进而对疑似抛洒物的目标原帧图像进行语义分割,实现最终的分类识别,利用帧差法进行抛洒物的初识别,克服了环境等因素对目标检测的影响,对疑似目标原帧图像进行语义识别,保证了最终识别效果的准确性,同时两者结合,增强了算法的可迁移性。
本发明提供了一种基于帧差法和语义分割结合的道路抛洒物识别方法,具体技术方案如下:
获取监控位置的目标视频流数据;
设定背景帧窗口,设置指针基于设定的背景帧窗口大小读取视频流;
每读取一个背景帧窗口的图像数据,将前x-1帧和当前帧的图像画面作为一个窗口,通过中值法,计算当前时刻的背景;
基于相邻时刻的背景,计算下一时刻背景和当前时刻背景的背景差;
对背景差图像进行图像处理操作,获得背景帧差图;
计算得到的所述背景帧差图中黑色像素点的比例,当比例超过设定阈值时,判定当前监控检测的路面上有疑似抛洒物滞留;
对出现疑似抛洒物的背景帧差图进行语义分割,判定其是否为落在目标道路上的抛洒物。
进一步的,当前时刻的背景,计算过程如下:
在基于背景帧窗口读取过程中,从读取的背景帧窗口中记录各帧中每个区域出现颜色的持续时间;
将持续时间超过设定时间阈值的颜色,判定为这个小区域的背景色。
进一步的,所述图像处理,为对所述背景差图像依次进行灰度化处理、二值化处理和降噪处理。
进一步的,所述语义分割采用被检测出疑似抛洒物滞留的当前帧的原帧画面。
进一步的,所述语义分割采用mmsegmentation模型。
进一步的,mmsegmentation模型采用The Highway Driving Dataset数据集进行训练。
本发明的有益效果如下:
基于设定背景帧窗口通过指针对视频流数据进行读取,能够对监控摄像的视频流进行实时处理,通过计算相邻帧的背景差,并经过图像处理获得背景帧差图,通过计算像素点比例,实现抛洒物的初次识别,再通过语义分割进行进一步的识别,判断物体种类,并对路面上有物体停留的情况实时发出报警,利用帧差法和语义分割结合,实现对道路抛洒物的精确识别,同时克服了环境造成的识别困难的影响。
附图说明
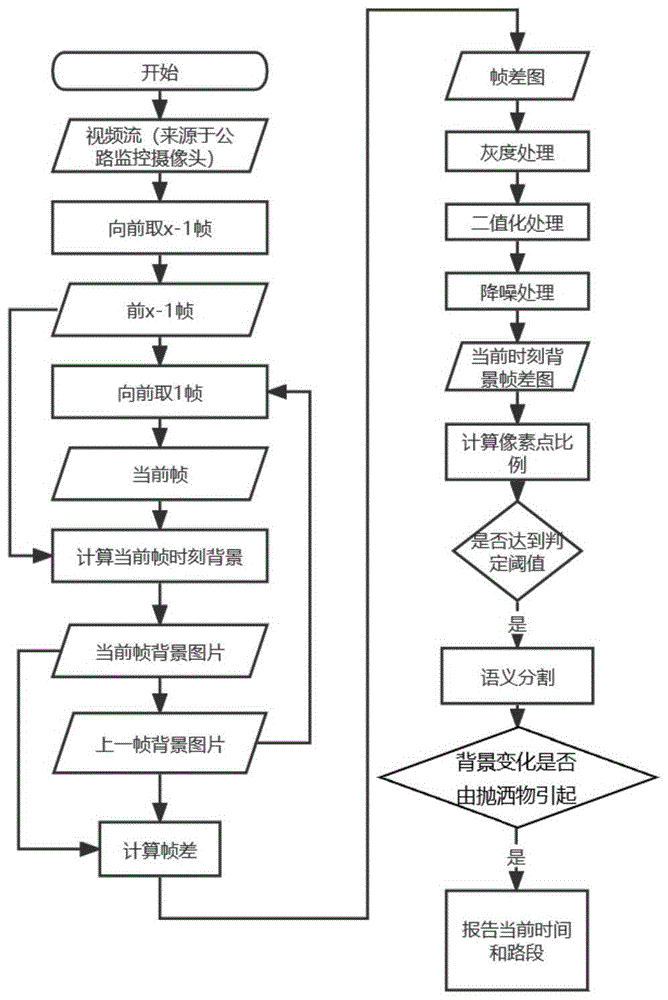
图1是本发明的方法流程示意图。
具体实施方式
在下面的描述中对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明实施例的描述中,需要说明的是,指示方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,或者是本领域技术人员惯常理解的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于区分描述,而不能理解为指示或暗示相对重要性。
在本发明实施例的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是直接连接,也可以通过中间媒介间接连接。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
实施例1
本发明的实施例1公开了一种基于帧差法和语义分割结合的道路抛洒物识别方法,如图1所示,首先通过帧差法进行抛洒物的一次识别;
帧差法是一种通过对视频图像序列中相邻两帧作差分运算来获得运动目标轮廓的方法,它可以很好地适用于存在多个运动目标和摄像机移动的情况。
一段视频是由若干个帧构成的,帧实质上是一张静止的图片,对一系列静止图片快速播放即可构成整个视频,其原理是使用当前帧和过去的若干帧进行比较,当监控场景中出现异常物体运动时,帧与帧之间会出现较为明显的差别,两帧相减,得到两帧图像亮度差的绝对值,判断它是否大于阈值来分析视频或图像序列的运动特性,确定图像序列中有无物体运动,对于那些在过去这一段时间中颜色和纹理特征完全没有变化或变化很小的区域,即可认定为是静止不动的背景,而那些有剧烈变化的区域即可认定为是运动物体。由于高速公路上的监控摄像头是静止不动的,背景在视频中也是静止的,所以可以使用帧差法对运动物体进行识别;抛洒物最终会以静止的状态掉落在高速公路路面上,在掉落的过程中,抛洒物是一个运动物体,而抛洒物停止运动后,帧差法就无法检测出这个运动物体,当某个运动物体在视频中消失并“融入背景”逃脱帧差法的检测时,即可认为有物体停留在了高速公路上,此时对帧差法的使用就已经结束,进入下一步检测。
结合图1所示,一次识别具体流程如下:
获取监控位置的目标视频流数据;
具体的,可从待监控检测识别位置处获取高速公路摄像头的视频流数据。
设定背景帧窗口,设置指针基于设定的背景帧窗口大小x读取视频流;
本实施例中,设定60帧(即x为60)为一个背景帧窗口来计算背景,设置指针R来读取获得的视频流数据。
每读取一个背景帧窗口的图像数据,将前x-1帧和当前帧的图像画面作为一个窗口,通过中值法,计算当前时刻的背景;
基于相邻时刻的背景,计算下一时刻背景和当前时刻背景的背景差;
本实施例中,具体如下:
R开始读取视频流中的帧并向前移动,R每读取x帧时,将前x-1帧和当前帧的图像画面作为一个窗口,使用中值法,计算当前时刻t的背景B_t;
在下一时刻R向前移动一帧,再对当前帧和前x-1帧用中值法计算当前t+1时刻的背景B_(t+1);
本实施例中,当前时刻的背景,计算过程如下:
在基于背景帧窗口读取过程中,从读取的背景帧窗口中记录各帧中每个区域出现颜色的持续时间;
将持续时间超过设定时间阈值的颜色,判定为这个小区域的背景色。
在得到相邻两个时刻的背景后,计算t和t+1时刻的背景差,即帧差。
基于指针持续读取视频流的帧图像,实现对监控视频的实时目标检测。
计算获得相邻时刻的背景差获得背景差图,即帧差图,对背景差图像进行图像处理操作,获得当前时刻的背景帧差图;
本实施例中,所述图像处理,为对所述背景差图像依次进行灰度化处理、二值化处理和降噪处理。
计算得到的所述背景帧差图中黑色像素点的比例,当比例超过设定阈值时,我们判断当前帧和前一帧的背景图像发生了变化,即说明有疑似抛洒物的物体滞留在路面上,融入了背景中;若未达到阈值,则说明路面情况正常,没有异常事件发生。
对一次识别后的结果,采用部分第三方的语义分割模型并进行部分优化来进行语义分割;语义分割模型会将一张关于高速公路的图片分成车辆,行人,路面,背景,交通标志牌等多个种类,其精确度可以将图片中每一个像素点归入某一类;在前一步发现有物体停留在高速公路上之后,我们使用语义分割对此帧进行语义分割,判断停留的物体具体是什么,具体位置是否停留在高速公路路面上。当抛洒位置不在高速公路路面(比如落在路边)时,算法可以选择不报警;而当抛洒位置在路面上时,算法报警通知相关部门进行处置。
结合图1所示,具体如下:
对出现疑似抛洒物的背景帧差图进行语义分割,判定其是否为落在目标道路上的抛洒物;
当确有抛洒物事件发生时,向控制端报告当前时刻和发生抛洒物事件的路段,以便对路面进行清理。
本实施例中,所述语义分割采用被检测出疑似抛洒物滞留的当前帧的原帧画面。
本实施例中,所述语义分割采用mmsegmentation模型作为基本模型进行训练和优化。
具体的,mmsegmentation模型在训练中,采用The Highway Driving Dataset数据集进行训练,该数据集包含了大量的高速公路相关数据。
本发明并不局限于前述的具体实施方式。本发明扩展到任何在本说明书中披露的新特征或任何新的组合,以及披露的任一新的方法或过程的步骤或任何新的组合。