一种基于BERT和前馈神经网络的文本纠错方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明属于人工智能和自然语言处理领域,尤其涉及一种基于BERT和前馈神经网络的文本纠错方法。
技术背景
文本纠错是一项纠正文本中错误内容的自然语言处理技术,具体包含拼写纠错、语法纠错和特点场景下的语义语用纠错等纠错对象。其中拼写纠错的特点是不改变文本长度,只对文本中出现的错别字进行一对一的纠正;语法纠错和语义语用纠错需要处理文本中的多词错误、少词错误、用词错误和词序错误等错误,可能改变文本的长度。
近年来诸如BERT的大规模深度预训练语言模型促进了自然语言处理领域的快速发展,使得在进行具体的文本处理任务时能够获得一个较好的初始文本语义表示,从而减少模型收敛所需要的时间和成本。
传统文本纠错主要采用基于规则或翻译模型的方法,其中基于规则的方法主要依靠人工定义替换词字典,只能对特定的几种错误进行纠正;利用翻译模型进行文本纠错是目前的主流方法,并且基于神经网络的翻译模型已经替代基于统计的翻译模型用于纠错,该方法将文本纠错作为从错误句子翻译为正确句子的翻译问题来解决,虽然效果良好、语句通顺,但是需要大量训练数据,并且在使用时存在耗时长的问题。另外,如果只针对拼写错误进行纠正,目前主要采用序列标注方法,能快速纠正错别字,但是不适用于其它错误的纠正。
发明内容
本发明的目的在于针对现有技术的不足,提供一种基于BERT和前馈神经网络的文本纠错方法。本发明采用一种简便的模型识别和纠正文本中存在的各种错误。
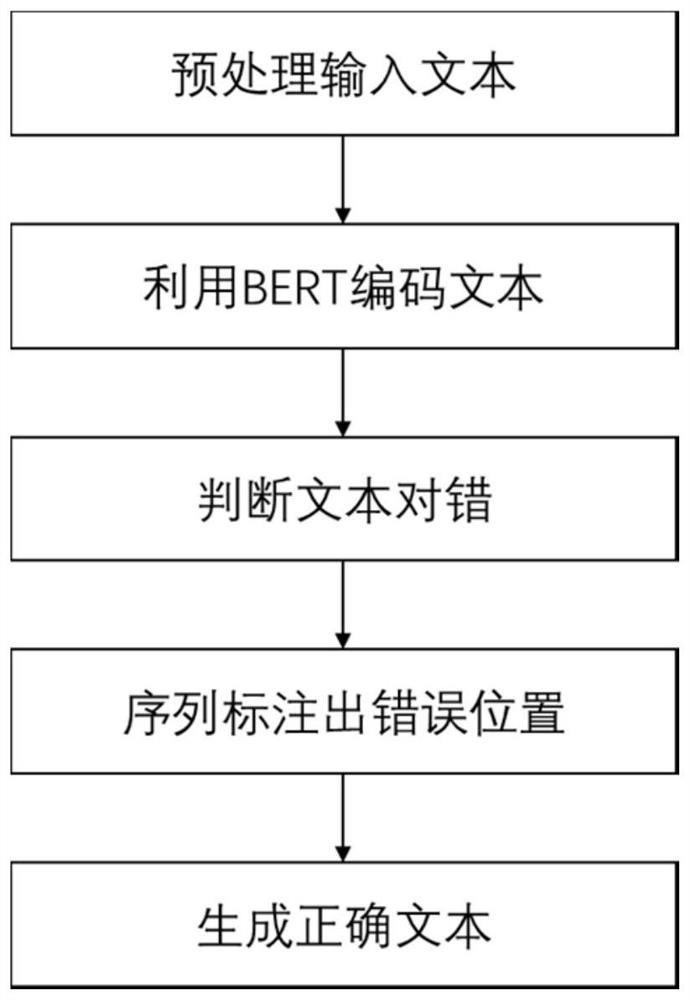
本发明的目的是通过以下技术方案来实现的:一种基于BERT和前馈神经网络的文本纠错方法,包含以下步骤:
1)对于文本纠错语料数据进行预处理。
2)将步骤1)预处理后的输入文本基于BERT编码,得到特征表示和语义表示。
3)基于步骤2)得到的输入文本语义表示,判断文本是否为正确文本。
4)基于步骤2)得到的输入文本特征表示和步骤3)的判断结果,检测文本中错误的位置。
5)基于步骤4)找到的错误位置,生成错误文本对应的正确文本。
进一步地,所述步骤1)中,数据预处理方法:
1.1)对于获取的文本数据进行预处理操作。
1.2)对文本进行分词,如果为中文,则按字为单位进行分词;如果是英文,按wordpiece形式进行分词。
1.3)在文本开始处添加特殊字符“[CLS]”,在结束处添加特殊字符“[SEP]”。
1.4)如果为训练数据,通过比较分词后的源字符串和目标字符串,计算文本对错标签、字符错误类型标签和错误对应正确文本的标签。
进一步地,所述步骤2)中,基于BERT编码文本表示:
2.1)利用BERT预训练字词向量和位置向量,字词嵌入和位置嵌入输入文本,获得文本初步向量表示:
其中,E
2.2)利用BERT中的L层Transformer模块获取每个字符的语义特征表示
H
2.3)利用“[CLS]”字符对应特征
进一步地,所述步骤3)中,判断文本是否为正确文本:
3.1)选择步骤2.3)中由BERT输出的文本整体语义表示c,作为判断文本对错的特征。
3.2)使用前馈神经网络,将c映射为一个数值,然后使用sigmoid函数,计算得到预测文本不正确的概率:
P
其中,W
3.3)将P
3.4)对于判定为正确的输入文本,不再进行后续的纠错操作,直接将输入文本作为纠错结果输出。
3.5)在模型训练时,使用二元交叉熵损失函数来计算文本对错判断的损失值:
Loss
其中,y
进一步地,所述步骤4)中,检测文本中错误的位置:
4.1)选择步骤2.2)中由BERT输出的每个字的特征表示H
4.2)定义每个字符的类型为正确、冗余、正确但后面缺失内容和用词错误,每个字符对应这四种类型中的一种,其对应的操作标签分别为保留、删除、在后面添加和替换。
4.3)使用前馈神经网络结合softmax函数对输入文本进行序列标注,用于检测需要对每个字符进行的操作:
其中,
4.4)在获得输入文本的预测标签序列后,基于规则获取文本中的错误位置pos=(s′,e′):对于连续的删除标签或者连续的替换标签,其推导出的错误开始位置s’和结束位置e’为连续标签所在位置区间[s,e]的前一个位置和后一个位置,即s′=s-1,e′=e+1;对于标签序列中的每一个在后面添加标签,其推导出的错误开始位置s’为该标签自身的位置s,错误结束位置e’为开始位置后面的一个位置,即e′=s′+1。
4.5)对于预测序列标签全部是由保留标签构成的输入文本,不再进行后续的纠错操作,直接将输入文本作为纠错结果输出。
4.6)在模型训练时,使用交叉熵损失函数来计算序列标注的损失值:
其中,
进一步地,所述步骤5)中,生成错误文本对应的正确文本:
5.1)依据步骤4.4)中获得的错误位置,从步骤2.2)中获得的所有字符特征向量H
其中,s和e为一个错误的开始和结束位置,
5.2)定义一个深度学习模型学习的位置嵌入矩阵E′
5.3)利用多层前馈神经网络,结合错误信息和位置嵌入向量,提取正确文本特征:
h
其中,h
5.4)结合softmax函数,将错误特征表示映射到BERT定义的字典大小维度中,取字典中概率最大的字作为生成的第j个字:
此处多层前馈网络最后一层使用的权重参数为BERT中字词嵌入矩阵E
5.5)在模型训练和使用时,对一个错误都将生成MAX_LEN个字的纠错文本,但是只截取生成文本中出现特殊字符“[EOP]”之前的文本作为结果,如果没有生成特殊字符“[EOP]”则将全部生成的文本作为结果。
5.6)利用步骤4.4)中检测出的错误位置,结合生成的正确文本,替换输入文本中的错误内容,同时删除添加的特殊字符“[CLS]”和“[SEP]”,得到最终纠错的输出。
5.7)在模型训练时,使用交叉熵损失函数来计算文本生成的损失值:
其中,m是一个文本中错误的个数;k
本发明的有益效果是:本发明将序列标注用于文本纠错的处理对象,使得能够使用序列标注方法快速准确纠正各种类型的错误,而不仅限于拼写纠错;本发明基于BERT进行文本纠错,可对大规模语料中的错误文本进行纠错并生成正确的文本,同时改进传统基于翻译模型纠错方法耗时长的问题,将文本纠错由逐个字生成正确句子的串行过程优化为只针对错误内容用前馈神经网络进行纠错的并行过程。
附图说明
图1是本发明提出方法的流程图;
图2是本发明设计的文本纠错模型架构图;
图3是本发明采用的BERT模型内部结构图。
具体实施方式
下面结合附图以及具体实例对本发明提出的方法进行进一步的详细说明。
本发明一种基于BERT和前馈神经网络的文本纠错方法,使用深度学习方法,结合预训练语言模型BERT,能有效的从文本中提取出字词词性、句法结构等语义信息,从而获得每个字在上下文中的特征表示。此外,本发明设计的三个不同的前馈神经网络,能利用提取到的特征信息,分别进行文本对错判断、错误位置检测和正确文本生成的功能,将各模块有机结合起来,即可实现本发明文本纠错的目的;如图1所示,包括以下步骤:
1、数据预处理
对于文本纠错语料数据,首先对每个文本进行分词操作;特别地,对于中文文本,按照字为单位进行切分;对于英文单词,除按照空格进行切分每个单词外,还要利用大规模英文语料的统计结果,将每个单词切分成word piece形式。在分词后,根据实际需求设置停用词字典,过滤文本中的停用词。另外,需要在每个文本的开头处添加一个表示文本开始的特殊字符“[CLS]”,以及在文本末尾处添加一个表示文本结束的特殊字符“[SEP]”。
对于训练数据集,需要通过比对输入文本X={x
文本正确还是错误的标签y
用于标记错误类型的标签序列元素
其中,纠错的目标文本
2、BERT编码
将输入文本X进行BERT编码操作主要分为两步:
第一步是字词嵌入,会把X中的每个字转换为向量表示,这利用到了BERT定义的两个嵌入矩阵,分别是字嵌入矩阵E
第二步是基于Transfomer的自注意力编码表示模块,由L层Transfomer模块构成,每层计算方式相同,都使用前一层的输出作为输入:
H
其中,l=1~L;第一层的输入为字词嵌入后的文本
此外,BERT在预训练时将第一个输入字符“[CLS]”对应的输出
其中,tanh为激活函数,W
3、文本对错判断
判断输入文本X是否为正确文本,如果判断是正确文本则不再进行后续的错误位置检测和文本纠错操作,判断方法为利用步骤2得到的输入文本语义表示c,结合前馈神经网络进行对错判断的二分类任务:
P
其中,二分类任务输出结果是输入文本的错误概率P
在模型训练时,使用二元交叉熵损失函数BCELoss来计算文本对错判断的损失值:
Loss
4、错误位置检测
检测文本中哪些位置上的字词是错误的,并根据错误类型在对应的位置打上标签。采用序列标注的方法,使用一个前馈神经网络处理步骤2得到的输入文本的特征表示H
其中,i1=1~n;W
在模型训练时,使用交叉熵损失函数CrossEntropLosss来计算序列标注的损失值:
在使用前馈神经网络进行序列标注,检测出需要对每个字进行的操作后,可以计算出文本中错误存在的开始位置和结束位置。假设在输入n个字符的文本X后,获得的n个操作中,输入{x
在本发明中定义的错误开始位置比实际的位置前移一个单位,定义的错误结束位置比实际的位置后移一个单位,这一方面是为了便于获取正确文本生成的输入数据,另一方面是为了统一各错误类型的处理流程。因为对于多词错误、用词错误而言,需要对它们进行删除和替换操作,错误的位置可以直接定义到文本中错误的字词上,而对于少词错误,是需要在两个字之间插入缺失的字词,这两个字本身并没有错误,所以需要将错误位置的范围前后扩大一个字,即开始位置为错误的前一个字,结束位置为错误的后一个字。
5、正确文本生成
在得知错误位置后,基于错误所在的上下文语义信息,基于前馈神经网络的方法并行生成错误对应的正确文本;需要分成三步进行:
第一步,根据步骤4中得到的错误位置,截取步骤2中得到的文本表示H
其中,mean表示求平均。在这步中,如果处理的是少词错误,则s′+1=e′,即没有中间的状态向量,对此设置一个初始值为随机值,并在模型训练中优化的变量h
第二步,利用多层前馈神经网络,结合错误信息和位置嵌入向量,提取正确文本特征。由于需要利用一个错误的上下文信息h
h
其中,i3是指文本中存在的第i3个错误,j是指第i3个错误目标生成的第j个字。由于在实际使用本发明模型进行纠错时,不知道错误对应的正确文本究竟由几个字构成,所以在训练和使用模型时统一限制生成MAX_LEN个字,再根据生成文本中的特殊字符“[EOP]”出现的位置,截取“[EOP]”之前生成的字作为纠错结果。如果没有生成特殊字符“[EOP]”则将全部生成的文本作为结果。
第三步,使用前馈神经网络从特征h
其中,j=1~k
通过上述操作,可以得到步骤4中检测出错误对应的正确文本,再结合错误在输入文本中出现的位置,即可带回原文进行修改并得到纠错后的文本。
在模型训练时,使用交叉熵损失函数CrossEntropLoss来计算文本生成的损失值:
其中,m是一个样本对应的错误个数,k
为了体现本发明对各种文本错误类型的纠正具有通用性,结合四个文本实例进行本发明提出的文本纠错方法说明。假设有一个正确的输入文本X1=“保护知识产权”;一个带有少字错误的输入文本X2=“保护知识”;一个带有用词错误的输入文本X3=“保护知只产权”;一个带有多字错误的输入文本X4=“保护护知识产权”,下面介绍如何对这四个文本进行纠错。
如图2~3所示,本实施例的方法由五个步骤组成:
步骤1:预处理输入文本,对于中文文本按字为单位进行分词,并且在文本开始处添加特殊字符“[CLS]”,在文本结尾出添加特殊字符“[SEP]”。
得到的处理结果为X1=[“[CLS]”,“保”,“护”,“知”,“识”,“产”,“权”,“[SEP]”],X2=[“[CLS]”,“保”,“护”,“知”,“识”,“[SEP]”],X3=[“[CLS]”,“保”,“护”,“知”,“只”,“产”,“权”,“[SEP]”],X4=[“[CLS]”,“保”,“护”,“护”,“知”,“识”,“产”,“权”,“[SEP]”]。
此处假设本发明提出的纠错模型已经训练完成,处于运用模型进行纠错的阶段,故不需要计算模型训练需要的目标值。
步骤2:利用BERT编码输入文本,假设使用基础版本的中文预训练BERT模型,它的字词嵌入维度为768,词表大小为21128个,共由12层Transformer模块堆叠而成。
处理流程为先对文本进行字词嵌入和位置嵌入,然后将嵌入后的文本输入Transformer模块中,取最后一层Transformer模块的输出,获得每个文本的整体特征表示c以及每个文本中每个字在文本中的语义表示
步骤3:判断文本对错,将步骤2得到的文本整体表示c输入前馈神经网络,再输入sigmoid函数,获得文本对错的概率P
例如上述四个文本的预测结果分别是0.1、0.8、0.9和0.8,设置的阈值为0.5,则认为第一个文本X1是正确的,而其它三个文本是错误的。
对于预测正确的文本,直接将原始的输入文本作为模型的纠正输出,不再进行后续的纠错操作。
步骤4:序列标注出错误的位置。对于步骤3中检测出的含有错误的文本,在本步骤中会检测出错误的具体位置,处理方式为利用前馈神经网络对步骤2中得到的每个字的语义表示
操作的类型由保留、删除、在后面添加和替换四种,它们的数值对应表示分别为0、1、2和3。对于文本X2,其中“识”字对应的概率假设为
在获得操作序列后,可以计算出错误在输入文本中的开始位置和结束位置,如文本X2的错误位置为(5,6),X3的为(4,6),X4的为(2,4)。
如果一个文本在本步骤中未检测出错误的位置,即获得的操作序列全部由0构成,则认为这个文本同样是正确的,直接将该文本作为模型的纠错结果输出。
步骤5:生成正确文本。本步骤需要使用步骤2获得字词语义表示
之后通过给h
最后使用BERT本身的字词嵌入矩阵E
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 一种基于BERT和前馈神经网络的文本纠错方法
- 一种基于CNN与BERT模型的英文语法纠错方法