一种基于同义词发现的网页表格信息解析方法
文献发布时间:2023-06-19 11:52:33
技术领域
本发明属于数据处理方法技术领域,具体涉及一种基于同义词发现的网页表格信息解析方法。
背景技术
随着计算机的诞生和普及,人与计算机的交互已经融入了日常生活中,人类已经步入信息时代。如今,计算机己然成为人们娱乐、生活、工作的重要工具,并帮助人们大幅度提高工作效率、完成人类自身不能完成的计算量等巨大任务。同时,互联网信息量随着网络的加速、网络节点的增加以及硬件性能的提高迎来指数爆发式增长,人工处理这些海量数据是一个不可能完成的任务,要从海量数据中筛选出有用信息,须依靠计算能力强大的计算机。
随着信息化的快速发展,网页数据无论是数量还是传播速度都呈现几何级的增长,网页数据处理技术的运用也越来越广泛,不管是日常生活还是工业生产,网页数据处理变得越来越重要。网页数据处理是用计算机对网页进行解析,以达到提取信息、整合信息的技术。现代社会网页数据中表格无处不在,对于网页中表格文本信息进行查找、搜索成了常态,但对于上百万网页的表格信息,人工查找起来过于繁琐,而且容易出现遗漏、出错,造成了不可预估的损失,现有的文本处理网页信息系统自动化程度低,且通用性不高,无法满足网页数据信息多样性和复杂性的要求,如何快速而且准确的将网页结构中所需的关键信息定位并且提取出来成了多个领域的热点问题。
针对网页文本信息的非结构化特征和无序性,一般只能采用全文检索的方式查找。但是网页中充斥着大量的无关信息,比如广告和无关链接以及其他内容,有用信息和无用信息混杂在一起,给网页信息的检索问题带来极大的困难。
发明内容
本发明的目的是提供一种基于同义词发现的网页表格信息解析方法,解决了现有网页文本信息检索效率低下的问题。
本发明所采用的技术方案是,一种基于同义词发现的网页表格信息解析方法,包括以下步骤:
步骤1,网页原始数据预处理,即去掉原始数据中无用代码符号和代码,得到预训练文本;
步骤2,对步骤1中的预训练文本进行分词预处理,随后进行关键词筛选,筛选结束后得到关键词词典;将关键词词典再次进行分词,生成词向量的基本知识库;
步骤3,将步骤2得到的基本知识库利用词向量技术,得到目标词的相近词出现的概率,获得同义词词典;
步骤4,解析待处理网页中的数据,根据网页表格标签代码样式,把网页中的表格数据转存到一个预先设置的二维数组列表里;
步骤5,通过步骤3的同义词词典对步骤4中的二维列表里的数据进行定位,然后根据特征信息的特点,进行信息提取和整合,完成解析过程。
本发明的特征还在于,
步骤1中的预训练文本为格式为.Json或.txt的文本信息。
步骤2的具体步骤为:
步骤2.1,构造停用词库,采用分词法对步骤1中的预训练文本进行分词预处理;
步骤2.2,将步骤2.1分词预处理得到的分词文本结果逐行读取文本,遍历词条,组合当前词条和下一词条,出现如下三种情况:
若两词条皆不为停用词,则将其组合一起作为新词条存入新的组合词库中;若当前词条为停用词,则忽略当前词条;若下一词条为停用词,则忽略下一词条,进行重组;
步骤2.3,对经步骤2.2处理得到的文本数据结果进行关键词筛选分类,把相似的词条筛选出来,得到关键词词典,作为二次分词的自定义词库;
步骤2.4,对于步骤2.3得到的自定义词库重新分词,即再次执行步骤2.1-2.3,得到生成词向量的基本知识库。
步骤2.1具体为:
步骤2.1.1,构造前缀词典,将词条作为键,词频作为对应的键值,遍历前缀词典,若前缀对应的键不存在,则将该前缀设为词典新的键,并将对应键值设置为0;
步骤2.1.2,使用正则表达式切割步骤1的预训练文本,预训练文本中每一个单独的子句均可生成一个有向无环图DAG,使用概率最大路径分词;
步骤2.1.3,对未登录词则采用隐马尔可夫模型HMM的联合概率建模;随后通过Viterbi算法求出概率最大的状态序列,然后基于状态序列输出文本的构词位置,进行分词。
步骤3具体为:
步骤3.1,根据基本知识库建立词汇表,词汇表中任一单词拥有一个随机的词向量;将单词w
步骤3.2,根据单词w
步骤3.3,采用梯度下降法调整分类器中输入的词向量,使得实际路径向正确路径靠拢;在训练结束后,从词汇表中得到每个单词对应的词向量,获得词向量模型;
步骤3.4,保存步骤3.3的词向量模型,调用most_similar方法得到关键词的同义词,获得同义词词典。
步骤4具体为:
步骤4,解析待处理网页中的数据,根据网页表格标签代码样式,把网页中的表格数据转存到一个预先设置的二维数组列表里。
步骤4.1,使用Beautifulsuop模块对待处理网页结构解析,利用网页中的表格标签定位到表格相应位置,查找到网页中成对的最小表格标签;
步骤4.2,计算表格中tr、td的数量,从而给出二维列表的行数,然后自定义给出列数,通过步骤4.1中解析网页标签的方式填入表格信息。
本发明的有益效果是:本发明一种基于同义词发现的网页表格信息解析方法,主要分为数据获取,数据处理和数据使用三大部分,可实现对于用户所需数据的准确提取,由于把网页中的表格数据首先进行了转存,因此不会受限于网页代码的限制,也不用受制于网络中表格形式的多样性等优点,由于进行了同义词发现过程,进一步增加了信息提取的准确性。
附图说明
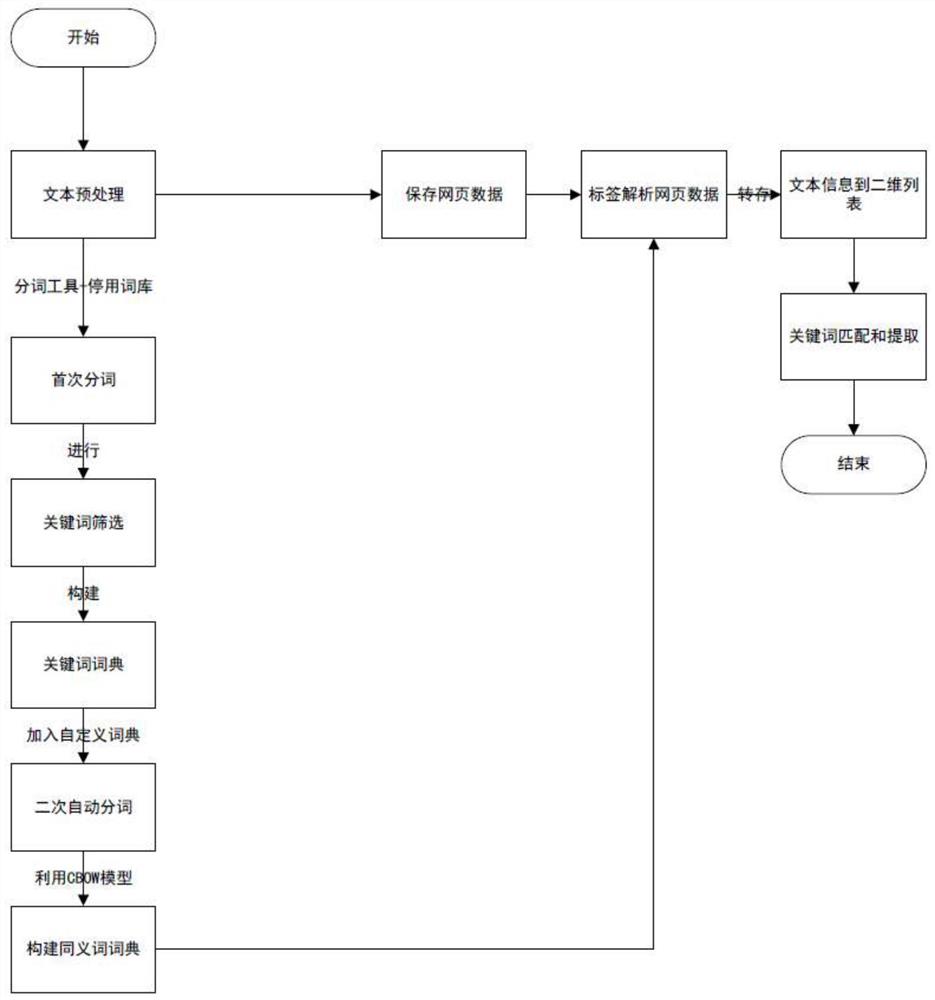
图1是本发明一种基于同义词发现的网页表格信息解析方法的流程图;
图2是本发明一种基于同义词发现的网页表格信息解析方法中分词的流程图;
图3是本发明一种基于同义词发现的网页表格信息解析方法中CBOW训练词向量模型图;
图4是本发明一种基于同义词发现的网页表格信息解析方法中表格信息处理的系统架构图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于同义词发现的网页表格信息解析方法,如图1所示,包括以下步骤:
步骤1,进行网页原始数据预处理,去掉原始数据中无用代码符号和代码,得到格式为.Json或.txt的文本信息作为预训练文本。
步骤2,对步骤1中的预训练文本进行分词预处理,随后进行关键词筛选,筛选结束后得到关键词词典;将关键词词典再次进行分词,生成词向量的基本知识库。
步骤2.1,构造停用词库,采用分词法对步骤1中的预训练文本进行分词预处理。
如图2所示,步骤2.1.1,根据统计词典构造前缀词典,将词条作为键,词频作为对应的键值,遍历前缀词典,若前缀对应的键不存在,则将该前缀设为词典新的键,并将对应键值设置为0;
步骤2.1.2,使用正则表达式切割步骤1的预训练文本,预训练文本中每一个单独的子句均可生成一个有向无环图DAG,有向无环图DAG的起点到终点有若干路径,使用概率最大路径进行分词;
步骤2.1.3,对未登录词则采用隐马尔可夫模型HMM的联合概率建模,如公式(1)所示:
公式(1)中,参数x为观察变量序列,参数y为隐状态变量序列,参数start为开始时刻的标签,参数end为结束标签,参数L为某个时刻参数p(y
在构造联合概率时,每个词在构造特定词语时都占据着确定构造位置,设定每个字最多只有四个构词位置:即词首B、词中M、词尾E和单独成词S,用数学语言表达如公式(2):
将经联合概率建模处理后的文本传入后,通过Viterbi算法求出概率最大的状态序列,然后基于状态序列输出文本的构词位置,进行分词。
步骤2.2,将步骤2.1得到的分词文本结果进行逐行读取文本,遍历词条,组合当前词条和下一词条,出现如下三种情况:
若两词条皆不为停用词,则将其组合一起作为新词条存入新的组合词库中;
若当前词条为停用词,则忽略当前词条;
若下一词条为停用词,则忽略下一词条,进行重组。
步骤2.3,对步骤2.2得到的文本数据结果进行关键词筛选分类,把相似的词条筛选出来,得到关键词词典,作为二次分词的自定义词库;
步骤2.4,对于自定义词库重新分词,即再次执行步骤2.1-2.3,即得到生成词向量的基本知识库。
步骤3,将步骤2的基本知识库利用词向量技术,得到目标词的相近词出现的概率,获得同义词词典。
步骤3.1,根据步骤2处理后的基本知识库建立词汇表,词汇表中任一单词拥有一个随机的词向量。
将单词w
步骤3.2,根据单词w
步骤3.3,采用梯度下降法调整分类器中输入的词向量,使得实际路径向正确路径靠拢;在训练结束后,从词汇表中得到每个单词对应的词向量,获得词向量模型;
步骤3.4,保存步骤3.3的词向量模型,调用most_similar方法得到关键词的同义词,获得同义词词典。
步骤4,如图4所示,解析待处理网页中的数据,根据网页表格标签代码样式,把网页中的表格数据转存到一个预先设置的二维数组列表里。
步骤4.1,使用Beautifulsuop模块对待处理网页结构解析,利用网页中的表格标签定位到表格相应位置,查找到网页中成对的最小表格标签;
步骤4.2,计算表格中tr、td的数量,从而给出二维列表的行数,然后自定义给出列数,通过步骤4.1中解析网页标签的方式填入表格信息。
步骤5,通过步骤3的同义词词典对步骤4中的二维列表里的数据进行定位,然后根据特征信息的特点,进行信息提取和整合,从而完成解析过程。
实施例
目标:使用本发明方法,在网页数据中,提取关键词中标金额对应的金额信息。
具体应用过程如下:
首先提取json数据中的网页文本数据,制成预处理之前的数据集;
然后对数据集中文本数据进行第一次分词预处理,得到分开的中标和金额两个词条,在此基础上进行词语的组合,基于停用词典结合、同时结合当前词条和下一词条,则有以下三种情况:若两词条皆不为停用词,则将其组合在一起作为新词条存入新的组合词库中,若当前词条为停用词,则忽略当前词条;若下一词条为停用词,则忽略下一词条,进行重组;
在第一次分词完成后,中标金额已成为一个词条,接着进行关键词筛选和聚类方法的应用,以得到中标金额相关的词典,将此词典作为自定义词典,加入分词工具中,即可得到自动分出来的中标金额等相关词语;
最后利用word2vec中的CBOW模型共现中标金额的相似词,接着以此结果做为关键词同义词词典,在保存网页数据的二维列表里进行关键词的定位和匹配,最后根据表格存储的特点,得到中标金额所对应的金额信息,如果是在表格外的文本信息里,则可以直接定位提取。
- 一种基于同义词发现的网页表格信息解析方法
- 基于Web时态对象模型的过时网页信息自动发现方法