一种物联网场景下的密文相似数据去重管理方法
文献发布时间:2023-06-19 18:30:43
技术领域
本发明属于信息安全技术领域,公开了数据去重在新领域的应用,具体涉及一种物联网场景下的密文相似数据去重管理方法。
背景技术
随着物联网和智能化社会的发展,使得物联网数据呈爆炸式增长,本地存储空间难以对其进行有效地存储和管理,部分物联网设备采用迭代覆盖等技术以降低存储压力,如监控视频的存储有效期仅为一个月,这大大降低了物联网数据的可用性和可追溯性,难以满足一些企业或用户进行数据分析或异常查看的要求。
云存储的产生为海量数据的存储管理提供了实用的补救措施。然而,由于云存储的一对多服务架构以及不同用户之间存在信息壁垒,使得大量的冗余数据占据云存储空间。数据去重技术可以使得数据只保留一个,并删除其他重复的副本,有效解决了数据冗余问题。然而,由于物联网数据的特殊性特征,使得现有数据去重方案无法适用于物联网数据。
与普通互联网数据不同,物联网数据具有规范性,数据格式和大小都是一样的。并且来自同一地区的同一设备的数据大多是相似的,并携带相同的信息。由于记录的具体数据和时间戳等存在微小的差异,大量的相似数据无法被归类为相同的数据,使得目前的数据去重方法无法识别相似数据,不适合当前的物联网系统。
此外,物联网数据的实时性特点对数据处理的响应速度也有较高的要求。边缘计算可以采用边缘节点对数据进行预处理,并将处理后的有价值的数据传递给CSP,从而减少网络传输压力,节省存储成本。与云计算相比,边缘计算可以提供更低的延迟,对实时数据处理的适应性更强。由于用户在边缘计算和云存储过程中会失去对其数据的物理控制,因此数据安全是用户的基本诉求。然而,加密技术的目标是提供明文数据的语义安全,使密文数据无法区分,这增加了数据去重的难度。虽然通过密钥传递等方式可以使得相同的数据加密成相同的密文,仍然无法满足相似性数据密文去重的需求。为此,如何在不传递密钥的情况下打破用户间的信息壁垒,实现相似数据的密文去重,是一个值得探讨的问题。
并且,目前大多数的数据管理系统只考虑了数据安全和存储成本这两个因素,忽略了数据的可访问性和可扩展性。在物联网系统中,数据存储主要用于数据分析;如果不能进行分析,数据存储价值就会降低。因此,我们还需要考虑如何提高物联网数据的可用性和可扩展性。
发明内容
为解决上述问题,本发明公开了一种物联网场景下的密文相似数据去重管理方法,有效解决了CSP数据管理和物联网数据存储需求之间的矛盾。本发明构建了一个可并行的基于边缘的相似数据去重系统框架,采用边缘节点对数据进行去重操作,提升数据上传的效率,降低传输压力。此外,本发明可以直接比较密码文本的相似性,进行相似性去重操作,在保证数据安全的同时,大幅降低存储成本。我们的系统还考虑到了数据的可用性,通过数据权限拓展提高了数据的可用性。
本发明采用的技术方案是:一种物联网场景下的密文相似数据去重管理方法,包括如下步骤:
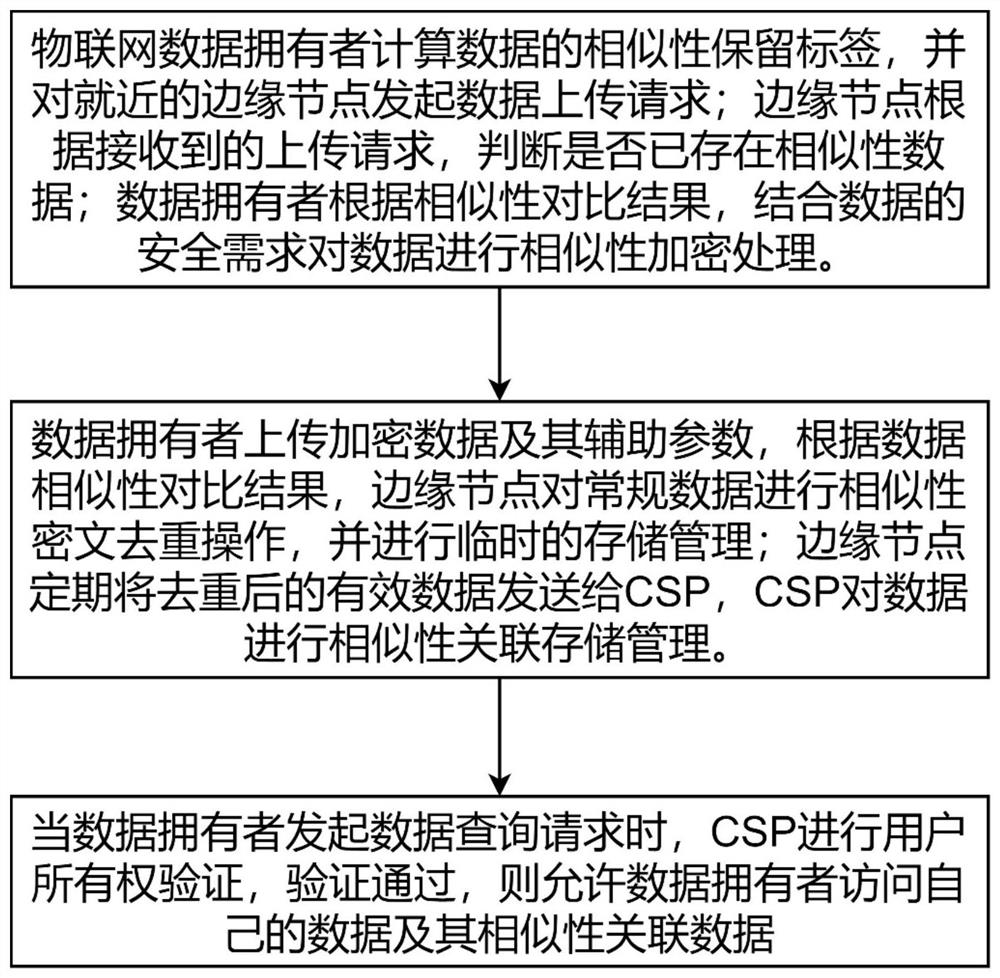
S1,物联网数据拥有者计算数据的相似性保留标签,并对就近的边缘节点发起数据上传请求;边缘节点根据接收到的上传请求,对数据进行数据相似性对比,判断是否已存在相似性数据。数据拥有者根据相似性对比结果,结合数据的安全需求对数据进行相似性加密处理;
S2,数据拥有者上传加密数据及其辅助参数,根据数据相似性对比结果,边缘节点对常规数据进行相似性密文去重操作,并进行临时的存储管理;边缘节点定期将去重后的有效数据发送给CSP,CSP对数据进行相似性关联存储管理;
S3,当数据拥有者发起数据查询请求时,CSP进行用户所有权验证,验证通过,则进行用户权限拓展,允许数据拥有者访问自己的数据及其相似性关联数据。
作为本发明进一步改进在于:所述步骤S1进一步包括:
S11,数据拥有者发起的数据上传请求,数据拥有者采用相似性保留标签生成方法计算数据的相似性保留标签,并对就近的边缘节点发起数据上传请求。
S12,根据接收到的上传请求,边缘节点判断是否已存在相似性数据;数据拥有者根据相似性对比结果,结合数据的安全需求对数据进行相似性加密处理;
步骤S12包括如下的子步骤:
S121,物联网数据上传请求到达后,边缘节点将接收到的相似性保留标签t
S122,若存在相似数据,则CSP返回给数据拥有者一个密钥辅助参数P
S123,若不存在相似数据,数据拥有者直接通过基于模糊提取的密钥生成方法FE-KG(1
S124,数据拥有者利用密钥计算加密数据并得到相应的密文,具体的加密过程可以表示为
作为本发明进一步改进在于:所述步骤S2进一步包括:
S21,数据拥有者上传加密数据及其辅助参数,根据数据相似性对比结果,边缘节点对常规数据进行相似性密文去重操作,并进行临时的存储管理;
步骤S21包括如下的子步骤:
S211,数据拥有者仅需存储文件标签t
S212,若边缘节点上不存在相似数据,边缘节点存储相似性保留标签t
S213,若边缘节点上已存在相似数据,边缘节点将不再重复存储,直接对数据进行去重操作;
S22,边缘节点定期将去重后的有效数据发送给CSP,CSP对数据进行相似性关联存储管理;
具体的,步骤S22包括如下的子步骤:
S221,边缘节点定期将去重后的有效数据发送给CSP,CSP将新上传数据和已有数据进行数据相似性对比;
S221,由于边缘节点和CSP存储时按标签大小顺序存储,因此CSP进行相似数据查找时,指针仅需按标签大小顺序移动即可,无需反复;
S221,若存在相似数据,则进行相似性关联存储,即先按标签顺序进行存储,并在每条数据最后增加相似数据链接;
S221,若不存在相似数据,则直接按标签顺序进行插入存储。
作为本发明进一步改进在于:所述步骤S3进一步包括:
S31,当数据分析者发起数据访问请求时,CSP首先对数据分析者进行所有权证明,并将结果反馈给数据分析者;
S32,若验证通过,根据CSP的访问控制策略,数据分析者不仅可以获得自己的数据的密文c
具体的,步骤S32包括如下的子步骤:
S321,用户首先将t
S322,用户利用密钥k
S33,若验证不通过,则用户无法获得数据密文。
本发明的有益效果:
1、当数据拥有者发起数据上传请求并上传相似性保留标签,通过标签可以直接比较数据的相似性,并在进行相似性密文去重操作,在保证数据安全的同时大幅降低存储成本。
2、本发明还构建了一个可并行的基于边缘的相似数据去重系统框架。在本发明中,数据相似性比较和去重操作直接由边缘节点进行,边缘节点仅将去重后的有效数据上传给CSP进行存储管理,提高了数据传输效率,降低了传输压力。
3、本系统还允许CSP对授权数据进行数据权限扩展。允许数据拥有者访问他们自己的数据以及其相似的数据,提高了物联网数据的可用性。
附图说明
图1为本发明的方法步骤流程图;
图2为本发明的系统框架图;
图3为本发明的响应交互图;
图4为本发明的整体系统流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明,应理解下述具体实施方式仅 用于说明本发明而不用于限制本发明的范围。需要说明的是,下面描述中使用的词语“前”、 “后”、“左”、“右”、“上”和“下”指的是附图中的方向,词语“内”和“外”分别指的是朝向或远 离特定部件几何中心的方向。本方案中的符号及其定义如表1所示:表1
本文提出了一种物联网场景下的密文相似数据去重管理方法,该方法依托相似性加密方法对物联网数据进行安全管理,使得相似的数据加密仍然是相似的,使得相似数据密文去重得以实现。引入边缘节点来处理物联网数据,可并行的操作满足了物联网数据的实时性需求。通过生成保持相似性的标签生成方法,边缘节点可以比较数据密文的相似程度,并结合物联网数据的特点,只对常规数据进行相似数据去重,进一步确保了异常数据的安全性。此外,边缘节点仅将去重的有效数据上传到CSP,减少了通信开销,节省存储空间;CSP对数据进行相似性关联存储,并允许数据拥有者查看自己的数据及其相似数据,提高了数据的可用性和可拓展性。
以下,通过具体的步骤进一步详细说明本发明公开的技术方案。
如图1、2、4所示,本文提供了一种物联网场景下的密文相似数据去重管理方法,包括如下的步骤:
(1)数据拥有者发起的数据上传请求,数据拥有者采用以下方法计算数据的相似性保留标签,并对就近的边缘节点发起数据上传请求。
具体的,本发明设计的标签生成方法主要有六个过程:分词、hash、二值化转换、加权、合并、降维:
分词:对给定的一段文本进行分词,产生n个特征词,并赋予每个词一个权重。
Hash:判断分词是否为数值型数据,若不是,则通过hash函数对每个词向量进行映射,产生一个n位二进制串。
二值化转换:判断分词是否为数值型数据,若是,则将数据进行二值化转换作为该分词的hash。
加权:计算权重向量W=hash×weight,即hash二进制串中为1的乘以该特征词的分词权重,二进制串中为0的乘以该特征词的分词权重后取负,继而得到权重向量。
合并:对于一个文本,在计算出文本中所有特征词的权重向量后,将这些权重向量进行累加,得到一个新的权重向量。
降维:对合并后得到的权重向量进行处理,大于0的位置为1,小于0的位置为0,即可得到该文本的相似性保留标签。
(2)根据接收到的上传请求,边缘节点判断是否已存在相似性数据。数据拥有者根据相似性对比结果,结合数据的安全需求对数据进行相似性加密处理。
步骤(2)包括如下的子步骤:
(2.1)物联网数据上传请求到达后,边缘节点将接收到的相似性保留标签t
(2.2)若存在相似数据,则CSP返回给数据拥有者一个密钥辅助参数P
(2.3)若不存在相似数据,数据拥有者直接运行一个基于模糊提取的密钥生成方法FE-KG(1
(2.4)数据拥有者用计算加密数据并得到相应的密文,相似性加密方法以文件w和一个私钥k
(3)数据拥有者上传加密数据及其辅助参数,根据数据相似性对比结果,边缘节点对常规数据进行相似性密文去重操作,并进行临时的存储管理。
步骤(3)包括如下的子步骤:
(3.1)数据拥有者仅需存储文件标签t
(3.2)若边缘节点上不存在相似数据,边缘节点存储t
(3.3)若边缘节点上已存在相似数据,边缘节点将不再重复存储,直接对数据进行去重操作。
(4)边缘节点定期将去重后的有效数据发送给CSP,CSP对数据进行相似性关联存储管理。
步骤(4)包括如下的子步骤:
(4.1)当CSP接收到边缘节点定期上传的去重后的有效数据时,CSP将新上传数据和已有数据进行数据相似性对比。
(4.2)由于边缘节点和CSP存储时按标签大小顺序存储,因此CSP进行相似数据查找时,指针仅需按标签大小顺序移动即可,无需反复。
(4.3)若存在相似数据,则进行相似性关联存储,即先按标签顺序进行存储,并在每条数据最后增加相似数据链接,如图3所示。
(4.4)若不存在相似数据,则直接按标签顺序进行存储。
(5)当数据拥有者发起数据查询请求时,CSP进行PoW
步骤(5)包括如下的子步骤:
(5.1)CSP对数据进行存储管理的同时,还对用户的访问权限进行了拓展。当数据分析者发起数据访问请求时,CSP首先对数据分析者进行所有权证明,并将结果反馈给数据分析者。
(5.2)若验证通过,根据CSP的访问控制策略,返回给用户自己的数据密文c
(5.3)用户首先将t
(5.4)用户利用密钥k
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。
- 基于加密数据去重的分布式密文共享密钥管理方法及系统
- 一种在物联网场景下的分布式授权管理方法