基于时空域预测像素级篡改概率值的换脸视频检测方法及系统
文献发布时间:2023-06-19 18:37:28
技术领域
本发明涉及数字视频的篡改检测技术领域,具体涉及一种基于时空域预测像素级篡改概率值的换脸视频检测方法及系统。
背景技术
随着人脸伪造方法的快速发展,出现越来越多开源的换脸软件(如DeepFakes、DeepFaceLab2.0),很容易被大众获取去制作各种换脸视频,换脸软件的滥用引起了公众的广泛关注,因此迫切需要开发出有效的换脸篡改视频的检测技术;
目前大多数基于图像分割思想的Deepfake检测算法将换脸视频视为特殊的拼接篡改问题,认为篡改图像最具区分性的特征是局部的,而不是全局的,更多利用流行的神经分割网络,如堆积大量卷积层和转置卷积层的全卷积网络模型生成大尺度篡改区域预测图,去检测局部的篡改痕迹,而不是从全局上从不同层面收集全局统计特征。但最新的换脸技术制作的伪造人脸质量都非常的高,往往很难从图像局部上提取出细微的篡改信息,只从局部提取篡改特征的检测算法容易出现跨库性能急剧下降的域泛化不足的问题。所以应该从全局取证角度,借助背景和脸部区域不一致性检测真伪。除此之外,全卷积网络模型大多参数较大,模型计算复杂度较高,并且网络容易出现过拟合。
发明内容
为了克服现有技术存在的缺陷与不足,本发明提供一种基于时空域预测像素级篡改概率值的换脸视频检测方法及系统,本发明采用多层次时空特征提取网络和双注意力机制的模型进行时空不一致特征提取,从时间多分辨率的角度提取出时空不一致特征,并对篡改掩膜通过采样构建多组坐标位置-篡改值对(x坐标,y坐标,篡改值),将时空不一致特征与随机采样的若干个像素点的xy轴坐标进行拼接,通过坐标位置重建得到该像素点的篡改概率预测值,进行像素级篡改概率值的辅助监督,在库内和跨库测试中均具有很好的检测性能,具有良好的泛化性。
为了达到上述目的,本发明采用以下技术方案:
本发明提供一种基于时空域预测像素级篡改概率值的换脸视频检测方法,包括下述步骤:
将待测视频进行分帧,对每一帧图像进行人脸框检测提取;
根据人脸关键点构建篡改掩膜;
对待检测图像的篡改掩膜进行随机采样,得到多个像素点的坐标位置以及对应的篡改值;
基于DenseNet模块构建浅层的卷积层模块,对输入的人脸图像进行空域特征提取,输出空域特征;
基于ConvLSTM构建多层次时域特征提取模块,将空域特征输入多层次时域特征提取模块输出时空特征,对应不同时间分辨率;
构建双注意力机制模块,所述双注意力机制模块设有时空注意力机制和时域分辨率注意力机制,在时空注意力机制中生成三维概率注意力图,对多个时空特征进行特征增强,在时域分辨率注意力机制中输入特征增强后的时空特征,计算多个时空特征之间的时域关联性,自适应计算不同时空特征的权重值,加权求得时空不一致特征;
将时空不一致特征与像素点的坐标通道进行拼接,经多层卷积层后生成像素坐标位置对应的篡改概率预测值,将篡改值通道作为篡改值标签,对比像素级篡改概率预测值和篡改值标签计算交叉熵损失函数;
设定阈值,基于设定阈值对时空不一致特征进行二分类,得到换脸视频篡改检测结果。
作为优选的技术方案,所述根据人脸关键点构建篡改掩膜,具体步骤包括:
根据人脸关键点的点集生成一个凸多边形作为篡改区域构建篡改掩膜,所述篡改掩膜设有二值化0或1的值,当判定假脸图像在人脸轮廓区域被篡改过时,人脸轮廓区域内均设为1值,背景区域均设为0值;当判定真脸图像在整张图像中均未被篡改过时,整张掩膜均设为0值;
根据人脸框位置裁剪出人脸区域图片,并采用双线性插值对图片重采样成统一的预设分辨率作为图像输入。
作为优选的技术方案,所述在时空注意力机制中生成三维概率注意力图,对多个时空特征进行特征增强,具体步骤包括:
在时空注意力机制中,将时空特征沿着不同的输入特征方向轴使用最大池化和平均池化操作得到两个三维的注意力图,将两个三维的注意力图拼揍后经过3D卷积和Sigmoid函数生成三维概率特征图,将三维概率特征图与时空特征逐元素相乘,得到特征增强后的时空特征。
作为优选的技术方案,所述在时空注意力机制中生成三维概率注意力图,对多个时空特征进行特征增强,具体表示为:
其中,
作为优选的技术方案,所述在时域分辨率注意力机制中输入特征增强后的时空特征,计算多个时空特征之间的时域关联性,自适应计算不同时空特征的权重值,具体步骤包括:
特征增强后的时空特征经过三维的最大池化和三维的平均池化操作,得到最大池化特征和平均池化特征,将最大池化特征和平均池化特征分别输入多层感知器,自适应生成权重向量,提取时空特征在不同时间分辨率下的时域关联。
作为优选的技术方案,所述在时域分辨率注意力机制中输入特征增强后的时空特征,计算多个时空特征之间的时域关联性,自适应计算不同时空特征的权重值,加权求得时空不一致特征,具体表示为:
其中,
作为优选的技术方案,所述对比像素级篡改概率预测值和篡改值标签计算交叉熵损失函数,具体计算公式表示为:
其中,p′表示篡改概率预测值,p表示篡改值标签,p
作为优选的技术方案,所述基于设定阈值对时空不一致特征进行二分类,具体步骤包括:
将时空不一致特征平铺展开为一维特征,输入到两层全连接层的分类器,输出待检测帧的篡改概率值,将篡改概率值与设定阈值进行比较,高于设定阈值则判定人脸图像为篡改图像,低于设定阈值则判定人脸图像为真实图像。
作为优选的技术方案,还包括网络训练损失函数构建步骤,所述网络训练损失函数包括二分类真假预测与真实标签的交叉熵损失函数L
L
其中,p′表示篡改概率预测值,p表示篡改值标签,p
本发明还提供一种基于时空域预测像素级篡改概率值的换脸视频检测系统,包括:视频预处理模块、篡改掩膜构建模块、坐标位置及篡改值对构建模块、空域特征提取模块、多层次时域特征提取模块、双注意力机制构建模块、像素级位置篡改概率值重建模块、二分类模块和检测结果输出模块;
所述视频预处理模块用于将待测视频分帧并进行人脸框的检测提取;
所述篡改掩膜构建模块用于根据人脸关键点构建篡改掩膜;
所述坐标位置及篡改值对构建模块用于对待检测图像的篡改掩膜进行随机采样,得到多个像素点的坐标位置以及对应的篡改值;
所述空域特征提取模块用于基于DenseNet模块构建浅层的卷积层模块,对输入的人脸图像进行空域特征提取,输出空域特征;
所述多层次时域特征提取模块用于基于ConvLSTM构建多层次时域特征提取模块,将空域特征输入多层次时域特征提取模块输出时空特征,对应不同时间分辨率;
所述双注意力机制构建模块用于构建双注意力机制模块,所述双注意力机制模块设有时空注意力机制和时域分辨率注意力机制,在时空注意力机制中生成三维概率注意力图,对多个时空特征进行特征增强,在时域分辨率注意力机制中输入特征增强后的时空特征,计算多个时空特征之间的时域关联性,自适应计算不同时空特征的权重值,加权求得时空不一致特征;
所述像素级位置篡改概率值重建模块用于将时空不一致特征与像素点的坐标通道进行拼接,经多层卷积层后生成像素坐标位置对应的篡改概率预测值,将篡改值通道作为篡改值标签,对比像素级篡改概率预测值和篡改值标签计算交叉熵损失函数;
所述二分类模块用于基于设定阈值对时空不一致特征进行二分类;
所述检测结果输出模块用于输出二分类后的换脸视频篡改检测结果。
本发明与现有技术相比,具有如下优点和有益效果:
(1)本发明采用像素级位置篡改概率值重建的方式作为辅助监督,通过采样坐标信息的方法解决了以往使用全卷积网络模型生成篡改概率图的方式计算复杂度高的问题,并且解决了大尺度预测图导致的过拟合问题,提高网络的域泛化性。
(2)本发明构建了双注意力机制模块,将注意力模块应用到3D卷积网络中,能够更好的结合空间信息和不同时间分辨率的时间信息来提高模型的检测能力,从局部帧到全局帧多尺度分析篡改信息,让网络更专注于时空域中最具有区分性的部分。
附图说明
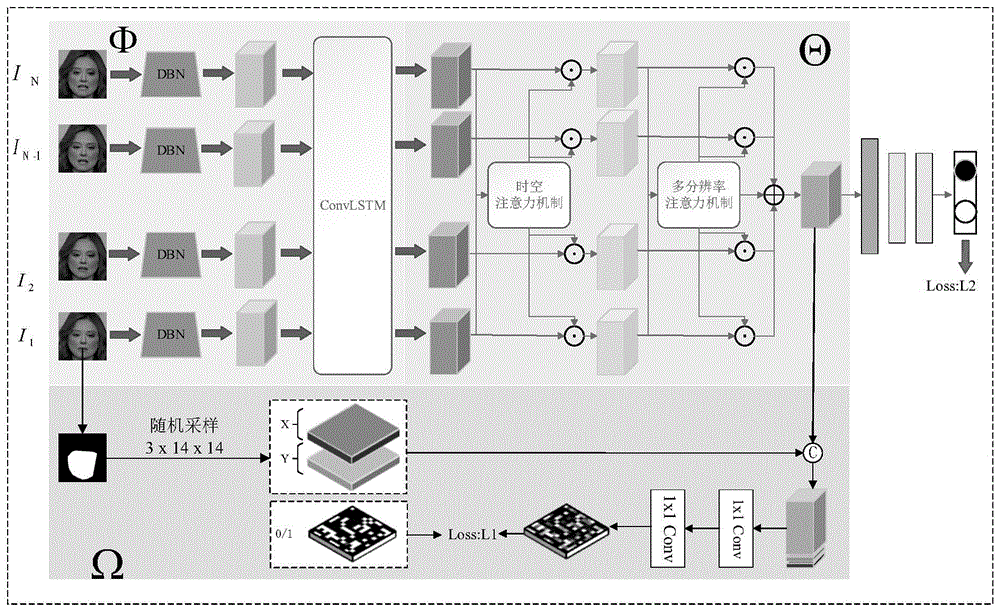
图1为本实施例基于时空域预测像素级篡改概率值的换脸视频检测方法的框架示意图;
图2为本实施例基于时空域预测像素级篡改概率值的换脸视频检测方法的训练阶段流程示意图;
图3为本实施例基于时空域预测像素级篡改概率值的换脸视频检测方法中浅层空域特征提取的网络结构示意图;
图4为本实施例双注意力模块中时空注意力机制的网络结构示意图;
图5为本实施例双注意力模块中时域分辨率注意力机制的网络结构示意图;
图6为本实施例像素级位置篡改概率值重建的网络结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例
本实施例以在FaceForensics++(FF++)(C23)数据库上进行训练,在FF++(C23)数据库上进行跨不同伪造方法测试以及CelebDF、DeepfakeDetection(DFD)、DeepfakeDetection Challenge(DFDC)数据库上进行跨库测试为例。FaceForensics++数据库使用H.264编码器分别合成压缩率0(C0)、压缩率23(C23),压缩率40(C40)3种不同压缩程度的视频,其中真实视频1000个,换脸视频3000个,FaceForensics++包含了4种伪造方法生成的伪造视频,包括Deepfakes(DF)、NeuralTextures(NT)、FaceSwap(FS)和Face2Face(F2F)这四种伪造方法。DeepfakeDetection数据库视频包含无压缩率(C0),压缩率23(C23),压缩率40(C40),其中包含真实视频363个,换脸视频3068个。
首先对FF++数据库进行划分,以7:2:1的比例分为训练集、验证集和测试集,同时为了保证正负样本的比例均衡,在选取的数据集中保证真实视频帧和换脸视频帧的比例在1:1左右。实验在Ubuntu 18.04系统上进行,使用3.8版本的Python语言和1.7.0版本的Pytorch人工神经网络库,CUDA版本为11.0,cudnn版本为7.6.5。
如图1、图2所示,本实施例提供一种基于时空域预测像素级篡改概率值的换脸视频检测方法,使用多层次时空特征提取模块提取不同时间分辨率的时空特征,再使用双注意力机制提取时域关联,得到特征增强后的时空不一致特征,通过在时空不一致特征上拼接坐标信息(x坐标,y坐标),准确预测出该坐标点的篡改概率值进行辅助监督,最后对该时空不一致特征输入二分类判别器得到待检测帧的篡改概率进行真假脸判决,网络训练部分的具体步骤包括:
S1:视频预处理,将各个数据集的视频进行分帧,保存为帧序列F,并使用Dlib库中的get_frontal_face_detector模块对每一帧图像进行人脸框检测提取;
S2:根据人脸关键点构建篡改掩膜;
在本实施例中,对于每个视频VX,在帧序列F
在本实施例中,对于训练训练集重每一个视频VX进行视频帧分帧,得到F={F
在本实施例中,裁剪图片区域为所检测的人脸框区域的1.3倍人脸,对原视频帧图像和篡改掩膜裁剪后,并将其重采样为224×224分辨率作为本发明模型输入图像,采样方法为双线性插值法;
S3:构建多组坐标位置-篡改值对;
在本实施例中,对待检测图片的篡改掩膜进行随机采样获得14×14个像素点,取其x坐标、y坐标和篡改值,即获得3×14×14大小的坐标位置-篡改值对,三个通道分别表示x坐标,y坐标,篡改值。其中x、y坐标位置将用于与时空不一致特征进行拼接,而篡改值作为和篡改概率预测值进行对比的标签值;
S4:构建多层次时空特征提取模块CNN-ConvLSTM,将N帧连续图像输入多层次时空特征提取模块CNN-ConvLSTM获得不同时间分辨率的时空特征,得到N个时空特征;
在本实施例中,选取第t
在本实施例中,基于DenseNet模块构建浅层的卷积层模块,对输入的N帧人脸图像进行空域特征提取,输出N个空域特征;基于ConvLSTM构建多层次时域特征提取模块,该模块输入N个空域特征,输出N个时空特征,对应不同时间分辨率。
输入N帧连续帧,经过浅层卷积层模块提取N个空域特征S
S
其中,其中I
如图3所示,浅层空域特征提取网络输入大小为224×224大小的裁剪后的人脸图像,为RGB和YUV拼接的六颜色通道,浅层空域特征提取网络包括三个卷积模块(第一卷积模块和第二卷积模块):第一卷积模块包括一个步长为1的6通道输入3×3第一卷积层、一个步长为3的3通道输入的7×7第二卷积层、一个BN层、一个Relu激活函数、一个步长为2的2×2最大池化层,第二卷积模块包括6个卷积层的第一DenseBlock模块、第三卷积模块包括12个卷积层的第二DenseBlock模块;
S5:构建双注意力机制模块,将N个时空特征输入双注意力机制模块提取三维注意力图和时域关联权重值,求得时空不一致特征;
在本实施例中,输入为N个时空特征,经过两个注意力机制,第一个注意力机制为时空注意力机制,第二个注意力机制为时域分辨率注意力机制。
如图4所示,在时空注意力机制中,将步骤S4所获得的N个时空特征
其中
第二个注意力机制模块是时域分辨率注意力机制,对每个时空特征图使用三维的最大池化和三维的平均池化操作,并通过多层感知器MLP,可以给多层次时空特征自适应地生成权重向量,提取时空特征在不同时间分辨率下的时域关联,从时域全局相邻帧再到局部相邻帧多尺度地捕捉篡改信息。
如图5所示,在时域分辨率注意力机制中,输入N个时空特征图
其中,
S6:构建像素级位置篡改概率值重建进行辅助监督;
将经过双注意力机制模块后的时空不一致特征(256×14×14)与步骤S3采样得到的坐标位置-篡改值对中的x、y坐标两通道(2×14×14)进行拼接后,输入到两层1×1卷积层,得到根据像素点坐标位置预测的篡改概率值,将坐标位置-篡改值对中的篡改值通道作为标签,对预测得到篡改概率值和像素坐标对应的篡改值标签计算交叉熵损失函数L
其中,p′表示篡改概率预测值,p表示篡改值标签。
如图6所示,拼接时空不一致特征和坐标位置(x坐标,y坐标),输入到两层卷积层计算输出对应像素点的篡改概率预测值,其中卷积层均采用步长为1的1×1卷积核。
S7:对时空不一致特征进行二分类得到检测结果;
在本实施例中,将时空不一致特征平铺展开为一维特征,输入到两层全连接层的分类器,输出一个待检测帧的篡改概率值,判别真假脸,设定阈值为0.5,高于阈值则判定该人脸图像为篡改图像,否则为真实图像。其中第一层全连接层输出为1×64,第二层全连接层输出为1×1;
S8:构建网络训练的损失函数;
在本实施例中,损失函数包括两部分:二分类真假预测与真实标签的交叉熵损失函数L
L
其中,p′表示篡改概率预测值,p表示篡改值标签,p
S9:设置网络参数优化算法;
在本实施例中,采用Adam算法进行参数优化,设置学习率为1x10
S10:训练网络;
S11;不同伪造方法之间测试的模型应用;
在本实施例中,加载模型训练步骤保存的模型结构和参数作为检测系统的后台模块;将测试集的每个视频都选取连续10帧的,提取10个单帧特征,输入检测系统,预测分类结果。
FaceForensics++是许多Deepfake检测方法中使用最广泛的数据库,它包含了来自互联网的1000个原始真实视频,每个真实视频对应了4种伪造方法生成的伪造视频,包括Deepfakes(DF)、NeuralTextures(NT)、FaceSwap(FS)和Face2Face(F2F)这四种伪造方法。
本发明加载利用FF++数据库的其中一种伪造方法的训练集训练后的网络的模型和权重,然后使用FF++四种伪造方法的数据库的测试集进行测试。
如下表1所示,得到不同伪造方法之间的测试结果;
表1不同伪造方法之间的测试结果
S12:从FF++到其他数据库测试的模型应用;
在本实施例中,加载模型训练步骤保存的模型结构和参数作为检测系统的后台模块;将测试集的每个视频都选取连续10帧的,提取10个单帧特征,输入检测系统,预测分类结果。
本发明加载利用FF++(HQ)数据库的训练集训练后的网络的模型和权重,然后使用DFD、DFDC、Celeb-DF数据库的测试集进行跨库测试,并与最新的检测算法进行跨库测试的结果比较。
如下表2所示,得到从FF++到其他数据库的测试结果:
表2从FF++到其他数据库的测试结果
本实施例还提供一种基于时空域预测像素级篡改概率值的换脸视频检测系统,包括:视频预处理模块、篡改掩膜构建模块、坐标位置及篡改值对构建模块、空域特征提取模块、多层次时域特征提取模块、双注意力机制构建模块、像素级位置篡改概率值重建模块、二分类模块和检测结果输出模块;
在本实施例中,视频预处理模块用于将待测视频分帧并进行人脸框的检测提取;
在本实施例中,篡改掩膜构建模块用于根据人脸关键点构建篡改掩膜,具体对人脸框检测提取人脸68个关键点,根据关键点点集生成一个凸多边形(即人脸轮廓)作为篡改区域构建篡改掩膜,篡改掩膜只有二值化0或1,认为假脸在凸多边形区域均被篡改,设为1值,背景没有被篡改,设为0值;而真脸在整张图像中均未被篡改,设为0值;
在本实施例中,坐标位置及篡改值对构建模块用于从篡改掩膜中随机采样得到多个像素点的坐标位置(x坐标,y坐标)以及对应的篡改值,组成坐标位置及篡改值对,用于辅助监督时进行像素级位置篡改值重建。其中x、y坐标位置将用于与时空不一致特征进行拼接,而篡改值作为和篡改概率预测值进行对比的标签值;
在本实施例中,空域特征提取模块用于基于DenseNet模块构建浅层的卷积层模块,对输入的人脸图像进行空域特征提取,输出空域特征;
在本实施例中,多层次时域特征提取模块用于基于ConvLSTM构建多层次时域特征提取模块,将空域特征输入多层次时域特征提取模块输出时空特征,对应不同时间分辨率;
在本实施例中,双注意力机制构建模块用于构建双注意力机制模块,所述双注意力机制模块设有时空注意力机制和时域分辨率注意力机制,在时空注意力机制中生成三维概率注意力图,对多个时空特征进行特征增强,在时域分辨率注意力机制中输入特征增强后的时空特征,计算多个时空特征之间的时域关联性,自适应计算不同时空特征的权重值,加权求得时空不一致特征;
在本实施例中,像素级位置篡改概率值重建模块用于将最终生成的时空不一致特征和坐标位置-篡改值对中的像素点x、y坐标通道进行拼接,经两层1×1卷积层后,生成像素坐标位置对应的篡改概率预测值,将坐标位置-篡改值对中的篡改值通道作为标签,对比重建得到的像素级篡改概率预测值和篡改值标签计算交叉熵损失函数;
在本实施例中,二分类模块用于基于设定阈值对时空不一致特征进行二分类,检测结果输出模块用于输出二分类结果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。