一种物联网的多维数据处理方法
文献发布时间:2023-06-19 19:28:50
技术领域
本发明涉及电数字数据处理技术领域,具体涉及一种物联网的多维数据处理方法。
背景技术
各类电力物联网设备在监测电力数据时,会产生大量的多维数据,为了提高资源存储率,往往都是先对各类电力物联网设备的监测数据进行打包压缩,以达到降低互联网带宽占用率和方便数据管理的目的。
现有各种数据压缩方法,可实现对各类物联网设备监测数据的压缩。但是如果物联网设备出现异常,由于异常的数据会导致物联网设备监测数据的变化变大,或者说不规律性增大,所以此时物联网设备监测数据的重复率便会下降,不利于数据压缩从而导致对物联网设备监测数据的压缩效果变差、导致数据存储率增大,最终,在物联网设备异常时,会因为采集所得压缩数据中存在大量无用数据而导致无法及时获取准确的异常信息,从而导致物联网设备异常不能被及时地发现。
发明内容
为了解决在物联网设备出现异常时,因异常数据的存在而导致物联网设备监测数据重复率下降无法得到有效压缩,进而导致数据存储率增大的问题,本发明的目的在于提供一种物联网的多维数据处理方法,所采用的技术方案具体如下:
本发明一个实施例提供了一种物联网的多维数据处理方法,方法包括:
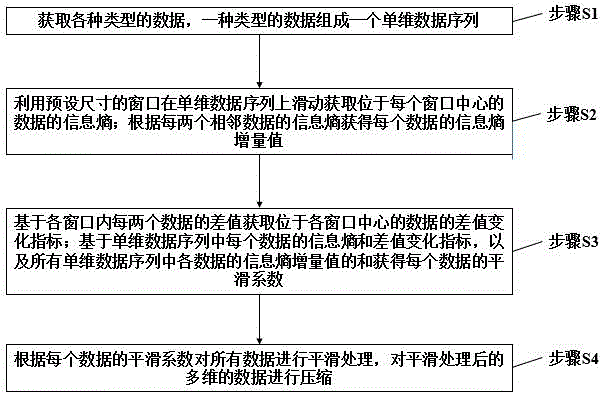
获取各种类型的数据,一种类型的数据组成一个单维数据序列;
利用预设尺寸的窗口在单维数据序列上滑动获取位于每个窗口中心的数据的信息熵;根据每两个相邻数据的信息熵获得每个数据的信息熵增量值;
基于各窗口内每两个数据的差值获取位于各窗口中心的数据的差值变化指标;基于单维数据序列中每个数据的信息熵和差值变化指标,以及所有单维数据序列中各数据的信息熵增量值的和获得每个数据的平滑系数;
根据每个数据的平滑系数对所有数据进行平滑处理,对平滑处理后的多维的数据进行压缩。
优选地,根据每两个相邻数据的信息熵获得每个数据的信息熵增量值,包括:将相邻的两个数据中后一个数据的信息熵与前一个数据的信息熵进行作差并求绝对值,得到相邻的两个数据中前一个数据的信息熵增量值,进而得到每个数据的信息熵增量值。
优选地,获取每个数据的差值变化指标,包括:获得预设尺寸的窗口在单维数据序列上滑动时窗口内的数据中每两个数据的差值的绝对值;获取最大的差值的绝对值,作为基准值;将每个差值的绝对值与基准值的比值记为差异程度;对所述窗口内每两个数据的差异程度进行聚类获得不同的类别;分别获得每个类别内所有差异程度的均值,所述均值最小的类别为第一类别;第一类别的所有差异程度的数量与不同的类别内所有差异程度的数量的比值为位于该窗口中心的数据的差值变化指标,进而获得每个数据的差值变化指标。
优选地,每个数据的平滑系数为:
其中,
优选地,根据每个数据的平滑系数对所有数据进行平滑处理,包括:将每个数据的平滑系数作为对每个数据加权平均时的权重,获得进行平滑处理后的每个数据。
本发明实施例至少具有如下有益效果:本发明利用各种类型的物联网设备传感器采集到各种类型的数据,每种类型的数据组成一个单维数据序列,进一步的获得单维数据序列中每个数据的信息熵,用于表征每个数据周围的数据的混乱程度;从而获得每个数据的信息熵增量值,进而通过信息熵增量值确定每个数据的平滑系数,能够增加数据整体的重复率,提高压缩率;进一步的,对位于窗口内的每两个数据的差值的绝对值进行分析,获得每个数据的差值变化指标,在信息熵增量值的基础上进一步的确定实际的数据的变化大小,结合每个数据的信息熵增量值确定每个数据的平滑系数,能够避免仅凭信息熵增量值确定平滑系数时的误差,使得对数据平滑时有更好的平滑性,进一步提高了数据平滑后的重复率,增加了数据的可压缩率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案和优点,下面将对实施例或现有技术描述中所需要使用的附图作简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
图1为本发明实施例提供的一种物联网的多维数据处理方法的方法流程图。
具体实施方式
为了更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明提出的一种物联网的多维数据处理方法,其具体实施方式、结构、特征及其功效,详细说明如下。在下述说明中,不同的“一个实施例”或“另一个实施例”指的不一定是同一实施例。此外,一或多个实施例中的特定特征、结构、或特点可由任何合适形式组合。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。
下面结合附图具体的说明本发明所提供的一种物联网的多维数据处理方法的具体方案。
实施例:
本发明的主要应用场景为:不同类的电力物联网设备对智慧能源数据进行数据采集并压缩,在设备正常工作时,数据的变化很小,此时对数据进行压缩时,压缩率是很大的,数据的传输效率很高,但当设备出现异常时,会出现异常的数据,这些异常的数据会降低整体数据的重复率降低,从而也会降低压缩率,使得数据存储率降低,因此需要对数据进行平滑处理。
请参阅图1,其示出了本发明实施例提供的一种物联网的多维数据处理方法的方法流程图,该方法包括以下步骤:
步骤S1,获取各种类型的数据;一种类型的数据组成一个单维数据序列。
因为有不同类型的物联网设备,且每种物联网设备的数据类型也是不一样的,因此需要利用电力机房中不同的物联网设备传感器采集各种类型的数据,得到多维的数据,而一种类型的数据就是为一种单维度的数据,且采集不同类型的数据的采样频率都是相同的,因此将一种类型的数据组成一个单维数据序列,也即是一个物联网设备对应一个单维数据序列,其中需要说明的是,单维数据序列中的每个时刻的数据的排列是按照时序顺序进行排列的。
在电力机房的各种设备都正常工作的状态下,各物联网设备将采集后的数据传输至数据压缩模块进行打包压缩;当出现异常数据时,会降低数据的重复率,使得压缩时的压缩率也会降低,因此需要对这些数据进行平滑处理,提高数据的重复率。
步骤S2,利用预设尺寸的窗口在单维数据序列上滑动获取位于每个窗口中心的数据的信息熵;根据每两个相邻数据的信息熵获得每个数据的信息熵增量值。
当局部时间段内各数据的信息熵的变大,则表示在局部时间段内出现了较多不同值的数据,在对数据平滑时应该尤其注意这一部分的数据,进而可以先求每个数据的信息熵的增量和所有的数据的信息熵的增量的和,然后对每个数据的信息熵的增量和所有的数据的信息熵的增量的和进行分析得到每个数据的进行平滑时的权重,进而根据每个数据的进行平滑时的权重,完成数据平滑。
数据的信息熵的变大,表示在局部时间段内出现了较多不同值的数据,首先需要先进行数据滑窗,根据数据滑窗计算得到每个数据的信息熵值,进而根据前后连续数据之间信息熵的变化值,得到信息熵增量值。
在此设置预设尺寸的窗口,优选地,由于单维数据序列是一个时序上的序列,在本实施例中窗口的长度为数据打包压缩时每一次打包时间间隔中所采集的数据的长度,例如一次打包时间间隔内采集了5个数据,则窗口的尺寸就是1*5,如果采集了11个数据,则窗口的长度就是1*11,需要说明的是,实施者也可以根据具体情况对窗口的尺寸进行调整,但需要保证窗口的长度为奇数,宽度为1,另外窗口滑动的步长为1。
另外,当窗口在单维数据序列上滑动时,单维数据序列中的每个数据作为窗口中心的数据,例如窗口的尺寸为1*5,当求取单维数据序列中第四个数据的信息熵时,第四个数据作为窗口中心的数据,也即是窗口内第3个数据;另外窗口在单维数据序列上滑动时,当经过单维数据序列的起始几位数据和末尾几位数据时,需要对窗口内的数据进行补充,例如尺寸为1*5的窗口经过单维数据序列中的第一个数据时,也即是第一个数据作为窗口中心的数据,此时窗口的前两位数据是不存在的,因此对需要补充两个数据到窗口内,使得窗口内的数据为5个,优选地,在本实施例中,补充的数据的值都为0,实施者也可以根据单维数据序列的数据情况对补充的数据的值进行调整,还可以利用插值法对窗口内的数据进行插值,使得窗口在单维数据序列上滑动时窗口内数据的数量始终与窗口的尺寸保持一致。
进一步的,利用窗口内的数据求取窗口中心的数据的信息熵,以一个窗口为例,获得窗口内每个数据在窗口中出现的频率,然后根据每个数据在窗口内出现的频率获得位于窗口中心的数据的信息熵,用公式表示为:
其中,
最后获得单维数据序列中每个数据的信息熵增量值,将相邻的两个数据中后一个数据的信息熵与前一个数据的信息熵进行作差并求绝对值,得到相邻的两个数据中前一个数据的信息熵增量值,用公式表示为:
其中,
由此,可以得到每个单维数据序列中每个数据的信息熵增量值,用于表述不同物联网设备的数据的变化情况,一个数据的熵增量越大,说明该数据相较于其他的数据发生变化的可能程度就越大,在对数据进行平滑时,需要格外注意该数据。
步骤S3,基于各窗口内每两个数据的差值获取位于各窗口中心的数据的差值变化指标;基于单维数据序列中每个数据的信息熵和差值变化指标,以及所有单维数据序列中各数据的信息熵增量值的和获得每个数据的平滑系数。
在传送数据时,是先将待传输的数据存储在上行区域中,当间隔一定时间段后,再将该上行区域所存储数据打包压缩发至网络,为了降低网络的带宽压力,需要对多维度的数据中的每个数据进行不同程度的平滑,提高数据的重复率,进而提高数据的压缩率,使得数据包变小。
其中在常规的平滑权值分配中,会根据不同维度的数据下的对应的信息熵增量值在总体所有数据对应的信息熵增量值的和中的占比对数据进行平滑处理,但是仅考虑所述占比作为平滑权值,仅仅是考虑了数据的变化,并没有考虑数据变化程度的大小,因此得到的平滑权值是有误差的,并不一定能保证得到的数据平滑后的结果在进行数据压缩时能够得到预期的最大压缩率,所以还需要对单维数据序列中的数据的差值进行分析,得到最终不同数据的平滑系数分配权值。
由此获得每个窗口内的所有数据,将这些数据中的每两个数据进行作差,得到作差后的差值的绝对值,其中挑选出最大的差值的绝对值,作为基准值,每个差值的绝对值与基准值的比值为差异程度,一个窗口对应的所有差异程度组成一个序列,为记为窗口差值序列,通过该序列中的元素的值,能够分析窗口内所有数据的变化程度的大小。其中窗口差值序列中的每一个元素都为差值的绝对值对应的差异程度,由此可以得到窗口在单维数据序列上滑动时位于窗口中心的元素对应的窗口差值序列,也即是每个单维数据序列中每个数据对应一个窗口差值序列。
进一步的,对一个窗口对应的窗口差值序列中的元素进行聚类,聚类的依据是根据差值序列中元素的大小进行聚类,其中,聚类为公知技术,在此不再进行详细的阐述;聚类可以将窗口差值序列中的元素分为不同的类别,优选地,在本实施例中选用k-means聚类算法进行聚类,设定将窗口差值序列中的元素分为两类,这是为了体现差值序列中数值较小一部分元素的特征,实施者可以根据具体情况对分成的类别数进行设定;分别求取每一个类别中所有差异程度的均值,记为第一均值和第二均值,比较第一均值和第二均值的大小,较小的对应的类别为第一类别,至此可以得到各个数据对应的第一类别。
第一类别内所有差异程度的数量与两个类别内所有差异程度的数量的比值为该窗口对应的差值变化指标,也即是位于该窗口中心的数据的差值变化指标,用公式表示为:
其中,
最后,获取每个数据的信息熵增量值与所有数据的信息熵增量值的和的比值,结合每个数据的差值变化指标进行分析,获得每个数据的平滑系数,用公式表示为:
其中,
为各物联网设备对应的所有单维数据序列中各信息熵增量值的和,其值越大,表示当前总体所有物联网设备的数据有变化,数据的信息量增加较大。
的值越大,表示第m个物联网设备对应的单维数据序列中第n个数据的变化大,且对整体数据的信息量变化影响越大,其第m个物联网设备对应的单维数据序列中第n个数据应当保留下来的信息应该越多,在平滑时其分配的平滑系数应当越大。
但是若仅以
其中在信息熵较小的数据处,具有的特征是:数据之间的差值往往较低,但是又不完全是,因为信息熵值在计算时,是仅根据数据的重复量进行计算,而没有考虑数据之间的差值,而为了使得在平滑时,能够得到更好的平滑性,则应当对差值较小处的数据增大平滑力度。因此选取了差异程度的均值较小的类别内元素的数量与两个类别内所有元素的数量的比值,也即是利用差值变化指标对
越大,表示当前第m个物联网设备对应的单维数据序列中的第n个数据对应的窗口差值序列中的差异程度总体相对偏小,也即是值较小的差异程度占比更多,则第m个物联网设备对应的单维数据序列中第n个数据点对应的平滑系数值应当更小,所以利用以e为底的负指数函数对
另外,如果直接用计算出来的
步骤S4,根据每个数据的平滑系数对所有数据进行平滑处理,对平滑处理后的多维的数据进行压缩。
在步骤S3中,计算出了各单维数据序列中各个数据的平滑系数,将各个数据的平滑系数作为对数据进行加权平均时的权值,对每个数据进行平滑处理。平滑处理后的数据重复率相较于原来的数据重复率会提升,在进行数据传输时能够提高压缩率。
其中数据压缩算法有很多,本实施例中选用霍夫曼编码对平滑处理后的多维的数据进行压缩,然后将压缩后数据进行传输,需要说明的是,由于数据压缩的算法有很多,所以实施者可以根据实际情况选择其他算法进行数据压缩。
需要说明的是:上述本发明实施例先后顺序仅仅为了描述,不代表实施例的优劣。且上述对本说明书特定实施例进行了描述。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。