一种模型的编辑方法及系统
文献发布时间:2023-06-19 09:44:49
技术领域
本发明涉及计算机视觉技术领域,具体涉及一种模型的编辑方法及系统。
背景技术
随着电商的快速发展,以及服饰行业庞大的市场容量,对服饰的线上展示和试穿有着很高的需求。现有技术中对于服饰的展示主要分为三种方式:2D图片展示和3D模型展示以及视频展示方式。其中3D模型展示主要采用的三维扫描和三维软件建模的方式进行展示。现有技术有如下的问题:
如果要实现服饰模型的3D化,将服饰录入到线上进行展示,现有技术通常是需要将服饰的打板数据,即服饰的设计图纸,通过专业的服饰建模软件实现3D化。三维扫描建模的方式需要采购硬件扫描设备对服饰进行环绕扫描,对场景的背景灯光环境有一定要求,需要专人进行操作设备,最后需要对模型进行调整和修补。
如果通过2D图片即比较传统的对服饰产品进行拍照,使用照片进行展示,展示形式比较单一,展示的内容局限于拍照的角度,因此所展示的内容有限,另外平面的效果图没有整体的三维视觉效果,在体验上缺乏真实感;三维扫描建模效率比较高,但是需要依赖硬件设备以及对场景的灯光背景有一定要求,另外扫描的模型的数据很大,一般需要进行二次优化才能应用。3D建模的方式就是使用3D软件进行模型制作,需要熟练的人员进行操作,工作的流程相对比较复杂,效率比较低,成本也比较高。所以目前市面上的线上服饰展示效果3D优于2D,但是3D的服饰录入存在以上居多问题,导致存在了很长一段时间的瓶颈期。
发明内容
本发明解决的技术问题是,提供了一种更好的线上服饰试穿展示效果,为用户进行服饰挑选提供了方便。
为了解决上述技术问题,本发明提供的技术方案为:
一种模型的编辑方法,包括:
获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息;
将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值;
根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。
优选地,所述模特三维模型的构建方法为:
获取身着服饰的真人模特的照片或视频;
对照片或视频进行分析,从而对真人模特进行三维重建,生成模特三维模型;
获取模特三维模型的姿势信息。获取照片与视频可以构建不同姿势与服装形状的数据库,使得真人模特进行三维重建时,重建的结果更加的准确。
进一步优选地,所述将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值具体为:
将模特三维模型与使用者三维模型进行姿势对齐;
比对模特三维模型与使用者三维模型的网格区别;
通过网格区别获取每个信息点的位移值。通过比对的方法可以更准确的获取到模特三维模型与使用者三维模型的差别,从而可以转化成服饰的变形量。
进一步优选地,所述根据信息点的位移值对使用者三维模型生成变形后的服饰具体为:
将空间每个信息点的位移值映射到真人模特的照片或视频上,将照片或视频中的服饰进行变形。
进一步优选地,所述将照片或视频中的服饰进行变形后还包括:
将变形后的照片或视频与使用者三维模型进行融合,生成具有试穿效果的使用者三维模型。通过上述的方法即可准确的完成,根据使用者的姿势快速准确的生成对应的变形服装,该方式展示服装效果更好,可以实现用户试装的效果。
优选地,所述使用者三维模型设置有骨骼系统,所述骨骼系统分为动作层与变形层;
所述的动作层用于控制表情或动作;
所述的变形层用于根据使用者的移动或者缩放的骨骼点,驱动使用者三维模型进行变形。
优选地,所述使用者三维模型的姿势通过骨骼变形进行展示,该骨骼变形的方法为:
获取骨骼,将骨骼之间设置影响关系以及三维模型权重;
将使用者三维模型与模特三维模型进行对齐,并将骨骼之间的影响关系以及三维权重解除;
将骨骼位置与使用者三维模型对齐,加载骨骼之间的影响关系以及三维模型权重。
优选地,所述将骨骼之间设置影响关系以及三维模型权重具体为:
预先设定配置文件,所述配置文件包括,骨骼之间的影响关系配表,以及三维模型的权重配表。通过将骨骼之间设置影响关系以及三维模型权重,可以更好的使骨骼带动整个骨骼系统进行运动,从而能更好的进行身体结构的调节变形以及动作及表情的加载。为了简化调节的步骤,本方法将骨骼设定为可互相影响,并且骨骼之间的位置也进行了权重的分配,从而使骨骼系统趋于稳定,不会在调节的过程中产生严重的畸变。从而更好的完成脸部的模拟妆容,身体结构的调节变形以及动作及表情的加载。
优选地,所述的三维权重的设置方法为:获取骨骼位置,根据骨骼位置对所在区域的三维模型的网格设置权重,所述的骨骼的位置通过最小二乘法进行求解。通过上述的方法可以完成脸部的模拟妆容,身体结构的调节变形以及动作及表情的加载。
一种模型的编辑系统,包括:
模型获取模块:所述模型获取模块用于获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息;
对比模块:所述对比模块用于将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值;
变形模块:所述变形模块用于根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。
与现有技术相比,本发明具有的有益效果为:本发明提供了一种更好的线上服饰试穿展示效果,为用户进行服饰挑选提供了方便。具体的,获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息;将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值;根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。通过使用者三维模型以及模特三维模型姿势的差别信息,生成变形后的服饰,从而将变形后的服饰与使用者三维模型进行融合,完成试穿。实现线上的服饰试穿,更好的将试穿效果进行展示,给用户带来方便,提高线上服饰购买的体验。
附图说明
下面结合附图和实施例对本发明进一步说明。
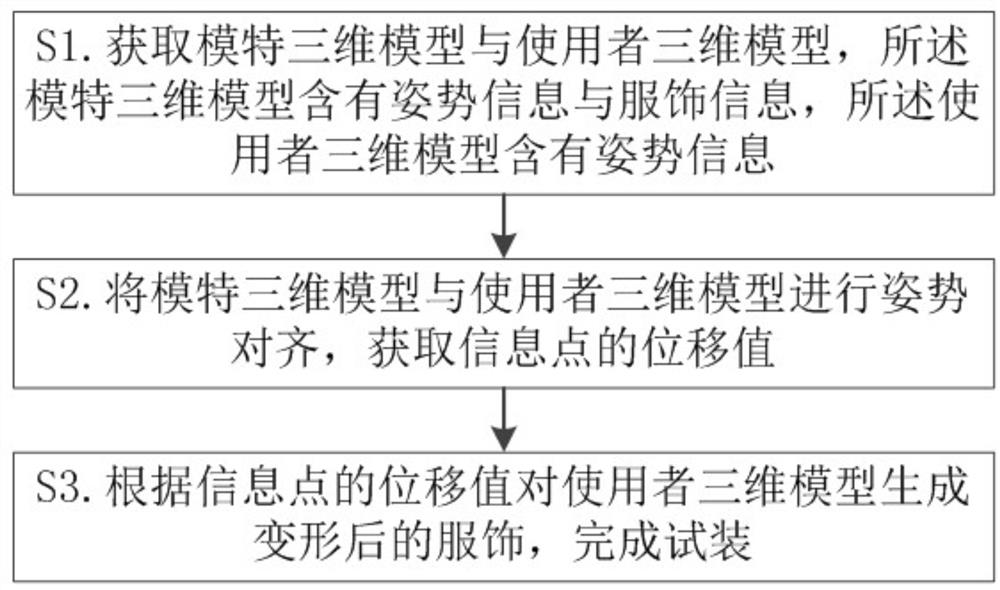
图1是本发明所述的一种模型的编辑方法的流程示意图;
图2是本发明所述的一种模型的编辑系统的结构图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本流程图,因此其仅显示与本发明有关的流程。
实施例1
如图1所示,是本发明提供的一种模型的编辑方法,包括:
S1.获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息;
S2.将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值;
S3.根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。
步骤S1:获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息。
所述模特三维模型的构建方法为:获取身着服饰的真人模特的照片或视频;对照片或视频进行分析,从而对真人模特进行三维重建,生成模特三维模型;获取模特三维模型的姿势信息。
所述使用者三维模型为用户通过构建人体三维模型进行设置的,人体三维模型的构建方法不限制于扫描或人体照片识别等技术构建。
在本发明在具体实施时,通过下述方法构建人体三维模型:首先预制可变形且已预制骨骼系统的标准三维模型,其中,三维模型根据体型结构的不同,可分为男性、女性、胖、瘦等多个基础3D人体模型或者单个基础3D人体模型。当使用者三维模型接收到姿势转变指令时,预制模型首先根据用户的姿势进行变形,变形完成后将骨骼系统根据变形后的预制模型进行相同位置的转换。所述姿势信息包括动作信息以及体型信息。
步骤S2:将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值。在具体实施时,采用了对抗神经网络,对信息点的位移值进行获取。
所述将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值具体为:将模特三维模型与使用者三维模型进行姿势对齐;比对模特三维模型与使用者三维模型的网格区别;通过网格区别获取每个信息点的位移值。
步骤S3:根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。
所述根据信息点的位移值对使用者三维模型生成变形后的服饰具体为:将空间每个信息点的位移值映射到真人模特的照片或视频上,将照片或视频中的服饰进行变形。
所述将照片或视频中的服饰进行变形后还包括:将变形后的照片或视频与使用者三维模型进行融合,生成具有试穿效果的使用者三维模型。
本发明避开了构建大量模型的方法,使用更简便的将模特三维模型与使用者三维模型进行对比,从而通过对抗网络形成变形后的服饰,与使用者三维模型进行融合,可以为用户提供试穿效果。实现根据用户不同姿势的对服饰进行展示,达到了更好的展示效果。
上述的过程是对用户的服饰进行变形的方法,同时,本发明还公开了对于表情以及动作的变形方法,如下所示:
所述使用者三维模型设置有骨骼系统,所述骨骼系统分为动作层与变形层;所述的动作层用于控制表情或动作;所述的变形层用于根据使用者的移动或者缩放的骨骼点,驱动使用者三维模型进行变形。
所述使用者三维模型的姿势通过骨骼变形进行展示,该骨骼变形的方法为:获取骨骼,将骨骼之间设置影响关系以及三维模型权重;将使用者三维模型与模特三维模型进行对齐,并将骨骼之间的影响关系以及三维权重解除;将骨骼位置与使用者三维模型对齐,加载骨骼之间的影响关系以及三维模型权重。
所述将骨骼之间设置影响关系以及三维模型权重具体为:预先设定配置文件,所述配置文件包括,骨骼之间的影响关系配表,以及三维模型的权重配表。通过将骨骼之间设置影响关系以及三维模型权重,可以更好的使骨骼带动整个骨骼系统进行运动,从而能更好的进行身体结构的调节变形以及动作及表情的加载。
所述的三维权重的设置方法为:获取骨骼位置,根据骨骼位置对所在区域的三维模型的网格设置权重,所述的骨骼的位置通过最小二乘法进行求解。本方法将骨骼设定为可互相影响,并且骨骼之间的位置也进行了权重的分配,从而使骨骼系统趋于稳定,不会在调节的过程中产生严重的畸变。从而更好的完成脸部的模拟妆容,身体结构的调节变形以及动作及表情的加载。
实施例2
如图2所示,本发明提供了一种模型的编辑系统,包括:
模型获取模块1:所述模型获取模块用于获取模特三维模型与使用者三维模型,所述模特三维模型含有姿势信息与服饰信息,所述使用者三维模型含有姿势信息;
对比模块2:所述对比模块用于将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值;
变形模块3:所述变形模块用于根据信息点的位移值对使用者三维模型生成变形后的服饰,完成试装。
所述模型获取模块1与对比模块2相连接,所述对比模块2与变形模块3相连接。
具体的:本发明通过模型获取模块1,获取了模特三维模型与使用者三维模型,所述模特三维模型与使用者三维模型分别设置有姿势信息。
所述模特三维模型的构建方法为:获取身着服饰的真人模特的照片或视频;对照片或视频进行分析,从而对真人模特进行三维重建,生成模特三维模型;获取模特三维模型的姿势信息。
所述使用者三维模型为用户通过构建人体三维模型进行设置的,不限制扫描或人体照片识别等技术构建。
在本发明中,所述的构建人体三维模型的方法为:首先预制可变形且已预制骨骼系统的标准三维模型,其中,三维模型根据体型结构的不同,可分为男性、女性、胖、瘦等多个基础3D人体模型或者单个基础3D人体模型。当使用者三维模型接收到姿势转变指令时,预制模型首先根据用户的姿势进行变形,变形完成后将骨骼系统根据变形后的预制模型进行相同位置的转换。所述姿势信息包括动作信息以及体型信息。
对比模块2接收到两个模型后,将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值。在具体实施时,采用了对抗神经网络,对服饰的变形量进行计算。
所述将模特三维模型与使用者三维模型进行姿势对齐,获取信息点的位移值具体为:将模特三维模型与使用者三维模型进行姿势对齐;比对模特三维模型与使用者三维模型的网格区别;通过网格区别获取每个信息点的位移值。
对比模块2将服饰变形量传输至变形模块。变形模块3根据差异量对使用者三维模型进行变形。
所述根据信息点的位移值对使用者三维模型生成变形后的服饰具体为:将空间每个信息点的位移值映射到真人模特的照片或视频上,将照片或视频中的服饰进行变形。
所述将照片或视频中的服饰进行变形后还包括:将变形后的照片或视频与使用者三维模型进行融合,生成具有试穿效果的使用者三维模型。
本申请还具体公开了对于使用者三维模型的表情以及动作的变形系统,具体如下:
所述使用者三维模型设置有骨骼系统,所述骨骼系统分为动作层与变形层;所述的动作层用于控制表情或动作;所述的变形层用于根据使用者的移动或者缩放的骨骼点,驱动使用者三维模型进行变形。
所述使用者三维模型的姿势通过骨骼变形进行展示,该骨骼变形的方法为:获取骨骼,将骨骼之间设置影响关系以及三维模型权重;将使用者三维模型与模特三维模型进行对齐,并将骨骼之间的影响关系以及三维权重解除;将骨骼位置与使用者三维模型对齐,加载骨骼之间的影响关系以及三维模型权重。
所述将骨骼之间设置影响关系以及三维模型权重具体为:预先设定配置文件,所述配置文件包括,骨骼之间的影响关系配表,以及三维模型的权重配表。通过将骨骼之间设置影响关系以及三维模型权重,可以更好的使骨骼带动整个骨骼系统进行运动,从而能更好的进行身体结构的调节变形以及动作及表情的加载。
所述的三维权重的设置方法为:获取骨骼位置,根据骨骼位置对所在区域的三维模型的网格设置权重,所述的骨骼的位置通过最小二乘法进行求解。
上列详细说明是针对本发明可行实施例的具体说明,以上实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
- 一种模型编辑系统的创建方法及模型编辑系统
- 一种在线模型编辑方法及在线模型编辑系统