一种多尺度融合的菜品识别方法
文献发布时间:2023-06-19 10:16:30
技术领域
本发明涉及一种菜品识别方法,具体涉及一种多尺度融合的菜品识别方法。
背景技术
目前菜品识别的方式主要分为两种,一种是直接利用一个单独的学习网络对图片中的待识别菜品目标进行检测及识别,这种方法通用性差,扩展性弱。另一种方法是将定位和识别拆分成两个网络,但是两个网络串联过程中会由于前置定位模型结果偏差极大程度影响到识别网络识别能力,同时,不同的定位方法也影响着识别能力。主流的定位方法是定位盛有菜品的餐具信息作为识别的输入图像,但是餐具自身的颜色、形状,菜品盛放形状很大程度上影响菜品识别的精度,因此考虑设计一种能减少餐具信息对识别模型的影响的识别算法。
菜品识别领域与其他物体识别领域存在自身的困难:菜品自身的区域难以界定,盛放菜品器皿的形状、颜色、纹理以及菜品摆放方式,都会对以餐具为识别目标的识别算法产生很大的影响,因此设计一种基于两种特征的组合特征识别模式。
发明内容
本发明要解决的技术问题是提供一种多尺度融合的菜品识别方法,多尺度目标检测识别,从而提高菜品识别的准确率。
为了解决所述技术问题,本发明采用的技术方案是:一种多尺度融合的菜品识别方法,包括以下步骤:
S01)、构建菜品特征库,针对需要预测的所有菜品,采用多尺度融合的方法提取菜品特征,构建菜品特征库;
S02)、针对待预测的菜品,采用多尺度融合的方法提取待预测菜品特征,将待预测菜品特征与菜品特征库中的内容进行特征比对,最相近者即为当前预测菜品的种类;
采用多尺度融合的方法提取需要预测的所有菜品或待预测菜品的特征的过程为:
A)、获取托盘目标图片,图片内容包括托盘中包含完整的不定个数的盛有菜品的餐具完整图案;
B)、利用深度学习定位模型对步骤A获取的图片进行餐具目标预测,获得餐具坐标信息;
C)、采用背景建模方式去除步骤B结果中的餐盘信息,降低图片中的无效信息,获得菜品自身图像信息;
D)、对步骤C结果确定重心位置;
E)、以步骤D结果为中心坐标,以步骤B图像尺寸一半为新图片尺寸,生成新的菜品信息图像;
F)、将步骤B和步骤E的结果分别作为两组深度学习特征提取网络输入,构成两组深度神经网络分类模型:
G)、将步骤F中的两组深度神经网络分类模型去掉分类输出层,保存至倒数第二层,将两组深度神经网络分类模型的输出叠加,构建新的全连接层神经网络,用于训练新的综合特征识别模型,综合特征识别模型对两组深度神经网络分类模型的输出进行识别,从而获得菜品特征。
进一步的,综合特征识别模型将两组深度神经网络分类模型组合,2组N维向量组合为2N维向量,N为深度神经网络分类模型的输出维数;并跟随一层包含100个神经元的隐藏层以及分类个数维度的分类层;训练完成后,综合特征识别模型的倒数第二层的100维向量的表示即为当前菜品的特征。
进一步的,深度神经网络分类模型采用Resnet-50为主体框架,首先通过分类任务训练模型。
进一步的,两个深度神经网络分类模型的倒数第二层均使用200维向量,即深度神经网络分类网络的输出维数为200。
进一步的,步骤D中,通过对像素数量进行加权统计获得重心位置。
进一步的,步骤C中,背景建模方式为:提前采集餐具图像信息,并进行旋转、缩放校正,进行图像对应位置差运算。
进一步的,深度学习定位模型采用YOLOV3模型,训练样本库由餐具图片及其外接矩形坐标信息组成。
进一步的,深度学习定位模型的输出为输入图片中包含餐具的外接矩形坐标信息。
进一步的,步骤S02中,特征比对采用求余弦距离的方式。
进一步的,所述菜品特征库为当日菜品特征库。
本发明的有益效果:
与现有技术相比,本发明具有以下显著优点:
提取餐具内部菜品信息特征,从而去除了餐具颜色、形状、纹理等信息带来的识别率下降的问题。
采用不同粒度特征组合特征比对的方式,降低了使用单个特征进行特征比对的偶然性,增加了准确率和鲁棒性。
附图说明
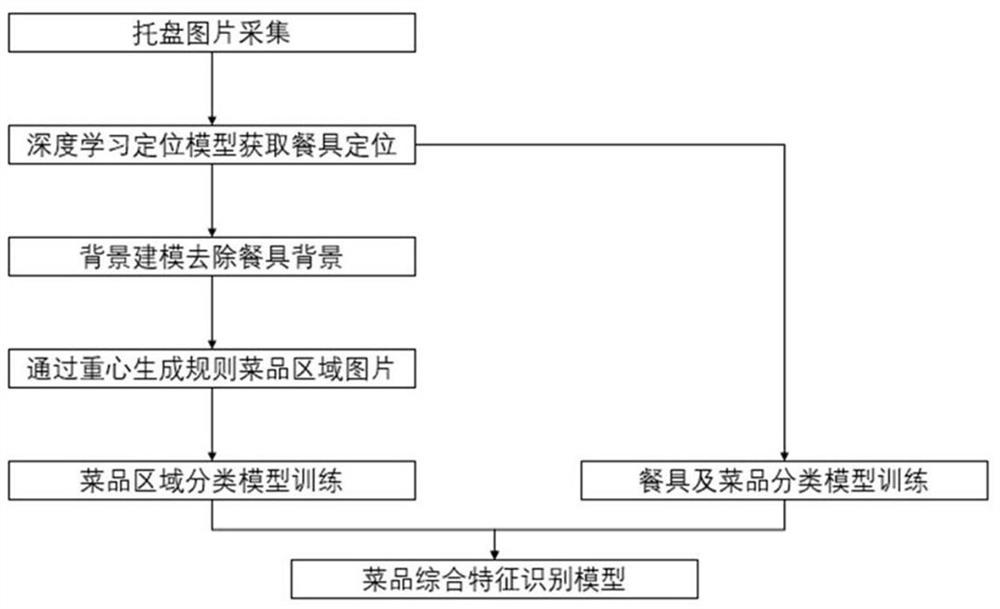
图1为采用多尺度融合的方法提取菜品特征的流程图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的说明。
实施例1
本实施例公开一种多尺度融合的菜品识别方法,本方法包括构建菜品特征库和特征比对两部分,构建菜品特征库和特征比对均采用多尺度特征融合的方法。针对需要预测的所有菜品,采用多尺度融合的方法提取菜品特征,构建菜品特征库;针对待预测的菜品,采用多尺度融合的方法提取待预测菜品特征,将待预测菜品特征与菜品特征库中的内容进行特征比对,最相近者即为当前预测菜品的种类。
本实施例中,所述菜品特征库可以为当日菜品特征库,也可以是当周菜品特征库,根据实际情况,对菜品特征库进行更新。
本实施例中,特征向量比对方式采用求余弦距离的方式,也可以采用其他特征比对方式。
如图1所示,采用多尺度融合的方法提取需要预测的所有菜品或待预测菜品的特征的过程为:
A)、获取托盘目标图片,图片内容包括托盘中包含完整的不定个数的盛有菜品的餐具完整图案;
B)、利用深度学习定位模型对步骤A获取的图片进行餐具目标预测,获得餐具坐标信息;
本实施例中,所述深度学习定位模型采用YOLOV3模型,训练样本库由餐具图片及其外接矩形坐标信息组成。所述深度学习定位模型的输出为输入图片中包含餐具的外接矩形坐标信息。
C)、采用背景建模方式去除步骤B结果中的餐盘信息,降低图片中的无效信息,获得菜品自身图像信息;
本实施例中,所述背景建模方法是:提前采集餐具图像信息,并进行旋转、缩放校正,进行图像对应位置差运算。
D)、对步骤C结果确定重心位置;本实施中,通过对像素数量进行加权统计获得重心位置。
E)、以步骤D结果为中心坐标,以步骤B图像尺寸一半为新图片尺寸,生成新的菜品信息图像;如步骤N结果图片左上与右下坐标信息为(x1,y1),(x2,y2),新生成的图片坐上与右下坐标为(x-(x2-x1)/4,y+(y1-y2)/4),((x+(x2-x1)/4,y-(y1-y2)/4)),其中x,y为步骤D所求重心坐标。
F)、将步骤B和步骤E的结果分别作为两组深度学习特征提取网络输入,构成两组深度神经网络分类模型:
本实施例中,所述深度神经网络分类模型采用Resnet-50为主体框架,首先通过分类任务形式训练模型。两个深度神经网络分类模型的倒数第二层,均使用200维向量。
G)、将步骤F中的两组深度神经网络分类模型去掉分类输出层,保存至倒数第二层,将两组深度神经网络分类模型的输出叠加,构建新的全连接层神经网络,用于训练新的综合特征识别模型。综合特征识别模型对两组深度神经网络分类模型的输出进行识别,从而获得菜品特征。
本实施例中,综合特征识别模型将两组分类模型组合,2组200维向量组合为400维向量,并跟随一层包含100个神经元的隐藏层,以及分类个数维度的分类层。
本实施例中,训练综合特征识别模型使用的分别为步骤F训练模型的预训练结果。训练完成后,该模型的倒数第二层的100维向量的表示即为当前菜品的特征。
以上所揭露仅为本发明的一个典型的具体实施案例,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所做的等同变化仍视为本发明所涵盖的范围。
- 一种多尺度融合的菜品识别方法
- 一种基于时序多尺度融合的行人重识别方法及系统