模型构建优化方法、设备、介质及计算机程序产品
文献发布时间:2023-06-19 10:21:15
技术领域
本申请涉及金融科技(Fintech)的机器学习技术领域,尤其涉及一种模型构建优化方法、设备、介质及计算机程序产品。
背景技术
随着金融科技,尤其是互联网科技金融的不断发展,越来越多的技术(如分布式、人工智能等)应用在金融领域,但金融业也对技术提出了更高的要求,如对金融业对应待办事项的分发也有更高的要求。
随着计算机技术的不断发展,机器学习模型的应用也越来越广泛,在纵向联邦学习场景中,存在某些参与方样本过少的情况,也即,存在小样本参与方,进而将导致小样本参与方训练的小样本模型容易过拟合,目前,通常通过横向联邦学习扩展训练样本的维度,进而可达到防止小样本模型过拟合的目的,但是,由于横向联邦学习的进行各参与方的特征需要对齐,进而若小样本参与方与其他方未存在可对齐的特征或者可对齐的特征较少而导致无法进行横向联邦学习或者横向联邦学习的效果较差,则仍然存在由于小样本模型容易过拟合的问题。
发明内容
本申请的主要目的在于提供一种模型构建优化方法、设备、介质及计算机程序产品,旨在解决现有技术中小样本模型容易过拟合的技术问题。
为实现上述目的,本申请提供一种模型构建优化方法,所述模型构建优化方法应用于模型构建优化设备,所述模型构建优化方法包括:
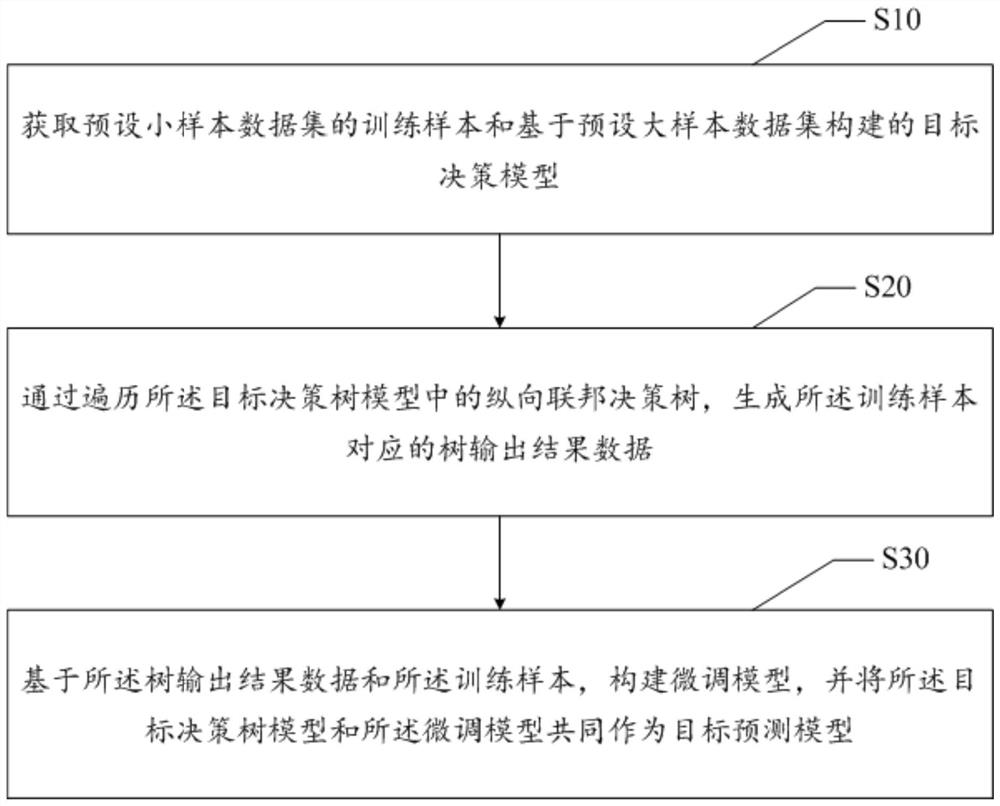
获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型;
通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据;
基于所述树输出结果数据和所述训练样本,构建微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型。
本申请还提供一种样本预测方法,所述样本预测方法应用于样本预测设备,所述样本预测方法包括:
获取待预测样本,并通过遍历预设目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果;
基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果。
本申请还提供一种模型构建优化装置,所述模型构建优化装置为虚拟装置,且所述模型构建优化装置应用于模型构建优化设备,所述模型构建优化装置包括:
获取模块,用于获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型;
生成模块,用于通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据;
构建模块,用于基于所述树输出结果数据和所述训练样本,构建微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型。
本申请还提供一种样本预测装置,所述样本预测装置为虚拟装置,且所述样本预测装置应用于样本预测设备,所述样本预测装置包括:
遍历模块,用于获取待预测样本,并通过遍历预设目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果;
预测模块,用于基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果。
本申请还提供一种模型构建优化设备,所述模型构建优化设备为实体设备,所述模型构建优化设备包括:存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的所述模型构建优化方法的程序,所述模型构建优化方法的程序被处理器执行时可实现如上述的模型构建优化方法的步骤。
本申请还提供一种样本预测设备,所述样本预测设备为实体设备,所述样本预测设备包括:存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的所述样本预测方法的程序,所述样本预测方法的程序被处理器执行时可实现如上述的样本预测方法的步骤。
本申请还提供一种可读存储介质,所述可读存储介质上存储有实现模型构建优化方法的程序,所述模型构建优化方法的程序被处理器执行时实现如上述的模型构建优化方法的步骤。
本申请还提供一种可读存储介质,所述可读存储介质上存储有实现样本预测方法的程序,所述样本预测方法的程序被处理器执行时实现如上述的样本预测方法的步骤。
本申请还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述的模型构建优化方法的步骤。
本申请还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述的样本预测方法的步骤。
本申请提供了一种模型构建优化方法、设备、介质及计算机程序产品,相比于现有技术采用的横向联邦学习扩展训练样本的维度,进而实现防止小样本模型过拟合的目的的技术手段,本申请首先获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型,进而通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据,其中,由于所述目标决策模型是基于预设大样本数据集构建的,进而所述目标决策模型学习到了预设大样本数据集的数据分布,进而通过将预设小样本数据集的训练样本输入目标决策模型生成树输出结果数据,使得树输出结果数据与预设大样本数据集的数据分布具备关联性,进而实现了基于预设样本数据集构建预设小样本数据集的训练样本的中间特征的目的,进而获取基于预设小样本数据集构建的待微调模型,并基于各所述训练树输出值,对所述待微调模型的模型参数进行微调,获得所述目标预测模型,也即,通过训练样本的中间决策树特征,对待微调模型的模型参数进行微调,使得待微调模型在学习到预设小样本数据集的特征基础上,以生成中间决策树特征的方式间接地学习到了预设大样本数据集的特征,进而实现了基于大样本数据间接地对小样本模型的模型参数进行微调的目的,进而基于所述树输出结果数据和所述训练样本,构建微调模型,实现了间接扩展微调模型对应的训练样本的样本维度的目的,也即,实现了将预设大样本数据集的中间决策树特征迁移到小样本模型的目的,提高小样本模型的泛化能力,所以降低了小样本模型过拟合的风险,克服了若小样本参与方与其他方未存在可对齐的特征或者可对齐的特征较少而导致无法进行横向联邦学习或者横向联邦学习的效果较差时,小样本模型容易过拟合的技术缺陷,所以,解决了小样本模型容易过拟合的技术问题。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本申请模型构建优化方法第一实施例的流程示意图;
图2为本申请模型构建优化方法中构建所述目标决策树模型的系统架构示意图;
图3为本申请模型构建优化方法第二实施例的流程示意图;
图4为本申请实施例中模型构建优化方法涉及的硬件运行环境的设备结构示意图。
图5为本申请实施例中样本预测方法涉及的硬件运行环境的设备结构示意图;
图6为本申请实施例方案涉及的硬件架构示意图。
本申请目的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本申请,并不用于限定本申请。
本申请实施例提供一种模型构建优化方法,在本申请模型构建优化方法的第一实施例中,参照图1,所述模型构建优化方法包括:
步骤S10,获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型;
在本实施例中,所述模型构建优化方法应用于第一设备,其中,所述第一设备为具备预设小样本数据集的联邦学习参与设备,其中,所述预设小样本数据集为数据量小于预设第一数据量阈值的数据集,其中,所述第一设备可基于预设小样本数据集与第二设备进行纵向联邦学习建模,以构建纵向联邦学习模型,但是由于预设小样本数据集的数据量较小,则容易导致纵向联邦学习模型过拟合,其中,所述第二设备为数据提供方。
获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型,具体地,在预设小样本数据集选取预设数量的训练样本,并接收第三设备发送的基于预设大样本数据集构建的目标决策模型,其中,所述第三设备为具备预设大样本数据集的联邦学习参与设备,所述预设大样本数据集为数据集大于预设第二数据量阈值的数据集,其中,所述预设第二数据量阈值大于或者等于所述预设第一数据量阈值,所述第一设备的预设小样本数据集对应的应用场景与所述第三设备的预设大样本数据集对应的应用场景相似,例如,假设第一设备为银行A,第三设备为银行B,第一设备的应用场景为基于本地数据存款数据,对用户进行风险评估,第三设备的应用场景为基于本地数据存款数据,预测对用户的放款额度等。
可选地,在另一种实施方式中,所述预设小样本数据集为预设第一样本数据集,所述预设大样本数据集为预设第二样本数据集,且所述预设第一样本数据集的数据量小于所述预设第二样本数据集的数据量。
步骤S20,通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据;
在本实施例中,需要描述的是,所述目标决策模型为所述第三设备基于预设大样本数据集,与所述数据提供方进行纵向联邦学习建模构建的,所述目标决策树模型包括GBDT(Gradient Boosting Decision Tree,梯度提升树)模型。
通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据,具体地,将所述训练样本输入所述目标决策树模型,并通过遍历所述目标决策树模型中的纵向联邦决策树,确定所述训练样本在各所述纵向联邦决策树中的归属叶子节点,进而获取各所述归属叶子节点对应的树输出结果,进而将各所述树输出结果作为所述树输出结果数据。
其中,所述模型构建优化方法应用于第一设备,所述目标决策树模型至少包括一纵向联邦决策树,所述树输出结果数据至少包括一树输出结果,
所述通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据的步骤包括:
步骤S21,将所述训练样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属;
在本实施例中,需要说明的是,所述纵向联邦决策树的每一树节点均包括节点标记,用于标识树节点的归属,也即,判断树节点是属于第一设备还是其他的第二设备,其中,所述第二设备的数量可以为多个,所述纵向联邦决策树存储于所述第一设备中。
将所述训练样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属,具体地,将训练样本输入所述纵向联邦决策树,并遍历所述纵向联邦决策树的根节点,以基于所述根节点中的节点标记判断所述根节点的归属。
步骤S22,若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述训练样本的所属孩子节点;
在本实施例中,若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述训练样本的所属孩子节点,具体地,若根节点属于第二设备,向所述第二设备发送预测请求,其中,所述预测请求中包括样本ID和特征编码,其中,所述样本ID为所述训练样本的身份标识,所述特征编码为树节点对应的用于进行树节点分裂的特征的标识,进而所述第二设备在接收到所述样本ID和所述特征编码之后,所述第二设备可基于所述样本ID和所述特征编码获取对应的本地存储的特征分裂值以判断所述训练样本的归属,也即,判断所述训练样本是属于左孩子节点还是右孩子节点,获得判断结果,并将判断结果作为反馈结果向第一设备进行反馈,进而第一设备接收所述第二设备反馈的反馈结果,其中,所述反馈结果中包括判断所述训练样本是属于左孩子节点还是右孩子节点的判断结果,并基于所述判断结果,确定所述训练样本的所属孩子节点,例如,假设所述树节点A分裂对应的特征为年龄特征,特征分裂值为35,则证明年龄小于35岁的样本均在所述树节点A的左孩子节点,年龄大于或者等于35岁的样本均在所述树节点A的右孩子节点。
步骤S23,判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果;
在本实施例中,判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果,具体地,判断所述所属孩子节点是否为叶子节点,若所述所属孩子节点为叶子节点,则将所述所属孩子节点作为所述训练样本的归属叶子节点,并获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果。
步骤S24,若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果;
在本实施例中,若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果,具体地,若所述所属孩子节点不属于所述叶子节点类型,则由所述所属孩子节点继续往下遍历所述纵向联邦决策树,直至确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果。
步骤S25,若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述训练样本的所述所属孩子节点,以确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果。
在本实施例中,若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述训练样本的所述所属孩子节点,以确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果,具体地,若根节点属于所述第一设备,则基于存储于所述第一设备中的所述根节点对应的特征分裂值,确定所述训练样本的所述所属孩子节点,进而进行所述所属孩子节点是否属于叶子节点类型的判断,若所述所属孩子节点为叶子节点类型,则确定所述所属孩子节点为所述训练样本对应的归属叶子节点,若所述所属孩子节点不为叶子节点类型,则继续遍历所述所属孩子节点,直至确定所述训练样本对应的归属叶子节点,进而获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果。
步骤S30,基于所述树输出结果数据和所述训练样本,构建微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型。
在本实施例例中,基于所述树输出结果数据和所述训练样本,构建微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型,具体地,基于预设小样本数据集中各训练样本对应的输出结果数据,构造各所述训练样本对应的中间特征,进而基于各所述训练样本和各所述训练样本对应的中间特征,生成扩展训练数据集,进而基于所述扩展训练数据集,与所述第二设备进行纵向联邦学习建模,构建所述微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型。
其中,所述模型构建优化方法应用于第一设备,所述树输出结果数据至少包括一树输出结果,
所述基于所述树输出结果数据和所述训练样本,构建微调模型的步骤包括:
步骤S31,基于各所述树输出结果,构建中间特征,并生成具备所述中间特征的扩展训练样本;
在本实施例中,需要说明的是,所述树输出结果包括树输出值,其中,所述输出值为所述训练样本对应的归属叶子节点中记录的样本权重。
基于各所述树输出结果,构建中间特征,并生成具备所述中间特征的扩展训练样本,具体地,将训练样本对应的各所述树输出值进行拼接,获得各所述训练样本对应的拼接向量,进而将所述拼接向量作为所述中间特征,进而将所述中间特征与训练样本对应的样本表示向量进行拼接,获得具备所述中间特征的扩展训练样本,其中,所述样本表示向量为由训练样本对应的各特征值编码组成的向量,用于表示所述训练样本。
其中,所述树输出结果包括叶子节点编码和树输出值,
所述基于各所述树输出结果,构建中间特征的步骤包括:
步骤S311,将各所述树输出值进行拼接,获得所述中间特征;和/或,
在本实施例中,将各所述树输出值拼接而成的拼接向量作为所述中间特征。
步骤S312,将各所述叶子节点编码对应的位置编码向量进行拼接,获得所述中间特征;和/或,
在本实施例中,需要说明的是,所述纵向联邦决策树的叶子节点均具备叶子节点编码,且当训练样本由目标决策树的根节点输入时,在经历一系列的特征判断条件后,最终将落在所述纵向联邦决策树的一叶子节点,则该叶子节点与这一系列的特征判断条件存在对应关系,进而该叶子节点可用于进训练样本的特征拓展,其中,特征判断条件为用于判断训练样本是属于树节点的左孩子节点还是右孩子节点的判断条件,其中,所述特征判断条件可以为特征分裂值。
将各所述叶子节点编码对应的位置编码向量进行拼接,获得所述中间特征,具体地,基于预设的叶子节点编码与位置编码之间的映射关系,将各所述叶子节点编码映射为对应的位置编码,例如,假设所述叶子节点编码为A1,其中,A表示叶子节点属于目标决策树模型的第一颗纵向联邦决策树,1表示叶子节点为第一颗目标决策树中的第一个叶子节点,进而基于预设的叶子节点编码与位置编码之间的映射关系,确定对应的位置编码为1,进而对各所述位置编码进行独热编码,获得各位置编码对应的位置编码向量,进而将各所述位置编码向量拼接的向量作为中间特征。
步骤S313,基于各所述树输出值,分别对各所述叶子节点编码对应的位置编码向量进行加权,获得各加权位置编码向量;
在本实施例中,基于各所述树输出值,分别对各所述叶子节点编码对应的位置编码向量进行加权,获得各加权位置编码向量,具体地,基于预设的叶子节点编码与位置编码之间的映射关系,将各所述叶子节点编码映射为对应的位置编码,进而对各所述位置编码进行独热编码,获得各位置编码对应的位置编码向量,进而基于各所述树输出值,分别为对应的位置编码向量进行加权,输出各所述位置编码向量对应的加权位置编码向量。
步骤S314,将各所述加权位置编码向量进行拼接,获得所述中间特征。
在本实施例中,将各所述加权位置编码向量拼接的向量作为中间特征。
步骤S32,基于具备所述扩展训练样本的扩展数据集,通过与第二设备进行纵向联邦学习建模,生成所述微调模型。
在本实施例中,需要说明的是,所述预设小样本数据集中每一训练样本对应一扩展训练样本,所述扩展数据集至少包括一扩展训练样本。
基于具备所述扩展训练样本的扩展数据集,通过与第二设备进行纵向联邦学习建模,生成所述微调模型,具体地,在所述扩展数据集中选择联邦训练样本,并基于所述联邦训练样样本,对预设待训练微调模型进行迭代训练,直至满足预设迭代次数,获取所述预设待训练微调模型的模型参数信息,并将所述模型参数信息发送至预设联邦服务器,并接收所述预设联邦服务器基于所述模型参数信息反馈的联邦模型参数信息,进而基于所述联邦模型参数信息,对所述预设待训练微调模型进行更新,并判断所述预设待训练微调模型是否满足预设联邦训练结束条件,若是,则将所述预设待训练微调模型作为微调模型,若否,则返回所述在所述扩展数据集中选择联邦训练样本的步骤。
其中,所述基于具备所述扩展训练样本的扩展数据集,通过与第二设备进行纵向联邦学习建模,生成所述微调模型的步骤包括:
步骤S321,在所述扩展数据集中选取联邦训练样本;
在本实施例中,需要说明的是,所述扩展数据集至少包括一联邦训练样本,其中,所述联邦训练样本为基于中间特征进行扩展之后的训练样本。
步骤S322,基于所述联邦训练样本,对预设待训练微调模型进行迭代训练,直至所述预设待训练微调模型满足预设迭代训练次数,获取所述预设待训练微调模型的本地模型参数信息;
在本实施例中,基于所述联邦训练样本,对预设待训练微调模型进行迭代训练,直至所述预设待训练微调模型满足预设迭代训练次数,获取所述预设待训练微调模型的本地模型参数信息,具体地,将所述联邦训练样本输入预设待训练微调模型,对所述联邦训练样本进行分类,获得训练分类标签,并计算所述训练分类标签与所述联邦训练样本对应的预设分类标签的差值,获得模型损失,进而基于所述模型损失,对所述预设待训练微调模型的模型参数进行更新,并判断更新后的预设待训练微调模型是否满足预设迭代训练次数,若满足,则获取更新后的待训练微调模型的本地模型参数,并对所述本地模型参数进行同态加密,获得所述本地模型参数信息。
步骤S323,将所述本地模型参数信息发送至预设联邦服务器,以供所述预设联邦服务器基于所述本地模型参数信息和所述第二设备发送的第二本地模型参数信息,生成联邦模型参数信息;
在本实施例中,将所述本地模型参数信息发送至预设联邦服务器,以供所述预设联邦服务器基于所述本地模型参数信息和所述第二设备发送的第二本地模型参数信息,生成联邦模型参数信息,具体地,将所述本地模型参数信息发送至预设联邦服务器,以供所述预设联邦服务器接收第一设备发送的所述本地模型参数信息和第二设备发送的第二本地模型参数信息,其中,所述第二本地模型参数信息为同态加密的第二设备的本地模型参数,并依据预设联邦规则,将所述本地模型参数信息和第二本地模型参数信息进行聚合,获得联邦模型参数信息,其中,所述预设联邦规则包括加权平均以及求和等。
步骤S324,接收所述联邦模型参数信息,并基于所述联邦模型参数信息,对所述预设待训练微调模型进行更新,以判断所述预设待训练微调模型是否满足预设联邦训练结束条件;
在本实施例中,接收所述联邦模型参数信息,并基于所述联邦模型参数信息,对所述预设待训练微调模型进行更新,以判断所述预设待训练微调模型是否满足预设联邦训练结束条件,具体地,接收所述联邦模型参数信息,并对所述联邦模型参数信息进行解密,获得联邦模型参数,进而将所述预设待训练微调模型的模型参数替换更新为联邦模型参数,并判断替换更新后的预设待训练微调模型是否满足预设联邦训练结束条件,其中,所述预设联邦训练结束条件包括损失函数收敛和达到最大迭代次数阈值等。
步骤S325,若是,则将所述待训练微调模型作为所述微调模型;
步骤S326,若否,则返回所述在所述扩展数据集中选取联邦训练样本的步骤。
在本实施例中,若是,则证明本次纵向联邦学习建模结束,并将所述待训练微调模型作为所述微调模型,若否,则证明本次纵向联邦学习建模未结束,并返回所述在所述扩展数据集中选取联邦训练样本的步骤,继续进行纵向联邦学习建模,如图2所示为构建所述目标决策树模型的系统架构示意图,其中,数据源属于所述第二设备,大样本客户属于所述第三设备,小样本客户属于所述第一设备,GBDT模型为所述目标决策树模型,LR(LogisticRegression,逻辑回归)模型为所述微调模型,GBDT中间特征为所述中间特征,“ID”表示样本,“X”和“Y”表示样本特征。
本申请实施例提供了一种模型构建优化方法,相比于现有技术采用的横向联邦学习扩展训练样本的维度,进而实现防止小样本模型过拟合的目的的技术手段,本申请实施例首先获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型,进而通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据,其中,由于所述目标决策模型是基于预设大样本数据集构建的,进而所述目标决策模型学习到了预设大样本数据集的数据分布,进而通过将预设小样本数据集的训练样本输入目标决策模型生成树输出结果数据,使得树输出结果数据与预设大样本数据集的数据分布具备关联性,进而实现了基于预设样本数据集构建预设小样本数据集的训练样本的中间特征的目的,进而获取基于预设小样本数据集构建的待微调模型,并基于各所述训练树输出值,对所述待微调模型的模型参数进行微调,获得所述目标预测模型,也即,通过训练样本的中间决策树特征,对待微调模型的模型参数进行微调,使得待微调模型在学习到预设小样本数据集的特征基础上,以生成中间决策树特征的方式间接地学习到了预设大样本数据集的特征,进而实现了基于大样本数据间接地对小样本模型的模型参数进行微调的目的,进而基于所述树输出结果数据和所述训练样本,构建微调模型,实现了间接扩展微调模型对应的训练样本的样本维度的目的,也即,实现了将预设大样本数据集的中间决策树特征迁移到小样本模型的目的,提高小样本模型的泛化能力,所以降低了小样本模型过拟合的风险,克服了若小样本参与方与其他方未存在可对齐的特征或者可对齐的特征较少而导致无法进行横向联邦学习或者横向联邦学习的效果较差时,小样本模型容易过拟合的技术缺陷,所以,解决了小样本模型容易过拟合的技术问题。
进一步地,参照图3,基于本申请中第一实施例,在本申请的另一实施例中,所述样本预测方法包括:
步骤A10,获取待预测样本,并通过遍历所述目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果;
在本实施例中,获取待预测样本,并通过遍历所述目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果,具体地,将所述待预测样本输入预设目标决策树模型,并通过遍历所述预设目标决策树模型中各纵向联邦决策树,确定所述待预测样本在各所述纵向联邦决策树中的归属目标叶子节点,进而获取各所述归属目标叶子节点对应的树输出预测结果。
其中,所述样本预测方法应用于第一设备,所述预设目标决策树模型至少包括一纵向联邦决策树,所述树输出预测结果数据至少包括一树输出预测结果,
所述通过遍历预设目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果的步骤包括:
步骤A11,将所述待预测样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属;
在本实施例中,需要说明的是,所述纵向联邦决策树的每一树节点均包括节点标记,用于标识树节点的归属,也即,判断树节点是属于第一设备还是其他的第二设备,其中,所述第二设备的数量可以为多个,所述纵向联邦决策树存储于所述第一设备中。
将所述待预测样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属,具体地,将待预测样本输入所述纵向联邦决策树,并遍历所述纵向联邦决策树的根节点,以基于所述根节点中的节点标记判断所述根节点的归属。
步骤A12,若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述待预测样本的所属孩子节点;
在本实施例中,若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述待预测样本的所属孩子节点,具体地,若根节点属于第二设备,向所述第二设备发送预测请求,其中,所述预测请求中包括样本ID和特征编码,其中,所述样本ID为所述待预测样本的身份标识,所述特征编码为树节点对应的用于进行树节点分裂的特征的标识,进而所述第二设备在接收到所述样本ID和所述特征编码之后,所述第二设备可基于所述样本ID和所述特征编码获取对应的本地存储的特征分裂值以判断所述待预测样本的归属,也即,判断所述待预测样本是属于左孩子节点还是右孩子节点,获得判断结果,并将判断结果作为反馈结果向第一设备进行反馈,进而第一设备接收所述第二设备反馈的反馈结果,其中,所述反馈结果中包括判断所述待预测样本是属于左孩子节点还是右孩子节点的判断结果,并基于所述判断结果,确定所述待预测样本的所属孩子节点。
步骤A13,判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果;
在本实施例中,判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果,具体地,判断所述所属孩子节点是否为叶子节点,若所述所属孩子节点为叶子节点,则将所述所属孩子节点作为所述训练样本的归属叶子节点,并获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果,其中,所述样本权重为树输出预测值。
步骤A14,若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果;
在本实施例中,若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果,具体地,若所述所属孩子节点不属于所述叶子节点类型,则由所述所属孩子节点继续往下遍历所述纵向联邦决策树,直至确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果。
步骤A15,若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述待预测样本的所述所属孩子节点,以确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果。
在本实施例中,若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述待预测样本的所述所属孩子节点,以确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果,具体地,若根节点属于所述第一设备,则基于存储于所述第一设备中的所述根节点对应的特征分裂值,确定所述待预测样本的所述所属孩子节点,进而进行所述所属孩子节点是否属于叶子节点类型的判断,若所述所属孩子节点为叶子节点类型,则确定所述所属孩子节点为所述待预测样本对应的归属叶子节点,若所述所属孩子节点不为叶子节点类型,则继续遍历所述所属孩子节点,直至确定所述待预测样本对应的归属叶子节点,进而获取所述归属叶子节点对应的叶子节点编码和所述归属叶子节点中记录的样本权重共同作为所述树输出结果。
步骤A20,基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果。
在本实施例中,基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果,具体地,基于各所述输出结果,构造所述待预测样本的目标中间特征,其中,所述目标中间特征为基于所述待预测样本在各纵向联邦决策树中的树输出预测结果生成的决策树特征,用于作为所述待预测样本的扩展特征对所述待预测样本进行模型预测,进而将所述目标中间特征与所述待预测样本拼接后输入预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果。
其中,所述预设目标预测模型包括LR模型,所述目标预测结果包括分类结果,
所述基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果的步骤包括:
步骤A21,基于各所述树输出预测结果,构建目标中间特征,并生成所述待预测样本对应的具备所述目标中间特征的扩展预测样本;
在本实施例中,需要说明的是,所述树输出预测结果包括叶子节点标签和树输出预测值,其中,所述树输出预测值为样本权重。
基于各所述树输出预测结果,构建目标中间特征,并生成所述待预测样本对应的具备所述目标中间特征的扩展预测样本,具体地,将各所述树输出预测值拼接的向量作为目标中间特征,并将所述目标中间特征与所述待预测样本的样本表示向量进行拼接,获得所述扩展预测样本。
其中,所述树输出预测结果包括叶子节点预测编码和树输出预测值,
所述基于各所述树输出预测结果,构建目标中间特征的步骤包括:
步骤A211,将各所述树输出预测值进行拼接,获得所述目标中间特征;和/或,
在本实施例中,将各所述树输出预测值进行拼接获得的拼接向量作为所述目标中间特征。
步骤A212,将各所述叶子节点预测编码对应的位置编码预测向量进行拼接,获得所述目标中间特征;和/或,
在本实施例中,将各所述叶子节点预测编码对应的位置编码预测向量进行拼接,获得所述目标中间特征,具体地,基于预设的叶子节点编码与位置预测编码之间的映射关系,将所述待预测样本对应的各所述叶子节点编码映射为对应的目标位置预测编码,并对各所述目标位置预测编码进行独热编码,获得各所述目标位置预测编码对应的目标位置编码预测向量,进而将各所述目标位置编码预测向量拼接为所述目标中间特征。
步骤A213,基于各所述树输出预测值,分别对各所述叶子节点预测编码对应的位置编码预测向量进行加权,获得各加权位置编码预测向量;
在本实施例中,基于各所述树输出预测值,分别对各所述叶子节点预测编码对应的位置编码预测向量进行加权,获得各加权位置编码预测向量,具体地,基于预设的叶子节点编码与位置预测编码之间的映射关系,将所述待预测样本对应的各所述叶子节点编码映射为对应的目标位置预测编码,并对各所述目标位置预测编码进行独热编码,获得各所述目标位置预测编码对应的目标位置编码预测向量,进而基于各所述树输出预测值,分别为对应的目标位置编码预测向量进行加权,输出各所述目标位置编码预测向量对应的加权目标位置编码预测向量,例如,假设目标决策树模型中各纵向联邦决策树一共存在6个叶子节点,所述树输出预测值为0.8,所述目标位置预测编码为1,则经独热编码后获得的目标位置编码预测向量为(1,0,0,0,0,0),所述加权目标位置编码预测向量为(0.8,0,0,0,0,0)。
步骤A214,将各所述加权位置编码预测向量进行拼接,获得所述目标中间特征。
在本实施例中,将各所述加权位置编码预测向量进行拼接获得的拼接向量作为所述目标中间特征。
步骤A22,将所述扩展预测样本输入所述LR模型,以基于所述扩展预测样本,对所述待预测样本进行分类,获得所述分类结果。
在本实施例中,将所述扩展预测样本输入所述LR模型,以基于所述扩展预测样本,对所述待预测样本进行分类,获得所述分类结果,具体地,将所述扩展预测样本输入所述LR模型,以将所述扩展预测样本对应的扩展预测样本表示向量映射为逻辑回归值,并基于所述逻辑回归值,确定所述待预测样本的分类结果,其中,所述逻辑回归值可用于表示待样本属于某一分类的分类概率,进而当所述分类概率大于预设分类概率阈值时,则可判定所述待预测样本属于分类概率对应的样本类别。
本申请实施例提供了一种样本预测优化方法,也即,首先获取待预测样本,并通过遍历所述目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果,进而基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果,也即,基于各所述树输出预测结果,构造所述待预测样本的额外特征,而由于目标决策树模型是基于预设大样本数据集构建的,进而实现了基于预设大样本数据集构造来自于预设小样本数据集的待预测样本的额外特征的目的,并依据额外特征与原先的待预测样本,通过基于预设小样本数据集构建的微调模型,对待预测样本执行模型预测,可实现了更加丰富特征的样本进行模型预测的目的,进而提高了小样本模型预测的准确度。
参照图4,图4是本申请实施例方案涉及的硬件运行环境的设备结构示意图。
如图4所示,该模型构建优化设备可以包括:处理器1001,例如CPU,存储器1005,通信总线1002。其中,通信总线1002用于实现处理器1001和存储器1005之间的连接通信。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储设备。
可选地,该模型构建优化设备还可以包括矩形用户接口、网络接口、摄像头、RF(Radio Frequency,射频)电路,传感器、音频电路、WiFi模块等等。矩形用户接口可以包括显示屏(Display)、输入子模块比如键盘(Keyboard),可选矩形用户接口还可以包括标准的有线接口、无线接口。网络接口可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。
本领域技术人员可以理解,图4中示出的模型构建优化设备结构并不构成对模型构建优化设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图4所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块以及模型构建优化程序。操作系统是管理和控制模型构建优化设备硬件和软件资源的程序,支持模型构建优化程序以及其它软件和/或,程序的运行。网络通信模块用于实现存储器1005内部各组件之间的通信,以及与模型构建优化系统中其它硬件和软件之间通信。
在图4所示的模型构建优化设备中,处理器1001用于执行存储器1005中存储的模型构建优化程序,实现上述任一项所述的模型构建优化方法的步骤。
本申请模型构建优化设备具体实施方式与上述模型构建优化方法各实施例基本相同,在此不再赘述。
参照图5,图5是本申请实施例方案涉及的硬件运行环境的设备结构示意图。
如图5所示,该样本预测设备可以包括:处理器1001,例如CPU,存储器1005,通信总线1002。其中,通信总线1002用于实现处理器1001和存储器1005之间的连接通信。存储器1005可以是高速RAM存储器,也可以是稳定的存储器(non-volatile memory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储设备。
可选地,该样本预测设备还可以包括矩形用户接口、网络接口、摄像头、RF(RadioFrequency,射频)电路,传感器、音频电路、WiFi模块等等。矩形用户接口可以包括显示屏(Display)、输入子模块比如键盘(Keyboard),可选矩形用户接口还可以包括标准的有线接口、无线接口。网络接口可选的可以包括标准的有线接口、无线接口(如WI-FI接口)。
本领域技术人员可以理解,图5中示出的样本预测设备结构并不构成对样本预测设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图5所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块以及样本预测程序。操作系统是管理和控制样本预测设备硬件和软件资源的程序,支持样本预测程序以及其它软件和/或,程序的运行。网络通信模块用于实现存储器1005内部各组件之间的通信,以及与样本预测系统中其它硬件和软件之间通信。
在图5所示的样本预测设备中,处理器1001用于执行存储器1005中存储的样本预测程序,实现上述任一项所述的样本预测方法的步骤。
本申请样本预测设备具体实施方式与上述样本预测方法各实施例基本相同,在此不再赘述。
本申请实施例还提供一种模型构建优化装置,所述模型构建优化装置应用于第一设备,所述模型构建优化装置包括:
获取模块,用于获取预设小样本数据集的训练样本和基于预设大样本数据集构建的目标决策模型;
生成模块,用于通过遍历所述目标决策树模型中的纵向联邦决策树,生成所述训练样本对应的树输出结果数据;
构建模块,用于基于所述树输出结果数据和所述训练样本,构建微调模型,并将所述目标决策树模型和所述微调模型共同作为目标预测模型。
可选地,所述构建模块还用于:
基于各所述树输出结果,构建中间特征,并生成具备所述中间特征的扩展训练样本;
基于具备所述扩展训练样本的扩展数据集,通过与第二设备进行纵向联邦学习建模,生成所述微调模型。
可选地,所述构建模块还用于:
将各所述树输出值进行拼接,获得所述中间特征;和/或,
将各所述叶子节点编码对应的位置编码向量进行拼接,获得所述中间特征;和/或,
基于各所述树输出值,分别对各所述叶子节点编码对应的位置编码向量进行加权,获得各加权位置编码向量;
将各所述加权位置编码向量进行拼接,获得所述中间特征。
可选地,所述构建模块还用于:
在所述扩展数据集中选取联邦训练样本;
基于所述联邦训练样本,对预设待训练微调模型进行迭代训练,直至所述预设待训练微调模型满足预设迭代训练次数,获取所述预设待训练微调模型的本地模型参数信息;
将所述本地模型参数信息发送至预设联邦服务器,以供所述预设联邦服务器基于所述本地模型参数信息和所述第二设备发送的第二本地模型参数信息,生成联邦模型参数信息;
接收所述联邦模型参数信息,并基于所述联邦模型参数信息,对所述预设待训练微调模型进行更新,以判断所述预设待训练微调模型是否满足预设联邦训练结束条件;
若是,则将所述待训练微调模型作为所述微调模型;
若否,则返回所述在所述扩展数据集中选取联邦训练样本的步骤。
可选地,所述生成模块还用于:
将所述训练样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属;
若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述训练样本的所属孩子节点;
判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果;
若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果;
若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述训练样本的所述所属孩子节点,以确定所述训练样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出结果。
本申请模型构建优化装置的具体实施方式与上述模型构建优化方法各实施例基本相同,在此不再赘述。
本申请实施例还提供一种样本预测装置,所述样本预测装置应用于第一设备,所述样本预测装置包括:
遍历模块,用于获取待预测样本,并通过遍历预设目标决策树模型中各纵向联邦决策树,生成所述待预测样本在各所述纵向联邦决策树中的树输出预测结果;
预测模块,用于基于各所述树输出预测结果和预设目标预测模型,对所述待预测样本执行模型预测,获得目标预测结果。
可选地,所述预测模块还用于:
基于各所述树输出预测结果,构建目标中间特征,并生成所述待预测样本对应的具备所述目标中间特征的扩展预测样本;
将所述扩展预测样本输入所述LR模型,以基于所述扩展预测样本,对所述待预测样本进行分类,获得所述分类结果。
可选地,所述预测模块还用于:
将各所述树输出预测值进行拼接,获得所述目标中间特征;和/或,
将各所述叶子节点预测编码对应的位置编码预测向量进行拼接,获得所述目标中间特征;和/或,
基于各所述树输出预测值,分别对各所述叶子节点预测编码对应的位置编码预测向量进行加权,获得各加权位置编码预测向量;
将各所述加权位置编码预测向量进行拼接,获得所述目标中间特征。
可选地,所述遍历模块还用于:
将所述待预测样本输入所述纵向联邦决策树,并开始遍历所述纵向联邦决策树,以判断所述纵向联邦决策树的根节点的归属;
若所述根节点属于第二设备,则向所述第二设备发送预测请求,并接收所述第二设备反馈的反馈结果,以基于所述反馈结果确定所述待预测样本的所属孩子节点;
判断所述所属孩子节点是否属于叶子节点类型,若所述所属孩子节点属于所述叶子节点类型,则将所述所属孩子节点作为归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果;
若所述所属孩子节点不属于所述叶子节点类型,则继续遍历所述纵向联邦决策树,直至确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果;
若所述根节点属于所述第一设备,则基于所述第一设备中的特征分裂值,确定所述待预测样本的所述所属孩子节点,以确定所述待预测样本对应的归属叶子节点,并获取所述归属叶子节点对应的所述树输出预测结果。
本申请样本预测装置的具体实施方式与上述样本预测方法各实施例基本相同,在此不再赘述。
本申请实施例提供了一种可读存储介质,且所述可读存储介质存储有一个或者一个以上程序,所述一个或者一个以上程序还可被一个或者一个以上的处理器执行以用于实现上述任一项所述的模型构建优化方法的步骤。
本申请可读存储介质具体实施方式与上述模型构建优化方法各实施例基本相同,在此不再赘述。
本申请实施例提供了一种可读存储介质,且所述可读存储介质存储有一个或者一个以上程序,所述一个或者一个以上程序还可被一个或者一个以上的处理器执行以用于实现上述任一项所述的样本预测方法的步骤。
本申请可读存储介质具体实施方式与上述样本预测方法各实施例基本相同,在此不再赘述。
本申请实施例提供了一种计算机程序产品,且所述计算机程序产品包括有一个或者一个以上计算机程序,所述一个或者一个以上计算机程序还可被一个或者一个以上的处理器执行以用于实现上述任一项所述的模型构建优化方法的步骤。
本申请计算机程序产品具体实施方式与上述模型构建优化方法各实施例基本相同,在此不再赘述。
本申请实施例提供了一种计算机程序产品,且所述计算机程序产品包括有一个或者一个以上计算机程序,所述一个或者一个以上计算机程序还可被一个或者一个以上的处理器执行以用于实现上述任一项所述的样本预测方法的步骤。
本申请计算机程序产品具体实施方式与上述样本预测方法各实施例基本相同,在此不再赘述。
以上仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利处理范围内。
- 模型构建优化方法、设备、介质及计算机程序产品
- 模型构建优化方法、设备、介质及计算机程序产品