基于非开挖泥浆流变参数弱监督机器学习的地层识别方法
文献发布时间:2023-06-19 11:42:32
技术领域
本发明涉及计算机辅助设计技术领域,特别涉及基于非开挖泥浆流变参数弱监督机器学习的地层识别方法。
背景技术
对非开挖掘进段地层岩性信息的精准掌控是能够保障安全施工的重要手段。
在非开挖施工时,施工位置常处于城区,难以进行精准工程勘察,在施工前获取掘进段地层岩性准确信息更是无从可知,导致非开挖掘进处于“摸黑”状态。与地层岩性配伍性差的钻具,更是难以高效掘进。与地层岩性配伍性差的非开挖泥浆,无法平衡地层压力,没有足够的润滑性,导致掘进效率低,孔壁失稳等问题。
钻遇不同地层,钻屑污染导致标准比对泥浆流变性产生变化。含盐地层钻屑会导致泥浆中膨润土水化颗粒双电层压缩,水土分层,粘度降低。水敏性地层钻屑包涵水敏性矿物会导致泥浆粘度有所上涨。卵砾石地层钻屑比重大,导致泥浆密度有所上涨。
非开挖施工难以知晓掘进段地层信息的问题在于两点:施工工期紧张,而且尚未有与之配套的前期勘探。
非开挖施工难以知晓掘进段地层信息的根本原因在于非开挖施工地点处于城区,为保持城市交通畅通与市容整洁,非开挖施工工期紧张,无法预留足够前期地质勘探时间,地层岩土信息难以获取。而非开挖在同种地层中掘进时,其泥浆流变参数具有一定的统计学特征,比如非开挖在硬岩地层掘进,在相同泥浆方案条件下其返浆密度较大、塑性粘度较高。
因此,如何解决非开挖施工缺乏地质信息保障问题,如何对泥浆流变参数进行识别,解析出数据采集处的地层信息成为本领域技术人员急需解决的技术问题。
发明内容
有鉴于现有技术的上述缺陷,本发明提供基于非开挖泥浆流变参数弱监督机器学习的地层识别方法,实现的目的是通过大量收集不同地层的泥浆流变参数,利用KNN-SVM算法进行分类分析,获得地层识别模型,再对泥浆流变参数使用弱监督机器学习解决地层识别问题,在地层识别模型识别正确率高的前提下进行地层识别,拥有着极高的识别率。
为实现上述目的,本发明公开了基于非开挖泥浆流变参数弱监督机器学习的地层识别方法;步骤如下:
步骤1、在数据采集层,采集已知地层的大量泥浆流变参数样本,然后提取出具有优秀品质的若干所述泥浆流变参数样本作为样本参数;
步骤2、利用KNN算法,将所述已知地层的带有标签的泥浆流变数据传递给未知地层,扩大带有所述标签的所述泥浆流变数据的数量;
步骤3、在统计性特征提取层,从扩大后的带有所述标签的所述泥浆流变数据中获取所述已知地层的泥浆流变参数,提取出所述已知地层的所述泥浆流变参数的统计性特征;
步骤4、在建模数据备份层,将所述已知地层的所述泥浆流变参数的所述统计性特征作为建模数据进行备份,形成备份数据;
步骤5、在弱监督机器学习模型层,通过所述统计性特征提取层的所述统计性特征和所述建模数据备份层的所述备份数据,使用SVM算法进行地层识别模型,即KNN-SVM模型的建立,然后对所述KNN-SVM模型的识别正确率进行验证;
步骤6、提取所需识别地层的所述统计性特征,使用所述KNN-SVM模型,对所需识别地层进行识别。
优选的,具有优秀品质的每一所述泥浆流变参数样本的提取方法如下:
首先,对相应的所述泥浆流变参数样本进行数据清洗及标准化;
然后,将被数据清洗及标准化后的每一所述泥浆流变参数样本经过皮尔逊相关系数处理;
再,筛选相关系数大于0.5的每一所述泥浆流变参数样本即为具有优秀品质的所述泥浆流变参数样本;
所述泥浆流变参数样本的标准化方法为z-score标准化,转化函数为:新的泥浆流变数据=(原始泥浆流变数据-均值)/标准差。
优选的,所述已知地层的带有所述标签的每一所述泥浆流变数据的所述标签均来源于勘察资料中地层岩性描述。
优选的,所述统计性特征为非开挖泥浆信息统计性特征。
更优选的,所述统计性特征包括泥浆塑性粘度PV、泥浆密度和泥浆表观粘度。
优选的,使用SVM算法进行地层识别模型,即KNN-SVM模型的建立步骤如下:
步骤5.1、从所述统计性特征提取层和所述建模数据备份层获取建模数据;
步骤5.2、设置KNN算法的K值,K从1取值到15,K值的最终确认采用交叉验证法,即将训练数据拆分成6:4两份;其中,前6份进行标签传递模型的建立,后4份进行准确率验证,对所述标签传递模型的准确率进行验证,取所述准确率最高的所述标签传递模型对应的K值;
步骤5.3、建立KNN标签传递模型,输入未知标签泥浆流变数据,获得全标签泥浆流变数据集;
步骤5.4、将所述全标签泥浆流变数据集导入SVM算法,进行地层识别模型的训练,地层识别结果包括杂填土类、粘土类、粉细砂类、砾石类和淤泥类;
步骤5.5、将建模备份数据外的已知地层泥浆流变参数导入SVM地层识别模型,对SVM地层识别模型的识别正确率进行判断,当SVM地层识别模型的识别正确率低于90%时,重新执行步骤5.4至步骤5.5,直至SVM地层识别模型正确率达到90%。
优选的,所述步骤6,提取所需识别地层的所述统计性特征,使用所述KNN-SVM模型,对所需识别地层进行识别的步骤如下:
步骤6.1、提取所需识别地层的所述统计性特征;
步骤6.2、将提取出的所述统计性特征,即泥浆流变参数作为输入数据传递给所述KNN-SVM模型;
步骤6.3、返回识别结果。
优选的,所述未知地层包括杂填土、粘土、粉细砂、砾石和淤泥。
本发明的有益效果:
本发明的应用解决了非开挖施工中难以识别非开挖掘进地层的问题,拥有很高的成长性,随着建模样本集增大,模型的精确度和可行度也会越来越高,而且时间代价低,建模数据可以被广泛的应用于各种非开挖施工中。
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
附图说明
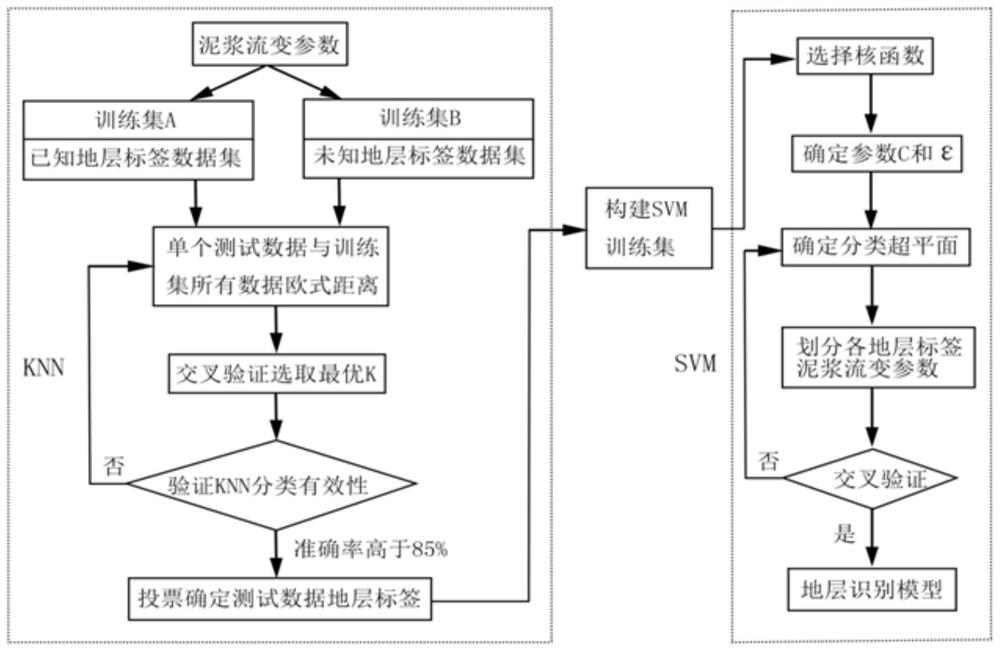
图1示出本发明一实施例的流程框架示意图。
图2示出本发明一实施例中数据处理的工作流程示意图。
图3示出本发明一实施例中机器学习建模层详细过程图。
图4示出本发明一实施例中KNN模型图。
具体实施方式
实施例1
如图1所示,基于非开挖泥浆流变参数弱监督机器学习的地层识别方法;步骤如下:
步骤1、在数据采集层,采集已知地层的大量泥浆流变参数样本,然后提取出具有优秀品质的若干泥浆流变参数样本作为样本参数;
步骤2、利用KNN算法,将已知地层的带有标签的泥浆流变数据传递给未知地层,扩大带有标签的泥浆流变数据的数量;
步骤3、在统计性特征提取层,从扩大后的带有标签的泥浆流变数据中获取已知地层的泥浆流变参数,提取出已知地层的泥浆流变参数的统计性特征;
步骤4、在建模数据备份层,将已知地层的泥浆流变参数的统计性特征作为建模数据进行备份,形成备份数据;
步骤5、在弱监督机器学习模型层,通过统计性特征提取层的统计性特征和建模数据备份层的备份数据,使用SVM算法进行地层识别模型,即KNN-SVM模型的建立,然后对KNN-SVM模型的识别正确率进行验证;
步骤6、提取所需识别地层的统计性特征,使用KNN-SVM模型,对所需识别地层进行识别。
本发明的原理如下:
本发明通过泥浆性能检测系统获取导向阶段已知地层的泥浆性能参数,利用KNN算法对所有泥浆性能参数建立标签,支持向量机机器学习形成地层岩性识别模型。
然后,将未知地层泥浆性能参数导入地层岩性识别模型得到地层岩性信息,以调整非开挖泥浆性能及钻进工艺是非开挖掘进不可或缺技术,这对于非开挖的高效安全掘进具有重要意义。
本发明通过大量收集不同地层的泥浆流变参数,并通过KNN-SVM算法对其进行分类分析,即可获得地层识别模型。
本发明使用弱监督机器学习建模的方法,对泥浆流变参数进行分类分析,弱监督机器学习建模的识别方法拥有更高的合理性和可信度。
在实际应用中,可选用多种统计性特征作为地层识别特征,并将KNN算法和SVM算法联合使用作为弱监督机器学习算法。
技术框架包含了泥浆流变数据采集,地层特征提取,建模数据备份,弱监督机器学习建模,地层识别这五个模块。泥浆流变数据采集的对象是非开挖导向段返排泥浆参数。
本发明通过提取数据样本中统计性特征,建立KNN-SVM模型,在模型识别正确率高的前提下进行地层识别,拥有着极高的识别率。
在某些实施例中,具有优秀品质的每一泥浆流变参数样本的提取方法如下:
首先,对相应的泥浆流变参数样本进行数据清洗及标准化;
然后,将被数据清洗及标准化后的每一泥浆流变参数样本经过皮尔逊相关系数处理;
再,筛选相关系数大于0.5的每一泥浆流变参数样本即为具有优秀品质的泥浆流变参数样本;
泥浆流变参数样本的标准化方法为z-score标准化,转化函数为:新的泥浆流变数据=(原始泥浆流变数据-均值)/标准差。
在某些实施例中,已知地层的带有标签的每一泥浆流变数据的标签均来源于勘察资料中地层岩性描述。
在某些实施例中,统计性特征为非开挖泥浆信息统计性特征。
在某些实施例中,统计性特征包括泥浆塑性粘度PV、泥浆密度和泥浆表观粘度。
在某些实施例中,使用SVM算法进行地层识别模型,即KNN-SVM模型的建立步骤如下:
步骤5.1、从统计性特征提取层和建模数据备份层获取建模数据;
步骤5.2、设置KNN算法的K值,K从1取值到15,K值的最终确认采用交叉验证法,即将训练数据拆分成6:4两份;其中,前6份进行标签传递模型的建立,后4份进行准确率验证,对标签传递模型的准确率进行验证,取准确率最高的标签传递模型对应的K值;
步骤5.3、建立KNN标签传递模型,输入未知标签泥浆流变数据,获得全标签泥浆流变数据集;
步骤5.4、将全标签泥浆流变数据集导入SVM算法,进行地层识别模型的训练,地层识别结果包括杂填土类、粘土类、粉细砂类、砾石类和淤泥类;
步骤5.5、将建模备份数据外的已知地层泥浆流变参数导入SVM地层识别模型,对SVM地层识别模型的识别正确率进行判断,当SVM地层识别模型的识别正确率低于90%时,重新执行步骤5.4至步骤5.5,直至SVM地层识别模型正确率达到90%。
在某些实施例中,步骤6,提取所需识别地层的统计性特征,使用KNN-SVM模型,对所需识别地层进行识别的步骤如下:
步骤6.1、提取所需识别地层的统计性特征;
步骤6.2、将提取出的统计性特征,即泥浆流变参数作为输入数据传递给KNN-SVM模型;
步骤6.3、返回识别结果。
在某些实施例中,未知地层包括杂填土、粘土、粉细砂、砾石和淤泥。
实施例2
以如图1所示技术框架图,采用分层模型框架;不同层有独立功能,每一层的数据输入源自上一层的数据输出,顶部的非开挖泥浆检测系统采集非开挖导向段返排泥浆参数,应用z-score和皮尔逊相关系数对所取得数据进行标准化处理,并备份导入泥浆流变参数样本空间。KNN算法的数据输入可直接应用泥浆流变参数样本空间数据,扩大有标签泥浆流变数据,再应用SVM算法对标签地层进行分类,得到地层识别模型,具体如下:
步骤1、在数据采集层,采集大量已知地层的泥浆流变参数样本,提取出其中具有优秀品质的泥浆流变参数作为样本数据;
已知地层为非开挖掘进路线中经过前期勘探的地层,并有详细地层参数与地层标签;泥浆流变参数为非开挖钻机掘进导向段已知地层时的返排泥浆流变参数,通过泥浆检测系统自动采集;
如图2所示,泥浆流变参数样本的质量对于建模质量的影响非常高,因此在样本空间建立前,将会对泥浆流变数据进行一次筛选,剔除异常数据,并对不同类数据进行标准化处理,提取其中优质的相关度高的数据作为建模样本。
是对随钻参数样本先进行z-score标准化,标准化后的泥浆流变数据再经过皮尔逊相关系数处理后,筛选的相关系数大于0.5的泥浆流变参数即为具有优秀品质的随钻参数,其中,z-score转化函数为“新的泥浆流变数据=(原始泥浆流变数据-均值)/标准差”。
在对采集的泥浆流变数据进行筛选后,将最终优秀的泥浆流变数据进行样本分别存储,基于KNN-SVM算法弱监督机器学习的特性,区分存储便于对泥浆流变数据进行标签。
步骤2、K近邻算法是在一组已知地层标签泥浆流变数据中寻找一个或者若干个与当前泥浆流变数据最相似数据,并将其地层标签传递给当前泥浆流变数据。该算法基于实例惰性学习,无需额外数据描述规则。在分类过程中,KNN算法直接利用样本间关系,有极高的鲁棒性。将步骤1中缺乏地层标签样本数据导入KNN算法中,实现地层标签传递,扩容有标签数据量。如图4所示KNN标签传递示意图;
步骤3、在统计性特征提取层,从步骤2中的样本数据获取已知地层的泥浆流变参数,提取出已知地层泥浆流变参数的统计性特征;本发明提取的特征一共有3种,请参考表1,所提取的已知地层泥浆流变参数的统计性特征包括3种非开挖泥浆信息统计性特征;的3种非开挖泥浆信息统计性特征包括泥浆塑性粘度PV、泥浆表观粘度AV、泥浆密度;统计性特征提取结束后,会备份作为下一次建模的建模数据。
表1中有12种特征为地层识别模型统计性特征,主要为非开挖泥浆参数这类相关。
表1所需提取的3种随钻特征列举
步骤4、在建模数据备份层,将步骤3提取出的已知地层泥浆流变参数统计性特征作为建模数据进行备份;
步骤5、在弱监督机器学习模型层,读取步骤3中统计性特征提取层的数据和步骤4的建模数据备份层的数据,使用SVM算法进行SVM模型建立,并对SVM模型识别正确率进行验证;如图3所示,具体如下:
将特征选择后的泥浆流变参数与地层数据读入程序,通过6:4划分法划分已有数据为样本集与测试集。选择所有数据中的60%数据为训练集进行SVM模型的训练,40%的数据作为测试集来检验SVM模型的准确度。将训练数据读入模型进行SVM的训练。SVM模型训练完毕后将训练集样本数据进行测试得到训练样本在模型上的准确度。再将测试集数据带入模型进行运行得到测试集在模型中的预测结果,输出测试集使用模型进行预测的精度。最后将所有数据代入模型中预测,得到整体数据的一个预测精度。在模型中输出训练集精度、测试集精度与整体数据的精度,输出训练集精度和输出测试集精度是为了当模型整体精度较低时能推断出是过拟合还是欠拟合导致的模型效果较差。输出整体数据集的精度是为了能选择最好精度的模型,并且当模型精度在90%以下时会重复进行训练,当模型精度达到90%以上时才会输出模型。
步骤6、提取所需识别地层的统计性特征,使用步骤5建立好的模型,对未知地层进行识别;具体包括如下步骤:
步骤6.1、提取所需识别地层的统计性特征,包括3种非开挖泥浆信息统计性特征;
步骤6.2、将提取出的统计性特征即泥浆流变参数作为输入传递给所建立的KNN-SVM模型;
步骤6.3、模型最后返回识别结果。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 基于非开挖泥浆流变参数弱监督机器学习的地层识别方法
- 基于非监督机器学习的CNG加气子站异常加气行为识别方法