用于客户端和服务器的模块化GPU体系结构
文献发布时间:2023-06-19 19:27:02
技术领域
本公开总体上关于数据处理,并且更具体地关于经由通用图形处理单元进行的数据处理。
背景技术
可以通过设计包括所有部件的超集的客户端或服务器体系结构并随后是部分故障或性能较低的产品装入不同的细分产品,来针对图形产品设备执行产品类别内的产品市场细分。相应地,在给定的体系结构世代内,不同层级或分类的产品在体系结构上可能是类似的、具有不同的存储器量或处理资源量。然而,一般而言,被设计成用于在服务器设备中使用的图形产品将具有与被设计成用于客户端设备的产品不同的核心体系结构。另外,针对细分客户端和细分服务器可使用不同的软件组织,即使对于预期执行类似功能的部件也是如此。
附图说明
在所附附图中以示例方式而非限制方式来图示本发明,在附图中,类似的附图标记指示类似的要素,其中:
图1是图示配置成用于实现本文中描述的实施例的一个或多个方面的计算机系统的框图;
图2A-图2D图示并行处理器部件;
图3A-图3C是图形多处理器和基于多处理器的GPU的框图;
图4A-图4F图示在其中多个GPU通信地耦合至多个多核心处理器的示例性体系结构;
图5图示图形处理管线;
图6图示机器学习软件栈;
图7图示通用图形处理单元;
图8图示多GPU计算系统;
图9A-图9B图示示例性深度神经网络的层;
图10图示示例性循环神经网络;
图11图示深度神经网络的训练和部署;
图12A是图示分布式学习的框图;
图12B是图示可编程网络接口和数据处理单元的框图;
图13图示适于使用经训练的模型执行推断的示例性推断片上系统(system on achip,SOC);
图14是处理系统的框图;
图15A-图15C图示计算系统和图形处理器;
图16A-图16C图示附加的图形处理器和计算加速器体系结构的框图;
图17是图形处理器的图形处理引擎的框图;
图18A-图18B图示包括在图形处理器核心中采用的处理元件的阵列的线程执行逻辑;
图19图示附加执行单元;
图20是图示图形处理器指令格式的框图;
图21是附加的图形处理器体系结构的框图;
图22A-图22B图示图形处理器命令格式和命令序列;
图23图示用于数据处理系统的示例性图形软件体系结构;
图24A是图示IP核心开发系统的框图;
图24B图示集成电路封装组件的横截面侧视图;
图24C图示封装组件,该封装组件包括连接到衬底的多个单元的硬件逻辑小芯片(例如,基础管芯);
图24D图示包括可互换小芯片的封装组件;
图25是图示示例性片上系统集成电路的框图;
图26A-图26B是图示用于在SoC内使用的示例性图形处理器的框图;
图27图示根据本文中所描述的实施例的、用于客户端和服务器的模块化GPU体系结构;
图28图示根据实施例的模块化图形核心集群;
图29是根据实施例的模块化图形处理器的片的框图;
图30图示根据实施例的单片客户端图形SoC;
图31图示根据实施例的多片客户端图形SoC;
图32图示根据实施例的可缩放多板服务器图形处理器;
图33图示根据实施例的、具有多片图形SoC的可缩放多板服务器图形处理器;
图34图示根据实施例的用于模块化图形SoC的可互换小芯片系统;
图35图示根据实施例的、用于配置用于模块化图形SoC的组件集合的方法;以及
图36是根据实施例的包括图形处理器的计算设备的框图。
具体实施方式
图形处理单元(graphics processing unit,GPU)通信地耦合至主机/处理器核心以加速例如图形操作、机器学习操作、模式分析操作、和/或各种通用GPU(general-purposeGPU,GPGPU)功能。GPU可通过总线或另一互连(例如,诸如PCIe或NVLink之类的高速互连)通信地耦合至主机处理器/核心。替代地,GPU可集成在与核心相同的封装或芯片上,并且通过内部处理器总线/互连(即,在封装或芯片内部)通信地耦合至核心。无论GPU被连接所采取的方式如何,处理器核心都可将工作以工作描述符中所包含的命令/指令序列的形式分配给GPU。GPU随后使用专用电路/逻辑来高效地处理这些命令/指令。
当前的并行图形数据处理包括被开发成对图形数据执行特定操作的系统和方法,这些特定操作诸如例如,线性内插、曲面细分、栅格化、纹理映射、深度测试等。传统意义上而言,图形处理器使用固定功能计算单元来处理图形数据。然而,更最近地,已使图形处理器的多个部分可编程,使得此类处理器能够支持更广泛种类的操作以处理顶点数据和片段数据。
为了进一步提升性能,图形处理器典型地实现诸如管线化的处理技术,这些处理技术尝试贯穿图形管线的不同部分并行地处理尽可能多的图形数据。具有单指令多线程(single instruction,multiple thread,SIMT)体系结构的并行图形处理器被设计成使图形管线中的并行处理的量最大化。在SIMT体系结构中,成组的并行线程尝试尽可能频繁地一起同步地执行程序指令以提高处理效率。可在Shane Cook的“CUDA编程”第3章第37-51页(2013年)中找到用于SIMT体系结构的软件和硬件的总体概述。
本文中所描述的是可经由对模块化且可缩放的片上系统集成电路(system on achip integrated circuit,SoC)的使用而跨客户端(入门、主流、发烧友)和服务器(高性能计算、机器学习、媒体)可缩放的分立的图形处理体系结构。可以基于目标产品类别和预期细分市场来选择图形SoC的各种模块。例如,可以基于为产品选择的存储器技术和产品的预期用例来选择不同类型的模块。随后,可以将所选择的模块封装和组装到跨产品类别和细分市场的各种终端产品中。
在以下描述中,陈述了众多特定细节以提供更透彻的理解。然而,对于本领域的技术人员将显而易见的是,可以在没有这些特定细节中的一个或多个细节的情况下实践本文中描述的实施例。在其他实例中,未描述公知的特征以免混淆当前实施例的细节。
系统概览
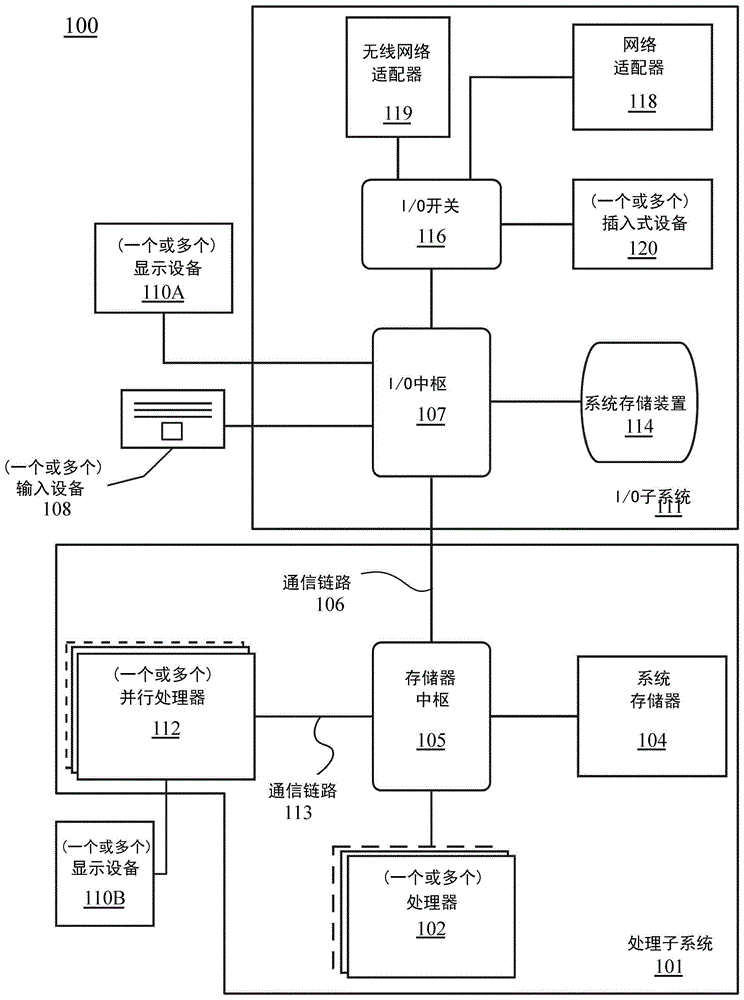
图1是图示配置成用于实现本文中描述的实施例的一个或多个方面的计算系统100的框图。计算系统100包括处理子系统101,该处理子系统具有经由互连路径通信的一个或多个处理器102和系统存储器104,该互连路径可包括存储器中枢105。存储器中枢105可以是芯片组部件内的单独部件,或者可被集成在一个或多个处理器102内。存储器中枢105经由通信链路106与I/O子系统111耦合。I/O子系统111包括I/O中枢107,该I/O中枢107可使计算系统100能够从一个或多个输入设备108接收输入。此外,I/O中枢107可使显示控制器(其可被包括在一个或多个处理器102中)将输出提供给一个或多个显示设备110A。在一个实施例中,与I/O中枢107耦合的一个或多个显示设备110A可包括本地的、内部的、或嵌入式的显示设备。
处理子系统101例如包括经由总线或其他通信链路113耦合至存储器中枢105的一个或多个并行处理器112。通信链路113可以是任何数量的基于标准的通信链路技术或协议中的一种,诸如但不限于PCI快速(PCI Express),或者可以是供应方特定的通信接口或通信结构(fabric)。一个或多个并行处理器112可形成可包括大量处理核心和/或处理集群的计算集中的并行或向量处理系统,诸如,集成众核心(many integrated core,MIC)处理器。例如,一个或多个并行处理器112形成图形处理子系统,该图形处理子系统可以向经由I/O中枢107耦合的一个或多个显示设备110A中的一个显示设备输出像素。一个或多个并行处理器112还可包括显示控制器和显示接口(未示出),用于启用至一个或多个显示设备110B的直接连接。
在I/O子系统111内,系统存储单元114可连接到I/O中枢107,从而为计算系统100提供存储机制。I/O开关116可用于提供接口机制,以启用I/O中枢107与其他部件之间的连接,其他部件诸如,可被集成到平台中的网络适配器118和/或无线网络适配器119、以及可经由一个或多个插入式设备120而被添加的各种其他设备。(一个或多个)插入式设备120还可包括例如一个或多个外部图形处理器设备、图形卡、和/或计算加速器。网络适配器118可以是以太网适配器或另一有线网络适配器。无线网络适配器119可包括以下一者或多者:Wi-Fi、蓝牙、近场通信(near field communication,NFC)、或包括一个或多个无线的无线电装置的其他网络设备。
计算系统100可包括未显式地示出的其他部件,包括USB或其他端口连接、光学存储驱动器、视频捕捉设备等等,这些部件也可连接到I/O中枢107。将图1中的各种部件互连的通信路径可使用任何合适的协议来实现,合适的协议诸如,基于PCI(PeripheralComponent Interconnect,外围部件互连)的协议(例如,PCI-Express)、或任何其他总线或点到点通信接口和/或(多种)协议,诸如,NVLink高速互连、计算快捷链路
一个或多个并行处理器112可包含针对图形和视频处理进行优化的电路(包括例如,视频输出电路),并构成图形处理单元(graphics processing unit,GPU)。替代地或附加地,本文中更详细地所描述,一个或多个并行处理器112可包含针对通用处理进行优化同时保留底层计算体系结构的电路。计算系统100的部件可与一个或多个其他系统元件集成在单个集成电路上。例如,一个或多个并行处理器112、存储器中枢105、(一个或多个)处理器102、以及I/O中枢107可被集成到片上系统(system on chip,SoC)集成电路中。替代地,计算系统100的部件可被集成到单个封装中以形成系统级封装(system in package,SIP)配置。在一个实施例中,计算系统100的部件的至少部分可被集成到多芯片模块(multi-chip module,MCM)中,该MCM可与其他多芯片模块一起被互连到模块化计算系统中。
将领会,本文中所示出的计算系统100是说明性的,并且变体和修改是可能的。可根据需要修改连接拓扑,包括桥接器的数量和布置、(一个或多个)处理器102的数量、以及(一个或多个)并行处理器112的数量。例如,系统存储器104可直接而不是通过桥接器连接到(一个或多个)处理器102,而其他设备经由存储器中枢105和(一个或多个)处理器102与系统存储器104通信。在其他替代拓扑中,(一个或多个)并行处理器连接到I/O中枢107或直接连接到一个或多个处理器102中的一个处理器,而不是连接到存储器中枢105。在其他实施例中,I/O中枢107和存储器中枢105可集成到单个芯片中。两组或更多组处理器102经由多个插槽被附连也是可能的,多个插槽可与(一个或多个)并行处理器112的两个或更多个实例耦合。
本文中所示出的特定部件中的一些是任选的,并且可以是并非在计算系统100的所有实现方式中都包括这些部件。例如,可支持任何数量的插入式卡或外围设备,或者可消除一些部件。此外,一些体系结构可针对与图1中所图示的那些部件类似的部件使用不同的术语。例如,存储器中枢105在一些体系结构中可被称为北桥,而I/O中枢107可被称为南桥。
图2A图示并行处理器200。并行处理器200可以是如本文中所述的GPU、GPGPU等。并行处理器200的各种部分可使用一个或多个集成电路器件来实现,一个或多个集成电路器件诸如,可编程处理器、专用集成电路(application specific integrated circuit,ASIC)、或现场可编程门阵列(field programmable gate array,FPGA)。所图示的并行处理器200可以是图1中示出的(一个或多个)并行处理器112中的一个或多个。
并行处理器200包括并行处理单元202。并行处理单元包括启用与其他设备的通信的I/O单元204,其他设备包括并行处理单元202的其他实例。I/O单元可直接连接到其他设备。例如,I/O单元204通过使用中枢或开关接口(诸如,存储器中枢105)与其他设备连接。存储器中枢105与I/O单元204之间的连接形成通信链路113。在并行处理单元202内,I/O单元204与主机接口206以及存储器交叉开关216连接,其中,主机接口206接收涉及执行处理操作的命令,并且存储器交叉开关216接收涉及执行存储器操作的命令。
当主机接口206经由I/O单元204接收命令缓冲器时,主机接口206可以将用于执行那些命令的工作操作引导至前端208。在一个实施例中,前端208与调度器210耦合,该调度器210配置成用于将命令或其它工作项目分发给处理集群阵列212。调度器210确保在任务被分发给处理集群阵列212中的处理集群之前,处理集群阵列212被适当地配置并且处于有效状态。调度器210可经由在微控制器上执行的固件逻辑来实现。微控制器实现的调度器210可被配置成以粗粒度和细粒度执行复杂的调度和工作分发操作,从而实现对在处理阵列212上执行的线程的快速抢占和上下文切换。优选地,主机软件可以经由多个图形处理门铃中的一个来证实用于在处理集群阵列212上调度的工作负载。在其他示例中,可使用对新工作负载或中断的轮询来标识或指示要执行的工作的可用性。工作负载随后可由调度器微控制器内的调度器210逻辑跨处理集群阵列212自动地分发。
处理集群阵列212可以包括最多“N”个处理集群(例如,集群214A、集群214B至集群214N)。处理集群阵列212中的每个集群214A-214N可执行大量的并发线程。调度器210可以使用各种调度和/或工作分发算法将工作分配给处理集群阵列212中的集群214A-214N,这些调度和/或工作分发算法可取决于针对每种类型的程序或计算出现的工作负载而变化。调度可以由调度器210动态地处置,或可以在对于被配置成供处理集群阵列212执行的程序逻辑的编译期间部分地由编译器逻辑辅助。任选地,处理集群阵列212中的不同的集群214A-214N可以被分配用于处理不同类型的程序或用于执行不同类型的计算。
处理集群阵列212可以配置成用于执行各种类型的并行处理操作。例如,处理集群阵列212被配置成用于执行通用并行计算操作。例如,处理集群阵列212可包括用于执行处理任务的逻辑,这些处理任务包括视频和/或音频数据的过滤、执行包括物理操作的建模操作、以及执行数据变换。
处理集群阵列212配置成用于执行并行图形处理操作。在其中并行处理器200被配置成用于执行图形处理操作的此类实施例中,处理集群阵列212可包括用于支持此类图形处理操作的执行的附加逻辑,包括但不限于用于执行纹理操作的纹理采样逻辑、以及曲面细分逻辑和其他顶点处理逻辑。此外,处理集群阵列212可被配置成执行图形处理相关的着色器程序,诸如但不限于顶点着色器、曲面细分着色器、几何着色器和像素着色器。并行处理单元202可以经由I/O单元204从系统存储器传输数据以供处理。在处理期间,可在处理期间将所传输的数据存储到片上存储器(例如,并行处理器存储器222),随后将该数据写回到系统存储器。
在其中使用并行处理单元202来执行图形处理的实施例中,调度器210可被配置成用于将处理工作负载分成近似相等大小的任务,以更好地实现图形处理操作向处理集群阵列212中的多个集群214A-214N的分发。在这些实施例中的一些实施例中,处理集群阵列212的部分可被配置成用于执行不同类型的处理。例如,第一部分可被配置成用于执行顶点着色和拓扑生成,第二部分可被配置成用于执行曲面细分和几何着色,并且第三部分可被配置成用于执行像素着色或其他屏幕空间操作,以产生用于显示的经渲染的图像。由集群214A-214N中的一个或多个产生的中间数据可被存储在缓冲器中,以允许中间数据在集群214A-214N之间被传送以用于进一步处理。
在操作期间,处理集群阵列212可以经由调度器210接收要被执行的处理任务,该调度器210从前端208接收定义处理任务的命令。对于图形处理操作,处理任务可包括要被处理的数据以及定义将如何处理该数据(例如,将执行什么程序)的状态参数和命令的索引,该数据例如,表面(补片(patch))数据、基元数据、顶点数据和/或像素数据。调度器210可被配置成用于取得(fetch)与任务对应的索引,或者可从前端208接收索引。前端208可被配置成用于确保在由传入命令缓冲器(例如,批量缓冲器、推入缓冲器等)指定的工作负载被发起之前处理集群阵列212被配置成有效状态。
并行处理单元202的一个或多个实例中的每个实例可以与并行处理器存储器222耦合。可以经由存储器交叉开关216来访问并行处理器存储器222,该存储器交叉开关216可以接收来自处理集群阵列212以及I/O单元204的存储器请求。存储器交叉开关216可经由存储器接口218来访问并行处理器存储器222。存储器接口218可包括各自可耦合至并行处理器存储器222的部分(例如,存储器单元)的多个分区单元(例如,分区单元220A、分区单元220B、直到分区单元220N)。分区单元220A-220N的数量可被配置成等于存储器单元的数量,使得第一分区单元220A具有对应的第一存储器单元224A,第二分区单元220B具有对应的存储器单元224B,并且第N分区单元220N具有对应的第N存储器单元224N。在其他实施例中,分区单元220A-220N的数量可以不等于存储器设备的数量。
存储器单元224A-224N可以包括各种类型的存储器设备,包括动态随机存取存储器(dynamic random-access memory,DRAM)或图形随机存取存储器,诸如,同步图形随机存取存储器(synchronous graphics random access memory,SGRAM),包括图形双倍数据速率(graphics double data rate,GDDR)存储器。任选地,存储器单元224A-224N还可包括3D堆叠式存储器,包括但不限于高带宽存储器(high bandwidth memory,HBM)。本领域技术人员将领会,存储器单元224A-224N的具体实现方式可有所不同,并且可从各种常规设计中的一个常规设计选择。诸如帧缓冲器或纹理映射之类的渲染目标可跨存储器单元224A-224N被存储,从而允许分区单元220A-220N并行地写入每个渲染目标的部分,以高效地使用并行处理器存储器222的可用带宽。在一些实施例中,并行处理器存储器222的本地实例可被排除,以有利于利用结合本地缓存存储器的系统存储器的统一存储器设计。
任选地,处理集群阵列212中的集群214A-214N中的任一者具有处理将被写入到并行处理器存储器222内的存储器单元224A-224N中的任一者的数据的能力。存储器交叉开关216可被配置成用于将每个集群214A-214N的输出传输到任何分区单元220A-220N或传输到另一集群214A-214N,该另一集群214A-214N可对输出执行附加的处理操作。每个集群214A-214N可通过存储器交叉开关216与存储器接口218通信,以从各种外部存储器设备读取或向各种外部存储器设备写入。在具有存储器交叉开关216的实施例中的一个实施例中,存储器交叉开关216具有至存储器接口218的连接以与I/O单元204通信,并具有至并行处理器存储器222的本地实例的连接,从而使不同处理集群214A-214N内的处理单元能够与系统存储器或不在并行处理单元202本地的其他存储器通信。一般而言,存储器交叉开关216例如可以能够使用虚拟通道来分离集群214A-214N与分区单元220A-220N之间的通信量流。
尽管在并行处理器200内图示出并行处理单元202的单个实例,但可以包括并行处理单元202的任何数量的实例。例如,并行处理单元202的多个实例可以被设置在单个插入式卡上,或者多个插入式卡可以被互连。例如,并行处理器200可以是插入式设备,诸如,图1的插入式设备120,该插入式设备可以是图形卡(诸如,包括一个或多个GPU的分立的图形卡)、一个或多个存储器设备、以及设备至设备或网络或结构接口。并行处理单元202的不同实例可被配置成即便不同实例具有不同数量的处理核心、不同量的本地并行处理器存储器、和/或其他配置区别也进行互操作。任选地,并行处理单元202的一些实例相对于其他实例可包括更高精度浮点单元。包含并行处理单元202或并行处理器200的一个或多个实例的系统能以各种配置和形状因子来实现,这些配置和形状因子包括但不限于,桌面型电脑、膝上型电脑、或手持式个人计算机、服务器、工作站、游戏控制台和/或嵌入式系统。编排器可使用以下一者或多者来形成用于工作负载执行的复合节点:分解的处理器资源、缓存资源、存储器资源、存储资源、和联网资源。
图2B是分区单元220的框图。分区单元220可以是图2A的分区单元220A-220N中的一个分区单元的实例。如图所示,分区单元220包括L2缓存221、帧缓冲器接口225、和ROP226(栅格操作单元)。L2缓存221是被配置成用于执行从存储器交叉开关216和ROP 226接收的加载和存储操作的读取/写入缓存。读取未命中和紧急写回请求由L2缓存221输出到帧缓冲器接口225以用于处理。更新也可经由帧缓冲器接口225被发送到帧缓冲器以用于处理。在一个实施例中,帧缓冲器接口225与并行处理器存储器中的存储器单元(诸如,(例如,并行处理器存储器222内的)图2A的存储器单元224A-224N)中的一个存储器单元对接。分区单元220附加地或替代地还可经由存储器控制器(未示出)与并行处理器存储器中的存储器单元中的一个存储器单元对接。
在图形应用中,ROP 226是执行栅格操作(诸如,模板印制(stencil)、z测试、混合等等)的处理单元。ROP 226随后输出经处理的图形数据,该经处理的图形数据被存储在图形存储器中。在一些实施例中,ROP 226包括CODEC 227或与CODEC 227耦合,该CODEC 227包括压缩逻辑,该压缩逻辑用于对被写入存储器或L2缓存221的深度或颜色数据进行压缩,并对从存储器或L2缓存221读取的深度或颜色数据进行解压缩。压缩逻辑可以是利用多种压缩算法中的一种或多种的无损压缩逻辑。由CODEC 227执行的压缩的类型可以基于将要被压缩的数据的统计特性而变化。例如,在一个实施例中,逐片(tile)地对深度和颜色数据执行Δ颜色压缩。在一个实施例中,CODEC 227包括压缩和解压缩逻辑,该压缩和解压缩逻辑可对与机器学习操作相关联的计算数据进行压缩和解压缩。CODEC 227可例如对用于稀疏机器学习操作的稀疏矩阵数据进行压缩。CODEC 227还可对按稀疏矩阵格式(例如,坐标列表编码(COO)、压缩稀疏行(compressed sparse row,CSR)、压缩稀疏列(compress sparsecolumn,CSC)等)编码的稀疏矩阵数据进行压缩以生成经压缩且经编码的稀疏矩阵数据。经压缩且经编码的稀疏矩阵数据可在由处理元件处理之前或在处理元件能够被配置成消耗经压缩的、经编码的、或经压缩且经编码的数据以用于处理之前被解压缩和/或解码。
ROP 226可被包括在每个处理集群(例如,图2A的集群214A-214N)内而不是被包括在分区单元220内。在此类实施例中,通过存储器交叉开关216来传送对像素数据而非像素片段数据的读取和写入请求。经处理的图形数据可被显示在显示设备(诸如,图1的一个或多个显示设备110A-110B中的一个显示设备)上,被路由以用于由(一个或多个)处理器102进一步处理,或者被路由以用于由图2A的并行处理器200内的处理实体中的一个处理实体进一步处理。
图2C是并行处理单元内的处理集群214的框图。例如,处理集群是图2A的处理集群214A-214N中的一个处理集群的实例。处理集群214可被配置成用于并行地执行许多线程,其中,术语“线程”是指对特定的输入数据的集合执行的特定程序的实例。任选地,可使用单指令多数据(single-instruction,multiple-data,SIMD)指令发出技术以在不提供多个独立的指令单元的情况下支持大量线程的并行执行。替代地,可使用单指令多线程(single-instruction,multiple-thread,SIMT)技术来使用被配置成用于向处理集群中的每个处理集群内的处理引擎的集合发出指令的共同的指令单元来支持大量总体上同步的线程的并行执行。与其中所有处理引擎典型地执行相同指令的SIMD执行机制不同,SIMT执行允许不同的线程更容易地遵循通过给定的线程程序的发散的执行路径。本领域技术人员将理解,SIMD处理机制表示SIMT处理机制的功能子集。
可以经由将处理任务分发给SIMT并行处理器的管线管理器232来控制处理集群214的操作。管线管理器232接收来自图2A的调度器210的指令,并且经由图形多处理器234和/或纹理单元236来管理那些指令的执行。所图示的图形多处理器234是SIMT并行处理器的示例性实例。然而,可将不同体系结构的各种类型的SIMT并行处理器包括在处理集群214内。图形多处理器234的一个或多个实例可被包括在处理集群214内。图形多处理器234可以处理数据,并且数据交叉开关240可以用于将经处理的数据分发到多个可能的目的地中的一个目的地,多个可能的目的地包括其他着色器单元。管线管理器232可通过指定用于要经由数据交叉开关240分发的经处理的数据的目的地来促进经处理的数据的分发。
处理集群214内的每个图形多处理器234可以包括相同的功能执行逻辑集合(例如,算术逻辑单元、加载-存储单元等)。能以管线化的方式配置功能执行逻辑,按照该管线化的方式,新指令可在先前指令完成之前被发出。功能执行逻辑支持各种操作,包括整数和浮点算术、比较操作、布尔操作、比特移位、以及各种代数函数的计算。可利用相同的功能单元硬件来执行不同的操作,并且功能单元的不同组合可以存在。
被传送至处理集群214的指令构成线程。跨并行处理引擎的集合执行的线程的集合是线程组。线程组对不同的输入数据执行相同的程序。线程组内的每个线程可被指派给图形多处理器234内的不同的处理引擎。线程组可包括比图形多处理器234内的处理引擎的数量更少的线程。当线程组包括比处理引擎的数量更少的线程时,处理引擎中的一个或多个处理引擎在其间线程组正被处理的周期期间可以是空闲的。线程组也可包括比图形多处理器234内的处理引擎的数量更多的线程。当线程组包括比图形多处理器234内的处理引擎的数量更多的线程时,可在连续的时钟周期上执行处理。任选地,可在图形多处理器234上并发地执行多个线程组。
图形多处理器234可包括内部缓存存储器,以执行加载和存储操作。任选地,图形多处理器可放弃内部缓存,并使用处理集群214内的缓存存储器(例如,第一级(level 1,L1)缓存248)。每个图形多处理器234还具有对分区单元(例如,图2A的分区单元220A-220N)内的第二级(L2)缓存的访问权,这些L2缓存在所有处理集群214之间被共享,并且可被用于在线程之间传输数据。图形多处理器234还可访问芯片外全局存储器,该片外全局存储器可包括本地并行处理器存储器和/或系统存储器中的一个或多个。并行处理单元202外部的任何存储器可被用作全局存储器。在其中处理集群214包括图形多处理器234的多个实例的实施例可共享共同的指令和数据,该共同的指令和数据可被存储在L1缓存248中。
每个处理集群214可包括被配置成用于将虚拟地址映射到物理地址的MMU 245(存储器管理单元)。在其他实施例中,MMU 245的一个或多个实例可驻留在图2A的存储器接口218内。MMU 245包括用于将虚拟地址映射到片的物理地址的页表条目(page table entry,PTE)的集合,并且任选地包括缓存行索引。MMU 245可包括可驻留在图形多处理器234或L1缓存或处理集群214内的地址转译后备缓冲器(translation lookaside buffer,TLB)或缓存。物理地址被处理,以分发表面数据访问局部性,从而允许分区单元之间的高效的请求交织。缓存行索引可用于确定对缓存行的请求是命中还是未命中。
在图形和计算应用中,处理集群214可被配置以使得每个图形多处理器234耦合至纹理单元236以供执行纹理映射操作,例如,确定纹理样本位置、读取纹理数据、以及过滤纹理数据。纹理数据从内部纹理L1缓存(未示出)被读取,或者在一些实施例中,从图形多处理器234内的L1缓存被读取,并且根据需要从L2缓存、本地并行处理器存储器或系统存储器被取得。每个图形多处理器234将经处理的任务输出到数据交叉开关240,以将经处理器的任务提供给另一处理集群214以进行进一步处理,或经由存储器交叉开关216将经处理的任务存储在L2缓存、本地并行处理器存储器、或系统存储器中。preROP 242(pre-rasteroperations unit,预先栅格操作单元)被配置成用于从图形多处理器234接收数据,将数据引导至ROP单元,这些ROP单元可与如本文中所描述的分区单元(例如,图2A的分区单元220A-220N)一起被定位。preROP 242单元可针对颜色混合执行优化,组织像素颜色数据,并且执行地址转换。
将领会,本文中所描述的核心体系结构是说明性的,并且变体和修改是可能的。可将任何数量的处理单元(例如,图形多处理器234、纹理单元236、preROP 242等)包括在处理集群214内。进一步地,虽然示出仅一个处理集群214,但是如本文中所描述的并行处理单元可包括处理集群214的任何数量的实例。任选地,每个处理集群214可被配置成用于使用单独且不同的处理单元、L1缓存、L2缓存等来独立于其他处理集群214进行操作。
图2D示出图形多处理器234的示例,其中图形多处理器234与处理集群214的管线管理器232耦合。图形多处理器234具有执行管线,该执行管线包括但不限于指令缓存252、指令单元254、地址映射单元256、寄存器堆258、一个或多个通用图形处理单元(generalpurpose graphics processing unit,GPGPU)核心262、以及一个或多个加载/存储单元266。GPGPU核心262和/或加载/存储单元266经由存储器和缓存互连268与缓存存储器272和共享存储器270耦合。图形多处理器234可附加地包括张量/或光线追踪核心263,该张量和/或光线追踪核心263包括用于加速矩阵和/或光线追踪操作的硬件逻辑。
指令缓存252可从管线管理器232接收要执行的指令流。指令可被缓存在指令缓存252中,并且被调遣以供由指令单元254执行。指令单元254可以将指令作为线程组(例如,单元组(warp))进行调遣,其中,线程组中的每个线程被指派给GPGPU核心262内的不同的执行单元。指令可通过指定统一地址空间内的地址来访问本地地址空间、共享地址空间或全局地址空间中的任一者。可以使用地址映射单元256将统一地址空间中的地址转换为可以由加载/存储单元266访问的不同的存储器地址。
寄存器堆258为图形多处理器234的功能单元提供寄存器的集合。寄存器堆258为连接到图形多处理器234的功能单元(例如,GPGPU核心262、加载/存储单元266)的功能单元的数据路径的操作对象提供临时存储。寄存器堆258可在功能单元中的每个功能单元之间进行划分,使得每个功能单元被分配寄存器堆258的专用部分。例如,寄存器堆258可在由图形多处理器234执行的不同单元组之间进行划分。
GPGPU核心262可以各自包括用于执行图形多处理器234的指令的浮点单元(floating point unit,FPU)和/或整数算术逻辑单元(arithmetic logic unit,ALU)。在一些实现方式中,GPGPU核心262可包括能以其他方式驻留在张量和/或光线追踪核心263内的硬件逻辑。GPGPU核心262在体系结构上可以是类似的,或者在体系结构上可以是不同的。例如,并且在一个实施例中,GPGPU核心262的第一部分包括单精度FPU和整数ALU,而GPGPU核心的第二部分包括双精度FPU。任选地,FPU可实现针对浮点算术的IEEE 754-2008标准,或启用可变精度浮点算术。图形多处理器234可附加地包括用于执行特定功能的一个或多个固定功能或特殊功能单元,该特定功能诸如复制矩形或像素混合操作。GPGPU核心中的一个或多还可包括固定功能或特殊功能逻辑。
GPGPU核心262可包括能够对数据的多个集合执行单个指令的SIMD逻辑。任选地,GPGPU核心262可以物理地执行SIMD4、SIMD8和SIMD16指令,并且逻辑地执行SIMD1、SIMD2和SIMD32指令。针对GPGPU核心的SIMD指令可以由着色器编译器在编译时生成,或在执行针对单程序多数据(single program multiple data,SPMD)或SIMT体系结构而编写并且编译的程序时自动地生成。可以经由单个SIMD指令来执行被配置成用于SIMT执行模型的程序的多个线程。例如,并且在一个实施例中,可以经由单个SIMD8逻辑单元来并行地执行八个SIMT线程,这八个SIMT线程执行相同或类似的操作。
存储器和缓存互连268是将图形多处理器234的功能单元中的每个功能单元连接到寄存器堆258并连接至共享存储器270的互连网络。例如,存储器和缓存互连268是允许加载/存储单元266实现共享存储器270与寄存器堆258之间的加载和存储操作的交叉开关互连。寄存器堆258能以与GPGPU核心262相同的频率进行操作,因此GPGPU核心262与寄存器堆258之间的数据传输是非常低等待时间的。共享存储器270可用于启用在图形多处理器234的功能单元上执行的线程之间的通信。缓存存储器272可被用作数据缓存,例如,以对在功能单元与纹理单元236之间传递的纹理数据进行缓存。共享存储器270还可被用作被管理的经缓存的程序。共享存储器270和缓存存储器272可与数据交叉开关240耦合,以启用与处理集群的其他部件的通信。在GPGPU核心262上执行的线程除被存储在缓存存储器272内的被自动缓存的数据之外还能以编程方式将数据存储在共享存储器内。
图3A-图3C图示根据实施例的附加的图形多处理器。图3A-图3B图示图形多处理器325、350,它们与图2C的图形多处理器234相关,并且可替代那些图形多处理器中的一个被使用。因此,本文中结合图形多处理器234对任何特征的公开也公开了对应的与图形多处理器325、350的结合,但不限于此。图3C图示图形处理单元(graphics processing unit,GPU)380,该GPU 380包括布置为多核心组365A-365N的图形处理资源的专用集合,多核心组365A-365N与图形多处理器325、350对应。所图示的图形多处理器325、350和多核心组365A-365N可以是能够同时执行大量执行线程的流式多处理器(streaming multiprocessors,SM)。
图3A的图形多处理器325包括相对于图2D的图形多处理器234的、执行资源单元的多个附加实例。例如,图形多处理器325可包括指令单元332A-332B、寄存器堆334A-334B和(一个或多个)纹理单元344A-344B的多个实例。图形多处理器325还包括多个图形或计算执行单元的集合(例如,GPGPU核心336A-336B、张量核心337A-337B、光线追踪核心338A-338B)以及多个加载/存储单元的集合340A-340B。执行资源单元具有共同的指令缓存330、纹理和/或数据缓存存储器342、以及共享存储器346。
各部件可以经由互连结构327进行通信。互连结构327可包括一个或多个交叉开关以启用在图形多处理器325的各部件之间的通信。互连结构327是单独的、高速网络结构层,图形多处理器325的每个部件堆叠在该网络结构层上。图形多处理器325的部件经由互连结构327与远程部件通信。例如,核心336A-336B、337A-337B以及338A-338B可以各自经由互连结构327与共享存储器346通信。互连结构327可对图形多处理器325内的通信进行仲裁,以确保部件之间公平的带宽分配。
图3B的图形多处理器350包括多个执行资源的集合356A-356D,其中,如图2D和图3A中所图示,每个执行资源的集合包括多个指令单元、寄存器堆、GPGPU核心、以及加载存储单元。执行资源356A-356可与用于纹理操作的(一个或多个)纹理单元360A-360D协同地工作,同时共享指令缓存354和共享存储器353。例如,执行资源356A-356D可共享指令缓存354和共享存储器353、以及纹理和/或数据缓存存储器358A-358B的多个实例。各种部件可经由与图3A中的互连结构327类似的互连结构352进行通信。
本领域技术人员将理解,图1、图2A-图2D以及图3A-图3B中所描述的体系结构是描述性的,并且在当前实施例的范围方面不是限制性的。因此,本文中描述的技术可实现在任何经适当地配置的处理单元上而不背离本文中描述的实施例的范围,这些处理单元包括但不限于:一个或多个移动应用处理器;一个或多个桌面型电脑或服务器中央处理单元(central processing unit,CPU),包括多核心CPU;一个或多个并行处理器单元,诸如,图2A的并行处理单元202、以及一个或多个图形处理器或专用处理单元。
本文中所描述的并行处理器或GPGPU可通信地耦合至主机/处理器核心以加速图形操作、机器学习操作、模式分析操作、以及各种通用GPU(GPGPU)功能。GPU可通过总线或另一互连(例如,高速互连,诸如,PCIe、NVLink、或其他已知的协议、标准化协议、或专属协议)通信地耦合至主机处理器/核心。在其他实施例中,GPU可集成在与核心相同的封装或芯片上,并且通过内部处理器总线/互连(即,在封装或芯片内部)通信地耦合至核心。无论GPU被连接所采取的方式如何,处理器核心都可将工作以工作描述符中所包含的命令/指令序列的形式分配给GPU。GPU随后使用专用电路/逻辑来高效地处理这些命令/指令。
图3C图示图形处理单元(graphics processing unit,GPU)380,该GPU 380包括布置为多核心组365A-365N的图形处理资源的专用集合。虽然提供仅单个多核心组365A的细节,但是将领会,其他多核心组365B-365N可配备有图形处理资源的相同或类似的集合。相对于多核心组365A-365描述的细节还可应用于本文中描述的任何图形多处理器234、325、350。
如所图示,多核心组365A可包括图形核心的集合370、张量核心的集合371以及光线追踪核心的集合372。调度器/调遣器368调度和调遣图形线程以用于在各个核心370、371、372上执行。寄存器堆的集合369存储在执行图形线程时由核心370、371、372使用的操作对象值。这些寄存器堆可包括例如用于存储整数值的整数寄存器、用于存储浮点值的浮点寄存器、用于存储紧缩(packed)数据元素(整数和/或浮点数据元素)的向量寄存器以及用于存储张量/矩阵值的片寄存器。片寄存器可被实现为向量寄存器的组合集合。
一个或多个组合的第一级(L1)缓存和共享存储器单元373在本地将图形数据存储在每个多核心组365A内,图形数据诸如纹理数据、顶点数据、像素数据、光线数据、包围体数据等。一个或多个纹理单元374也可用于执行纹理操作,诸如,纹理映射和采样。由所有多核心组365A-365N或多核心组365A-365N的子集共享的第二级(L2)缓存375存储用于多个并发的图形线程的图形数据和/或指令。如所图示,可跨多个多核心组365A-365N共享L2缓存375。一个或多个存储器控制器367将GPU 380耦合至存储器366,该存储器366可以是系统存储器(例如,DRAM)和/或专用图形存储器(例如,GDDR6存储器)。
输入/输出(Input/output,I/O)电路363将GPU 380耦合至一个或多个I/O设备362,这一个或多个I/O设备362诸如数字信号处理器(digital signal processor,DSP)、网络控制器或用户输入设备。片上互连可用于将I/O设备362耦合至GPU 380和存储器366。I/O电路363的一个或多个I/O存储器管理单元(I/O memory management unit,IOMMU)364直接将I/O设备362耦合至系统存储器366。任选地,IOMMU 364管理用于将虚拟地址映射到系统存储器366中的物理地址的多个集合的页表。I/O设备362、(一个或多个)CPU 361和(一个或多个)GPU 380随后可共享相同的虚拟地址空间。
在IOMMU 364的一个实现方式中,IOMMU 364支持虚拟化。在这种情况下,IOMMU366可以管理用于将宾客/图形虚拟地址映射到宾客/图形物理地址的第一集合的页表以及用于将宾客/图形物理地址映射到(例如,系统存储器366内的)系统/主机物理地址的第二集合的页表。第一集合的页表和第二集合的页表中的每一个的基址可被存储在控制寄存器中,并且在上下文切换时被换出(例如,使得新上下文被提供有对相关集合的页表的访问权)。虽然未在图3C中图示,但是核心370、371、372和/或多核心组365A-365N中的每一个可包括转译后备缓冲器(TLB),这些TLB用于对宾客虚拟至宾客物理转换、宾客物理至主机物理转换以及宾客虚拟至主机物理转换进行缓存。
(一个或多个)CPU 361、GPU 380和I/O设备362可以被集成在单个半导体芯片和/或芯片封装上。所图示的存储器366可集成在同一芯片上,或者可经由芯片外接口被耦合至存储器控制器367。在一个实现方式中,存储器366包括共享与其他物理系统级存储器相同的虚拟地址空间的GDDR6存储器,但是本文中描述的根本性原理不限于该特定的实现方式。
张量核心371可包括专门被设计成用于执行矩阵操作的多个执行单元,这些矩阵操作是用于执行深度学习操作的基本计算操作。例如,可将同步矩阵乘法操作用于神经网络训练和推断。张量核心371可使用各种操作对象精度来执行矩阵处理,各种操作对象精度包括单精度浮点(例如,32比特)、半精度浮点(例如,16比特)、整数字(16比特)、字节(8比特)和半字节(4比特)。例如,神经网络实现方式提取每个经渲染场景的特征,从而潜在地组合来自多个帧的细节,以构建高质量的最终图像。
在深度学习实现方式中,可调度并行的矩阵乘法工作以用于在张量核心371上执行。神经网络的训练尤其需要大量矩阵点积操作。为了处理N x N x N矩阵乘法的内积公式化,张量核心371可包括至少N个点积处理元件。在矩阵乘法开始之前,一个完整的矩阵被加载到片寄存器中,并且对于N个循环中的每个循环,第二矩阵的至少一列被加载。对于每个循环,存在被处理的N个点积。
取决于特定的实现方式,能以不同精度来存储矩阵元素,包括16比特的字、8比特的字节(例如,INT8)以及4比特的半字节(例如,INT4)。可为张量核心371指定不同的精度模式以确保将最高效的精度用于不同的工作负载(例如,诸如推断工作负载,其可容忍至字节和半字节的量化(quantization))。所支持的格式附加地包括64比特浮点(64-bitfloating point,FP64)和非IEEE浮点格式,诸如,bfloat16格式(例如,Brain浮点格式)、具有一个符号比特、八个指数比特和八个有效数字比特(其中的七个被显式地存储)的16比特浮点格式。一个实施例包括对降低精度的张量浮点格式(TF32)的支持,该TF32格式具有FP32(8比特)的范围以及FP16(10比特)的精度。能以相对于FP32的更高性能以及相对于FP16的增加的精度对FP32输入执行降低精度的TF32操作并产生FP32输出。
在一个实施例中,张量核心371支持用于在其中绝大多数值为零的矩阵的稀疏操作模式。张量核心371包括对以稀疏矩阵表示(例如,坐标列表编码(COO)、压缩稀疏行(CSR)、压缩稀疏列(CSC)等)来编码的稀疏输入矩阵的支持。张量核心371还包括对在稀疏矩阵表示可被进一步压缩的情况下的压缩稀疏矩阵表示的支持。经压缩的矩阵数据、经编码的矩阵数据和/或经压缩且经编码的矩阵数据以及相关联的压缩和/或编码元数据可由张量核心371读取,并且非零值可被提取。例如,对于给定的输入矩阵A,非零值可从矩阵A的至少部分的经压缩的和/或经编码的表示来加载。基于矩阵A中非零值的位置(其可从与非零值相关联的索引或坐标元数据确定),输入矩阵B中的对应值可被加载。取决于要执行的操作(例如,乘法),如果对应的值是零值,则从输入矩阵B加载值可被绕过。在一个实施例中,对于某些操作(诸如,乘法操作)的值的配对可由调度器逻辑预扫描,并且仅非零输入之间的操作被调度。取决于矩阵A和矩阵B的维度以及要执行的操作,输出矩阵C可以是密集或稀疏的。在输出矩阵C是稀疏的情况下且取决于张量核心371的配置,输出矩阵C可以按压缩格式、稀疏编码或压缩稀疏编码被输出。
光线追踪核心372可加速用于实时光线追踪实现方式和非实时光线追踪实现方式两者的光线追踪操作。具体而言,光线追踪核心372可包括光线遍历/相交电路,该光线遍历/相交电路用于使用包围体层次体系(bounding volume hierarchy,BVH)来执行光线遍历并标识封围在BVH容体内的光线与基元之间的相交。光线追踪核心372还可包括用于执行深度测试和剔除(例如,使用Z缓冲器或类似布置)的电路。在一个实现方式中,光线追踪核心372与本文中描述的图像降噪技术协同地执行遍历和相交操作,该图像降噪技术的至少部分可在张量核心371上执行。例如,张量核心371可实现深度学习神经网络以执行对由光线追踪核心372生成的帧的降噪。然而,(一个或多个)CPU361、图形核心370和/或光线追踪核心372还可实现全部的降噪和/或深度学习算法或降噪和/或深度学习算法中的一部分。
此外,如上文所描述,可采用对于降噪的分布式方法,其中,GPU380在通过网络或高速互连而耦合至其他计算设备的计算设备中。按照该分布式方法,经互连的计算设备可共享神经网络学习/训练数据,以改善整个系统学习执行用于不同类型的图像帧和/或不同的图形应用的降噪的速度。
光线追踪核心372可处理所有的BVH遍历和/或光线-基元相交,从而使图形核心370免于被针对每条光线的数千条指令过载。例如,每个光线追踪核心372包括用于执行包围盒测试(例如,用于遍历操作)的第一集合的专业电路和/或用于执行光线-三角形相交测试(例如,使已被遍历的光线相交)的第二集合的专业电路。因此,例如,多核心组365A可简单地发起光线探测,并且光线追踪核心372独立地执行光线遍历和相交,并将命中数据(例如,命中、无命中、多个命中等)返回到线程上下文。当光线追踪核心370执行遍历和相交操作时,其他核心371、372被释放以执行其他图形或计算工作。
任选地,每个光线追踪核心372可包括用于执行BVH测试操作的遍历单元和/或执行光线-基元相交测试的相交单元。相交单元生成“命中”、“无命中”或“多个命中”响应,该相交单元将这些响应提供给适当的线程。在遍历和相交操作期间,其他核心(例如,图形核心370和张量核心371)的执行资源被释放以执行其他形式的图形工作。
在下文描述的一个任选实施例中,使用在其中工作被分布在图形核心370与光线追踪核心372之间的混合式栅格化/光线追踪方法。
光线追踪核心372(和/或其他核心370、371)可包括对光线追踪指令集的硬件支持,光线追踪指令集诸如:微软的DirectX光线追踪(DirectX Ray Tracing,DXR),其包括DispatchRays命令;以及光线生成着色器、最近命中着色器、任何命中着色器和未命中着色器,它们使得能够为每个对象指派着色器和纹理的唯一集合。可由光线追踪核心372、图形核心370和张量核心371支持的另一光线追踪平台是Vulkan 1.1.85。然而,要注意,本文中描述的根本性原理不限于任何特定的光线追踪ISA。
一般而言,各个核心372、371、370可支持包括用于以下各项中的一项或多项的指令/函数的光线追踪指令集:光线生成、最近命中、任何命中、光线-基元相交、逐基元和层次体系包围盒构建、未命中、拜访、和异常。更具体地,优选的实施例包括用于执行以下功能中的一项或多项的光线追踪指令:
光线生成
最近命中
任何命中
相交
逐基元包围盒构建
未命中
拜访
异常
在一个实施例中,光线追踪核心372可适于加速通用计算操作,这些通用计算操作可使用与光线相交测试类似的计算技术来加速。可提供计算框架,该计算框架使着色器程序能够被编译为经由光线追踪核心执行通用计算操作的低级别指令和/或基元。可受益于在光线追踪核心372上执行的计算操作的示例性计算问题包括涉及坐标空间内光束、波、光线或粒子传播的计算。可相对于坐标空间内的几何体或网格计算与那个传播相关联的交互。例如,与通过环境的电磁信号传播相关联的计算可经由使用经由光线追踪核心被执行的指令或基元来加速。信号通过环境中的对象发生的折射和反射可被计算为直接的光线追踪模拟。
光线追踪核心372还可用于执行不直接与光线追踪类似的计算。例如,可使用光线追踪核心372来加速网格投影、网格细化和体积采样计算。还可执行通用坐标空间计算,诸如,最近邻计算。例如,可通过定义坐标空间中围绕给定点的包围盒来发现该点附近的点的集合。随后可使用光线追踪核心372内的BVH和光线探测逻辑来确定包围盒内点的集合的相交。相交构成原点以及那个原点的最近邻。可并行于在图形核心372和张量核心371上执行的计算来执行使用光线追踪核心372来执行的计算。着色器编译器可被配置成将计算着色器或其他通用图形处理程序编译为能够跨图形核心370、张量核心371和光线追踪核心372被并行化的低级别基元。
用于GPU至主机处理器互连的技术
图4A图示在其中多个GPU 410-413(例如,诸如图2A中示出的并行处理器200)通过高速链路440A-440D(例如,总线、点到点互连等)通信地耦合至多个多核心处理器405-406的示例性体系结构。取决于实现方式,高速链路440A-440D可支持4GB/s、30GB/s、80GB/s或更高的通信吞吐量。可使用各种互连协议,包括但不限于PCIe 4.0或5.0和NVLink 2.0。然而,本文中描述的根本性原理不限于任何特定的通信协议或吞吐量。
GPU 410-413中的两个或更多个可通过高速链路442A-442B被互连,高速链路442A-442B可使用与针对高速链路440A-440D使用的那些协议/链路相同或不同的协议/链路来实现。类似地,多核心处理器405-406中的两个或更多个可通过高速链路443进行连接,该高速链路443可以是在20GB/s、30GB/s、120GB/s或更高速度下进行操作的对称多处理器(symmetric multi-processor,SMP)总线。替代地,图4A中示出的各种系统部件之间的所有通信可使用相同的协议/链路(例如,通过共同的互连结构)来实现。然而,如所提及,本文中描述的根本性原理不限于任何特定类型的互连技术。
多核心处理器405和多核心处理器406中的每一者可分别经由存储器互连430A-430B通信地耦合至处理器存储器401-402,并且每个GPU 410-413分别通过GPU存储器互连450A-450D通信地耦合至GPU存储器420-423。存储器互连430A-430B和450A-450D可利用相同或不同的存储器访问技术。作为示例并且不作为限制,处理器存储器401-402和GPU存储器420-423可以是诸如动态随机存取存储器(dynamic random-access memory,DRAM)(包括堆叠式DRAM)、图形DDR SDRAM(GDDR)(例如,GDDR5、GDDR6)、或高带宽存储器(HighBandwidth Memory,HBM)之类的易失性存储器,并且/或者可以是诸如3D Xpoint/Optane或Nano-Ram之类的非易失性存储器。例如,存储器的某个部分可以是易失性存储器,并且另一部分可以是非易失性存储器(例如,使用两级存储器(two-level memory,2LM)层次体系)。本文中描述的存储器子系统可与数种存储器技术兼容,这些存储器技术诸如由JEDEC(Joint Electronic Device Engineering Council,联合电子设备工程委员会)发布的双倍数据速率版本。
如下文所描述,尽管各处理器405-406和GPU 410-413可分别物理地耦合至特定的存储器401-402、420-423,但是可实现在其中同一虚拟系统地址空间(也被称为“有效地址”空间)在所有的各种物理存储器之间分布的统一存储器体系结构。例如,处理器存储器401-402各自可包括64GB的系统存储器空间,并且GPU 420-423各自可包括32GB的系统存储器地址空间(从而在该示例中产生总共256GB的可寻址存储器)。
图4B图示多核心处理器407与图形加速模块446之间的互连的附加的任选细节。图形加速模块446可包括集成在线卡上的一个或多个GPU芯片,该线卡经由高速链路440耦合至处理器407。替代地,图形加速模块446可集成在与处理器407相同的封装或芯片上。
所图示的处理器407包括多个核心460A-460D,这些核心各自具有转译后备缓冲器461A-461D以及一个或多个缓存462A-462D。核心可包括用于执行指令并处理数据的各种其他部件,未图示出这些部件以避免使本文中描述的部件的根本性原理模糊(例如,指令取得单元、分支预测单元、解码器、执行单元、重排序缓冲器等)。缓存462A-462D可包括第一级(L1)缓存和第二级(L2)缓存。此外,一个或多个共享缓存456可被包括在缓存层次体系中,并由核心的集合460A-460D共享。例如,处理器407的一个实施例包括24个核心,这些核心各自具有其自身的L1缓存、十二个共享L2缓存、以及十二个共享L3缓存。在该实施例中,L2缓存和L3缓存中的一者由两个相邻的核心共享。处理器407和图形加速器集成模块446与系统存储器441连接,该系统存储器441可包括处理器存储器401-402。
经由通过一致性总线464的核心间通信为存储在各缓存462A-462D、456和系统存储器441中的数据和指令维持一致性。例如,每个缓存可具有与其相关联的缓存一致性逻辑/电路,以响应于检测到的对特定缓存行的读取或写入而通过一致性总线464进行通信。在一个实现方式中,通过一致性总线464实现缓存监听协议,以监听缓存访问。缓存监听/一致性技术为本领域技术人员很好地理解,并且将不在此详细描述,以避免使本文中描述的根本性原理模糊。
可以提供将图形加速模块446通信地耦合至一致性总线464的代理电路425,从而允许图形加速模块446作为核心的对等方参与缓存一致性协议。具体而言,接口435提供通过高速链路440(例如,PCIe总线、NVLink等)而至代理电路425的连接性,并且接口437将图形加速模块446连接到高速链路440。
在一个实现方式中,加速器集成电路436代表图形加速模块446的多个图形处理引擎431、432、N提供缓存管理、存储器访问、上下文管理、以及中断管理服务。图形处理引擎431、432、N各自可包括分开的图形处理单元(graphics processing unit,GPU)。替代地,图形处理引擎431、432、N可包括GPU内的不同类型的图形处理引擎,诸如,图形执行单元、媒体处理引擎(例如,视频编码器/解码器)、采样器以及blit引擎。换言之,图形加速模块可以是具有多个图形处理引擎431-432、N的GPU,或者图形处理引擎431-432、N可以是集成在共同的封装、线卡或芯片上的单独的GPU。
加速器集成电路436可包括存储器管理单元(memory management unit,MMU)439,该MMU 439用于执行诸如虚拟到物理存储器转换(也称为有效到实际存储器转换)之类的各种存储器管理功能以及用于访问系统存储器441的存储器访问协议。MMU 439还可包括用于对虚拟/有效到物理/实际地址转换进行缓存的转译后备缓冲器(TLB)(未示出)。在一个实现方式中,缓存438存储用于由图形处理引擎431、432、N高效访问的命令和数据。存储在缓存438和图形存储器433-434、M中的数据可被保持与核心缓存462A-462D、456和系统存储器441一致。如所提及,这可经由代理电路425来完成,该代理电路425代表缓存438和存储器433-434、M参与缓存一致性机制(例如,向缓存438发送与处理器缓存462A-462D、456上的缓存行的修改/访问相关的更新,并从缓存438接收更新)。
寄存器的集合445存储用于由图形处理引擎431-432、N执行的线程的上下文数据,并且上下文管理电路448管理这些线程上下文。例如,上下文管理电路448可执行保存和恢复操作,以在上下文期间保存和恢复各线程的上下文(例如,其中第一线程被保存并且第二线程被恢复,使得第二线程可由图形处理引擎执行)。例如,在上下文切换时,上下文管理电路448可将当前寄存器值存储到存储器中的指定区域(例如,由上下文指针标识)。当返回到该上下文时,其随后可恢复寄存器值。中断管理电路447例如可从系统设备接收中断,并处理从系统设备接收的中断。
在一个实现方式中,由MMU 439将来自图形处理器引擎431的虚拟/有效地址转换为系统存储器441中的实际/物理地址。任选地,加速器集成电路436支持多个(例如,4个、8个、16个)图形加速器模块446和/或其他加速器设备。图形加速器模块446可专用于在处理器407上执行的单个应用,或者可在多个应用之间被共享。任选地,提供虚拟化图形执行环境,在该虚拟化图形执行环境中,图形处理引擎431-432、N的资源与多个应用、虚拟机(virtual machine,VM)、或容器共享。资源可被细分为“切片”,这些切片基于与VM和/或应用相关联的处理要求和优先级被分配给不同的VM和/或应用。VM和容器在本文中可以可互换地使用。
虚拟机(VM)可以是运行操作系统以及一个或多个应用的软件。VM可由规范、配置文件、虚拟盘文件、非易失性随机存取存储器(non-volatile random access memory,NVRAM)设置文件和日志文件来定义,并且由主机计算平台的物理资源备份。VM可包括被安装在模仿专用硬件的软件上的操作系统(operating system,OS)或应用环境。终端用户在虚拟机上具有如同他们将在专用硬件上所具有的相同体验。被称为管理程序的专业化软件完全对PC客户端或服务器的CPU、存储器、硬盘、网络和其他硬件资源进行仿真,从而使虚拟机能够共享资源。管理程序可对彼此隔离的多个虚拟硬件平台进行仿真,从而允许虚拟机在相同的底层物理主机上运行
容器可以是应用、配置和依赖关系的软件包,因此,应用在一个计算环境到另一计算环境可靠地运行。容器可共享安装在服务器平台上的操作系统,并且作为隔离的进程运行。容器可以是包含软件运行所需的任何内容(诸如,系统工具、库和设置)的软件包。容器并不像传统的软件程序那样被安装,这允许容器与其他软件隔离且与操作系统自身隔离。容器的隔离性质提供若干益处。首先,容器中的软件将在不同环境中以相同方式运行。例如,包括PHP和MySQL的容器可在
因此,加速器集成电路436充当用于图形加速模块446的、到系统的桥接器,并且提供地址转换和系统存储器缓存服务。在一个实施例中,为了促进桥接功能,加速器集成电路436还可包括共享I/O 497(例如,PCIe、USB或其他元件)和硬件,以启用对电压、时钟控制、性能、热和安全性的系统控制。共享I/O 497可利用分开的物理连接,或者可跨越高速链路440。此外,加速器集成电路436可提供虚拟化设施,以供主机处理器管理对图形处理引擎、中断和存储器管理的虚拟化。
由于图形处理引擎431-432、N的硬件资源被显式地映射到由主机处理器407看到的实际地址空间,因此任何主机处理器可以使用有效地址值来直接对这些资源进行寻址。加速器集成电路436的一个任选功能是对图形处理引擎431-432进行物理分离,使得它们对于系统显得像独立的单元。
一个或多个图形存储器433-434、M可分别耦合至图形处理引擎431-432、N中的每一个。图形存储器433-434、M存储正由图形处理引擎431-432、N中的每一个处理的指令和数据。图形存储器433-434、M可以是诸如DRAM(包括堆叠式DRAM)、GDDR存储器(例如,GDDR5、GDDR6)或HBM之类的易失性存储器,和/或可以是诸如3D Xpoint/Optane、三星Z-NAND、或Nano-Ram之类的非易失性存储器。
为了减少高速链路440上的数据通信量,可使用偏置技术来确保存储在图形存储器433-434、M中的数据是将由图形处理引擎431-432、N最频繁地使用并且优选地不由核心460A-460D使用(至少不频繁地使用)的数据。类似地,偏置机制尝试将核心(并且优选地不由图形处理引擎431-432、N)所需要的数据保持在核心的缓存462A-462D、456和系统存储器441内。
根据图4C中示出的变体,加速器集成电路436被集成在处理器407内。图形处理引擎431-432、N通过高速链路440、经由接口437和接口435(其再次可利用任何形式的总线或接口协议)直接向加速器集成电路436通信。加速器集成电路436可执行与参考图4B所描述的那些操作相同的操作,但是考虑到该加速器集成电路436与一致性总线464和缓存462A-462D、456紧密邻近,其潜在地能以较高的吞吐量执行操作。
所描述的实施例可支持不同的编程模型,这些编程模型包括专用进程编程模型(无图形加速模块虚拟化)和共享编程模型(具有虚拟化)。后者可包括受加速器集成电路436控制的编程模型以及受图形加速模块446控制的编程模型。
在专用进程模型的实施例中,图形处理引擎431、432、N在单个操作系统下可专用于单个应用或进程。单个应用可使其他应用请求漏到图形引擎431、432、…、N,从而在VM/分区内提供虚拟化。
在专用进程编程模型中,图形处理引擎431、432、N可由多个VM/应用分区共享。共享模型需要系统管理程序来使图形处理引擎431-432、N虚拟化,以允许由每个操作系统进行的访问。对于不具有管理程序的单分区系统,图形处理引擎431-432、N由操作系统拥有。在这两种情况下,操作系统可使图形处理引擎431-432、N虚拟化,以提供对每个进程或应用的访问权。
对于共享编程模型,图形加速模块446或各个图形处理引擎431-432、N使用进程句柄来选择进程要素。进程要素可被存储在系统存储器441中,并且可以是使用本文中所描述的有效地址到实际地址转换技术而可寻址的。进程句柄可以是在向图形处理引擎431-432、N注册其上下文(即,调用系统软件以将进程要素添加到进程要素链表)时提供给主机进程的实现方式特定的值。进程句柄的较低的16比特可以是进程要素在进程要素链表内的偏移。
图4D图示示例性加速器集成切片490。如本文中所使用,“切片”包括加速器集成电路436的处理资源的指定部分。系统存储器441内的应用有效地址空间482存储进程要素483。进程要素483可响应于来自在处理器407上执行的应用480的GPU调用481而被存储。进程要素483包含对应应用480的进程状态。包含在进程要素483中的工作描述符(workdescriptor,WD)484可以是由应用请求的单个作业,或者可包含指向作业队列的指针。在后一种情况下,WD 484是指向应用的地址空间482中的作业请求队列的指针。
图形加速模块446和/或各个图形处理引擎431-432、N可以由系统中的全部进程或系统中的进程的子集共享。例如,本文中描述的技术可包括用于建立进程状态并将WD 484发送至图形加速模块446以在虚拟化环境中开始作业的基础设施。
在一个实现方式中,专用进程编程模型是实现方式特定的。在该模型中,单个进程拥有图形加速模块446或单独的图形处理引擎431。由于图形加速模块446由单个进程拥有,因此图形加速模块446被指派时,管理程序针对拥有的分区对加速器集成电路436进行初始化,并且操作系统针对拥有的进程对加速器集成电路436进行初始化。
在操作中,加速器集成切片490中的WD取得单元491取得下一WD 484,该下一WD484包括要由图形加速模块446的图形处理引擎中的一个图形处理引擎完成的工作的指示。如图所示,来自WD 484的数据可被存储在寄存器445中,并且由MMU 439、中断管理电路447和/或上下文管理电路448使用。例如,MMU 439可包括用于访问OS虚拟地址空间485内的段表/页表486的段/页走查电路。中断管理电路447可处理从图形加速模块446接收的中断事件492。当执行图形操作时,由图形处理引擎431-432、N生成的有效地址493由MMU 439转换成实际地址。
相同的寄存器集合445针对每个图形处理引擎431-432、N和/或图形加速模块446可被复制,并且可由管理程序或操作系统初始化。这些被复制的寄存器中的每个寄存器可被包括在加速器集成切片490中。在一个实施例中,每个图形处理引擎431-432、N可作为不同的图形处理器设备向管理程序496呈现。可针对特定图形处理引擎431-432、N的客户端配置QoS设置,并且可启用每个引擎的客户端之间的数据隔离。在表1中示出可由管理程序初始化的示例性寄存器。
表1-管理程序初始化的寄存器
在表2中示出可由操作系统初始化的示例性寄存器。
表2-操作系统初始化的寄存器
每个WD 484对于特定的图形加速模块446和/或图形处理引擎431-432、N可以是特定的。它包含图形处理引擎431-432、N完成其工作所需要的所有信息,或者它可以是指向应用已经建立要完成的工作的命令队列所在的存储器位置的指针。
图4E图示共享模型的附加的任选细节。它包括进程要素列表499被存储在其中的管理程序实际地址空间498。管理程序实际地址空间498是经由管理程序496可访问的,管理程序496针对操作系统495使图形加速模块引擎虚拟化。
共享编程模型允许来自系统中的全部分区或系统中的分区的子集的全部进程或进程的子集使用图形加速模块446。存在在其中图形加速模块446由多个进程和分区共享的两种编程模型:时分共享和图形定向共享。
在该模型中,系统管理程序496拥有图形加速模块446,并使其功能对所有的操作系统495可用。为使图形加速模块446支持由系统496进行的虚拟化,图形加速模块446可遵守以下要求:1)应用的作业请求必须是自主的(即,状态不需要在作业之间被维持),或者图形加速模块446必须提供上下文保存和恢复机制。2)由图形加速模块446保证应用的作业请求在所指定的时间量内完成,包括任何转换错误,或者图形加速模块446提供抢占对作业的处理的能力。3)图形加速模块446当在定向共享编程模型中操作时必须被保证进程之间的公平性。
对于共享模型,可需要应用480来用图形加速模块446类型、工作描述符(WD)、权限掩码寄存器(authority mask register,AMR)值和上下文保存/恢复区域指针(contextsave/restore area pointer,CSRP)作出操作系统495系统调用。图形加速模块446类型描述针对系统调用的目标加速功能。图形加速模块446类型可以是系统特定值。特别针对图形加速模块446对WD进行格式化,并且WD可以采用以下形式:图形加速模块446命令、指向用户定义的结构的有效地址指针、指向命令队列的有效地址指针、或用于描述要由图形加速模块446完成的工作的任何其他数据结构。在一个实施例中,AMR值是要用于当前进程的AMR状态。值被传递到操作系统与应用设置AMR类似。如果加速器集成电路436和图形加速模块446实现方式不支持用户权限掩码覆盖寄存器(User Authority Mask Override Register,UAMOR),则操作系统可在管理程序调用中传递AMR之前将当前UAMOR值应用到AMR值。管理程序496可在将AMR放置到进程要素483中之前任选地应用当前权限掩码覆盖寄存器(Authority Mask Override Register,AMOR)值。CSRP可以是包含应用的地址空间482中的区域的有效地址以供图形加速模块446用来保存和恢复上下文状态的寄存器445中的一个寄存器。如果没有状态被要求以被保存在作业之间或者当作业被抢占时,则该指针是任选的。上下文保存/恢复区域可以是钉置(pinned)的系统存储器。
在接收到系统调用时,操作系统495可验证应用480已注册并且已被给予使用图形加速模块446的权限。操作系统492随后利用表3中示出的信息来调用管理程序496
表3-OS对管理程序的调用参数
在接收管理程序调用时,管理程序496验证操作系统495已注册并且已被给予使用图形加速模块446的权限。管理程序496随后将进程要素483置于针对对应的图形加速模块446类型的进程要素链表中。进程要素可包括表4中示出的信息。
表4-进程要素信息
管理程序可初始化多个加速集成切片490的寄存器445。
如图4F中所图示,在一个任选实现方式中,采用经由共同的虚拟存储器地址空间可寻址的统一存储器,该共同的虚拟存储器地址空间被用于访问物理处理器存储器401-402和GPU存储器420-423。在该实现方式中,在GPU 410-413上执行的操作利用同一虚拟/有效存储器地址空间来访问处理器存储器401-402并且反之亦然,由此简化可编程性。虚拟/有效地址空间的第一部分可被分配给处理器存储器401,第二部分可被分配给第二处理器存储器402,第三部分可被分配给GPU存储器420,以此类推。整个虚拟/有效存储器空间(有时被称为有效地址空间)由此可跨处理器存储器401-402和GPU存储器420-423中的每一个分布,从而允许任何处理器或GPU利用映射到该存储器的虚拟地址来访问任何物理存储器。
可提供MMU 439A-439E中的一个或多个MMU内的偏置/一致性管理电路494A-494E,这些偏置/一致性管理电路494A-494E确保主机处理器(例如,405)的缓存与GPU 410-413的缓存之间的缓存一致性,并且实现指示某些类型的数据应当被存储在其中的物理存储器的偏置技术。虽然在图4F中图示偏置/一致性管理电路494A-494E的多个实例,但是可在一个或多个主机处理器405的MMU内和/或在加速器集成电路436内实现偏置/一致性电路。
GPU附连的存储器420-423可被映射为系统存储器的部分并使用共享虚拟存储器(shared virtual memory,SVM)技术来访问,但是不遭受与完全系统缓存一致性相关联的典型性能缺陷。GPU附连的存储器420-423在没有繁重的缓存一致性开销的情况下作为系统存储器被访问的能力为GPU迁移提供了有益的操作环境。该布置允许主机处理器405在没有传统的I/O DMA数据复制的开销的情况下设置操作对象并访问计算结果。此类传统复制涉及驱动器调用、中断、以及存储器映射的I/O(memory mapped I/O,MMIO)访问,它们相对于简单的存储器访问全都是低效的。同时,在没有缓存一致性开销的情况下访问GPU附连的存储器420-423的能力对于被迁移的计算的执行时间可以是关键的。例如,在具有大量流式写入存储器通信量的情况下,缓存一致性开销可能显著地降低由GPU 410-413看到的有效写入带宽。操作对象设置的效率、结果访问的效率以及GPU计算的效率在确定GPU迁移的有效性时全都发挥作用。
GPU偏置与主机处理器偏置之间的选择可由偏置跟踪器数据结构驱动。例如,可使用偏置表,该偏置表可以是页粒度的结构(即,以存储器页的粒度受控制),该页粒度的结构包括每GPU附连的存储器页的1个或2个比特。偏置表可在一个或多个GPU附连的存储器420-423的偷取的存储器范围中实现,在GPU 410-413中具有或不具有偏置缓存(例如,用于对频繁/最近使用的偏置表的条目进行缓存)。替代地,整个偏置表可被维持在GPU内。
在一个实现方式中,在对GPU存储器的实际访问之前,访问与对GPU附连的存储器420-423的每次访问相关联的偏置表条目,从而导致下列操作。首先,来自GPU 410-413的、在GPU偏置中发现它们的页的本地请求直接被转发至对应的GPU存储器420-423。来自GPU的、在主机偏置中发现它们的页的本地请求被转发至处理器405(例如,如上文所讨论,通过高速链路)。任选地,来自处理器405的、在主机处理器偏置中发现所请求的页的请求像正常存储器读取那样完成该请求。替代地,涉及GPU偏置的页的请求可被转发至GPU 410-413。如果GPU当前不是正在使用该页,则GPU随后可将该页转变为主机处理器偏置。
可通过基于软件的机制、或通过硬件辅助的基于软件的机制、或对于有限的情况集合而言通过基于纯硬件的机制来改变页的偏置状态。
一种用于改变偏置状态的机制采用API调用(例如,OpenCL),其进而调用GPU的设备驱动器,该设备驱动器进而向GPU发送指引该GPU改变偏置状态并针对一些转变在主机中执行缓存转储清除操作的消息(或使命令描述符入列)。针对从主机处理器405偏置到GPU偏置的转变需要缓存转储清除操作,但针对相反的转变不需要缓存转储清除操作。
可通过临时渲染不可由主机处理器405缓存的GPU偏置的页来维持缓存一致性。为了访问这些页,处理器405可请求从GPU 410访问,取决于实现方式,GPU可以或可以不准予立即访问。因此,为了减少主机处理器405与GPU 410之间的通信,确保GPU偏置的页是GPU所需但不是主机处理器405所需的那些页是有益的,并且反之亦然。
图形处理管线
图5图示图形处理管线500。图形多处理器(诸如,图2D中的图形多处理器234、图3A的图形多处理器325、图3B的图形多处理器350)可实现所图示的图形处理管线500。图形多处理器可被包括在如本文中所描述的并行处理子系统内,并行处理子系统诸如图2A的并行处理器200,其可与图1的(一个或多个)并行处理器112相关并且可替代那些并行处理器中的一个被使用。各种并行处理器系统可经由如本文中所描述的并行处理单元(例如,图2A的并行处理单元202)的一个或多个实例来实现图形处理管线500。例如,着色器单元(例如,图2C的图形多处理器234)可被配置成用于执行以下一者或多者的功能:顶点处理单元504、曲面细分控制处理单元508、曲面细分评估处理单元512、几何处理单元516、以及片段/像素处理单元524。数据组装器502、基元组装器506、514、518、曲面细分单元510、栅格化器522、以及栅格操作单元526的功能也可由处理集群(例如,图2A的处理集群214)内的其他处理引擎和对应的分区单元(例如,图2A的分区单元220A-220N)执行。图形处理管线500还可使用用于一个或多个功能的专用处理单元来实现。图形处理管线500的一个或多个部分由通用处理器(例如,CPU)内的并行处理逻辑执行也是可能的。任选地,图形处理管线500的一个或多个部分可以经由存储器接口528来访问片上存储器(例如,如图2A中的并行处理器存储器222),该存储器接口528可以是图2A的存储器接口218的实例。图形处理器管线500还可经由图3C中的多核心组365A来实现。
数据组装器502是可收集针对表面和基元的顶点数据的处理单元。数据组装器502随后将顶点数据输出到顶点处理单元504,该顶点数据包括顶点属性。顶点处理单元504是可编程执行单元,该可编程执行单元执行顶点着色器程序,从而按照顶点着色器程序所指定地来照明以及变换顶点数据。顶点处理单元504读取存储在缓存、本地或系统存储器中的数据以供在处理顶点数据时使用,并且可被编程为用于将顶点数据从基于对象的坐标表示变换为世界空间坐标空间或归一化设备坐标空间。
基元组装器506的第一实例从顶点处理单元504接收顶点属性。基元组装器506根据需要读取所存储的顶点属性,并且构建图形基元以供由曲面细分控制处理单元508进行处理。图形基元包括如由各种图形处理应用编程接口(application programminginterface,API)支持的三角形、线段、点、补片等。
曲面细分控制处理单元508将输入顶点视为几何补片的控制点。将控制点从来自补片的输入表示(例如,补片的基础)变换为适合于在由曲面细分评估处理单元512进行的表面评估中使用的表示。曲面细分控制处理单元508还可计算几何补片的边缘的曲面细分因子。曲面细分因子应用于单个边缘,并量化与该边缘相关联的依赖于视图的细节等级。曲面细分单元510配置成用于接收补片的边缘的曲面细分因子,并且用于将补片曲面细分成多个几何基元(诸如,线、三角形或四边形基元),这些几何基元被传送到曲面细分评估处理单元512。曲面细分评估处理单元512对经细分的补片的参数化坐标进行操作,以生成与几何基元相关联的每个顶点的表面表示和顶点属性。
基元组装器514的第二实例根据需要从曲面细分评估处理单元512接收顶点属性,读取所存储的顶点属性,并且构建图形基元以供由几何处理单元516进行处理。几何处理单元516是可编程执行单元,该可编程执行单元执行几何着色器程序以按照几何着色器程序所指定地变换从基元组装器514接收到的图形基元。几何处理单元516可被编程为用于将图形基元细分为一个或多个新的图形基元并计算被用于对这些新的图形基元进行栅格化的参数。
几何处理单元516可能能够在几何流中添加或删除元素。几何处理单元516向基元组装器518输出指定新的图形基元的参数和顶点。基元组装器518从几何处理单元516接收参数和顶点,并构建图形基元以供由视口缩放、剔除和裁剪单元520进行处理。几何处理单元516读取被存储在并行处理器存储器或系统存储器中的数据,以供在处理几何数据时使用。视口缩放、剔除和裁剪单元520执行裁剪、剔除和视口缩放,并且将经处理的图形基元输出到栅格化器522。
栅格化器522可执行深度剔除和其他基于深度的优化。栅格化器522还对新的图形基元执行扫描转换以生成片段并将那些片段和相关联的覆盖数据输出到片段/像素处理单元524。片段/像素处理单元524是被配置成用于执行片段着色器程序或像素着色器程序的可编程执行单元。片段/像素处理单元524按照片段或像素着色器程序所指定地变换从栅格化器522接收的片段或像素。例如,片段/像素处理单元524可被编程为用于执行包括但不限于纹理映射、着色、混合、纹理校正和透视校正的操作,以产生被输出到栅格操作单元526的经着色的片段或像素。片段/像素处理单元524可读取被存储在并行处理器存储器或系统存储器中的数据,以供在处理片段数据时使用。片段或像素着色器程序可被配置成用于取决于为处理单元配置的采样率而以样本、像素、片或其他粒度进行着色。
栅格操作单元526是处理单元,该处理单元执行栅格操作并将像素数据输出为要被存储在图形存储器(例如,如图2A中的并行处理器存储器222和/或如图1中的系统存储器104)中、要在一个或多个显示设备110A-110B上显示或用于由一个或多个处理器102或并行处理器112中的一个进一步处理的经处理的图形数据,这些栅格操作包括但不限于模版印制、z测试、混合等等。栅格操作单元526可被配置成用于压缩被写入到存储器的z数据或颜色数据并解压缩从存储器读取的z数据或颜色数据。
机器学习概览
可应用上文描述的体系结构以执行使用机器学习模型的训练和推断操作。机器学习在解决许多种类的任务方面已经是成功的。当训练和使用机器学习算法(例如,神经网络)时产生的计算自然地适合于高效的并行实现。相应地,诸如通用图形处理单元(GPGPU)之类的并行处理器已在深度神经网络的实际实现中扮演了重要角色。具有单指令多线程(SIMT)体系结构的并行图形处理器被设计成使图形管线中的并行处理的量最大化。在SIMT体系结构中,成组的并行线程尝试尽可能频繁地一起同步地执行程序指令以增加处理效率。由并行机器学习算法实现方式提供的效率允许使用高容量网络并且使得能够对较大的数据集训练那些网络。
机器学习算法是能够基于数据集合进行学习的算法。例如,机器学习算法可以被设计成用于对数据集内的高级抽象进行建模。例如,可以使用图像识别算法来确定给定的输入属于若干类别中的哪个类别;给定输入,回归算法可以输出数值;并且可以使用模式识别算法来生成经转换的文本或者执行文本到语音和/或语音识别。
示例性类型的机器学习算法是神经网络。存在许多类型的神经网络;简单类型的神经网络是前馈网络。前馈网络可以被实现为在其中按层来布置节点的非循环图。典型地,前馈网络拓扑包括由至少一个隐藏层分开的输入层和输出层。隐藏层将由输入层接收的输入变换为对在输出层中生成输出有用的表示。网络节点经由边被完全连接到相邻层中的节点,但在每个层内的节点之间不存在边。在前馈网络的输入层的节点处接收的数据经由激活函数被传播(即,“前馈”)至输出层的节点,该激活函数基于分别与连接这些层的边中的每一条边相关联的系数(“权重”)来计算网络中每个连续层的节点的状态。取决于正由正被执行的算法表示的特定模型,来自神经网络算法的输出可以采用各种形式。
在可使用机器学习算法对特定问题建模之前,使用训练数据集来训练算法。训练神经网络涉及:选择网络拓扑;使用表示正由网络建模的问题的训练数据的集合;以及调整权重,直到网络模型针对训练数据集的所有实例都以最小误差执行。例如,在针对神经网络的有监督学习训练过程期间,由网络响应于表示训练数据集中的实例的输入而产生的输出与那个实例的“正确的”标记输出进行比较,计算表示输出与标记输出之间的差异的误差信号,并且随着误差信号通过网络的层被向后传播,调整与连接相关联的权重以使那个误差最小化。当根据训练数据集的实例生成的输出中的每个输出的误差被最小化时,网络被认为是“经训练的”。
机器学习算法的准确度会显著地受用于训练算法的数据集的质量影响。训练过程可能是计算密集型的,并且在常规通用处理器上可能需要大量的时间。相应地,使用并行处理硬件来训练许多类型的机器学习算法。这对于优化神经网络的训练是特别有用的,因为在调整神经网络中的系数时执行的计算本身自然地适于并行实现方式。具体地,许多机器学习算法和软件应用已被适配成利用通用图形处理设备内的并行处理硬件。
图6是机器学习软件栈600的广义图。机器学习应用602是能够被配置成用于使用训练数据集来训练神经网络或使用经训练的深度神经网络来实现机器智能的任何逻辑。机器学习应用602可包括用于神经网络的训练和推断功能和/或可用于在部署之前训练神经网络的专业软件。机器学习应用602可实现任何类型的机器智能,包括但不限于:图像识别、地图创建和定位、自主导航、语音合成、医学成像或语言翻译。示例机器学习应用602包括但不限于基于语音的虚拟助手、图像或面部识别算法、自主导航、以及被用于训练由机器学习应用602使用的机器学习模型的软件工具。
可以经由机器学习框架604来启用用于机器学习应用602的硬件加速。机器学习框架604可提供机器学习基元的库。机器学习基元是通常由机器学习算法执行的基本操作。在没有机器学习框架604的情况下,将需要机器学习算法的开发者创建和优化与机器学习算法相关联的主计算逻辑,随后在开发新的并行处理器时重新优化计算逻辑。相反,机器学习应用可以被配置成使用由机器学习框架604提供的基元来执行必要的计算。示例性基元包括张量卷积、激活函数和池化,它们是在训练卷积神经网络(convolutional neuralnetwork,CNN)时执行的计算操作。机器学习框架604还可以提供基元以实现由许多机器学习算法执行的基本线性代数子程序,诸如,矩阵和向量操作。机器学习框架604的示例包括但不限于TensorFlow(张量流)、TensorRT、PyTorch、MXNet、Caffee、以及其他高级机器学习框架。
机器学习框架604可处理从机器学习应用602接收的输入数据,并生成至计算框架606的适当输入。计算框架606可抽象出提供给GPGPU驱动器608的底层指令,以使得机器学习框架604能够经由GPGPU硬件610来利用硬件加速而无需机器学习框架604非常熟悉GPGPU硬件610的体系结构。此外,计算框架606可以跨各种类型和世代的GPGPU硬件610来启用用于机器学习框架604的硬件加速。示例性计算框架606包括CUDA计算框架和相关联的机器学习库,诸如,CUDA深度神经网络(CUDA Deep Neural Network,cuDNN)库。机器学习软件栈600还可包括通信库或框架以促进多GPU和多节点计算。
GPGPU机器学习加速
图7图示通用图形处理单元700,其可以是图2A的并行处理器200或图1的(一个或多个)并行处理器112。通用处理单元(GPGPU)700可被配置成用于提供对由机器学习框架提供的基元的硬件加速的支持,以加速处理与训练深度神经网络相关联的类型的计算工作负载。此外,GPGPU 700可直接链接到GPGPU的其他实例以创建多GPU集群,从而改善尤其是深度神经网络的训练速度。基元也受支持以加速用于经部署的神经网络的推断操作。
GPGPU 700包括用于启用与主机处理器的连接的主机接口702。主机接口702可以是PCI快速接口。然而,主机接口还可以是供应方特定的通信接口或通信结构。GPGPU 700从主机处理器接收命令,并且使用全局调度器704以将与那些命令相关联的执行线程分发给处理集群的集合706A-706H。处理集群706A-706H共享缓存存储器708。缓存存储器708可充当用于处理集群706A-706H内的缓存存储器的较高级别的缓存。所图示的处理集群706A-706H可与图2A中的处理集群214A-214N对应。
GPGPU 700包括经由存储器控制器的集合712A-712B与处理集群706A-706H耦合的存储器714A-714B。存储器714A-714B可包括各种类型的存储器设备,包括动态随机存取存储器(dynamic random-access memory,DRAM)或图形随机存取存储器,诸如,同步图形随机存取存储器(synchronous graphics random access memory,SGRAM),包括图形双倍数据速率(graphics double data rate,GDDR)存储器。存储器714A-714B还可包括3D堆叠式存储器,包括但不限于高带宽存储器(high bandwidth memory,HBM)。
处理集群706A-706H中的每一个可包括图形多处理器的集合,诸如,图2D的图形多处理器234、图3A的图形多处理器325、图3B的图形多处理器350、或者可包括图3C中的多核心组365A-365N。计算集群的图形多处理器包括能够以包括适用于机器学习计算的精度的一系列精度来执行计算操作的多种类型的整数和浮点逻辑单元。例如,处理集群706A-706H中的每一个计算集群中的浮点单元的至少子集可被配置成用于执行16比特或32比特浮点操作,而浮点单元的不同子集可被配置成用于执行64比特浮点操作。
GPGPU 700的多个实例可以被配置成作为计算集群进行操作。由计算集群用于同步和数据交换的通信机制跨实施例而有所不同。例如,GPGPU 700的多个实例通过主机接口702进行通信。在一个实施例中,GPGPU 700包括I/O中枢709,该I/O中枢700将GPGPU 710与GPU链路710耦合,该GPU链路710启用至GPGPU的其他实例的直接连接。GPU链路710可耦合至专用GPU-GPU桥接器,该GPU-GPU桥接器启用GPGPU 700的多个实例之间的通信和同步。任选地,GPU链路710与高速互连耦合,以将数据传送至其他GPGPU或并行处理器并且从其他GPGPU或并行处理器接收数据。GPGPU 700的多个实例可位于单独的数据处理系统中,并且可经由网络设备进行通信,该网络设备可经由主机接口702来访问。附加于或替代于主机接口702,GPU链路710可被配置成用于启用至主机处理器的连接。
尽管GPGPU 700的所图示的配置可以配置成用于训练神经网络,但是GPGPU 700的替代配置可被配置成用于在高性能或低功率推断平台内的部署。在推断配置中,相对于训练配置,GPGPU 700包括处理集群706A-706H中的更少的处理集群。此外,与存储器714A-714B相关联的存储器技术在推断配置与训练配置之间可有所不同。在一个实施例中,GPGPU700的推断配置可支持推断专用指令。例如,推断配置可提供对一个或多个8比特整数点积指令的支持,这一个或多个8比特整数点积指令通常在用于经部署的神经网络的推断操作期间被使用。
图8图示多GPU计算系统800。多GPU计算系统800可包括经由主机接口开关804被耦合至多个GPGPU 806A-806D的处理器802。主机接口开关804可以是将处理器802耦合至PCI快速总线的PCI快速开关设备,处理器802能够通过该PCI快速总线与GPGPU的集合806A-806D通信。多个GPGPU 806A-806D中的每一个可以是图7的GPGPU 700的实例。GPGPU 806A-806D可经由高速点到点GPU-GPU链路的集合816来互连。高速GPU-GPU链路可以经由专用GPU链路连接到GPU 806A-806D中的每一个,该专用GPU链路诸如图7中的GPU链路710。P2P GPU链路816启用GPGPU 806A-806D中的每一个GPGPU之间的直接通信,而不需要通过处理器802被连接到的主机接口总线进行的通信。利用定向到P2P GPU链路的GPU-GPU通信量,主机接口总线保持可用于系统存储器访问,或用于例如经由一个或多个网络设备与多GPU计算系统800的其他实例通信。虽然在图8中806A-806D经由主机接口开关804连接到处理器802,但是处理器802可附加地包括对P2P GPU链路8056的直接支持,并直接连接到GPGPU 806A-806D。在一个实施例中,P2P GPU链路806使多GPU计算系统800能够作为单个逻辑GPU进行操作。
机器学习神经网络实现方式
本文中描述的计算体系结构可被配置成用于执行特别适合于训练和部署用于机器学习的神经网络的类型的并行处理。可以将神经网络概括为具有图关系的函数的网络。如本领域中所公知,存在用于机器学习的各种类型的神经网络实现方式。一种示例性类型的神经网络是如先前所描述的前馈网络。
第二示例性类型的神经网络是卷积神经网络(CNN)。CNN是用于处理具有已知的、栅格状拓扑的数据(诸如,图像数据)的专业的前馈神经网络。相应地,CNN通常用于计算机视觉和图像识别应用,但是它们也可用于其他类型的模式识别,诸如,语音和语言处理。CNN输入层中的节点被组织为“过滤器”的集合(由视网膜中发现的感受野激发的特征检测器),并且每个过滤器集合的输出被传播至网络的连续层中的节点。用于CNN的计算包括将卷积数学运算应用于每个过滤器以产生那个过滤器的输出。卷积是由两个函数执行以产生第三函数的专业种类的数学运算,该第三函数是两个原始函数中的一个函数的修改版本。在卷积网络术语中,至卷积的第一函数可被称为输入,而第二函数可被称为卷积核心。输出可被称为特征图。例如,至卷积层的输入可以是定义输入图像的各种颜色分量的多维数据数组。卷积核心可以是多维参数数组,其中通过用于神经网络的训练过程来使参数适配。
循环神经网络(recurrent neural network,RNN)是包括层之间的反馈连接的一系列前馈神经网络。RNN通过跨神经网络的不同部分共享参数数据来启用对序列化数据进行建模。用于RNN的体系结构包括循环。这些循环表示变量的当前值在将来时刻对其自身值的影响,因为来自RNN的输出数据的至少部分被用作反馈以用于处理序列中的后续输入。由于语言数据可被组成的可变本质,这个特征使RNN变得对语言处理特别有用。
下文描述的附图呈现了示例性前馈网络、CNN网络和RNN网络,并且描述了用于分别训练和部署那些类型的网络中的每一种的一般过程。将理解,这些描述就本文中描述的任何特定实施例而言是示例性且是非限制性的,并且一般说来所图示的概念一般可应用于深度神经网络和机器学习技术。
上文描述的示例性神经网络可以用于执行深度学习。深度学习是使用深度神经网络的机器学习。与仅包括单个隐藏层的浅层神经网络不同,在深度学习中使用的深度神经网络是由多个隐藏层组成的人工神经网络。更深的神经网络通常训练起来是更加计算密集性的。然而,网络的附加的隐藏层启用多步模式识别,该多步模式识别产生相对于浅层机器学习技术的减小的输出误差。
在深度学习中使用的深度神经网络典型地包括用于执行特征识别的前端网络,该前端网络耦合至后端网络,该后端网络表示可基于提供给数学模型的特征表示来执行操作(例如,对象分类、语音识别等)的数学模型。深度学习使得深度学习能够在无需针对模型执行手工的特征工程化的情况下被执行。相反,深度神经网络可基于输入数据内的统计结构或相关性来学习特征。所学习的特征可提供给数学模型,该数学模型可将所检测的特征映射至输出。由网络使用的数学模型通常专用于要执行的特定任务,并且将使用不同的模型来执行不同的任务。
一旦将神经网络结构化,就可以将学习模型应用于网络以将网络训练成执行特定任务。学习模型描述如何调整模型内的权重以减小网络的输出误差。误差的反向传播是用于训练神经网络的常用方法。输入向量被呈现给网络以供处理。使用损失函数将网络的输出与期望输出进行比较,并且为输出层中的神经元中的每个神经元计算误差值。随后,向后传播误差值,直到每个神经元具有粗略地表示该神经元对原始输出的贡献的相关联的误差值。网络随后可使用算法(诸如,随机梯度下降算法)通过那些误差进行学习,以更新神经网络的权重。
图9A-图9B图示示例性卷积神经网络。图9A图示CNN内的各个层。如图9A中所示,用于对图像处理建模的示例性CNN可接收描述输入图像的红色、绿色、和蓝色(RGB)分量的输入902。输入902可由多个卷积层(例如,卷积层904、卷积层906)处理。来自多个卷积层的输出任选地可由全连接层的集合908处理。如先前针对前馈网络所描述,全连接层中的神经元具有至前一层中的所有激活的完全连接。来自全连接层908的输出可用于从网络生成输出结果。可使用矩阵乘法而不是卷积来计算全连接层908内的激活。并非所有CNN实现方式都利用全连接层908。例如,在一些实现方式中,卷积层906可生成CNN的输出。
卷积层被稀疏地连接,这与在全连接层908中发现的传统神经网络配置不同。传统神经网络层被完全连接,使得每个输出单元与每个输入单元相互作用。然而,如图所示,卷积层被稀疏地连接,因为感受野的卷积的输出(而不是感受野中的节点中的每个节点的相应状态值)被输入到后续层的节点。与卷积层相关联的核心执行卷积操作,该卷积操作的输出被发送至下一层。在卷积层内执行的降维是使得CNN能够缩放以处理大图像的一个方面。
图9B图示CNN的卷积层内的示例性计算阶段。可以在卷积层914的三个阶段中处理至CNN的卷积层的输入912。这三个阶段可包括卷积阶段916、检测器阶段918和池化阶段920。卷积层914随后可将数据输出至连续的卷积层。网络的最终卷积层可生成输出特征图数据或提供至全连接层的输入,例如以生成用于至CNN的输入的分类值。
在卷积阶段916中并行地执行若干个卷积,以产生线性激活的集合。卷积阶段916可包括仿射变换,该仿射变换是可被指定为线性变换加平移的任何变换。仿射变换包括旋转、平移、缩放和这些变换的组合。卷积阶段计算连接到输入中的特定区域的函数(例如,神经元)的输出,这些特定区域可以被确定为与神经元相关联的局部区域。神经元计算神经元的权重与局部输入中神经元被连接到的区域的权重之间的点积。来自卷积阶段916的输出定义由卷积层914的连续阶段处理的线性激活的集合。
线性激活可由检测器阶段918处理。在检测器阶段918中,每个线性激活由非线性激活函数处理。非线性激活函数增加整体网络的非线性性质,而不影响卷积层的感受野。可使用若干种类型的非线性激活函数。一种特定类型是修正线性单元(rectified linearunit,ReLU),其使用定义为f(x)=max(0,x)的激活函数,使得激活的阈值为零。
池化阶段920使用池化函数,该池化函数利用附近输出的摘要统计来替换第卷积层906的输出。池化函数可用于将平移不变性引入到神经网络中,使得至输入的小平移不改变经池化的输出。局部平移的不变性在其中特征在输入数据中的存在比特征的精确位置更重要的场景中可以是有用的。可以在池化阶段920期间使用各种类型的池化函数,包括最大池化、平均池化和l2范数池化。此外,一些CNN实现方式不包括池化阶段。相反,此类实现方式是相对于先前的卷积阶段具有增加的跨度的替代和附加卷积阶段。
来自卷积层914的输出随后可由下一层922处理。下一层922可以是附加的卷积层或是全连接层908中的一个层。例如,图9A的第一卷积层904可输出到第二卷积层906,而第二卷积层可输出到全连接层908中的第一层。
图10图示示例性循环神经网络1000。在循环神经网络(RNN)中,网络的先前状态影响网络的当前状态的输出。能以各种方式、使用各种函数来建立RNN。RNN的使用总体上围绕着使用数学模型以基于输入的先前序列来预测未来。例如,RNN可被用于执行统计语言建模,以在给定单词的先前序列的情况下预测即将到来的单词。所图示的RNN 1000可被描述为具有接收输入向量的输入层1002、用于实现循环函数的隐藏层1004、用于启用先前状态的‘记忆’的反馈机制1005、以及用于输出结果的输出层1006。RNN 1000基于时间步长进行操作。处于给定时间步长的RNN的状态经由反馈机制1005、基于先前的时间步长而受影响。对于给定的时间步长,隐藏层1004的状态由先前状态以及当前时间步长处的输入定义。处于第一时间步长的初始输入(x
除所描述的基本CNN和RNN网络之外,还可启用针对那些网络的变体的加速。一个示例RNN变体是长短期记忆(long short term memory,LSTM)RNN。LSTM RNN能够学习长期依赖关系,该长期依赖关系可对于处理较长的语言序列而言是必需的。CNN的变体是卷积深度信念网络,该卷积深度信念网络具有与CNN类似的结构,并且以与深度信念网络类似的方式被训练。深度信念网络(deep belief network,DBN)是由随机性(随机)变量的多个层组成的生成式神经网络。DBN可使用贪婪无监督学习来逐层训练。DBN的所学习的权重随后可被用来通过确定用于神经网络的权重的最佳初始集合来提供预训练神经网络。在进一步的实施例中,启用用于强化学习的加速。在强化学习中,人工代理通过与其环境交互来学习。该代理被配置成用于优化某些目标以使累积回报最大化。
图11图示深度神经网络的训练和部署。一旦已针对任务将给定的网络结构化,就使用训练数据集1102来训练神经网络。已开发各种训练框架1104来启用训练过程的硬件加速。例如,图6的机器学习框架604可被配置为训练框架1104。训练框架1104可接入未经训练的神经网络1106,并且使得未经训练的神经网络能够使用本文描述的并行处理资源被训练以生成经训练的神经网络1108。
为了开始训练过程,可随机地或通过使用深度信念网络进行预训练来选择初始权重。随后,以有监督或无监督方式执行训练循环。
有监督学习是在其中训练被执行为介导操作的学习方法,诸如,当训练数据集1102包括与输入的期望输出配对的该输入时,或在训练数据集包括具有已知输出的输入并且神经网络的输出被手动分级的情况下。网络处理输入,并且将所得的输出与预期输出或期望输出的集合进行比较。随后,通过系统往回传播误差。训练框架1104可进行调整以调整控制未经训练的神经网络1106的权重。训练框架1104可提供工具以监测未经训练的神经网络1106正在多好地收敛于适合基于已知的输入数据生成正确的答案的模型。随着网络的权重被调整以改良由神经网络生成的输出,训练过程反复地发生。训练过程可继续,直到神经网络达到与经训练的神经网络1108相关联的统计上期望的准确度。经训练的神经网络1108随后可被部署为实现任何数量的机器学习操作,以基于新数据1112的输入来生成推断结果1114。
无监督学习是在其中网络尝试使用未标记数据来训练其自身的学习方法。因此,针对无监督学习,训练数据集1102将包括不具有任何相关联的输出数据的输入数据。未经训练的神经网络1106可学习未标记输入内的分组,并且可确定单独的输入如何与整个数据集相关。无监督训练可被用于生成自组织图,该自组织图是能够执行在降低数据的维度方面有用的操作的类型的经训练的神经网络1108。无监督训练还可被用于执行异常检测,该异常检测允许标识输入数据集中的、从数据的正常模式偏离的数据点。
还可采用有监督训练和无监督训练的变体。半监督学习是在其中在训练数据集1102中包括具有相同分布的经标记数据和未标记数据的混合的技术。渐进式学习是有监督学习的变体,其中连续地使用输入数据以进一步训练模型。渐进式学习使得经训练的神经网络1108能够适配于新数据1112,而不忘记在初始训练期间根植在网络内的知识。
无论是有监督还是无监督的,用于特别深的神经网络的训练过程对于单个计算节点可能是过于计算密集的。可以使用计算节点的分布式网络而不是使用单个计算节点来加速训练过程。
图12A是图示分布式学习的框图。分布式学习是使用多个分布式计算节点来执行神经网络的有监督或无监督训练的训练模型。分布式计算节点各自可包括一个或多个主机处理器或通用处理节点中的一个或多个通用处理节点,通用处理节点诸如图7中的高度并行的通用图形处理单元700。如图所示,能以模型并行性1202、数据并行性1204、或模型和数据并行性的组合1206来执行分布式学习。
在模型并行性1202中,分布式系统中的不同计算节点可为单个网络的不同部分执行训练计算。例如,神经网络的每一层可由分布式系统的不同处理节点训练。模型并行性的益处包括缩放到特别大的模型的能力。分割与神经网络的不同层相关联的计算使得能够训练非常大型的神经网络,在大型神经网络中,所有层的权重将无法适配到单个节点的存储器中。在一些实例中,模型并行性在执行大型神经网络的无监督训练时可以是特别有用的。
在数据并行性1204中,分布式网络的不同节点具有模型的完整实例,并且每个节点接收数据的不同部分。来自不同节点的结果随后被组合。虽然实现数据并行性的不同方式是可能的,但是数据并行性训练方式全都需要将结果组合并使每个节点之间的模型参数同步的技术。用于组合数据的示例性方式包括参数求平均以及基于更新的数据并行性。参数求平均对训练数据的子集训练每个节点,并且将全局参数(例如,权重、偏置)设置为来自每个节点的参数的平均值。参数求平均使用维护参数数据的中央参数服务器。基于更新的数据并行性与参数求平均类似,例外在于,对模型的更新被传输,而不是将参数从节点传输到参数服务器。另外,能以分散化的方式执行基于更新的数据并行性,其中更新被压缩并且在节点之间传输。
可以例如在其中每个计算节点包括多个GPU的分布式系统中实现组合式模型和数据并行性1206。每个节点可具有模型的完整实例,其中每个节点内的单独GPU被用于训练模型的不同部分。
分布式训练相对于在单个机器上的训练已增加开销。然而,本文中描述的并行处理器和GPGPU各自可实现各种技术以降低分布式训练的开销,包括用于启用高带宽GPU-GPU数据传输和加速的远程数据同步的技术。
图12B是图示可编程网络接口1210和数据处理单元的框图。可编程网络接口1210是可用于加速分布式环境内的基于网络的计算任务的可编程网络引擎。可编程网络接口1210可经由主机接口1270与主机系统耦合。可编程网络接口1210可用于加速用于主机系统的CPU或GPU的网络或存储操作。主机系统例如可以是用于执行分布式训练的分布式学习系统的节点,例如,如图12A中所示。主机系统也可以是数据中心内的数据中心节点。
在一个实施例中,可由可编程网络接口1210加速对包含模型数据的远程存储装置的存取。例如,可编程网络接口1210可被配置成用于将远程存储设备呈现为主机系统的本地存储设备。可编程网络接口1210还可加速在主机系统的GPU与远程系统的GPU之间执行的远程直接存储器存取(remote direct memory access,RDMA)操作。在一个实施例中,可编程网络接口1210可启用存储功能,诸如但不限于NVME-oF。可编程网络接口1210还可代表主机系统加速用于远程存储装置的加密、数据完整性、压缩和其他操作,从而允许远程存储装置逼近直接附连至主机系统的存储设备的等待时间。
可编程网络接口1210还可代表主机系统执行资源分配和管理。存储安全操作可被迁移到可编程网络接口1210,并且与远程存储资源的分配和管理协同地执行。用于管理对远程存储装置的存取的、否则将由主机系统的处理器执行的基于网络的操作可替代地由可编程网络接口1210执行。
在一个实施例中,网络和/或数据安全操作可从主机系统迁移到可编程网络接口1210。用于数据中心节点的数据中心安全策略可由可编程网络接口1210而不是主机系统的处理器来处置。例如,可编程网络接口1210可检测并缓解在主机系统上的被尝试的基于网络的攻击(例如,DDoS),从而防止攻击破坏主机系统的可用性。
可编程网络接口1210可包括经由多个处理器核心1222执行操作系统的片上系统(SoC 1220)。处理器核心1222可包括通用处理器(例如,CPU)核心。在一个实施例中,处理器核心1222还可包括一个或多个GPU核心。SoC1220可执行存储在存储器设备1240上的指令。存储设备1250可存储本地操作系统数据。存储设备1250和存储器设备1240还可用于对用于主机系统的远程数据进行缓存。网络端口1260A-1260B启用至网络或结构的连接,并且促进针对SoC 1220的网络访问,并经由主机接口1270促进针对主机系统的网络访问。可编程网络接口1210还可包括I/O接口1275,诸如,USB接口。I/O接口1275可用于将外部设备耦合至可编程网络接口1210或耦合为调试接口。可编程网络接口1210还包括管理接口1230,该管理接口1230使主机设备上的软件能够管理和配置可编程网络接口1210和/或SoC 1220。在一个实施例中,可编程网络接口1210还可包括一个或多个加速器或GPU 1245以接受并行计算任务从经由网络端口1260A-1260B耦合的SoC 1220、主机系统或远程系统的迁移。
示例性机器学习应用
可以应用机器学习以解决各种技术问题,包括但不限于计算机视觉、自主驾驶和导航、语音识别以及语言处理。计算机视觉在传统上已是机器学习应用的最活跃研究领域之一。计算机视觉的应用范围为从重现人类视觉能力(诸如,识别人脸)到创建新类别的视觉能力。例如,计算机视觉应用可以配置成用于从在视频中可见的物体中诱发的振动来识别声波。并行处理器加速的机器学习使得计算机视觉应用能够使用比先前可行的训练数据集显著更大的训练数据集来训练,并且使得推理系统能够使用低功率并行处理器来部署。
并行处理器加速的机器学习具有自主驾驶应用,包括车道和道路标志识别、障碍回避、导航和驾驶控制。加速的机器学习技术可用于基于定义对特定训练输入的适当响应的数据集来训练驾驶模型。本文中描述的并行处理器能够实现对用于自主驾驶解决方案的日益复杂的神经网络的快速训练,并且能够实现将低功率推断处理器部署在适合于集成到自主交通工具中的移动平台中。
并行处理器加速的深度神经网络已启用用于自动语音识别(automatic speechrecognition,ASR)的机器学习方式。ASR包括创建在给定的输入声序列的情况下计算最优可能的语言序列的函数。使用深度神经网络的加速的机器学习已启用对于先前用于ASR的隐马尔可夫模型(hidden Markov model,HMM)和高斯混合模型(Gaussian mixture model,GMM)的替代。
并行处理器加速的机器学习还可以用于加速自然语言处理。自动学习过程可以利用统计推断算法以产生对于有误差的或不熟悉的输入强健的模型。示例性自然语言处理器应用包括人类语言之间的自动机器翻译。
可以将用于机器学习的并行处理平台划分为训练平台和部署平台。训练平台总体上是高度并行的,并且包括用于加速多GPU单节点训练和多节点多GPU训练的优化。适用于训练的示例性并行处理器包括图7的通用图形处理单元700和图8的多GPU计算系统800。相反,经部署的机器学习平台一般包括适于在诸如相机、自主机器人和自主交通工具之类的产品中使用的较低功率并行处理器。
此外,还可应用机器学习技术来加速或增强图形处理活动。例如,可将机器学习模型训练成用于识别由GPU加速应用生成的输出并生成那个输出的放大版本。可应用此类技术以加速生成用于游戏应用的高分辨率图像。各种其他图形管线活动可受益于机器学习的使用。例如,可将机器学习模型训练成用于对几何数据执行曲面细分操作以增加几何模型的复杂度,从而允许从具有相对较低的细节的几何体自动地生成细节更精细的几何体。
图13图示适于使用经训练的模型执行推断的示例性推断片上系统(SOC)1300。SOC1300可集成处理部件,包括媒体处理器1302、视觉处理器1304、GPGPU 1306和多核心处理器1308。GPGPU 1306可以是本文所描述的GPGPU,诸如,GPGPU 700,并且多核心处理器1308可以是本文中描述的多核心处理器,诸如,多核心处理器405-406。SOC 1300可附加地包括片上存储器1305,该片上存储器1305可启用能够由处理部件中的每个处理部件访问的共享片上数据池。处理部件可针对低功率操作进行优化,以启用对包括自主交通工具和自主机器人的各种机器学习平台的部署。例如,SOC 1300的一个实现方式可被用作用于自主交通工具的主控制系统的部分。在SOC 1300被配置成在自主交通工具中使用的情况下,SOC被设计和配置成符合部署管辖的相关功能安全标准。
在操作期间,媒体处理器1302和视觉处理器1304可协同地工作以加速计算机视觉操作。媒体处理器1302可启用对多个高分辨率(例如,4K、8K)视频流的低等待时间解码。经解码的视频流可被写入片上存储器1305中的缓冲器。视觉处理器1304随后可解析经解码的视频,并且对经解码的视频的帧执行初步处理操作,以准备好使用经训练的图像识别模型来处理帧。例如,视觉处理器1304可加速用于CNN的卷积操作,该CNN用于对高分辨率视频数据执行图像识别,同时后端模型计算由GPGPU 1306执行。
多核心处理器1308可包括控制逻辑,该控制逻辑用于辅助对由媒体处理器1302和视觉处理器1304执行的数据传输和共享存储器操作的定序和同步。多核心处理器1308还可充当应用处理器,以用于执行能够利用GPGPU 1306的推断计算能力的软件应用。例如,导航和驾驶逻辑的至少部分可实现在多核心处理器1308上执行的软件中。此类软件可直接将计算工作负载发出至GPGPU 1306,或者计算负载可被发出至多核心处理器1308,该多核心处理器1308可将那些操作的至少部分迁移至GPGPU 1306。
GPGPU 1306可包括计算集群,诸如,通用图形处理单元700内的低功率配置的处理集群706A-706H。GPGPU 1306内的计算集群可支持专门优化成在经训练的神经网络上执行推断计算的指令。例如,GPGPU 1306可支持用于执行诸如8比特和4比特整数向量操作之类的低精度计算的指令。
附加系统概览
图14是处理系统1400的框图。图14的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。系统1400可在一些各项中被使用:单处理器桌面型电脑系统、多处理器工作站系统、或具有大量处理器1402或处理器核心1407的服务器系统。系统1400可以是被并入在片上系统(SoC)集成电路内的处理平台,该片上系统(SoC)集成电路用于在移动设备、手持式设备或嵌入式设备中使用,诸如,用于在具有至局域网或广域网的有线或无线连接性的物联网(Internet-of-things,IoT)设备内使用。
系统1400可以是具有与图1的那些部件对应的部件的处理系统。例如,在不同配置中,(一个或多个)处理器1402或(一个或多个)处理器核心1407可与图1的(一个或多个)处理器102对应。(一个或多个)图形处理器1408可与图1的(一个或多个)并行处理器112对应。外部图形处理器1418可以是图1的(一个或多个)插入式设备120中的一个。
系统1400可包括以下各项,可与以下各项耦合,或可集成在以下各项内:基于服务器的游戏平台;游戏控制台,包括游戏和媒体控制台;移动游戏控制台、手持式游戏控制台、或在线游戏控制台。系统1400可以是移动电话、智能电话、平板计算设备或移动互联网连接的设备(诸如,具有低内部存储容量的膝上型计算机)的部分。处理系统1400也可包括以下各项,与以下各项耦合,或被集成在以下各项内:可穿戴设备,诸如,智能手表可穿戴设备;智能眼镜或服装,其利用增强现实(augmented reality,AR)或虚拟现实(virtualreality,VR)特征来增强,以提供视觉、音频或触觉输出来补充现实世界视觉、音频或触觉体验或以其他方式提供文本、音频、图形、视频、全息图像或视频、或触觉反馈;其他增强现实(AR)设备;或其他虚拟现实(VR)设备。处理系统1400可包括电视机或机顶盒设备,或可以是电视机或机顶盒设备的部分。系统1400可包括自动驾驶交通工具,与自动驾驶交通工具耦合,或集成在自动驾驶交通工具内,该自动驾驶交通工具诸如,公共汽车、拖拉机拖车、汽车、电机或电力循环、飞机或滑翔机(或其任何组合)。自动驾驶交通工具可使用系统1400来处理在该交通工具周围感测到的环境。
一个或多个处理器1402可包括一个或多个处理器核心1407,这一个或多个处理器核心1407用于处理指令,这些指令当被执行时,执行用于系统和用户软件的操作。一个或多个处理器核心1407中的至少一个处理器核心可被配置成用于处理特定的指令集1409。指令集1409可促进复杂指令集计算(Complex Instruction Set Computing,CISC)、精简指令集计算(Reduced Instruction Set Computing,RISC)或经由超长指令字(Very LongInstruction Word,VLIW)的计算。一个或多个处理器核心1407可以处理不同的指令集1409,不同的指令集1409可包括用于促进对其他指令集的仿真的指令。处理器核心1407还可包括其他处理设备,诸如,数字信号处理器(Digital Signal Processor,DSP)。
处理器1402可包括缓存存储器1404。取决于体系结构,处理器1402可具有单个内部缓存或多级的内部缓存。在一些实施例中,缓存存储器在处理器1402的各种部件之间被共享。在一些实施例中,处理器1402也使用外部缓存(例如,第三级(L3)缓存或最后一级缓存(Last Level Cache,LLC))(未示出),可使用已知的缓存一致性技术在处理器核心1407之间共享该外部缓存。寄存器堆1406可附加地被包括在处理器1402中,并且可包括用于存储不同类型的数据的不同类型的寄存器(例如,整数寄存器、浮点寄存器、状态寄存器以及指令指针寄存器)。一些寄存器可以是通用寄存器,而其他寄存器可以专用于处理器1402的设计。
一个或多个处理器1402可与一个或多个接口总线1410耦合,以在处理器1402与系统1400中的其他部件之间传送通信信号,诸如,地址、数据、或控制信号。在这些实施例中的一个实施例中,接口总线1410可以是处理器总线,诸如,直接媒体接口(Direct MediaInterface,DMI)总线的某个版本。然而,处理器总线不限于DMI总线,并且可包括一个或多个外围部件互连总线(例如,PCI、PCI快速)、存储器总线、或其他类型的接口总线。例如,(一个或多个)处理器1402可包括集成存储器控制器1416和平台控制器中枢1430。存储器控制器1416促进存储器设备与系统1400的其他部件之间的通信,而平台控制器中枢(platformcontroller hub,PCH)1430提供经由本地I/O总线至I/O设备的连接。
存储器设备1420可以是动态随机存取存储器(dynamic random-access memory,DRAM)设备、静态随机存取存储器(static random-access memory,SRAM)设备、闪存设备、相变存储器设备、或具有合适的性能以充当进程存储器的某个其他存储器设备。存储器设备1420可以例如作为用于系统1400的系统存储器来操作,以存储数据1422和指令1421,用于在一个或多个处理器1402执行应用或进程时使用。存储器控制器1416也与任选的外部图形处理器1418耦合,该任选的外部图形处理器1418可与处理器1402中的一个或多个图形处理器1408通信以执行图形操作和媒体操作。在一些实施例中,可由加速器1412辅助图形操作、媒体操作和/或计算操作,该加速器112是可被配置成用于执行专业的图形操作、媒体操作或计算操作的集合的协处理器。例如,加速器1412可以是用于优化机器学习或计算操作的矩阵乘法加速器。加速器1412可以是光线追踪加速器,该光线追踪加速器可用于与图形处理器1408协同地执行光线追踪操作。在一个实施例中,可替代加速器1412使用外部加速器1419,或可与加速器1412协同地使用外部加速器1419。
可提供显示设备1411,该显示设备1411可连接到(一个或多个)处理器1402。显示设备1411可以是以下各项中的一项或多项:内部显示设备,如在移动电子设备或膝上型设备中;或经由显示接口(例如,显示端口等)附接的外部显示设备。显示设备1411可以是头戴式显示器(head mounted display,HMD),诸如,用于在虚拟现实(VR)应用或增强现实(AR)应用中使用的立体显示设备。
平台控制器中枢1430使外围设备能够经由高速I/O总线连接到存储器设备1420和处理器1402。I/O外围设备包括但不限于音频控制器1446、网络控制器1434、固件接口1428、无线收发器1426、触摸传感器1425、数据存储设备1424(例如,非易失性存储器、易失性存器、硬盘驱动器、闪存、NAND、3D NAND、3D Xpoint/Optane等)。数据存储设备1424可以经由存储接口(例如,SATA)或经由外围总线(诸如,外围部件互连总线(例如,PCI、PCI快速))连接。触摸传感器1425可以包括触摸屏传感器、压力传感器、或指纹传感器。无线收发器1426可以是Wi-Fi收发器、蓝牙收发器、或移动网络收发器,该移动网络收发器诸如3G、4G、5G或长期演进(Long-Term Evolution,LTE)收发器。固件接口1428启用与系统固件的通信,并且可以例如是统一可扩展固件接口(unified extensible firmware interface,UEFI)。网络控制器1434可启用至有线网络的网络连接。在一些实施例中,高性能网络控制器(未示出)与接口总线1410耦合。音频控制器1446可以是多声道高清音频控制器。在这些实施例中的一个实施例中,系统1400包括用于将传统(例如,个人系统2(PS/2))设备耦合至系统的任选的传统I/O控制器1440。平台控制器中枢1430还可以连接到一个或多个通用串行总线(Universal Serial Bus,USB)控制器1442连接输入设备,诸如,键盘和鼠标1443组合、相机1444、或其他USB输入设备。
将领会,所示的系统1400是示例性而非限制性的,因为也可以使用以不同方式配置的其他类型的数据处理系统。例如,存储器控制器1416和平台控制器中枢1430的实例可以集成到分立的外部图形处理器中,该分立的外部图形处理器诸如外部图形处理器1418。平台控制器中枢1430和/或存储器控制器1416可以在一个或多个处理器1402外部。例如,系统1400可包括外部存储器控制器1416和平台控制器中枢1430,该外部存储器控制器1416和平台控制器中枢1430可以被配置为在与(一个或多个)处理器1402通信的系统芯片组内的存储器控制器中枢和外围控制器中枢。
例如,可使用电路板(“橇板(sled)”),在该电路板上被放置的部件(诸如,CPU、存储器和其他部件)经设计以实现提升的热性能。诸如处理器之类的处理部件可位于橇板的顶侧上,而诸如DIMM之类的附近存储器位于橇板的底侧上。作为由该设计提供的增强的气流的结果,部件能以比在典型系统中更高的频率和功率等级来操作,由此提高性能。此外,橇板配置成盲配机架中的功率和数据通信线缆,由此增强它们被快速地移除、升级、重新安装和/或替换的能力。类似地,位于橇板上的各个部件(诸如,处理器、加速器、存储器和数据存储驱动器)由于它们距彼此的增加的间距而被配置成易于升级。在说明性实施例中,部件附加地包括用于证明它们的真实性的硬件认证特征。
数据中心可利用支持多个其他网络体系结构的单个网络体系结构(“结构”),多个其他网络体系结构包括以太网和全方位路径。橇板可经由光纤耦合至交换机,这提供比典型的双绞线布线(例如,5类、5e类、6类等)更高的带宽和更低的等待时间。由于高带宽、低等待时间的互连和网络体系结构,数据中心在使用中可集中在物理上分散的诸如存储器、加速器(例如,GPU、图形加速器、FPGA、ASIC、神经网络和/或人工智能加速器等)和数据存储驱动器之类的资源,并且根据需要将它们提供给计算资源(例如,处理器),从而使计算资源能够就好像被集中的资源在本地那样访问这些被集中的资源。
功率供应或功率源可将电压和/或电流提供给系统1400或本文中描述的任何部件或系统。在一个示例中,功率供应包括用于插入到墙壁插座中的AC-DC(交流-直流)适配器。此类AC功率可以是可再生能源(例如,太阳能)功率源。在一个示例中,功率源包括DC功率源,诸如,外部AC-DC转换器。功率源或功率供应可包括用于通过接近充电场来充电的无线充电硬件。功率源可包括内部电池、交流供应、基于动作的功率供应、太阳能功率供应、或燃料电池源。
图15A-图15C图示计算系统和图形处理器。图15A-图15C的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。
图15A是处理器1500的框图,该处理器1500可以是处理器1402中的一个处理器的变体,并且可以替代那些处理器中的一个处理器被使用。因此,本文中结合处理器1500对任何特征的公开也公开了对应的与(一个或多个)处理器1402的结合,但不限于此。处理器1500可具有一个或多个处理器核心1502A-1502N、集成存储器控制器1514、以及集成图形处理器1508。在集成图形处理器1508被排除的情况下,包括处理器的系统将包括系统芯片组内的、或经由系统总线耦合的图形处理器设备。处理器1500可包括附加的核心,这些附加的核心最多由虚线框表示的附加核心1502N并包括由虚线框表示的附加核心1502N。处理器核心1502A-1502N中的每一个包括一个或多个内部缓存单元1504A-1504N。在一些实施例中,每个处理器核心1502A-1502N也具有对一个或多个共享缓存单元1506的访问权。内部缓存单元1504A-1504N和共享缓存单元1506表示处理器1500内的缓存存储器层次体系。缓存存储器层次体系可包括每个处理器核心内的至少一个级别的指令和数据缓存以及一个或多个级别的共享的中级缓存,诸如,第二级(L2)、第三级(L3)、第四级(L4)、或其他级别的缓存,其中,在外部存储器之前的最高级别的缓存被分类为LLC。在一些实施例中,缓存一致性逻辑维持各缓存单元1506与1504A-1504N之间的一致性。
处理器1500还可包括一个或多个总线控制器单元的集合1516和系统代理核心1510。一个或多个总线控制器单元1516管理外围总线的集合,诸如,一个或多个PCI总线或PCI快速总线。系统代理核心1510提供对各处理器部件的管理功能。系统代理核心1510可包括用于管理对各种外部存储器设备(未示出)的访问的一个或多个集成存储器控制器1514。
例如,处理器核心1502A-1502N中的一个或多个处理器核心可包括针对同步多线程操作的支持。系统代理核心1510包括用于在多线程处理期间协调并操作核心1502A-1502N的部件。系统代理核心1510可附加地包括功率控制单元(power control unit,PCU),该功率控制单元(PCU)包括用于调节处理器核心1502A-1502N和图形处理器1508的功率状态的逻辑和部件。
处理器1500可附加地包括用于执行图形处理操作的图形处理器1508。在这些实施例中的一些实施例中,图形处理器1508与共享缓存单元的集合1506以及系统代理核心1510耦合,该系统代理核心1510包括一个或多个集成存储器控制器1514。系统代理核心1510还可包括用于将图形处理器输出驱动到一个或多个经耦合的显示器的显示控制器1511。显示控制器1511还可以是经由至少一个互连与图形处理器耦合的单独模块,或者可以集成在图形处理器1508内。
基于环的互连1512可用于耦合处理器1500的内部部件。然而,可以使用替代的互连单元,诸如,点到点互连、交换式互连、或其他技术,包括本领域中公知的技术。在具有基于环的互连1512的这些实施例中的一些实施例中,图形处理器1508经由I/O链路1513与基于环的互连1512耦合。
示例性I/O链路1513表示多个各种各样的I/O互连中的至少一种,包括促进各处理器部件与高性能存储器模块1518(诸如,eDRAM模块或高带宽存储器(high-bandwidthmemory,HMB)模块)之间的通信的封装上I/O互连。处理器核心1502A-1502N以及图形处理器1508可将存储器模块1518用作本地处理器模块或共享的最后一级缓存。
处理器核心1502A-1502N可以例如是执行相同的指令集体系结构的同构核心。替代地,处理器核心1502A-1502N在指令集体系结构(instruction set architecture,ISA)方面是异构的,其中,处理器核心1502A-1502N中的一个或多个执行第一指令集,而其他核心中的至少一个执行第一指令集的子集或不同的指令集。处理器核心1502A-1502N在微体系结构方面可以是异构的,其中,具有相对较高功耗的一个或多个核心与具有较低功耗的一个或多个功率核心耦合。作为另一示例,处理器核心1502A-1502N在计算能力方面是异构的。此外,处理器1500可在一个或多个芯片上实现,或者被实现为除其他部件之外还具有所图示的部件的SoC集成电路。
图15B是根据本文中所描述的一些实施例的图形处理器核心1519的硬件逻辑的框图。图形处理器核心1519(有时称为核心切片)可以是模块化图形处理器内的一个或多个图形核心。图形处理器核心1519是一个图形核心切片的示例,并且基于目标功率包络和性能包络,如本文中所描述的图形处理器可包括多个图形核心切片。每个图形处理器核心1519可包括固定功能块1530,该固定功能块1530与多个子核心1521A-1521F(也称为子切片)耦合,多个子核心1521A-1521F包括模块化的通用和固定功能逻辑的块。在一种配置中,多个子核心1521A-1521F中的子核心(子切片)在体系结构上等效于图2D的图形多处理器234、图3A的图形多处理器325和/或图3C的多核心组365A-365N中的多核心组。
固定功能块1530可包括几何/固定功能管线1531,该几何/固定功能管线1531例如在较低性能和/或较低功率的图形处理器实现方式中可由图形处理器核心1519中的所有子核心共享。几何/固定功能管线1531可包括3D固定功能管线(例如,如在下文描述的图16A中的3D管线1612)、视频前端单元、线程生成器和线程调遣器、以及统一返回缓冲器管理器,该统一返回缓冲器管理器管理统一返回缓冲器(例如,如下文所描述的在图17中的统一返回缓冲器1718)。
固定功能块1530还可包括图形SoC接口1532、图形微控制器1533和媒体管线1534。图形SoC接口1532提供图形处理器核心1519与片上系统集成电路内的其他处理器核心之间的接口。图形微控制器1533是可被配置成管理图形处理器核心1519的各种功能的可编程子处理器,这些功能包括线程调遣、调度和抢占。媒体管线1534(例如,图16A和图17的媒体管线1616)包括用于促进对包括图像数据和视频数据的多媒体数据进行解码、编码、预处理和/或后处理的逻辑。媒体管线1534经由对子核心1521A-1521F内的计算或采样逻辑的请求来实现媒体操作。
SoC接口1532可使图形处理器核心1519能够与通用应用处理器核心(例如,CPU)和/或SoC内的其他部件进行通信,其他部件包括诸如共享的最后一级缓存存储器之类的存储器层次体系元件、系统RAM、和/或嵌入式芯片上或封装上DRAM。SoC接口1532还可启用与SoC内的诸如相机成像管线之类的固定功能设备的通信,并且启用全局存储器原子性的使用和/或实现全局存储器原子性,该全局存储器原子性可在图形处理器核心1519与SoC内的CPU之间被共享。SoC接口1532还可实现针对图形处理器核心1519的功率管理控制,并且启用图形处理器核心1519的时钟域与SoC内的其他时钟域之间的接口。任选地,SoC接口1532使得能够从命令流转化器和全局线程调遣器接收命令缓冲器,该命令流转化器和全局线程调遣器配置成用于将命令和指令提供给图形处理器内的一个或多个图形核心中的每一个图形核心。当媒体操作要被执行时,这些命令和指令可以被调遣给媒体管线1534,或者当图形处理操作要被执行时,这些命令和指令可以被调遣给几何和固定功能管线(例如,几何和固定功能管线1531、几何和固定功能管线1537)。
图形微控制器1533可被配置成用于执行针对图形处理器核心1519的各种调度任务和管理任务。在一个配置中,图形微控制器1533可例如对子核心1521A-1521F内的执行单元(execution unit,EU)阵列1522A-1522F、1524A-1524F内的各种图形并行引擎执行图形和/或计算工作负载调度。在该工作负载调度中,在包括图形处理器核心1519的SoC的CPU核心上执行的主机软件可将工作负载提交到多个图形处理器门铃(doorbell)中的一个图形处理器门铃,这调用了对适当的图形引擎的调度操作。调度操作包括:确定接下来要运行哪个工作负载,将工作负载提交到命令流转化器,抢占在引擎上运行的现有工作负载,监测工作负载的进度,以及当工作负载完成时通知主机软件。任选地,图形微控制器1533还可促进图形处理器核心1519的低功率或空闲状态,从而向图形处理器核心1519提供独立于操作系统和/或系统上的图形驱动器软件、跨低功率状态转变来保存和恢复图形处理器核心1519内的寄存器的能力。
图形处理器核心1519可具有多于或少于所图示的子核心1521A-1521F,最多N个模块化子核心。对于N个子核心的每个集合,图形处理器核心1519还可包括共享功能逻辑1535、共享和/或缓存存储器1536、几何/固定功能管线1537、以及用于加速各种图形和计算处理操作的附加的固定功能逻辑1538。共享功能逻辑1535可包括与图17的共享功能逻辑1720(例如,采样器逻辑、数学逻辑、和/或线程间通信逻辑)相关联的、可由图形处理器核心1519内的每N个子核心共享的逻辑单元。共享和/或缓存存储器1536可以是用于图形处理器核心1519内的N个子核心的集合1521A-1521F的最后一级缓存,并且还可以充当可由多个子核心访问的共享存储器。几何/固定功能管线1537而不是几何/固定功能管线1531可被包括在固定功能块1530内,并且几何/固定功能管线1537可包括相同或类似的逻辑单元。
图形处理器核心1519可包括附加的固定功能逻辑1538,该附加的固定功能逻辑1538可包括供由图形处理器核心1519使用的各种固定功能加速逻辑。任选地,附加的固定功能逻辑1538包括供在仅位置着色中使用的附加的几何管线。在仅位置着色中,存在两个几何管线:几何/固定功能管线1538、1531内的完全几何管线;以及剔除管线,其是可被包括在附加的固定功能逻辑1538内的附加的几何管线。例如,剔除管线可以是完全几何管线的精简版本。完全管线和剔除管线可以执行同一应用的不同实例,每个实例具有单独的上下文。仅位置着色可以隐藏被丢弃三角形的长剔除运行,从而在一些实例中使得着色能够更早地被完成。例如,附加的固定功能逻辑1538内的剔除管线逻辑可以与主应用并行地执行位置着色器,并且通常比完全管线更快地生成关键结果,因为剔除管线仅取得顶点的位置属性并且仅对顶点的位置属性进行着色,而不对去往帧缓冲器的像素执行栅格化和渲染。剔除管线可以使用所生成的关键结果来计算所有三角形的可见性信息,而无需考虑那些三角形是否被剔除。完全管线(其在本实例中可以被称为重放(replay)管线)可以消耗该可见性信息以跳过被剔除的三角形,从而仅对最终被传递到栅格化阶段的可见的三角形进行着色。
任选地,附加的固定功能逻辑1538还可包括机器学习加速逻辑,诸如,固定功能矩阵乘法逻辑,该机器学习加速逻辑用于包括针对机器学习训练或推断的优化的实现方式。
在每个图形子核心1521A-1521F内包括可用于响应于由图形管线、媒体管线、或着色器程序作出的请求而执行图形操作、媒体操作和计算操作的执行资源的集合。图形子核心1521A-1521F包括:多个EU阵列1522A-1522F、1524A-1524F;线程调遣和线程间通信(thread dispatch and inter-thread communication,TD/IC)逻辑1523A-1523F;3D(例如,纹理)采样器1525A-1525F;媒体采样器1526A-1526F;着色器处理器1527A-1527F;以及共享的本地存储器(shared local memory,SLM)1528A-1528F。EU阵列1522A-1502F、1524A-1524F各自包括多个执行单元,这些执行单元是能够执行浮点和整数/定点逻辑操作以服务于图形操作、媒体操作或计算操作(包括图形程序、媒体程序或计算着色器程序)的通用图形处理单元。TD/IC逻辑1523A-1523F执行针对子核心内的执行单元的本地线程调遣和线程控制操作,并且促进在子核心的执行单元上执行的线程之间的通信。3D采样器1525A-1525F可将纹理或其他3D图形相关的数据读取到存储器中。3D采样器可基于所配置的样本状态以及与给定纹理相关联的纹理格式以不同方式读取纹理数据。媒体采样器1526A-1526F可基于与媒体数据相关联的类型和格式来执行类似的读取操作。例如,每个图形子核心1521A-1521F可替代地包括统一3D和媒体采样器。在子核心1521A-1521F中的每个子核心内的执行单元上执行的线程可利用每个子核心内的共享的本地存储器1528A-1528F,以使在线程组内执行的线程能够使用片上存储器的共同的池来执行。
图15C是根据本文中描述的实施例的通用图形处理器单元(GPGPU)1570的框图,该GPGPU 1570可被配置为图形处理器(例如,图形处理器1508)和/或计算加速器。GPGPU 1570可经由一个或多个系统和/或存储器总线与主机处理器(例如,一个或多个CPU 1546)和存储器1571、1572互连。存储器1571可以是可与一个或多个CPU 1546进行共享的系统存储器,而存储器1572是专用于GPGPU 1570的设备存储器。例如,GPGPU 1570和设备存储器1572内的部件可被映射到可由一个或多个CPU 1546访问的存储器地址中。可经由存储器控制器1568来促进对存储器1571和1572的访问。存储器控制器1568可包括内部直接存储器存取(direct memory access,DMA)控制器1569,或可包括用于执行否则将由DMA控制器执行的操作的逻辑。
GPGPU 1570包括多个缓存存储器,这些缓存存储器包括L2缓存1553、L1缓存1554、指令缓存1555、以及共享存储器1556,该共享存储器1556的至少部分也可被分区为缓存存储器。GPGPU 1570还包括多个计算单元1560A-1560N。每个计算单元1560A-1560N包括向量寄存器的集合1561、标量寄存器的集合1562、向量逻辑单元的集合1563、以及标量逻辑单元的集合1564。计算单元1560A-1560N还可包括本地共享存储器1565和程序计数器1566。计算单元1560A-1560N可与常量缓存1567耦合,该常量缓存1567可用于存储常量数据,该常量数据是将在GPGPU 1570上执行的核心程序或着色器程序的运行期间不会改变的数据。常量缓存1567可以是标量数据缓存,并且经缓存的数据可被直接取到标量寄存器1562中。
在操作期间,一个或多个CPU 1546可将命令写入到GPGPU 1570中的寄存器中,或写入到GPGPU 1570中的、已经被映射到可访问地址空间中的存储器中。命令处理器1557可从寄存器或存储器读取命令,并且确定如何将在GPGPU 1570内处理那些命令。随后可使用线程调遣器1558来将线程调遣给计算单元1560A-1560N以执行那些命令。每个计算单元1560A-1560N可独立于其他计算单元来执行线程。此外,每个计算单元1560A-1560N可被独立地配置成用于有条件计算,并且可有条件地将计算的结果输出到存储器。当所提交的命令完成时,命令处理器1557可中断一个或多个CPU 1546。
图16A-图16C图示由本文中描述、例如根据图15A-图15C的实施例提供的附加的图形处理器和计算加速器体系结构的框图。图16A-图16C的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。
图16A是图形处理器1600的框图,该图形处理器1600可以是分立的图形处理单元,或可以是与多个处理核心或其他半导体器件集成的图形处理器,其他半导体器件诸如但不限于存储器设备或网络接口。图形处理器1600可以是图形处理器1508的变体,并且可替代图形处理器1508被使用。因此,本文中结合图形处理器1508对任何特征的公开也公开了对应的与图形处理器1600的结合,但不限于此。图形处理器可经由至图形处理器上的寄存器的存储器映射的I/O接口并且利用被放置到处理器存储器中的命令进行通信。图形处理器1600可包括用于访问存储器的存储器接口1614。存储器接口1614可以是至本地存储器、一个或多个内部缓存、一个或多个共享的外部缓存、和/或至系统存储器的接口。
任选地,图形处理器1600还包括用于将显示输出数据驱动到显示设备1618的显示控制器1602。显示控制器1602包括用于显示器的一个或多个叠加平面以及多层的视频或用户界面元素的合成的硬件。显示设备1618可以是内部或外部显示设备。在一个实施例中,显示设备1618是头戴式显示设备,诸如,虚拟现实(VR)显示设备或增强现实(AR)显示设备。图形处理器1600可包括用于将媒体编码到一种或多种媒体编码格式,从一种或多种媒体编码格式对媒体解码,或在一种或多种媒体编码格式之间对媒体转码的视频编解码器引擎1606,这一种或多种媒体编码格式包括但不限于:移动图片专家组(Moving PictureExperts Group,MPEG)格式(诸如,MPEG-2)、高级视频译码(Advanced Video Coding,AVC)格式(诸如,H.264/MPEG-4 AVC、H.265/HEVC、开放媒体联盟(Alliance for Open Media,AOMedia)VP8、VP9)、以及电影和电视工程师协会(the Society of Motion Picture&Television Engineers,SMPTE)421M/VC-1、和联合图像专家组(Joint PhotographicExperts Group,JPEG)格式(诸如,JPEG、以及运动JPEG(Motion JPEG,MJPEG)格式)。
图形处理器1600可包括块图像传输(block image transfer,BLIT)引擎1603,用于执行二维(2D)栅格化器操作,包括例如,比特边界块传输。然而,替代地,可使用图形处理引擎(graphics processing engine,GPE)1610的一个或多个部件执行2D图形操作。在一些实施例中,GPE 1610是用于执行图形操作的计算引擎,这些图形操作包括三维(3D)图形操作和媒体操作。
GPE 1610可包括用于执行3D操作的3D管线1612,该3D操作诸如,使用作用于3D基元形状(例如,矩形、三角形等)的处理函数来渲染三维图像和场景。3D管线1612包括可编程和固定功能元件,这些可编程和固定功能元件执行元件内的各种任务和/或生成到3D/媒体子系统1615的执行线程。虽然3D管线1612可用于执行媒体操作,但是GPE 1610的实施例还包括媒体管线1616,该媒体管线1616专门用于执行媒体操作,诸如,视频后处理和图像增强。
媒体管线1616可包括固定功能或可编程逻辑单元,用于代替、或代表视频编解码器引擎1606来执行一个或多个专业的媒体操作,诸如,视频解码加速、视频去隔行、以及视频编码加速。媒体管线1616可附加地包括线程生成单元,用于生成线程以供在3D/媒体子系统1615上执行。所生成的线程在3D/媒体子系统1615中所包括的一个或多个图形执行单元上执行用于媒体操作的计算。
3D/媒体子系统1615可包括用于执行由3D管线1612和媒体管线1616生成的线程的逻辑。管线可将线程执行请求发送到3D/媒体子系统1615,该3D/媒体子系统1615包括用于对于对可用的线程执行资源的各种请求进行仲裁和调遣的线程调遣逻辑。执行资源包括用于处理3D线程和媒体线程的图形执行单元的阵列。3D/媒体子系统1615可包括用于线程指令和数据的一个或多个内部缓存。此外,3D/媒体子系统1615还可包括用于在线程之间共享数据并用于存储输出数据的共享存储器,其包括寄存器和可寻址存储器。
图16B图示图形处理器1620,该图形处理器1620是图形处理器1600的变体,并且可替代图形处理器1600被使用且反之亦然。因此,本文中结合图形处理器1600对任何特征的公开也公开了对应的与图形处理器1620的结合,但不限于此。根据本文中描述的实施例,图形处理器1620具有分片体系结构。图形处理器1620可包括图形处理引擎集群1622,该图形处理引擎集群1622在图形引擎片1610A-1610D内具有图16A的图形处理器引擎1610的多个实例。每个图形引擎片1610A-1610D可经由片互连的集合1623A-1623F被互连。每个图形引擎片1610A-1610D还可经由存储器互连1625A-1625D被连接到存储器模块或存储器设备1626A-1626D。存储器设备1626A-1626D可使用任何图形存储器技术。例如,存储器设备1626A-1626D可以是图形双倍数据速率(graphics double data rate,GDDR)存储器。存储器设备1626A-1626D可以是HBM模块,这些HBM可与其相应的图形引擎片1610A-1610D一起在管芯上。存储器设备1626A-1626D可以是可被堆叠在其相应的图形引擎片1610A-1610D的顶部上的堆叠式存储器设备。每个图形引擎片1610A-1610D和相关联的存储器1626A-1626D可驻留在分开的小芯片上,这些分开的小芯片被接合到基础管芯或基础衬底,如在图24B-图24D中进一步详细地所描述。
图形处理器1620可配置有非统一存储器存取(non-uniform memory access,NUMA)系统,在该NUMA系统中,存储器设备1626A-1626D与相关联的图形引擎片1610A-1610D耦合。给定的存储器设备可由与该存储器设备直接连接到的图形引擎片不同的片访问。然而,当存取本地片时,对存储器设备1626A-1626D的存取等待时间可以最低。在一个实施例中,启用缓存一致的NUMA(cache coherent NUMA,ccNUMA)系统,该ccNUMA系统使用片互连1623A-1623F来启用图形引擎片1610A-1610D内的缓存控制器之间的通信,以便当多于一个缓存存储相同的存储器位置时保持一致的存储器镜像。
图形处理引擎集群1622可与芯片上或封装上结构互连1624连接。在一个实施例中,结构互连1624包括网络处理器、片上网络(network on a chip,NoC)、或用于使结构互连1624能充当在图形处理器1620的部件之间交换数据分组的分组交换型结构互连的另一交换处理器。结构互连1624可启用图形引擎片1610A-1610D与诸如视频编解码器1606和一个或多个副本引擎1604之类的部件之间的通信。副本引擎1604可用于将数据移出存储器设备1626A-1626D和在图形处理器1620外部的存储器(例如,系统存储器),将数据移入存储器设备1626A-1626D和在图形处理器1620外部的存储器(例如,系统存储器),并且在存储器设备1626A-1626D与在图形处理器1620外部的存储器(例如,系统存储器)之间移动数据。结构互连1624还可用于将图形引擎片1610A-1610D互连。图形处理器1620可任选地包括显示控制器1602,用于启用与外部显示设备1618的连接。图形处理器还可被配置为图形加速器或计算加速器。在加速器配置中,显示控制器1602和显示设备1618可被省略。
图形处理器1620可经由主机接口1628连接到主机系统。主机接口1628可启用图形处理器1620、系统存储器和/或其他系统部件之间的通信。主机接口1628可以是例如PCI快速总线或另一类型的主机系统接口。例如,主机接口1628可以是NVLink或NVSwitch接口。主机接口1628和结构互连1624可以协作以使图形处理器1620的多个实例能充当单个逻辑设备。主机接口1628和结构互连1624之间的协作还可使各个图形引擎片1610A-1610D能够作为不同的逻辑图形设备向主机系统呈现。
图16C图示根据本文中描述的实施例的计算加速器1630。计算加速器1630可包括与图16B的图形处理器1620的体系结构类似性,并且针对计算加速进行优化。计算引擎集群1632可包括计算引擎片的集合1640A-1640D,计算引擎片的集合1640A-1640D包括针对并行或基于向量的通用计算操作优化的执行逻辑。计算引擎片1640A-1640D可以不包括固定功能图形处理逻辑,但是在一些实施例中,计算引擎片1640A-1640D中的一个或多个可包括用于执行媒体加速的逻辑。计算引擎片1640A-1640D可经由存储器互连1625A-1625D连接到存储器1626A-1626D。存储器1626A-1626D和存储器互连1625A-1625D可以是与在图形处理器1620中类似的技术,或者可以是不同的技术。图形计算引擎片1640A-1640D还可经由片互连的集合1623A-1623F被互连,并且可与结构互连1624连接和/或通过结构互连1624被互连。在一个实施例中,计算加速器1630包括可被配置为设备范围的缓存的大型L3缓存1636。计算加速器1630还能以与图16B的图形处理器1620类似的方式经由主机接口1628连接到主机处理器和存储器。
计算加速器1630还可包括集成网络接口1642。在一个实施例中,集成网络接口1642包括网络处理器和控制器逻辑,该控制器逻辑使计算引擎集群1632能够在无需数据跨越主机系统的存储器的情况下通过物理层互连1644进行通信。在一个实施例中,计算引擎片1640A-1640D中的一个由网络处理器逻辑替代,并且要经由物理层互连1644传送或接收的数据可直接向存储器1626A-1626D或从存储器1626A-1626D传送。计算加速器1630的多个实例可经由物理层互连1644被结合到单个逻辑设备中。替代地,各计算引擎片1640A-1640D可被呈现为不同的网络可访问计算加速器设备。
图形处理引擎
图17是根据一些实施例的图形处理器的图形处理引擎1710的框图。图形处理引擎(graphics processing engine,GPE)1710可以是图16A中示出的GPE 1610的某个版本,并且还可表示图16B的图形引擎片1610A-1610D。图17的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。例如,在图17中也图示图16A的3D管线1612和媒体管线1616。媒体管线1616在GPE 1710的一些实施例中是任选的,并且可以不显式地被包括在GPE 1710内。例如并且在至少一个实施例中,单独的媒体和/或图像处理器被耦合至GPE 1710。
GPE 1710可与命令流转化器1703耦合或包括命令流转化器1703,该命令流转化器1703将命令流提供给3D管线1612和/或媒体管线1616。替代地或附加地,命令流转化器1703可直接耦合至统一返回缓冲器1718。统一返回缓冲器1718可通信地耦合至图形核心阵列1714。任选地,命令流转化器1703与存储器耦合,该存储器可以是系统存储器、或内部缓存存储器和共享缓存存储器中的一个或多个。命令流转化器1703可从存储器接收命令,并且将这些命令发送至3D管线1612和/或媒体管线1616。这些命令是从环形缓冲器取得的指示,该环形缓冲器存储用于3D管线1612和媒体管线1616的命令。环形缓冲器可附加地包括存储批量的多个命令的批量命令缓冲器。用于3D管线1612的命令还可包括对存储在存储器中的数据的引用,这些数据诸如但不限于用于3D管线1612的顶点数据和几何数据和/或用于媒体管线1616的图像数据和存储器对象。3D管线1612和媒体管线1616通过经由相应的管线内的逻辑执行操作或者通过将一个或多个执行线程调遣至图形核心阵列1714来处理命令和数据。图形核心阵列1714可包括一个或多个图形核心(例如,(一个或多个)图形核心1715A、(一个或多个)图形核心1715B)的块,每个块包括一个或多个图形核心。每个图形核心包括图形执行资源的集合,该图形执行资源的集合包括:用于执行图形操作和计算操作的通用和图形专用执行逻辑;以及固定功能纹理处理逻辑和/或机器学习和人工智能加速逻辑。
在各实施例中,3D管线1612可包括用于通过处理指令并将执行线程调遣给图形核心阵列1714来处理一个或多个着色器程序的固定功能和可编程逻辑,这一个或多个着色器程序诸如,顶点着色器、几何着色器、像素着色器、片段着色器、计算着色器、或其他着色器程序。图形核心阵列1714提供统一的执行资源块,以供在处理这些着色器程序时使用。图形核心阵列1714的(一个或多个)图形核心1715A-1715B内的多功能执行逻辑(例如,执行单元)包括对各种3D API着色器语言的支持,并且可执行与多个着色器相关联的多个同步执行线程。
图形核心阵列1714可包括用于执行诸如视频和/或图像处理之类的媒体功能的执行逻辑。除了图形处理操作之外,执行单元还可包括可编程以执行并行的通用计算操作的通用逻辑。通用逻辑可并行地或结合图14的(一个或多个)处理器核心1407或图15A中的核心1502A-1502N内的通用逻辑来执行处理操作。
由在图形核心阵列1714上执行的线程生成的输出数据可以将数据输出到统一返回缓冲器(unified return buffer,URB)1718中的存储器。URB1718可存储用于多个线程的数据。URB 1718可用于在图形核心阵列1714上执行的不同线程之间发送数据。URB 1718可附加地用于在图形核心阵列1714上的线程与共享功能逻辑1720内的固定功能逻辑之间的同步。
任选地,图形核心阵列1714可以是可缩放的,使得阵列包括可变数量的图形核心,每个图形核心都具有基于GPE 1710的目标功率和性能等级的可变数量的执行单元。执行资源可以是动态地可缩放的,使得执行资源可根据需要被启用或禁用。
图形核心阵列1714与共享功能逻辑1720耦合,该共享功能逻辑1720包括在图形核心阵列中的图形核心之间被共享的多个资源。共享功能逻辑1720内的共享功能是将专业的补充功能提供给图形核心阵列1714的硬件逻辑单元。在各实施例中,共享功能逻辑1720包括但不限于采样器1721逻辑、数学1722逻辑和线程间通信(inter-thread communication,ITC)1723逻辑。此外,可实现共享功能逻辑1720内的一个或多个缓存1725。
至少在其中对于给定的专业功能的需求不足以包括在图形核心阵列1714中的情况下实现共享功能。相反,那个专业功能的单个实例化被实现为共享功能逻辑1720中的独立实体,并且在图形核心阵列1714内的执行资源之间被共享。在图形核心阵列1714之间被共享并被包括在图形核心阵列1714内的确切的功能集因实施例而异。共享功能逻辑1720内的由图形核心阵列1714广泛使用的特定共享功能可被包括在图形核心阵列1714内的共享功能逻辑1716内。任选地,图形核心阵列1714内的共享功能逻辑1716可包括共享功能逻辑1720内的一些或所有逻辑。共享功能逻辑1720内的所有逻辑元件可以在图形核心阵列1714的共享功能逻辑1716内被复制。替代地,共享功能逻辑1720被排除以有利于图形核心阵列1714内的共享功能逻辑1716。
执行单元
图18A-图18B图示根据本文中所描述的实施例的线程执行逻辑1800,该线程执行逻辑1800包括在图形处理器核心中采用的处理元件的阵列。图14-图18B的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。图18A-图18B图示线程执行逻辑1800的概览,该线程执行逻辑1800可表示以图15B的每个子核心1521A-1521F图示的硬件逻辑。图18A表示通用图形处理器内的执行单元,而图18B表示可在计算加速器内被使用的执行单元。
如在图18A中所图示,线程执行逻辑1800可包括着色器处理器1802、线程调遣器1804、指令缓存1806、包括多个图形执行单元1808A-1808N的可缩放执行单元阵列、采样器1810、共享本地存储器1811、数据缓存1812、以及数据端口1814。任选地,可缩放执行单元阵列可通过基于工作负载的计算要求启用或禁用一个或多个执行单元(例如,执行单元1808A、1808B、1808C、1808D,一直到1808N-1和1808N中的任一个)来动态地缩放。所包括的部件可经由互连结构被互连,该互连结构链接到部件中的每个部件。线程执行逻辑1800可包括通过指令缓存1806、数据端口1814、采样器1810、以及图形执行单元1808A-1808N中的一个或多个而到存储器(诸如,系统存储器或缓存存储器)的一个或多个连接。每个执行单元(例如,1808A)可以是能够执行多个同步硬件线程同时针对每个线程并行地处理多个数据元素的独立式可编程通用计算单元。在各实施例中,执行单元1808A-1808N的阵列是可缩放的以包括任何数量的单独执行单元。
在一些实施例中,执行单元1808A-1808N可以主要用于执行着色器程序。着色器处理器1802可处理各种着色器程序,并且可经由线程调遣器1804调遣与着色器程序相关联的执行线程。线程调遣器可包括用于对来自图形管线和媒体管线的线程发起请求进行仲裁并在图形执行单元1808A-1808N中的一个或多个图形执行单元上实例化所请求的线程的逻辑。例如,几何管线可将顶点着色器、曲面细分着色器或几何着色器调遣给线程执行逻辑以用于处理。任选地,线程调遣器1804也可处理来自执行着色器程序的运行时线程生成请求。
在一些实施例中,图形执行单元1808A-1808N可支持包括对许多标准3D图形着色器指令的原生支持的指令集,使得以最小的转换执行来自图形库(例如,Direct 3D和OpenGL)的着色器程序。这些执行单元支持顶点和几何处理(例如,顶点程序、几何程序、顶点着色器)、像素处理(例如,像素着色器、片段着色器)以及通用处理(例如,计算和媒体着色器)。执行单元1808A-1808N中的每个执行单元都能够进行多发出单指令多数据(singleinstruction multiple data,SIMD)执行,并且多线程操作在面对较高等待时间的存储器访问时启用高效的执行环境。每个执行单元内的每个硬件线程都具有专用的高带宽寄存器堆和相关联的独立线程状态。对于能够进行整数操作、单精度浮点操作和双精度浮点操作、能够具有SIMD分支能力、能够进行逻辑操作、能够进行超越操作和能够进行其他混杂操作的管线,执行是针对每个时钟多发出的。在等待来自存储器或共享功能中的一个共享功能的数据时,执行单元1808A-1808N内的依赖性逻辑使等待的线程休眠,直到所请求的数据已返回。当等待的线程正在休眠时,硬件资源可致力于处理其他线程。例如,在与顶点着色器操作相关联的延迟期间,执行单元可执行针对像素着色器、片段着色器或包括不同顶点着色器的另一类型的着色器(诸如,图21中图示的顶点着色器2107)程序的操作。各实施例可应用以使用利用单指令多线程(Single Instruction Multiple Thread,SIMT)的执行,作为对SIMD的使用的替代,或作为对SIMD的使用的附加。对SIMD核心或操作的引用也可应用于SIMT,或应用于SIMD与SIMT的组合。
图形执行单元1808A-1808N中的每个执行单元对数据元素的数组进行操作。数据元素的数量是“执行大小”、或用于指令的通道的数量。执行通道是用于指令内的数据元素访问、掩蔽、和流控制的执行的逻辑单元。通道的数量可独立于用于特定图形处理器的物理算术逻辑单元(Arithmetic Logic Unit,ALU)、浮点单元(Floating-Point Unit,FPU)、或其他逻辑单元(例如,张量核心、光线追踪核心等)的数量。此外,图形执行单元1808A-1808N可支持整数和浮点数据类型。
执行单元指令集包括SIMD指令。各种数据元素可以作为紧缩数据类型存储在寄存器中,并且执行单元将基于元素的数据大小来处理各个元素。例如,当对256比特宽的向量进行操作时,向量的256比特被存储在寄存器中,并且执行单元将向量操作为四个单独的64比特紧缩数据元素(四字(Quad-Word,QW)大小数据元素)、八个单独的32比特紧缩数据元素(双字(Double Word,DW)大小数据元素)、十六个单独的16比特紧缩数据元素(字(Word,W)大小数据元素)、或三十二个单独的8比特数据元素(字节(byte,B)大小数据元素)。然而,不同的向量宽度和寄存器大小是可能的。
任选地,可将一个或多个执行单元组合到融合图形执行单元1809A-1809N中,该融合执行单元1809A-1809N具有对于融合EU而言共同的线程控制逻辑(1807A-1807N)。可以将多个EU融合到EU组中。融合的EU组中的每个EU可以配置成用于执行单独的SIMD硬件线程。融合的EU组中的EU的数量可以根据实施例而有所不同。此外,可以逐EU地执行各种SIMD宽度,包括但不限于SIMD8、SIMD16和SIMD32。每个融合图形执行单元1809A-1809N包括至少两个执行单元。例如,融合执行单元1809A包括第一EU 1808A、第二EU 1808B、以及对于第一EU1808A和第二EU 1808B而言共同的线程控制逻辑1807A。线程控制逻辑1807A控制在融合图形执行单元1809A上执行的线程,从而允许融合执行单元1809A-1809N内的每个EU使用共同的指令指针寄存器来执行。
一个或多个内部指令缓存(例如,1806)被包括在线程执行逻辑1800中,以对用于执行单元的线程指令进行缓存。一个或多个数据缓存(例如,1812)可被包括在线程执行逻辑1800中,以在线程执行期间对线程数据进行缓存。在执行逻辑1800上执行的线程还可将被显式地管理的数据存储在共享本地存储器1811中。采样器1810可被包括,以便为3D操作提供纹理采样,并为媒体操作提供媒体采样。采样器1810可包括专业的纹理或媒体采样功能,以便在将所采样的数据提供给执行单元之前在采样过程期间处理纹理数据或媒体数据。
在执行期间,图形管线和媒体管线经由线程生成和调遣逻辑将线程发起请求发送到线程执行逻辑1800。一旦几何对象的组已经被处理并被栅格化为像素数据,着色器处理器1802内的像素处理器逻辑(例如,像素着色器逻辑、片段着色器逻辑等)就被调用以进一步计算输出信息,并且使得结果被写入到输出表面(例如,颜色缓冲器、深度缓冲器、模版印刷缓冲器等)。像素着色器或片段着色器可计算各顶点属性的值,各顶点属性的值将跨经栅格化的对象而被内插。着色器处理器1802内的像素处理器逻辑随后可执行应用编程接口(API)供应的像素着色器程序或片段着色器程序。为了执行着色器程序,着色器处理器1802经由线程调遣器1804将线程调遣给执行单元(例如,1808A)。着色器处理器1802可使用采样器1810中的纹理采样逻辑来访问存储在存储器中的纹理映射中的纹理数据。对纹理数据和输入几何数据的算术操作计算针对每个几何片段的像素颜色数据,或丢弃一个或多个像素而不进行进一步处理。
此外,数据端口1814可提供存储器访问机制,以供线程执行逻辑1800将经处理的数据输出至存储器以便在图形处理器输出管线上进一步处理。数据端口1814可包括或耦合至一个或多个缓存存储器(例如,数据缓存1812),以便对数据进行缓存,以用于经由数据端口1814进行存储器访问。
任选地,执行逻辑1800还可包括可提供光线追踪加速功能的光线追踪器1805。光线追踪器1805可支持光线追踪指令集,该光线追踪指令集包括用于光线生成的指令/函数。光线追踪指令集可与由图3C中的光线追踪核心372支持的光线追踪指令集类似或不同。
图18B图示执行单元1808的示例性内部细节。图形执行单元1808可包括指令取得单元1837、通用寄存器堆阵列(general register file array,GRF)1824、体系结构寄存器堆阵列(architectural register file array,ARF)1826、线程仲裁器1822、发送单元1830、分支单元1832、SIMD浮点单元(floating point unit,FPU)的集合1834,并任选地包括专用整数SIMD ALU的集合1835。GRF 1824和ARF 1826包括与可在图形执行单元1808中活跃的每个同步硬件线程相关联的通用寄存器堆和体系结构寄存器堆的集合。每线程体系结构状态可被维持在ARF 1826中,而在线程执行期间使用的数据被存储在GRF 1824中。每个线程的执行状态,包括用于每个线程的指令指针,可以被保存在ARF1826中的线程专用寄存器中。
图形执行单元1808可具有作为同步多线程(Simultaneous Multi-Threading,SMT)与细粒度交织多线程(Interleaved Multi-Threading,IMT)的组合的体系结构。该体系结构可具有模块化配置,该模块化配置可以在设计时基于同步线程的目标数量和每个执行单元的寄存器的数量进行微调,其中跨用于执行多个同步线程的逻辑来划分执行单元资源。可由图形执行单元1808执行的逻辑线程的数量不限于硬件线程的数量,并且可将多个逻辑线程指派给每个硬件线程。
任选地,图形执行单元1808可协同发出多条指令,这些指令可以各自是不同的指令。图形执行单元1808的线程仲裁器1822可以将指令调遣给以下各项中的一项以供执行:发送单元1830、分支单元1832或(一个或多个)SIMD FPU 1834。每个执行线程可访问GRF1824内的128个通用寄存器,其中,每个寄存器可存储可作为具有32比特数据元素的SIMD 8元素向量访问的32个字节。每个执行单元线程可具有对GRF 1824内的4个千字节的访问权,但是实施例不限于此,并且在其他实施例中可以提供更多或更少的寄存器资源。图形执行单元1808可被分区为能够独立地执行计算操作的七个硬件线程,但是每个执行单元的线程的数量还可根据实施例而有所不同,例如,可支持最多16个硬件线程。在其中七个线程可访问4个千字节的示例性实施例中,GRF 1824可以存储总共28个千字节。在其中16个线程可访问4个千字节的另一示例性实施例中,GRF 1824可存储总共64个千字节。然而,每个执行单元的线程的数量不限于那些示例,并且可以多于或少于给定的数量。灵活的寻址模式可准许对寄存器一起进行寻址,从而建立实际上更宽的寄存器或者表示跨步式矩形块数据结构。
附加地或替代地,可经由通过消息传递发送单元1830执行的“发送”指令来调遣存储器操作、采样器操作以及其他较长等待时间的系统通信。分支指令可被调遣给专用分支单元1832,以促进SIMD分散和最终的汇聚。
图形执行单元1808可包括用于执行浮点操作的一个或多个SIMD浮点单元(floating point unit,FPU)1834。(一个或多个)FPU 1834还可支持整数计算。在一些实例中,(一个或多个)FPU 1834可以SIMD执行最多数量M个32比特浮点(或整数)操作,或者SIMD执行最多2M个16比特整数或16比特浮点操作。任选地,(一个或多个)FPU中的至少一个提供支持高吞吐量超越数学函数和双精度64比特浮点的扩展数学能力。8比特整数SIMD ALU的集合1835也可存在,并且可专门优化成用于执行与机器学习计算相关联的操作。
任选地,可以在图形子核心分组(例如,子切片)中对图形执行单元1808的多个实例的阵列进行实例化。为了可缩放性,产品体系结构师可以选择每子核心分组的执行单元的确切数量。执行单元1808可跨多个执行通道执行指令。此外,在图形执行单元1808上执行的每个线程可在不同的通道上执行。
图19图示进一步的示例性执行单元1900。图19的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。执行单元1900可以是用于在例如图16C中的计算引擎片1640A-1640D中使用的计算优化的执行单元,但不限于此。执行单元1900也可在图16B中的图形引擎片1610A-1610D中使用。执行单元1900可包括线程控制单元1901、线程状态单元1902、指令取得/预取单元1903、以及指令解码单元1904。执行单元1900可附加地包括寄存器堆1906,该寄存器堆1906存储可被指派给执行单元内的硬件线程的寄存器。执行单元1900可附加地包括发送单元1907和分支单元1908。发送单元1907和分支单元1908能以与图18B的图形执行单元1808的发送单元1830和分支单元1832类似的方式操作。
执行单元1900还可包括计算单元1910,该计算单元1910包括多个不同类型的功能单元。计算单元1910还可包括ALU 1911、脉动阵列1912和数学单元1913。ALU 1911包括算术逻辑单元的阵列。ALU 1911可被配置成用于跨多个处理通路和数据通道并且针对多个硬件和/或软件线程执行64比特、32比特和16比特整数操作和浮点操作。ALU 1911可同时(例如,在同一时钟周期内)执行整数操作和浮点操作。
脉动阵列1912包括数据处理单元的宽W且深D的网络,其可用于以脉动方式执行向量或其他数据并行操作。脉动阵列1912可被配置成用于执行各种矩阵操作,包括点积操作、外积操作、以及一般矩阵-矩阵乘法(general matrix-matrix multiplication,GEMM)操作。脉动阵列1912可支持16比特浮点操作以及8比特、4比特、2比特和二进制的整数操作。脉动阵列1912可被配置成用于加速机器学习操作。脉动阵列1912可配置有对于相对于电气和电子工程师学会(Institute of Electrical and Electronics Engineers,IEEE)754格式具有不同数量的尾数比特和指数比特的bfloat16、(brain浮点)16比特浮点格式、或张量浮点32比特浮点格式(TF32)的支持。也可支持FP64格式。
在一个实施例中,脉动阵列1912包括用于加速稀疏矩阵操作的硬件。可绕过用于输入数据的稀疏区域的乘法操作而不牺牲吞吐量。可检测输入矩阵内的块稀疏度,并且可绕过具有已知输出值的操作。在一个实施例中,脉动阵列1912包括用于启用对具有压缩表示的稀疏数据的操作的硬件。稀疏矩阵的压缩表示存储非零值和元数据,该元数据定义矩阵内的非零值的位置。示例性压缩表示包括但不限于压缩张量表示,诸如,压缩稀疏行(compressed sparse row,CSR)表示、压缩稀疏列(compressed sparse column,CSC)表示、和压缩稀疏纤维(compressed sparse fiber,CSF)表示。对压缩表示的支持使得操作能够对按压缩张量格式的输入执行而无需压缩表示被解压缩或解码。在此类实施例中,可仅对非零输入值执行操作,并且所得到的非零输出值可被映射到输出矩阵中。在一些实施例中,还提供对机器专用无损数据压缩格式的硬件支持,这些机器专用无损数据压缩格式当在硬件内传送数据或跨系统总线传送数据时被使用。此类数据可按用于稀疏输入数据的压缩格式被保留,并且脉动阵列1912可使用用于经压缩数据的压缩元数据,以使得操作能够对仅非零值执行或使得对于乘法操作能够绕过零数据输入的块。
数学单元1913可被配置成用于以高效的且比ALU1911更低功率的方式执行数学操作的特定子集。数学单元1913可包括可在由所描述的其他实施例提供的图形处理引擎的共享功能逻辑中发现的数学逻辑,例如,图17的共享功能逻辑1722的数学逻辑1720。数学单元1913可被配置成用于执行32比特和64比特浮点操作。
线程控制单元1901包括用于控制执行单元内的线程的执行的逻辑。线程控制单元1901可包括线程仲裁逻辑,该线程仲裁逻辑用于启动、停止以及抢占执行单元1900内线程的执行。线程状态单元1902可用于存储用于被指派以在执行单元1900上执行的线程的线程状态。将线程状态存储在执行单元1900内使得能够在线程变得被阻止或空闲时快速抢占那些线程。指令取得/预取单元1903可从较高级别执行逻辑的指令缓存(例如,如图18A中的指令缓存1806)取得指令。指令取得/预取单元1903还可基于对当前执行线程的分析来发出对要被加载到指令缓存中的指令的预取请求。指令解码单元1904可用于对要由计算单元执行的指令进行解码。指令解码单元1904可被用作次级解码器以将复杂指令解码为组成的微操作。
执行单元1900附加地包括寄存器堆1906,该寄存器堆1906可由在执行单元1900上执行的硬件线程使用。寄存器堆1906中的寄存器可跨用于执行执行单元1900的计算单元1910内的多个同步线程的逻辑而被划分。可由图形执行单元1900执行的逻辑线程的数量不限于硬件线程的数量,并且可将多个逻辑线程指派给每个硬件线程。基于所支持的硬件线程的数量,寄存器堆1906的大小可因实施例而异。可使用寄存器重命名来动态地将寄存器分配给硬件线程。
图20是图示图形处理器指令格式2000的框图。图形处理器执行单元支持具有按照多种格式的指令的指令集。实线框图示通常被包括在执行单元指令中的组成部分,而虚线包括任选的或仅被包括在指令的子集中的组成部分。在一些实施例中,所描述和图示的图形处理器指令格式2000是宏指令,因为它们是供应至执行单元的指令,这与产生自一旦指令被处理就进行的指令解码的微操作相反。因此,单个指令可使硬件执行多个微操作。
如本文中所描述的图形处理器执行单元可以原生地支持128比特指令格式2010的指令。基于所选择的指令、指令选项和操作对象数量,64比特紧凑指令格式2030可用于一些指令。原生的128比特指令格式2010提供对所有指令选项的访问,而一些选项和操作在64比特格式2030中受限。64比特格式2030中可用的原生指令因实施例而异。使用索引字段2013中的索引值的集合将指令部分地压缩。执行单元硬件基于索引值来引用压缩表的集合,并使用压缩表输出来重构128比特指令格式2010的原生指令。可以使用其他大小和格式的指令。
针对每种格式,指令操作码2012限定执行单元要执行的操作。执行单元跨每个操作对象的多个数据元素并行地执行每条指令。例如,响应于加法指令,执行单元跨表示纹理元素或图片元素的每个颜色通道执行同步加法操作。默认地,执行单元跨操作对象的所有数据通道执行每条指令。指令控制字段2014可启用对某些执行选项(诸如,通道选择(例如,谓词(predication))和数据通道顺序(例如,拌和(swizzle)))的控制。针对128比特指令格式2010的指令,执行大小字段2016限制将被并行地执行的数据通道的数量。执行大小字段2016可能不可用于64比特紧凑指令格式2030。
一些执行单元指令具有最多三个操作对象,包括两个源操作对象src0 2020、src12022以及一个目的地操作对象(dest 2018)。其他指令(诸如,例如数据操纵指令、点积指令、乘加指令、或乘法累加指令)可具有第三源操作对象(例如,SRC2 2024),指令操作码2012确定源操作对象的数量。指令的最后一个源操作对象可以是与指令一起被传递的立即数(例如,硬编码的)值。执行单元还可以支持多个目的地指令,其中目的地中的一个或多个是基于指令和/或指定的目的地而隐含的或隐式的。
128比特指令格式2010可包括访问/寻址模式字段2026,该访问/寻址模式字段2026例如指定使用直接寄存器寻址模式还是间接寄存器寻址模式。当使用直接寄存器寻址模式时,由指令中的比特直接提供一个或多个操作对象的寄存器地址。
128比特指令格式2010还可包括访问/寻址模式字段2026,该访问/寻址模式字段2026指定指令的寻址模式和/或访问模式。访问模式可用于限定指令的数据访问对齐。可支持包括16字节对齐访问模式和1字节对齐访问模式的访问模式,其中,访问模式的字节对齐确定指令操作对象的访问对齐。例如,当处于第一模式时,指令可将字节对齐的寻址用于源操作对象和目的地操作对象,并且当处于第二模式时,指令可将16字节对齐的寻址用于所有的源操作对象和目的地操作对象。
访问/寻址模式字段2026的寻址模式部分可以确定指令要使用直接寻址还是间接寻址。当使用直接寄存器寻址模式时,指令中的比特直接提供一个或多个操作对象的寄存器地址。当使用间接寄存器寻址模式时,可以基于指令中的地址寄存器值和地址立即数字段来计算一个或多个操作对象的寄存器地址。
可以基于操作码2012比特字段对指令进行分组从而简化操作码解码2040。针对8比特的操作码,比特4、比特5、和比特6允许执行单元确定操作码的类型。所示出的确切的操作码分组仅是示例。移动和逻辑操作码组2042可以包括数据移动和逻辑指令(例如,移动(mov)、比较(cmp))。移动和逻辑组2042可以共享五个最低有效的比特(least significantbit,LSB),其中,移动(mov)指令采用0000xxxxb的形式,而逻辑指令采用0001xxxxb的形式。流控制指令组2044(例如,调用(call)、跳转(jmp))包括0010xxxxb(例如,0x20)形式的指令。混杂指令组2046包括指令的混合,包括0011xxxxb(例如,0x30)形式的同步指令(例如,等待(wait)、发送(send))。并行数学指令组2048包括0100xxxxb(例如,0x40)形式的逐分量的算术指令(例如,加、乘(mul))。并行数学指令组2048跨数据通道并行地执行算术操作。向量数学组2050包括0101xxxxb(例如,0x50)形式的算术指令(例如,dp4)。向量数学组对向量操作对象执行算术,诸如,点积计算。在一个实施例中,所图示的操作码解码2040可用于确定执行单元的哪个部分将用于执行经解码的指令。例如,一些指令可被指定为将由脉动阵列执行的脉动指令。其他指令(诸如,光线追踪指令(未示出))可被路由至执行逻辑的切片或分区内的光线追踪核心或光线追踪逻辑。
图形管线
图21是根据另一个实施例的图形处理器2100的框图。图21的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。
图形处理器2100可包括不同类型的图形处理管线,诸如,几何管线2120、媒体管线2130、显示引擎2140、线程执行逻辑2150、以及渲染输出管线2170。图形处理器2100可以是包括一个或多个通用处理核心的多核心处理系统内的图形处理器。图形处理器可通过至一个或多个控制寄存器(未示出)的寄存器写入、或者经由通过环形互连2102发出至图形处理器2100的命令被控制。环形互连2102可将图形处理器2100耦合至其他处理部件(诸如,其他图形处理器或通用处理器)。由命令流转化器2103解释来自环形互连2102的命令,该命令流转化器2103将指令供应至几何管线2120或媒体管线2130的各个部件。
命令流转化器2103可引导顶点取得器2105的操作,该顶点取得器2105从存储器读取顶点数据,并执行由命令流转化器2103提供的顶点处理命令。顶点取得器2105可将顶点数据提供给顶点着色器2107,该顶点着色器2107对每一个顶点执行坐标空间变换和照明操作。顶点取得器2105和顶点着色器2107可通过经由线程调遣器2131将执行线程调遣给执行单元2152A-2152B来执行顶点处理指令。
执行单元2152A-2152B可以是具有用于执行图形操作和媒体操作的指令集的向量处理器的阵列。执行单元2152A-2152B可具有专用于每个阵列或在阵列之间被共享的所附接的L1缓存2151。缓存可以被配置为数据缓存、指令缓存、或被分区为在不同分区中包含数据和指令的单个缓存。
几何管线2120可包括用于执行3D对象的硬件加速曲面细分的曲面细分部件。可编程壳体着色器2111可配置曲面细分操作。可编程域着色器2117可提供对曲面细分输出的后端评估。曲面细分器2113可在外壳着色器2111的指示下进行操作,并且可包含用于基于粗糙的几何模型来生成详细的几何对象集合的专用逻辑,该粗糙的几何模型作为输入被提供给几何管线2120。此外,如果不使用曲面细分,则可以绕过曲面细分部件(例如,外壳着色器2111、曲面细分器2113和域着色器2117)。曲面细分部件可基于从顶点着色器2107接收的数据进行操作。
完整的几何对象可由几何着色器2119经由被调遣给执行单元2152A-2152B的一个或多个线程来处理,或者可以直接行进至裁剪器2129。几何着色器可对整个几何对象操作,而不是像在图形管线的先前的阶段中那样对顶点或顶点的补片进行操作。如果禁用曲面细分,则几何着色器2119从顶点着色器2107接收输入。几何着色器2119可以是可由几何着色器程序编程的,以便在禁用曲面细分单元的情况下执行几何曲面细分。
在栅格化之前,裁剪器2129处理顶点数据。裁剪器2129可以是固定功能裁剪器或具有裁剪和几何着色器功能的可编程裁剪器。渲染输出管线2170中的栅格化器和深度测试部件2173可调遣像素着色器以将几何对象转换为逐像素表示。像素着色器逻辑可被包括在线程执行逻辑2150中。任选地,应用可绕过栅格化器和深度测试部件2173,并且经由流出单元2123访问未栅格化的顶点数据。
图形处理器2100具有互连总线、互连结构、或允许数据和消息在处理器的主要部件之间传递的某个其他互连机制。在一些实施例中,执行单元2152A-2152B和相关联的逻辑单元(例如,L1缓存2151、采样器2154、纹理缓存2158等)经由数据端口2156进行互连,以执行存储器访问并且与处理器的渲染输出管线部件进行通信。采样器2154、缓存2151、2158和执行单元2152A-2152B各自可具有单独的存储器访问路径。任选地,纹理缓存2158也可被配置为采样器缓存。
渲染输出管线2170可包含栅格化器和深度测试部件2173,其将基于顶点的对象转换为相关联的基于像素的表示。栅格化器逻辑可包括用于执行固定功能三角形和线栅格化的窗口器/掩码器单元。在一些实施例中,相关联的渲染缓存2178和深度缓存2179也是可用的。像素操作部件2177对数据执行基于像素的操作,但是在一些实例中,与2D操作相关联的像素操作(例如,利用混合的比特块图像传输)由2D引擎2141执行,或者在显示时由显示控制器2143使用叠加显示平面来代替。共享的L3缓存2175可以可用于所有的图形部件,从而允许在不使用主系统存储器的情况下共享数据。
媒体管线2130可包括媒体引擎2137和视频前端2134。视频前端2134可从命令流转化器2103接收管线命令。媒体管线2130可包括单独的命令流转化器。视频前端2134可在将媒体命令发送到媒体引擎2137之前处理该媒体命令。媒体引擎2137可包括用于生成线程以用于经由线程调遣器2131调遣给线程执行逻辑2150的线程生成功能。
图形处理器2100可包括显示引擎2140。该显示引擎2140可在处理器2100外部,并且可经由环形互连2102、或某个其他互连总线或结构来与图形处理器耦合。显示引擎2140可包括2D引擎2141和显示控制器2143。显示引擎2140可包含能够独立于3D管线进行操作的专用逻辑。显示控制器2143可与显示设备(未示出)耦合,该显示设备可以是如在膝上型计算机中的系统集成的显示设备或经由显示设备连接器而附连的外部显示设备。
几何管线2120和媒体管线2130可以可被配置成用于基于多个图形和媒体编程接口来执行操作,并且不专用于任何一个应用编程接口(application programminginterface,API)。用于图形处理器的驱动器软件可将专用于特定图形或媒体库的API调用转换为可由图形处理器处理的命令。可以为全部来自Khronos Group的开放图形库(OpenGraphics Library,OpenGL)、开放计算语言(Open Computing Language,OpenCL)和/或Vulkan图形和计算API提供支持。也可以为来自微软公司的Direct3D库提供支持。可支持这些库的组合。还可以为开源计算机视觉库(Open Source Computer Vision Library,OpenCV)提供支持。如果可进行从未来API的管线到图形处理器的管线的映射,则具有兼容3D管线的未来API也将受到支持。
图形管线编程
图22A是图示用于对图形处理管线编程的图形处理命令格式2200的框图,图形处理管线诸如例如结合图16A、图17、图21描述的管线。图22B是图示根据实施例的图形处理器命令序列2210的框图。图22A中的实线框图示一般被包括在图形命令中的组成部分,而虚线包括任选的或仅被包括在图形命令的子集中的组成部分。图22A的示例性图形处理器命令格式2200包括用于标识命令的客户端2202、命令操作代码(操作码)2204和数据2206的数据字段。子操作码2205和命令大小2208也被包括在一些命令中。
客户端2202可指定图形设备的处理命令数据的客户端单元。图形处理器命令解析器可检查每一个命令的客户端字段以调整对命令的进一步的处理,并且将命令数据路由至适当的客户端单元。图形处理器客户端单元可包括存储器接口单元、渲染单元、2D单元、3D单元、和媒体单元。每个客户端单元可具有处理命令的对应的处理管线。一旦由客户端单元接收到命令,客户端单元就读取操作码2204以及子操作码2205(如果存在)以确定要执行的操作。客户端单元使用数据字段2206中的信息来执行命令。针对一些命令,预期显式的命令大小2208指定命令的大小。命令解析器可基于命令操作码自动地确定命令中的至少一些命令的大小。命令可经由双字的倍数被对齐。还可使用其他命令格式。
图22B中的流程图示示例性图形处理器命令序列2210。以示例性图形处理器为特征的数据处理系统的软件或固件可使用所示出的命令序列的某个版本来建立、执行并终止图形操作的集合。仅出于示例目的示出并描述样本命令序列,并且样本命令序列不限于这些特定的命令或该命令序列。此外,命令可以作为批量的命令在命令序列中被发出,使得图形处理器将以至少部分地并发的方式处理命令序列。
图形处理器命令序列2210能以管线转储清除命令2212开始,以使任何活跃的图形管线完成用于管线的当前未决的命令。任选地,3D管线2222和媒体管线2224可以不并发地操作。执行管线转储清除以使活跃的图形管线完成任何未决命令。响应于管线转储清除,用于图形处理器的命令解析器将暂停命令处理,直到活跃的绘画引擎完成未决操作并且相关的读缓存被无效。任选地,渲染缓存中被标记为“脏”的任何数据可以被转储清除到存储器。管线转储清除命令2212可用于管线同步,或可在将图形处理器置于低功率状态之前被使用。
当命令序列需要图形处理器在管线之间显式地切换时,可使用管线选择命令2213。在发出管线命令之前可在执行上下文中仅需要一次管线选择命令2213,除非上下文是发出针对这两条管线的命令。可紧接在经由管线选择命令2213进行的管线切换之前需要管线转储清除命令2212。
管线控制命令2214可配置用于操作的图形管线,并且可用于对3D管线2222和媒体管线2224编程。管线控制命令2214可为活跃的管线配置管线状态。管线控制命令2214可用于管线同步,并且用于在处理批量的命令之前清除来自活跃管线内的一个或多个缓存存储器的数据。
与返回缓冲器状态2216有关的命令可用于将用于相应管线的返回缓冲器的集合配置成用于写入数据。一些管线操作需要对一个或多个返回缓冲器的分配、选择或配置,在处理期间操作将中间数据写入这一个或多个返回缓冲器中。图形处理器也可使用一个或多个返回缓冲器以存储输出数据并执行跨线程通信。返回缓冲器状态2216可包括选择要用于管线操作的集合的返回缓冲器的大小和数量。
命令序列中的其余命令基于用于操作的活跃管线而不同。基于管线判定2220,命令序列被定制成用于以3D管线状态2230开始的3D管线2222、或者在媒体管线状态2240处开始的媒体管线2224。
用于配置3D管线状态2230的命令包括用于顶点缓冲器状态、顶点元素状态、常量颜色状态、深度缓冲器状态、以及将在处理3D基元命令之前配置的其他状态变量的3D状态设置命令。这些命令的值至少部分地基于使用中的特定3D API来确定。3D管线状态2230命令也可以能够在将不会使用某些管线元件的情况下选择性地禁用或绕过那些元件。
3D基元2232命令可用于提交要由3D管线处理的3D基元。经由3D基元2232命令传递给图形处理器的命令和相关联的参数被转发到图形管线中的顶点取得功能。顶点取得功能使用3D基元2232命令数据来生成多个顶点数据结构。顶点数据结构被存储在一个或多个返回缓冲器中。3D基元2232命令可用于经由顶点着色器对3D基元执行顶点操作。为了处理顶点着色器,3D管线2222将着色器执行线程调遣给图形处理器执行单元。
3D管线2222可经由执行2234命令或事件来触发。寄存器可写入触发命令执行。可经由命令序列中的“去往(go)”或“踢除(kick)”命令来触发执行。命令执行可使用管线同步命令以通过图形管线对命令序列转储清除来触发。3D管线将执行针对3D基元的几何处理。一旦操作完成,就对所得到的几何对象进行栅格化,并且像素引擎对所得到的像素进行着色。对于那些操作,还可以包括用于控制像素着色和像素后端操作的附加命令。
当执行媒体操作时,图形处理器命令序列2210可遵循媒体管线2224路径。一般而言,针对媒体管线2224进行编程的特定用途和方式取决于要执行的媒体或计算操作。在媒体解码操作期间,特定的媒体解码操作可被迁移到媒体管线。也可绕过媒体管线,并且可使用由一个或多个通用处理核心提供的资源完全地或部分地执行媒体解码。媒体管线还可包括用于通用图形处理器单元(GPGPU)操作的元件,其中,图形处理器用于使用计算着色器程序来执行SIMD向量操作,这些计算着色器程序并不明确地与图形基元的渲染相关。
能以与3D管线2222类似的方式来配置媒体管线2224。将用于配置媒体管线状态2240的命令的集合调遣或放置到命令队列中,在媒体对象命令2242之前。用于媒体管线状态2240的命令可包括用于配置将被用于处理媒体对象的媒体管线元件的数据。这包括用于在媒体管线内配置视频解码和视频编码逻辑的数据,诸如编码或解码格式。用于媒体管线状态2240的命令还可支持使用指向包含批量的状态设置的“间接”状态元素的一个或多个指针。
媒体对象命令2242可供应指向用于由媒体管线处理的媒体对象的指针。媒体对象包括存储器缓冲器,该存储器缓冲器包含要处理的视频数据。任选地,在发出媒体对象命令2242之前,所有的媒体管线状态必须是有效的。一旦管线状态被配置并且媒体对象命令2242被排队,就经由执行命令2244或等效的执行事件(例如,寄存器写入)来触发媒体管线2224。随后可通过由3D管线2222或媒体管线2224提供的操作对来自媒体管线2224的输出进行后处理。能以与媒体操作类似的方式配置和执行GPGPU操作。
图形软件体系结构
图23图示用于数据处理系统2300的示例性图形软件体系结构。此类软件体系结构可包括3D图形应用2310、操作系统2320以及至少一个处理器2330。处理器2330可包括图形处理器2332以及一个或多个通用处理器核心2334。处理器2330可以是处理器1402或本文中描述的处理器中的任何其他处理器的变体。可替代处理器1402或本文中描述的处理器中的任何其他处理器来使用处理器2330。因此,结合处理器1402或本文中描述的处理器中的任何其他处理器对任何特征的公开也公开了对应的与图形处理器2330的结合,但不限于此。此外,图23的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。图形应用2310和操作系统2320各自在数据处理系统的系统存储器2350中执行。
3D图形应用2310可包含一个或多个着色器程序,这一个或多个着色器程序包括着色器指令2312。着色器语言指令可以采用高级着色器语言,诸如,Direct3D的高级着色器语言(High-Level Shader Language,HLSL)、OpenGL着色器语言(OpenGL Shader LanguageGLSL),等等。应用还可包括采用适于由通用处理器核心2334执行的机器语言的可执行指令2314。应用还可包括由顶点数据限定的图形对象2316。
操作系统2320可以是来自微软公司的
用户模式图形驱动器2326可包含后端着色器编译器2327以将着色器指令2312编译为硬件专用表示。当OpenGL API在使用中时,将采用GLSL高级语言的着色器指令2312传递至用户模式图形驱动器2326以用于编译。用户模式图形驱动器2326可使用操作系统内核模式功能2328来与内核模式图形驱动器2329通信。内核模式图形驱动器2329可与图形处理器2332通信以调遣命令和指令。
IP核心实现方式
一个或多个方面可以由存储在机器可读介质上的代表性代码实现,该机器可读介质表示和/或限定集成电路(诸如,处理器)内的逻辑。例如,机器可读介质可包括表示处理器内的各种逻辑的指令。当由机器读取时,指令可使机器制造用于执行本文所描述的技术的逻辑。此类表示(被称为“IP核心”)是集成电路的逻辑的可重复使用单元,这些可重复使用单元可以作为描述集成电路的结构的硬件模型而被存储在有形的、机器可读介质上。可以将硬件模型供应至在制造集成电路的制造机器上加载硬件模型的各客户或制造设施。可以制造集成电路,使得电路执行与本文中描述的实施例中的任一实施例相关联地描述的操作。
图24A是图示根据实施例的可用于制造集成电路以执行操作的IP核心开发系统2400的框图。IP核心开发系统2400可以用于生成可并入到更大的设计中或用于构建整个集成电路(例如,SOC集成电路)的模块化、可重复使用的设计。设计设施2430可生成采用高级编程语言(例如,C/C++)的IP核心设计的软件仿真2410。软件仿真2410可用于使用仿真模型2412来设计、测试并验证IP核心的行为。仿真模型2412可包括功能仿真、行为仿真和/或时序仿真。随后可从仿真模型2412创建或合成寄存器传输级(register transfer level,RTL)设计2415。RTL设计2415是对硬件寄存器之间的数字信号的流进行建模的集成电路(包括使用建模的数字信号来执行的相关联的逻辑)的行为的抽象。除了RTL设计2415之外,还可创建、设计或合成逻辑级或晶体管级的较低级别设计。由此,初始设计和仿真的特定细节可有所不同。
可由设计设施进一步将RTL设计2415或等效方案合成到硬件模型2420中,该硬件模型2420可以采用硬件描述语言(hardware description language,HDL)或物理设计数据的某种其他表示。可以进一步仿真或测试HDL以验证IP核心设计。可使用非易失性存储器2440(例如,硬盘、闪存、或任何非易失性存储介质)来存储IP核心设计以用于递送至第三方制造设施2465。替代地,可通过有线连接2450或无线连接2460(例如,经由互联网)来传送IP核心设计。制造设施2465随后可制造至少部分地基于IP核心设计的集成电路。所制造的集成电路可被配置成用于执行根据本文中描述的至少一个实施例的操作。
图24B图示集成电路封装组件2470的横截面侧视图。集成电路封装组件2470图示如本文中所描述的一个或多个处理器或加速器设备的实现方式。封装组件2470包括连接至衬底2480的多个硬件逻辑单元2472、2474。逻辑2472、2474可至少部分地实现在可配置逻辑或固定功能逻辑硬件中,并且可包括本文中描述的(一个或多个)处理器核心、(一个或多个)图形处理器或其他加速器设备中的任一者的一个或多个部分。每个逻辑单元2472、2474可实现在半导体管芯内,并且经由互连组织2473与衬底2480耦合。互连组织2473可被配置成用于在逻辑2472、2474与衬底2480之间路由电信号,并且可包括互连,该互连诸如但不限于凸块或支柱。互连组织2473可被配置成路由电信号,诸如例如,与逻辑2472、2474的操作相关联的输入/输出(I/O)信号和/或功率或接地信号。任选地,衬底2480可以是基于环氧树脂的层压衬底。衬底2480还可包括其他合适类型的衬底。封装组件2470可经由封装互连2483连接到其他电气设备。封装互连2483可耦合至衬底2480的表面以将电信号路由到其他电气设备,诸如主板、其他芯片组或多芯片模块。
逻辑单元2472、2474可与桥接器2482电耦合,该桥接器2482被配置成用于在逻辑2472与逻辑2474之间路由电信号。桥接器2482可以是为电信号提供路由的密集互连组织。桥接器2482可包括由玻璃或合适的半导体材料构成的桥接器衬底。电路由特征可形成在桥接器衬底上,以提供逻辑2472与逻辑2474之间的芯片-芯片连接。
尽管图示了两个逻辑单元2472、2474和桥接器2482,但是本文中所描述的实施例可包括在一个或多个管芯上的更多或更少的逻辑单元。这一个或多个管芯可以由零个或更多个桥接器连接,因为当逻辑被包括在单个管芯上时,可以排除桥接器2482。替代地,多个管芯或逻辑单元可以由一个或多个桥接器连接。此外,多个逻辑单元、管芯和桥接器可按其他可能的配置(包括三维配置)被连接在一起。
图24C图示封装组件2490,该封装组件2490包括连接到衬底2480的多个单元的硬件逻辑小芯片(例如,基础管芯)。如本文中所描述的图形处理单元、并行处理器和/或计算加速器可由分开制造的各种硅小芯片组成。在该上下文中,小芯片是至少部分地被封装的集成电路,该至少部分地被封装的集成电路包括可与其他小芯片一起被组装到更大的封装中的不同的逻辑单元。具有不同IP核心逻辑的各种集合的小芯片可被组装到单个器件中。此外,小芯片可使用有源中介层(interposer)技术而被集成到基础管芯或基础小芯片中。本文中描述的概念启用GPU内的不同形式的IP之间的互连和通信。IP核心可使用不同的工艺技术来制造并在制造期间被构成,这避免了尤其是对于具有若干风格的IP的大型SoC的将多个IP汇聚到同一制造工艺的复杂性。允许使用多种工艺技术改善了上市时间,并提供具有成本效益的方法来创建多个产品SKU。此外,分解的IP更易修改以被独立地功率门控,对于给定工作负载不在使用中的部件可被关断,从而降低总功耗。
在各实施例中,封装组件2490可包括由结构2485或一个或多个桥接器2487互连的更少或更多数量的部件和小芯片。封装组件2490内的小芯片可具有使用芯片-晶片-衬底(Chip-on-Wafer-on-Substrate)堆叠的2.5D布置,其中,多个管芯并排地堆叠在硅中介层上,该硅中介层包括硅通孔(through-silicon vias,TSV)以将小芯片与衬底2480耦合,该衬底2480包括至封装互连2483的电气连接。
在一个实施例中,硅中介层是有源中介层2489,该有源中介层2489除TSV外还包括嵌入式逻辑。在此类实施例中,封装组件2490内的小芯片使用3D面对面管芯堆叠被布置在有源中介层2489的顶部上。有源中介层2489除互连结构2485和硅桥接器2487外还可包括用于I/O 2491的硬件逻辑、缓存存储器2492和其他硬件逻辑2493。结构2485启用各中逻辑小芯片2472、2474与有源中介层2489内的逻辑2491、2493之间的通信。结构2485可以是在封装组件的部件之间交换数据分组的NoC互连或另一形式的分组交换型结构。对于复杂组件,结构2485可以是启用封装组件2490的各硬件逻辑之间的通信的专用小芯片。
有源中介层2489内的桥接器结构2487可用于促进例如逻辑或I/O小芯片2474与存储器小芯片2475之间的点到点互连。在一些实现方式中,桥接器结构2487还可被嵌入在衬底2480内。
硬件逻辑小芯片可包括专用硬件逻辑小芯片2472、逻辑或I/O小芯片2474、和/或存储器小芯片2475。硬件逻辑小芯片2472以及逻辑或I/O小芯片2474可以至少部分地实现在可配置逻辑或固定功能逻辑硬件中,并且可包括本文中描述的(一个或多个)处理器核心、(一个或多个)图形处理器、并行处理器或其他加速器设备中的任一个的一个或多个部分。存储器小芯片2475可以是DRAM(例如,GDDR、HBM)存储器或缓存(SRAM)存储器。有源中介层2489(或衬底2480)内的缓存存储器2492可充当用于封装组件2490的全局缓存,充当分布式全局缓存的部分,或充当用于结构2485的专用缓存。
每个小芯片可被制造为单独的半导体管芯,并且可与基础管芯耦合,该基础管芯嵌入在衬底2480内或与衬底2480耦合。与衬底2480的耦合可经由互连组织2473来执行。互连组织2473可被配置成用于在衬底2480内的各种小芯片与逻辑之间路由电信号。互连组织2473可包括互连,诸如但不限于凸块或支柱。在一些实施例中,互连组织2473可被配置成用于路由电信号,诸如例如,与逻辑、I/O和存储器小芯片的操作相关联的输入/输出(I/O)信号和/或功率或接地信号。在一个实施例中,附加的互连组织将有源中介层2489与衬底2480耦合。
衬底2480可以是基于环氧树脂的层压衬底,然而,它不限于此,并且衬底2480还可包括其他合适类型的衬底。封装组件2490可经由封装互连2483连接到其他电气设备。封装互连2483可耦合至衬底2480的表面以将电信号路由到其他电气设备,诸如,主板、其他芯片组或多芯片模块。
逻辑或I/O小芯片2474和存储器小芯片2475可经由桥接器2487被电耦合,该桥接器2487被配置成用于在逻辑或I/O小芯片2474与存储器小芯片2475之间路由电信号。桥接器2487可以是为电信号提供路由的密集互连组织。桥接器2487可包括由玻璃或合适的半导体材料构成的桥接器衬底。电路由特征可形成在桥接器衬底上以提供逻辑或I/O小芯片2474与存储器小芯片2475之间的芯片-芯片连接。桥接器2487还可被称为硅桥接器或互连桥接器。例如,桥接器2487是嵌入式多管芯互连桥接器(Embedded Multi-dieInterconnect Bridge,EMIB)。替代地,桥接器2487可简单地是从一个小芯片到另一小芯片的直接连接。
图24D图示根据实施例的包括可互换小芯片2495的封装组件2494。可互换小芯片2495可被组装到一个或多个基础小芯片2496、2498上的标准化插槽中。基础小芯片2496、2498可经由桥接器互连2497被耦合,该桥接器互连2497可与本文中描述的其他桥接器互连类似,并且可以是例如EMIB。存储器小芯片也可经由桥接器互连被连接到逻辑或I/O小芯片。I/O和逻辑小芯片可经由互连结构进行通信。基础小芯片各自都能以用于逻辑或I/O或存储器/缓存中的一者的标准化格式来支持一个或多个插槽。
SRAM和功率递送电路可被制造到基础小芯片2496、2498中的一个或多个中,基础小芯片2496、2498可使用相对于可互换小芯片2495不同的工艺技术来制造,可互换小芯片2495堆叠在基础小芯片的顶部上。例如,可使用较大工艺技术来制造基础小芯片2496、2498,同时可使用较小工艺技术来制造可互换小芯片。可互换小芯片2495中的一个或多个可以是存储器(例如,DRAM)小芯片。可基于针对使用封装组件2494的产品的功率和/或性能来为封装组件2494选择不同的存储器密度。此外,可在组装时基于针对产品的功率和/或性能来选择具有不同数量的类型的功能单元的逻辑小芯片。此外,可将包含具有不同类型的IP逻辑核心的小芯片插入到可互换小芯片插槽中,从而启用可混合并匹配不同技术的IP块的混合式处理器设计。
示例性片上系统集成电路
图25-图26B图示可使用一个或多个IP核心制造的示例性集成电路和相关联的图形处理器。除了所图示的内容之外,还可包括其他逻辑和电路,包括附加的图形处理器/核心、外围接口控制器或通用处理器核心。图25-图26B的具有与本文中任何其他附图的元件相同或类似名称的元件描述与其他附图中相同的元件,可按与其他附图中类似的方式操作或运行,可包括相同的部件,并且可链接到其他实体,该实体如本文中其他地方所描述的那些实体,但不限于此。
图25是图示可使用一个或多个IP核心来制造的示例性片上系统集成电路2500的框图。示例性集成电路2500包括一个或多个应用处理器2505(例如,CPU)、至少一个图形处理器2510,该至少一个图形处理器2510可以是图形处理器1408、1508、2510的变体,或者可以是本文中描述的并且可替代所描述的任何图形处理器被使用的任何图形处理器。因此,本文中结合图形处理器对任何特征的公开也公开了对应的与图形处理器2510的结合,但不限于此。集成电路2500可附加地包括图像处理器2515和/或视频处理器2520,图像处理器2515和视频处理器2520中的任一者可以是来自相同的设计设施或多个不同的设计设施的模块化IP核心。集成电路2500可包括外围或总线逻辑,包括USB控制器2525、UART控制器2530、SPI/SDIO控制器2535和I
图26A-图26B是图示根据本文中所描述的实施例的用于在SoC内使用的示例性图形处理器的框图。所图示的图形处理器可以是图形处理器1408、1508、2510、或本文中描述的任何其他图形处理器的变体。图形处理器可替代图形处理器1408、1508、2510、或本文中描述的图形处理器中的任何其他图形处理器被使用。因此,结合图形处理器1408、1508、2510或本文中描述的图形处理器中的任何其他图形处理器对任何特征的公开也公开了对应的与图26A-图26B的图形处理器的结合,但不限于此。图26A图示根据实施例的可以使用一个或多个IP核心来制造的片上系统集成电路的示例性图形处理器2610。图26B图示根据实施例的可以使用一个或多个IP核心来制造的片上系统集成电路的附加的示例图形处理器2640。图26A的图形处理器2610是低功率图形处理器核心的示例。图26B的图形处理器2640是较高性能的图形处理器核心的示例。例如,如本段开头所提及,图形处理器2610和图形处理器2640中的每个图形处理器可以是图25的图形处理器2510的变体。
如图26A中所示,图形处理器2610包括顶点处理器2605和一个或多个片段处理器2615A-2615N(例如,2615A、2615B、2615C、2615D,一直到2615N-1和2615N)。图形处理器2610可以经由单独的逻辑执行不同的着色器程序,使得顶点处理器2605被优化以执行用于顶点着色器程序的操作,而一个或多个片段处理器2615A-2615N执行用于片段或像素着色器程序的片段(例如,像素)着色操作。顶点处理器2605执行3D图形管线的顶点处理阶段,并生成基元和顶点数据。(一个或多个)片段处理器2615A-2615N使用由顶点处理器2605生成的基元数据和顶点数据来产生被显示在显示设备上的帧缓冲器。(一个或多个)片段处理器2615A-2615N可被优化以执行如在OpenGL API中提供的片段着色器程序,这些片段着色器程序可以用于执行与如在Direct 3D API中提供的像素着色器程序类似的操作。
图形处理器2610附加地包括一个或多个存储器管理单元(memory managementunit,MMU)2620A-2620B、(一个或多个)缓存2625A-2625B以及(一个或多个)电路互连2630A-2630B。这一个或多个MMU 2620A-2620B为图形处理器2610(包括为顶点处理器2605和/或(一个或多个)片段处理器2615A-2615N)提供虚拟到物理地址映射,除了存储在一个或多个缓存2625A-2625B中的顶点数据或图像/纹理数据之外,该虚拟到物理地址映射还可以引用存储在存储器中的顶点数据或图像/纹理数据。一个或多个MMU 2620A-2620B可以与系统内的其他MMU同步,使得每个处理器2505-2520可以参与共享或统一的虚拟存储器系统,系统内的其他MMU包括与图25的一个或多个应用处理器2505、图像处理器2515和/或视频处理器2520相关联的一个或多个MMU。图形处理器2610的部件可与本文中描述的其他图形处理器的部件对应。一个或多个MMU 2620A-2620B可与图2C的MMU 245对应。顶点处理器2605和片段处理器2615A-2515N可与图形多处理器234对应。根据实施例,一个或多个电路互连2630A-2630B使得图形处理器2610能够经由SoC的内部总线或经由直接连接来与SoC内的其他IP核心对接。一个或多个电路互连2630A-2630B可与图2C的数据交叉开关240对应。可在图形处理器2610的类似部件与本文中描述的各种图形处理器体系结构之间发现进一步的对应性。
如图26B中所示,图形处理器2640包括图26A的图形处理器2610的一个或多个MMU2620A-2620B、缓存2625A-2625B和电路互连2630A-2630B。图形处理器2640包括一个或多个着色器核心2655A-2655N(例如,2655A、2655B、26555C、2655D、2655E、2655F,一直到2655N-1和2655N),其提供统一的着色器核心体系结构,其中,单个核心或单个类型的核心可执行所有类型的可编程着色器代码,包括用于实现顶点着色器、片段着色器和/或计算着色器的着色器程序代码。存在的着色器核心的确切数量可以因实施例和实现方式而异。此外,图形处理器2640包括核心间任务管理器2645,该核心间任务管理器2645充当用于将执行线程调遣给一个或多个着色器核心2655A-2655N的线程调遣器和用于加速对基于片的渲染的分片操作的分片单元2658,在基于片的渲染中,针对场景的渲染操作在图像空间中被细分,例如以利用场景内的局部空间一致性或优化内部缓存的使用。着色器核心2655A-2655N可例如与图2D中的图形多处理器234对应,或分别与图3A和图3B的图形多处理器325、350对应,或与图3C的多核心组365A对应。
图形SoC体系结构
图27图示用于图形SoC 2700的模块化客户端/服务器体系结构的框图。示出汇聚式体系结构视图,其包括利用体系结构内的特定的模块化连接点构造的图形SoC 2700的部件,使得部件可被添加,可从单片式设计被移除,或者可按分解式设计被划分在多个小芯片之间。例如,主机连接性可以在分开的主机接口管芯2710上,其中,物理接口(physicalinterface,PHY 2711)、上游端口(upstream port,USP 2712)和结构桥接器(2713)在第一管芯上,并且交换结构和其余SoC部件在第二管芯上。客户端配置可包括具有外围部件互连快速(peripheral component interconnect express,PCIe)支持(例如,PCIe 5等)的主机接口管芯2710,而服务器配置可利用对PCIe以及计算快速链路(compute link,CXL)和CXL.mem/cache(CXL.存储器/缓存)2751的支持启用对主机接口管芯2710的使用。在一个实施例中,功率管理块2720也可从主SoC体系结构分解。功率管理块2720包括用于促进图形SoC 2700上的功率管理功能的功率管理单元(power management unit,PUNIT 2721)以及各种功率和平台互连。图形SoC 2700内的部件通信可使用边带网络来执行,该边带网络是用于在图形SoC 2700的部件之间传递带外信息的标准化机制。边带路由器(例如,SBR2753)可在边带网络上在部件之间路由消息。SoC地址解码器2762可通过维护用于存储器映射的输入/输出(memory mapped input/output,MMIO)与同各地址范围相关联的SoC部件之间的映射来促进通过边带网络的消息传送。在一个实施例中,SoC地址解码器2762是可编程的,使得用于各SoC部件的地址映射可基于针对被组装的产品而选择的部件被动态地编程。来自各部件的遥测也可由图形SoC 2700输出。遥测输出可经由来自主交换结构的带内请求和经由边带网络的带外请求两者被配置。
一个或多个主交换结构2752A-2752C提供用于图形SoC 2700的主通信机制。主交换结构2752A-2752C与图16B-图16C的结构互连1624相关联,并且还可以表示图24C的结构2485。在一个实施例中,第一主交换结构(primary switch fabric,PSF-0)2752A可与主机接口管芯2710上的结构桥接器2713耦合,而第二主交换结构(PSF-1)2752B和第三主交换结构(PSF-2)2752C与第一主交换结构2752A耦合。主交换结构2752A-2752C的客户端可经由虚拟交换端口(例如,virtual switch port,VSP 2760)与交换结构耦合。在一个实施例中,至汇聚式存储器接口桥接器2757的主交换结构与主交换结构2752A-2752C中的至少一个耦合,以经由主机接口管芯2710启用对与存储器接口2790耦合的存储器的访问,该主机接口管芯2710允许外部设备访问图形SoC 2700的存储器。在一个实施例中,测试访问模块(testaccess module,TAM2754)与主交换结构(例如,PSF-1 2752B)耦合,以启用针对图形SoC2700的调试功能。在一个实施例中,TAM 2754可用于经由SMT通用输入/输出(general-purpose input/output,GPIO)接口来访问调试逻辑。
GPIO接口(例如,GPIO 2758)还可用于访问闪存设备2756,该闪存设备2755可存储例如用于图形SoC 2700的各部件的固件以及用于安全控制器2755的固件。在一个实施例中,安全控制器2755是用于基于服务器的GPU系统的底座安全控制器。一个实施例还包括熔丝阵列2763和相关联的熔丝控制器2764。熔丝阵列2763包括一旦经编程就变成只读的一次性可编程非易失性存储装置。在一个实施例中,熔丝阵列包括真随机数生成器(truerandom number generator,TRNG),该TRNG用于使熔丝阵列中的熔丝被感测的方式随机化,使得较难简单地演练设备并确定熔丝阵列2763内的存储元素的所有值。
设备单元2761可经由VSP 2760与主交换结构(例如,PSF-0 2752A)耦合,在一个实施例中,该VSP 2760是用于图形SoC 2700的PCIe/CXL端点控制器。设备单元2761可与用于一些产品的显示控制器2732和相关联的显示物理接口2733耦合,而其他产品、尤其是基于服务器的产品可排除显示控制器2732和相关联的显示物理接口2733。图形SoC 2700还可包括音频设备2730,以经由附连的显示连接促进音频输出。在一个实施例中,显示和音频输出可经由USB4/雷电(Thunderbolt)互连2766被执行。可提供显示端口(DisplayPort)替代模式、USB协议隧穿、和高速数据传递。
第二管芯上的SoC部件中的一些也可位于第三管芯上。例如,包括多个图形核心集群的计算块2780以及相关联的存储器接口2790可驻留在第三管芯上。计算块2780可包括图形核心,该图形核心具有矩阵加速器和/或用于专注于计算和/或机器学习的服务器产品的脉动阵列,而脉动阵列对于针对不同的细分服务器的另一产品(诸如,对于专注于媒体的服务器产品)可被排除或被修改。相应地,计算块2780内的图形核心集群在细分客户端与细分服务器之间可有所不同,而无需重新设计SoC体系结构。替代地,具有不同版本的计算块2780的不同小芯片可在组装期间被附加至有源基础管芯。如本文中所描述,有源基础管芯是除了将小芯片的片互连到封装互连的TSV外还包括嵌入式逻辑的硅管芯。
在计算块2780和相关联的存储器接口2790驻留在第三管芯上的情况下,不同类型的图形核心和存储器配对可被用于不同产品,并且不同的图形核心体系结构可被使用。基于服务器的计算块2780可与HBM存储器(例如,HBM2E、HBM3)相关联,而基于客户端的计算块2780可与GDDR存储器(例如,GDDR6、GDDR6X)相关联。在一个实施例中,低功率产品可与低功率DDR(low power DDR,LPDDR)存储器子系统耦合。存储器接口2782和/或存储器桥接器2784可用于连接计算块2780和存储器接口2790。在一个实施例中,存储器接口2782可驻留在有源基础管芯内。此外,当制造模块针对不同的细分市场或产品类别时,可使用不同的工艺技术节点。
在一个实施例中,存储器接口2790可驻留在第四管芯上,其中,不同的存储器技术被用于共享计算块2780内的图形核心体系结构的不同的细分产品。例如,服务器产品可与HBM存储器的堆叠耦合,而针对游戏爱好者的客户端产品可包括结合GDDR6X存储器的某个版本的专注于服务器的计算块2780。还可对封装上HBM以及经由高速存储器互连与分开的HBM封装耦合的产品作出区分。
在一个实施例中,可缩放媒体块和全局控制2769可被包括并与存储器结构2768耦合。存储器结构2768启用可缩放媒体块和全局控制2769与计算块2780和附连的存储器接口2790之间的通信。存储器结构2768与图16B-图16C的存储器互连1625A-1625D相关联,并且在一个实施例中可以至少部分地利用图24C的结构2485。
在一个实施例中,存储器接口2790和相关联的存储器设备可利用动态电压和频率缩放。当执行受存储器子系统的性能限制的存储器密集型工作负载时,存储器系统的电压和频率可被缩放以提供更高的存储器性能。当空闲时或当执行相比存储器性能更受计算性能限制的工作负载时,存储器子系统的电压可频率可被减小,从而允许计算引擎的电压和频率缩放而不超出总设备功率限制。
在一个实施例中,针对每个图形产品SKU、基于与那个SKU相关联的功率包络标识工作点的集合。在分立的图形系统中,存储器设备(GDDR、HBM等)仅能以有限的电压集合来操作。在存储器训练期间,在工厂重置时,可操作电压和频率点被训练。经训练的参数随后被存储在闪存设备上以用于稍后取回。基于硅后校准,适当的电压和频率点被确定,并且存储器子系统被配置成用于启用那些点之间的转变。硬件被配置成用于在不在用户体验或工作负载性能方面显著地影响现有工作负载的情况下迅速地切换频率。在必要时,较高的电压可被用于启用最高的存储器频率集合。
在一个实施例中,本文中描述的图形SoC 2700体系结构可配置成用于针对服务器和客户端设备启用多片产品,并且对于服务器设备启用多插槽产品。片对片接口2711可被包括以使图形SoC 2700能够与附加的片或管芯耦合。片对插槽接口2773可被包括并与附加的小芯片插槽2774和连接性管芯2775耦合,该连接性管芯2775允许多板服务器图形GPU被组装。片对片接口2771和片对插槽接口2773各自可与存储器结构2768耦合,以使用于各片和插槽的存储器能够经由远程片和插槽被访问。
图28图示根据实施例的模块化图形核心集群2820。图形核心集群2820是图27的计算块2780内的图形核心集群的示例。图形核心集群2820包括多个图形核心2824A-2824N。图形核心集群2820具有使得图形核心2824A-2824N能够在客户端产品与服务器产品之间被区分的模块化设计。在一个实施例中,多个图形核心2824A-2824N中的每一个图形核心包括计算逻辑2802A-2802N、存储器加载/存储单元2804A-2804N、指令缓存2805A-2805N、数据缓存/共享本地存储器2806A-2806N、光线追踪单元2808A-2808N、采样器2810A-2810N和固定功能逻辑块2812A-2812N。指令缓存2805A-2805N、数据缓存/共享本地存储器2806A-2806N、光线追踪单元2808A-2808N、采样器2810A-2810N和固定功能逻辑2812A-2812N的功能与上述图形处理器体系结构中的等效功能对应。
参考图形核心2824A,计算逻辑2802A包括向量处理逻辑和矩阵操作加速逻辑,该向量处理逻辑和矩阵操作加速逻辑可配置用于对各种整数和浮点数据格式的数据执行并行计算操作。相对于客户端设备,可以针对服务器设备以不同的方式来构造计算逻辑2802A-2802N。例如,强调机器学习的服务器设备包括针对低精度或混合精度操作被优化的矩阵加速逻辑。强调高性能计算的服务器设备可以包括针对单精度浮点操作或双精度浮点操作被优化的矩阵加速逻辑。一些聚焦于高性能计算或介质的服务器设备可以排除矩阵加速逻辑而支持其他部件,这些部件诸如更高性能的介质编码/解密逻辑或者用于执行双精度操作的更大量的向量引擎。计算逻辑2802A-2802N的向量引擎包括可变宽度向量逻辑,如上文参照图3C所描述,可变宽度向量逻辑可配置成用于以不同的整数和浮点精度进行的SIMD和SIMT操作两者。
存储器加载/存储单元2804A服务于由计算逻辑2802A发出的存储器访问请求。例如,响应于从存储器加载数据或将数据存储到存储器的指令,消息发送单元可以向存储器加载/存储单元2804A发送包括存储器访问请求的消息。存储器访问请求可以由存储器加载/存储单元2804A处理,以将所请求的数据加载到缓存或存储器或从缓存或存储器加载或存储到与计算逻辑2802A相关联的寄存器堆中。在一些实施例中,还可以基于由光线追踪单元2808A或采样器2810A执行的操作来执行存储器访问。
图29图示根据实施例的多片图形处理器的片2900。片2900包括全局调遣器2902,用于将线程调遣到由多个图形核心集群2820A-2820N内的图形核心提供的处理资源。在一个实施例中,每个图形核心集群各自包括多个图形核心2824A-2824N。存储器结构2903启用图形核心集群2920A-2920N、L3缓存2906和存储器子系统2910之间的通信。L2缓存2904与存储器结构2903耦合,并且在一个实施例中用于缓存经由存储器结构2903执行的事务。片互连2908实现与图形处理器上的其他片的通信,并且可以是图16B-图16C的片互连1623A-1623F和/或图27的片对片接口2771中的一个。在一个实施例中,L3缓存2906是专用于片2900的处理资源的每片缓存。在一个实施例中,L3缓存2906是GPU范围的L3缓存的分区。在一个实施例中,L3缓存2906被排除在片2900之外,并且L2缓存2904充当L2/L3缓存。在此类实施例中,多片图形处理器可以包括缓存由图形处理器执行的所有存储器访问的大型系统缓存。存储器子系统2910包括与片2900耦合的一个或多个存储器模块。在一个实施例中,存储器子系统2910是ccNUMA存储器系统的部分,该ccNUMA存储器系统包括与多片图形处理器中的其他片耦合的存储器模块。在各实施例和配置中,存储器子系统2910可以包括GDDR、HBM或LPDDR存储器设备,以及用于那些存储器设备的各种控制器和PHY。存储器子系统2910可以像片2900的计算和结构部件那样驻留在单独的管芯或片上。
图30-图33图示可以从图27的模块化客户端/服务器图形SoC 2700实现的各种产品构造。图30图示根据实施例的单片客户端图形SoC。图31图示根据实施例的多片客户端图形SoC。图32图示根据实施例的可缩放多板服务器图形处理器。图33图示根据实施例的、具有多片图形SoC的可缩放多板服务器图形处理器。
如本文中所描述,服务器产品是指高性能计算和/或AI/深度学习/机器学习专用的细分,而客户端产品是指发烧友产品、主流产品、低功耗产品或移动产品。服务器专用的部件可以用更适合于面向客户端的产品的部件来代替。示例细分服务器部件包括片对片和片对插槽多管芯结构互连接口,其用于在具有高功率预算的大规模产品上使用,以实现高计算和存储器能力。还支持连接性管芯互连,以促进对实现GPU的多板连接性的板对板夹层连接器的使用。示例客户端专用部件包括显示接口和显示控制器、以及用于基于显示的音频输出支持的音频接口。对于高端客户端系统,也可以包括实现到有限数量的附加片的连接的片对片多管芯结构互连。
如图30中所示,可以构造单片客户端设备3000,其包括在有源基础管芯3004上具有客户端图形片3006的封装3002。有源基础管芯可以包括第4级(level-4,L4)缓存存储器。如同图24C的缓存存储器2492,L4缓存存储器可以充当用于封装3002的全局缓存。单片客户端设备3000可以包括到GDDR存储器的GDDR存储器互连3010A-3010B,其可以被包括在容纳单片客户端设备3000的图形卡上。在一个实施例中,客户端图形片3006可以以不同于有源基础管芯3004的工艺技术来制造。
如图31所示,可以构造多片客户端设备3100,其包括多管芯封装3102、以及驻留在多个有源基础管芯3104A-3104B上的多个客户端图形片3106A-3106B。多个客户端图形片3106A-3106B可以经由片对片链路3107被互连,该片对片链路3107可以是多管芯结构互连(multi-die fabric interconnect,MDFI),诸如图27的片对片接口2771。MDFI耦合相应客户端图形片3106A-3106B的主交换结构。在一个实施例中,主客户端图形片3106A包括主机互连3105部件,该主机互连3105部件可驻留在如图27中的主机接口管芯2710上。主机互连3105部件可以从次客户端图形片3106B被排除。客户端图形片3106A-3106B中的每一个可以具有相应的GDDR存储器互连3010A-3010B。直接连接至每个相应的客户端图形片3106A-3106B的存储器是其他客户端图形SoC通过片对片链路3107可访问的。
如图32中所示,可以构造单片服务器设备3200,其包括具有有源基础管芯3204和服务器图形片3206的封装3202。封装3202可以包括多个HBM互连3210A-3210B,其用于经由有源基础管芯3204实现服务器图形片3206与HBM存储器之间的连接,该HBM存储器也可被包括在封装3202上或驻留在单独的封装中。单片服务器设备3200包括处于有源基础管芯3204上的单个服务器图形SoC片,但是包括多个连接性管芯3205A-3205A,这些连接性管芯3205A-3205A经由夹层连接器3201A-3201B实现与其他封装的连接,这允许对多封装服务器GPU的组装。
如图33中所示,可以构造多片服务器设备3300,其包括具有单个有源基础管芯3304和多个服务器图形片3306A-3306B的封装3302。如所图示,有源基础管芯3304的单个实例可以包括多个服务器图形片3306A-3306B。在一个实施例中,封装3302可以被配置成用于接纳有源基础管芯3304的多个实例。由此,服务器产品的计算和存储器密度可以基于有源基础管芯3304上所包括的服务器图形片3306A-3306B的数量、有源基础管芯3304的实例的数量、以及与服务器图形片3306A-3306B相关联的HBM互连3210A-3210D的相关联的数量来缩放。有源基础管芯3304可以包括充当用于多片服务器设备3300的全局系统缓存的缓存存储器。当存在有源基础管芯3304的多个实例时,可以创建分布式系统缓存。
图34图示根据实施例的、用于模块化图形SoC的可互换小芯片系统。在一个实施例中,可互换小芯片系统3400包括至少一个基础小芯片3410,该至少一个基础小芯片3410包括多个存储器小芯片槽3401A-3401F以及多个逻辑小芯片槽3402A-3402F。逻辑小芯片槽(例如,3402A)和存储器小芯片槽(例如,3401A)可由互连桥接器3435连接,该互连桥接器3435可与本文中描述的其他互连桥接器类似。逻辑小芯片槽3402A-3402F可经由结构互连3408被互连。结构互连3408包括交换逻辑3418,该交换逻辑3418可被配置成用于通过将数据封装为结构分组而以对数据不可知的方式使得能够在逻辑小芯片槽之间中继数据分组。结构分组随后可被交换到结构互连3408内的目的地槽。
结构互连3408可包括一个或多个物理数据信道。一个或多个可编程虚拟信道可由每个物理信道承载。虚拟信道可被独立地仲裁,其中信道访问逐虚拟信道单独地被协商。通过虚拟信道的通信量可被分类为一个或多个通信量类别。在一个实施例中,优先级排定系统允许虚拟信道和通信量类别被指派用于仲裁的相对优先级。在一个实施例中,通信量平衡算法操作以向耦合至结构的每个节点维持基本相等的带宽和吞吐量。在一个实施例中,结构互连逻辑以比耦合至结构的节点高的时钟速率操作,从而在维持节点之间的带宽要求的同时允许互连宽度的减小。在某些节点要求较高带宽的情况下,多个物理链路可被组合以承载单个虚拟信道。在一个实施例中,每个物理链路在空闲时可单独地被时钟门控。可将早期指示即将到来的活动用作在数据被传送之前唤醒物理链路的触发。
图35图示根据实施例的、用于配置用于模块化图形SoC的组件集合的方法3500。方法3500可以在图形设备的最终产品配置期间执行,如本文中所描述,该图形设备将使用图形SoC 2700的模块化客户端/服务器体系结构来构造。
方法3500包括配置用于封装的有源基础管芯的数量(即,步骤3502)。封装可以被配置成包括一个或多个有源基础管芯。方法3500附加地包括配置用于每个基础管芯的小芯片片(chiplet tile)的数量(即,步骤3504)。有源基础管芯可以包括一个或多个小芯片片。对于服务器产品,可以经由对用于连接多个封装的插槽的使用来添加附加的有源基础管芯和小芯片片。方法3500附加地包括配置存储器子系统(即,步骤3506)。分别对于低功率产品、客户端产品和服务器产品,存储器子系统可以包括例如针对LPDDR、GDDR或HBM存储器的存储器控制器和物理接口。方法3500附加地包括配置处理资源的类型和数量(即,步骤3508)。在一个实施例中,计算资源可以处于单独的管芯上并且可以独立地被配置,其中,客户端部件和服务器部件具有不同数量的图形核心集群、具有含不同数量的图形核心的图形核心集群、或者具有在向量引擎和矩阵引擎之间具有不同平衡的图形核心。方法3500附加地包括基于图形SoC片的所配置的部件来配置可编程SoC地址解码器(即,步骤3510)。经由对可编程SoC地址解码器的使用,可以基于图形SoC片的最终配置来调整用于SoC内的部件通信的地址。
附加的示例性计算设备
图36是根据实施例的包括图形处理器3604的计算设备3600的框图。计算设备3600的多个版本可以是通信设备或可被包括在通信设备内,该通信设备诸如机顶盒(例如,基于互联网的有线电视机顶盒等)、基于全球定位系统(global positioning system,GPS)的设备等。计算设备3600还可以是移动计算设备或可被包括在移动计算设备内,该移动计算设备诸如,蜂窝电话、智能电话、个人数字助理(personal digital assistant,PDA)、平板计算机、膝上型电脑、电子阅读器、智能电视、电视平台、可穿戴设备(例如,眼镜、手表、项链、智能卡、首饰、服饰等)、媒体播放器等。例如,在一个实施例中,计算设备3600包括采用集成电路(integrated circuit,“IC”)(诸如,片上系统(system on a chip,“SoC”或“SOC”))的移动计算设备,该集成电路将计算设备3600的各种硬件和/或软件部件集成在单个芯片上。计算设备3600可以是包括可以从如本文中所描述的图形SoC 2700的模块化服务器/客户端体系结构构造的部件的计算设备。
计算设备3600包括图形处理器3604。图形处理器3604表示本文中描述的任何图形处理器。在一个实施例中,图形处理器3604包括缓存3614,该缓存3614可以是单个缓存,或可被划分为缓存存储器的多个片段,该缓存3614包括但不限于任何数量的L1缓存、L2缓存、L3缓存或L4缓存、渲染缓存、深度缓存、采样器缓存、和/或着色器单元缓存。在一个实施例中,缓存3614可以是与应用处理器3606共享的最后一级缓存。
在一个实施例中,图形处理器3604包括图形微控制器,该图形微控制器实现用于图形处理器的控制和调度逻辑。控制和调度逻辑可以是由图形微控制器3615执行的固件。固件可以在引导时由图形驱动器逻辑3622加载。固件也可以被编程到电子可擦除可编程只读存储器,或从图形微控制器3615内的闪存设备加载。固件可以启用GPU OS 3616,该GPUOS 3616包括设备管理逻辑3617和驱动器逻辑3618、以及调度器3619。GPU OS 3616还可包括图形存储器管理器3620,该图形存储器管理器3620可补充或替换图形驱动器逻辑3622内的图形存储器管理器3621。
图形处理器3604还包括GPGPU引擎3644,该GPGPU引擎3644包括如本文所述的一个或多个图形引擎、图形处理器核心、以及其他图形执行资源。此类图形执行资源能以包括但不限于以下各项的形式来呈现:执行单元、着色器引擎、片段处理器、顶点处理器、流式多处理器、图形处理器集群、或适于处理图形或图像资源或在异构处理器中执行通用计算操作的计算资源的任何集合。GPGPU引擎3644的处理资源可被包括在连接到衬底的硬件逻辑的多个片内,如图24B-图24D中所图示。GPGPU引擎3644可包括GPU片3645,这些GPU片3645包括图形处理和执行资源、缓存、采样器等。GPU片3645还可包括本地易失性存储器或可与一个或多个存储器片耦合,这一个或多个存储器片诸如图16B-图16C中的存储器片1626A-1626D。
GPGPU引擎3644还可包括一个或多个特殊片3646,这一个或多个特殊片3646包括例如非易失性存储器片3656、网络处理器片3657、和/或通用计算片3658。GPGPU引擎3644还包括矩阵乘法加速器3660。通用计算片3658还可包括用于加速矩阵乘法操作的逻辑。非易失性存储器片3656可包括非易失性存储器单元和控制器逻辑。非易失性存储器片3656的控制器逻辑可由设备管理逻辑3617或驱动器逻辑3618中的一个来管理。网络处理器片3657可包括网络处理资源,该网络处理资源耦合至计算设备3600的输入/输出(input/output,I/O)源3610内的物理接口。网络处理器片3657可由设备管理逻辑3617或驱动器逻辑3618中的一个或多个来管理。
矩阵乘法加速器3660是如本文中所述的模块化可缩放稀疏矩阵乘法加速器。矩阵乘法加速器3660可包括多个处理路径,其中每个处理路径包括多个管线阶段。每个处理路径可执行单独的指令。在各实施例中,矩阵乘法加速器3660可具有本文中描述的矩阵乘法加速器中的任何一个或多个的体系结构特征。例如,在一个实施例中,矩阵乘法加速器3660是双管线并行脉动阵列。在一个实施例中,矩阵乘法加速器3660可配置成用于仅对至少一个输入矩阵的非零值进行操作。在存在块稀疏度的情况下,可以绕过对整个列或子矩阵的操作。矩阵乘法加速器3660还可以包括基于这些实施例的任何组合的任何逻辑,并且特别地包括根据本文中描述的实施例的用于启用对随机稀疏度的支持的逻辑。例如,矩阵乘法加速器3660可以被配置用于接受按照稀疏编码或经压缩的稀疏编码的输入并且仅对输入的非零值进行操作。
如所图示,在一个实施例中,除了图形处理器3604之外,计算设备3600可进一步包括任何数量和类型的硬件部件和/或软件部件,包括但不限于应用处理器3606、存储器3608、以及输入/输出(input/output,I/O)源3610。应用处理器3606可与硬件图形管线交互以共享图形管线功能。经处理的数据被存储在硬件图形管线中的缓冲器中,并且状态信息被存储在存储器3608中。所得的数据可以被传递至显示控制器以用于经由显示设备来输出。显示设备可具有各种类型,诸如,阴极射线管(Cathode Ray Tube,CRT)、薄膜晶体管(Thin Film Transistor,TFT)、液晶显示器(Liquid Crystal Display,LCD)、有机发光二极管(Organic Light Emitting Diode,OLED)阵列等,并且显示设备可配置成用于经由图形用户界面来向用户显示信息。
应用处理器3606可包括一个或多个处理器,诸如,图1的(一个或多个)处理器102,并且可以是至少部分地用于执行计算设备3600的操作系统(operating system,OS)3602的中央处理单元(central processing unit,CPU)。OS 3602可充当计算设备3600的硬件和/或物理资源与一个或多个用户之间的接口。OS 3602可包括用于计算设备3600中的各种硬件设备的驱动器逻辑。驱动器逻辑可包括图形驱动器逻辑3622,该图形驱动器逻辑3622可包括图23的用户模式图形驱动器2326和/或内核模式图形驱动器2329。图形驱动器逻辑可以包括图形存储器管理器3621,用于管理用于图形处理器3604的虚拟存储器地址空间。图形存储器管理器3621可促进可由应用处理器3606和图形处理器3604访问的统一虚拟地址空间。
设想了在一些实施例中,图形处理器3604可以作为应用处理器3606的部分(诸如,物理CPU封装的部分)而存在,在这种情况下,存储器3608的至少部分可以由应用处理器3606和图形处理器3604共享,但是存储器3608的至少部分可以是图形处理器3604独有的。图形处理器3604可以具有存储器的单独存储。存储器3608可包括缓冲器的预分配区域(例如,帧缓冲器);然而,本领域普通技术人员应当理解,实施例不限于此,并且可使用可由较低的图形管线访问的任何存储器。存储器3608可包括各种形式的随机存取存储器(random-access memory,RAM)(例如,SGRAM、SDRAM、SRAM等),其包含利用图形处理器3604以渲染桌面或3D图形场景的应用。在一个实施例中,存储器3608具有多级层次体系,包括处理器本地HBM存储器和系统范围的存储器,系统范围的存储器可以包括DDR存储器(例如,DDR5等)。系统存储器的一部分也可以是非易失性持久存储器。
存储器控制器中枢(诸如,图14的存储器控制器1416)可访问存储器3608中的数据,并将其转发到图形处理器3604以用于图形管线处理。存储器3608可变得对计算设备3600内的其他部件可用。例如,在软件程序或应用的实现方式中,从计算设备3600的各种I/O源3610接收的任何数据(例如,输入图形数据)在由一个或多个处理器(例如,应用处理器3606)操作之前可临时被排队到存储器3608中。类似地,软件程序确定应当从计算设备3600通过设备的通信接口中的一个通信接口被发送到外部实体或者应当被存储到内部存储元件内的数据在被传送或被存储之前通常临时被排队在存储器3608中。
I/O源可包括诸如触摸屏、触摸面板、触摸板、虚拟或常规键盘、虚拟或常规鼠标、端口、连接器、网络设备等之类的设备,并且可经由如图14中引用的平台控制器中枢1430进行附接。此外,I/O源3610可包括被实现用于将数据传递到计算设备3600和/或从计算设备3600传递数据的一个或多个I/O设备(例如,网络适配器);或者被实现用于计算设备3600内的大规模非易失性存储装置的一个或多个I/O设备(例如,SSD/HDD)。包括字母数字和其他键的用户输入设备可用于将信息和命令选择传递到图形处理器3604。另一类型的用户输入设备是用于将方向信息和命令选择传递到GPU并用于控制显示设备上的光标移动的光标控件,诸如,鼠标、轨迹球、触摸屏、触摸板、或光标方向键。可采用计算设备3600的相机和话筒阵列来观察姿势、记录音频和视频,并且接收和传送可视命令和音频命令。
I/O源3610可包括一个或多个网络接口。网络接口可包括相关联的网络处理逻辑和/或与网络处理器片3657耦合。一个或多个网络接口可提供对以下各项的访问:LAN、广域网(wide area network,WAN)、城域网(metropolitan area network,MAN)、个域网(personal area network,PAN)、蓝牙、云网络、蜂窝或移动网络(例如,第三代(3rdGeneration,3G)、第四代(4th Generation,4G)、第五代(5th Generation,5G)等)、内联网、因特网等。(一个或多个)网络接口可包括例如具有一个或多个天线的无线网络接口。(一个或多个)网络接口还可包括例如用于经由网络电缆与远程设备通信的有线网络接口,网络电缆可以是例如以太网电缆、同轴电缆、光纤电缆、串行电缆或并行电缆。
(一个或多个)网络接口可例如通过遵照IEEE 802.11标准来提供对LAN的访问,并且/或者无线网络接口可例如通过遵照蓝牙标准来提供对个域网的访问。还可支持其他无线网络接口和/或协议,包括先前版本和后续版本的标准。附加于或替代于经由无线LAN标准的通信,(一个或多个)网络接口可使用例如以下协议来提供无线通信:时分多址(TimeDivision,Multiple Access,TDMA)协议、全球移动通信系统(Global Systems for MobileCommunications,GSM)协议、码分多址(Code Division,Multiple Access,CDMA)协议和/或任何其他类型的无线通信协议。
应当理解,对于某些实现方式,比在上文中所描述的示例更少或更多地配备的系统可以是优选的。因此,取决于多种因素,本文中描述的计算设备的配置可因实现方式而异,这些因素诸如,价格约束、性能要求、技术改进、或其他情况。示例包括(但不限于)移动设备、个人数字助理、移动计算设备、智能电话、蜂窝电话、手机、单向寻呼机、双向寻呼机、消息收发设备、计算机、个人计算机(personal computer,PC)、桌面型电脑、膝上型电脑、笔记本计算机、手持式计算机、平板计算机、服务器、服务器阵列或服务器场、web服务器、网络服务器、互联网服务器、工作站、小型计算机、大型计算机、超级计算机、网络装置、web装置、分布式计算系统、多处理器系统、基于处理器的系统、消费电子产品、可编程消费电子产品、电视机、数字电视、机顶盒、无线接入点、基站、订户站、移动订户中心、无线电网络控制器、路由器、中枢、网关、桥接器、交换机、机器、或其组合。
本文中所描述的实施例提供了一种图形处理器,该图形处理器包括:有源基础管芯,该有源基础管芯包括结构互连;以及小芯片,该小芯片包括交换结构,其中,小芯片经由互连组织阵列与有源基础管芯耦合,该互连组织阵列将结构互连与交换结构耦合,并且小芯片包括:第一模块化互连,该第一模块化互连被配置成用于将图形处理资源块耦合至交换结构;以及第二模块化互连,该第二模块化互连被配置成用于将存储器子系统与交换结构和图形处理资源块耦合,存储器互连包括存储器控制器集合和物理接口集合。在一个实施例中,第一小芯片附加地包括被配置成用于将主机互连物理接口和上游端口耦合至交换结构的第三模块化互连,该第三模块化互连被配置成用于经由结构桥接器而与交换结构耦合。存储器子系统与图形双倍数据速率(GDDR)存储器设备或高带宽存储器(HBM)设备相关联。第一模块化互连被配置成用于将具有第一数量的图形核心集群的第一图形处理资源块或具有第二数量的图形核心集群的第二图形资源块中的一者耦合至交换结构。第一图形处理资源块包括第一图形核心集合,该第一图形核心集合中的每个图形核心包括矩阵加速器和向量引擎。第二图形处理资源块包括第一图形核心集合,该第一图形核心集合中的每个图形核心包括向量引擎。向量引擎包括可配置用于执行可变向量宽度操作的硬件逻辑。一个实施例附加地包括与第一小芯片耦合的第二小芯片,该第二小芯片包括缓存存储器,其中,该缓存存储器是最后一级缓存。存储器子系统具有可动态地配置的电压和频率。
一个实施例提供一种包括上文所描述的图形处理器的图形处理设备。
一个实施例提供一种用于使用本文中所描述的模块化客户端/服务器图形SoC体系结构来配置图形处理设备的方法。该方法包括配置用于封装的有源基础管芯的数量,其中,该封装可以被配置成包括一个或多个有源基础管芯。方法附加地包括:配置用于每个基础管芯的小芯片片的数量;配置用于图形处理设备的存储器子系统;配置处理资源的类型和数量;以及基于图形SoC片的所配置的部件来配置可编程SoC地址解码器。
前述说明书和附图应以说明性意义而非限制性意义来看待。本领域技术人员将理解,可对本文中描述的实施例作出各种修改和改变,而不背离如所附权利要求所述的特征的更宽泛的精神和范围。