一种基于FPGA的通用卷积神经网络加速器实现方法
文献发布时间:2023-06-19 19:30:30
技术领域
本发明涉及深度学习、嵌入式机器视觉领域,特别是涉及一种基于FPGA的通用卷积神经网络加速器实现方法。
背景技术
目前,深度学习特别是卷积神经网络在目标检测和识别领域得到了广泛应用。随着卷积神经网络模型结构的复杂性增加和识别精度的提高,对部署平台的算力提出了挑战。目前,该类算法的部署几乎都以GPU为主,而难以在嵌入式平台以及低端的CPU运行,从而导致高性能的模型难以在基于嵌入式设备的移动端实现。另一方面,尽管ASIC芯片具有高算力,高能效等优点,可以在特定领域内代替GPU,但是ASIC的开发周期长,而神经网络的架构更新较快,导致硬件的迭代周期无法满足算法的要求。因此,FPGA以其并行性和计算结构的可快速重构性,以及低功耗,高能效的优点,为深度学习算法的部署提供了新的思路。同时卷积神经网络具有计算单一性的特点,这使得FPGA可以很容易做并行加速,从而满足高算力的要求。
发明内容
为解决上述问题,本发明提供一种基于FPGA的通用卷积神经网络加速器实现方法,其特征是异构计算,可拓展。所述异构即本发明所述方法采用软硬协同的方式设计了一种通用的卷积神经网络加速器架构,在FPGA的处理器系统侧设计了控制算法,在FPGA的可编程逻辑侧设计了RTL卷积神经网络加速器IP,通过配置可实现对不同网络模型的加速。
本发明的技术方案:
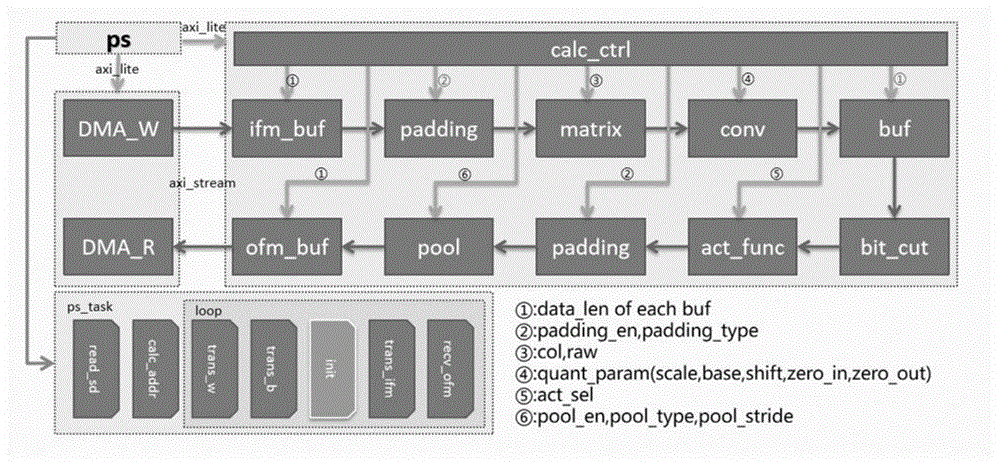
一种基于FPGA的通用卷积神经网络加速器实现方法,包括处理器系统(PL)和可编程逻辑(PL)两部分,硬件平台采用XILINX的ZYNQ系列FPGA,在FPGA的处理器系统侧设计控制算法,在FPGA的可编程逻辑侧设计RTL卷积神经网络加速器IP,硬件系统中包含摄像头和VGA接口,对摄像头采集的图像进行识别,并将结果通过VGA接口输出到外接屏幕。
所述处理器系统包括CORTEX-M0的处理器内核、DMA、DDR控制器、DDR、SDIO控制器,以及处理器运行控制算法和摄像头驱动程序;所述处理器运行控制算法包括在中断服务函数中根据网络层数关系计算对应的参数地址,DMA发送和接收的地址和使能信号,以及对RTL卷积神经网络加速器IP控制寄存器的写操作,所有的参数都保存在各自的数组中,每次计算需要的参数为数组中的一段数据,而参数要通过DMA发送给RTL卷积神经网络加速器IP,所以每次计算前要将所需数据对应的地址给到DMA,DMA把该段地址的数据发送给RTL卷积神经网络加速器IP,另外还要通过AXI_lite协议来配置加速器的计算模式,AXI_lite协议用4个32BIT的寄存器,将寄存器译码成需要的控制信息,传给RTL卷积神经网络加速器IP。
所述RTL卷积神经网络加速器IP包括矩阵生成模块、padding模块、DSP阵列模块、重量化模块、池化模块、AXI总线模块和多个片上缓存;片上缓存包括输入特征图缓存、权重缓存、偏置缓存、中间结果缓存和输出特征图缓存,其中权重缓存、输入图像缓存及输出图像缓存均为8BIT,偏置缓存为16BIT,中间结果缓存为32BIT;加速器的输入输出为AXI_lite协议和AXI_stream协议接口;矩阵生成模块是在输入特征图上提取滑动窗口;padding模块采用硬件padding模式,用于在图像周围补零;DSP阵列模块为加速器的计算单元,用于并行加速乘累加操作;重量化模块是将计算完的高BIT数据量化为8BIT,以便下一层直接计算;池化模块即降采样,用于压缩特征图,提取特征;AXI总线模块包含AXI_lite模块和AXI_stream模块,AXI_lite模块用于传递控制信息,AXI_stream模块用于传递数据流;多个片上缓存用于量化后参数的存放以及输入特征图、中间计算结果和输出特征图的缓存。
所述矩阵生成模块由两个同步FIFO及外围控制电路构成;将FIFO首尾相连,数据依次进入第一个FIFO,第一个FIFO的输出将控制在下一行开始,并将读出的数据写入第二个FIFO,这样由缓存在FIFO中的两行数据以及输入的第三行数据就可以在每个时钟生成一个像素矩阵。
所述padding模块是为了让卷积输出的特征图尺寸与输入相同,卷积计算前和池化计算前在图像的周围补零;padding模块与输入特征图或者中间层结果缓存区配合工作;在padding模块中,对行列进行计数,根据需要设置的补零格式计算需要补零的位置,计数到对应的补零位置时,将读取使能拉低,而在其余位置将读使能拉高;padding模块支持两种补零格式,其一是在图像周围加一圈零,其二是在图像右侧和底边各加一圈零,比如输入图像的大小是28*28,经过第一种补零之后,尺寸变为30*30,而经过第二种之后,尺寸应变为29*29。
所述DSP阵列模块输入的数据有8BIT的特征图、8BIT的权重数据和16BIT的偏置数据;其中权重数据和特征图要进行乘累加,最后要加上偏置,所以输出的数据宽度为19BIT,经过重量化模块之后,位宽变为32BIT;在DSP阵列模块中,由于DSP的数据位宽是固定的,卷积的数据均为8BIT,可以利用乘法结合律使得一个DSP做两个乘法,所以用288个DSP做576个乘法,可实现64路卷积并行计算,这里乘法结果是8BIT;在乘法之后,设计加法树对乘法结果累加,比如对于3*3的窗口而言,有9个16BIT数进行累加,累加结果用20BIT保存,这里的数据要进入重量化模块。
所述重量化模块是为了让上一层计算的20BIT结果变为8BIT,然后8BIT用32BIT保存,后续会截位到8BIT,进而可直接用于下一层的输入,量化的原理与PC端量化原理相同,重量化模块的scale是在PC端量化算法中通过观测得到,只需要通过处理器系统用AXI_lite协议发送给加速器即可;另外由于不同网络之间卷积层数量不同的关系,在重量化之后设置了中间结果缓存区,用于多批次计算结果的累加,重量化模块还要控制中间结果缓存区的读使能,使中间层结果缓存区读出的数据与重量化模块的计算输出数据在时序上对齐,以便于多批次的累加;在重量化计算过程中涉及到舍入操作,选用两种舍入方法供配置,即向偶数舍入和四舍五入,根据软件算法版本不同,舍入不同,可以灵活选择,同时设计低BIT矫正算法,用于硬件实现向偶数舍入。
所述池化模块是指最大值池化,由一个同步FIFO及外部控制电路构成,原理为将输入的数据逐个比较大小,把结果存入FIFO中,第二行数据做同样的操作,等第二行的结果出现时要和上一行的数据比较,就得到了最大值池化的结果。
所述多个片上缓存均基于双口BRAM设计;其中,在权重缓存中,将输入权重数据流进行转置,使其满足并行计算的格式要求;偏置缓存中,每个时钟输入64BIT的数据,即4个偏置参数(4*16BIT),两个是时钟输入一组(8*16BIT),分别存在8个BRAM中;而在输入特征图和输出特征图的缓存中,均采用乒乓的策略,以便流水下计算的同时依然能够读取之前的计算结果。
与现有技术相比,本发明的有益效果是:本发明基于FPGA,设计了一种通用的卷积神经完了过加速器实现方法,基于此方法设计的通用卷积神经网络加速器,根据FPGA资源做了细粒度的优化,并且在精度满足要求的情况下,将参数占用的存储空间降低至1/4,大量节约了资源,通过对DSP的高效利用将卷积的并行度提高到64路,极大的提高了卷积神经网络的前向推理速度,峰值算例达到60GOPS,功耗3.105W,加速器部分功耗0.526W,占用LUT18167个,DSP297个,BRAM100个,与桌面级CPU和GPU相比,具有更高的能效比。此外,本领域技术人员可根据本方法的架构进行拓展和裁剪,以便于对应更高和更低资源的FPGA。
附图说明
图1为加速器架构及单层卷积计算流程图。
图2为模型计算流程图。
具体实施方式
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
PC端训练好的网络无法直接部署在FPGA上,需要先做量化,在本发明中,选择将权重量化为INT8数据类型,偏置量化为16BIT数据,具体方法为在每一层之中插入观察器,用于观察参数的scale,这个观察的过程需要用测试集的数据推理至少一百次,这样可以观察到一组合适的参数,利用这个scale对权重,偏置进行量化计算,需要提到的是,PYTORCH并没有对偏置进行量化,而是进行了浮点型的运算,由于加速器中并未设计浮点运算单元,所以需要把偏置量化到16BIT,而偏置的scale直接用权重的scale代替,量化原理为:
q=round(r/s+zero)
其中q为INT8型的、量化后的数据;r为浮点型;s是scale,代表浮点数的数据范围;zero是量化后的零点位置。
接着提取参数。量化后的数据分层写入bin文件,再写入时根据加速器中缓存区的设计,要对PYTORCH导出的tensor格式做相应的转置,以方便后续数据的传输和保存,接着将数据写入BIN文件,放在SD卡中。
量化后的权重数据存在SD卡中,先通过处理器系统缓存在DDR中,后续通过控制算法分别将每一层的权重参数传入加速器中的权重缓存区,该过程由DMA完成。
量化后的偏置数据存在SD卡中,先通过处理器系统缓存在DDR中,后续通过控制算法分别将每一层的权重参数传入加速器中的偏置缓存区,该过程由DMA完成。
对于输入特征图,可以是SD卡中的图片,也可以是摄像头的像素数据,这里用摄像头数据举例说明。摄像头采用SCCB协议初始化,可以使用硬件和软件两种方法配置,SCCB与IIC类似,软件实现的原理即模拟IIC时序,写入配置信息,摄像头接口采用DVP接口,每个时钟传入一个8BIT数据,而摄像头传入的初始数据格式为RGB565,共16BIT,所以这里需要两个时钟才能接受一个完整的像素数据,接着要把RGB565转化为RGB888,通常的做法是将高位数据补到低位,对于R通道来说,将高三位数据添加到低三位,对于G通道来说,将高两位添加到低位,而B通道与R通道做法相同。补位后的数据缓存在DDR中.而加速器输入通道为8,所以在计算前的时候还需要把剩余通道补零。该过程由处理器系统完成。
如图1所示,数据准备好之后,进入loop任务中,下面将分步骤描述单层卷积计算的流程:
第一步:发送权重数据。前面步骤中已经将量化后的参数存在DDR中,包括权重,偏置以及量化参数等,接着把一次计算需要的权重发送到加速器IP中的权重缓存区,这里的权重缓存区是经过特殊设计的,可以满足多通道并行计算的要求,发送完成后每次参数更新由处理器系统控制,若卷积层的权重数超过缓存区能够缓存的数量,那么权重应该分批次发送。
第二步:发送偏置数据。把一次计算需要的权重发送到加速器IP中的偏置缓存区,这里的偏置缓存区与权重缓存类似,只是位宽不同,发送完成后每次参数更新由处理器系统控制,同样的,若偏执参数数量超过缓存区能够缓存的数量,那么偏置应该分批次发送。
第三步:加速器进行初始化,将控制信息传给加速器的寄存器组,这里的寄存器组是4个32BIT的寄存器,用AXI_lite协议传送,要根据模型的参数配置本次计算的加速器参数,可提供配置的寄存器有如下:
第四步:发送特征图。加速器IP的计算主要分为两段流水线,第一段流水线是通过DMA将数据传入RTL加速器上的输入缓存区,padding模块会读取缓存区中的数据,判断是否需要进行padding操作,并且将数据传给矩阵生成模块,接着生成卷积的滑动窗口,再将这个窗口中的数据传给DSP阵列模块;DSP阵列模块中将接收到的参数做乘累加,同时会根据控制信息判断是否需要累加上次计算的结果,并且将结果输出给重量化模块;重量化模块把累加后的高位宽数据重新量化为8BIT,并且存入中间结果缓存区;第二段流水线是padding模块从中间结果缓存区读取数据,并且判断是否需要执行padding操作,将处理后的数据传给池化模块;池化模块判断是否需要进行pooling操作,以及执行pooling的类型,本加速器中支持最大值池化,在本加速器架构下,用户可自行添加平均值池化等,池化后的数据写入输出数据缓存区;上述流水线的所有数据都以data,valid的组合给出,方便各模块进行设计和调试。
第五步:接收计算结果。计算完成以后的输出特征图缓存在输出缓存区,接着加速器会拉起发送使能,这时候加速器侧的AXI_stream主机发起握手,从机为DMA的接收通道,握手成功之后,将输出缓存区中的数据传回DDR中,在这期间,处理器系统已经计算好了将要传回来的数据要存放的地址空间,当传输过程结束后,DMA拉起处理器系统的中断,在中断服务函数中做一些标志位的处理,至此,一次计算完成,如果卷积层的通道数大于加速器单次可计算的通道数,可重复执行上述过程。
以上为单层卷积计算的流程,而卷积神经网络通常会有很多层,由于本方法提出的是一种通用的加速器,可以稍加配置实现对各种卷积的加速,如图2所示,一个卷积层如果单次计算无法完成,就要循环计算多次,而对于完整网络来说,则按照单层的方法循环计算多次,后续层可用相同的计算方法,需要根据层数关系配置控制寄存器。