一种基于流量前域对抗混淆的网站指纹防御方法
文献发布时间:2023-06-19 19:32:07
技术领域
本发明涉及网络安全技术,具体涉及一种基于流量前域对抗混淆的网站指纹防御方法。
背景技术
随着互联网使用率的增长,网络隐私保护成为互联网用户的一种普遍需求。基于洋葱路由的匿名网络Tor已经成为最流行的互联网隐私增强技术之一。然而,Tor网络易受网站指纹攻击的影响。网站指纹攻击是一种流量分析攻击,可以使本地被动窃听者获知匿名用户正在访问的网站,对网络用户隐私安全造成了极大的威胁。在机器学习的角度上,网站指纹攻击可以被建模为一个分类问题,攻击者,如用户互联网服务提供商、本地系统管理员,可以利用用户访问网站流量特征的差异,分类不同网站。攻击者提取流量的特征信息(如数据包大小,数据包发送时间等),对流量所属的网站进行识别。因此网站指纹攻击的性能很大程度上取决与分类器算法与提取的数据特征。
为了应对网站指纹攻击的威胁,许多网站指纹防御方案被提出,它们通过虚拟数据包填充将一条敏感流量的特征进行掩盖或混淆。但这些防御方法只考虑全局的流量序列统计信息,缺乏对具体保护流量的个性化填充设计。因此,当前提出的网站指纹防御方案在防御性能和针对性上存在不足。
发明内容
发明目的:为解决当前提出的网站指纹防御方案在防御性能和针对性上存在的不足,该方法针对网络用户产生的网络流量,基于对抗学习方法,在网络流量前域填充虚拟数据包,生成网络流量对抗样本,混淆网络流量模式信息,成功抵御了基于深度神经网络的网站指纹攻击,对匿名流量用户隐私安全实现保护,本发明提供一种基于流量前域对抗混淆的网站指纹防御方法。
技术方案:本发明的一种基于流量前域对抗混淆的网站指纹防御方法,主要是针对任意一网络流量w
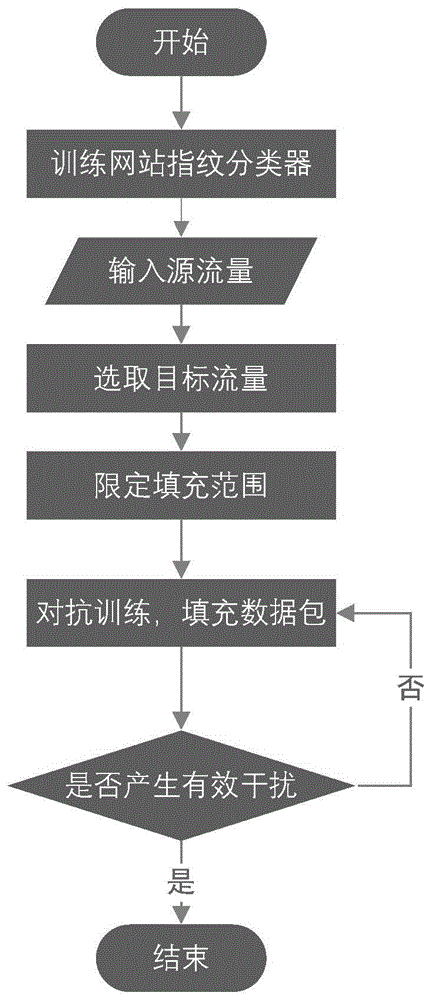
步骤(1)、训练网站指纹分类器
首先,收集网络流量:使用抓包工具收集访问流量,将抓取到的网络流量转换为可用格式,并对每条网络流量打上对应网站的标签;
然后,提取网络流量中数据包方向特征:网络流量中的数据包一部分由客户端发送,另一部分由服务器发送,将来自两种发送方的发送方向提取;
接着,将所得数据包方向特征转换为突发形式,所述突发是指同一方向上的连续数据包序列,突发形式下的数据包发送方向信息由每个突发中含有的数据包个数组成;
最后,使用网站流量突发数据训练网站指纹分类器:网站指纹分类器的损失函数为交叉熵函数,以实现较高的精度;
步骤(2)、选定目标流量轨迹
访问非敏感网站,从收集到的非敏感网络流量数据集中抽取一定量的网络流量,提取网络流量中数据包的方向信息,构成随机流量池;在随机流量池中选择与原始轨迹方向信息分布相近的一条网络轨迹,作为目标轨迹w
步骤(3)、限定填充范围
根据实际部署需求,确定网络流量前域信息富集区,划分虚拟数据包的填充范围;此处将填充范围限定为前域信息富集区,流量前域含有更多的特征信息,因此将数据包填充至流量前域对网站指纹攻击者的干扰会更有效,同时也会使得填充的数据包总量变少,减小网站指纹防御部署所产生的带宽消耗;
步骤(4)、填充数据包
在原始轨迹w
步骤(5)、判断填充后轨迹性能
依据网站指纹分类器预测错误的概率是否超过阈值判断填充是否成功,具体内容为:判断步骤(3)中的填充是否有效干扰步骤(1)中训练的基于深度网络的网站指纹分类器,干扰不成功则转回到步骤(3),干扰成功则输出为防御成功的轨迹w
进一步地,所述步骤(1)中使用抓包工具收集网络访问流量,将抓取到的网络流量转换为可用格式,并对每条网络流量打上对应网站的标签;使用网络流量突发作为训练数据,训练深度学习网络作为后续使用的网站指纹分类器;所述网站指纹分类器由输入层、卷积层、全连接层与Softmax层构成,输入层获取网站指纹信息,卷积层对于网站指纹信息进行提取与筛选,全连接层对于提取出的网站指纹特征进行分类,Softmax层将分类结果输出,分类器损失函数为交叉熵函数,即为:
其中p为网站指纹分类的真实概率分布,q为网站指纹分类器预测的概率分布;x
进一步地,所述步骤(2)的具体过程为:
从非敏感网络流量数据集中抽取一定量的网络流量轨迹,提取网络流量数据包中的方向信息,以网络流量中的突发信息构成随机流量池;
依次计算随机流量池中网络流量突发与原始轨迹间的距离,将其作为衡量分布信息相近程度的依据;在随机流量池中选择与原始轨迹方向信息分布相近的一条网络轨迹,作为目标轨迹w
原始轨迹记为w
/>
d(w
D=γd(w
流量间距离D由两类距离乘以对应系数γ构成。
进一步地,所述步骤(4)中填充数据包的具体过程为:
计算原始轨迹w
其中,t
单个突发填充量计算公式为:
若目标轨迹的单个突发大于原始轨迹的单个突发,则依据两者的曼哈顿距离逐步填充至网站指纹分类器无法分辨。
有益效果:本发明针对现有网站指纹防御只考虑全局的流量序列统计信息,缺乏对具体保护流量的个性化填充设计的问题,结合对抗性样本生成技术与流量前域填充方案,在随机流量池中依据流量序列分布距离选取目标轨迹,通过双向填充虚拟数据包掩盖原始流量特征,混淆网站指纹攻击者的分类器,对匿名流量用户隐私安全产生切实有效的保护。本发明使用对抗性样本生成技术,在数据集中故意添加细微的干扰,以导致深度网站指纹攻击误分类,增强填充方案的干扰性能;仅向流量的前几秒,即流量前域,进行虚拟数据包填充,以避免填充流量全长导致的大量带宽开销,增强可部署性。
附图说明
图1为本发明的整体流程图;
图2为本发明中数据包填充流程示意图。
具体实施方式
下面对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
本发明结合对抗性样本生成技术与前域流量填充方法,混淆用户的网站指纹流量特征。首先抓取流量用作分类器训练集与目标流量集,然后训练一个有一定分类精度的网站指纹分类器。当一条网络流量需要被保护时,在之前收集到的目标流量集中选定一条分布与被保护流量相近的目标轨迹,并在限定的流量前域填充范围内进行多次数据包填充,直至分类器无法准确分类出受保护流量的类别。本发明能够通过双向填充虚拟数据包掩盖原始流量特征,混淆网站指纹攻击者的分类器,对匿名流量用户隐私安全实现保护。
本发明通过以下技术特征实现有效的流量填充,进而混淆网站指纹攻击者的分类器:
1.本发明将数据包填充范围限定至流量前域,使得填充带宽消耗有效降低,方案可部署性增加。
2.本发明使用对抗性样本生成技术,制定了有效的填充方案,提升了防御性能。
如图l所示,本发明一种基于流量前域对抗混淆的网站指纹防御方法,包括以下步骤:
步骤(1)、训练网站指纹分类器
收集网络流量,提取网络流量中数据包方向特征,然后将所得数据包方向特征转换为突发形式,所述突发是指同一方向上的连续数据包序列,突发形式下的数据包发送方向信息由每个突发中含有的数据包个数组成;
接着,使用网站流量突发数据训练网站指纹分类器:网站指纹分类器损失函数为交叉熵函数Loss;
其中p为网站指纹分类的真实概率分布,q为网站指纹分类器预测的概率分布;x
步骤(2)、选定目标流量轨迹
访问非敏感网站,从收集到的非敏感网络流量数据集中抽取一定量的网络流量,提取网络流量中数据包的方向信息,构成随机流量池;在随机流量池中选择与原始轨迹方向信息分布相近的一条网络轨迹,作为目标轨迹w
原始轨迹记为w
d(w
D=γd(w
流量间距离D由两类距离乘以对应系数γ构成;
步骤(3)、限定填充范围
根据实际部署需求,确定网络流量前域信息富集区,划分虚拟数据包的填充范围;
步骤(4)、填充数据包
在原始轨迹w
计算原始轨迹w
其中,t
单个突发填充量计算公式为:
若目标轨迹的单个突发大于原始轨迹的单个突发,则依据两者的曼哈顿距离逐步填充至网站指纹分类器无法分辨;
步骤(5)、判断填充后轨迹性能
判断步骤(3)中的填充是否有效干扰步骤(1)中训练的基于深度网络的网站指纹分类器,干扰不成功则转回到步骤(3),干扰成功则输出为防御成功的轨迹w
实施例
本实施例其他步骤同上,但是虚拟数据包填充算法如图2所示,具体如下:
算法1虚拟数据包填充算法
输入:初始流量序列w
输出:防御后流量序列w
1)从目标流量样本池T中挑选数量为N的流量样本,构成随机流量池T
2)将初始流量序列w
3)创建空流量序列w
4)d
5)for item
6)计算item
7)If d>d
8)w
9)end if
10)end for
11)while M正确分类w
12)向原轨迹w
13)end while
14)使用w
15)将w
上述虚拟数据包填充算法解释
假设有一组需要保护的站点,站点中有一个流量实例w
w
为给w
将原始轨迹记为w
d(w
D=γd(w
流量间距离D由两类距离乘以对应系数γ构成。
同时以w
其中,t
单个突发填充量计算公式为:
若目标轨迹的单个突发大于原始轨迹的单个突发,则依据两者的曼哈顿距离逐步填充至网站指纹分类器无法分辨。
在详细的特征注入过程中,w
上述实施例表明,本发明通过在网络流量中填充少量虚拟数据包,干扰网站指纹攻击者的分类器,规避用户通信信息泄露的风险。在此基础上,本发明使用对抗性样本生成技术,以增强填充方案的干扰性能;使用前域填充技术,以减轻部署防御造成的带宽开销,增强可部署性。本发明增强了防御技术的针对性,实现了对流量的个性化保护,实现了防护性能与带宽消耗之间的平衡,解决了匿名网络用户的隐私保护问题。