一种基于路网和排斥偏好的空间关键字组查询方法和系统
文献发布时间:2024-04-18 19:58:26
技术领域
本发明涉及空间数据库查询的领域,具体是一种基于路网和排斥偏好的空间关键字组查询方法和系统。
背景技术
空间关键字查询是空间数据库领域的重要研究问题。空间关键字查询有众多查询模型,其中,空间关键字组查询在日常生活中应用广泛,例如某游客去某城市旅游,在酒店中规划想要去的地点,需要包括一段时间内吃饭、逛公园、看电影等想要进行的活动,此时需要一组最优的目的地集合。空间关键字组查询技术可以返回一组兴趣点,这组兴趣点的关键字信息完整覆盖查询需求,因此空间关键字组查询技术在基于搜搜的服务中具有良好的研究前景。
目前已有的空间关键字组查询研究主要是考虑在欧式空间中匹配一组正向关键字的结果集。然而现实生活不同于欧式空间,欧式距离也不适用于真实情况,因此研究路网环境更有意义。除此之外,大多数研究没有考虑过用户的排斥偏好,即用户可能存在的忌口或者反感事项等偏好。所以,基于路网和排斥偏好的空间关键字组查询方法和系统可以提升用户体验。
对于此类NP-hard的决策问题,使用传统匹配的方法时间复杂度很高而且存储开销大,本发明提出一种新的索引技术,可以高效率的缩减搜索空间,提高查询效率。
发明内容
针对现有技术的不足,本发明提供了一种基于路网和排斥偏好的空间关键字组查询方法和系统,其目的在于,通过提出新的索引IBG-tree索引,可以高效率的筛选符合查询正向偏好和排斥偏好的候选兴趣点同时记录下其距离信息。
为实现上述目的,按照本发明的一个方面,提供了一种基于路网和排斥偏好的空间关键字组查询方法和系统,包括以下步骤。
(1)获取路网环境数据和用户的查询信息和兴趣点信息,其中路网环境抽象为一个带权无向图G=(V, E, W),其中V代表路网中的顶点集,每个顶点v∈V,表示一个道路交叉口或者某条路的终点;E代表路网中边的集合,e
(2)建立IBG-tree索引,并通过该索引筛选出候选集,将候选集中的兴趣点存储在哈希表T中;其中,IBG-tree索引基于G-tree索引引入布隆过滤器技术和倒排文件技术,索引树的每个结点都包含有距离矩阵、倒排文件IF、布隆过滤器文件BF和关键字交集UK以及边界点信息,其中,叶结点的距离矩阵中存储该结点内边界点与其他结点间的最短距离,非叶结点的距离矩阵中存储该结点内边界点之间的最短距离,IF用于存储该结点及其子结点中的关键字与结点之间的对应情况;BF和UK,共同用于筛查排斥关键字。
(3)根据哈希表T的候选集内容和查询q的关键字信息,筛选出结果集;其中哈希表T的索引键值为查询q.K+内的正向关键字,每个关键字对应的存储空间里存储包含有该关键字的兴趣点,若兴趣点的数量大于1个,则依据该兴趣点距离其所在结点内边界点的最小路网距离进行升序排序。
优选的,步骤(2)中的筛选过程具体为:初始化一个队列Q为空,根结点入队,当队列Q非空时,出队一个结点,通过该结点的布隆过滤器BF和UK判断该结点的关键字是否包含排斥关键字,若q.K-里的排斥关键字出现在该结点中,则该结点及其子结点可以剪枝排除,若该结点中没有排斥关键字,则通过IF匹配正向关键字,若该结点中匹配到q.K+内的正向关键字,当该结点是不是兴趣点对象时将该结点入队Q,当该结点是兴趣点对象时,则根据其匹配到的正向关键字和其距离信息加入哈希表T中。
优选的,步骤(3)中的筛选过程具体为:初始化min为0,结果集Res为空,根据不同的查询正向关键字,进行兴趣点的笛卡尔积操作得到多个可行解集存入集合Slist,当Slist非空时,取出一个可行解集存入S,计算S中距离查询点q.loc位置的最大距离Dist(q,S)和S中内部距离最远的两个兴趣点的距离为可行解集的组内距离S.indist,从而得到可行解集的空间距离代价S.cost;若当前可行解的空间距离代价S.cost小于目前最小的代价min,则将S存入Res中,将min赋值为S.cost,直至Slist为空,Res为返回的结果集,即最优的查询结果。
优选的,步骤(3)中计算可行解集的距离代价采用以下公式:
附图说明
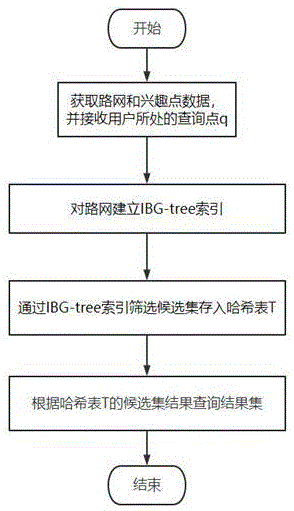
图1是本发明基于路网和排斥偏好的空间关键字组查询方法和系统的流程图。
图2是本发明路网环境和兴趣点信息示意图。
图3是本发明路网环境图分区示意图示意图。
图4是本发明IBG-tree索引示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
如图1所示,本发明提供一种基于路网和排斥偏好的空间关键字组查询方法和系统,主要包括三个步骤,首先获得路网和兴趣点数据以及查询信息,其次根据路网和兴趣点信息分布建立IBG-tree索引,通过该索引筛选出符合查询关键字要求的候选集对象放入哈希表T中,最后根据T内的内容查询出结果集。
如图2所示,具体而言,图2中是示例数据抽象出的路网模型,其中圆形表示一个顶点v,对应现实场景中的路口,两个顶点之间的线段是边e,对应现实场景中的路段,边上的数字是这条边的权值w,代表距离代价,可以对应现实场景中的距离;菱形表示一个兴趣点p,对应现实场景中的商铺等地点;兴趣点的距离信息表示为与其所在边较小顶点的距离,例如图2中p
如图3所示,对路网环境进行图分区,每个分区中黑色圆形是该分区的边界点,边界点即该分区中可以直接通往其他分区的顶点。五角星形表示查询q,在本实施例中q.K+ ={ t
如图4所示,根据图3的分区情况构建IBG-tree索引,每个树结点都包含有倒排文件IF,布隆过滤器BF、关键字交集UK和该结点的距离矩阵和边界点信息。
初始化队列Q为空,根结点G0入队,队列非空时,出队一个结点,通过该结点的布隆过滤器BF和UK判断该结点的关键字是否包含排斥关键字t
根据哈希表T的内容进行笛卡尔积,生成一批可行解集存入Slist中,Slist集合内容为{ {p
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 基于路网索引的Top-K空间关键字查询方法
- 一种道路网络下多用户空间关键词查询方法