一种基于Map的数据分类方法
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及通信领域,尤其涉及一种基于Map的数据分类方法。
背景技术
朴素贝叶斯分类(Naive Bayes Classification):基于贝叶斯定理,通过计算在给定特征条件下的类别概率来进行分类。它假设特征之间相互独立,且每个特征对于分类的贡献是相互独立的。
决策树分类(Decision Tree Classification):构建一棵决策树,根据特征的取值逐步判断数据属于哪个类别。通过分裂特征和分支规则,将数据集划分为不同的类别。
K近邻分类(K-Nearest Neighbors Classification):根据数据样本在特征空间的距离来判断其类别。K近邻算法会计算一个新样本与训练集样本的距离,并选择距离最近的K个样本的类别进行投票,最终将新样本归为投票结果最多的类别。
支持向量机分类(Support Vector Machine Classification):通过将数据映射到高维特征空间,并在该空间中找到一个最优的超平面,将不同类别的数据分开。支持向量机寻求最大化两个类别之间的间隔,并将数据分到两个不同的分类区域。
逻辑回归(Logistic Regression):通过将线性回归模型的输出通过一个sigmoid函数进行映射,将输出值转化为某个类别的概率来进行分类。逻辑回归主要用于二分类问题,但也可以扩展到多类别分类问题。
集成学习方法(Ensemble Learning):将多个基分类器的结果进行组合,以获得比单个分类器更好的分类性能。常见的集成学习方法包括随机森林、梯度提升树等。
综上所述,不同的数据分类技术各有优缺点,在对于中小规模数据量,快速实现分类方法都需要一定难度的算法实现。
数据分类是一种将数据按照一定规则或特征进行划分和分类的过程。
数据分类的背景来源于对于大量数据的需求和认知,人们意识到通过将数据进行分类和组织更好地理解和利用数据。随着互联网技术的不断发展,大数据时代的到来,数据的规模和复杂度不断增加,数据分类成为了一项重要的任务。
在实际应用场景中,需要快速对一定规模特定数据,按照特定属性进行快速准确分类。在此需要快速响应,实现特定分类算法思路,并且易于集成当前已有程序中。
对于快速准确进行分类的方法,采用机器学习、深度学习等方法时,准确度无法达到运算系统的要求,并且部分实现无法达到效率上的要求,数据量的规模的变化,对于系统的运行效率影响较大。因此需要寻找一种实现简单,方便集成,并且具有较高运行效率的分类方法。
发明内容
鉴于上述问题,提出了本发明以便提供克服上述问题或者至少部分地解决上述问题的一种基于Map的数据分类方法。
根据本发明的一个方面,提供了一种基于Map的数据分类方法,所述分类方法包括:
步骤S1:获取目标数据,并对所述目标数据进行封装,并写在一个类中;
步骤S2:对需要分类的规则,定义为类中的属性;
步骤S3:重写类中的分类函数;
步骤S4:选定一个数据结构进行分类操作。
可选的,所述分类函数包括:
Booloperator<(const CustomClassData&right)const;和bool operator==(const CustomClassData&right)const。
可选的,所述步骤S4:选定一个数据结构进行分类操作之后还包括:
步骤S5:将所组织好的数据,作为key,插入到数据结构中。
可选的,所述步骤S5:将所组织好的数据,作为key,插入到数据结构中之后还包括:
步骤S6:所得到的数据结构,为分类好的数据。
可选的,所述步骤S2:对需要分类的规则具体包括:采用红黑树进行分类时,直接采用已有的实现红黑树算法的数据结构。
本发明提供的一种基于Map的数据分类方法,所述分类方法包括:步骤S1:获取目标数据,并对所述目标数据进行封装,并写在一个类中;步骤S2:对需要分类的规则,定义为类中的属性;步骤S3:重写类中的分类函数;步骤S4:选定一个数据结构进行分类操作。采用红黑树作为底层实现原理的数据结构进行数据分类,提高开发效率,并且做到对数据的封装,能够做到算法复杂度为O(logn)。算法实现简答,仅需要很少量的代码实现,易于软件集成,在程序运行中,对过程数据进行实时分类运算。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
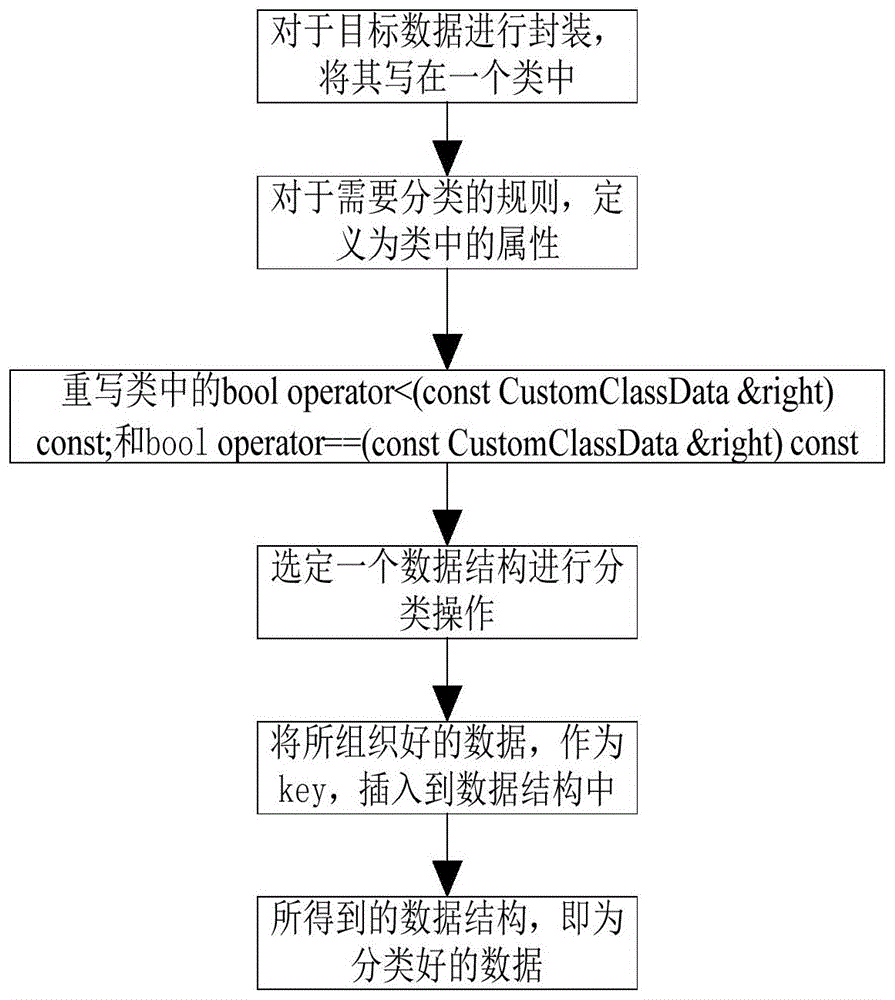
图1为本发明实施例提供的一种基于Map的数据分类方法的流程图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明的说明书实施例和权利要求书及附图中的术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元。
下面结合附图和实施例,对本发明的技术方案做进一步的详细描述。
如图1所示,一种基于Map的数据分类方法,所述分类方法包括:步骤1、对于目标数据进行封装,将其写在一个类中;
步骤2、对于需要分类的规则,定义为类中的属性;
步骤3、重写类中的bool operator<(const CustomClassData&right)const;和bool operator==(const CustomClassData&right)const;
步骤4、选定一个数据结构进行分类操作;
步骤5、将所组织好的数据,作为key,插入到数据结构中;
步骤6、所得到的数据结构,即为分类好的数据。
对于一系列数据进行快速分类时,主要应用到红黑树的特性,以及已经应用红黑树作为底层实现原理的数据结构。在具体实现中,只需要对需要分类的数据按照一定规则进行封装,在封装中,只需要实现特定的函数,最终的分类,交给数据结构自动实现。
通过采用红黑树作为底层实现原理的数据结构进行数据分类,大大提高开发效率,并且做到对数据的封装,能够做到算法复杂度为O(logn)。算法实现简答,仅需要很少量的代码实现,易于软件集成,在程序运行中,对过程数据进行实时分类运算。
解决了现有分类算法,需要算法实现,并且处理效率低下,在实现后,需要对算法进行稳定测试的一系列问题。
对于采用红黑树进行分类时,直接采用已有的实现红黑树算法的数据结构,例如STL中的std::map,Qt中的QMap等。
将需要分类的数据进行自定义类类型封装,作为map中的key。由于map底层采用红黑树算法实现,依据红黑树的特性,需要对key中自定义类型按照所需要排序的属性实现比较方法的重载,例如C++中实现bool operator<(const CustomClass&right)const;方法的实现。
并且能够灵活的将所有或者部分需要分类规则的属性进行分装在单独的类中,此时需要对于属性封装的类,需要自定义实现比较的相关方法,例如C++中实现booloperator<(const CustomClassData&right)const;和bool operator==(constCustomClassData&right)const;方法的实现。
有益效果:通过采用红黑树作为底层实现原理的数据结构进行数据分类,大大提高开发效率,并且做到对数据的封装,能够做到算法复杂度为O(logn)。算法实现简答,仅需要很少量的代码实现,易于软件集成,在程序运行中,对过程数据进行实时分类运算。
解决了现有分类算法,需要算法实现,并且处理效率低下,在实现后,需要对算法进行稳定测试的一系列问题。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。