一种基于语义相似度的中文自动文本摘要评价方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及自然语言处理技术领域,具体涉及一种基于语义相似度的中文自动文本摘要评价方法。
背景技术
当前社会的发展正在朝着人工智能、大数据的信息化方向发展,各式各样的文本信息层出不穷,如新浪微博、豆瓣短评、新闻日报等大量信息涌入到人们的日常生活之中,这也导致人们日常所获取的都是大量且冗余信息,许多精确且重要的内容都被过长的文本所遮掩,从而难以快速高效的获取有用信息。
随着人工智能技术的不断发展与进步,自动文本摘要技术逐渐在高效压缩提取信息方面发挥着重大作用。在传统的文本生成任务中,对于神经网络模型所生成的文本,人们往往很难评估他们的质量。如果单纯的是通过人工的评估的方式来评选机器所生成的文本摘要,其过程是非常昂贵且耗时的,并且还会存在因为每个人的评估标准不一致而导致的评分误差。当研究人员对模型进行更新和改进之后,其生成结果则还需要重新评估,故而非常影响实验效率。且由于文本摘要兴起于国外,生成的文本主要是语法结构相对规范的英文,故而采用BLEU、ROUGE等方法,以词的重合度作为评价标准来判断生成摘要的质量是具有可行性的。但对于中文来说,标准汉语语法中最大的特点就是没有严格意义的形态变化,例如,名词通常没有格的变化,动词也不分人称,这与欧洲的语言存在的较大的差别。汉语的另一特点是省略,即不影响主题意思的词往往会被省略。故而人们要表达出一个意思可以存在多种不同的表达方式,在以字的重合度作为评价标准时,则显得不太准确。
发明内容
本发明的目的在于针对现有的中文文本摘要评价方法多采用英文摘要的评价方法与实际中文使用者的语言习惯存在偏差的问题,提供一种可用来提高中文文本摘要评价的准确性的一种基于语义相似度的中文自动文本摘要评价方法。
为实现上述目的,本发明提供了一种基于语义相似度的中文自动文本摘要评价方法,包括以下步骤:
步骤一、从LCSTS中文摘要数据集PARTⅡ、PARTⅢ部分中抽取出摘要文本、新闻短文本和人工标注;
步骤二、对抽取出的摘要文本和新闻短文本进行预处理,使用预训练词向量对摘要文本和新闻短文本进行表征;
步骤三、将以预训练词向量进行表征的摘要文本和新闻短文本输入至DPCNN-Siamese混合网络模型中进行评分。
作为本发明的进一步方案:所述步骤二中对摘要文本和新闻短文本进行预处理的具体步骤如下:
步骤2.1、通过python的lxml库将LCSTS中文摘要数据集中的摘要文本、新闻短文本和人工标注的内容抽取出来,并按照对应顺序分别输出到不同文件中;
步骤2.2、使用LTP分词工具对从LCSTS中文摘要数据集中抽取出的摘要文本和新闻短文本进行分词处理,并使用中文维基百科语料预训练词向量作为中文数据的文本词向量;
步骤2.3、将摘要文本和新闻短文本中的中文转换成300维的预训练词向量,并将每一条摘要文本的篇长处理成32字符、每一条新闻短文本的篇长处理成128字符;
步骤2.4、将已经处理成篇长32字符的摘要文本和128字符的新闻短文本分别输入到神经网络中。
优选的,将摘要文本的篇长处理成32字符的具体方法如下:设置一个(n,32)维的空列表,并逐条录入摘要文本数据,当该条摘要文本的篇长小于32字符时,则在其后以补零的方式处理;当该条摘要文本的篇长大于32字符时,则截掉超出32字符的内容,只录入前32个字符的数据。
优选的,将新闻短文本的篇长处理成128字符的具体方法如下:设置一个(n,128)维的空列表,并逐条录入新闻短文本文本数据,当该条新闻短文本的篇长小于128字符时,则在其后以补零的方式进行处理;当该条新闻短文本的篇长大于128字符时,则截掉超出128字符的内容,只录入前128个字符的数据。
其中:n代表LCSTS中文摘要数据集的样本个数。
作为本发明的进一步方案:所述步骤三对摘要文本和新闻短文本进行评分的具体步骤如下:
步骤3.1、将摘要文本和新闻短文本分别输入至基于Siamese网络的结构中;
步骤3.2、根据输入至基于Siamese网络的结构中的摘要文本和新闻短文本的长度分别通过深度不同的DPCNN网络1和DPCNN网络2进行特征抽取;
步骤3.3、将摘要文本和新闻短文本的特征通过concat函数进行拼接池化后输入至全连接层中;
步骤3.4、将人工标注作为分类结果,使用softmax函数对输入至全连接层中的摘要文本和新闻短文本的特征与人工标注进行语义相似度进行匹配、打分;
步骤3.5、将生成摘要文本或新闻短文本相似度打分进行加权平均,得到该条摘要文本或新闻短文本的文本得分。
作为本发明的进一步方案:所述DPCNN-Siamese混合网络模型设置为Siamese网络模型与DPCNN网络模型相结合的混合网络模型,其中,Siamese网络模型用于进行语义相似度匹配,DPCNN网络模型用于对摘要文本或新闻短文本的特征进行提取。
作为本发明的进一步方案:为更好的将摘要文本或新闻短文本的特征与人工标注进行语义相似度匹配,以获得一个符合中文使用者阅读的摘要文本或新闻短文本评价模型,在进行摘要文本或新闻短文本的特征与人工标注进行语义相似度匹配、打分时对所述DPCNN-Siamese混合网络模型进行训练。
优选的,所述DPCNN-Siamese混合网络模型的训练具体实施方式如下:
步骤1、在实验中选取了CNN1D、CNN2D、BiLSTM模型来与DPCNN-Siamese混合网络模型进行对比试验,其中,以CNN1D模型作为baseline进行效果对比;
步骤2、在embedding层中文选取中文维基百科语料训练的词向量,英文选取斯坦福glove预训练的词向量,并将embedding设置为可训练,其中,BiLSTM网络的隐藏层设置为128,CNN网络与DPCNN网络的卷积核尺寸大小设置为3、4、5,卷积核的数量设置为256,并启用L1、L2正则化,优化算法使用Adam算法,学习率设置为0.001;
步骤3、模型训练结果以F1值三个评价指标作为结果进行评价。
优选的,所述F1值的计算公式为:
其中:P表示为正确率,R表示为召回率,TP表示为预测值与真实值同真,FP表示为预测值为真且真实值为假,FN表示为预测值为假且真实值为真。
作为本发明的进一步方案:所述DPCNN-Siamese混合网络模型的搭建具体步骤如下:
步骤①、结合文本摘要数据结构的特点,对Siamese网络的结构进行了改进;
步骤②、使用Siamese网络结构将经过词向量表示的摘要文本与新闻短文本{C
步骤③、对两个文本向量采用concatenate函数进行拼接处理,随后经过pooling层进行池化;
步骤④、在文本特征向量池化后,通过全连接层以及softmax函数之后进行分类处理。
优选的,对所述Siamese网络的结构进行改进的具体方法如下:将Siamese网络中的两个相同结构且共享权值的子网络改进为两个深度不同的DPCNN网络,用以对中文摘要数据集中长度不同的摘要文本与新闻短文本进行特征提取,使用concat操作将两个DPCNN网络的输出拼接成一个文本向量,在经过池化层与全连接层之后,最后使用softmax进行分类处理。
优选的,所述文本特征提取层包含两个深度不同的DPCNN网络模块。
与现有技术相比,本发明具有以下有益效果:
(1)本发明提出一种基于Siamese网络结构的混合改进模型,使用LCSTS数据集中带有人工评价的部分,将新闻标题和新闻内容作为输入,分别DPCNN网络结构提取文本的特征,并将两个网络层的输出进行拼合,以人工评价的等级作为标签数据进行训练,通过模拟中文使用者的语言习惯来评价模型所生成的中文文本摘要的好坏。
(2)本发明提出一种模拟中文使用者阅读习惯的自动文本摘要评价模型,使用Siamese网络作为基础架构,其中针对摘要文本和原文本长度不同,采用不同深度的DPCNN网络提取文本特征,来从语义角度对生成的摘要文本进行评价。
除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明的整体架构示意图;
图2是本发明中文本处理的架构示意图;
图3是本发明中LCSTS中文短文本摘要原始数据集示意图;
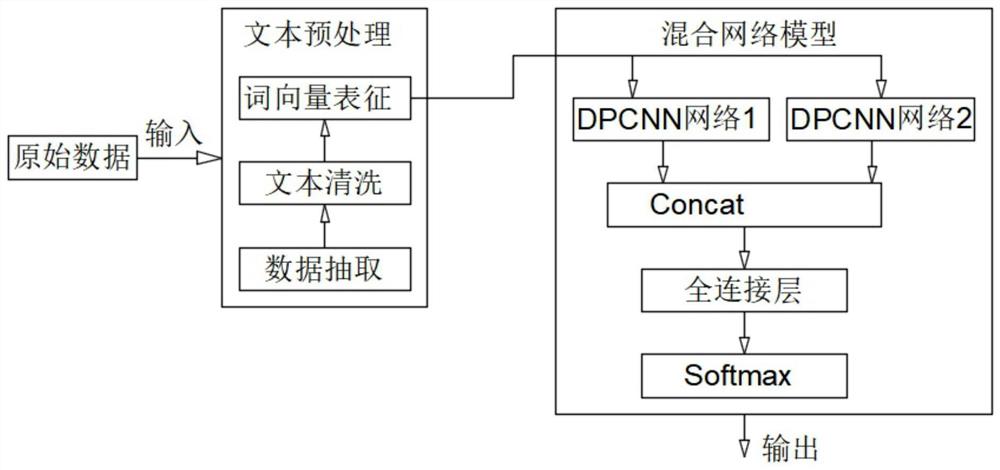
图4是本发明中DPCNN-Siamese混合网络模型架构的示意图;
图5是本发明中TextCNN网络模型架构示意图;
图6是本发明中DPCNN网络模型架构示意图;
图7是本发明中Siamese网络模型架构示意图。
具体实施方式
为使本发明的上述目的、特征和优点等能够更加明确易懂,下面结合附图对本发明的具体实施方式做详细的说明。需说明的是,本发明附图均采用简化的形式且均使用非精确比例,仅用以方便、清晰地辅助说明本发明实施;本发明中所提及的若干,并非限于附图实例中具体数量;本发明中所提及的‘前’‘中’‘后’‘左’‘右’‘上’‘下’‘顶部’‘底部’‘中部’等指示的方位或位置关系,均基于本发明附图所示的方位或位置关系,而不指示或暗示所指的装置或零部件必须具有特定的方位,亦不能理解为对本发明的限制。
本实施例:
参见图1至图3所示,本发明提供的一种基于语义相似度的中文自动文本摘要评价方法,具体步骤如下:
步骤一、从LCSTS中文摘要数据集PARTⅡ、PARTⅢ部分中抽取出摘要文本、新闻短文本和人工标注;
步骤二、对摘要文本和新闻短文本进行预处理,使用预训练词向量对摘要文本和新闻短文本进行表征;
步骤三、将摘要文本和新闻短文本输入至DPCNN-Siamese混合网络模型中进行评分。
优选的,所述步骤二中对摘要文本和新闻短文本进行预处理的具体步骤如下:
步骤2.1、通过python的lxml库将LCSTS中文摘要数据集中的摘要文本、新闻短文本和人工标注的内容抽取出来,并按照对应顺序分别输出到不同文件中;
步骤2.2、使用哈工大LTP(语言技术平台)分词工具对文本进行分词处理,并使用中文维基百科语料预训练词向量(中文词向量)作为文本词向量;
步骤2.3、将摘要文本和新闻短文本中的中文转换成300维的预训练词向量,并将每一条摘要文本的篇长处理成32字符、每一条新闻短文本的篇长处理成128字符;
步骤2.4、将已经处理成篇长32字符的摘要文本和128字符的新闻短文本分别输入到神经网络中。
优选的,将摘要文本的篇长处理成32字符的具体方法如下:设置一个(n,32)维的空列表,并逐条录入摘要文本数据,当该条摘要文本的篇长小于32字符时,则在其后以补零的方式处理;当该条摘要文本的篇长大于32字符时,则截掉超出32字符的内容,只录入前32个字符的数据。
优选的,将新闻短文本的篇长处理成128字符的具体方法如下:设置一个(n,128)维的空列表,并逐条录入新闻短文本文本数据,当该条新闻短文本的篇长小于128字符时,则在其后以补零的方式进行处理;当该条新闻短文本的篇长大于128字符时,则截掉超出128字符的内容,只录入前128个字符的数据。
优选的,n代表LCSTS中文摘要数据集的样本个数。
优选的,所述步骤三对摘要文本和新闻短文本进行评分的具体步骤如下:
步骤3.1、将摘要文本和新闻短文本分别输入至基于Siamese网络的结构中;
步骤3.2、根据输入至基于Siamese网络的结构中的摘要文本和新闻短文本的长度分别通过深度不同的DPCNN网络1和DPCNN网络2进行特征抽取;
步骤3.3、将摘要文本和新闻短文本的特征通过concat函数进行拼接池化后输入至全连接层中;
步骤3.4、将人工标注作为分类结果,使用softmax函数对输入至全连接层中的摘要文本和新闻短文本的相似度进行打分;
步骤3.5、将生成摘要文本或新闻短文本相似度打分进行加权平均,得到该条摘要文本或新闻短文本的文本得分。
优选的,所述DPCNN-Siamese混合网络模型设置为Siamese网络模型与DPCNN网络模型相结合的混合网络模型,其中:Siamese网络模型用于进行语义相似度匹配;DPCNN网络模型用于对摘要文本或新闻短文本的特征进行提取。
参见图4所示,所述DPCNN-Siamese混合网络模型的搭建具体步骤如下:
步骤①、结合文本摘要数据结构的特点,对Siamese网络的结构进行了改进;
步骤②、使用Siamese网络结构将经过词向量表示的摘要文本与新闻短文本{C
步骤③、对两个文本向量采用concatenate函数进行拼接处理,随后经过pooling层进行池化;
步骤④、在文本特征向量池化后,通过全连接层以及softmax函数之后进行分类处理。
采用CNN网络(卷积神经网络)捕捉文本中的局部特征的具体实施方式如下:
DPCNN网络(Deep PyramidConvolutional NeuralNetworks,深度卷积神经网络)是基于TextCNN网络(Text ConvolutionalNeural Networks网络,文本卷积神经网络)在自然语言处理领域中的应用而提出来的,CNN网络(卷积神经网络)的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干个单词或字符组成的滑动窗口,类似于N-gram,特征向量c
c
其中:c
由CNN网络的滑动窗口采集完所有的文字向量所得到的特征即为
c=[c
其中:c为CNN卷积神经网络卷积完成后的的文本特征向量,c
参见图4所示,在TextCNN网络中,文本中每个词都是由n维词向量组成,输入矩阵的大小为m*n,其中m为句子长度;CNN网络需要对输入样本进行卷积操作,对于文本数据,卷积核不在横向滑动,只向下滑动,类似于n-gram提取词语词之间的局部相关性,如图中含有三种步长策略(分别为2、3、4),每个步长都有两个卷积核,在不同词窗上应用不同的卷积核,最终得到6个卷积后的向量;然后对每一个向量进行最大池化操作并进行全连接,最终得到句子的特征表示,将这个句子向量输入到分类器进行分类。
参见图5所示,DPCNN网络的底层保持了于TextCNN网络类似的结构,并将包含多尺寸卷积滤波器的卷积层的卷积结果成为Region embedding(区域嵌入)过程,其作用就是对一个文本区域或片段(比如3gram)进行一组卷积操作后生成的embedding特征;DPCNN网络在Region embedding之后进行两次等长卷积,以便让每个单词更丰富的表示出来;之后重复进行等长卷积和1/2池化来提取特征,同时进行残差连接来解决梯度弥散问题,由于1/2池化层的存在,文本序列的长度会随着block数量的增加呈指数级减少,如式2所示:
num_blocks=log
其中:num_blocks为DPCNN网络中的block数量,seq_len为文本的序列长度。
DPCNN在深层次网络中为了解决梯度弥散问题,运用了shortcut connect方法,将前后等长卷积网络连接起来,如式3所示:
G(W)=z+f(z)....................................................(4)
其中:z为前一层的神经网络的输出,f(z)为当前层的神经网络输出,G(W)为下一层的神经网络输出。
卷积神经网络之所以能在文本处理任务上发挥作用,其优势主要在于能够自动地对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。
参见图6所示,Siamese网络(神经网络)设置有两个结构相同且共享权值的子网络,两个所述的子网络分别用于接收两个输入X
其中:E(X
当y=0时,LOSS函数随着E单调递增;当y=1时,LOSS函数随着E单调递减,具体公式如下所示:
L
其中:y表示为两个语句是否相似的指征,相似为1,不相似为0;L表示为
优选的,为更好的将摘要文本或新闻短文本的特征与人工标注进行语义相似度匹配,以获得一个符合中文使用者阅读的摘要文本或新闻短文本评价模型,在进行摘要文本或新闻短文本的特征与人工标注进行语义相似度匹配、打分时对所述DPCNN-Siamese混合网络模型进行训练。
所述DPCNN-Siamese混合网络模型的训练具体实施方式如下:
步骤1、在实验中选取了CNN1D、CNN2D、BiLSTM模型来与DPCNN-Siamese混合网络模型进行对比试验,其中,以CNN1D模型作为baseline进行效果对比;
步骤2、在embedding层中文选取中文维基百科语料训练的词向量,英文选取斯坦福glove预训练的词向量,并将embedding设置为可训练,其中,BiLSTM网络的隐藏层设置为128,CNN网络与DPCNN网络的卷积核尺寸大小设置为3、4、5,卷积核的数量设置为256,并启用L1、L2正则化,优化算法使用Adam算法,学习率设置为0.001;
步骤4、模型训练结果以F1值三个评价指标作为结果进行评价。
优选的,所述F1值的计算公式为:
其中:P表示为正确率,R表示为召回率,TP表示为预测值与真实值同真,FP表示为预测值为真且真实值为假,FN表示为预测值为假且真实值为真。
其具体对应关系可见表1。
表1
经对比发现,DPCNN-Siamese混合网络模型在中文数据集上的表现要优于其他网络,效率更高,其在短文本语义特征相似度的比对上更具优势。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于语义相似度的中文自动文本摘要评价方法
- 一种基于语义相关度模型的中文文本摘要获取方法