一种解决面向多个画像标签作业调度任务的方法
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及系统开发技术领域,尤其涉及一种解决面向多个画像标签作业调度任务的方法。
背景技术
由于用户画像系统的需求,需要开发成百上千个标签脚本,为了降低每个标签数据之间的耦合性,每个标签需要单独提交spark任务,并且每天需要定时作业刷新前一天产生的新标签。但是产生了许多问题:
1、标签的生成需要专门的人员写计算脚本,随着标签的增多,调度任务规模的增加,人为成本越来越大;
2、任务之间的依赖关系杂乱;
3、不便于查看当前执行到哪一个任务;
4、出现问题不能快速定位;
5、不便于记录历史调度任务的执行情况。
发明内容
为了克服现有技术的不足,本发明提供一种解决面向多个画像标签作业调度任务的方法,以解决上述的技术问题。
本发明解决其技术问题所采用的技术方案是:
一种解决面向多个画像标签作业调度任务的方法,包括下列步骤:
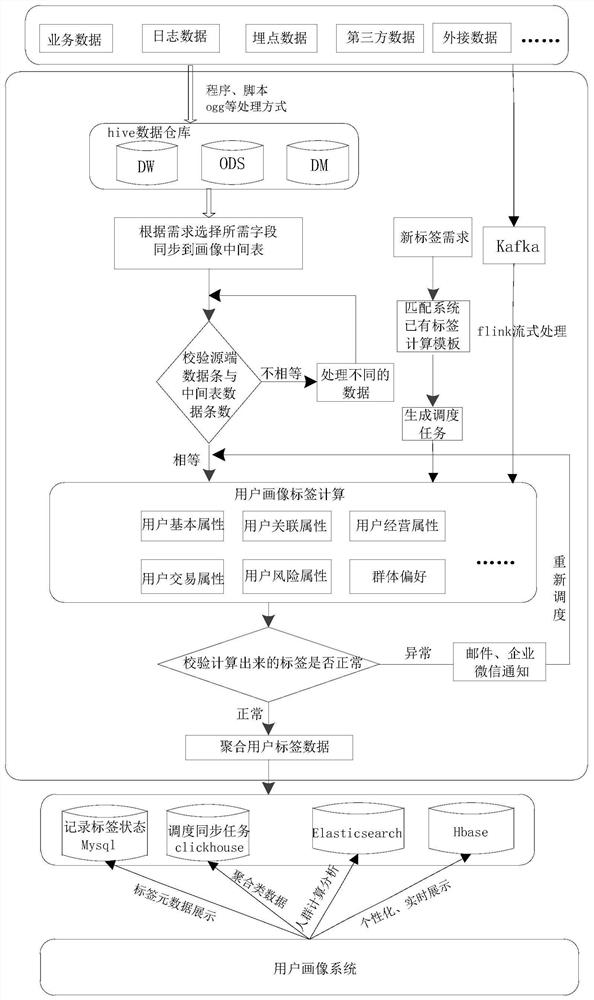
步骤一:采集用户画像所需的数据,包括业务数据、日志数据、埋点数据以及第三方数据存储到hive数据仓库中,并作为离线数据调度的源端;
步骤二:同步字段到hive数据仓库中;
步骤三:校验源端数据条数与同步到画像中间表中的数据条数,如果一致,则开启离线标签数据的调度作业,计算用户画像的离线标签数据,如果不一致,则删除同步的那一天的数据并进行重新调度;
步骤四:校验计算的离线标签数据是否正常,如果异常,则发送邮件以及企业微信通知相关人员,如果正常,则启动聚合用户标签数据的调度任务,聚合完成后同步标签数据以及聚合后的标签数据存入到多个不同类型的数据库。
作为上述技术方案的改进,该方法还包括Kafka进行实时标签数据处理,计算需要实时处理的用户画像标签数据,保存到画像数据库。
作为上述技术方案的改进,步骤一当中,业务数据、日志数据、埋点数据以及第三方数据通过程序、脚本以及ogg的方式存入到hive数据仓库对应的DW库、ODS库、DM库。
作为上述技术方案的改进,业务数据、日志数据、埋点数据以及第三方数据存入DW库、ODS库以及DM库后,hive数据仓库发起表字段需求。
作为上述技术方案的改进,根据需求选择hive数据仓库中所需表字段同步到hive数据仓库的画像中间表中。
作为上述技术方案的改进,步骤三中,离线数据会根据标签之间的依赖关系通过dolphin scheduler平台进行调度。
作为上述技术方案的改进,步骤四中,同步的数据包括标签状态的数据、同步生成的标签数据以及同步聚合后的数据;
标签状态的数据记录到mysql数据库,如果同步那一天的数据异常,则取前一天正常的数据进行展示;
同步生成的标签数据记录到clickhouse数据库;
同步聚合后的数据记录到elasticsearch和hbase数据库。
作为上述技术方案的改进,同步的标签数据通过dolphin scheduler平台进行调度。
作为上述技术方案的改进,该方法还包括如果有新标签需求,直接根据需求内容匹配已有的标签模板,生成调度任务,直接计算用户画像的标签。
本发明的有益效果是:
(1)可以做到通用类型标签根据业务人员需求自动生成;
(2)各个标签任务之间的关系清晰易查看,方便任务有条不紊的执行;
(3)可以可视化清楚的看到当前执行到的任务;
(4)方便根据日志快速定位出现的问题,以便及时处理问题;
(5)便于查看每个任务执行的时间,以便后面优化作业时间;
(6)当任务出现问题时重新调度,并发送邮件通知,保证数据的可靠性及稳定性。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1为本发明的结构示意图。
具体实施方式
以下将结合实施例和附图对本发明的构思、具体结构及产生的技术效果进行清楚、完整地描述,以充分地理解本发明的目的、特征和效果。显然,所描述的实施例只是本发明的一部分实施例,而不是全部实施例,基于本发明的实施例,本领域的技术人员在不付出创造性劳动的前提下所获得的其他实施例,均属于本发明保护的范围。另外,专利中涉及到的所有联接/连接关系,并非单指构件直接相接,而是指可根据具体实施情况,通过添加或减少联接辅件,来组成更优的联接结构。本发明创造中的各个技术特征,在不互相矛盾冲突的前提下可以交互组合。
参考图1,本发明揭示了一种解决面向多个画像标签作业调度任务的方法,包括下列步骤:
步骤一:采集用户画像所需的数据,包括业务数据、日志数据、埋点数据以及第三方数据存储到hive数据仓库中,并作为离线数据调度的源端;
步骤二:同步字段到hive数据仓库中;
步骤三:校验源端数据条数与同步到画像中间表中的数据条数,如果一致,则开启离线标签数据的调度作业,计算用户画像的离线标签数据,如果不一致,则删除同步的那一天的数据并进行重新调度;
步骤四:校验计算的离线标签数据是否正常,如果异常,则发送邮件以及企业微信通知相关人员,如果正常,则启动聚合用户标签数据的调度任务,聚合完成后同步标签数据以及聚合后的标签数据存入到多个不同类型的数据库。
在上述实施例中,业务数据、日志数据、埋点数据以及第三方数据存储到hive数据仓库中的DW库、ODS库以及DM库后,hive数据仓库发起表字段需求。根据需求选择hive数据仓库中所需表字段同步到hive数据仓库的画像中间表中。然后发起校验,如果源端数据条数与同步到画像中间表中的数据条数一致,则开启离线标签数据的调度作业,计算用户画像的离线标签数据,如果不一致,则删除同步的那一天的数据并进行重新调度,即根据标签类型的不同,重新发起校验,开启离线标签数据的调度任务后生成用户画像标签的数据,校验计算的离线标签数据是否正常,如果异常,则发送邮件以及企业微信通知相关人员,然后重新发起调度,即重新发起校验计算;如果正常,则启动聚合用户标签数据的调度任务,聚合完成后同步标签数据以及聚合后的标签数据存入到多个不同类型的数据库,在上述过程中,可以做到通用类型标签根据业务人员需求自动生成,而且各个标签任务之间的关系清晰易查看,方便任务有条不紊的执行,当任务出现问题时重新调度,并发送邮件通知,保证数据的可靠性及稳定性。
该方法还包括Kafka进行实时标签数据处理,计算需要实时处理的用户画像标签数据,保存到画像数据库。
进一步的,业务数据、日志数据、埋点数据以及第三方数据通过程序、脚本以及ogg的方式存入到hive数据仓库对应的DW库、ODS库、DM库。业务数据、日志数据、埋点数据以及第三方数据存入DW库、ODS库以及DM库后,hive数据仓库发起表字段需求。根据需求选择hive数据仓库中所需表字段同步到hive数据仓库的画像中间表中。
在上述实施例中,所述的实时数据和离线数据相同,均包括业务数据、日志数据、埋点数据、第三方数据以及外接数据。其中,埋点是数据采集领域的术语,尤其是用户行为数据采集领域,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。离线数据是经过程序、脚本以及ogg渠道进行处理,实时数据经过Kafka通道进行处理。
再进一步的,该方法还包括如果有新标签需求,直接根据需求内容匹配已有的标签模板,生成调度任务,直接计算用户画像的标签数据。
在本方案的步骤三中,离线数据会根据标签之间的依赖关系通过dolphinscheduler平台进行调度。dolphin scheduler平台为调度系统,可以可视化清楚的看到当前执行到的任务,方便根据日志快速定位出现的问题,以便及时处理问题,便于查看每个任务执行的时间,以便后续优化作业时间。
在本方案的步骤四中,同步的数据包括标签状态的数据、同步生成的标签数据以及同步聚合后的数据,其中,同步的标签数据通过dolphin scheduler平台进行调度,标签状态的数据记录到mysql数据库,如果同步那一天的数据异常,则取前一天正常的数据进行展示,同步生成的标签数据记录到clickhouse数据库,同步聚合后的数据记录到elasticsearch和hbase数据库。mysql数据库可以展示标签元数据,clickhouse数据库对于大批量数据的聚合性能非常快,所以标签聚合数据会从clickhouse数据库中取,elasticsearch数据库负责人群计算分析,hbase数据库可以个性化、实时展示用户画像系统采集的数据。
本发明的有益效果是:
(1)可以做到通用类型标签根据业务人员需求自动生成;
(2)各个标签任务之间的关系清晰易查看,方便任务有条不紊的执行;
(3)可以可视化清楚的看到当前执行到的任务;
(4)方便根据日志快速定位出现的问题,以便及时处理问题;
(5)便于查看每个任务执行的时间,以便后面优化作业时间;
(6)当任务出现问题时重新调度,并发送邮件通知,保证数据的可靠性及稳定性。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 一种解决面向多个画像标签作业调度任务的方法
- 面向生物基因测序计算任务的多队列回填作业调度方法