一种垃圾短信过滤方法、系统及算机可读存储介质
文献发布时间:2023-06-19 13:48:08
技术领域
本发明涉及通信技术领域,尤其涉及一种垃圾短信过滤方法、系统及算机可读存储介质。
背景技术
日常企业短信发送时,往往不经意间伴随着各种垃圾短信,对受众群体造成各种困扰,严重影响到人们的正常生活,为此各个通信运营商经常接到大量的垃圾短信投诉问题。目前,垃圾短信的处理方式几乎都是以关键字过滤的方式,进行拦截,通过设置大量关键字黑名单等一刀切方式,经常造成正常短信被拦截,对相关业务造成损失。
发明内容
本发明要解决的技术问题在于,针对现有技术的上述通过设置大量关键字黑名单等一刀切方式,经常造成正常短信被拦截,对相关业务造成损失的缺陷,提供一种垃圾短信过滤方法、系统及算机可读存储介质。
本发明解决其技术问题所采用的技术方案是:构造一种垃圾短信过滤方法,包括:
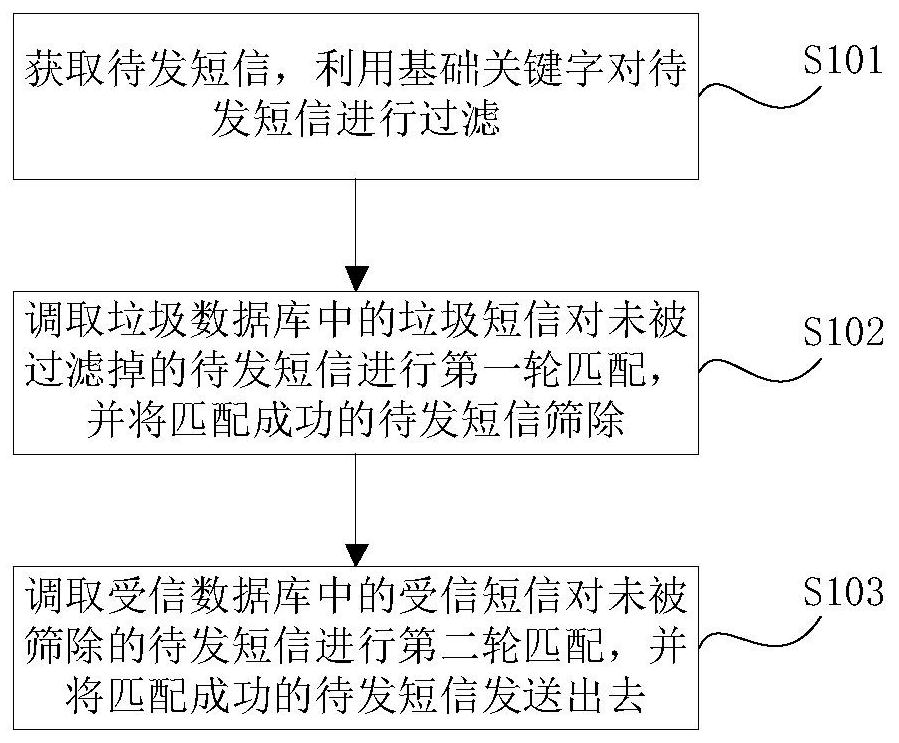
获取待发短信,利用基础关键字对待发短信进行过滤;
调取垃圾数据库中的垃圾短信对未被过滤掉的待发短信进行第一轮匹配,并将匹配成功的待发短信筛除;
调取受信数据库中的受信短信对未被筛除的待发短信进行第二轮匹配,并将匹配成功的待发短信发送出去。
优选地,所述方法还包括:将第二轮匹配时未匹配成功的待发短信放入内容库中以进行人工审查;将内容库中通过人工审查的待发短信发送出去,同时将其放入受信数据库中作为受信短信;将内容库中未通过人工审查的待发短信放入垃圾数据库中作为垃圾短信。
优选地,所述方法还包括:在所述第一轮匹配/第二轮匹配中,针对每一个待发短信,对垃圾数据库/调取受信数据库中的垃圾短信/受信短信按照分组同时进行匹配,并在任一组发现匹配成功的垃圾短信/受信短信时结束对当前待发短信的匹配。
优选地,所述方法还包括:定时或者不定时的对每一组的垃圾短信/受信短信进行排序;
在所述第一轮匹配/第二轮匹配中,每一组都是按照本组的垃圾短信/受信短信的排序,逐个调取垃圾短信/受信短信与待发短信进行匹配。
优选地,所述的对每一组的垃圾短信/受信短信进行排序,包括:统计同一组的各个垃圾短信/受信短信匹配成功的次数,并按照匹配成功的次数从高到低的顺序,对同一组的各个垃圾短信/受信短信进行排序。
优选地,在所述第一轮匹配/第二轮匹配时,对每一组的排序进行实时修正,包括:对每一组的各个垃圾短信/受信短信的匹配成功的次数进行监控,如果某个垃圾短信/受信短信在预设时长内匹配成功的次数达到预设值,则判定所述某个垃圾短信/受信短信的匹配短信出现集中发送状态,将所述某个垃圾短信/受信短信调整到其所在组的首位,并在所述集中发送状态消失时将所述某个垃圾短信/受信短信按照匹配成功的次数恢复排序。
优选地,在所述第一轮匹配/第二轮匹配时,将待发短信的短信内容和调取的垃圾短信/受信短信的短信内容分别进行分词处理,再根据分词结果计算相似度,如果相似度达到预设要求则判定匹配成功。
本发明另一方面还构造了一种垃圾短信过滤系统,包括处理器和存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
本发明另一方面还构造了一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法的步骤。
本发明的垃圾短信过滤方法、系统及算机可读存储介质,具有以下有益效果:本发明在结合少量基础关键字过滤的前提下,基于生成的含有垃圾短信、受信短信的两个库,对垃圾短信和受信短信进行校验,确保垃圾短信被过滤,受信短信正常发送,减轻对受众群体的困扰,降低投诉量,避免工作浪费。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图:
图1是本发明垃圾短信过滤方法的流程图;
图2是垃圾短信过滤方法的原理图;
图3是组内排序的原理图。
具体实施方式
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的典型实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。
为了现有技术中解决通过设置大量关键字黑名单等一刀切方式,经常造成正常短信被拦截,对相关业务造成损失的缺陷,本发明总的思路是:利用少量的基础关键字对待发短信进行初步的过滤,然后调取垃圾数据库中的垃圾短信对未被过滤掉的待发短信进行第一轮匹配,并将匹配成功的待发短信筛除,最后调取受信数据库中的受信短信对未被筛除的待发短信进行第二轮匹配,并将匹配成功的待发短信发送出去。
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案进行详细的说明,应当理解本发明实施例以及实施例中的具体特征是对本申请技术方案的详细的说明,而不是对本申请技术方案的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互组合。
本发明的方法是在短信下发任务提交后,获取提交的短信内容验证完短信发送等基础流程后启动。参考图1和图2,本发明的垃圾短信过滤方法包括:
S101:获取待发短信,利用基础关键字对待发短信进行过滤。
参考图2,过滤掉的短信直接拒绝发送,不再进行后面的步骤。
利用基础关键字对待发短信进行过滤,主要是检测待发短信的短信内容中是否存在基础关键字。基础关键字是指的行业内明令禁止的关键字,比如“法轮功”等。区别于现有技术中的垃圾短信的处理方式中的关键字的是,本发明的基础关键字是非常少的。
S102:调取垃圾数据库中的垃圾短信对未被过滤掉的待发短信进行第一轮匹配,并将匹配成功的待发短信筛除。
由于经过步骤S101的过滤后,还是可能存在需要筛除的短信,所以步骤S102的目的就是对这些短信进行进一步地的筛除。参考图2,筛除的短信直接拒绝发送,不再进行后面的步骤。
为了提高匹配的效率,可以将垃圾数据库中的短信复制一份到缓存中,之后进行匹配时,都是从缓存中取短信数据。
具体的,匹配时,具体是将待发短信的短信内容和调取的垃圾短信的短信内容分别进行分词处理,再根据分词结果计算相似度,如果相似度达到预设要求则判定匹配成功。比如说,“我是中国人”这条短信分词为“我是”、“中国人”。至于相似度的计算,可以是匹配上的分词的占比。比如说,待发短信的短信内容有K1个分词,调取的垃圾短信有K2个分词,两者匹配上的分词的数量是K3,则匹配上的分词的占比是K3/K2,如果K3/K2达到或者超过设定的阈值,则认为相似度达到预设要求,匹配成功。另外,两个分词匹配上,一般是指的两个分词完全一样。需要说明的是,相似度的计算还可以是其他方式,具体并不做限制,只要能体现两个短信的分词相似度即可。
优选地,本发明采用分组同时匹配的方式进行匹配,为此,在匹配之前需要将复制到缓存中的垃圾数据库中的所有垃圾短信进行分组。例如,可以按照服务器CPU核数为基准进行分组,均分每个分组的内容长度,例如假设垃圾数据库中的垃圾短信个数是Len,比如160个,CPU核数为n核,比如16核,将其分为16个分组,每组为M个垃圾短信,则M=Len/n=10,可以理解的是,如果Len/n非整数,则M为Len/n取整后加一。
在分组的基础上,本发明进行第一轮匹配时,针对每一个待发短信,对垃圾数据库中的垃圾短信按照分组同时进行匹配,并在任一组发现匹配成功的垃圾短信时结束对当前待发短信的匹配。还是以上面的16个分组为例,为每一个分组分配一个处理线程,即总共有16个处理线程同时对同一个待发短信进行匹配,这16个处理线程共享匹配标识,一旦其中一个线程匹配成功,则其余的线程全部停止,否则,所有线程需要全部执行完毕。
进一步地,对于每一组来说,组内的垃圾短信也可以排序,将最有可能匹配到的垃圾短信放到最前面优先匹配,以进一步提高匹配效率,所以本发明的方法还优选包括:定时或者不定时的对每一组的垃圾短信进行排序。比如可以选择短信发送比较空闲的时间段进行重新排序。
参考图3,上述的排序具体包括:统计同一组的各个垃圾短信匹配成功的次数,并按照匹配成功的次数从高到低的顺序,对同一组的各个垃圾短信进行排序。比如假设某一组有垃圾短信A、B、C…、G、H,他们匹配成功的次数是按照图3左边的排序从高到低。
在上述排序的基础上,本发明进行第一轮匹配时,每一组都是按照本组的垃圾短信的排序,逐个调取垃圾短信与待发短信进行匹配。即每一个线程都是按照顺序逐个调取该线程所对应的分组内的垃圾短信与待发短信进行匹配。参考图3,在与待发短信匹配时,会先调取短信A与待发短信匹配,如果匹配成功,则结束匹配,否则继续调取短信B匹配,以此类推。
进一步优选地,在所述第一轮匹配时,对每一组的排序进行实时修正,具体包括:对每一组的各个垃圾短信的匹配成功的次数进行监控,如果某个垃圾短信在预设时长内匹配成功的次数达到预设值,则判定所述某个垃圾短信的匹配短信出现集中发送状态,将所述某个垃圾短信调整到其所在组的首位,并在所述集中发送状态消失时将所述某个垃圾短信按照匹配成功的次数恢复排序。
参考图3,假设当前监控到排在最后面的短信H在预设时长内匹配成功的次数达到预设值,则判定所述某个垃圾短信H的匹配短信出现集中发送状态,则将短信H调到首位,如图3中第一个箭头所示。这样,当需要集中发送某一条短信时,可以迅速的匹配成功。短信集中发送完毕后,则重新按照短信H的匹配成功的次数恢复排序,如图3中第二个箭头所示。可以理解的是,图3中的短信H不再是在短信G之后,是因为由于经过集中发送,短信H的匹配成功的次数增加,所以按照匹配成功的次数恢复排序时,并不一定是原来的排序了,可能排序会有提升。
如此,可以实现组内的动态排序,保证在短信大量提交时,相似内容的,可以优先匹配发送。
S103:调取受信数据库中的受信短信对未被筛除的待发短信进行第二轮匹配,并将匹配成功的待发短信发送出去。
由于经过步骤S102的过滤后,可能存在一些处于灰色地带的短信,所以步骤S103的目的就是对这些短信进行进一步地的筛除。参考图2,只有受信任的短信才可以发送。
需要说明的是,本实施例中,第二轮匹配与第一轮匹配的具体原理是相同的,比如分词比较、分组匹配、组内排序修正等,这些都可以参考第一轮匹配部分,此处不再赘述。
进一步优选地,参考图2,其中所述方法还包括:将第二轮匹配时未匹配成功的待发短信放入内容库中以进行人工审查;将内容库中通过人工审查的待发短信发送出去,同时将其放入受信数据库中作为受信短信;将内容库中未通过人工审查的待发短信放入垃圾数据库中作为垃圾短信。经过此种处理,可以进一步提高短信过滤的可靠性。
前面步骤S102提到整个方法优选从缓存取数据,所以一旦人工审查导致垃圾数据库、受信数据库的数据变动,则需要同步刷新缓存,即将短信放入垃圾数据库、受信数据库的同时也放入一份到缓存的垃圾数据库、受信数据库中。同时,由于数据库中短信的加入,分组、排序也要同步触发更新。
如此,本发明将无法比对的短信内容确保进入内容库,保证数据完整有效,避免内容库本身出现无效数据,增加校验压力。另外,需要说明的是,内容库的维护,可由人工或其他业务规则实现。
综上,本实施例在结合少量基础关键字过滤的前提下,基于生成的含有垃圾短信、受信短信的两个库,对垃圾短信和受信短信进行校验,确保垃圾短信被过滤,受信短信正常发送,减轻对受众群体的困扰,降低投诉量,避免工作浪费。本发明实施例的减少预设的关键字,降低正常短信被拦截的情况,自动生成、更新的垃圾短信和受信短信的库,自动清理、维护,提高垃圾短信过滤的准确率,提高短信发送成功率。
基于同一方面构思,本发明还公开一种垃圾短信过滤系统,包括处理器和存储器,所述存储器存储有计算机程序,所述计算机程序被处理器执行时实现如前述方法实施例的步骤,具体实现过程参考上述方法实施例部分,此处不再赘述。
基于同一方面构思,本发明还公开一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时实现如前述方法实施例的步骤,具体实现过程参考上述方法实施例部分,此处不再赘述。所述的存储介质可为磁碟、光盘、只读存储记忆体或随机存储记忆体等。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。