一种基于混合数据库的知识图谱及其构建方法
文献发布时间:2023-06-19 12:27:31
技术领域
本发明属于知识图谱构建技术领域,具体涉及一种基于混合数据库的知识图谱及其构建方法。
背景技术
知识图谱是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系。通过对错综复杂的文档数据进行有效的加工、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合大量知识,从而实现知识的快速响应和推理。
目前,知识图谱大多由关系数据库或图数据库进行构建存储。基于关系型数据库构建的知识图谱通常是以表的形式建立数据行存储知识,以多表之间的关联存储数据的关系,具有结构清晰,速度稳定的优点,但是其存在知识关系无法有效表达,难以扩展的缺点。图数据库是种新型的数据库,它是和关系型数据库不一样的非关系型数据库。图数据库里面含有节点和边,这两者都是基于图论的。图论中的基本元素节点就是对应着图数据库中的节点,连接元素节点的边就对应着图数据库中连接节点的关系。目前基于图数据库的构建知识图谱也十分普遍,能直观形象地存储知识三元组,擅长表达知识关联和知识推理,但其存在结构比较复杂,对表结构的数据支持度不高。
在一个复杂的知识图谱系统中,仅使用关系数据库对知识推理的支持度较低,需要使用复杂的表结构构建知识关联;而如果仅使用图数据库则难以实现普通数据表的管理(如增删查改),图数据库知识往往被抽象为结点和关系,易于推理,但批量增删查改消耗大量时间。因此,如何实现对于复杂知识图谱的构建就成为了亟待解决的问题。
发明内容
针对背景技术所存在的问题,本发明的目的在于提供一种基于混合数据库的知识图谱及其构建方法。该知识图谱同时采用关系数据库和图数据库进行数据的存储,将结构化数据进行构建使得其能在关系数据库和图数据之间转化,从而实现对复杂任务的处理。
为实现上述目的,本发明的技术方案如下:
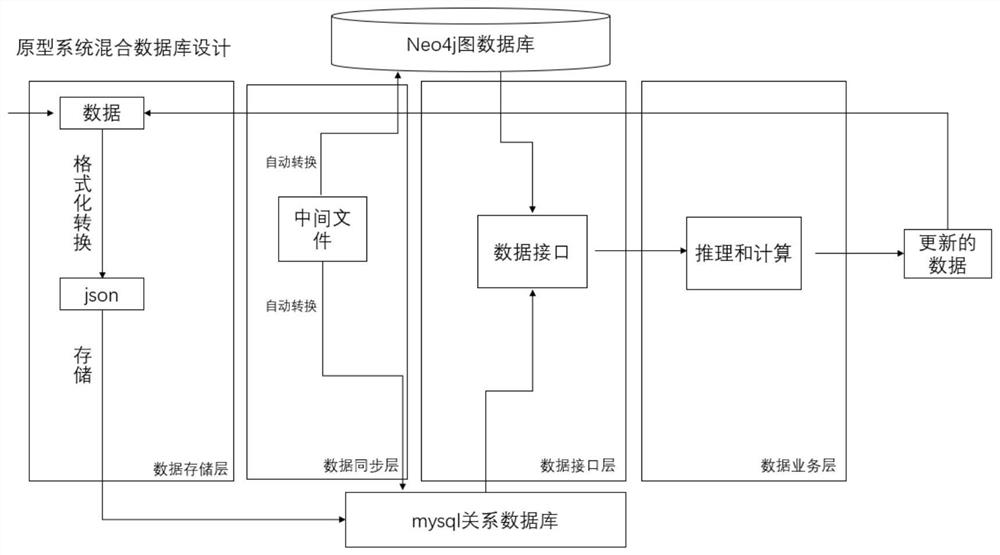
一种基于混合数据库的知识图谱,包括数据存储层、数据同步层、数据接口层和数据业务层;所述数据存储层用于得到自然语言数据的结构化信息,并存储到关系数据库;所述数据同步层将结构化信息进行二次抽取处理,并存储至图数据库中,同时二次抽取处理结果能够在关系数据库和图数据库中实现同步转换;所述数据接口层用于数据的差异化提取;所述数据业务层用于推理和知识图谱的更新。
一种基于混合数据库的知识图谱构建方法,包括以下步骤:
步骤1.先将自然语言数据格式化,通过抽取转换为json类型的格式,使用编号、标签、属性三种方式进行描述,得到结构化信息,然后存储到关系数据库中;
步骤2.基于资源描述框架(RDF)原则将步骤1得到的结构化信息进行二次抽取处理,得到抽取结果,然后存储到图数据库中,并得到编号、标签、属性构成的实体结点,以及实体结点与实体结点之间的连接关系;
所述图数据库和关系数据库均能对二次抽取结果进行实时读取,实现图数据库和关系数据库的自动同步;
步骤3.根据实际需求数据的取出样式,实现数据的差异化提取,具体为:对于结点型数据,使用json格式进行提取,对于关系型数据,使用图数据库关系格式进行提取;
步骤4.对步骤3所提取的数据依据图论算法进行推理,然后将推理结果重新进行步骤1和步骤2,实现知识图谱的构建和更新。
进一步地,步骤1中抽取的方式为实体抽取、关系抽取或属性抽取等;关系数据库为mysql关系数据库。
进一步地,步骤2中所述图数据库为Neo4j图数据库;对于实体结点,图数据库由数据本身构成数据实体结点,与数据结点形成实体-关系属性-属性值的连接;对于关系,可以直接形成实体-关系-实体的连接。
进一步地,步骤4中的结果包括属性、关系、结点编号等。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.本发明构建的知识图谱集合了关系数据库的特点,方便结构化数据的增删查改,同时数据转化为图数据的形式,可以构建知识关系,实现知识快速推理。
2.本发明知识图谱以关系数据库作为基础,在这一过程中采用json格式,该格式可以实现知识属性的拓展,同时可以送进图数据库中进行综合的推理与分析。
3.本发明通过图数据库对构建的知识图谱,将知识的关联形式化的存储起来,由于其数据关联以图的形式实现,知识间的关联传递查找效率均比表的索引要快,因而极大地提高了算法的处理效率。
附图说明
图1为本发明基于混合数据库构建知识图谱的流程图。
图2为本发明图数据库中存储数据的图形式。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
一种基于混合数据库的知识图谱构建方法,包括以下步骤:
步骤1.先将自然语言数据格式化,通过抽取转换为json类型的格式,使用编号、标签、属性三种方式进行描述,得到结构化信息,然后存储到关系数据库中;
步骤2.基于资源描述框架(RDF)原则将步骤1得到的结构化信息进行二次抽取处理,得到抽取结果,然后存储到图数据库中,并得到编号、标签、属性构成的实体结点,以及实体结点与实体结点之间的连接关系;
所述图数据库和关系数据库均能对二次抽取结果进行实时读取,实现图数据库和关系数据库的自动同步;
步骤3.根据实际需求数据的取出样式,实现数据的差异化提取,具体为:对于结点型数据,使用json格式进行提取,对于关系型数据,使用图数据库关系格式进行提取;
步骤4.对步骤3所提取的数据依据图论算法进行推理,然后将推理结果重新进行步骤1和步骤2,实现知识图谱的构建和更新。
实施例1
以机电设备知识图谱构建为例,其构建流程图如图1所示,包括以下步骤:
步骤1:构建数据存储层:先将机电系统信息的数据格式化,通过实体抽取、关系抽取和属性抽取转换为json类型的格式,即通过三种抽取方式,从数据库表中提取了实体、关系与属性等知识要素,并经过知识融合,削除实体指称项与实体对象之间的歧义,得到一系列基本的模型关系表达,使用编号、标签、属性三种方式进行描述,得到结构化信息,存储到关系数据库中;
步骤2:构建数据存储层同步层:基于资源描述框架(RDF)原则将步骤1得到的结构化信息进行二次抽取处理,得到抽取结果,然后存储到图数据库中;其中,设备的编号、标签、属性构成实体结点,实体结点与实体结点之间形成实体-关系属性-属性值的连接;对于关系,可以直接形成实体-关系-实体的连接;
关系数据库中存储的设备表,每一行都表示一个设备的属性,将行抽取出来可以进行层次化的展开,从而在图数据库产生层次化结点和关系;
RDF原则指数据抽象为实体-关系-实体,实体-属性-属性值,实体和属性值可认为是结点,即实体-关系-实体,
比如一条设备在关系数据库中的结构化描述是:
编号标签属性
1设备{“名称”:“设备1”,“系统”:“供电系统”,····}
基于RDF原则将关系数据库中结构化信息进行二次抽取的具体过程为:
结点描述
[{编号:11,属性:{“名称”:“设备1”}},
{编号:12,属性:{“名称”:“1”}},
{编号:13,属性:{“名称”:“设备”}},
{编号:14,属性:{“名称”:“供电系统”}}]
·
·
关系描述
[{编号:111,标签:编号,属性:{“起始结点”:11,“终止结点”:12}},
{编号:112,标签:标签,属性:{“起始结点”:11,“终止结点”:13}},
{编号:113,标签:系统,属性:{“起始结点”:11,“终止结点”:14}}]
·
·
结合关系和结点,在图数据库中即可生成如图2所示的图;
步骤3:构建数据接口层:定义取出数据的样式,即可依据编号、标签、属性定义取出数据的样式,属性内可自由定义取出的数据,编写代码构建功能函数,实现数据差异化提取;对于结点型数据和关系型数据,统一使用编号、标签、属性的json格式进行提取;
步骤4:构建数据业务层:对步骤3所提取的数据依据图论算法进行推理,然后将推理结果重新进行步骤1和步骤2,进行推理与储存同步,实现知识图谱的构建和更新。
在图数据库中经过各种任务推理,得出各种任务推理的结果,一般是以实体结点、模型信息、关联关系、负载数值等等组成,其中实体结点和模型信息和任务设备资源表互相转换,关联关系和任务关系表相互转换,负载数值等和任务信息表相互转换,由此进行推理与储存同步。
推理任务开始进行的时候,图数据库会自动和关系数据库进行任务信息同步,包括设备检入的资源信息,设备已有的关系连接等等,并且以这些为基础进行信息推理。结合关系数据库及图数据库,在已有的关系连接和实体中,依据多种图论算法给出相应的结果。结果包括:属性,关系,结点编号等等,这些会自动同步到任务数据库中,以及其他的信息数据库。
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。