一种虚拟域内基于多显卡的分片虚拟化负载均衡调度
文献发布时间:2023-06-19 19:28:50
技术领域
本发明属于虚拟化领域,涉及一种虚拟域内基于多显卡的分片虚拟化负载均衡调度
背景技术
GPU(图形处理器单元)主要用于2D、3D图形渲染以及高性能并行运算,其浮点运算和并行运算速度可以比CPU强上百倍之多,使用GPU虚拟化技术之后,可以让运行在数据中心服务器上的虚拟机实例共享一块或多块GPU处理器进行图形运算,大大增加了桌面访问方式的安全与高效性。
目前,几种经典的虚拟化技术如设备模拟、API转发、GPU直通等,虽然在一定程度上解决了人们对于GPU虚拟化的需求,但这些解决方案依旧不能平衡好性能、功能和共享能力,在实现完整的GPU虚拟化上仍然存在挑战。设备模拟实现过于复杂且性能低,API转发不能很好的实现全特性支持,GPU直通在性能与功能上均取得了非常好的效果,但是不支持共享。有鉴于此,Intel在《A Full GPU Virtualization Solution with MediatedPass-Through》一文中提出了一种基于中介透传的GPU分片虚拟化方案gVirt,其通过透传vGPU对性能相关资源的访问、拦截并模拟vGPU对特权相关资源的访问,有效的提高了vGPU的性能与共享性,且实现了GPU全特性支持。
然而,上述方法仍存在一些不可忽略的缺陷:第一,由于没有考虑单节点多GPU的情况,其只能对主机上的一块GPU进行分片,因此无法充分利用多个GPU的计算资源来让一台主机支持更多需求vGPU的虚拟机,进而提高了主机硬件的购买成本;第二,当前大部分GPU均为非抢占式工作制,因此被调度到的vGPU需要等上一个vGPU命令全部跑完才能开始向pGPU提交命令,而vGPU在一个时间片内所提交命令的完成时间有可能超出时间片,继而对下一个vGPU造成等待开销,为了迁就GPU的非抢占式工作制度,gVirt实现了一个粗粒度的调度策略,即大概判断vGPU提交的命令能否在一个时间片内运行完,若gVirt判断已提交命令的完成时间接近时间片,则该vGPU即使还有剩余时间片也不会再提交命令,进而限制了分片虚拟化框架对GPU命令的吞吐量;第三,由于没有考虑到虚拟机的负载也会产生变化,而vGPU的权重在创建之初就已被指定且不可更改,因此存在vGPU空转大部分时间片的可能,这增加了负载均衡的时间开销。
发明内容
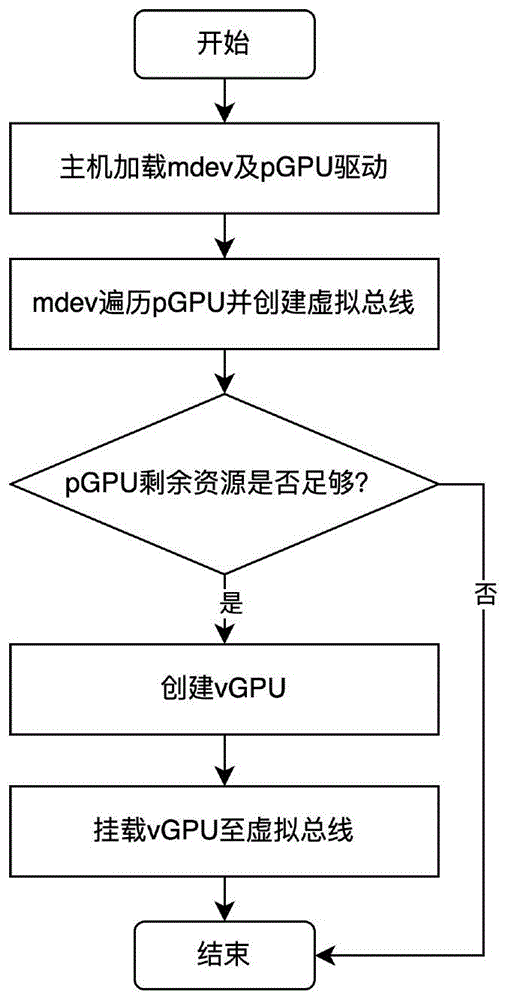
为提升分片虚拟化框架的可扩展性,本发明提供了一种虚拟域内基于多显卡的分片虚拟化负载均衡调度。本方法不仅支持对多显卡进行分片,有效降低主机硬件购买成本,提升对多GPU计算资源的利用,分片流程图如图1所示,而且通过新增命令链表避免vGPU将命令直接提交给pGPU,vGPU在一个时间片内可以不受限的将命令提交至命令链表,提升了分片虚拟化框架对GPU命令的吞吐量,本发明还具备负载感知特性,依据负载情况动态调整vGPU权重,优化了vGPU之间的负载均衡,vGPU权重重分配如图2所示。本发明所述方法包括以下主要步骤:
1.硬件检索阶段
首先,每台主机的PCI-e总线都会挂载多个设备,在对pGPU进行分片之前需要区分并收集pGPU信息,以此作为vGPU与pGPU对应的依据。收集的pGPU信息包括:BDF(设备标志符)、配置空间信息、固件信息。BDF用于对应vGPU与pGPU,配置空间信息用于从所有的PCIE设备中筛选出GPU以及记录GPU的IO空间,固件信息用于记录GPU支持的分辨率。
其次,作为被切分出来的虚拟设备,vGPU依旧属于PCI设备范畴,但其不能被直接挂载于物理PCI-e总线上,因此需要为每个pGPU创建一条虚拟总线,该虚拟总线用于挂载vGPU,不同pGPU对应的虚拟总线号(B)不同,同一虚拟总线中vGPU对应的设备号(D)不同,由此做到vGPU与pGPU的对应以及vGPU之间的区分。
做完上述准备工作后,分片虚拟化框架mdev为每个pGPU创建sysfs目录,用户通过更改不同sysfs目录的值即可在不同pGPU上创建不同规格的vGPU。
2.GPU分片阶段
GPU分片虚拟化可从两个维度上来定义:其一,是对GPU在时间片段上的划分,与CPU的进程调度类似,一个物理GPU的计算引擎在几个vGPU之间共享,而调度时间片一般都在1-10ms左右;其二,是对GPU资源的划分,主要是指对GPU显存的划分。以NVIDIA为例:一个物理GPU带有16GB的显存,那么按照16个vGPU来划分,每个vGPU得到1GB的显存。
与已有的分片虚拟化方案不同的是,gVirt是对单个pGPU进行分片,因此无需考虑pGPU与vGPU之间的对应关系。而本方法是对多个pGPU进行分片,因而需要在vGPU与pGPU之间建立关联,防止vGPU将命令提交至另一块pGPU上,本方案的分片具体过程包括以下几个部分:
(1)剩余资源检测。在接收到分片请求之后,mdev会先判断pGPU剩余的物理资源,比如显存,是否能够再创建一个指定规格的vGPU。若剩余资源不足以创建新的vGPU,则直接结束分片进程,否则进入下一步。
(2)配置空间初始化。设置各个BAR的大小与虚拟固件信息,GPU设备通过PCI-e总线接入到主机上。Base Address Registers(BARs)是MMIO的窗口,在GPU启动时候配置,GPU的控制寄存器和内存都映射到了BARs中。虚拟固件信息主要包括对分辨率的设置,根据分辨率生成不同的虚拟固件。
(3)虚拟寄存器vREG初始化。mdev需要做到拦截并模拟vGPU对特权相关资源的访问,虚拟寄存器是关键一环。在初始化虚拟寄存器过程中,将访问虚拟寄存器时的钩子函数与虚拟寄存器绑定,这样在虚拟机VM中原生的GPU驱动访问寄存器的时候,会产生VM exit并trap至mdev框架中对应虚拟寄存器的钩子函数,由钩子函数模拟vGPU对寄存器的访问。
(4)其余虚拟部件初始化。除却vREG以外,vGPU大量工作都是在其余虚拟部件中进行的,在初始化过程中定义了虚拟部件的钩子函数,具体来说包含以下几类虚拟部件:
1.虚拟3d引擎、2.虚拟2d引擎、3.虚拟中断控制器、4.虚拟dma控制器。定义的钩子函数有:命令提交函数、特殊状态判断函数、注销函数等。
(5)挂载vGPU。创建好vGPU之后,调用mdev_device_register()函数将vGPU挂载至虚拟总线,之后再通过配置VM的硬件参数即可使用vGPU。
3.vGPU命令处理
于VM内安装原生GPU驱动之后,VM中的上层应用便可通过核外、核内驱动使用vGPU的各种特性,如2D、3D、编解码等。提交GPU命令时,VM内的GPU驱动依旧认为自己访问到的是物理寄存器,而实际上该寄存器地址只是映射至VM的一段被标记为写保护的内存而已。因此GPU驱动在访问该寄存器时会触发VM exit,进而将命令提交进程trap至mdev。
创建vGPU之初便已指定好各个虚拟寄存器被访问时的钩子函数,当mdev进行寄存器地址匹配得知VM访问的是命令提交寄存器之后,钩子函数便会进行如下操作:
(1)取命令。调用vfio_dma_rw()函数并根据命令提交寄存器的值从VM的内存中将本次提交的命令取至mdev;
(2)命令类型解析。VM中上层应用发送的GPU指令不一定是图形渲染或者并行计算,也有可能是等待GPU硬件过渡至某一状态。处理计算类命令,mdev将命令直接发送给GPU硬件,处理状态等待类命令,mdev会读取特定状态所对应物理寄存器的值,不同类型命令的处理函数不同,因此需要解析命令类型,在第一步中取到GPU命令后,通过对命令头进行解析得出命令类型。
(3)缓存命令。为了配合GPU的非抢占式工作制,同时尽可能增加mdev对GPU命令的吐量,mdev解析完命令之后并不会直接提交给硬件,而是将其存储至链表中,链表元素包含的信息:命令长度、命令类型、命令内容。
(4)提交命令。vGPU获取调度权限后,mdev遍历命令链表并根据命令类型与数量计算命令执行时间,直至遍历完整个链表或已被遍历命令的执行时间接近时间片。例如命令链表cmdlist= 4.vGPU权重重分配 VM开机后,随着用户对GPU负载密集型软件使用情况的不同,GPU负载也会产生变化。比如,VM从闲置状态到打开GPU负载软件,这会导致负载的突然增加,当GPU负载软件完成工作后,会导致负载的减少。针对这类负载变化情况,有必要增加负载感知机制,使用该机制确保vGPU得到的时间片资源与其负载大致匹配,达到vGPU之间的负载均衡。以下为vGPU权重重分配的具体过程: (1)剩余时间片计算:若令vGPU T (2)权重重分配:考虑到vGPU负载密度的波动性,统计其十次的负载完成情况,在vGPU工作十轮之后,计算得出总剩余时间片T 附图说明 图1:GPU分片虚拟化流程示意图 图2:vGPU权重重分配示意图 具体实施方式 本发明的硬件环境要是PC主机。主机软、硬件配置如下: CPU:Intel i56400 主板:映泰B150S1 D4 内存:16GB DDR4 硬盘:Intel 535SSD 240G 显卡:国产GPU 操作系统:Ubuntu 20.04,内核版本为5.8.0.43 Vim,版本号为:8.1 gcc,版本号为:9.3.0 make,版本号为:4.2.1 版本管理工具为git,版本号为:2.24.1 本发明的软件实现以Ubuntu20.04为平台,使用C语言开发。 本发明的操作主要分为两部分,第一部分为多GPU分片,第二部分为基于负载感知的权重重分配。 1.多GPU分片 (1)算法描述 算法输入:pGPU 算法输出:vGPU 说明:pGPU即挂载于PCI-e总线上的物理GPU设备,mdev驱动被加载至内核时,会扫描所有GPU设备并记录其信息。 算法步骤: 1)为pGPU创建sysfs,后续用户可通过更改sysfs的值来通知mdev创建分片设备; 2)剩余资源检测,若资源不足,则结束分片进程; 3)创建vGPU,主要是虚拟寄存器及其余虚拟部件的初始化; 4)挂载vGPU。 其伪代码如下: /> 2.vGPU权重重分配 (1)算法描述 算法输入:vGPUs 算法输出:无输出 说明:vGPUs是由同一个pGPU分片出来的所有vGPU设备,拿到vGPU结构体以后,可根据结构体内的剩余时间片以及权重信息计算出新的权重。 算法步骤: 1)统计剩余时间片,通过这一步可判断被浪费的总时间片资源是多少; 2)将剩余时间片转换为权重; 3)将权重均分给负载密度大(无剩余时间片)的vGPU。 其伪代码如下: /> />