YOLO和分块-融合策略结合的稠密人脸检测方法
文献发布时间:2023-06-19 10:21:15
技术领域
本发明涉及机器视觉技术领域,具体涉及一种YOLO和分块-融合策略结合的稠密人脸检测方法。
背景技术
人脸检测作为机器视觉领域的经典问题,在安防监控、人机交互、移动支付、等领域都有重要的应用价值。当前,随着人们生活水平的提高,人脸检测在日常生活中的需求也越来越广泛,同时,科技水平的发展也使人脸检测的应用范围不断扩大。如密集人群监测,教室人数统计等复杂场景的人脸检测也开始受到人们关注。然而密集人群中的人脸不同于传统人脸识别应用场景中具有清晰特征的人脸,如图1所示,因为受到遮挡、角度、模糊、尺度过小等因素影响,密集场景下的稠密人脸检测难度较大,而尺度过小则是其中尤为明显的问题。
针对密集场景下的稠密人脸主要存在的尺度过小的问题,学者们从小尺度人脸检测角度出发。
文献[1]Zhang S,Zhu X,Zhen L,et al.S
文献[2]Hu P,Ramanan D.Finding Tiny Faces[C].Computer Vision&PatternRecognition,2017:arXiv:1612.04402.通过结合人脸上下文特征来分析人脸,提高了小尺度人脸的检测效果,但更多的上下文易受遮挡影响,这在密集场景中尤为明显;
文献[3]Sam D B,Peri S V,Sundararaman M N,et al.Locate,Size and Count:Accurately Resolving People in Dense Crowds via Detection[J].IEEETransactions on Pattern Analysis and Machine Intelligence,2020:1-1.从人群计数角度出发,提出一种新的卷积神经网络框架,该网络用多分辨率特征提取代替典型的多尺度输入,同时其输出的预测分辨率也高于其他人脸检测器,在密集人群检测中取得明显提升;
文献[4]Bai Y,Zhang Y,Ding M,et al.Finding Tiny Faces in the Wild withGenerative Adversarial Network[C].computer vision and pattern recognition,2018:21-30.提出利用超分辨率,对于模糊的小人脸利用生成对抗网络实现分辨率的提高,利用超分辨率网络将小人脸放大,实现了小人脸精度的提高;
文献[5]中国专利[申请号:202010418338.4]提出一种基于特征融合和视觉感受野网络的多尺度人脸检测方法,以VGG-16为基础网络,由视觉感受野网络、空洞卷积网络共同组成。在不同分辨率的特征层上采用不同的方法提取候选框,在小尺度人脸上取得了较好的效果。但该方案通过增加网络宽度和深度,明显增加了计算量。上述方法为了追求在小尺度人脸上的检测精度,针对特定的网络进行修改,复杂的网络模型导致运算量增加,消耗时间长,具有较大的限制,应用场景较少。
中国专利[申请号:201910326673.9]针对密集小人脸检测提出基于级联多尺度的密集人脸检测方法,针对特定尺度范围分别训练不同尺度下的检测器,将这些检测器级联起来,该方案具有良好的扩展性,可以搭载在任何人脸检测深度模型中,然而该方案通过增加检测器数量,模型运算消耗大量时间。
文献[6]Redmon J,Divvala S K,Girshick R,et al.You Only Look Once:Unified,Real-Time Object Detection[C].computer vision and patternrecognition,2016:779-788记载的YOLO(You only look once)是由Joseph Redmon提出的基于单个神经网络的目标检测系统。YOLO不同于R-CNN等Two-stage算法需要生成区域建议从而消耗算力导致速度较慢,而是利用单个卷积神经网络,将输入图片分成n*n个网格,对每个网格进行预测,直接对目标进行分类和回归,实现端到端的检测,因此检测速度大幅提升。
YOLO在GPU上达到45fps,同时其简化版本达到155fps。之后YOLO为了提高精度,又相继提出:
文献[7]Redmon J,Farhadi A.YOLO9000:Better,Faster,Stronger[C].IEEEConference on Computer Vision&Pattern Recognition,2017:7263-7271中记载YOLO9000;
文献[8]Redmon J,Farhadi A.YOLOv3:An Incremental Improvement.arXiv e-prints,2018:arXiv:1804.02767中记载YOLOv3;
文献[9]Bochkovskiy A,Wang C-Y,Liao H.YOLOv4:Optimal Speed andAccuracy of Object Detection[J].ArXiv,2020,abs/2004.10934中记载YOLOv4。
YOLO作为一种性能优异的通用目标检测算法,其在速度上的优势保证了在工程上应用的可行性,因此也有人尝试使用YOLO来解决相关问题。
文献[10]邓珍荣,白善今,马富欣,改进YOLO的密集小尺度人脸检测方法[J].计算机工程与设计,2020,v.41;No.399(03):282-287.通过改进YOLO网络模型结构来检测检测密集人脸,通过在不同层级的特征图上进行细粒度的特征融合,提高对小尺度人脸特征的表示能力,但该文献使用YOLO初始版本,受到自身网络限制,特征提取网络结构简单,导致在目标检测中对小目标的检测精度较低。
中国专利[申请号:201911235709.9]提出基于YOLO的人脸检测方法,使用MobileNetv2提取图像特征,整个方案具有较快的推断速度,每张图推断时间为0.09秒,但是该方案欠缺精度,在密集场景小人脸检测上存在不足。
密集场景的人脸检测因为其存在的遮挡、模糊、尺度过小等原因,使得密集场景的人脸检测存在诸多难点:1)稠密人脸因为其密集分布受到遮挡、角度等的影响导致特征不明显;2)小尺度人脸由于尺度过小,缺少足够的特征信息,难以从背景特征中区分;3)基于CNN的人脸检测算法通常使用下采样操作,使小尺度人脸损失空间信息,其特征也被背景特征淹没。同时当前的算法在密集场景人脸检测中又存在利用复杂的网络模型进行密集人脸检测,导致运算量大,或者使用轻量级网络,拥有较快的检测速度但无法应对密集场景下稠密人脸的检测问题。
发明内容
针对密集场景下人脸检测难的问题,本发明提供一种YOLO和分块-融合策略结合的稠密人脸检测方法,利用YOLOv3网络的速度优势以及较高的目标检测精度,通过分块-融合策略提高在密集人脸上的检测精度,实现密集场景下的稠密人脸检测。
本发明采取的技术方案为:
一种YOLO和分块-融合策略结合的稠密人脸检测方法,包括以下步骤:
步骤1:对人脸训练数据集进行数据增广,扩充密集场景下的人脸样本;
步骤2:构建YOLOv3和分块-融合策略相结合的YOLOv3网络模型,在检测阶段,将原图进行分块,并将分块得到的子图和原图一同输入到YOLOv3网络模型中分别进行检测;
步骤3:对NMS算法进行改进,解决大尺度人脸融合问题的同时提高小人脸检测的精度。
所述步骤1中,人脸训练数据集采用WIDERFACE数据集,对原始WIDERFACE数据集中的原图进行分块,获得分块的子图,来实现密集场景下稠密人脸样本的扩充,同时保留有原始分辨率图像的原图。
所述步骤1中,在分块时,分割的子图其宽度bw和高度bh的计算公式如下:
bw=(overlap_rate+1)*w/2 (1);
bh=(overlap_rate+1)*h/2 (2);
其中:w和h分别为原图的宽和高,overlap_rate为分块边缘重叠率;
所述步骤1中,在分块的同时,对图片分块时根据不同的场景采取不同的策略,包括:
(a)对大尺度人脸不分块;
(b)人脸残缺和无人脸的分块舍弃,仅保留人脸完整的分块。
(c)密集场景下保留分块区域,但不完整的大尺度人脸标注将被舍弃;
(d)密集场景下均匀分布人脸且无明显尺度跨越则直接分块。
所述步骤2中,构建YOLOv3和分块-融合策略相结合的YOLOv3网络模型。
本发明构建的YOLOv3和分块-融合策略相结合的YOLOv3网络模型分为模型训练和目标检测两个阶段,具体如下:
模型训练:本发明在模型训练阶段使用YOLOv3网络模型进行训练,训练时使用步骤1中数据增广后的人脸数据集,其中YOLOv3网络训练损失函数如公式(3.1~3.6)所示:
YOLOv3损失函数包含边界框中心点坐标损失Loss
目标检测:
本发明在目标检测阶段,利用模型训练阶段得到的权重文件进行检测,检测时首先将输入图片执行带边缘重叠的分块,得到分块与原图共5张图片,之后将分块图片与输入图片一同输入到YOLOv3网络中,在YOLOv3网络中分别对5张图片进行预测,其中YOLOv3网络对每张图片进行预测的具体过程如下,首先输入图片经过YOLOv3网络的特征提取网络darknet53,darknet53网络包含53个卷积层,通过darknet53卷积之后,得到输入图片1/32尺寸的特征图。以416*416*3尺寸的输入图片为例,通过darknet53网络卷积后,将得到13*13*255尺寸的特征图,在13*13*255特征图的基础上通过上采样以及与浅层特征融合又分别得到26*26*255、52*52*25尺寸的特征图,这3个尺度下的特征图分别用于对大尺度、中尺度、小尺度目标进行预测。YOLOv3通过在这3个尺度下的特征图上分别预测得到大、中、小3个尺度下的目标,其中YOLOv3网络模型在特征图上的目标检测原理为,YOLOv3网络对特征图上的每个像素对应的网格,都会给出3个anchor进行预测,找到大小最合适的anchor,其中anchor由训练前通过对数据集进行聚类得到,之后网络输出的4个偏移量,即可得到预测框。YOLOv3对每个预测边界框,给出4个值,t
b
b
其中,t
当YOLOv3网络完成了原图加分块图片一共5张图片的预测之后,将其中4张分块图片的预测结果映射到原始图片上,最终使用本发明提出的NMS算法去除冗余预测结果之后得到最终的检测结果。
所述步骤3中,改进的NMS算法流程如下:
(1)将输入候选预测边界框列表B,按照得分降序排列;
(2)选取得分最高的预测边界框A添加到输出列表D,并将得分最高的预测边界框A从候选预测边界框列表B中去除;
(3)计算得分最高的预测边界框A与候选预测边界框列表B中其他所有框的IOU值,并去除大于阈值的候选框;
IOU值的计算如公式(5)所示,命名为B-IOU:
当出现边界框B_BOX1完全包含另一个较小的边界框B_BOX2时,设定B_BOX1为置信度更高的边界框,此时两个边界框的交集为B_BOX2,B-IOU则不采用并集,直接使用要比较的边界框B_BOX2,此时比值B_BOX2/B_BOX2的比值结果为1,大于设置的IOU阈值0.5,能够将错误的冗余边界框B_BOX2去除。
④重复上述步骤,直到候选预测边界框列表B为空,返回输出列表D。
所述步骤3中,基于改进的NMS算法包括NMS方案1、NMS方案2;
NMS方案1流程如下:
S1:输入合并后的预测边界框列表B、以及原图预测框列表O,均按得分排序;
S2:判断预测边界框列表B是否为空,若是,直接执行S11;若否,进行S3;
S3:获取原图预测框列表O中面积最大的边界框B_BOX1;
S4:判断边界框B_BOX1面积是否大于阈值;若是,进行S5;若否,进行S6;
S5:从原图预测框列表O中去除面积最大的边界框B_BOX1,添加到列表D中,并从预测边界框列表B中删除面积最大的边界框B_BOX1,之后跳过S6,执行S7;
S6:获取预测边界框列表B中得分最高的边界框B_BOX1,添加到列表D中,并从预测边界框列表B中删除得分最高的边界框B_BOX1;
S7:从预测边界框列表B中选取下一个边界框B_BOX与边界框B_BOX1执行公式(5)B-IOU计算;
S8:判断B-IOU是否大于阈值;若是,进行S9;若否,进行S10;
S9:从预测边界框列表B中去除边界框B_BOX;
S10:是否完成所有边界框的B-IOU计算;若是,返回S2;若否,返回S7;
S11:输出最终预测边界框列表D。
NMS方案2流程如下:
S-1:输入检测图片,并初始化列表A,B,C,D;
S-2:将输入图片进行检测并获取检测结果保存到A中,同时初始化分块重叠率为0;
S-3:获取当前分块重叠率;
S-4:按照重叠率对输入图片分块,并对分块进行检测;
S-5:将分块检测结果合并后,保存到预测边界框列表B中;
S-6:将S-2中预测边界框列表A结果保存到输出列表D中;
S-7:判断输出列表D是否为空;若是,执行步骤S-13;若否,执行步骤S-8;
S-8:获取列表D中一个边界框B_BOX1,保存到列表C中,并从输出列表D中删除该框;
S-9:从预测边界框列表B中选取未比较的边界框B_BOX,与边界框B_BOX1行公式(5)B-IOU计算;
S-10:判断B-IOU是否大于阈值;若是,执行步骤S-11;若否,执行步骤S-12;
S-11:从预测边界框列表B中去除边界框B_BOX;
S-12:判断是否完成预测边界框列表B中所有边界框的B-IOU计算;若是,返回步骤S-7;若否,返回步骤S-9;
S-13:将预测边界框列表B和列表C合并为新的检测结果,并保存到预测边界框列表A中,清空列表B和C;
S-13:分块重叠率增加0.1;
S-14:判断分块重叠率是否大于0.9;若是,直接进行步骤S-15;若否,返回步骤S-3;
S-15:输出列表D;
本发明一种YOLO和分块-融合策略结合的稠密人脸检测方法,技术效果如下:、
1)本发明方案首先针对WIDERFACE数据集的训练集密集场景人脸样本较少的问题,提出一种将分块应用于数据增广的方案,该方法针对不同尺度的人脸采取不同的分块方案,有效扩充了密集场景下的人脸样本。然后构建YOLOv3和分块-融合策略相结合的网络,在检测阶段,按照一定的边缘重叠率将原图分为4块,并将分块得到的图片和原图一同输入到网络中分别进行检测。之后本发明方案针对经典NMS算法在分块-融合策略中大尺度人脸边界框融合时出现的边界框冗余以及图6(a)所示的错误检测问题,对NMS算法进行改进,提出两种NMS算法的改进方案,实现了正确检测,效果如图6(b)所示。
2)本发明方案提出的YOLOv3和分块-融合策略相结合的人脸检测算法,相比于YOLOv3初始模型,在WIDERFACE验证集“hard”子集上的精度获得了7%的提升。在4K-FACE整体数据集上提升了4.9%的精度。同时,本发明方案提出的分块-融合策略不针对特定网络,可以广泛应用于各种目标检测算法中对小目标以及密集场景下目标精度的提升。同时,本发明方案提出的针对分块-融合策略的基于B-IOU的NMS算法在其他密集场景的目标检测中也有一定的作用。
3)针对经典NMS方案无法很好解决分块-融合中的人脸包含问题,本发明提出了两种改进NMS方案,改进NMS方案1的算法流程如图7所示,主要解决分块中大尺度人脸融合问题;改进NMS方案2的算法流程如图8所示,利用迭代的思想,通过多次NMS在解决人脸融合问题的同时,利用不同分块重叠率下的检测提高小人脸的召回提高最终检测精度。
附图说明
图1为密集场景下的稠密人脸检测示意图。
图2(a)为对大尺度人脸不分块示意图;
图2(b)为舍弃人脸残缺和无人脸分块仅保留完整人脸分块示意图;
图2(c)为密集场景下保留分块区域示意图;
图2(d)为密集场景下均匀分布人脸且无明显尺度跨越则直接分块示意图。
图3为分块策略中使小人脸相对尺度增大示意图。
图4(a)为经典NMS方案中的IOU计算方法边界框相交示意图;
图4(b)为经典NMS方案中的IOU计算方法边界框包含示意图。
图5(a)为本发明NMS方案1中的IOU计算方法边界框相交示意图;
图5(b)为本发明NMS方案2中的IOU计算方法边界框包含示意图。
图6(a)为经典NMS方案在分块-融合策略中的错误检测示意图。
图6(b)为利用本发明的NMS方案实现正确检测的示意图。
图7为本发明改进NMS方案1流程图。
图8为本发明改进NMS方案2流程图。
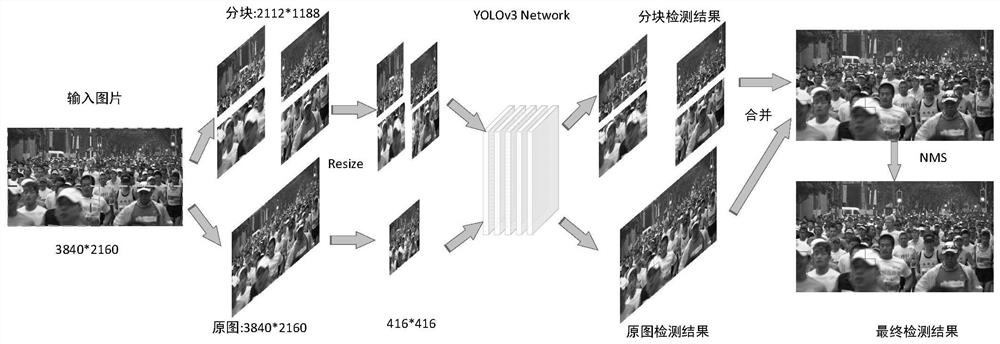
图9为YOLOv3和分块-融合策略相结合的人脸检测流程示意图。
具体实施方式
YOLO和分块-融合策略结合的稠密人脸检测方法,包括以下步骤:
步骤1:对人脸数据集增广,扩充密集场景下的稠密人脸样本用于训练;
步骤2:构建与分块-融合策略相结合的YOLOv3网络模型;
步骤3:针对分块-融合策略对NMS算法提出两种改进方案。
每一步的详细内容如下:
步骤1:数据预处理,本发明对密集场景下的稠密人脸检测模型的训练选择WIDERFACE数据集,文献[11]Yang S,Ping L,Chen C L,et al.WIDER FACE:A FaceDetection Benchmark[C].IEEE Conference on Computer Vision&PatternRecognition,2016:arXiv:1511.06523.中有记载。WIDERFACE数据集是目前应用广泛的人脸训练数据集,但是密集场景下的人脸样本不足,在单张图片中,人脸密集程度与人脸数成正相关,单张图片中人脸越多,人脸越密集。如表1所示,为该数据集中单张图片中包含人脸数与对应图片的数量,其中具有较多人脸的密集人脸场景的图片仍然较少,因此在训练前本发明需要对密集人脸样本进行扩充。
本发明对训练数据集通过对原始WIDERFACE数据集训练集中的图片进行分块,获得分块子图来实现密集场景下稠密人脸样本的扩充。同时,受到YOLO网络自身感受野的限制,存在当目标尺度过大超出YOLO网络的感受野时,网络因无法获取完整人脸的特征而影响训练的问题。因此,在使用分块策略对训练集进行分块时,考虑到在分块中大尺度的人脸的相对尺度也会增大,可能超出YOLO网络的感受野。所以为了避免大尺度人脸因为分块获得更大的相对尺度导致尺度跨越过大影响训练,在训练集中同时保留了原始分辨率的图像。表1同时描述了本发明根据图片中包含人脸数将WIDERFACE训练集图片分为不同的类别,对不同的类别分别采取不同的分块策略。通过限制不同类别的图片分块得到的图片数量,在扩充密集人脸样本的同时保证密集人脸样本在训练数据集中的比例。
表1训练集中不同类别图片分块策略
其中,在分块时分割的子图宽度bw和高度bh的计算公式如下:
bw=(overlap_rate+1)*w/2 (1)
bh=(overlap_rate+1)*h/2 (2)
其中:w和h分别为原图的宽和高,overlap_rate为分块边缘重叠率。在分块的同时,考虑到分块切割过程中会导致人脸的不完整,相应的人脸的标注信息也会残缺,因此在对图片分块时根据不同的场景采取不同的策略。
如图2(a)~图2(d)所示:图2(a)中对大尺度人脸不分块;图2(b)中绿色分块(人脸残缺)和黄色分块(无人脸)的分块舍弃,仅保留红色分块;图2(c)中密集场景下保留分块区域,但不完整的大尺度人脸标注将被舍弃;图2(d)中密集场景下均匀分布人脸且无明显尺度跨越则直接分块。
步骤2:针对YOLOv3网络在小目标检测上存在的检测精度不够理想的问题,提出YOLOv3和分块-融合策略相结合的算法,通过分块-融合策略提高在小尺度目标上的检测精度。在小目标检测中,目标的召回率会随着目标相对尺寸的增大而增大。在小目标检测中,目标的召回率会明显提升目标检测的精度,因此解决小人脸检测的难题可以通过提高小人脸的分辨率以及增大小人脸的相对尺度来解决。如图3所示,本发明使用分块-融合策略,通过分块,分块中的小人脸将会获得更大的相对尺度。同时,通过分块,图片在检测输入时,下采样率降低,小人脸会保留更多的像素信息,留下更多的特征,使小人脸更容易被检测。
步骤3:针对分块-融合策略在大尺度人脸检测中融合时存在的问题,对基于交并比的NMS算法进行改进,解决大尺度人脸融合问题的同时提高小人脸检测的精度。NMS算法是目标检测领域中对目标进行定位时用于去除多余预测边界框的常用方法。经典NMS算法的流程如下:
1)将输入候选预测边界框列表B按照得分降序排列;
2)选取得分最高的预测边界框A添加到输出列表D,并将框A从候选框列表B中去除;
3)计算框A与B中其他所有框的IOU值,并去除大于阈值的候选框;
4)重复上述步骤直到候选列表B为空,返回输出列表D。
经典NMS算法在对检测结果进行融合时会出现如下两个问题:
问题1:经典NMS算法中在步骤3)中使用IOU来判断是否去除待比较的预测边界框B_BOX2,而IOU是通过两个边界框所包围区域的交集比上并集得到的值是否大于设置的阈值来判断是否去除待比较的预测边界框。经典NMS算法中IOU的计算如公式(3)所示:
图4(a)、图4(b)描述了经典NMS算法中IOU的两种边界框的情况,当出现如图4(b)所示边界框B_BOX1完全包含另一个较小的边界框B_BOX2时,设B_BOX1为置信度最高的边界框,此时两个边界框的交集为B_BOX2,并集为B_BOX1,显然交集与并集比值B_BOX2/B_BOX1的比值小于阈值0.5,本发明设置IOU阈值为0.5;而无法删除B_BOX2,从而导致在检测结果中出现冗余边界框B_BOX2。若简单通过降低阈值来避免该情况的出现,则又会导致部分距离较近的人脸容易被错误的去除。
因此,本发明针对分块-融合以及密集场景下的目标检测对经典NMS算法中的IOU方案做出改进,本发明中IOU的计算如公式(5)所示,命名为B-IOU:
图5(a)、图5(b)描述了调整后的B-IOU的计算方式,图5(b)中则显示了本发明中如何去除大尺度人脸中出现的具有被包含边界框时的冗余检测,当出现如图4(b)所示边界框B_BOX1完全包含另一个较小的边界框B_BOX2时,仍设B_BOX1为置信度更高的边界框,此时两个边界框的交集为B_BOX2,B-IOU则不采用并集,直接使用要比较的边界框B_BOX2,此时比值B_BOX2/B_BOX2的比值结果为1,大于设置的IOU阈值0.5,成功将错误的冗余边界框B_BOX2去除。
问题2:经典NMS算法步骤2中以边界框的得分为标准来选择是否为最佳的预测边界框,然而在某些情况下得分最高的不一定为最佳预测边界框。如在分块-融合中,对于图片中较大尺度的人脸,在分块时会被切割为不完整的人脸,导致分块中的人脸残缺。在检测时,对于同一个人脸,分块检测结果中不完整的预测边界框的得分高于原图检测结果中完整的预测边界框的得分,在NMS融合过程中,分块和原图的预测结果通过得分选择,使得原图中完整的预测边界框被分块中得分更高的但残缺的预测边界框抑制。如图6(a)所示,经典NMS算法无法正确进行错误冗余边界框的删除,图6中数字表示预测边界框的得分。
为了解决分块-融合中出现的大尺度人脸边界框在融合中出现的边界框冗余以及图6(a)所示的错误检测问题,本发明对经典NMS算法的融合流程进行改进。针对问题2中经典NMS算法以预测边界框得分来选择最佳预测边界框的情况进行改进,有效解决了经典NMS算法在分块-融合策略中存在的问题,实现了正确检测,检测效果如图6(b)所示。本发明提出两种改进方案,具体方案如下:
其中,NMS方案1将经典NMS方案中以预测边界框得分为标准来选择最佳预测边界框,调整为当原图检测结果中的预测边界框的面积大于阈值时则认为是最佳预测边界框,小于阈值的预测边界框则仍以得分为标准来判断是否为最佳预测边界框,其具体程如图7所示。
改进的NMS方案2中,获得原图检测结果和第一次无边缘重叠时的分块的检测结果后,在NMS阶段不使用预测框得分为判断标准,而是以原图检测结果中的预测边界框作为最佳预测边界框来去除分块检测中产生的冗余边界框,将分块检测结果中剩余的预测边界框原图检测结果中的预测边界框合并获得新的检测结果,之后增加分块边缘重叠率,增加大小为0.1,按照新的重叠率对原图进行分块再进行检测,将上一步中获得的新的检测结果作为最佳的预测边界框来去除本次分块检测结果中冗余的预测边界框,之后再合并,重复上述步骤直到分块重叠率为0.9停止。其具体流程如图8所示。
将本发明方案改进的NMS方案应用于分块-融合策略检测阶段,本发明YOLOv3和分块-融合策略相结合的人脸检测算法,最终的检测流程如图9所示,首先输入图片经过分块与原图一同被Resize为416*416的尺寸输入到网络中,分别执行检测,之后合并检测结果,利用本发明方案中提出的改进的NMS方案1进行融合得到最终的检测结果。图9中NMS为本发明方案改进的NMS方案1。
最终本发明的模型利用WIDERFACE训练集进行训练,在WIDERFACE数据集的验证集上进行测试,同时为了说明本发明在高分辨下的密集人脸检测所具有的优势,同时在4K-FACE数据集上进行测试,其中4K-Face数据集由S-Face制作,见文献[12]Wang J,Yuan Y,YuG,et al.SFace:An Efficient Network for Face Detection in Large ScaleVariations[J]:arXiv:1804.06559.中记载。该文献使用外科医生、庆典、旅游等可能包含人脸的场景的关键字搜索网络上的图片,但仅保留包含人脸的4K分辨率图像,最终数据集包含5102张图像,超过30000个人脸。该数据集的人脸尺度变化范围更大,更加挑战模型对大尺度跨越的人脸检测的能力,但该数据集相比WIDERFACE规模太小,因此在本发明中仅用于对模型的性能进行评估。4K-Face数据集的下载链接如下:https://github.com/wjfwzzc/4K-Face。表2和表3分别描述了本发明在WIDERFACE验证集上的精度和在4K-FACE数据集上的精度对比,本发明基于YOLOv3实现,相比于YOLOv3本发明在WIDERFACE包含大量密集场景的“hard”子集上取得了最好的表现。在4K-FACE数据集上尺度小于32的人脸检测中同样取得了最好的表现。
表2本发明和其他算法在WIDER FACE验证集上的精度对比表
表2中文献[13]为:Lin T,Goyal P,Girshick R,et al.Focal Loss for DenseObject Detection[C].international conference on computer vision,2017:2999-3007.
表2中文献[14]为:Yu J,Jiang Y,Wang Z,et al.UnitBox:An Advanced ObjectDetection Network[C].acm multimedia,2016:516-520.
表2中文献[15]为:Deng J,Guo J,Zhou Y,et al.RetinaFace:Single-stageDense Face Localisation in the Wild[J].arXiv preprint arXiv:1905.00641,2019.
表3本发明和其他算法在4K-FACE数据集上不同尺度下的精度对比表
- YOLO和分块-融合策略结合的稠密人脸检测方法
- YOLO与旋转-融合策略相结合的鸟类视觉目标检测方法