一种基于NL2SQL技术的配电自动化图表生成方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及语义识别领域,尤其涉及一种基于NL2SQL技术的配电自动化图表生成方法。
背景技术
随电网服务型系统的不断完善,系统如浙江配电自动化Ⅳ区主站系统的数据规模和复杂度日益增大,数据分析人员从海量信息数据中找到合适有用的信息的难度日渐增加。重要信息或关键信息的获取往往需要依赖对系统功能模块熟悉的人员进行数据筛取和数据分析。因此,现有的数据筛取和数据分析需要大量的时间。
发明内容
为解决上述问题,本发明提出一种基于NL2SQL技术的配电自动化图表生成方法。
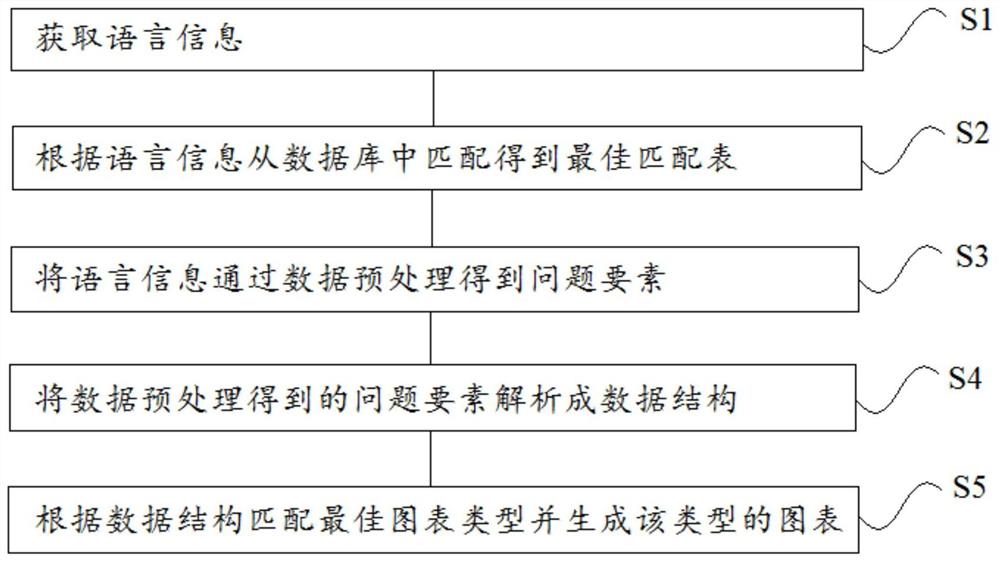
一种基于NL2SQL技术的配电自动化图表生成方法,包括:
获取语言信息;
根据语言信息从数据库中匹配得到最佳匹配表;
将语言信息通过数据预处理得到问题要素;
将数据预处理得到的问题要素解析成数据结构;
根据数据结构匹配最佳图表类型并生成该类型的图表。
优选的,所述根据语言信息从数据库中匹配得到最佳匹配表包括:
将数据库中表的字段名、枚举值、实体标签按字级别构建成倒排索引;
通过计算语言信息中问题与每个表的字段名、枚举值和标签的jaccard距离,当问题中包含与两个及以上的表相关的字段时,采用position_diff计算方式将问题中匹配得到的字段按顺序排列,并计算在倒排索引中记录的距离的差分序列之和;
进行到排序得到最佳匹配表。
优选的,所述通过计算语言信息中问题与每个表的字段名、枚举值和标签的jaccard距离包括:
其中,question是问题中字和实体标签的集合,table是表的字段名,invert_index是倒排索引。
优选的,所述采用position_diff计算方式将问题中匹配得到的字段按顺序排列包括:
优选的,所述根据语言信息从数据库中匹配得到最佳匹配表包括:
通过word2vec模型对词进行向量化,对问题进行分词;
在问题上使用长度为3的滑动窗口从左向右滑动,每滑动一次,计算窗口内的词的向量和预先设定的表向量之间的相似度;
每个窗口相似度的最大值为表的分数,以最终得出数值最大的为最佳匹配表。
优选的,所述将语言信息通过数据预处理得到问题要素包括:
对问题进行分词、词性标注、实体识别和依存句法分析。
优选的,所述数据结构包含需要查询的字段、查询结果数量、排序和分组要求。
优选的,所述根据数据结构匹配最佳图表类型并生成该类型的图表包括:
以维度和指标为条件设定规则以描述不同类型图表;
根据数据结构通过关键词库在问题上进行匹配,若匹配成功,则得到候选图表类型,若该候选图表类型满足对应的图表类型规则,则该候选图表类型为最终结果,否则直接使用规则的方式得到需要的图表类型。
本发明的有益效果:获取语言信息;根据语言信息从数据库中匹配得到最佳匹配表;将语言信息通过数据预处理得到问题要素;将数据预处理得到的问题要素解析成数据结构;根据数据结构匹配最佳图表类型并生成该类型的图表。本发明能够根据需要自动获取数据并自动生成对应类型的图表。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是本发明实施例一种基于NL2SQL技术的配电自动化图表生成方法流程示意图;
图2是本发明实施例一种基于NL2SQL技术的配电自动化图表生成方法中精确匹配的流程示意图;
图3是本发明实施例一种基于NL2SQL技术的配电自动化图表生成方法中模糊匹配的流程示意图。
具体实施方式
以下结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
在电力系统里,电网信息系统往往是一个大而复杂的系统,电网信息量巨大,当需要找寻历史数据或需要利用各处数据生成图表进行数据分析时,由于数据庞大且来处复杂,用户难以准确找到合适的能够加以利用的数据。本发明的基本思想是根据用户的语言信息进行分析意图,通过得到的分析意图自动从数据库中提取数据、生成表格。
基于上述思想,本发明实施例提出一种基于NL2SQL技术的配电自动化图表生成方法,如图1所示,包括以下步骤:
S1:获取语言信息。
在本实施例中,可以通过麦克风阵列等语音采集装置获取用户的语言信息。语言信息包括所要获取的数据相关的问题以及所要生成表格相关的问题。
S2:根据语言信息从数据库中匹配得到最佳匹配表。
数据库用于存储记载数据的表格。当后台在元数据发生变更时,调用读写服务,在数据库库中的元数据发生变动时对缓存进行更新。
在本实施例中,采用精确匹配和模糊匹配相结合的策略,根据语言信息从数据库中匹配得到最佳匹配表,能保证精确匹配的同时兼顾效率。
其中,精确匹配采取离线任务、在线任务相结合的模式,如图2所示,精确匹配包括以下步骤:
S201:离线任务中将数据库中表的字段名、枚举值、实体标签按字级别构建成倒排索引;
S202:在线任务中通过计算语言信息中问题与每个表的字段名、枚举值和标签的jaccard距离,当问题中包含与两个及以上的表相关的字段时,采用position_diff计算方式将问题中匹配得到的字段按顺序排列,并计算在倒排索引中记录的距离的差分序列之和;
S203:进行到排序得到最佳匹配表。
通过计算语言信息中问题与每个表的字段名、枚举值和标签的jaccard距离包括:
其中,question是问题中字和实体标签的集合,table是表的字段名,invert_index是倒排索引。
所述采用position_diff计算方式将问题中匹配得到的字段按顺序排列包括:
其中,如图3所示,模糊匹配包括以下步骤:
S211:通过word2vec模型对词进行向量化,对问题进行分词;
Word2vec用来产生词向量的相关模型。这些模型为浅层双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。
S221:在问题上使用长度为3的滑动窗口从左向右滑动,每滑动一次,计算窗口内的词的向量和预先设定的表向量之间的相似度;
S223:每个窗口相似度的最大值为表的分数,以最终得出数值最大的为最佳匹配表。
S3:将语言信息通过数据预处理得到问题要素。
在本实施例中,数据预处理包含对问题进行分词、词性标注、实体识别和依存句法分析。采用word2vec对词进行向量化的方式对问题进行分词。
S4:将数据预处理得到的问题要素解析成数据结构。
在本实施例中,将数据预处理得到的问题要素解析成数据结构,数据结构包含需要查询的字段、查询结果数量、排序和分组要求,同时说明了图表的指标及维度。
S5:根据数据结构匹配最佳图表类型并生成该类型的图表。
根据数据结构匹配最佳图表类型进行展示。以维度和指标为条件设定规则以描述不同类型图表,采用“先关键词后规则”匹配过程,根据预处理得到的问题要素翻译得到的数据结构,通过关键词库在问题上进行匹配,若匹配成功,即得到候选图表类型,若该候选图表类型满足对应的图表类型规则,该候选图表即为最终结果,否则系统直接使用规则的方式得到需要的图表类型。
本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 一种基于NL2SQL技术的配电自动化图表生成方法
- 一种兼容多种大数据图表库引擎的图表生成方法及装置