一种多模态特征融合的人物交互行为识别方法
文献发布时间:2023-06-19 10:57:17
技术领域
本发明属于计算机视觉和行为识别技术领域,涉及一种多模态特征融合的人物交互行为识别方法。
背景技术
随着人工智能技术的不断发展和应用,人体行为识别是目前计算机视觉与模式识别领域的一个热门研究方向,其广泛应用于智能视频监控、运动行为分析、人机智能交互、虚拟现实等领域。因深度传感器可有效的避免受到光照、遮挡,环境变化等因素的影响,基于骨骼数据的行为识别方法得到了越来越多的研究。传统的基于骨架的动作识别通常人为设计特征来表示骨架,现有的基于深度学习的方法分为三种:递归神经网络模型(RNN)、卷积神经网络模型(CNN)、图卷积网络模型(GCN),其中连接点信息分别被表示成向量序列、伪图像、图。基于序列的方法将骨架信息表示成有着设计好的遍历规则的骨架序列,然后用RNN进行动作识别;基于图像的方法通常把骨架信息表示成伪图像;基于图的方法用图来表示骨架信息,天然地保留了人体骨架信息。最近,将人体骨骼建模为时空图的图卷积网络(GCN)取得了优越的性能,但现有的方法中依然存在着如下问题:
(1)特征选择过于单一,不能更有效更丰富的反应运动变化信息对动作视频进行理解分类;
(2)对于场景中人与物存在交互的动作相互错分概率较高,识别准确率低;
(3)数据集存在一部分无法准确追踪到骨骼点的负样本,影响最终识别结果。
发明内容
本发明的目的是提供一种多模态特征融合的人物交互行为识别方法,解决了现有技术中存在的场景中人与物存在交互时动作相互错分概率较高,识别准确率低的问题。
本发明所采用的技术方案是,一种多模态特征融合的人物交互行为识别方法,具体按照以下步骤实施:
步骤1、在现有3D骨骼数据集NTU RGB+D中筛选人、物交互动作类别,通过算法标定获取交互物信息;
步骤2、通过对步骤1获取的交互物信息基于深度学习的交互物判断算法对步骤1中3D骨骼数据集NTU RGB+D中人、物是否存在交互进行判断;
步骤3、对步骤2存在交互的动作类别,进行骨骼、RGB信息网络框架模型的搭建,并对模型进行训练;
步骤4、对步骤2存在交互的动作类别,考虑人与物时空关系变化规律,搭建人、物空间关系网络模型;
步骤5、对步骤3,步骤4模型整体进行优化,将骨骼、RGB、人物空间关系多模态信息特征进行融合,最后使用已训练好的模型对交互动作进行识别分类。。
本发明的特点还在于:
步骤1具体按照以下步骤实施:
步骤1.1、在NTU RGB+D数据集60类动作中筛选存在人物交互动作类别;
步骤1.2、利用跟踪算法Siam RPN对步骤1.1筛选动作类别物体进行跟踪以获取物体位置(x
步骤1.3、每个动作序列物体位置信息以.txt格式保存方便数据的读入与预处理;
步骤1.4、对NTU RGB+D数据集动作场景进行正负样本标定,正样本为存在人物交互,标为1,负样本为不存在人物交互,标为0。
步骤2具体按照以下步骤实施:
步骤2.1、根据人、物重心进行连接,形成特征向量对;
步骤2.2、将特征向量对以时间维度排列编码形成二维矩阵;
步骤2.3、上述二维矩阵以图像形式输入到交互判断网络中进行训练;
步骤2.4、调整网络结构和参数,使模型能准确的判断动作序列是否存在人物交互。
步骤3具体按照以下步骤实施:
步骤3.1、基于3D骨骼数据的行为识别,采用图卷积网络建模有效的获取空间运动信息;
步骤3.2、对图卷积中邻接矩阵重新定义,使模型参数具有权重和注意力,更形象的反映空间连接关系;
步骤3.3、基于RGB特征的行为识别,以不同高度和宽度裁剪动作序列中单帧图片,然后尺度归一化调整到相同大小;
步骤3.4、对裁剪后的动作序列中RGB信息,使用在ImageNet和Kinetics上预先训练的ResNeXt3D-101模型进行训练;
步骤3.5、通过参数调整优化以上模型识别分类性能。
步骤4具体按照以下步骤实施:
步骤4.1、利用关节点位置与物体位置变化关系进行空间建模;
步骤4.2、选取多个关节点与物体进行向量连接,向量方向由关节指向物体;
步骤4.3、以动作序列时间t为行,不同关节点向量为列构建像素矩阵作为输入,采用卷积神经网络进行特征学习并完成动作的分类;
步骤4.4、根据人、物空间关系特征,选择合适网络结构并进行参数调整使性能达到最好。
步骤5具体按照以下步骤实施:
步骤5.1、考虑到特征选择融合互补性,将三支流模型在相同条件下进行融合;
步骤5.2、相同实验基准下,融合各模型对比平均准确率,判断各支流运动信息对最终动作分类是否有补充;
步骤5.3、对数据集中骨骼关节点追踪不准确的负样本进行筛选,以提高模型整体性能;
步骤5.4、将动作序列输入到搭建好的多模态融合网络模型中,计算输出预测分类结果对应的标签。
本发明的有益效果是:
1、本发明多模态特征融合的人物交互行为识别方法使用多特征融合策略使行为数据样本更具表征能力,并改变了原有的深度网络结构与特征编码方式,相比于传统的单一特征提取网络,能更好的对动作进行识别;
2、本发明多模态特征融合的人物交互行为识别方法针对使用的样本数据,通过骨骼关节点可视化发现负样本,误差分析对其进行剔除能更有效的完成网络对数据样本的学习,从而达到更好的分类和识别效果;
3、对于场景中人与物存在交互的动作相互错分概率较高,识别准确率低的问题。分析原因在这些动作都集中在相同身体部位,但用骨骼节点数据表示这些局部细粒度的动作,类间相似度会较高。本发明多模态特征融合的人物交互行为识别方法提出的多模态的融合策略对存在交互的动作引入交互物的RGB信息进行融合能更有效的区分这些动作,解决以上人、物交互动作识别存在的问题。
附图说明
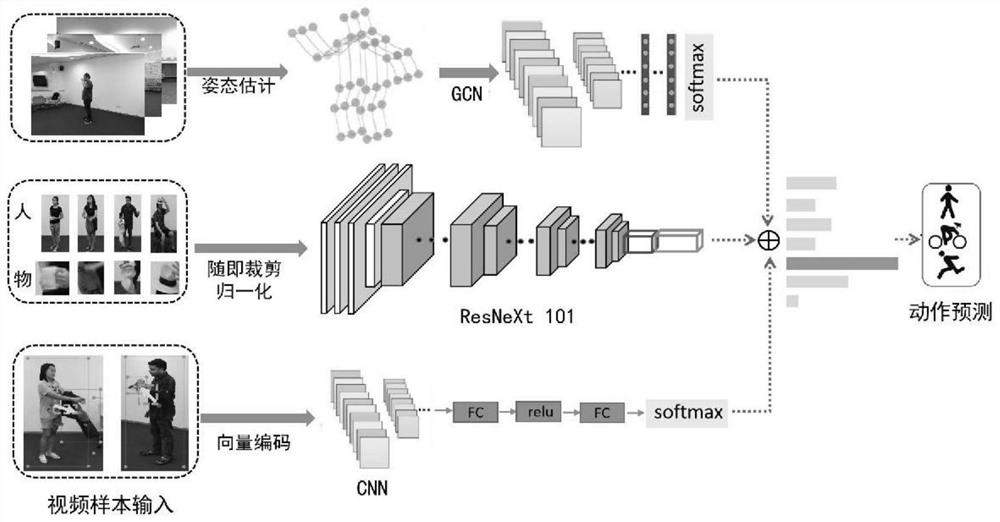
图1是本发明一种多模态特征融合的人物交互行为识别方法的结构框图;
图2是本发明一种多模态特征融合的人物交互行为识别方法人物交互标定示意图;
图3是本发明一种多模态特征融合的人物交互行为识别方法人物交互判断网络结构示意图;
图4是本发明一种多模态特征融合的人物交互行为识别方法人物交互问题示意图;
图5是本发明一种多模态特征融合的人物交互行为识别方法数据预处理前后对比示意图;
图6是本发明一种多模态特征融合的人物交互行为识别方法第三支流(人、物、空间关系建模)示意图;
图7是本发明一种多模态特征融合的人物交互行为识别方法负样本数据示意图.
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种多模态特征融合的人物交互行为识别方法,如图1所示,具体按照以下步骤实施:
步骤1、在现有3D骨骼数据集NTU RGB+D中筛选人、物交互动作类别,通过算法标定获取交互物信息;如图2所示,具体按照以下步骤实施:
步骤1.1、NTU RGB+D动作识别数据集由56,880个动作样本组成,包含每个样本的RGB视频,深度图序列,3D骨架数据和红外视频,在NTU RGB+D数据集60类动作中筛选存在人物交互动作类别,喝水,吃东西,阅读,写字等;
步骤1.2、利用基于孪生网络的跟踪算法Siam RPN对步骤1.1筛选动作类别物体进行逐帧跟踪,对丢帧或跟踪失败样本采取手工标注的方式以获取物体位置(x
步骤1.3、每个动作序列物体位置信息以.txt格式逐帧保存,方便数据的读入与预处理;
步骤1.4、为解决样本中人与物体是否存在交互的问题,对NTU RGB+D数据集动作场景进行正负样本标定,正样本为存在人物交互,标为1。负样本为不存在人物交互,标为0;
步骤2、通过对步骤1获取的交互物信息基于深度学习的交互物判断算法对步骤1中3D骨骼数据集NTU RGB+D中人、物是否存在交互进行判断,如图3所示,具体按照以下步骤实施:
步骤2.1、根据人、物重心进行连接,形成特征向量对,人、物重心x以及两点间的距离d计算公式如下:
d=(y
其中(x
步骤2.2、将特征向量对以空间位置坐标(x,y)和距离d进行排列,时间维度视频进行等间隔采样排列,编码形成二维矩阵;
步骤2.3、编码好的2D图像依次进行卷积、归一化、激活操作,输出图像,具体先用CNN前五层提特征,得到特征向量,再在行(时间上)做池化,池化核6*1,这实现时域上的信息融合,将正负样本输入到网络中进行训练,实现交互判断的功能;
步骤2.4、调整网络结构和参数,包括卷积层数与卷积核大小,非线性激活函数的选用,BatchNorm层的加入,以及损失函数和正则化项的定义,使模型能稳定的判断动作序列是否存在交互情况;
损失函数具体采用交叉熵损失函数,具体计算为:
其中C表示数量,即数据集中动作的类别数;y
人物交互动作判断主要问题在于一些动作姿态在骨骼的角度上十分相似,基于骨骼信息的方法无法很好的区分,如图4所示,左边“喝水”和“吃东西”的动作与右边“玩手机”和“敲键盘”的动作姿态极为相似难以区分,导致识别率低,以下步骤解决了这个问题;
步骤3、对步骤2存在交互的动作类别,进行骨骼、RGB信息网络框架模型的搭建,并对模型进行训练,具体按照以下步骤实施:
步骤3.1、基于3D骨骼行为识别,输入时间序列的骨骼数据x
为了使数据表达的更加精确,预处理阶段将每个样本归一化以统一每个通道的数据分布,“脊柱关节”作为坐标原点,每个关节的坐标都减去“脊柱关节”以获得新坐标,最后将身体关节的原始3D位置从相机坐标系转换为身体坐标。对于每个样本执行3D旋转将与向量平行的X轴从“右肩”(第5个关节)固定到“左肩”(第9个关节),并将Y轴固定到“脊柱基部”,如图5所示;
具体地,对于第j帧,空间坐标系的平移参数
其中
步骤3.2、对于图的定义,G=(V,E),V为节点集合,E为边的集合,对于每个节点i,均有其特征X
其中f表示特征图,V表示图形的顶点,B
步骤3.3、原始动作视频帧像素为1920x1080,为了减轻背景的干扰,本发明从原始图像和裁剪人物部分,裁剪位置是从四个角和一个中心随机选择的,根据裁切率[1、0.75、0.5]裁切每个图像,然后尺度归一化调整到相同大小;
步骤3.4、对裁剪后的动作序列中RGB信息,使用4块GTX 2080Ti GPU在ImageNet和Kinetics上预先训练的ResNeXt3D-101模型进行微调训练,batch设置为32;
步骤3.5、学习率以0.01初始化,并在精度达到饱和后乘以0.1,随机梯度下降法SGD用作优化器,权重衰减设置为0.0005。网络迭代60次,通过参数调整使以上模型识别分类性能达到最优;
步骤4、对步骤2存在交互的动作类别,考虑人与物时空关系变化规律,搭建人、物空间关系网络模型;具体按照以下步骤实施:
步骤4.1、步骤1中已得到存在交互动作中物体的空间位置,利用关节点位置与物体位置变化关系进行空间建模;
步骤4.2、如图6所示,选取多个关节点与物体进行向量连接,向量方向由关节指向物体,形成多个向量对;
步骤4.3、以动作序列时间t为行,不同关节点向量为列构建像素矩阵作为输入,采用卷积神经网络进行特征学习并完成动作的分类;
步骤4.4、根据选取特征,特征图输入维度10×10,其结构依次包括输入层、批量归一化层(BN)、激活函数、全局平均池化层、全连接层和Softmax输出层,为防止数据给网络带来的过拟合情况,将数据进行标准化处理,并加入正则化项来重新定义损失函数使网络达到最好收敛:
其中y
步骤5、对步骤3,步骤4模型整体进行优化,将骨骼、RGB、人物空间关系多模态信息特征进行融合,最后使用已训练好的模型对交互动作进行识别分类;具体按照以下步骤实施:
步骤5.1、考虑到特征选择融合互补性,分别训练测试三支流模型交互动作分类准确率,并将三支流模型在相同条件下进行融合;
步骤5.2、在深度学习中,最基本的融合方法:(1)按点逐位相加(point-wiseaddition)和(2)进行向量拼接(concatenate),而应用在输出层常用的有平均分数融合、最大分数融合,多重积分融合,本发明在平均分数融合的基础上设置加权因子,使融合效果更为出色,最后在相同实验基准下,加入各支流模型对比平均准确率,达到模型整体性能的提升;
步骤5.3、如图7所示,用kinect V2算法采集的NTU RGB+D数据中存在追踪不准确的关节点,为减少这些数据对网络训练的影响,手动筛选负样本以提高模型整体性能;
步骤5.4、所有实验都是在Pytorch深度框架下进行的,warm up epoch设置为5,防止模型出现振荡,学习率设置为0.1,并在第20次迭代和第40次迭代除以10,迭代次数共设置为60,通过多次参数调整使准确率趋于稳定和最高,将动作序列输入到搭建好的多模态融合网络模型中,计算输出预测分类结果对应的标签。
本发明一种多模态特征融合的人物交互行为识别方法通过判断视频中人与物是否存在交互若存在交互,此时利用场景中人的交互物可以对信息进行有效补充从而达到动作分类。现有基于3D行为识别方法所存在的问题,对于场景中人与物存在交互的动作相互错分概率较高,识别准确率低。原因在于人与物产生交互,这些动作都集中在相同身体部位,但用骨骼节点数据表示这些局部细粒度的动作,类间相似度会较高。本发明考虑到人、物交互动作中RGB信息以及物体的时空信息对3D行为识别的互补性,在现有数据集上进行了特征信息的融合来达到更好的识别效果,并且手动剔除了一部分负样本。这种情况下本方法可以有更强的鲁棒性,识别结果可靠性高。
下表是相同实验条件下对NTU RGB+D数据集中13类存在交互问题的动作数据在各模型上的测试结果:
从表中可看出,这13类动作在前3种经典方法中识别率低于整个数据集,实验中单加入RGB信息的2s+TSN(13)
下表是相同实验条件下对NTU RGB+D数据集所有60类动作在各模型上的测试结果。
从表中可以看出该数据集上最经典,最新方法包括传统算法lie Group,基于深度学习递归神经网络(RNN),卷积神经网络(CNN),图卷积网络(GCN)的多种方法,本发明遵循文献中的标准做法,以top1的准确率记录跨对象(X-Sub)和跨视角(X-View)的识别性能,均高于其他方法,证明了该方法的有效性。
- 一种多模态特征融合的人物交互行为识别方法
- 一种基于多模态特征融合深度网络的视频人物识别方法