用于听力系统的与环境有关的运行的方法
文献发布时间:2023-06-19 11:17:41
技术领域
本发明涉及一种用于听力系统的与环境有关的运行的方法,其中,在训练阶段,在多个考察时间点,分别确定听力系统的第一用户的最初的多个环境数据的值,并且根据每个考察时间点的环境数据的值,分别形成特征空间中的特征向量,其中,针对第一环境情形,预先给定听力系统的信号处理的设置的至少一个值,并且其中,在应用阶段,在应用时间点,确定听力系统的第一用户或者第二用户的最初的多个环境数据的值,并且根据环境数据的值,形成应用时间点的相应的特征向量,并且与听力系统的信号处理的至少一个值的预先给定对应,针对第一环境情形,设置听力系统的信号处理的至少一个值,并且利用如此设置的至少一个值运行听力系统。
背景技术
在听力系统中,向用户提供基于音频电信号产生的声音信号供倾听,音频电信号就其而言表示用户的声学环境。在此,听力系统的一个重要的案例是助听器,借助助听器,要通过特别是与频带有关的对音频信号的信号处理,尽可能校正用户的听力障碍,以便因此优选使用户能够更好地听到环境声音中的有用信号。在此,助听器可以以不同的结构形式、例如BTE、ITE、CIC、RIC或者其它形式给出。与此类似的一种听力系统由听力辅助设备、例如人工耳蜗或者骨传导耳机给出。但是也可以通过PSAD(
与环境有关的听力系统的运行特别是对于助听器来说是已知的。在此,根据听力情形确定音频信号的信号处理的设置,其中,听力情形通过具有特定的类似的声学特征的声学环境的标准化的组给出。如果根据音频信号识别出存在标准化的组中的一个,那么利用针对该声学环境组事先确定的相应的设置来处理音频信号。
在此,经常例如在工厂侧,事先根据针对各个在声学上可测量的特征固定地预先给定的标准,对听力情形进行定义。经常针对预先给定的听力情形,预先给定相应地相关的信号处理的预设置,用户还可以个体化地对这些预设置进行调整。
然而,对各个听力情形的声学识别一方面是复杂的并且可能易出错的事情,因为声学环境可能不刚好具有相应的听力情形(例如街道附近的户外的“鸡尾酒会”等)实际需要的声学特征。另一方面,由于为了相对于彼此区分各个声学环境并且为了相应地关联听力情形而评估的多个特征,因此用户本身几乎不可能有意义地定义与其日常生活理想地匹配的听力情形。因此,用户对此大多参考对预先给定的听力情形的定义。
发明内容
因此,本发明要解决的技术问题是,给出一种方法,借助这种方法,用户一方面可以与环境有关地运行听力系统,但是也可以尽可能个体化地使环境与用户匹配。
根据本发明,上述技术问题通过用于与环境有关地运行听力系统的方法来解决,其中,在训练阶段,在多个考察时间点,分别确定听力系统的第一用户的最初的多个环境数据的值,并且根据每个考察时间点的环境数据的值,分别形成至少四维的、特别是至少六维的特征空间中的特征向量,将每个特征向量分别映射为最大三维、特别是二维的显示空间中的相关的代表向量,并且根据代表向量的子组的空间分布,针对听力系统的第一环境情形,定义显示空间中的第一区域,其中,针对第一环境情形,预先给定听力系统的信号处理的设置的至少一个值。
在此设置为,在应用阶段,在应用时间点,确定听力系统的第一用户或者第二用户的最初的多个环境数据的值,并且根据环境数据的值,形成应用时间点的相应的特征向量,根据显示空间的第一区域,并且根据应用时间点的特征向量,特别是自动识别第一环境情形的存在,并且与听力系统的信号处理的至少一个值的预先给定对应,针对第一环境情形,特别是自动设置听力系统的信号处理的至少一个值,并且利用如此设置的至少一个值运行听力系统。部分本身被视为具有创造性的有利的设计方案是下面的描述的主题。
因此,在训练阶段,一方面根据环境数据确定第一环境情形,并且确定如何能够根据环境数据区分第一环境情形与其它环境情形。此外,预先给定针对第一环境情形要应用于听力系统的音频信号的信号处理的设置。在应用阶段,确定相应的环境数据的当前存在的值,并且现在可以根据环境数据的这些值来确定是否存在第一环境情形。如果是这种情况,那么利用对此预先给定的信号处理的设置运行听力系统。
在此,在训练阶段,在不同的考察时间点确定环境数据的值,使得根据在各个考察时间点确定的环境数据的值形成的特征向量,表示尽可能多的声学环境。在此,作为环境数据,优选包括关于诸如背景噪声的频率、声音信号的稳定性、声音水平、调制频率等的声学环境参量的声学环境数据。此外,作为环境数据,也可以包括其它意义上的“非声学”的数据,例如关于听力系统的运动传感器的加速度或者其它运动参量的数据,但是也可以包括例如可以借助EEG、EMG、PPG(Photoplethysmogram(光体积描记图))、EKG等检测的生物特征数据。
在此,可以通过听力系统的听力设备,即例如通过助听器,和/或通过听力系统的其它装置、例如智能电话或者智能手表或者具有相应的传感设备的其它适当的装置,来测量所提到的参量。根据测量的参量确定环境数据的值,可以在相应的装置本身中、即在助听器中或者在智能电话等中进行,或者可以在例如从助听器或者从头戴式耳机传输到智能电话或者听力系统的类似的装置之后进行。在此,参量的测量优选连续或者准连续地(即以非常短的、例如几秒的范围内的时间间隔),优选在例如一周等内的较长的时间段内进行,从而尽可能完全地检测并且由此在一定程度上“再现(kartographiert)”用户通常遇到的环境。
作为环境数据的值,可以将所确定的所提到的或者其它的相应的参量的值,直接纳入相应的特征向量中,或者通过根据相应的参量形成平均值和/或平均值通过率(Mittelwert-Durchgangsrate)和/或方差或者类似的统计方法,形成纳入特征向量中的值。在最后提到的情况下,特征向量优选由如下的各个条目构成,这些条目分别以所描述的方式借助统计方法根据所提到的声学环境参量、运动参量和/或生物特征数据获得。在此,可以在一个考察时间点,相应地形成自先前的考察时间点以来的参量的各个值的时间上的平均值或者平均值通过率或者方差,并且将其作为环境数据的相应的值纳入特征向量中。
在此,在每个考察时间点,总共确定至少四个不同的特征的值、即不同的环境参量和/或运动参量和/或生物特征参量的各个统计特性
现在,为了向用户给出根据所确定的“特征”、即相应的特征向量单独确定各个环境情形的可能性,首先,将包含各个考察时间点的“特征”的各个特征向量,映射为显示空间中的各个相关的代表向量。在此,显示空间最多是三维的,优选是二维的,从而特别是可以针对用户,经由第一区域,将用于第一环境情形的定义的代表向量可视化。在此,特别是可以在听力系统的适当的可视化装置上、例如在智能电话的屏幕上进行显示空间的这种可视化,在这种情况下,智能电话通过其到方法中的结合而成为听力系统的一部分。在此,二维的显示空间可以直接作为“地图”来显示,三维的显示空间例如可以通过二维的截面或者三维的“点云”等来显示,用户可以在它们之间进行切换、变焦或者移动。
在此,优选将特征空间的特征向量,以如下方式映射为显示空间的代表向量,即,“类似的特征向量”,即由于其特征相对类似而在特征空间中相互比较靠近的特征向量,在显示空间中也相互比较靠近(例如相对于相应地使用的空间的总的大小)。在此,在显示空间中彼此明显分开的代表向量(或者代表向量组),优选允许推断出在特征空间中彼此分开的特征向量(或者相应的特征向量组),由此可以进行区分。相反,随着相关的相应的特征向量组的相应的代表向量在显示空间中的重叠增加,特征向量组的区分变得更困难。
现在,可以根据各个尽可能相互靠近的代表向量,在显示空间中定义第一区域。这种定义特别是可以由听力系统的用户来进行,或者也可以由用户的辅助人员(例如护理人员、护士等)来进行。为了进行定义,在此优选使用显示空间的可视化。在此,特别是还可以借助附加的标记,例如通过颜色显示,来提供各个代表向量,该颜色显示优选可以根据用户的针对作为基础的特征向量的日常/平日情形等,而对应于相应的考察时间点的附加的标记。对于用户来说,这可以简化代表向量的关联。在此,考察时间点的标记例如可以通过用户的如下输入来进行,即,该输入全局地确定其日常生活中的特定情形,即例如在家中、在车内(上班/回家的路上)、在办公室中、在职工食堂中、在运动中、在公园中等。
也就是说,现在,使用代表向量的子组,来根据其空间分布,特别是根据其(即其在显示空间中的相应的端部点)包围的区域,定义第一区域。代表向量的该子组对应于特征空间中的一个特征向量组,从而由此通过特征的相应的值范围,来确定第一环境情形。
现在,针对如此定义的、优选与用户的日常生活中的情形相关、但是还可以通过其它特征、特别是声学特征来表征的第一环境情形(例如办公室中或者家中等的不同的声学环境),预先给定听力系统的信号处理的设置的至少一个值。这优选由听力系统的用户(或者例如也可以由有技术经验的陪同人员或者护理人员)进行。为此,优选用户前往相应的环境(例如前往行驶的车辆、前往家里在室内、前往公园在户外、前往办公室/工位等)中,并且随后特别是“根据听觉”修改信号处理设置,例如借助声音平衡(Klangwaage),来修改高音重音或者低音重音或者用于风声抑制或者干扰噪声抑制的所谓的自适应参数。但是,原则上也考虑完全或者半专业训练的声学专家通常使用的每个参数的精细调节。这样的声学专家同样可以在远程适配会话中进行特定于环境的信号处理设置,因此进行针对第一环境情形的设置的定义。
因此,按照系统(Systematik),可以将训练阶段分为分析阶段和定义阶段,其中,分析阶段包括连续测量相关的参量、在相应的考察时间点确定各个相应的特征值以及将特征向量映射到显示空间中,而在定义阶段,根据代表向量,定义第一环境情形以及信号处理的设置的相关的至少一个值。
在应用阶段期间,将所进行的第一环境情形和听力系统的信号处理的相关的至少一个设置的定义,结合到听力系统的运行中。为此,首先,在应用阶段的应用时间点,通过听力系统,特别是也通过听力系统的听力设备,测量相同的环境参量和/或运动参量和/或生物特征参量,也在训练阶段测量这些参量,用于确定环境数据的值。以与此类似的方式,根据所测量的参量,形成与在训练阶段相同类型的环境数据的值和相应的特征向量。
现在,将应用时间点的特征向量,映射到显示空间中。这优选借助与训练阶段的相应的映射相同的算法,或者通过与所述算法尽可能一致的近似方法来进行,近似方法特别是将应用时间点的特征向量映射为显示空间中的代表向量,对于该代表向量来说,其相邻的环境的代表向量基于训练阶段的如下特征向量,即,这些特征向量在特征空间中也形成应用时间点的特征向量的相邻的环境。
现在,如果针对应用时间点如此形成的代表向量位于显示空间的第一区域中,那么可以推断出,存在第一环境情形,并且相应地在听力系统的运行中使用为此事先定义的信号处理的至少一个设置,即,例如将相应的、必要时与频带相关的放大和/或动态压缩、语音信号增加等,应用于听力系统的音频信号。
作为其替换,可以在特征空间中识别对应于如下特征向量的区域,这些特征向量在显示空间中的代表向量包含在第一区域内。当应用时间点的特征向量位于特征空间中的所述区域中时,也可以根据该区域来识别第一环境情形。
特别是,为了形成应用时间点的特征向量,优选可以以与在训练阶段的特征向量的形成中相同的方式,进行短期的时间上的平均(Mitteilung)(例如在几秒到几分钟的范围内)或者其它统计处理。
所描述的方法使得各个环境情形的定义能够具体地匹配于听力辅助设备佩戴者中的个人或者特殊的群体,此外,使得这种定义也可以由未经听力学或者科学训练的(有技术经验的)人员来进行,其中,对于环境情形的定义,仅需要听力系统(或者辅助性的陪同人员)的比较小的开销,因为这可以直接通过优选二维的显示空间的可视化来进行。
由此特别是可以满足小的用户群体的需求,对于这些用户群体来说,在制造商(或者其它解决方案提供商)方面,用于自动设置听力系统的环境情形的具体的定义将意味着过高的开销。由此,听力系统可以提供针对环境的分类器,与迄今为止已知的“定型的”环境情形的种类相比,这些分类器更有针对性地满足这些用户群体的需求,因为同样定义了诸如“在车内”、“在电视机前”的一般化的种类,因为听力系统的绝大多数用户都重复处于这种情形中。
此外,因为所述方法还适用于由未经听力学或者科学训练的有技术经验的人员使用,因此开创了如下可能性,即,不仅听力系统的制造商(例如助听器制造商),而且其它市场参与者或者用户可以自己进行定义,例如助听器声学专家等、特殊专业人群(例如牙医、音乐家、猎人)的陪同者或者各个有技术经验的用户也可以自己进行定义。因此,所述方法的使用变得与更大数量的用户相关,因为按照比例,通常很少的听力系统用户愿意进行全面的给定(Angaben)(例如在智能电话App中进行输入),相反,许多用户希望除了选择具体的功能以外进行尽可能少的给定,并且在其感到听力印象不舒服或者希望改善听力印象时,在万不得已时才进行输入。
就此而言,特别是也可以在训练阶段,由听力系统的第一用户进行第一环境情形的定义,而在应用阶段,由第二用户使用该定义。因此,第一用户可以提供其针对相应的特征向量定义的环境情形,以供其它用户使用。优选由在应用阶段使用听力系统的用户,来进行与第一环境情形相关的信号处理的设置的定义。
优选在训练阶段,通过用户输入,特别是根据听力系统的第一用户的日常例程的限定的情形,来相应地存储关于听力系统的当前使用情形的信息,其中,将关于使用情形的相应的信息与如下的特征向量和/或相关的代表向量连结(verknüpft),这些特征向量和/或相关的代表向量根据在特定使用情形期间考察的环境数据的值形成。在此,优选使用情形描述用户的日常生活中的特定情形、即例如在家、在车内(上班/回家的路上)、在办公室中、在职工食堂中、在运动中、在公园中等。也可以通过特征向量或者相关的代表向量的附加标记,在使用情形方面,将用户与第一环境情形相关联。
有利地,特别是借助屏幕将显示空间的至少一个部分区域可视化,并且在此显示代表向量的至少一个子集,其中,根据用户输入,特别是在可视化的代表向量的分组方面,定义显示空间中的第一区域。在此,屏幕特别是集成在听力系统的相应的辅助设备中,例如集成在与听力设备特别是可无线连接的智能电话、平板计算机等中。然后,用户可以直接在触摸屏上(在3D情况下通过相应的截面)看到二维或者必要时三维显示中的各个代表向量,并且相应地对其进行分组,以形成第一区域。
在此,特别是对于代表向量中的至少一些,至少根据第一用户的动作,将关于使用情形的相应的信息可视化。这可以通过相应的颜色显示或者通过在相应的代表向量上添加标签来进行。
有利地,至少在训练阶段,以如下方式将特征向量映射为相应地相关的代表向量,即,特征空间中的相应的至少三个特征向量的距离关系,由于映射至少近似地针对显示空间中的相关的三个代表向量的距离关系而得到保持。这特别是意味着,对于特征空间中的具有以下距离关系的相应的三个特征向量mv1、mv2、mv3来说:
|mv1–mv2|>|mv1–mv3|>|mv2–mv3|,
显示空间中的相关的代表向量rv1(关于mv1)、rv2(关于mv2)、rv3(关于mv3)满足以下距离关系:
|rv1–rv2|>|rv1–rv3|>|rv2–rv3|。
由此,将相对于在特征空间中所覆盖的整个区域仅稍微彼此不同的“类似的”特征向量的组,映射为相对于在显示空间中所覆盖的整个区域同样仅稍微彼此不同的“类似的”代表向量。
优选借助主成分分析(PCA)和/或局部线性嵌入(LLE)和/或等值线图映射(Isomap-Abbildung)和/或Sammon映射,和/或优选借助t-SNE算法,和/或优选借助自组织Kohonen网络,和/或优选借助UMAP映射,将特征向量映射为相应地相关的代表向量。所提到的方法满足所提到的距离关系方面的特性,并且可以有效地实现。
有利地,在应用阶段,在多个连续的应用时间点,分别确定最初的多个环境数据的值,并且根据环境数据的值,分别形成连续的应用时间点的相应的特征向量,其中,根据第一区域,并且根据所述连续的应用时间点的特征向量,特别是根据由所述特征向量构成的多边形或者由在显示空间中对应于所述特征向量的代表向量构成的多边形,来识别第一环境情形的存在。在此,特别是也可以借助机器学习来识别相关多边形外部的特征或者代表向量的如下区域,在这些区域中,对于应用时间点,相应的特征或者代表向量导致存在第一环境情形。
例如,始终使用(过去的应用时间点的)最新的五个代表向量,并且构造包括所有代表向量的多边形(一些或者所有代表向量或者其端点是多边形的拐角点)。当多边形的面积的至少一个可事先定义的百分比(例如80%)位于显示空间中的第一区域内时,才将听力系统与第一环境情形相关联,并且激活信号处理的相应的设置。由此可以避免可以归因于偶然的、但是对于环境来说可能不典型的发生的单个特征的单个“异常值”,尤其是导致环境情形方面的改变后的分类。
有利地,对于最初的多个环境数据,根据至少一个电声输入转换器、特别是麦克风的信号,确定声学环境数据,和/或根据特别是具有多维分辨率的加速度传感器和/或陀螺仪和/或GPS传感器的至少一个信号,确定与运动有关的环境数据。优选对于最初的多个环境数据,进一步根据GPS传感器的至少一个信号和/或WLAN连接,来确定与位置有关的环境数据,和/或借助EKG传感器和/或EEG传感器和/或PPG传感器和/或EMG传感器,来确定生物特征环境数据。用于产生生物特征环境数据的传感器特别是可以布置在设计为智能手表的辅助设备上。所提到的传感器特别适合用于尽可能全面地表征听力系统的环境情形。
在此,优选对于声学环境数据,在听力系统的第一或者第二用户的语音活动方面,和/或在电声输入转换器上风的出现方面和/或在噪声背景的频谱焦点方面,和/或在至少一个频带中的噪声背景方面,和/或在环境的声音信号的稳定性方面,和/或在自相关函数方面,和/或在给定调制频率(优选为4Hz,并且最大为10Hz)下的调制深度方面,和/或在语音活动、特别是用户自己的语音活动的使用方面,对至少一个电声输入转换器的信号进行分析。
有利地,作为考察时间点和/或应用时间点的环境数据的值,特别是关于相应的考察时间点和紧接在前的考察时间点之间的时间段,或者关于应用时间点和紧接在前的应用时间点之间的时间段,相应地确定相应的环境数据的平均值和/或方差和/或平均值通过率和/或值范围和/或中位数。借助这些数据,可以特别全面地表征听力系统的环境情形。
优选在考察时间点期间,借助至少一个电声输入转换器对环境的声音信号进行记录(Mittschnitt),并且将其与考察时间点的特征向量和相应的代表向量相关联,其中,根据用户输入,通过听力系统的至少一个输出转换器、特别是通过扬声器来再现记录。因此,用户可以附加地识别出,代表向量基于哪个具体的声学事件、即哪个噪声,并且使用这来定义第一区域。
有利地,根据声学环境数据,相应地在声学特征空间中形成考察时间点的特征向量的各个向量投影,其中,将声学特征空间的向量投影,相应地映射为最大三维、特别是二维的声学显示空间中的声学代表向量,其中,在声学显示空间中定义针对听力系统的第一环境情形的第二区域,并且其中,附加地根据声学显示空间的第二区域,特别是通过与应用时间点的特征向量到声学显示空间的映射的比较,来识别第一环境情形的存在。
听力系统的用户可能停留在如下环境中,在该环境中,特定的短噪声对用户产生干扰,从而对于这种环境,用户偏爱减弱这些噪声的信号处理设置。一个典型的示例是勺子碰到咖啡杯,或者类似地餐具发出的刺耳的声音。对此,存在不同的可能性,例如稍微减小对高频的放大,提高高频范围内的动态压缩,或者激活针对性地减弱突然出现的声音峰值的信号处理。
现在,当示例性地用户标记基于勺子碰到咖啡杯而突然出现的声音峰值的代表向量一次时,用户可以在可视化的显示中找到相应的代表向量的标记。预期该代表向量位于显示空间的如下区域中,即,使用情形“在家中”的代表向量位于该区域中,但是诸如“在办公室”或者“在车内”的使用情形中的代表向量不位于该区域中。现在,用户可以针对使用情形“在家中”确定所提到的改变中的一个,例如提高的高频范围内的动态压缩。在用户执行这一点之前,如下检查是有意义的,即,检查是否存在由于改变后的信号处理设置而同样听起来可能不一样的其它类似的噪声。
在此,用户可以受益于如下的相应的声学代表向量在声学显示空间中的显示,该声学代表向量是声学特征的相应的声学特征向量的投影,以便因此可以附加地或者也单独根据纯声学环境在声学显示空间中的显示,将第一环境情形与相应的第二区域相关联。
此外,优选可以将显示空间可视化,以相应地突出与声音事件相关的代表向量,并且同时、例如并排将具有相应的声学代表向量的声学显示空间可视化。
这种显示为用户提供如下优点,即,在声学代表向量的显示中,可以识别出与所标记的特征(“门铃”)非常类似的声音事件(即噪声),这是由于相对靠近相应的声学代表向量。在此,也可能可以在显示空间的同一区域中找到这两个声音事件(“勺子碰到咖啡杯”和“门铃”)的“完全的”代表向量(其附加地基于非声学数据),并且特别是将与同一使用情形(“在家中”)相关联。
现在,如果用户针对显示空间或者声学显示空间的第一、第二区域,因此针对如此定义的第一环境情形,进行信号处理的设置,由此例如使突然出现的听起来尖锐的音调(“咖啡杯”)减弱,那么由于声学显示空间,用户可以识别出同样使类似的噪声(“门铃”或者还有“烟雾探测器”)减弱,由此必要时用户可以做出可能不完全执行减弱的权衡决定,以便不错过这种噪声。
被证明进一步有利的是,附加地根据第一使用情形定义第一环境情形,并且针对第一环境情形,预先给定听力系统的信号处理的设置的第一值,并且根据第二使用情形定义第二环境情形,并且预先给定所述设置的相应的第二值,其中,特别是在声学显示空间中对应于第一环境情形的第二区域,与在声学显示空间中对应于第二环境情形的第二区域至少部分重叠,其中,根据第一或者第二使用情形的存在,来识别第一或者第二环境情形的存在,并且随后与听力系统的信号处理的第一或者第二值的预先给定对应,针对第一或者第二环境情形,设置听力系统的信号处理的第一或者第二值。
这特别是意味着,能够使得用户识别出类似、但是在不同的环境中、特别是在不同的使用情形下出现的噪声。根据使用情形,听力系统的用户可能针对特定的类似的噪声,偏爱不同的信号处理设置。
在此,作为示例提到猎人,猎人可能觉得报纸的沙沙声令人不舒服地响亮,而在狩猎时,他更想听到树叶的沙沙声。在训练阶段,将报纸的沙沙声标记为不舒服,但是不标记树叶的沙沙声。如果噪声虽然在声学上非常相似,但是还是可以区分开,那么用户可以定义不同的环境情形,因此定义信号处理的不同的设置。对不同的“沙沙声”进行不同的处理的愿望,例如可能在不同的使用情形“在家中”(例如阅读报纸)或者“工作/办公室”(同事翻阅文档)相对于“在户外”(在森林中的放松)中出现。
然后,特别是提供进行不同的处理的可能性,其方法是,在训练阶段,从助听器的所有传感器,即根据记录的音频信号(麦克风)和其它传感器信号,来确定映射到显示空间中的特征向量;根据记录的音频信号,来确定映射到声学显示空间中的声学特征向量。
用户可以根据标记的声学代表向量,识别出其希望改变后的信号处理(例如标记了“报纸的沙沙声”),但是通过声学显示空间,得到仍然存在非常类似的噪声(在此:树叶的沙沙声)的信息。在此,针对噪声“报纸的沙沙声”标记的声学代表向量,特别是可以形成声学代表向量的第一子组,因此形成声学显示空间中的第一区域,针对噪声“树叶的沙沙声”的另一个声学代表向量形成第二区域。
现在,用户可以在可视化中选择这种类似的噪声,随后在(“完全的”)显示空间中得到标记的代表向量,并且显示相应的在声学上类似的代表向量,并且可以根据其位置,识别出它们在那里是否位于可区分的区域中。然后,一个区域表示情形“在家中”,另一个区域例如表示“在森林中”。如果给出超出声学类似性的这种可区分性,那么针对性地调整针对一个环境情形(“在家中”)的信号处理,但是不调整针对另一个环境情形(“在森林中”)的信号处理。
优选使用如下听力系统,该听力系统具有听力设备、特别是助听器和/或听力辅助设备和/或头戴式耳机以及计算单元,并且特别是具有可视化装置。
在此,优选在训练阶段,由听力系统的第一用户,进行针对第一环境情形的第一区域的定义,并且将其存储在云服务器中,其中,对于应用阶段,由对于应用类似的、特别是在听力设备的结构方面相同的听力系统的第二用户,将所述定义从云服务器下载到听力系统中。由此,用户遇到的各个环境情形可以用于其它用户。
优选在应用阶段,通过用户输入,对第一区域的定义和/或对听力系统的信号处理的设置的至少一个值的预先给定进行校正,其中,随后在应用阶段,使用校正后的第一区域或者校正后的信号处理的设置的值。由此,用户一方面可以事后调整针对第一环境情形事先进行的信号处理的至少一个设置的定义,并且另一方面也可以事后进行例如噪声与环境情形的关联,或者可以事后消除这种关联。
有利地,相应地将每个特征向量映射为一维显示空间中的相关的代表向量,其中,根据代表向量的子组的端部点的空间分布,将显示空间中的第一区间,定义为针对听力系统的第一环境情形的第一区域。一维显示空间特别是可以对于比较小的数量的特征(例如六维的特征空间)是有利的。
本发明还涉及一种听力系统,其包括听力设备、特别是助听器、听力辅助设备或者头戴式耳机以及辅助设备,辅助设备具有计算单元、特别是智能电话或者平板计算机的处理器单元,其中,听力系统被配置为用于执行前面描述的方法。根据本发明的听力系统共享根据本发明的方法的优点。针对所述方法和其扩展方案给出的优点同样可以转用于听力系统。
优选听力系统包括可视化装置和/或用于用户输入的输入装置。在此,特别是,可视化装置和输入装置通过智能电话或者平板计算机的触摸屏来实现,智能电话或者平板计算机可以与听力设备连接,以进行传输数据。
在一个优选的设计方案中,听力系统包括如下部件:
-优选通过助听器给出的听力设备,特别是被配置为用于借助安装的至少一个麦克风记录音频信号,以及优选听力设备具有一个或者多个传感器、例如加速度传感器和/或陀螺仪,其记录“非声学的”环境数据。听力设备优选被配置为用于根据环境数据建立特征向量,并且特别是根据声学环境数据建立声学特征向量。
-辅助设备,其包括可视化装置和输入装置,并且优选通过智能电话或者平板计算机给出。辅助设备特别是包括用于确定环境数据(例如基于GPS的定位数据)的另外的传感器,其中,辅助设备优选被配置为用于借助无线连接将这些环境数据传输到听力设备,或者接收助听器的环境数据,并且建立所提到的特征向量。
此外,优选在听力系统中实现使得能够执行前面描述的方法的各个模块化的功能或者组成部分。这些模块化的功能特别是包括:
-软件输入模块,其提供用户接口,用户可以在用户接口上确定具体的环境情形,但是也可以确定使用情形,并且设置相应的标记(“在家中”、“在车内”、“在办公室中”、“在职工食堂中”、“看电视”、“骑摩托车”、“在音乐室中”),可以给出其现在处于所确定的使用情形中的一个中,或者离开该使用情形,可以确定具体的事件,并且设置标记(“牙医钻头”、“吸入装置”、“报纸的沙沙声”、“乐器演奏”),并且可以给出现在是否发生所确定的事件;
-降维模块,其将在训练阶段收集的特征向量映射到二维的(或者三维的或者一维的)显示空间中。在此,降维模块特别是可以以不同的变形方案实现,即通过实现t-SNE优化方法、作为UMAP、PCA或者作为Kohnen网络来实现,其在输入侧接收高维的特征向量,并且在输出侧输出二维的(或者三维的)代表向量。降维模块可以在听力设备上、在作为辅助设备的智能电话上或者在附加的计算机、例如PC/笔记本计算机上实现。
如果使用t-SNE优化方法,那么有利的是,优选在作为辅助设备的智能电话上或者在PC/笔记本计算机上实现降维模块,因为在那里提供高性能的处理器用于进行计算。Kohonen网络可以作为专用硬件在听力设备的ASIC上实现,或者可以在配置为Kohonen网络的听力设备的神经形态的芯片上实现,但是也可以配置为用于其它任务。Kohonen网络也可以在辅助设备上实现;
-特征编辑器,用于在显示器或者屏幕上的一定的面积中,作为点或者箭头,来显示特别是二维空间的向量,用于例如通过相应的染色,来突出与所示出的向量的标记对应的点,用于例如通过直接在点旁边的相应的文本字段,来对各个点的特性进行文本显示,并且用于并排显示两个特别是二维空间(相应的代表向量的显示空间和声学显示空间)。
在此,点的染色可以对应于对各个特征向量设置的标记。当标记给出使用情形或者环境情形时,染色相应地反映这一点。
一旦用户选择了声学显示空间中的一个点(代表向量),那么可以在视觉上突出“完全的”显示空间中的对应的点。用户因此可以识别出是否可以将两个彼此类似的声音事件、例如报纸的沙沙声和树叶的沙沙声(它们在声学特征空间中彼此靠近),与通过降维在包括其它环境特征的情况下彼此可区分的环境情形、例如“在家中”或者“在森林中”相关联,因为显示空间的对应的代表向量位于不同的区域中。特别是可以在辅助设备上实现特征编辑器。
-映射模块,其在应用阶段,将特征向量映射到二维或者三维的显示空间中。映射模块优选在听力设备本身中实现,但是也可以在辅助设备(优选作为智能电话给出)上实现,并且可以将所述映射的结果传输到听力设备。如果降维模块使用t-SNE方法,那么利用近似函数
附图说明
下面,根据附图详细说明本发明的实施例。在此:
图1示意性地以框图示出了用于与环境有关地运行听力系统的方法。
具体执行方式
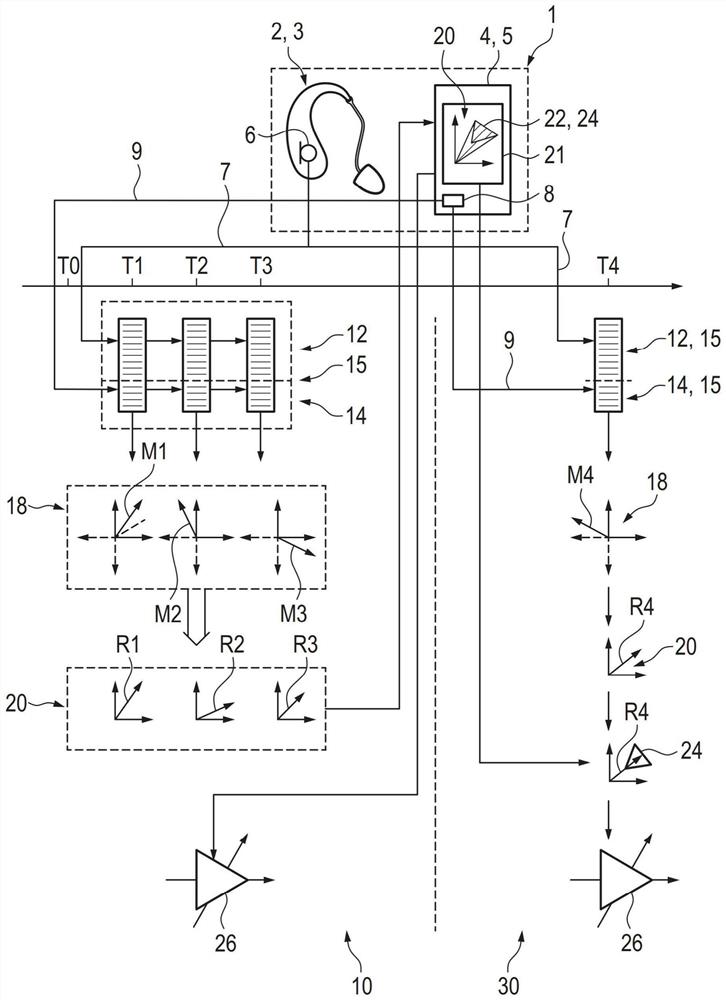
图1示意性地以框图示出了用于与环境有关地听力系统1的方法,其中,在此,听力系统由设计为助听器2的听力设备3以及设计为智能电话4的辅助设备5形成。听力设备3具有至少一个电声输入转换器6,其在此设计为麦克风,并且根据环境声音产生音频信号7。此外,听力设备3具有产生附加的传感器信号9的另外的传感器8。在此,传感器8例如可以包括加速度传感器,或者也可以包括温度传感器。
现在,在所述方法的训练阶段10中,分别根据音频信号7和传感器信号9,针对多个考察时间点T1、T2、T3确定环境数据。在此,这以如下方式来进行,即,首先根据音频信号7连续产生声学环境数据12。声学环境数据12在此包括:4Hz调制;开始平均值(Onset-Mean);自相关函数;噪声背景的低频和中频以及噪声背景的质心(Zentroid)的水平;稳定性;风活动;宽带最大水平;自身语音活动。同样根据传感器信号9连续产生与运动有关的环境数据14,在此,环境数据14包括所测量的三个空间方向上的瞬时加速度。
其它类型的声学环境数据12和/或与运动有关的环境数据14或者其它的特别是与位置有关的环境数据和/或生物特征环境数据,可以一般地作为环境数据15包括在内,例如磁场传感器、其它的手机和/或智能手表传感器、陀螺仪、脉冲测量、PPG测量(光体积描记图)、心电图(EKG)、通过测量心跳来识别压力及其变形方案、光传感器、气压计、倾听努力或者倾听活动(例如通过借助EEG测量而产生的“听觉注意”)、通过肌肉活动(EMG)对眼睛或者头部运动的测量、关于GPS的位置信息、WLAN信息、针对当前位置或者区域的地理定界(Geo-Fencing)或者蓝牙信标。
对于声学环境数据12(在此为十种不同类型的数据)和(在此为)三个与运动有关的环境数据14,相应地针对两个考察时间点T1、T2、T3之间的时间段进行缓冲16(对于考察时间点T1的考察,从起始时间点T0开始缓冲所提到的信号)。随后,针对每个单独的类型的声学环境数据12和与运动有关的环境数据14,分别形成平均值Mn、方差Var和平均值通过率MCR。在此,在两个考察时间点T1、T2、T3之间缓冲的时间段内,所提到的各个声学环境数据12和与运动有关的环境数据14的统计参量Mn、Var、MCR,针对缓冲时间段结束时的考察时间点T1、T2、T3,分别形成环境特征16,并且分别映射为高维度的特征空间18中的高维度特征向量M1、M2、M3。在此,仅通过针对各个特征向量M1、M2、M3的特征空间18的图形上的轴的数量,示出了由十个声学环境数据和三个与运动有关的环境数据构成的针对相应的三个统计特征的高的维度、例如39D。
现在,将特征向量M1、M2、M3中的每一个,从特征空间18映射为二维的显示空间20中的相应的代表向量R1、R2、R3。在此,例如借助t-SNE优化方法(t-DistributedStochastic Neighbor Embedding,t-分布随机邻居嵌入)来进行映射。
下面,简短地描述优化方法的过程(例如参见“Visualizing Data using t-SNE”,2008,Laurens van der Maaten and Geoffrey Hinton)。
所谓的困惑参数(Perplexity-Paramater)定义特征向量的有效邻居的数量,即,困惑参数确定多少个邻居对二维的显示空间20中的相应的代表向量的最终位置有影响(在此,例如可以将该参数的值设置为值50,或者设置为特征向量的数量的1/100的数量级)。之后,针对所有高维特征向量对,计算一次将两个相关的特征向量识别为高维度特征空间中的最近的邻居的概率测度(Wahrscheinlichkeitsmaβe)。这映射初始情形。
对于二维的显示空间,将随机高斯分布的随机数Y假设为初始值。之后,在各个迭代中计算Y中的当前的相似度关系。为了优化相似度关系的映射,现在,根据Kullback-Leibler散度(Divergenz)来确定特征空间与显示空间之间的相似度。借助所述散度的梯度,显示空间中的代表向量(或者其端点)在T次迭代内移动。
算法的一种可能的表示是:
-高维特征向量X={x
-
-
-结果:二维的显示空间Y={y
-方法开始:
-计算高维空间中的所有特征向量对p
-设置
-“随机抽取”n个二维的高斯分布的随机数,用于初始化Y
-对到显示空间中的映射r进行优化:
ο对于t=1到T,优化计数循环:
·计算二维空间中的当前的概率测度:
·测量X和Y之间的相似度(Kullback-Leibler散度):
·计算梯度:
·移动二维的代表向量:
ο优化结束
-方法结束
因此,参考本方法,通过上面描述的映射规则,由特征空间18的特征向量M1、M2、M2产生二维显示空间20中的代表向量R1、R2、R3。
听力系统1的用户现在可以在他的辅助设备5上(在智能电话4的屏幕21上)对显示空间20进行显示,并且例如将相关的区域22定义为第一区域24,第一区域24在其应用听力系统1时,对应于具体的第一环境情形25。现在,用户可以将听力设备3中的音频信号7的信号处理的具体的设置26(例如频带增益值和参数和/或压缩值和参数,或者噪声抑制的控制参数等)与所述第一区域24相关联。利用信号处理的设置26与第一区域24的关联(因此与在此的第一环境情形25的关联,第一环境情形25例如通过各个特征向量M1、M2、M3中的环境数据15的值来表征),针对特定的环境情形as的训练阶段10可以视为结束。在此,优选针对不同的环境情形进行多个训练阶段10。
在应用阶段30中,现在,根据听力设备3的音频信号7,并且根据传感器信号9,在应用时间点T4,考察与在训练阶段中相同的环境数据15,并且由其以相同的方式,根据在应用时间点T4确定的值,以相应的方式形成高维度的特征空间18中的特征向量M4。在此,这些值例如可以由在应用时间点T4之前的短的时间段(例如60秒等)内考察的声学的和与运动有关的数据12、14的平均值Mn、方差Var和平均值通过率MCR形成。
现在,将应用时间点T4的特征向量M4映射为显示空间20中的代表向量R4。
因为在本示例的训练阶段10中使用的用于将特征空间18的特征向量M1、M2、M3映射为显示空间20中的代表向量R1、R2、R3的t-SNE方法,是需要针对所使用的所有特征向量的知识的优化方法,因此在应用阶段30中,借助近似映射(例如所谓的“out-of-sampleextension(样本外扩展)”,即OOS核心)来进行相应的映射。这可以通过回归(Regression)来进行,借助回归,根据到显示空间20的相应的代表向量的特征空间18的一定数量的特征向量(例如特征向量的80%)对映射进行“学习”,并且使用剩余的特征向量(于是即例如20%),来“测试”产生的映射的质量。然后,利用“学习向量”的映射,即利用学习映射所使用的到相应的代表向量的特征向量,可以确定核心函数,核心函数获得其各自的空间(特征空间和显示空间)中的所述特征向量和代表向量之间的局部的距离关系。因此,通过获得已知的“学习向量”之间的局部的距离关系,可以将特征空间18的新的未知的特征向量,映射为显示空间20中的相关的代表向量。
关于此的详细说明例如可以在“Out-of-Sample Kernel and Extensions forNonparametric Dimensionality Reduction”,Andrej Gisbrecht,Wouter Lueks,BassamMokbel und Barbara Hammer,ESANN 2012 proceedings,European Symposium onArtificial Neural Networks,Computational Intelligence and Machine Learning,Brügge(Belgien),25.-27.April 2012中,以及在“Parametric nonlinear dimensionalityreduction using kernel t-SNE”,Andrej Gisbrecht,Alexander Schulz und BarbaraHammer,Neurocomputing,Vol.147,71–82,Januar 2015中找到。
现在,如果对于应用时间T4,如所描述的那样确定的代表向量R4位于第一区域24中,那么可以识别出,对于听力系统1,存在第一环境情形25,并且相应地利用音频信号26的信号处理的设置26运行听力设备3,并且将先前定义的增益值和参数和/或压缩值和参数或者噪声抑制的控制参数应用于音频信号7。
虽然在细节上通过优选的实施例详细说明和描述了本发明,但是本发明不局限于该实施例。本领域技术人员可以从中推导出其它变形,而不脱离本发明的保护范围。
附图标记列表
1 听力系统
2 助听器
3 听力设备
4 智能电话
5 辅助设备
6 输入转换器
7 音频信号
8 传感器
9 传感器信号
10 训练阶段
12 声学环境数据
14 与运动有关的环境数据
16 缓冲
18 特征空间
20 显示空间
21 屏幕
22 区域
24 第一区域
25 第一环境情形
26 (信号处理的)设置
30 应用阶段
M1、M2、M3 (训练阶段的)特征向量
M4 (应用阶段的)特征向量
MCR 平均值通过率
Mn 平均值
R1、R2、R3 (训练阶段的)代表向量
R4 (应用阶段的)代表向量
T0 开始时间点
T1、T2、T3 考察时间点
T4 应用时间点
Var 方差
- 用于运行听力系统的方法、听力系统、听力装置
- 用于听力系统的与环境有关的运行的方法