一种基于生成对抗网络的图像处理方法、系统和介质
文献发布时间:2023-06-19 11:22:42
技术领域
本发明涉及图像处理领域,尤其是涉及一种基于生成对抗网络的图像处理方法、系统和介质。
背景技术
宽光谱相机依赖于红外截止滤光片过滤掉可见光中的红外成分,使拍摄得到的图像颜色能够符合人眼的视觉习惯。如果去掉了这一物理硬件会导致成像出现颜色畸变,呈现一种不正常的偏红色调。普通CCD/CMOS相机只对较小范围内特定波长的电磁波敏感,而宽光谱相机是对某个较大波谱范围光线敏感的相机。相对于普通可见光相机来说,宽光谱相机能感应到的波长范围更大。但是,因为其感光范围大,所以可见光宽光谱相机对红外波段的光线也会有所感应。因此使用可见光宽光谱相机采集的图像中,R/G/B三通道都会混叠部分红外信号,这会导致照片呈现一种偏红色调的不正常的颜色状态。为了校正这种颜色畸变,可以通过在宽光谱相机前端增加红外截止滤光片来解决这一问题,但这往往需要硬件上的支持。
截止滤光片是一种特殊的滤光片,它与普通的滤光片不同之处在于它是从复合光中过滤掉不需要的波段,而仅仅保留所需要的波段。因为波段可分为长波和短波,所以截止滤光片也可分为长波截止滤光片和短波截止滤光片。其中长波截止滤光片是指保留长波段的光,过滤掉所有短波段的光;短波截止滤光片则是与其相反,保留短波段的光,过滤掉长波段的光。按照滤光片作用机制的不同又可将其分为三类:吸收型截止滤光片、薄膜干涉型截止滤光片,以及吸收与干涉组合型截止滤光片。红外截止滤光片是一种吸收型截止滤光片,它是由滤光片薄膜和衬底两部分组成,其利用的是精密光学镀膜技术的一种光学膜,使其在光学基片上能够交替镀上高低折射率。它的功能主要是使得可见光(400-630nm)能够穿过,近红外光(700-1100nm)截止,消除红外光线对CCD/CMOS成像的影响。主要应用于智能手机的摄像头、电脑内置摄像头、数码相机以及汽车的行车记录仪等领域。在各种数码成像设备中加入红外截止滤光片,能够使得拍摄出来的图像更符合人眼的视觉习惯。
但是,使用滤光片时,相机需要针对滤光片的安装与拆卸进行专业设计,这无疑增加了设计和生产成本;此外,滤光片在使用过程中,一般需要对其滤光波长进行周期检定,这无疑增加了相机的维护成本。
卷积神经网络,自其提出以来就是计算机视觉领域的核心算法之一,它是一种有深度结构并且包含卷积运算的前馈神经网络。它的神经元可以对周围一定范围内的神经元产生作用,在图像处理方面有非常显著的效果。在此算法提出之前,在神经网络中首先需要做的就是复杂的预处理,对特征的提取和特征的选择,然后再将其作为神经网络的输入。但是CNN则不同,它是一种端到端网络,可以减掉前期工作中对图像的预处理部分,将数据集中的原始图像作为输入,并且能够自动进行特征的学习,正是因为这种网络的便利性,使其能够得到广泛的应用。
1989年,LeCun等人提了应用与图像分类领域的LeNet网络,并且在其网络模型中第一次提出了“卷积”这个词,卷积神经网络也因此得名。他们在所提出的随机梯度下降算法也得到了大多数人的认可,在后面的深度学习中得到了广泛的使用。2006年,Hinton等人提出一种逐层学习和参数微调的方法,完善了深度学习的理论知识,从此卷积神经网络进入了飞速发展的时期。例如AleNet,ZFNet,VGGNet,GoogleNet,ResNet这些现在广为人知的网络模型纷纷被提出,并被广泛应用于各种图像处理问题的研究。
卷积神经网络的基本结构包括输入层,卷积层,激活层,池化层,全连接层和输出层。每一层的作用和形式都是不一样的,由输入到输出逐层提取数据的特征,在低层中学习数据的局部特征,高层中学习的是数据的全局特征,随着网络层次由低到高,网络所学习到的特征就会越来越抽象。不同的卷积神经网络模型具有不同的层级结构,所学习到的特征也是不一样的。本节研究了卷积神经网络的基本结构。
输入层
输入层顾名思义其主要作用就是将数据进行输入,但是并不仅限于此。还需要对输入的数据进行预处理工作,其中包含有图像的增强,去均值,归一化等。数据增强的目的是为了提高输入数据的质量,丰富数据的信息量,包含裁剪、旋转、平移等多种不同的方法。去均值简单来说就是将输入数据的维度中心化为零,这样做目的是将输入数据的中心回到坐标原点的位置。数据归一化则是将不同维度的数据取值都在同一个范围,减少因为数据取值范围不同对网络模型的干扰。
卷积层
卷积层是卷积神经网络的核心,是其最重要的结构之一,它的功能是使用卷积操作对输入的数据进行特征的提取,增加输入数据的特征,并且抑制噪声的产生。卷积层中的核心则是卷积核,不同的卷积核可以理解为提取不同的特征图像,输入一个二维图像,经过卷积运算得到多个二维特征图像。卷积核是由多个类似一般神经网络的神经元构成的,特征图中矩阵元素个数相当于卷积核中神经元个数,每一个神经元都有对应的权重和偏置。在使用卷积核进行卷积计算时,每一个神经元会与前一层中一定范围内的多个神经元连接,这个范围就是由卷积核的大小来确定的,这个连接的范围也被称为局部感受野。为了区别于全连接网络,降低神经网络的参数量,卷积层采用了一种名为参数共享的机制,其本质就是将每个神经元连接数据的权值固定,使得每个神经元只关注一个特征,因此卷积核也被称为滤波器。
激活层
激活层的本质就是调用激活函数,将卷积层的输出结果进行非线性映射,防止其线性输入线性输出,从而达到描述复杂特征的目的。使用较频繁的激活函数有Sigmoid函数、Tanh(双曲正切)函数、ReLu(Rectified Linear Unit)函数等,具体的函数形式及函数图像将在3.2节中进行描述。
池化层
池化层通常设置在连续的卷积层之间,对输出的数据特征图进行特征的选择和过滤,目的是为了压缩数据以及参数的数量,减少网络过拟合的概率。池化层依据的是图像特征的尺寸不变性,其方式也是多种多样的,例如最大池化和平均池化。最大池化是将相邻的区域中的最大值作为该池化层的输出,平均池化也是选择相邻的区域,但不同之处是将该区域中的平均值作为该层的输出。选择不同的池化方式对不同的网络模型的影响是很大的,有时候甚至会出现相差很大的训练效果。
全连接层
全连接层通常处于卷积神经网络的倒数第二层。该层的每一个神经元都与上层中的所有神经元连接,通常会导致参数量过大。
输出层
输出层是卷积神经网络的最后一层,不同的网络模型都会依据其目的的不同在这一层中对数据做不同的处理。
Goodfellow I J等学者在2014年提出了一种全新的构建网络模型的方法——生成对抗网络(GAN)。生成对抗网络的灵感来自于博弈论中的二人零和博弈(Two-playerZero-sum Game)。这种思想就是一种对抗的雏形。因为在二者博弈的过程中,必须要保证双方的收益和损失之和为零,所以博弈双方存在一种相互竞争的关系,对方的收益将会导致己方的损失,反之亦然。GANs模型就是博弈的具体表现,由生成器模型(Generator)和判别器模型(Discriminator)扮演博弈的双方。二者的任务也是截然相反的,生成器模型的任务是生成看起来接近所输入的原始数据的图像,让判别器无法做出正确判断其是由生成器生成的还是实验中所输入的图像。判别器的任务则是正确的判断出所给图像的来源,是由数据集中输入的还是生成器所伪造的。
发明内容
本发明的目的在于提供一种基于基于生成对抗网络的图像处理方案,以解决现有技术中存在的上述技术问题。
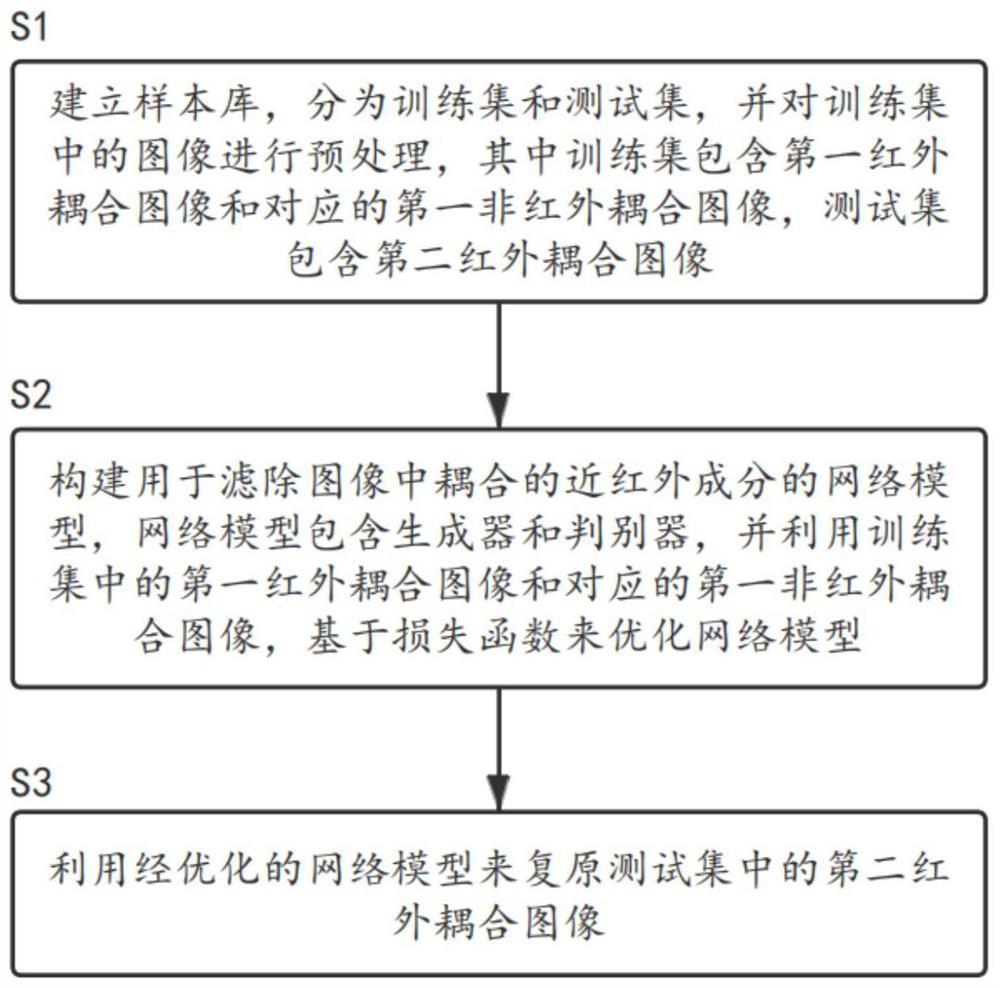
本发明第一方面提供了一种基于生成对抗网络的图像处理方法,所述方法用于滤除所述图像中耦合的近红外成分,所述图像处理方法包括:步骤S1、建立样本库,分为训练集和测试集,并对所述训练集中的图像进行预处理,其中所述训练集包含第一红外耦合图像和对应的第一非红外耦合图像,所述测试集包含第二红外耦合图像;步骤S2、构建用于滤除所述图像中耦合的近红外成分的网络模型,所述网络模型包含生成器和判别器,并利用所述训练集中的所述第一红外耦合图像和对应的第一非红外耦合图像,基于损失函数来优化所述网络模型;以及步骤S3、利用经优化的所述网络模型来复原所述测试集中的所述第二红外耦合图像。
根据本发明第一方面提供的方法,在步骤S1中,所述预处理包括:对所述第一红外耦合图像和对应的第一非红外耦合图像进行随机剪裁,并将其类型转化为张量,经归一化处理后设置其打开方式为RGB格式。
根据本发明第一方面提供的方法,所述生成器对输入所述网络模型的图像进行多次下采样、卷积、上采样以加深网络层数,所述判别器由卷积层而非全连接层构成;所述损失函数包括0-1损失函数、均方差损失函数、熵交叉损失函数以及合页损失函数中的一种或多种;在所述步骤S2中,优化所述网络模型包括:利用所述损失函数计算所述生成器损失和/或内容损失,并通过最小化所述生成器损失和/或内容损失来优化所述网络模型。
根据本发明第一方面提供的方法,在步骤S2中,以小批量且梯度下降的方式加载所述第一红外耦合图像和所述第一非红外耦合图像,以优化所述网络模型。
本发明第二方面提供了一种生成对抗网络的图像处理系统,所述系统用于滤除所述图像中耦合的近红外成分,所述图像处理系统包括:第一模块,被配置为建立样本库,分为训练集和测试集,并对所述训练集中的图像进行预处理,其中所述训练集包含第一红外耦合图像和对应的第一非红外耦合图像,所述测试集包含第二红外耦合图像;第二模块,被配置为构建用于滤除所述图像中耦合的近红外成分的网络模型,所述网络模型包含生成器和判别器,并利用所述训练集中的所述第一红外耦合图像和对应的第一非红外耦合图像,基于损失函数来优化所述网络模型;以及第三模块,被配置为利用经优化的所述网络模型来复原所述测试集中的所述第二红外耦合图像。
根据本发明第二方面提供的系统,所述第一模块具体被配置为,对所述第一红外耦合图像和对应的第一非红外耦合图像进行随机剪裁,并将其类型转化为张量,经归一化处理后设置其打开方式为RGB格式。
根据本发明第二方面提供的系统,所述生成器对输入所述网络模型的图像进行多次下采样、卷积、上采样以加深网络层数,所述判别器由卷积层而非全连接层构成;所述损失函数包括0-1损失函数、均方差损失函数、熵交叉损失函数以及合页损失函数中的一种或多种;所述第二模块具体被配置为:利用所述损失函数计算所述生成器损失和/或内容损失,并通过最小化所述生成器损失和/或内容损失来优化所述网络模型。
根据本发明第二方面提供的系统,所述第二模块被配置为,以小批量且梯度下降的方式加载所述第一红外耦合图像和所述第一非红外耦合图像,以优化所述网络模型。
本发明第三方面提供了一种存储有指令的非暂时性计算机可读介质,当所述指令由处理器执行时,执行根据本发明第一方面的基于生成对抗网络的图像处理方法中的步骤。
综上,实现了红外耦合图像复原为正常图像的深度神经网络设计。红外耦合图像复原方法是图像风格转换的一种特例,而深度神经网络能够提升该方法的训练效果。生成器的损失函数分为感知损失和对抗损失两部分,通过卷积神经网络的处理,能够对输入的红外耦合和图像及正常图像进行特征的提取,用于计算生成器的感知损失;在对抗损失的计算中使用WGAN模型且加入了梯度惩罚,提高训练的稳定性。二者的结合使得生成器生成的图像更贴近人眼的视觉习惯,提升的模型的效果。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为根据本发明实施例的基于生成对抗网络的图像处理方法的流程的示意图;
图2a为根据本发明实施例的对抗损失曲线图;
图2b为根据本发明实施例的感知损失曲线图;
图2c为根据本发明实施例的判别器损失曲线图;
图3a-3b为根据本发明实施例的训练实验截图;
图3c为根据本发明实施例的测试实验截图;
图3d、3f为根据本发明实施例的红外耦合图像;
图3e、3g为根据本发明实施例的复原后的图像;以及
图4为根据本发明实施例的基于生成对抗网络的图像处理系统的结构图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明第一方面提供了一种基于生成对抗网络的图像处理方法,所述方法用于滤除所述图像中耦合的近红外成分。图1为根据本发明实施例的基于生成对抗网络的图像处理方法的流程的示意图,如图1所示,所述图像处理方法包括:步骤S1、建立样本库,分为训练集和测试集,并对所述训练集中的图像进行预处理,其中所述训练集包含第一红外耦合图像和对应的第一非红外耦合图像,所述测试集包含第二红外耦合图像;步骤S2、构建用于滤除所述图像中耦合的近红外成分的网络模型,所述网络模型包含生成器和判别器,并利用所述训练集中的所述第一红外耦合图像和对应的第一非红外耦合图像,基于损失函数来优化所述网络模型;以及步骤S3、利用经优化的所述网络模型来复原所述测试集中的所述第二红外耦合图像。
在步骤S1,建立样本库,分为训练集和测试集,并对所述训练集中的图像进行预处理,其中所述训练集包含第一红外耦合图像和对应的第一非红外耦合图像,所述测试集包含第二红外耦合图像。所述预处理包括:对所述第一红外耦合图像和对应的第一非红外耦合图像进行随机剪裁,并将其类型转化为张量,经归一化处理后设置其打开方式为RGB格式。
使用可见光宽光谱相机在学校范围内采集了一万张自然场景下的正常图像和两万张自然场景下的红外耦合图像。这两万张红外耦合图像包括一万张白天的图像及一万张夜晚的图像,甄选正常图像中的9500张和红外耦合图像中的9500张(7000张白天,2500张夜晚)作为训练集,并且在剩余的红外耦合图像中甄选2000张图像作为测试集。
对图像进行预处理时,因为使用的是卷积神经网络,所以只需要对图像进行简单的预处理。首先需要构建两个数据包,分别命名为trainA和trainB,trainA中保存红外耦合图像,trainB中保存正常图像。图像处理时,首先使用python的包torchvision中的RandomCrop函数对图像进行随机裁剪为256×256大小,将其类型转化为张量,然后使用transforms.Normalize函数对图像进行归一化,其函数所使用的公式为:channel=(channel-mean)/std。在加载数据时只需要将图像的打开方式设置为RGB格式即可,到此数据集的构建完成。
在步骤S2,构建用于滤除所述图像中耦合的近红外成分的网络模型,所述网络模型包含生成器和判别器,并利用所述训练集中的所述第一红外耦合图像和对应的第一非红外耦合图像,基于损失函数来优化所述网络模型。所述生成器对输入所述网络模型的图像进行多次下采样、卷积、上采样以加深网络层数,所述判别器由卷积层而非全连接层构成;所述损失函数包括0-1损失函数、均方差损失函数、熵交叉损失函数以及合页损失函数中的一种或多种。在所述步骤S2中,优化所述网络模型包括:利用所述损失函数计算所述生成器损失和/或内容损失,并通过最小化所述生成器损失和/或内容损失来优化所述网络模型。
所述网络模型是基于DeblurGan及VGG19的基础上搭建的。生成器网络都是由卷积层和标准层以及激活层组成。其主要组成部分可分为下采样,残差块和上采样。
下采样
其本质就是对图像进行缩小操作,其原理就是对一幅W×H的图像,对其进行N倍的缩小操作,即是对(W/H)且(H/N),就可以得到缩小后的对应分辨率的图像,但是N必须为W和H的公约数。
上采样
其本质就是对图像进行放大操作,使其可以在更高分辨率的设备上也能呈现清晰图像。本课题中采取的算法是nearest算法(最近邻插值法),将图像放大为原图像的两倍,主要目的是恢复图像的大小,使其与输入相同。此处并没有使用原模型中的转置卷积作为上采样,使用转置卷积会导致训练结果有严重的棋盘效应(网格效应),将其改为上采样加卷积就可以大大减少棋盘效应对图像的影响。
在生成器模型中主要可分为:第一个卷积块卷积核大小为7×7,步长设为1,目的是保持输入数据尺寸大小不变。将上一步中得到的输出进行两次下采样操作,具体实现为两个卷积块,卷积核大小为3×3,其步长设为2。9个残差块。每个残差块中都带有两次卷积操作,卷积核大小为3×3,步长为1,但是不对图像大小做改变,两次卷积过程中使用了两次Dropout策略,防止模型过拟合。对图像进行两次上采样,目的是恢复图像的大小,使得输入图像与输出图像尺寸保持一致。最后进行一次卷积操作,卷积核大小为7×7,步长为1。
采用这种方式的生成器可以加深网络的层数,表现出样本分布中更好的潜在特征。本公开所使用的另一个模型是VGG19,该模型的使用是在构建生成器网络的loss函数中。此处使用互联网上训练好的VGG-19,其总体结构可分为5个模块。但是该网络模型中每一个模块中使用的卷积核大小(5×5)和最大池化尺寸(2×2)是相同的。
所述判别器模型与PatchGan大致相同。PatchGan模型也被称为马尔科夫判别器,是一种重要的判别器模型。因为CNN的分类模型是多种多样的,大多数判别器网络都是引入了全连接层,然后将最终的结点作为输出。但马尔科夫判别器不是这样做的,其网络结构全部由卷积层组成,并没有引入全连接层,输出结果也并不是一个结点,而是一个矩阵,最后将矩阵的均值转化为True/false输出。其判别器思想就是将原图分解为等大小的块,矩阵中的每一个输出对应着原图的一个块(patch)。其模型对保持图像的高分辨率、清晰化有很大作用。
判别器的模型使用的激活函数都为LeakyReLU,总体上可概括为三个卷积块:卷积核大小为4×4,步长设为2,目的是对图像进行下采样卷积操作;卷积核大小为4×4,步长设为2,同样对其进行下采样卷积操作,连续两次,然后卷积核大小不变,将步长设为1;卷积核大小为4×4,步长设为1,目的是将通道压缩为1。
损失函数(loss function)是用于判断网络模型的输出与输入的真实值之间的差距的函数。通常情况下,损失函数的值越小,就代表该网络模型的训练效果越好,但是也不能完全确定,其判断因素还需要比较输出数据的质量。在深度学习的过程中,不同的算法都有不同的想要达到的目标,具体表示就是一个目标函数,而训练中对算法的求解过程对应的就是目标函数的优化。
0-1损失
是一种最为简单的loss函数,类似于二分类函数,其结果要么为1要么为0。如果得到的输出与真实类别不用,则loss为1,若得到的输出与真实类别相同,则loss为0。其具体表现形式为:
均方差损失函数也是一种较为常用的损失函数。其思想是预测结果与真实结果的距离最小。其表现形式如下:
y
交叉熵损失的计算比较特殊,一般将其分为两个部分进行理解:
第一种,交叉熵损失是
基于softmax计算来的,softmax将网络最后输出z通过指数转变为概率形式,计算公式如下:
其中,分子
第二种,交叉熵损失
公式定义如下:
其中,y
合页损失函数也是一种较为常见的损失函数,其思想是给不同的分类结果不同的分数,目的是让正确的分类得分比其他分类的得分都高,为了将其在数学上表达出来,一般是设置一个阈值,若正确分类得分比其他分类得分高于这个阈值就认为该损失函数比较优秀。其计算公式为:
其中Z
关于生成器损失,WGAN采用了Earth-Mover距离(EM距离)作为loss,它是在最优路径规划下的最小消耗,计算的是在联合分布γ下,样本对距离的期望值,公式如下:
E(x,y)~γ[||x-y||] (7)
与原始的GAN的loss形式相比,其实WGAN就是生成器和判别器的loss不取log。wassertein距离相比KL散度和JS散度的优势在于,即使两个分布的支撑集没有重叠或者重叠非常少,仍然能反映两个分布的远近。而JS散度在此情况下是常量,KL散度可能无意义。
Gulrajani等提出的添加梯度惩罚项,以解决权重修改导致的优化问题。权重修改会迫使神经网络学习学习更简单的相似达到最优数据分布,导致结果质量不高。同时如果WGAN超参数设置不合理,权重修改可能会出现梯度消失或梯度爆炸的问题。当GAN的博弈达到一个局部平衡态,就会出现模型崩溃的问题。而且判别网络D在这种状态下产生的梯度是非常陡的。一般来说,使用梯度惩罚机制可以帮助避免这种状态的产生,极大增强GAN的稳定性,尽可能减少模型崩溃问题的产生。WGAN-GP实现了在多种GAN结构上稳定训练,且几乎不需要调整超参数。本课题使用的模型就是WGAN-GP,对抗的计算式为:
内容损失是评估生成的正常图像和ground truth(正确的数据标注)之间的差距。两个常用的选择是L1(也称为MAE,Mean Absolute Error)损失,和L2(也称为MSE,MeanSquared Error)损失。L1损失是以绝对误差作为距离,公式如下:
由于L1loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束。L1loss的最大问题是梯度在零点不平滑,导致会跳过极小值。L2loss,也可称为欧氏距离,它以误差的平方和作为距离,公式如下:
L2loss也常常作为正则项,但当预测值与目标值相差很大时,梯度容易爆炸。
本实施例还可以采取感知损失,它本质上就是一个L2损失,用VGG模型对目标图片与输出图片做特征提取,得到两个特征数据,但它计算的是CNN生成的feature map和正确数据标注的feature map之间的距离。感知loss采用图像像素进行求差时所计算的空间不再是图像空间。它有着与L2loss同样的形式,只是计算的空间被转换到了特征空间。定义如下:
其中,φ
图2a为根据本发明实施例的对抗损失曲线图;图2b为根据本发明实施例的感知损失曲线图;图2c为根据本发明实施例的判别器损失曲线图。
此外,在一些实施例中,关于评价标准,(Peak Signal to Noise Ratio)是目前来说使用频率最高,应用范围最广的评价图像质量的测量方法。但是其分数并不能完全代表图像质量的高低,有实验证明PSNR的分数与PSNR人眼看到的图像画质是有一定差距的,PSNR得分较高的图像人眼看起来反而不如PSNR得分较低的图像视觉效果好。本课题所采用的评价标准就是峰值信噪比。
PSNR的计算公式为:
MAX
在一些实施例中,在步骤S2中,以小批量且梯度下降的方式加载所述第一红外耦合图像和所述第一非红外耦合图像,以优化所述网络模型。关于参数优化所采用的小批量梯度下降法,训练出一个高质量的神经网络模型,一般都需要大量的高质量的训练集作为支撑。也正是因为训练集的数量比较大,如果一次性加载所有数据那么在计算每一次梯度下降时都需要考虑整个数据集的梯度,其所需要的GPU资源是无法承受的。而且在这种大规模的数据集中部分数据是比较接近的,没有必要浪费如此庞大的计算资源,在整个训练集上进行梯度的计算。所以,通常情况下目前的网络训练都是采用小批量梯度下降法。选择小批量梯度算法的目的就是为了减少所需要的计算机资源,避免资源的浪费。但是在小批量梯度下降法中有一个起决定作用的超参数——batch size。这个数值决定网络中每一次选取的数据多少,通常来说不会影响随机梯度的期望,但是对方差会产生不可忽略的影响。选择的batch size的值越大,随机梯度的方差就会越小,训练效果比较稳定,此时可以适当增大学习率,提高训练效率。反之,batch size较小的情况下,为了模型能够收敛,就需要将学习率设为一个较小的值。使用batch size为DeblurGan模型的默认值1,前150个epoch学习率为默认值0.0001,后120个epoch学习率会逐渐衰减,直到为0。
关于学习率优化算法的种类:(1)Adagrad(Adaptive Gradient)算法,其使用的就是L2范数的思想,也就是常用的L2距离,该算法在每次执行时都会动态的更新每个参数的学习率,使该模型能够得到更好的效果。该算法在总体趋势上看学习率是随着迭代次数的增加而逐渐减少的。但是这个算法有着很大的缺点,当整个网络经过多次的迭代后没有找到最优点时,在后续的迭代中找到最优点的机率也非常小。(2)RMSprop算法,也是一种自适应学习率的算法,但其与Adagrad不同之处在于可以避免学习率单调下降,而引发找不到最优点的问题。该算法在网络模型迭代的过程中,学习率会随着梯度的变化而动态的增大或者减小。(3)AdaDalta算法也是对Adagrad算法的一种优化。该算法与RMSprop算法相似,都能够动态的调整学习率增大或减小。但是该算法是以梯度平方的指数衰减移动平均值作为调整学习率大小的依据。相较于RMSprop算法能控制学习率的波动较为平稳。(4)动量法,这是一种与前面的几种优化算法截然不同的算法,它适用于课题选取的batch size比较小的情况。因为batch size设置值比较小,会导致损失函数的曲线以一种震荡的方式下降。这会导致随机梯度下降法中每次迭代得到的梯度估计与训练集中想要的最优估计差别较大,为了减缓这种效应的影响,使用物理中的动量概念。在物理中通常把动量认为物体在原运动方向上保持运动的趋势。动量法就是使用之前神经元计算的累积动量代替计算出来的梯度。(5)Adam算法,是本课题中使用的优化算法,该算法可以看作是动量法和RMSprop算法的融合。不但引入了物理中动量的概念,而且将其作为参数更新的方向,使其能够自适应的增大或减少学习率。在本课题中学习率自150个epoch后线性递减,直到学习率为0。
具体示例
在实验室服务器上执行程序,在docker环境下执行代码,本实验拟执行270个epoch,batch size设为1,首先是使用docker start命令启动docker,然后使用dockerattach连接所使用的容器,最后就是在容器中执行代码即可。
每次从规定路径中读入图片,进入网络中进行训练,记录每一批训练时的生成器loss和判别器loss,在下图中可以看到有三种loss数值,其中G_GAN代表的是对抗损失,G_L1代表的是感知损失。图片效果的比较是使用PSNR进行参考,学习率为0.0001,每训练五次生成器训练一次判别器。每次训练五个epoch都会保存相应的checkpoint,以备后续的训练中使用,每次也会保存最新的模型。在前150个epoch中学习率是不变的,在后120个epoch中学习率线性衰减,直到0为止。
训练命令:
python train.py--dataroot/workspace/DeblurGAN-master_1/train_data--learn_residual--resize_or_crop crop--fineSize 256--dataset_mode unaligned
其中train.py为训练文件;
/workspace/DeblurGAN-master_1/train_data为数据集的路径;
learn_residual为学习率大小,使用的时默认值0.0001;
resize_or_crop crop表示使用的裁剪方式;
fineSize 256表示裁剪后图像大小为256×256;
dataset_mode unaligned表示数据的加载模式为unaligned,即从分别从两个文件夹中加载图像。
训练过程:从两个数据集中取一批次数据;循环五次判别器网络,将其训练五次;将训练得到的判别器权值固定,执行生成器网络,训练一次生成器模型;将判别器的固定权值操作取消,设为可训练,然后继续执行第一步操作,直到整个数据集遍历结束,完成一个epoch。图3a-3b为根据本发明实施例的训练实验截图。
取2000张未加入训练集的红外耦合图像作为测试集,在测试完成后会将结果保存在results文件夹下。包含4000张图像,红外耦合图像及其复原后的图像两两为一对。
测试命令:
python test.py--dataroot./testdir_new/--model test--dataset_modesingle--learn_residual--resize_or_crop scale_width_and_crop--fineSize 256
test.py为测试文件,dataroot./testdir_new/表示测试文件夹的路径,modeltest表示执行的时test,默认值为train,-dataset_mode single表示数据加载模式为single,即为单张加载。
测试过程:加载数据;加载训练得到的生成器权重;得到复原后的图像。
图3c为根据本发明实施例的测试实验截图。另外,具体参见附图3d-3e以及3f-3g,其中图3d、3f为原始红外耦合图像,图3e、3g为复原后的图像。综上,通过以上实验分析可得,本课题所使用的生成对抗网络模型对红外耦合图像复原为正常图像是有比较明显的作用。
本发明第二方面提供了一种生成对抗网络的图像处理系统,所述系统用于滤除所述图像中耦合的近红外成分。图4为根据本发明实施例的基于生成对抗网络的图像处理系统的结构图;如图4所示,所述图像处理系统400包括:第一模块401,被配置为建立样本库,分为训练集和测试集,并对所述训练集中的图像进行预处理,其中所述训练集包含第一红外耦合图像和对应的第一非红外耦合图像,所述测试集包含第二红外耦合图像;第二模块402,被配置为构建用于滤除所述图像中耦合的近红外成分的网络模型,所述网络模型包含生成器和判别器,并利用所述训练集中的所述第一红外耦合图像和对应的第一非红外耦合图像,基于损失函数来优化所述网络模型;以及第三模块403,被配置为利用经优化的所述网络模型来复原所述测试集中的所述第二红外耦合图像。
根据本发明第二方面提供的系统,所述第一模块401具体被配置为,对所述第一红外耦合图像和对应的第一非红外耦合图像进行随机剪裁,并将其类型转化为张量,经归一化处理后设置其打开方式为RGB格式。
根据本发明第二方面提供的系统,所述生成器对输入所述网络模型的图像进行多次下采样、卷积、上采样以加深网络层数,所述判别器由卷积层而非全连接层构成;所述损失函数包括0-1损失函数、均方差损失函数、熵交叉损失函数以及合页损失函数中的一种或多种;所述第二模块402具体被配置为:利用所述损失函数计算所述生成器损失和/或内容损失,并通过最小化所述生成器损失和/或内容损失来优化所述网络模型。
所述第二模块402被配置为,以小批量且梯度下降的方式加载所述第一红外耦合图像和所述第一非红外耦合图像,以优化所述网络模型。
本发明第三方面提供了一种存储有指令的非暂时性计算机可读介质,当所述指令由处理器执行时,执行根据本发明第一方面的基于生成对抗网络的图像处理方法中的步骤。
综上,实现了红外耦合图像复原为正常图像的深度神经网络设计。红外耦合图像复原方法是图像风格转换的一种特例,而深度神经网络能够提升该方法的训练效果。生成器的损失函数分为感知损失和对抗损失两部分,通过卷积神经网络的处理,能够对输入的红外耦合和图像及正常图像进行特征的提取,用于计算生成器的感知损失;在对抗损失的计算中使用WGAN模型且加入了梯度惩罚,提高训练的稳定性。二者的结合使得生成器生成的图像更贴近人眼的视觉习惯,提升的模型的效果。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 一种基于生成对抗网络的图像处理方法、系统和介质
- 基于生成对抗网络GAN的图像处理方法、装置以及电子设备、存储介质