一种基于残差学习及空间变换网络的光场超分辨率重建方法
文献发布时间:2023-06-19 11:22:42
技术领域
本发明基于深度学习技术,研究了一种光场图像的超分辨率重建方法,利用空间变换网络STN(Spatial Transformer Networks)和递归学习的方法,本发明首先对光场图像进行2D子视点图像的提取,对其进行下采样处理,然后将目标相邻视点图像的低分辨率视图分别按照相对角度输入到改进后的空间变换网络中进行特征提取,之后得到目标图像的近似图,然后将目标图像进行上采样并进行卷积计算,将各路得到的结果放入递归结构的卷积神经网络中进行特征的学习,在光场公开数据集上进行训练,从而最终获得目标视图的高分辨率图像。本发明属于计算机视觉领域,涉及深度学习,光场图像处理,超分辨率重建等技术。
背景技术
作为革命性的成像技术,光场成像受到了学术界以及工业界的重点关注,特别是随着商用全光相机的出现以及最近在虚拟现实(VR)和增强现实(AR)领域的贡献。通过在主透镜和图像传感器之间插入微透镜阵列等附加光学组件的方法,全光相机能够捕获真实场景中光线的强度和方向信息,且其丰富的光线信息远超传统成像方法,结合计算成像技术可以实现多视点成像、全对焦成像、深度估计等功能。对于图像采集来讲,由于光场图像补充了(θ,Φ)角度维度的信息,使得成像可以克服只有一个平面清晰成像的特点,这极大促进了大场景下AI识别任务的研究进程。对于渲染显示方面来讲,(θ,Φ)维度信息的增加,使得渲染物体的各向异性光线得到补充,显得更加逼真,好莱坞电影渲染任务许多也采用了光场/反光场技术。
随着光场成像的发展,光场图像应用的一个主要障碍是图像中光线记录信息的表达效率不高,并且由于传感器分辨率的限制,光场图像的分辨率等于角分辨率与空间分辨率的乘积,本质上是以牺牲空间分辨率作为获得角分辨率的方式,因此角分辨率和空间分辨率之间的相互掣肘问题愈发突显,以实验数据集来讲,得到的子图像分辨率只有544*376,将分辨率提升2倍或者4倍后,得到的图像质量很差,其他方法得到的结果并不理想,因为它们没有有效的利用光场图像视点相关的特性,光场中存储了大量关于同一场景中光线的冗余信息,视图间关联性很强,本发明充分利用相邻视图的信息,通过对光场图像进行超分辨率重建的方法,提高了光场图像的空间分辨率,从而提高了光场图像的总分辨率。
传统超分辨率重建的方法有插值法、基于重建的方法,其中插值法常用的有最近邻插值法、双线性插值法、双三次插值法,基于传统插值的方法通常得到的重建图像过于平滑,提供图像的细节信息有限,高频信息丢失严重,而基于重建的图像超分辨率方法通常都是基于多帧图像的,需要结合先验知识,应用场景有限且不灵活,故本发明采用基于学习的先进的卷积神经网络方法对光场图像进行超分辨率重建。
深度学习作为近几年模式识别和图像处理等问题中的研究热点,越来越受到人们的关注。其中卷积神经网络(Convolutional Neural Network,CNN)在图像分类和目标检测中展现了出色的效果,深层次的神经元性的多参数网络有助于提取图像的细节特征,能有效的解决光场图像超分辨率重建中的细节恢复问题,但传统的基于学习的方法没有有效的利用光场图像相邻视点之间的信息,故采用传统的基于学习的卷积神经网络模型难以有效地完成对光场图像的超分辨率重建工作。
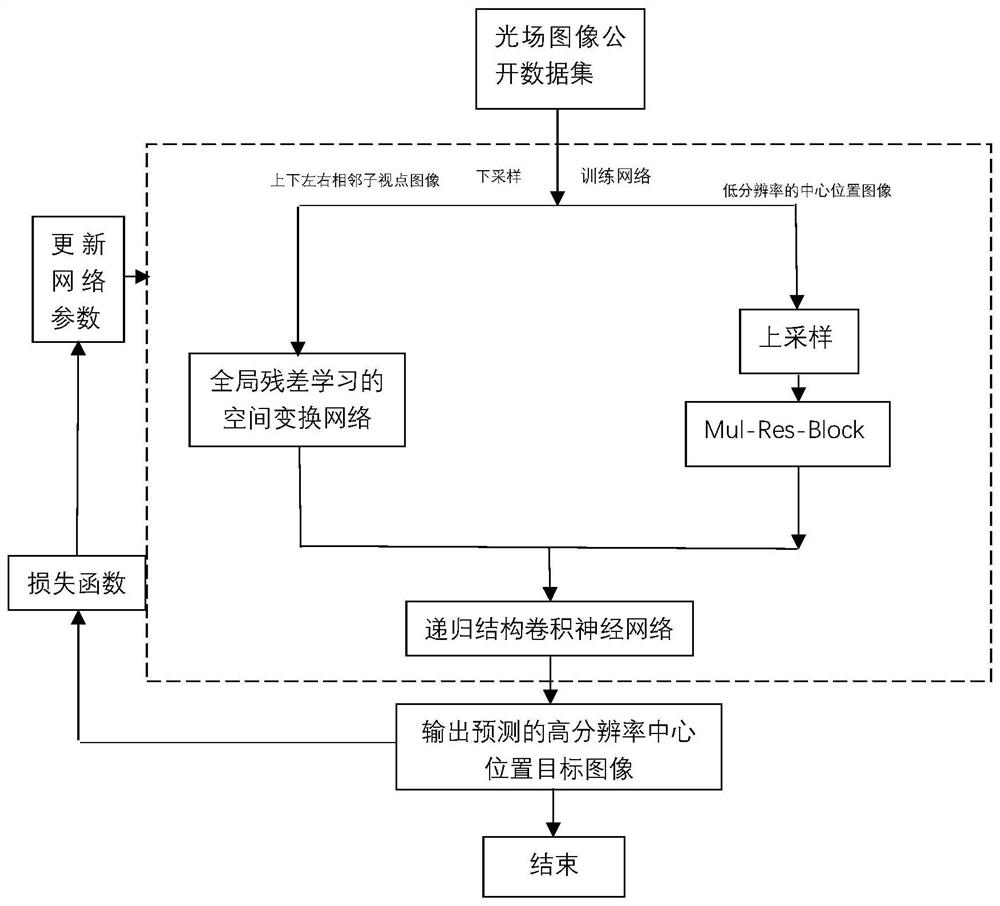
本发明提出的基于空间变换网络与递归学习的方法应用于光场图像的超分辨率重建。首先应用全新的4+1的融合模型,用来学习光场图像的特征和提取信息,此外,为了更好的提取特征,本发明将空间变换网络的定位器进行了改进,设计了全局残差连接的17层卷积层配合两层linear层提取2*3仿射变换矩阵的结构。该模型能够将低分辨率的目标视图和相邻视点图像的可用于超分辨率重建的像素信息充分利用起来,通过空间变换网络进行特征的迁移以及对目标图像的近似,从而进行特征图通道间的合并,然后通过递归结构的卷积神经网络对图像进行细节的恢复,训练集采用Kalantari公开数据集进行训练,并抽取25张光场图像(分解为6*6,即900张子视点图像)进行测试,经实验验证,生成的结果图像的PSNR测试在2倍,4倍超分辨率上均值分别达到36.11,29.20,SSIM值分别达到0.966,0.892。因此,本发明提出的光场超分辨率重建模型对于生成高质量的高分辨率光场图像有着重要的应用价值。
发明内容
本发明利用深度学习技术,提出了一种基于残差学习与空间变换网络的光场超分辨率重建方法,使用Kalantari公开数据集进行训练,重建出高分辨率的目标视图,高分辨率数值等于原分辨率乘超分辨率倍数。首先,将光场图像进行预处理,进行子视点图像的提取和下采样操作,下采样根据超分辨率倍数的不同设置不同的尺度。在此,本发明设计了上述4+1的融合模型,用来学习光场图像的特征和提取信息,首先按照上、下、左、右四个位置放入不同分支的网络之中,通过改进的空间变换网络(空间变换网络分为三部分,依次为定位网络、网格生成器、采样器)中的定位网络,进行2*3的仿射变换矩阵的预测,我们采用全局残差连接的卷积神经网络构造方法对定位网络进行设计和改进,通过网格生成器和采样器对目标图像进行重建,然后将不同分路得出的图像与经过上采样和Res-block模块卷积计算得到的特征图进行通道的合并,得到5通道特征图,然后将这5通道的特征图输入到递归结构的卷积神经网络中进行图像特征的细化和高频细节的恢复。使用随机梯度下降法(SGD)在Kalantari公开数据集上训练网络,得到训练后的网络模型,并重建出最终的结果。本方法主要流程如附图1所示,可分为以下三个步骤:
(1)光场数据的预处理
为了有效的利用光场子视点图像之间的关联信息,本发明首先将上述公开数据集中的光场图像通过角度坐标提取的方法提取子视点图像,每张光场图像选取6*6子视点图像进行实验,并对其进行下采样处理。得到低分辨率的图像作为输入,低分辨率具体数值等于原图像分辨率除以下采样倍数。
(2)光场图像特征的提取与重建
本发明使用的神经网络模型包含多条分支的改进后的空间变换网络与多层递归结构的卷积神经网络,首先通过梅花采样的方法,按上、下、中间、左、右位置对下采样的子视点图像进行选取,把上述的上、下、左、右位置图像分为四路分别放入各条分支的空间变换网络中,将上述梅花采样中的中间位置的子视点图像通过上采样与Res-block模块进行初步的超分辨率重建,对上述多分路得到的特征图进行通道的叠加,然后使用递归结构的卷积神经网络进行图像细节的恢复和重建,多分支空间变换网络可以有效的利用不同位置角度的子视点图像,为目标图像的重建提供更多的可用信息,通过对定位器使用全局残差连接的卷积神经网络进行改进,可以提高定位器的提取特征能力,使其可以回归出更精确的仿射变换矩阵,由于卷积运算在角度和尺度上都具有不变性,所以保证了提取特征的鲁棒性,递归结构的卷积层通过局部残差连接的方式,使图像可以恢复出更多细节。
(3)网络模型的训练
使用Kalantari公开数据集训练网络,该数据集包含125张光场图像,通过分割子视点图像可以得到125*14*14张子视点图像,数据集中包含了不同角度的自然景物图像,提高了模型的泛化能力,通过对学习率、动量参数等设置来决定权值更新的速度和提高训练自适应性,训练损失我们使用L1范数,上述设计可以有效提升模型的学习能力。
本发明与现有技术相比,具有以下明显的优势和有益效果:
本发明利用先进的基于残差学习的空间变换网络构建光场超分辨率重建模型。首先,相较于传统的插值算法,本发明得出的结果生成了更多的高频细节,相较于基于投影类的超分辨重建算法依赖相机参数的特点,本发明一定程度上克服了上述局限性,相较于普通的卷积神经网络,本发明采用的基于残差学习的空间变换网络与递归学习的方法得到了更高的PSNR与SSIM数值的图像,具体数值如表3所示。
附图说明
图1基于残差学习的空间变换网络的光场超分辨率重建方法流程图
图2残差学习的空间变换网络模型结构图
图3Res-block结构图
图4递归学习的卷积神经网络模型结构图
具体实施方式
根据上述描述,以下是一个具体的实施流程,但本专利所保护的范围并不限于该实施流程。
步骤1:光场数据的预处理
将上述公开数据集中的光场图像按角度坐标(u、v)进行提取的方法提取14*14规格的子视点图像(不同角度坐标的2D图像),每张子视点图像(尺寸为544*376)选取其中6*6的子视点图像进行实验,对其进行下采样处理。得到低分辨率图像作为输入,低分辨率具体数值等于原图像分辨率除以下采样倍数,用梅花采样的排序将图像按照上、下、中间、左、右的方式标记,若遇边界情况,不能构成梅花采样的排序,则缺失的位置图按其他位置图像的像素之和然后取均值代替,随后把所有图像颜色通道均转换为YCbCr通道,由于人眼对亮度信息最为敏感,我们单取Y通道作为输入的特征信息。(后续CbCr通道采用双三次线性插值法进行插值处理与后续得出的Y通道结果进行合并。)
步骤2:光场图像特征的提取与重建
在得到输入图像的特征图后,我们将图像按照相对位置分为上、下、左、右四路分别放入各条分支的空间变换网络中,其运算可以表述为:
等式左边的I代表通过四路STN(空间变换网络)生成的特征图,下标数字代表分支序号,右侧的I为输入。F
然后通过图像采样器,将输入特征图和采样网格作为输入,生成采样输出特征图。由于网格生成器生成的采样网格与输入特征图的离散网格值不完全对齐,因此使用双线性采样器对采样网格中的像素和邻域像素进行插值:
U表示原图,V表示输出的图,i表示图中第i个坐标点,V的尺寸可通过插值自行设定,H和W表示长度和宽度,其中n和m会遍历原图U的所有坐标点,U
上述为梅花采样的上下左右位置图像的处理,对于梅花采样的中间位置图像的处理,我们采用Bicubic插值法对图像进行上采样,将上采样的结果通过3个相同结构的卷积层数为2的Res-block模块进行卷积计算,每个模块通过局部残差连接,模块的输入通道为1,输出通道为1,中间通道均为64。然后与上述四张图像经过空间变换网络之后的结果进行通道的合并,得到通道数为5的特征图,此时可以表述为:
其中I
此时将I作为5通道的特征图输入到递归结构的卷积神经网络中进行图像细节的恢复,首先经过输入层卷积神经网络,输入通道为5,输出通道为64,卷积核尺寸为3,步长为1,然后经过9组递归卷积模块,每组为2层卷积神经网络组成,输入输出通道均为64,步长为1,卷积核尺寸为3,得到的结果作为残差与之前经过第一层卷积层计算后的结果相加,相加得到的结果作为输入送进输出层卷积神经网络,输入通道为64,输出通道为1,步长为1,卷积核尺寸为3,通过递归结构连接组成,如图四所示,此时可以表述为:
I
其中F
通过上述操作,最终得到1通道的高分辨率目标图像,高分辨率具体数值等于原分辨率乘超分辨率倍数。
步骤3:网络模型的训练
本发明使用Kalantari公开数据集训练网络,该数据集包含125张光场图像,其中100张作为训练集,25张作为测试集,通过分割子视点图像可以得到125*14*14张子视点图像,数据集中包含了不同角度的自然景物图像,提高了模型的泛化能力,其中取用质量比较好的在中间位置的6*6视图(以14*14为选取范围,横纵坐标分别取4-9位置图像,即为6*6)作为训练样本,训练样本图片数量为100*6*6,测试集图片数量为25*6*6。考虑到低分辨率图像与groundtruth之间的损失计算,我们采用L1范数作为损失函数。此时可以表述为:
其中L
接下来,我们采用随机梯度下降法(SGD),最小化上述损失函数,通过实验验证,本发明中学习率取10
详细训练过程如下:
1)随机初始化全卷积参数。
2)读入光场公开数据集,初始化卷积神经网络模型。
3)使用基于残差学习的空间变换网络进行计算,得出的图像与经过上采样和Res-Block卷积计算之后的图像进行通道的合并,得到5通道的特征图。
4)将5通道的特征图输入到递归结构的卷积神经网络中,得到高分辨率的Y通道图像Y
5)将图像Y
6)根据损失值L
7)根据损失值L
8)重复步骤(3-7)50次,直到损失函数得到的损失值收敛,此时网络中的参数值即为最终网络模型参数值。
将训练后的模型通过测试集进行测试,得到最终结果。
本发明提出的基于残差学习及空间变换网络的光场超分辨率重建算法,我们采用Kalantari公开数据集进行测试,且模型具有较深的网络层数,便于更好的学习特征,我们分别将up-scale设为2和4,在测试集上对比了VDSR与DRRN的方法,相较于VDSR与DRRN的深层网络学习方法,本发明充分利用了光场子视点图像之间的关联性,得到了可用于重建的更多有效信息,图像恢复的质量更高,本发明2倍、4倍超分结果的PSNR分别比VDSR高0.34DB、0.30DB,比DRRN在2倍、4倍超分结果的PSNR分别高0.1DB,0.17DB,这证明了我们方法的有效性,该实验也证明了利用光场子视点图像之间的关联对光场图像进行超分辨率重建的有益性,对于光场图像超分辨率网络模型性能的提升具有建设性意义。
表1
表2
表3
- 一种基于残差学习及空间变换网络的光场超分辨率重建方法
- 一种基于残差子图像的深度学习超分辨率重建方法