“存活性”检测系统
文献发布时间:2023-06-19 11:27:38
技术领域
本发明的领域涉及唇读系统,并且在一个实施方式中,涉及“存活性”检测系统。
该专利文档的公开内容的一部分包含受版权保护的资料。版权所有人不反对任何人以复写方式复制专利文档或专利公开内容(如在专利商标局专利文件或记录中),但保留其他所有版权。
背景技术
在过去的40年中,人机接口(HCI)通过命令行接口、GUI、鼠标到移动设备上的触摸/相机交互而得到了发展。苹果的Siri系统于2011年推出,预示了“嗓音优先”用户接口的到来。嗓音作为HCI的主要手段的使用预计在未来几年内将呈指数增长。给消费者带来的益处是显而易见的。嗓音UI快得多–人类每分钟可以说150个单词,而相比之下,每分钟可以键入40个单词。此外,嗓音UI更易于使用-方便、免手持和即时。
然而,嗓音UI的市场预测总是因在现实世界(即嘈杂的)环境中需要改进准确性而被质疑。语音识别技术都是基于音频的,尽管噪声消除技术有所进步,但当背景噪声水平升高时,单词准确率继续显着下降。由于在正常驾驶条件下的准确性差,因此在驾驶员调查中,车载嗓音激活一直被列为“最烦人的汽车技术”。
在个人助理市场的主导地位争夺战中,许多大型公司都在直接或间接地经由音频语音识别(ASR)技术合作伙伴投入大量资金来改进其解决方案的准确性。
在嘈杂的环境中,音频语音识别单词的准确水平通常会下降。视觉语音识别(VSR)技术因此可以用作音频语音识别系统的支持技术。例如,唇读技术可以通过在用户向相机说话时分析用户的嘴唇的移动来确定语音。这些嘴唇移动被称为视位,并且在视觉上等同于口语中的音素或声音单位。视位可以用来描述特定的声音。
因为视觉语音识别(VSR)技术对声学条件不敏感,例如背景噪声或其他人的说话,因此纯VSR系统也可以用在现实世界环境中,诸如那些环境噪声大的环境。
VSR技术的示例应用是在嘈杂的环境(例如汽车、公共交通、咖啡厅等)中在智能电话上使用嗓音基础虚拟个人助手时改进其准确性。第二示例包括在生物特征标识期间检查存活性,以防止使用人的视频或静态照片进行欺骗(也称为“重播攻击”)。
然而,在现实世界的用例场景中实施VSR技术仍然是一项艰巨的任务,其中诸如照明条件的变动、图像分辨率差和说话者头部移动等挑战可能导致一些困难。
本发明解决了上述漏洞以及上面未描述的其他问题。
发明内容
第一方面是一种存活性检测器:这是一种用于评估由基于计算机的系统查看的人是否是活人的检测系统,该系统包括:
(i)接口,其被配置为接收视频流;
(ii)单词、字母、字符或数字生成器子系统,其被配置为生成一个或多个单词、字母、字符或数字并将其输出到终端用户;
(iii)计算机视觉子系统,其被配置为分析接收到的视频流,并且使用唇读处理子系统或视位处理子系统确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字,并且输出终端用户是否是“活”人的置信度分数。
第二方面是一种认证系统:这是一种用于评估由基于计算机的系统查看的人是否被认证的认证系统,该系统包括:
(i)接口,其被配置为接收视频流;
(ii)单词、字母、字符或数字生成器子系统,其被配置为生成一个或多个单词、字母、字符或数字并将其输出到终端用户;
(iii)计算机视觉子系统,其被配置为:(a)分析接收到的视频流;并且
(b)使用唇读处理子系统或视位处理子系统确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字;并且(c)将来自唇读处理子系统或视位处理子系统的数据与对应于所述人生成的身份的存储数据进行比较;并且(d)输出终端用户是他们所声称的人的置信度分数。
第三方面是一种改进的基于计算机视觉的唇读系统:这是一种包括如下的唇读系统:
(i)接口,其被配置为接收视频流;以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户的嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中,唇读处理子系统实施自动照明补偿算法。
第四方面是一种确定语速的唇读系统:这是一种用于检测语速的唇读系统,其包括:
(i)接口,其被配置为接收视频流,以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,
其中该系统基于对终端用户嘴唇移动的分析来输出终端用户的语速。
第五方面是一种适应任何姿势变动的唇读系统,这是一种唇读系统,其包括:
(i)接口,其被配置为接收视频流,以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中,唇读处理子系统还被配置为动态地适应终端用户的头部旋转或移动的任何变动。
第六方面是一种抵抗虚假视频的基于计算机视觉的唇读系统:这是一种唇读系统,其包括:
(i)接口,其被配置为接收视频流,以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中,计算机视觉系统能够使用拼接检测方法通过对跨连续视频帧的像素信息进行分析来检测视频拼接攻击。
第七方面是一种专门针对嗓音受损的终端用户设计的基于计算机视觉的唇读系统:这是一种用于嗓音受损的终端用户的自动唇读系统,其包括:
(i)接口,其被配置为接收视频流;
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并切基于嘴唇移动来识别单词或句子,
(iii)在连接的设备上运行的软件应用程序,其被配置为从计算机视觉子系统接收所识别的单词或句子并且自动显示所识别的单词或句子。
第八方面是一种与音频语音识别系统集成的唇读系统:这是一种视听语音识别系统,其包括:
(i)接口,其被配置为接收视频流和音频流,
(ii)语音识别子系统,其被配置为分析音频流,检测来自终端用户的语音,并且识别终端用户说出的单词或句子,
(iii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
(iv)合并子系统,其配置为分析由语音识别子系统和唇读处理子系统所识别的单词或句子,并且输出候选单词或句子的列表,每个候选单词或句子与置信度分数或等级相关联,该置信度分数或等级指的是终端用户已经说出候选单词或句子的似然性或概率。
附图说明
现在将参考以下附图通过(一个或多个)示例的方式描述本发明的方面,每个附图均示出了本发明的特征:
图1是平台的高级框图。
图2是示出终端用户、在移动设备上运行的应用程序和LipSecure云服务之间的交互的高级序列图。
图3示出训练流水线和测试流水线的框图。
图4示出训练阶段的详细框图。
图5示出训练阶段的详细框图。
图6示出测试阶段的详细框图。
图7示出具有在特定特征提取用例中执行的步骤的框图。
图8示出图示自动数据生成系统的图。
图9示出图示特征提取过程的图。
图10示出DNN的架构。
图11示出结果表。
图12示出显示实验结果的曲线图。
图13示出显示实验结果的曲线图。
图14示出显示实验结果的曲线图。
图15示出显示实验结果的曲线图。
具体实施方式
我们组织了以下具体实施方式。
第一节是高级概述。
第二节是Liopa系统如何工作的更详细描述。
第三节是视听语音识别系统的更详细描述。
附录1是一篇论文(McShane,Philip,and Darryl Stewart."Challenge basedvisual speech recognition using deep learning."In Internet Technology andSecured Transactions(ICITST),2017 12th International Conference for,pp.405-410.IEEE,2017)。
附录2是Liopa系统中实施的高级关键特征的综述。
第一节、概述
可以通过在用户向相机说话或模仿时分析用户的嘴唇的移动来确定语音。这些嘴唇移动被称为视位,并且在视觉上等同于口语中的音素或声音单位。应用的示例是在线认证期间的活动检查,并且称为LipSecure(请参见第二节)。
然而,本申请中使用的技术不限于此用例。视觉语音识别技术也可以与音频语音识别技术组合,以跨广泛的环境条件改进单词识别准确性(请参见第二和第三节)。
进一步的应用包括但不限于:
·改进音频语音识别系统,例如:
ο车载嗓音激活和控制;
ο个人助理(例如Siri、Cortana、Google Now、Echo);
ο智能家居嗓音控制。
·自主纯视觉语音识别,例如:
ο视频片段(例如监控)中的关键单词/短语识别;
ο改进的现场直播字幕
ο与声带受损的人进行交流。
LipSecure不需要附加的硬件,并且可以在带有标准前置相机的任何设备(例如,智能电话、平板电脑、笔记本电脑、台式机、车载仪表板等)上工作。LipSecure可以与任何标准RGB相机以及IR/ToF传感器一起使用。
例如,面部识别(现已成为一种成熟的生物特征认证器,具有跨多种设备类型的多种应用程序)会使用对象的静态图像遭受反复的高调的欺骗攻击。通过将LipSecure技术与面部识别组合使用,将提示用户向相机说出/模仿单词、字母、字符或数字的序列,作为认证过程的一部分,从而确保存在“活”人并且认证有效。LipSecure在屏幕上生成和/或显示单词、字母、字符或数字的序列,或经由扬声器提供音频输出,并且然后将从由相机捕获的视频流导出的视位与其单词、字母、字符或数字的记录进行比较;如果匹配足够,则很可能不会欺骗(例如用静态照片)生物特征认证系统。单词、字母、字符或数字的序列可以随机选择,也可以从大型语料库中选择,因此通过预先录制大量不同单词、字母、字符或数字的视频进行欺骗非常困难。该系统可以配置为提出问题,诸如“你有什么颜色的头发?”,并且使用单词“棕色”的视位(语音识别引擎将语音分析为单词“棕色”)和用于分析用户头部的包含头发的部分并确定其颜色的计算机视觉系统两者来比较答案(例如“棕色”)。因此,我们具有多因素方法来确保生物特征认证。
进一步的可能的用例包括但不限于以下情况:
·法律/安全:
ο在线交易的不可抵赖性(non-repudiation);
ο在线认证期间的反欺骗;
·监控:
ο检测CCTV镜头中的“感兴趣的单词”、关键单词/短语;
·社交媒体:
ο在社交媒体交互期间确保身份确认;
·检测药物或酒精的消耗:
ο防止在药物或酒精的影响下驾驶/使用机具;
·机器人/智能制造:
ο与工业环境中的机器交互;
·情绪/行为检测:
ο在公共环境中或在线交易期间的愤怒检测/警报;
ο对象疲倦时的检测/警报;
·协助生活:
ο媒体的实时字幕;
ο协助听觉受损的对话(例如,谷歌眼镜应用程序,其从眼镜指向的人那里实时转录语音);
·语音对语音:
ο在嘈杂的环境中恢复退化的语音;
·健康护理:
ο行程(stroke)检测;
ο语音治疗;
ο与嗓音受损的患者交流;
·基于视频的IVR:
ο增强的交互式嗓音识别系统(例如与数字化身进行交互)。
第二节、技术概述
该技术基于视位分析的原理。使用视位,听力受损者可以视觉查看声音-有效地“唇读”整个人面部。
该技术通过以下方式模仿此过程:
·捕获对象说话的视频;
·跟踪并提取对象的嘴唇的移动;
·执行唇读特征提取,诸如嘴唇移动的自动编码和/或基于DCT(离散余弦变换)系数的特征提取;
·使用基于高斯混合模型(GMM)、隐马尔可夫模型(HMM)和深度神经网络(DNN)的技术来分析嘴唇移动;
·将分析的结果(逐个单词地)与通用模型进行比较,以确定说了什么,其中在系统安装期间通过分析大量说话者视频(其中说出的单词是已知的)的嘴唇移动来构建通用模型。
深度神经网络(DNN)是人工神经网络(ANN),在输入层和输出层之间具有多个隐藏层,与类似执行的浅网络相比,其给出了用更少的单元来建模复杂数据的潜力。
使用以上技术,系统的关键特征是:
·该系统可以针对单个/多个说话者进行训练,也可以是独立的说话者;
·该系统包括独特的图像特征提取和分析方法,这可以实现准确的语音识别;
·使用基于视位的深度神经网络执行嘴唇分析;
·算法用于将基于音频的识别的多个源与Liopa的VSR合并,以优化所有条件下的准确性。
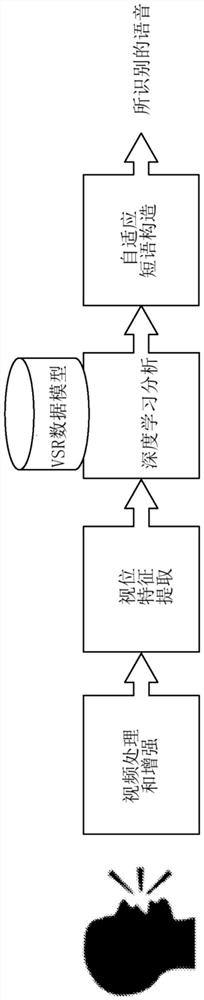
图1是基于灵活流水线的平台的高级框图,其包含许多功能构建框,包括:视频处理和增强、视位特征提取、深度学习分析、自适应短语构造。
2.1存活性检查(LipSecure)概述
LipSecure是云服务,它为用户认证服务提供存活性检查,以防止欺骗。LipSecure可以用作“存活性”检查,以验证在任何在线交互期间存在真实的人。例如,可以将LipSecure与面部识别(FR)系统一起部署,以消除通过使用用户的静态图像来愚弄FR系统的“欺骗”的常见问题。提示用户向相机说出/模仿由LipSecure服务生成的数字的随机序列。组合的FR/LipSecure解决方案将验证用户是否是他们意图的身份以及他们是否真实存在。
在高级下,Lip Secure系统提供两个主要功能:
1.请求和接收随机质询短语(例如,六个数字的序列)的能力;
2.提交说出质询短语的对象的视频以及请求该对象讲出的短语的文本的能力。然后,系统返回对象实际说出所请求的短语的概率(也就是置信度分数)。如果概率高,则存在“活”人。
图2是在下面示出在移动设备上运行的应用程序之间的可能交互的高级序列图,在调用该应用程序时,该应用程序对用户进行认证(例如,移动银行应用程序)。
2.2存活性检查(LipSecure)功能描述
如图3所示,Liopa VSR解决方案的实施方式包含两个主要部件:
1.训练流水线,其用于吸收大量训练数据并且创建通用基于VSR的模型。训练数据是说话者预先录制的视频,这些视频重复了来自用例语法的已知短语-在存活性检查的情况下,该已知短语是数字。
2.测试流水线,我分析用户说话的视频以确定他们讲出了什么,然后将该结果与请求的随机质询短语进行比较。
这些流水线将在以下各节中进行更详细的描述。
尽管在下面的描述中,将DCT特征提取用作示例,但也可以使用任何其他唇读特征提取方法,诸如主成分分析(PCA)或线性判别分析(LDA)。
可替代地,在训练系统以学习从捕获的图像或视频数据中提取哪些特征的情况下,也可以使用学习的特征提取方法(例如自动编码)。
在本文档中,图像或视频数据可以指代任何图像传感器数据,诸如IR(红外)图像传感器数据或深度传感器数据。
训练阶段
以下描述参考图4和图5所示的“训练阶段”图。
视频处理
1.裁剪流水线的输入是被逐帧读取的对象的整个面部的视频。
2.对每个帧(其中帧大小大于指定的大小)的缩小版本执行面部检测。如果在先前帧中找到了面部,则检测窗口将被限制到先前面部的位置周围的指定裁剪区。
3.在检测到面部的情况下,估计面部关键点(眼睛、鼻子、嘴巴等)。
4.在具有检测到的面部的帧中存在间隙的情况下,在成功检测到的帧之间线性插入关键点。
5.跨帧应用基于窗口的关键点平均平滑。
6.在透视变形算法中使用关键点以将面部映射到参考面部。
7.在适用的情况下,将多个检测到的关键点合并以计算所需的参考点(进一步平滑)。
8.固定裁剪区应用于标准的面部模板。
特征提取-离散余弦变换(DCT)
1.在给定裁剪后的视频的输入的情况下,将每一帧转换为灰度并将大小重新调整为16×16;
2.在给定预标识的最佳参数的情况下,执行选择的照明补偿,例如CLAHE(对比度受限的自适应直方图均衡);
3.计算DCT;
4.提取要使用的最终系数,例如三角形掩码,经由Z字形选择28个系数,并删除初始DCT-0(每帧产生27个系数);
5.在帧(使用原始视频帧)时间戳之间插入特征向量,以转换为指定的恒定帧速率。
6.归一化视频帧上的特征(减去均值并除以标准差)。
特征提取-自动编码器
1.隔离训练数据集的子集(包括理想化的实验室捕捉数据和设备捕捉数据的现实世界的混合)。
2.对齐是事先已知的(基本事实),或者是使用音频数据和预先构建的模型(例如使用HTK)生成的。
3.对齐用于将裁剪后的视频(大小为96×96)切片为各个单词,以用于隔离的单词识别的任务。
4.对裁剪后的隔离的单词视频片段执行数据扩展,其涉及随机子裁剪(大小为88×88)和水平翻转,以增加数据集大小并减少过度拟合。
5.实施端到端深度神经网络,其由一组3D卷积的前端和深度残差网络组成,具有用于隔离的单词分类的LSTM后端。
6.一旦在视觉语音数据的该子集上进行了训练,后端就被丢弃,并且前端用于生成特征向量(大小为256),该特征向量被插入到100fps并进行归一化(减去平均值并除以标准差)以用于训练和测试数据集。
7.将归一化的自动编码器特征(256)和归一化的DCT特征(27)组合成大小为283的级联特征向量。
8.输出是每个视频话语的提取的特征的适当存档文件(ark)。
模型构造阶段
1.用于模型构造的当前数据集由理想的实验室捕捉数据(由数字、命令和更多开放词汇组成)和现实世界设备捕捉数据(由基于数字和命令的词汇组成)组成。
2.数据的初始预处理由从所有视频文件中提取音频并且为每个单独的话语创建适当的转录。
3.按照上述过程从每个视频中提取特征。
4.使用与每个视频相对应的音频(在特征提取期间成功,即在裁剪期间未失败),生成13个梅尔频率倒谱系数(MFCC)。计算倒谱均值和方差归一化(CMVN)统计以给出零均值和单位方差倒谱(基于每个话语或每个说话者)。
5.计算最终特征级音频话语的帧长度,并且剪切或填充视频特征(使用最终帧)以匹配该长度。
6.将音频特征(MFCC)用于初始GMM-HMM构造中,以生成适当的对齐。
7.由于在初始模型构建阶段使用了音频,因此整个过程中使用的词典(辞典)基于音素而不是视位。
8.使用音频特征(MFCC)构建了单音HMMGMM,这是不包含有关周围音素的上下文信息的第一声学模型。
9.在给定当前声学模型的情况下,强制对齐音频特征和转录,以允许在下一个模型构建阶段中的参数细化。
10.构建三音HMMGMM,这是包含前后音素的上下文的模型。这是使用动态系数(增量+双增量(deltas+deltadeltas))构建的。
11.在给定三音增量模型的情况下,强制对齐音频特征和转录。
12.构建三音模型LDA-MLLT、线性判别分析–最大似然线性变换。其中LDA减少了特征空间,并且MLLT提供了变换,目的是归一化并最小化说话者之间的差异。
13.使用当前HMMGMM强制对齐音频特征和转录。
14.构建说话者自适应训练(SAT)HMMGMM,其使用每个说话者的特定数据变换来标准化数据。
15.强制对齐。
16.构建另一个(更大)的说话者自适应训练(SAT)HMMGMM,其使用每个说话者的特定数据变换来标准化数据。
17.强制对齐
注意:在给定我们的训练和预期的测试场景的情况下,已对整个模型构建阶段的参数进行了调整,以给出最佳性能。
18.然后,针对音频编码器和DCT视觉特征,使用从音频特征生成的音素对齐来训练DNN-HMM模型。为此,使用了TDNN-f链模型(NNET3)。这是分解时间延迟神经网络。链模型是Kaldi工具包内的DNN-HMM混合模型的特定实施方式。此模型内存在许多关键差异,最重要的是,1/3小的帧速率用于网络输出,从而允许更快地解码时间,并且从开始使用序列级目标函数(LF-MMI)对模型进行训练。训练TDNN-f的关键步骤包括:
a)将对齐生成为网格(使用最新的GMM-HMM模型和音频特征)。
b)创建语言目录的版本,每个音素具有一个状态。
c)使用新拓扑(音频特征)构建三音决策树。
d)生成用于网络的配置文件。在这里定义和调整架构和关键参数-包括层数、尺寸(输入、瓶颈和最终尺寸)、隐藏层和输出层上的L2规范化参数等)。
e)针对视觉特征训练定义的网络,指定更多可调整的参数,诸如学习率进度表、辍学进度表、时期数等。
注意:在给定训练集和预期的测试方案的情况下,对参数进行调整以给出最佳性能。另请注意,在不使用iVectors(这是NNET3链TDNN-f模型的标准特征)的情况下发现与说话者无关的场景中的最佳性能。
测试阶段
图6是显示“测试阶段”部件的图,包括视频处理和特征提取,如上所述。
测试/解码阶段:
1.输入:NNET3链TDNN-f模型、用于所有测试话语的特征(ark)文件以及用于评分的对应转录;
2.解码流水线:提取测试话语的特征,构建适当的语法/语言模型,构建解码图(HCLG),使用预构建的TDNN-f模型解码话语。
3.假设我们已经在语音丰富的数据集上训练了模型,我们能够在测试时使用该模型来识别训练期间未看到的单词和短语。为此,我们将所有新单词和对应的音素映射添加到辞典中,重建语言目录,构建语法/语言模型(如果我们在测试时的句子限于特定集(诸如基于命令),则这可以是固定的语法,或者我们可以使用统计n-gram语言模型用于更开放的词汇),使用所有更新和预先构建的声学模型构建解码曲线图,并且然后对测试话语进行解码。
4.然后使用评分来提供适当的度量,诸如单词错误率、单词识别准确性、句子错误率、句子识别准确性。初始验证集用于找到最佳语言模型/声学模型加权和单词插入罚分。
图7图示了特征提取用例的示例,并示出包含在特征提取期间执行的以下步骤的详细图:
·(71)首先接收原始视频作为输入。
·(72)然后分析视频帧,并且对每个已分析的帧检测界标,或者在时间点t=2:T下无法为任何给定帧提取界标的情况下,对界标进行插值。
·(73)执行照明补偿(例如CLAHE),从而增强对比度,并通过均等化灰度值的分布使图像的隐藏特征可见。
·(74)将图像的大小调整为16×16图像,以便获得所提供的信息的最紧凑表示。
·(75)计算离散余弦变换(DCT)。
·(76)使用三角形掩码来提取高能量系数->28个DCT系数,将DCT-0丢弃以给出每帧27个系数。再次给我们最有用的信息的最紧凑表示。
·(77)跨帧对特征进行归一化,即针对DCT-1->DCT-27范围内的每个DCT系数(减去平均值并除以标准差)。
·(78)假设固定帧速率,插值用于创建更多数据点,即输入特征表示25fps,我们希望具有100fps,因此使用三次样条插值创建新特征。
·(79)通过指定特征矩阵和头文件将最终特征转化为DNN格式文件。
2.3置信度评分算法
置信度评分算法是自适应加权评分过程,其基于以下原则:视位和生成的单词的选择比其他单词更难标识,并且可能容易与其他单词混淆。在给定已知的词汇和测试数据集的情况下,当前的HMM-DNN模型将用于持续评定性能。然后使用单词混淆矩阵来标识通常混淆的单词,以及与它们最常混淆的单词,然后假设我们已经向说话者询问了特定单词,那么就生成了某个单词出现的概率。解码和评分过程旨在在给定数据输入/声学模型/辞典/语言模型的情况下选择哪个单词/句子更有可能,在选择了最可能的短语之后,通过将预测的短语与询问的短语进行比较来生成分数。使用加权评分方法,我们使用通过评定标识的概率,以基于询问了哪个单词和系统评定中出现混淆的似然性来重新加权该分数。
2.4照明补偿
现实世界应用程序可以具有许多环境参数,这些参数降低了视觉唇读系统的单词准确性。例如,在灯光条件差的情况下,捕获的图像或视频可能具有低的动态范围,这可能增加系统的单词错误率。
2.4.1对比度受限的自适应直方图均衡
因此,用照明补偿方法实施唇读处理系统,以便在灯光条件差时改进单词准确性。作为示例,可以使用的照明补偿方法基于对比度受限的自适应直方图均衡(CLAHE)算法。
直方图均衡旨在在整个强度标度内均匀分布像素强度级别,但是这可能导致噪声过度放大。自适应直方图均衡旨在通过将图像细分为图块或块并针对每个块执行直方图均衡来解决它。为了进一步解决噪声过度放大的问题,CLAHE引入了“修剪限度”,在计算累积分布函数之前,以指定的阈值裁剪直方图。然后将相邻区域合并,并且使用双线性插值来去除遮挡伪像。因此,CLAHE通过增加局部区域的对比度来增强局部细节的可见性。使用CLAHE的缺点是它不是自动的,并且需要对参数进行设置-并且对这些设置非常敏感。重要的参数是修剪限度和图块大小。当前的解决方案集中在使用图像熵的这些参数的最佳设置上。使用搜索程序,由此在给定特定图像的情况下,以变化的修剪限度应用CLAHE,并且在这些图像熵值上绘制熵曲线–在最大曲率点选择了最佳修剪限度。
已经开发了CLAHE的自动和自适应版本来代替全局参数设置,其中使用图像信息自适应地选择CLAHE内的参数。
AUTO/ADAPT CLAHE算法的特征如下:
·在给定视频内,每帧的修剪限度和图块/块大小两者的完全自适应参数设置。
·对于给定帧:
ο首先通过使用基于搜索的方法N=2:12计算最佳图块大小。对于N的每个值,计算N×N的子图像矩阵,并且计算相关联的子图像的熵,存储给定所有子图像的最大熵。选择提供最大熵的N。
ο使用该最佳图块大小,现在通过使用熵曲线方法自适应地计算最佳修剪限度。
ο选择多个逐渐增加的修剪限度,并且使用所选的修剪限度(或图块/子图像,取决于应用程序的粒度)将CLAHE应用于图像。熵的变化经由熵曲线记录-并且将与最大曲率点相关联的修剪限度选择为最佳设置。
ο然后使用所选的图块大小和修剪限度来处理该帧。
2.4.2在唇读系统中用于灯光补偿的3维照明伽玛掩模:
通过使用基于帧的伽玛值通过一系列灯光扩展数据集来开发此方法。
使用用以自动确定最亮和最暗的算法,图像可以被变换并且仍然分辨出图像的细节,对该算法进行定制,使得为视频中的每个像素(局部伽玛)和时间点(帧)找到最佳伽玛值,以产生3D掩码以扩展训练视频中的每一帧。
唇读分类模型使用扩展的数据进行训练,并且使用来自一系列灯光条件的样本进行测试。使用测试结果,我们只能在特征空间中保留相关的扩展数据,以学习用于扩展照明稳健特征的函数,而无需先前数据、存储和存储器要求。
2.5拼接检测–用以确定通过视频拼接而进行的可能攻击的方法
可以用来尝试绕过LipSecure存活性验证过程的可能攻击是向系统显示正确的人讲出所请求的质询短语的假冒视频的视频回放。这可以可能地以多种方式产生:
a.将来自其他视频的人讲出各个数字的视频片段拼接在一起。本质上,这可以产生包括正确的人以正确顺序讲出正确数字的视频。
b.创建人讲出正确短语的深度假冒(DeepFake)视频。
c.使用面部交换工具将冒充者的面部界标的移动映射到所声称的说话者的面部界标上。本质上,这可以产生所声称的人讲出任何必要的话的动画。
检测过程本身可以是纯基于统计的,也可以是基于机器学习的。统计方法将直接关注像素信息,即通过研究跨帧对的像素值中的“正常”或预期变化并且基于标准差和通过经验研究预定的阈值来定义异常,以检测跨连续帧(图像)的像素强度的显著变化。
基于模型的异常检测方法将首先构造适当的模型(例如特征提取/HMM-DNN),以表示假设不存在拼接时的“正常”行为。然后将测试帧对以与拼接的帧对相比,标识跨合法帧对的对数似然性(loglikelihood)的变动,其中然后将确定阈值并将阈值用于标记可能的拼接情况。拼接检测的使用可以充当整体“质量标度”的组成部分,其将在一个最终的综合指标中考虑多个元素,诸如分辨率、照明、移动等。
通过构建表示外观的统计规范的模型(例如,这包括灯光特性、面部特征几何、肤色等特征)以及最重要的合法帧内的帧级过渡(例如,特征的速度和加速度等),可能检测到视频拼接攻击。然后,我们可以检测到可能指示假冒视频攻击的任何帧级异常。
2.6根据嘴唇移动的语速检测
VSR系统可以产生各种形式的输出。一种形式的输出是具有单词级(word-level)和音形级(phonetic-level)时间戳的单个最高评分话语,该时间戳指示每个单词和音素何时开始和停止。根据这些时间戳,可以根据“每分钟单词”或“每分钟音素”度量来确定视频中个人的说话速率。然而,音节而不是单词或音素被认为是用于测量语速的更稳定的发音单元。因此,我们通过称为自动音节化的过程将音素和单词序列转换为带时间戳的音节序列。然后,我们可以使用这些时间戳来确定说话者的“每分钟音节”的说话速率,并且还可以测量整个视频中人的音节持续时间的变化。音节持续时间变短的趋势将指示增加的语速。
可以将这些度量与该个人的先前数据进行比较,或者,如果尚未为该个人记录历史规范,则可以测量视频内的波动。
有关说话者在视频中如何说话(仅基于嘴唇移动)的这种元信息可以潜在地用于帮助确定人在视频中的情绪状态,并且可能帮助确定团队环境中的凸显的说话者的个人。结合其他形态(例如手势、注视角度),这可以提供有关团队动力和领导力的有用信息。此外,一些研究已经表明了压力水平和语速之间的明显的联系。可以标识出语速与在训练数据中发现的历史规范的差异,并将其用于提供有关对话语调的信息。
2.7基于动态时间规整的视觉语音识别
VSR的这种方法对于仅VSR的应用程序特别有用,并且尤其是在存在系统希望识别的短语目标列表的情况下。其也最一般地适用于以下应用程序,即用户将通过定期使用而为(或成为)系统所知,以及系统将能够随着时间的推移而适应其特定的嘴唇移动特性。
在此应用程序中,系统将使用少量的人讲出目标短语的实例进行填装,并且将这些实例存储为模板,针对模板可以对新出现的短语进行评分。
首次使用该系统时,用户可以选择记录其自己的目标短语的实例,并且这些实例可以用作目标模板,以便其将来与系统进行交互。然而,即使他们没有向系统提供任何明确的注册数据,也将能够使用动态时间规整找到具有最大相似性的标准模板。随着用户继续使用该系统,它将能够构建具有最可靠相似性分数的用户特定模板的配置文件。
该系统中的模板是从视频中提取的特征文件,并且表示人嘴唇外观和移动的静态和动态特征。可以基于K最近邻居算法针对每个目标短语针对每个用户维护最佳数量的模板。
在VSR系统的标准训练数据中可能无法很好地表示说话者的情况下,VSR的这种形式特别强大。例如,这对于嘴唇移动受医疗状况(例如,中风受害者)影响的人或儿童可能特别有效,并且因此将非常适合作为交互式玩具的定制和适应性(无声)输入机构。
2.8用于产生高质量数据以训练唇读神经网络的自动系统。
为了使自动唇读系统正常运行,需要大量的训练数据。这需要构建包含成千上万个的人说话的视频的数据库,以及每个视频讲了什么的准确转录。为了解决该问题,我们创建了可以进行以下操作的自动数据生成系统(请参见图8):
1.搜索和下载数字视频源或从传统视频源进行记录
2.在视频源中搜索合适的嘴唇移动片段
3.使用自动语音识别和/或转录标识说出的单词
4.提取人说出短语的视频片段并标记它们以训练唇读系统
总之,数据生成系统是唇读神经网络训练阶段的大量训练数据的自动源。
数据收集
数据收集阶段负责创建原始数字视频存储。存在两个主要部件。
第一个部件是视频数字化仪,其将从任何视频源进行记录。这是获取数字视频的简单蛮力方法。第二个部件是自定义的Web爬虫,它将在互联网上搜索视频数据并将其下载以进行检查。可以对爬虫进行自定义,以查看特定位置并搜索特定内容,例如“谈话的头”的视频。
视频处理步骤
从原始数字视频存储中,我们必须使用后处理技术从不可用的资料中过滤出高质量的视频资料。越来越复杂的视频处理流水线用于拒绝不满足质量标准的视频。
流水线阶段为:
1.视频帧率、比特率和分辨率是否足够高以指示高质量视频?
2.人检测→头部检测→面部特征检测→嘴唇检测-视频中是否有人?
3.面部角度检测–人在看着相机还是看着别处?
4.语音检测–人在移动他们的嘴唇吗?
如果满足流水线所有阶段的标准,则考虑音频,否则视频被拒绝。
音频处理步骤
我们判断音轨质量,以确定音轨是否清晰且无噪音。如果音频质量低,则我们拒绝视频。
一些视频源提供了文字转录。这可能是人为或计算机生成的。如果没有可用的转录,我们将使用自动语音识别来产生它。无论哪种方式,我们都将转录与视频对齐,以便我们知道讲出了什么以及在什么时候讲的。
贴标
数据收集系统的最后一部分是将视频与先前步骤的所有输出组合以产生精致的高质量带注释的数字视频存储。该存储针对每个条目包含以下内容:
·具有独特名称的说话的人的视频文件
·该人所说的文字转录,进行了时间对齐
·视频期间人的头部移动的统计记录
·视频来自哪里的记录
2.9多语言视觉语音识别
当前不存在可以处理多种语言的唇读系统。大多数只能识别英语,其他语言示例仅适用于单一语言。
多语言唇读有两个基本任务:语言检测和多语言建模。ML唇读系统可以分为两层;从而检测到语言(例如产生“英语”、“法语”或“官方语言”的预测),并且然后选择特定于语言的模型来解码语音,或者单个多语言模型可以检测来自任何语言的单词(或音素)。
多语言模型的显着优势是测试时的语言不变性。这在语言在对话中途或句子中途变化或者语言之间采用的单词变化的情况下防止系统中断。考虑到世界上第二语言说话者的数量,这一点特别重要。
迄今为止,在唇读系统中还没有关于第二语言说话者的公共工作,只有音频语音识别。当我们在婴儿时期学着说话的时候,我们既会倾听又会看着我们周围的人的脸。我们知道,嘴的形状和嘴唇运动(视位)随发音和内容而变化,但重要的是也会随语言变化。研究表明,语前婴儿可以通过在听其他语言时表现出痛苦来区分语言,因此我们可以推断视觉语音也受到类似的影响。
通过学习第二种或多种语言,说话者的视位字汇不会自使用第一语言学习的视位字汇发生变化,但是他们的使用方式却有所不同,因此如果唇读系统要真正地是多语言的,它对多语言说话者也将是稳健的。
2.10经由AVSR进行语音训练
音频语音识别用于许多语音教育任务,例如学习第二语言、儿童发育或中风后失语症患者的康复。我们使用视觉语音作为此任务的辅助的独特方法,即用于语音训练的AVSR,使得除了在训练期间听到音频外,参与者还可以观看不同速度的嘴唇运动的视频。这些视频(通常是发出某些声音的视觉姿势)可以帮助不同的学习者。
使这种方法独特的原因是,视觉语音如何随不同年龄段(和其他人口统计标签)而变化的知识的开发。儿童更有可能对语音中的音素共同发音,第二语言说话者正在使用相同的视位用于与针对他们的第一语言已经知道的声音不同的声音,并且中风患者不可能具有与他们中风前相同的面部肌肉,并且因此需要专业视频/视位模拟。
2.11基于VSR的谎言检测
用于谎言检测的面部分析并不是什么新鲜事物,但是使用视觉语音才是。谎言不是二元的,有些谎言是白色的谎言,并且有些我们讲出的事可能是对的,但这是避免泄露其他信息的答案。因此,分析语音期间的嘴唇运动(就像我们在机器唇读中所做的那样)作为用于诚实检测的面部分析是对语音真实的独特且更可能的评估。
2.12嘴遮掩的唇读
在现实世界中,面部和嘴唇对于相机并不总是完全可视;围巾、手、记录伪像是相机、物体或说话者运动引起的示例遮掩。
语音朗读(即使用整个面部来识别视觉语音,而不是仅使用嘴唇进行唇读)是解决短暂遮掩的可能方法。嘴唇是复杂的形状,当缺少视频的(一个或多个)部分时,要在整个视频中进行跟踪具有挑战性。物体和面部跟踪是两个大的研究主题,但是在唇读系统中都没有将其应用于嘴唇,因此面部的其余部分可以补充否则被遮掩的嘴唇掩盖的信息。
2.13 VSR特定的姿势不变性
在相对于说话者的姿势角度与训练期间看到的姿势角度不同的情况下,现实世界的唇读系统的性能下降。在这种情况下,说话者姿势变化可以比拟成其他噪声源,诸如照明变化,其中解决方案将通常需要额外的训练数据来覆盖变化或需要标准化方法来去除噪声。
确保系统对说话者姿势的变化是稳健的,消除了要求说话者采取朝向相机的稳定的正面视线姿势的限制,这将通常是在高度协作的说话者上训练系统的情况。这使得系统可以在说话者可能不知道或不能直接看相机的情况下使用,例如在驾驶员使用车载语音识别系统的情况下。这还提供了释放用户的空间,允许他们在周围自由移动的同时利用系统。
姿势不变性可以在特征级或模型级(或实际上在两者)下构建到系统中。在仅单个姿势可用于训练并且预期姿势变化可能受到合理限制时,姿势不变特征特别有用。此类特征有效地针对姿势角度进行归一化,从而将来自一系列姿势的特征映射到较窄的特征空间中。另一方面,姿势不变视觉语音模型最终可以允许完整范围的姿势变动。
在基于DCT的特征的情况下,可以通过去除较高阶和奇数的水平频率分量来实现姿势的稳健性。这具有迫使水平对称并且减小偏航角对水平嘴外观的影响的效果。另一方面,姿势不变模型最终可以允许完整范围的姿势变动。在学习的特征(例如自动编码器)的情况下,可以通过在多个视点上针对公共标签训练特征来实现姿势不变性。
在我们的系统中,我们训练了与姿势有关的自动编码器,对其进行调整以从来自已知姿势角度的嘴唇视频中提取特征。这些是使用一组独特的地面实况视频创建的,这些视频是使用包括多个相机的相机架捕获的,这些相机安装并定位为从各种姿势角度捕获说话者面部。相机具有一系列类型,包括标准RGB、IR、高帧率下的距离测量。数据是从来自各种种族、性别和年龄的多个不同说话者捕获的,以捕获说话者外观和动态的丰富集合。
然后,我们仅使用来自我们的与姿势有关的自动编码器的帧级特征表示,针对每个姿势训练HMM-DNN VSR模型的集合。因此,这些模型具有被调整为识别特定姿势角度下的语音状态的状态。为了确保每个姿势的每个HMM-DNN模型中的所有状态都表示相同的物理状态,我们首先使用音频流帧对齐来对齐输入帧和状态,并且确保用于音频语音识别的HMM-DMM模型架构与VSR模型是相同的,即,相同的单词、辞典、音素集和每个音素的状态数是相同的。
姿势不变的视觉语音模型最终可以允许完整范围的姿势变动。这可以通过在所有可用姿势上结合姿势不变特征训练的单个通用模型进行,或者经由多流建模进行,其中每个流表示姿势角度的子集,可以在识别期间被动态选择。可以使用帧的后验概率在帧级下执行这种动态选择,以确定最可能的模型和任何给定时间。单个模型方法更适合训练中姿势角度的分布不均匀的情况或训练中姿势角度未知的情况。另一方面,多流模型提供了跨视图实现最高唇读准确性的潜力,但需要更多受控的训练数据,每种技术的使用取决于特定的最终用途和数据的可用性。在我们的系统中,我们开发了姿态不变VSR方法,如下所示:
-我们假设人正面向相机或在相机的90度内,即该人处于相机的正视图或侧面或两者之间的任何角度,但在所有帧中,面部可视并且嘴也是可检测的。
-检测到头部并自动提取嘴的感兴趣区域(ROI)。
-然后将ROI帧传递到已在已知姿态角度上进行训练的自动编码器的集合,并收集每个的特征表示。
-然后使用每个调整的HMM-DNN模型对这些帧进行评分,以计算每个姿势的帧级似然性。
-最大似然性分数被确定为HMM-DNN系统中每种可能状态在那一刻的最可能姿势。然而,所有状态分数都将维持,以允许在帧序列的末端处的平滑。这种平滑将确保帧间姿势变化在合理的限制内,即可以对姿势变化的预期变化率施加约束,使得将不会期望姿势从一帧到另一帧过度变化,例如不超过30度。
-该系统提供了将来自多个VSR模型的输出进行组合的智能方法,该模型动态适应经由单个相机捕获的人的姿势外观。
2.14针对在线交易的不可抵赖性的视觉语音识别方法
不可抵赖性的传统方法集中在高度复杂的加密系统上,该系统旨在证明可以验证在线交易的起源和目的地,并且在这两个点之间传输的数据未被篡改。这些系统高度复杂,并且对于解决抵赖情况不切实际,因为它们(1)没有被绝大多数互联网用户所理解并且很少使用,(2)易受到端点设备的恶意软件攻击,(3)不能验证哪个实际的个人执行了哪些动作,(4)在抵赖争议中没有好处,因为已完成交易的可用数据太复杂,以至于无法理解,例如法律情况下,陪审团无法理解。
Liopa开发了基于VSR的不可抵赖性系统,以替代数字签名和加密,以提供无缝且用户友好的方法来确保在线交易和协议。这将基于面部识别的用户认证与视听语音识别(AVSR)组合。利用AVSR来防止认证欺骗并且验证在例如法律或在线商务交易期间需要说出的重要短语或句子是否被正确叙述。然后,存储自动验证的叙述视频,作为交易成功完成的证据,并且用作任何未来抵赖争议的证据。
该系统创新的关键领域是(1)使用AVSR系统,其将利用基于DNN的音频和视频语音识别技术来确保在所有环境条件下(例如,高水平的背景噪音或可变灯光等)准确地识别语音(2)面部识别与基于VSR的反欺骗技术的集成,其可以验证交易期间是否存在真实的认证的用户(例如,防止“重播”攻击)。
下面的可能用例演示了诸如可以如何在实践中利用这种系统:用户对购买健康保险感兴趣,并且保险提供商希望提供完全在线的自动服务,并且不涉及纸质文件的交换。用户通过提供照片ID的副本并叙述由相机记录在他们的计算机或智能电话/平板电脑上的确认短语来建立与保险公司的在线帐户。确认短语被验证,并且用户注册到面部识别系统。然后,在购买保险的交易期间,要求用户确认关键信息片段并同意某些限制以及条款和条件。在这些点上,捕获叙述的视频,对用户进行认证,并检查所讲出的内容的正确性。然后将这些叙述存储在保险公司系统中,以备将来使用。在保险期限期间,用户提出保险公司认为无效的索赔,例如,由于先前存在的健康状况。保险提供商能够拒绝索赔,并且提供来自用户不能成功质疑的首次购买交易的经过验证的视频证据。
2.15用于嗓音受损的基于VSR的语音识别应用程序
SRAVI(用于嗓音受损的语音识别应用程序)是针对患有语言受损的患者(诸如气管切开术的患者)的交流辅助。SRAVI应用程序可以在任何安卓设备(智能电话、平板电脑)上运行,并且当保持在患者面前时,它将跟踪嘴唇移动并标识出要说出的短语。
与昂贵且需要长期训练才能使用的替代方法相比,SRAVI可以为患者、其家庭成员和医护人员之间的交流提供易于使用、准确且具有成本效益的方法。通过建立简单、可靠的表达他们自己的方式,患者可以更好地与工作人员保持联系,以确保他们需要的护理。
SRAVI基于视觉语音识别(VSR)技术。患者的嘴唇移动的视频被设备相机捕获,并且被发送到Liopa基于云的VSR引擎进行处理。从预定义的列表中标识要说出的短语,并在设备上播放该短语的音频记录。可以根据护理设置(例如,医院或家庭)对预定义短语列表进行扩张和变化。SRAVI可以随着时间的推移适应各个患者的嘴唇移动,这意味着使用得越多,它就会变得越来越准确。
SRAVI易于使用,因为不需要对患者或家属进行艰苦的训练。终端用户只需要在设备前移动他们的嘴唇,并且该应用程序提供他们想说的话的立即翻译。家庭成员能够访问系统并且与患者更自由地进行交互。
3.视听语音识别系统。
现在描述将音频语音识别和VSR组合的视听语音识别(AVSR)系统。AVSR系统可以包括实施上述任何特征的VSR系统。
VSR技术也可以与音频语音识别技术组合,以跨变化级别的音频和视频噪声来提供最佳准确性。
我们已经开发了用于将音频语音识别与视频语音识别集成的3种方法。它们在下面列出:
·基于累积N最佳列表相似性的目标短语评分
·基于短语相似性的网格合并
·帧级MWSP集成
3.1基于累积N最佳列表相似性的目标短语评分
这种方法对于预期用户将说出来自目标短语的特定列表的短语的问题域特别有用。尽管优选的将是对集成的音频语音识别和VSR系统进行设计和调整,以使其仅专门识别目标短语,但这对于这种集成方法的工作来说并不是必需的。来自音频语音识别和VSR系统的输出可以包含在目标短语中找不到的短语。
此方法需要以下输入:
a.系统期望识别的目标短语集
b.音频语音识别系统和VSR系统产生的N最佳短语列表
该过程按以下方式工作:
来自音频语音识别和VSR引擎的N最佳列表根据似然性或概率分开排名。每个系统产生的列表的长度应相等,并且在理想情况下,将至少包含约10个短语。如果一个列表最初包含的短语比另一个列表多,则可以使用两种方法来平衡它。最简单的方法是删除最长列表中排名较低的短语,以确保相等的长度。第二种方法是使用短语相似性加权,其将来自一个模态的分数高于另一模态的分数的效果进行归一化。例如,如果一个列表包含10个短语,并且另一个列表仅包含7个短语,则可以通过乘以0.1(即1/10)来加权来自10个短语的列表的每个相似性分数,并且可以使用0.143(即1/7)来加权从另一个7个短语的列表中记录的相似性。
每个N最佳列表中的短语一次被获取一个,并且针对每个目标短语计算相似性分数。可以用各种方法来计算相似性分数,但是关键的计算是两个短语之间的编辑距离。可以基于短语中的单词标记来计算编辑距离,或者可以将编辑距离扩张为包括音形编辑距离。然后,基于以下公式将编辑距离转换为归一化的相似性度量S:
S=1-(E/L)
其中E是标记编辑距离,并且L是标记中两个短语(单词或音素)中较大者的长度。
单词级编辑距离
对于单词级编辑距离,使用动态编程将目标短语中的单词与所识别的短语中的单词对齐,以找到单词映射,这使两个短语之间的Levenshtein编辑距离最小。
音形级编辑距离
对于音形编辑距离,使用发音辞典将映射中的单词转换为音素串。然后可以计算音素串之间而不是单词串之间的Levenstein距离或替代地Jaro-Winkler距离。在此级上计算编辑距离优于单词级距离,因为这将有助于增强以下目标短语的似然性,这些目标短语在音形上类似于所识别的短语,但可能具有错误的单词标记。例如。如果目标短语列表包含短语“Ice cream”并且N最佳列表中所识别的短语“I scream”,则目标短语的单词级相似性将为0。然而,当使用音形编辑距离时,这些单词级短语将转换为“AY S.K R IY M”和“AY.SK R IY M”,其中句点指示所识别的单词边界。在这种情况下,编辑距离将为0,并且相似性将为1。
这种较低级的音形编辑距离还允许音频语音识别和VSR系统产生词汇量比“目标”列表中可能受限的词汇量大得多的短语。因此,可以集成“通用”大词汇量音频语音识别或VSR系统,并且可以将输出重新聚焦到目标列表,而无需对音频语音识别或VSR系统的任何重新训练。
累积相似性分数
为每个目标短语维持累积相似性评分。这是来自音频语音识别和VSR系统的N最佳列表中所有短语的所有相似性分数的总和。一旦针对所有目标短语对所有短语进行了评分,就根据目标短语的累积相似性分数对目标短语进行排名。如果任何将来的处理单元有必要或期望,则可以在这一点上将相似性分数归一化。最上面的短语可以是系统的输出,或者目标短语的整个排名列表也可以是具有其相关联的相似性分数的输出,该相似性分数用于指示每个目标短语的似然性。
模态可靠性加权
还可以对基于来自每个模态的短语而产生的每个单独的相似性分数应用进一步的加权。这些权重将允许在短语的排名中考虑模态(音频语音识别和VSR)的测量或期待的相对可靠性。例如,如果在识别时估计了高水平的音频噪声,或者可能是基于部署场景(在嘈杂的环境中)预期的,则可以将固定的“可靠性”权重应用于音频语音识别短语相似性0.6(介于0..1之间的值,其中0指示被视为完全损坏的模态,并且1是完全可靠的),同时对基于VSR模态计算的每个相似性应用0.9的权重。这些权重将具有以下效果:强调为VSR短语针对目标计算的相似性,并且不强调音频语音识别短语的相似性。同样地,如果在视频信号中检测到将影响VSR输出的可靠性的损坏或噪声(例如,非常差的照明),则可以将较低的可靠性权重应用于VSR短语相似性。
3.2基于短语相似性的网格合并
如果问题域是更通用的并且没有目标短语的特定列表,则此方法很有用。
此方法需要以下输入:
a.音频语音识别系统和VSR系统产生的N最佳短语列表
该过程按以下方式工作:
通过从音频语音识别短语列表(从最高似然性到最低似然性进行排名)中获取短语来创建和更新短语网格。每个短语都映射到当前网格节点和边,以找到具有距当前短语的最小编辑距离的通过网格的路径。如果需要新节点以将特定标记添加到网格,则在此阶段添加他们。更新网格中的节点之间的边缘权重,以考虑沿着网格路径新出现的标记。这意味着包含最频繁出现的单词序列的通过网格的路径将积累最强的权重。当所有短语都添加时,然后VSR短语将以相同方式添加到网格中。这产生了大网格,其包含表示两个列表中的短语的所有路径。重要的是要注意,这个较大网格可以包含以下路径,该路径表示在他们拥有的任一短语列表中都找不到的短语。此特性对于以下情况可能是重要的,其中音频语音识别系统对短语开头的单词高度自信并产生可靠结果而对短语结尾的识别差,而VSR系统可能对短语的开头不可靠而对短语的结尾高度可靠。这种集成方法有可能生成新的正确短语路径,该路径基于在开头处的音频语音识别短语和在结尾处的VSR短语。
此方法的最后一步是使用已针对使用中的问题域进行调整的特定语言模型,再次潜在地对网格路径重新评分。这允许从大量可能的短语路径列表中找到语法上最可能的短语。
3.3帧级MWSP集成
最终的低级集成方法可能比其他更高级的方法更强大,这有两个原因:
a.组合可以在系统通过音频和视频帧进行的初始解码期间发生,而其他后期集成方法则要等到它们各自的解码过程产生了完整的输出后才能开始。
b.该系统可以更适应于任一模态中的短期损坏/噪声。
可以应用一系列可能的算法来组合来自每个模态的分数。我们采用的方法基于最大加权流后验(MWSP)算法(Seymour,R.;Stewart,Darryl;Ji,Ming./Audio-visualIntegration for Robust Speech Recognition Using Maximum Weighted StreamPosteriors.Paper presented at Interspeech 2007,Antwerp,Belgium,pp.654-657)。
如果可以假设AVSR系统在稳定的声学环境(安静且噪声水平不变)中并且在稳定的视频条件下(例如相机移动小且照明条件不变)运行,则将可以在设计时确定组合系统时应该应用的最佳静态加权。一些研究表明,音频流的固定权重可能为0.7并且0.3是有效的。这是由于这样的事实,即音频流通常提供比视觉流更大的判别信息。然而,在现实世界条件中,由于变化的噪声水平,两个流的噪声水平以及因此的可靠性可能波动,因此AVSR系统必须旨在通过修改所应用的加权来保持稳健的性能。
MWSP算法已被表明提供了一些理想的特性,因为在安静或嘈杂的条件下操作时,其产生的识别性能(单词准确性)至少要高出并有可能高于各个模态的最佳性能。该算法的其他主要优点是,它允许系统动态优化在组合来自音频和视觉模态的概率输出时应用的权重,而无需显式测量任一模态中存在的噪声或损坏水平。可以针对音频和视频的每个输入帧优化权重。这意味着,在训练或设计时,系统无需了解有关将在将要部署系统的特定环境中存在的噪声类型或水平的任何事,并且可以将其部署在其中任一或两种模态中的噪声类型和水平可以随时间变化的应用中。
在已发表的论文中,在使用高斯混合模型表示HMM状态的多流隐马尔可夫模型系统内证明了MWSP算法的有效性。然而,MWSP算法可以同等地应用于其他建模架构中,包括具有深度神经网络状态表示的HMM。
附录1.使用深度学习的基于挑战的视觉语音识别
我们提出了一种新颖的方法,用于在基于挑战的框架内基于视觉语音识别进行存活性验证,该方法有可能在移动设备上使用,以防止在基于面部的存活性验证期间发生重播或欺骗攻击。该系统使用模型视觉语音识别,并且基于随机生成的质询短语与来自视觉语音识别器的假定话语之间的Levenshtein距离来确定存活性。使用基于深度学习的视觉语音识别方法来改进使用视觉语音识别进行存活性验证的技术水平。
Ⅰ.引言
越来越多地考虑代替使用密码来保护对诸如笔记本电脑和电话等电子设备的访问。获得这些设备的访问的最常见的用户认证方法是使用密码、用户ID、标识卡和PINS。这些技术有许多限制:可以通过监控或蛮力攻击来猜测、窃取或非法获取密码和PIN。近来,有许多引人注目的黑客是由于密码泄露引起的。这些黑客允许恶意人员使用有效用户的凭据获得对系统的访问,而无需用户存在。
为了增强安全性,已经考虑了基于密码的方法的替代方案,并且这些替代方案主要集中在生物特征认证的形式上。已经提出了许多不同的生物特征,其中最流行的涉及识别面部[1]、嗓音[1]或指纹[1][2]。这些系统虽然比密码更安全,但也有一些限制。指纹扫描系统准确、快速且稳健,然而它们很容易受到“欺骗”形式的影响,从而可以使用错误的指纹来愚弄传感器[2]。进一步的限制是在设备中具有专用指纹传感器的额外成本,这意味着很少有设备提供指纹扫描作为认证过程。
由于语音识别系统仅使用设备中的标准麦克风,因此它们可以廉价、通用地部署到所有移动设备类型。在安静的环境中,嗓音已被表明是高度准确且相当稳健的。喧吵和/或随时间变化的背景噪声的存在可以影响性能。此外,在某些环境中,清晰地对着麦克风说话可能被认为是不合适或不恰当的。
面部识别已被表明是高度准确的,并且对用户的环境、外观的变化、姿势和照明条件的变动可以是稳健的。面部识别系统的关键顾虑在于,面部识别系统可能易受到欺骗攻击,在该欺骗攻击中,未经授权的用户将照片保持在相机前面并以照片中的人获得访问[3]。在涉及移动设备的无监督的远程访问用例中,这些攻击形式更有可能成功。通过确保在认证过程中包括“存活性”检测,可以显着改进远程无监督的面部识别系统的安全性,从而确保授权用户存在并且在系统提示输入时做出响应。
在本文中,一种基于视觉短语验证算法的存活性验证的方式,该算法在基于质询的验证框架内使用视觉语音识别系统。具体地,验证过程涉及质询用户讲出随机生成的数字串,然后他们将向电话的相机说出该数字串。将在视频上执行视觉语音识别,并且如果视觉识别系统确信视频包含与质询短语匹配的嘴唇移动,则将验证用户的“存活性”。每次验证尝试时随机生成质询短语,以限制使用先前记录的视频进行重播攻击的可能性。
图9是示出特征提取处理的图。
对于实际使用,这种用于存活性验证的方法将与其他生物特征认证过程(诸如面部识别)组合,以改进生物特征系统的整体安全性和稳健性,并且将不会显著超出标准面部捕获过程而给用户带来不便。近年来,视觉语音识别已成为广泛研究的焦点,并且已经发展到可以将其稳健地用于有限的词汇任务的程度[4][5]。为生物特征应用使用视觉语音识别的先前研究集中于使用与音频组合的视觉信息[6][7],并且大多数研究都集中于使用视觉语音作为验证用户的身份的替代方式,不是用于验证存活性。Evano和Besacier[8]在分析视觉和音频特征的同步性的基础上,探讨了存活性验证,并使用XM2VTS数据集报告了14.5%的均等错误率。在[10]中,提出了一种仅基于使用视觉信息的存活性验证系统,该系统基于具有SVM(支持向量机)的语音识别,以识别已被单独分割的数字。使用了[10]中的仅利用视觉模态的方法,在XM2VTS数据集上报告的语音识别率为68%。在本文中,目的在于通过使用深度学习来显示对先前工作的改进。
Ⅱ.视觉语音识别
视觉语音识别旨在基于他们的嘴唇的移动来确定个人说出的文字。
当视觉语音识别系统接收视频时,执行识别的第一步骤是首先确定嘴唇在图像中的位置,并且提取嘴唇区域以用作感兴趣区域(ROI)。对于本文使用的系统,使用了Dlib图像处理库[9]。Dlib提供了面部界标检测器,该检测器已用于从每个视频帧中定位和提取ROI,此过程在[9]中进行了描述。
选择DCT变换是因为在[5]中其表明给出了良好的性能。然后将三角形掩码应用于DCT变换的结果,并从中选择15个最低频率系数,并去除DC分量,剩下14个DCT。DC分量被去除,因为最初的实验表明,当不存在DC分量时,系统更好地执行。然后将均值和方差归一化应用于特征向量。通过三次样条插值将特征的数量增加到100fps,因为发现这增加了视觉语音识别器的性能。从14个DCT中计算出差分系数和加速度系数。然后将它们与14个DCT连接,以给出42个系数的特征向量。
深度学习方法在解决诸如计算机视觉[11][12]、音频语音识别[13]和自然语言处理[14]等领域的问题中显示出了希望。为了创建能够执行与基于音频的语音识别软件相当的水平的视觉语音识别系统,选择了基于深度学习的方法。通过并入这种方法,目的在于产生将适用于现实世界应用的系统。
对于这项工作,我们采用了混合系统来执行视觉语音识别。术语混合是指将DNN(深度神经网络)和HMM(隐马尔可夫模型)组合的语音识别系统[15]。DNN用于提供HMM状态的后验概率估计。HMM对需要考虑语音的时间维度的长期依赖关系进行建模。对于这项工作,我们采用了在DCT特征上训练了的DNN-HMM。与先前的方法相比,使用DNN-HMM识别器已显示出语音识别系统的性能的显着改进[13][16]。在图10中可以看到DNN的架构。
在训练DNN之前,先对堆叠RBM(受限的Boltzmann机器)的DBN(深度信任网络)进行训练。此过程用于初始化DNN中隐藏层的参数。这是经由渴望的逐层过程完成的,其中每个RBM都经过训练,并且然后堆叠以产生DBN。RBM经由近似的随机梯度下降来训练。在该预训练步骤之后,使用sMBR(状态级最小贝叶斯风险)序列判别训练来训练DNN,因为这在[17][18]中被建议作为序列判别训练的最佳标准。
Ⅲ.存活性验证算法
语音识别系统的输出是单个最高似然假设短语,并且通常通过对一组测试话语执行识别并计算其平均单词错误率(WER)来测量识别系统的性能[19]。单个测试话语的WER被计算为
其中S是在假设短语中发现的替换错误的数量,I是插入错误,D是删除错误,并且N是正确转录中的单词的总数。S、D和I是通过在计算说出的话语的正确转录与假设短语之间的Levenshtein距离期间使用动态规划来确定的。
理想地,当说话者讲出质询短语时,视觉语音识别的结果将是完美的匹配,但视觉语音识别还不是完美的,并且取决于用户和所提供的视频的质量,通常可以以10%-40%之间的WER操作。因此,考虑到识别系统将以某个平均WER操作,看起来可信的是,如果将足够长的质询短语与识别器的输出进行比较并且Levenshtein距离在可接受的Levenshtein距离(ALD)阈值之内,则可以假定可能说出了与随机短语完全不同的质询短语,因此可以验证其存活性。在给定该设置的情况下,使用包含正确数量的随机数字的视频成功进行欺骗攻击的概率可以用公式2表示。
其中P是与包含从ν+1个单词类型的词汇中选择的w个单词的质询短语找到匹配的概率,并且其中系统允许ε错误。举一个具体的示例,其中w=20并且e=12的随机数字串视频成功用于欺骗攻击的概率为3.4×10
Ⅳ.基于网格的短语验证。
除了单个最高似然性假设短语外,还可以生成N最佳短语假设列表,这些短语假设是根据其从识别器的搜索网格中获知的其似然性进行排名的。N最佳列表通常包括短语,这些短语可能是最高排名的假设的细微变动。例如,如果用户被质询讲出以下短语:“一二七三九零八六四”,则得到的3个最佳列表可能如表1所示(图11)。
从本示例中可以看出,排名第二的假设所包含的错误少于最佳假设,并且在N最佳列表中的其他地方而不是在最上面找到正确的转录或与之的最近匹配并不罕见。N最佳列表的最大长度主要由识别期间的波束宽度和其他修整参数确定,但是实际上,通常在顶部附近找到正确的短语,并且在我们的实验中,总是在顶部50个短语之内。因此,我们允许系统对顶部100个短语中的每个假设短语执行短语验证,并且如果基于N最佳列表的搜索对任何短语进行了验证,则确定存活性为阳性。这潜在地允许将ALD阈值略微降低,从而导致假拒绝错误(FRR)的降低。
Ⅴ.XM2VTS数据集
对于实验,选择了XM2VTS数据集[20]。XM2VTS数据集是多模型数据集,其由讲出短语“零一二三四五六七八九”、“五零六九二八一三七四”和“乔把父亲的绿色鞋凳取出来了”的295位说话者组成。我们的实验的焦点是通过视觉语音识别进行数字识别,因此仅使用了数字串短语。基于洛桑(Lausanne)协议[21],将数据分为训练数据和测试数据。该协议将数据集分为训练和测试,以进行生物特征系统的训练和测试。该协议为数据集指定了两种不同的配置。我们使用协议的配置II作为选择我们的训练和测试数据的起点。具体地,我们选择来自测试分区中的70位说话者的视频作为我们的测试数据,以进行不依赖说话者的存活性验证实验。当训练识别器时,使用来自不在测试集中的说话者的视频。由于训练集中没有来自说话者的视频用于我们的实验,因此报告的结果指示该系统在不依赖说话者的条件下将如何执行,并且因此很好地指示了系统在得到来自新说话者的数据时将如何执行,如当将部署此类系统进行实际使用时将发生的情况。
在一个视频中将两个10位数字序列组合,以得到20位数字短语“零一二三四五六七八九五零六九二八一三七四”。在识别器的训练期间仅使用20位数字视频。使用此模型,使用20个单词的视频获得86.3%的单词准确性。为了允许调查变化的质询短语长度的影响,我们对测试集中的视频进行了细分,以从包含6、10和15位数字的数字串的测试数据中生成新视频。
这是通过基于视频中每个数字的单词边界将20位数字视频分割成包含较短短语的视频来实现的。这些是通过使用高准确性(99%单词准确性)基于音频的语音识别器对来自视频的音频执行强制对齐而获得的。使用这些边界,通过在20位数字短语上一次一个单词地移动大小为w的窗口,生成各种短语。基于这种方法生成视频的结果是,有可能扩大我们实验中使用的短语的数量。通过查看从原始20位数字视频生成的前几个10位数字视频可以看到各种短语,其为“零一二三四五六七七八九”、“一二三四五六七八九五”、“二三四五六七八九五零”等/在进行实验时,每个视频均作为可能的欺骗附件和有效的用户测试进行了测试。创建了欺骗攻击,其中设置为1000个正确长度的随机质询短语,其包含与视频的实际内容不匹配的数字串。这模拟了攻击的可能性,其中攻击者摆出正确用户讲出与系统提示用户讲出的短语不同的短语的视频。
Ⅵ.实验
使用视觉语音识别器对包含不同长度短语的视频进行了实验。对于实际使用,较短的短语是优选的,因为用户说话的时间较少,然而,在需要更强安全级别的情况下,可能期望较长的短语。
长度为6、10、15和20个单词的视频的平均持续时间分别为2、4、6和8秒。实验结果可见于图12至图15。这些图表示出当ALD阈值设置为不同值时的FRR(假拒绝错误)和FAR(假接受率)。示出了即使ALD阈值高达40%,FRR仍低于百分之一。
Ⅶ.未来工作
在这项工作中,已经探讨了使用基于深度学习的视觉语音识别作为基于质询的存活性验证的基础。已经示出了系统在各种短语长度上的性能,并且指示了针对不同短语长度的适当的ALD阈值。未来的工作将着眼于改进视觉语音识别系统的性能,以及如何使其在实际环境中使用时对这种系统所遇到的噪声更加稳健。
附录1参考文献
[1]Jain,Anil K.,Arun Ross,and Salil Prabhakar."An introduction tobiometric recognition."IEEE Transactions on circuits and systems for videotechnology 14,no.1(2004):4-20.
[2]Roberts,Chris."Biometric attack vectors and defences."Computers&Security 26,no.1(2007):14-25.
[3]Biggio,Battista,Zahid Akhtar,Giorgio Fumera,Gian Luca Marcialis,and Fabio Roli."Security evaluation of biometric authentication systems underreal spoofing attacks."IET biometrics 1,no.1(2012):11-24.
[4]Dupont,Stéphane,and Juergen Luettin."Audio-visual speech modelingfor continuous speech recognition."IEEE transactions on multimedia 2,no.3(2000):141-151.
[5]Pass,Adrian,Jianguo Zhang,and Darryl Stewart."An investigationinto features for multi-view lipreading."In Image Processing(ICIP),2010 17thIEEE International Conference on,pp.2417-2420.IEEE,2010.
[6]Chetty,Girija,and Michael Wagner."Biometric person authenticationwith liveness detection based on audio-visual fusion."International Journalof Biometrics 1,no.4(2009):463-478.
[7]Alam,Mohammad Rafiqul,Mohammed Bennamoun,Roberto Togneri,andFerdous Sohel."A joint deep boltzmann machine(jDBM)model for personidentification using mobile phone data."IEEE Transactions on Multimedia 19,no.2(2017):317-326.
[8]Eveno,Nicolas,and Laurent Besacier."A speaker independent"liveness"test for audio-visual biometrics."In Ninth European Conference onSpeech Communication and Technology.2005.
[9]Kazemi,Vahid,and Josephine Sullivan."One millisecond facealignment with an ensemble of regression trees."In Proceedings of the IEEEConference on Computer Vision and Pattern Recognition,pp.1867-1874.2014.
[10]Benhaim,Eric,Hichem Sahbi,and Guillaume Vitte."Designing relevantfeatures for visual speech recognition."In Acoustics,Speech and SignalProcessing(ICASSP),2013 IEEE International Conference on,pp.2420-2424.IEEE,2013
[11]LeCun,Yann,Koray Kavukcuoglu,and Clément Farabet."Convolutionalnetworks and applications in vision."In ISCAS,vol.2010,pp.253-256.2010.
[12]Taigman,Yaniv,Ming Yang,Marc'Aurelio Ranzato,and Lior Wolf."Deepface:Closing the gap to human-level performance in face verification."InProceedings of the IEEE conference on computer vision and patternrecognition,pp.1701-1708.2014.
[13]Graves,Alex,Abdel-rahman Mohamed,and Geoffrey Hinton."Speechrecognition with deep recurrent neural networks."In Acoustics,speech andsignal processing(icassp),2013 ieee international conference on,pp.6645-6649.IEEE,2013.
[14]Collobert,Ronan,Jason Weston,Léon Bottou,Michael Karlen,KorayKavukcuoglu,and Pavel Kuksa."Natural language processing(almost)fromscratch."Journal of Machine Learning Research 12,no.Aug(2011):2493-2537.
[15]Jaitly,Navdeep,Patrick Nguyen,Andrew Senior,and VincentVanhoucke."Application of pretrained deep neural networks to large vocabularyspeech recognition."In Thirteenth Annual Conference of the InternationalSpeech Communication Association.2012.
[16]Seymour,Rowan,Darryl Stewart,and Ji Ming."Comparison of imagetransform-based features for visual speech recognition in clean and corruptedvideos."Journal on Image and Video Processing 2008(2008):14.
[17]Kingsbury,Brian."Lattice-based optimization of sequenceclassification criteria for neural-network acoustic modeling."In Acoustics,Speech and Signal Processing,2009.ICASSP 2009.IEEE International Conferenceon,pp.3761-3764.IEEE,2009.
[18]Kingsbury,Brian,Tara N.Sainath,and Hagen Soltau."Scalable minimumBayes risk training of deep neural network acoustic models using distributedHessian-free optimization."In Thirteenth Annual Conference of theInternational Speech Communication Association.2012.
[19]Zechner,Klaus,and Alex Waibel."Minimizing word error rate intextual summaries of spoken language."In Proceedings of the 1st NorthAmerican chapter of the Association for Computational Linguistics conference,pp.186-193.Association for Computational Linguistics,2000.
[20]Messer,K.,J.Matas,J.Kittler,J.Luettin,and G.Maitre."XM2VTSbd:Theextended M2VTS database,proceedings 2nd conference on audio and video-basebiometric personal verification(AVBPA99)."(1999).
[21]Luettin,Juergen,and Gilbert Maitre."Evaluation protocol for theXM2FDB database(Lausanne Protocol)."(1998):98-05.
附录2–关键特征
本节总结了最重要的高级功能。本发明的实施方式可以包括这些高级特征中的一个或多个,或者这些特征中的任何特征的任何组合。注意,每个特征因此可能是独立的发明,并且可以与一个或多个其他特征组合。
A.使用基于视位的机器学习模型进行“存活性”检查
一种存活性检测系统,其包括:
(i)接口,其被配置为接收视频流;
(ii)单词、字母、字符或数字生成器子系统,其被配置为生成一个或多个单词、字母、字符或数字并将其输出到终端用户;
(iii)计算机视觉子系统,其被配置为分析接收到的视频流,并且使用唇读处理子系统或视位处理子系统来确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字,并且输出终端用户是“活”人的置信度分数。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统使用基于视位的机器学习模型。
·生成器子系统配置为生成随机单词、字母、字符或短语,并且将其输出到终端用户。
·随机单词、字母、字符或短语是从大型数据语料库中选择的。
·唇读处理子系统跟踪并提取终端用户嘴唇的移动。
·机器学习模型是深度神经网络模型。
·唇读处理子系统处理视频流并提取视位特征。
·唇读处理子系统实施特征提取方法,诸如DCT(离散余弦变换)、PCA(主成分分析)、LDA(线性判别分析)特征提取方法或学习特征提取方法。
·唇读处理子系统使用高斯混合模型(GMM)、隐马尔可夫模型(HMM)和/或深度神经网络技术。
·唇读处理子系统实施照明补偿方法。
·唇读处理子系统实施自动照明补偿算法,诸如自动和自适应对比度受限的自适应直方图均衡(CLAHE)算法。
·接口还被配置为接收音频流。
·使用算法来合并视频流和音频流。
·计算机视觉子系统被配置为当置信度分数高于预定阈值时认证终端用户。
·系统准许或拒绝终端用户访问在连接的设备上运行的应用程序。
·实施置信度评分算法,该算法将提取的视位特征、检测到的语音以及生成的单词、字母、字符或数字进行比较。
用于存活性检测的方法
一种用于存活性检测的方法,该方法包括:
(i)接收视频流;
(ii)生成一个或多个单词、字母、字符或数字并且将其输出到终端用户;
(iii)分析接收到的视频流,并且使用唇读处理技术或视位处理技术确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字,并且输出终端用户是“活”人的置信度分数。
B.认证
一种认证系统,其用于评估由基于计算机的系统查看的人是否被认证,该系统包括:
(i)接口,其被配置为接收视频流;
(ii)单词、字母、字符或数字生成器子系统,其被配置为生成一个或多个单词、字母、字符或数字并将其输出到终端用户;
(iii)计算机视觉子系统,其被配置为:(a)分析接收到的视频流;以及(b)使用唇读处理子系统或视位处理子系统来确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字;以及(c)将来自唇读处理子系统或视位处理子系统的数据与对应于所述人所声称的身份的存储数据进行比较;以及(d)输出终端用户是他们所声称的人的置信度分数。
一种认证系统,其包括
(i)接口,其被配置为接收视频流;
(ii)单词、字母、字符或数字生成器子系统,其被配置为生成一个或多个单词、字母、字符或数字并将其输出到终端用户;
(iii)计算机视觉子系统,其被配置为分析接收到的视频流,并且使用唇读处理子系统或视位处理子系统确定终端用户是否已经说出或模仿了该单词、字母、字符或数字或者每个单词、字母、字符或数字,并且输出终端用户是“活”人的置信度分数。
其中计算机视觉子系统被配置为当置信度分数高于预定阈值时认证终端用户。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·计算机视觉子系统使用基于视位的机器学习模型。
·生成器子系统被配置为生成随机单词、字母、字符或短语,并将其输出到终端用户。
·随机单词、字母、字符或短语是从大型语料库中选择的。
·计算机视觉子系统实施自动和自适应对比度受限的自适应直方图均衡(CLAHE)算法。
·唇读处理子系统处理视频流并提取视位特征。
·系统准许或拒绝终端用户访问在连接的设备上运行的应用程序。
·实施置信度评分算法,该算法将提取的视位特征、检测到的语音以及生成的随机短语进行比较。
C.具有照明补偿的唇读
一种唇读系统,其包括
(i)接口,其被配置为接收视频流,以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中唇读处理子系统实施自动照明补偿算法。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统分析每个视频帧,并且针对每个视频帧自适应选择照明补偿算法的参数。
·照明补偿算法基于对比度受限的自适应直方图均衡(CLAHE)。
·对于每个视频帧,使用熵曲线方法来选择最佳的图块大小和修剪限度。
·与最大曲率点相关联的修剪限度被选择为最佳设置。
·照明补偿算法使用分类模型,利用数据集来训练该分类模型,该数据集包含具有变化的灯光条件的视频帧。
·训练数据集使用针对视频帧的每个像素找到最佳值的3维伽马掩模来扩展。
D.语速检测
一种唇读系统,其用于确定终端用户的语速,该唇读系统包括:
(iii)接口,其被配置为接收视频流,以及
(iv)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,
其中计算机视觉子系统基于对终端用户嘴唇移动的分析来确定并输出终端用户的语速。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统使用基于视位的机器学习模型。
·唇读处理子系统实施照明补偿方法。
·唇读处理子系统处理视频流并提取视位特征。
·使用自动音节化过程将视位特征转换为带时间戳的音节序列。
·计算机视觉子系统确定终端用户的每分钟音节的语速。
·计算机视觉子系统测量整个视频流中终端用户的音节的持续时间的变化。
·计算机视觉子系统通过对语速的分析来确定或推断终端用户的情绪状态。
·将语速与终端用户的已知语速的历史记录进行比较。
·将语速与从大型终端用户语料库获得的标准语速的历史记录进行比较。
·计算机视觉子系统被配置为分析包括多于一个人的视频流,并且推断出作为凸显的说话者的人。
E.适应姿势变动的唇读系统
一种唇读系统,其包括
(iii)接口,其被配置为接收视频流,以及
(iv)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中唇读处理子系统还被配置为动态地适应终端用户的头部旋转或移动的任何变动。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统处理视频流并提取视位特征。
·唇读处理子系统使用基于视位的机器学习模型。
·唇读处理子系统实施照明补偿方法。
·唇读处理子系统使用基于视位的神经网络模型。
·神经网络模型包括多个与姿势有关的自动编码器,在与终端用户的特定姿势或头部旋转相对应的视频帧的大型数据集上训练自动编码器中的每个。
F.包括拼接检测的唇读
一种唇读系统,其包括
(i)接口,其被配置为接收视频流,以及
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
其中计算机视觉子系统能够使用拼接检测方法根据跨连续视频帧的像素信息的分析来检测视频拼接攻击。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统执行照明补偿方法。
·唇读处理子系统处理视频流并且提取视位特征。
·唇读处理子系统使用基于视位的机器学习模型。
·当跨连续帧的像素值的标准差高于预定阈值时,检测到视频拼接攻击。
·预定阈值是通过经验研究来确定的。
·拼接检测方法根据基于统计的方法。
·拼接检测方法考虑了跨连续帧的帧级过渡,诸如终端用户的面部特征的速度和加速度。
·拼接检测方法实施基于机器学习的方法来检测视频拼接,该基于机器学习的方法分析跨连续帧的像素信息。
·计算机视觉子系统输出已经正确检测到视频拼接攻击的置信度分数。
·置信度分数还考虑了视频帧参数,诸如分辨率、照明和嘴唇移动。
G.针对嗓音受损而设计的唇读系统
一种用于嗓音受损的终端用户的自动唇读系统,其包括:
(i)接口,其被配置为接收视频流;
(ii)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统分析接收到的视频流,跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
(iii)在连接的设备上运行的软件应用程序,其被配置为从计算机视觉子系统接收所识别的单词或句子并且自动显示所识别的单词或句子。
可选的
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·计算机视觉子系统使用基于视位的机器学习模型。
·计算机视觉子系统实施照明补偿方法。
·计算机视觉子系统处理视频流并提取视位特征。
·该软件应用程序提供被配置为接收视频流的接口。
·其中表示基于通用视觉语音识别的模型的训练数据集用于训练机器学习模型。
·其中适应于特定终端用户的训练数据集用于训练机器学习模型。
·其中基于系统和所识别的单词或句子的交互,当终端用户操作或与系统交互时,训练数据集被自动更新。
·其中特定终端用户是气管切开术的患者。
H.AVSR系统
一种视听语音识别系统,其包括:
(iii)接口,其被配置为接收视频流和音频流,
(iv)语音识别子系统,其被配置为分析音频流,检测来自终端用户的语音,并且识别终端用户说出的单词或句子,
(v)计算机视觉子系统,其被配置为使用唇读处理子系统或视位处理子系统来分析接收到的视频流,并且跟踪和提取终端用户嘴唇的移动,并且基于嘴唇移动来识别单词或句子,
(vi)合并子系统,其被配置为分析由语音识别子系统和唇读处理子系统所识别的单词或句子,并且输出候选单词或句子的列表,每个候选单词或句子与置信度分数或等级相关联,该置信度分数或等级指的是终端用户已经说出候选单词或句子的似然性或概率。
可选的:
·视频流包括图像数据,诸如2D图像数据、3D图像数据、红外图像传感器数据或深度传感器数据。
·视频流仅包含红外图像传感器数据。
·唇读处理子系统实施照明补偿方法。
·唇读处理子系统处理视频流并提取视位特征。
·唇读处理子系统使用基于视位的机器学习模型。
·合并子系统输出候选单词网格。
·合并子系统根据候选单词统计来构造路径权重。
·合并子系统标识单词网格的最佳路径。
·将候选单词或句子的列表与一组目标单词或句子进行比较。
·合并子系统确定每个候选单词或句子与每个目标单词或句子之间的编辑距离。
·编辑距离是单词级编辑距离或音形级编辑距离。
·每个候选单词或句子与针对每个目标单词或句子的一组相似性分数相关联。
·合并子系统对该组目标单词或句子进行排名。
·合并子系统输出具有最高排名目标单词或句子的列表。
·合并子系统输出最高排名目标单词或句子。
·合并子系统基于视频流或音频流的质量对置信度分数或等级进行加权或评估。
·合并子系统基于过去的发现和机器学习模型对置信度分数或等级进行加权或评估。
·使用语音或语言模型来更新置信度分数、等级或权重。
·在处理视频流和音频流时,合并子系统动态地更新候选单词或句子的列表及它们的置信度分数。
一般适用的特征和用例:
·计算机视觉子系统被本地部署在诸如智能电话、ATM、汽车信息娱乐或仪表板或其他设备的设备处;或部署在非基于云的服务器或数据中心内。
·计算机视觉子系统是基于云的计算机视觉子系统。
·该系统针对灯光条件差的环境进行了优化。
·该系统针对夜间条件进行了优化。
·当终端用户嘴唇或嘴的一部分被遮掩时,系统利用其他面部参数来推断由于嘴唇或嘴的一部分被遮掩而丢失的信息。
·该系统是水下唇读系统。
·该系统用于在线认证。
·该系统用于批准或授权在线交易。
·该系统被配置用于车载嗓音激活。
·该系统被配置用于个人助理(Siri、Cortana、Google Now、Echo)。
·系统被配置用于智能家居嗓音控制。
·该系统用于视频段(诸如监控)中的关键单词/短语识别;
·该系统被配置用于改进的现场直播字幕。
·该系统被配置用于在线交易的不可抵赖性。
·该系统被配置用于在线认证期间的反欺骗。
·该系统被配置为检测CCTV镜头中的“感兴趣的单词”、关键单词或短语。
·该系统被配置用于在社交媒体交互期间确保身份确认。
·该系统被配置用于防止在药物或酒精的影响下驱动/使用机具。
·该系统被配置用于与工业环境中的机器进行交互。
·该系统被配置为在公共环境中或在线交易期间检测愤怒并且在检测到愤怒之后发送警报。
·该系统被配置为检测疲倦并且当已经检测到疲倦时向外部或连接的设备发送警报。
·该系统被配置用于媒体的实时字幕。
·该系统被配置为用于协助听觉受损的对话(例如,谷歌眼镜应用程序,其从眼镜指向的人那里实时转录语音)。
·该系统被配置用于在嘈杂的环境中恢复退化的语音。
·该系统被配置用于行程检测。
·该系统被配置用于语音训练或治疗。
·针对特定类别的终端用户(诸如儿童或第二语言的终端用户或遭受中风的终端用户)定制语音训练或治疗。
·该系统被配置用于多语言终端用户。
·该系统被配置用于谎言检测。
·该系统被配置用于增强的交互式嗓音识别系统。
·该系统实时操作。
·实施上述系统的智能电话、平板电脑、笔记本电脑、台式机、车载仪表板。
注意
应当理解,上述布置仅是对本发明原理的应用的说明。在不脱离本发明的精神和范围的情况下,可以设计出许多修改和替代布置。虽然已经在附图中示出,并且结合当前被认为是本发明的最实际和优选示例以特殊性和细节在上文充分描述了本发明,但对于本领域的普通技术人员来说显而易见的是,在不脱离如本文所述的本发明的原理和构思的情况下可以进行许多修改。
- 一种陶瓷泥浆存浆量检测系统以及搅拌池
- 一种梁体双层存梁检测系统