卸载服务器和卸载程序
文献发布时间:2023-06-19 11:27:38
技术领域
本发明涉及一种将功能处理自动卸载(分流)到GPU(Graphics Processing Unit:图形处理器)等加速器(accelerator)的卸载服务器(offload server:分流服务器)和卸载程序(offload program:分流程序)。
背景技术
近年来,IoT(Internet of Things:物联网)技术正在发展,接连出现通过网络使用云技术来分析在设备侧收集到的数据且使其可视化的应用程序。
现有IoT的服务大多为从设备到网络、应用程序一体化架构的封闭型(silostype)。但是,为了进一步降低成本而提供各种各样的服务,OpenIoT(开放式物联网)的概念引起瞩目,该OpenIoT是指多个应用程序共享设备,使云、网络、设备的资源动态合作来提供服务。
在OpenIoT中,期望共享城市中的多个团体所持有的监视摄像头,用于寻找迷路的孩子、发现恐怖分子等多种用途。但是,在该例子中,不管是在设备侧还是在云侧进行分析,将摄像头影像的图像处理用于多种用途都会使CPU计算资源庞大。
另一方面,近年来,为了应对IoT等各种各样的领域,使用CPU以外的异构的计算资源的情况正在增加。例如,开始由强化了GPU(Graphics Processing Unit)(加速器)的服务器进行图像处理,或者由FPGA(Field Programmable Gate Array:现场可编程门阵列)(加速器)来加速信号处理。在Amazon Web Services(亚马逊网络服务:AWS)(注册商标)中,提供了GPU实例、FPGA实例,还能按需使用这些资源。Microsoft(注册商标)使用FPGA来使检索高效化。
在OpenIoT环境中,期待使用服务协作技术等来创造出各种各样的应用程序,并且通过进一步有效使用高端硬件,能够期待运行的应用程序的高性能化。但是,为此需要与运行的硬件对应进行编程、设定。例如,要求有CUDA(Compute Unified DeviceArchitecture:统一计算设备架构)、OpenCL(Open Computing Language:开放计算语言)等大量的技术知识,难度较大。
为了在用户的IoT应用程序中能够易于使用GPU或FPGA而有以下要求。即,当在OpenIoT环境中部署所运行的图像处理、加密处理等的通用应用程序时,期望由OpenIoT的平台对应用逻辑进行分析,且自动将处理(任务)向GPU、FPGA卸载。
(Tacit Computing技术)
向面向OpenIoT的平台,作为用于在服务中自由使用设备的机制,而提出了TacitComputing技术(参照非专利文献1)。Tacit Computing是能够根据设备在该时间点保持的实时数据,按需发现保持用户所需的数据的设备并使用的技术。
图11是用于说明Tacit Computing的概要的图。
在Tacit Computing中,通过从云层2、网络层3、设备层4这3层中发现适合向用户提供的服务的资源并使其协作,来满足该用户的需要,继续提供服务(图11的附图标记a)。在云层2中设置有数据中心(DC:data center)30,在网络层3中设置有网络边缘20,在设备层4中设置有网关10。另外,为了应对3层的结构中的时时刻刻变化的状况,尽可能在接近产生数据的现场的设备层中进行处理(图11的附图标记b)。通过在更低的层中进行处理,能够削减网络流量(图11的附图标记c)、抑制隐私性高的数据的流出(图11的附图标记d)。
在该Tacit Computing中,作为其要素技术,使用实时数据检索技术和设备虚拟化技术。
实时数据检索技术是用于检索提供用户所需数据的设备的技术。作为IoT服务的例子,有在桥等设施上设置多个传感器来监视劣化状况等的服务。在该情况下,由于劣化状况不太可能急剧发展,因此,可以按数小时等的周期将多个点的传感器数据上传到云上,通过统计软件或机械学习来分析劣化状况的变化。与此相对,在向定点摄像头拍摄到的人物进行信息引导、警告警报等的服务的例子中,人物在摄像头中仅出现几秒左右,另外,可以说只有拍摄到该人物的摄像头的影像对该人物来说才是有意义的数据。这样,将在设备层产生且时时刻刻变化的数据称作实时数据。
为了检索用户所需的该实时数据,在Tacit Computing中,无需等待将数据上传到云层,而在下位层中配置进行分析的功能,在该下位层中检索实时数据。
例如,朋友参加了公路接力赛跑预选赛,想要自动连接拍摄到该朋友的摄像头的影像。在该情况下,例如当请求将朋友的运动员号码作为检索关键字时,在TacitComputing中,在带有摄像头的网关或网络边缘中配置OpenCV(Open Source ComputerVision Library:开源计算机视觉库)等图像分析功能。然后,在接近摄像头的场所对影像进行分析,通过图像分析提取朋友的运动员号码,由此能够确定拍摄到朋友的摄像头。这样一来,在Tacit Computing中使用实时数据检索技术。
接着,在通过实时数据检索技术确定了想要利用的设备的情况下,需要实际使用该设备。IoT设备由多个制造商开发,使用时的协议、接口、地址等按每种设备而不同。因此,通过设备虚拟化技术来吸收各个设备中的接口的差异。
例如,在上述的例子中,根据获取摄像头影像那样的共同的请求,在带有摄像头的网关(Gateway)等中按每种设备设置适配器来进行协议等的转换,在此基础上进行与各个摄像头对应的请求。通过使用这种设备虚拟化技术,用户能够在没有意识到各个设备的差异的情况下来使用该设备。
(向GPU的卸载)
将GPU的计算能力用于图像处理以外的其他用途的GPGPU(General Purpose GPU:通用图形处理器)的开发环境CUDA正在发展。CUDA是面向GPGPU的开发环境。另外,作为用于将GPU、FPGA、多核CPU等的异构硬件统一地进行处理的标准规格,还出现了OpenCL。
在CUDA或OpenCL中,通过C语言的扩展来进行编程。但是,需要描述GPU等设备与CPU之间的内存拷贝、释放等,描述的难度高。实际上,掌握CUDA或OpenCL的技术人员数量并不多。
为了易于执行GPGPU而存在以下技术:在指令形式(在源代码中插入命令行的形式)下,指定应该进行loop语句等并行处理的位置,编译器(compiler)按照指令将其转换为面向设备的代码。作为技术规范有OpenACC(Open Accelerator)等,作为编译器有PGI编译器(注册商标)等。例如,在使用OpenACC的例子中,用户在由C/C++/Fortran语言来书写的代码中指定由OpenACC指令来进行并行处理等。PGI编译器检查代码的并行可能性,生成GPU用、CPU用执行二进制,来实现执行模块化。IBM JDK(注册商标)支持将符合Java(注册商标)的lambda形式的并行处理指定卸载给GPU的功能。通过使用这些技术,程序员无需意识到向GPU存储器的数据分配等。
这样,能够通过OpenCL、CUDA、OpenACC等技术向GPU进行卸载处理。
现有技术文献
非专利文献
非专利文献1:Y.Yamato,T.Demizu,H.Noguchi and M.Kataoka,“Automatic GPUOffloading Technology for Open IoT Environment,”IEEE Internet of ThingsJournal,DOI:10.1109/JIOT.2018.2872545,Sep.2018.
非专利文献2:Y.Tanaka,M.Yoshimi.M.Miki and T.Hiroyasu,"EvaluationofOptimization Method for Fortran Codes with GPU AutomaticParallelizationCompiler,"IPSJ SIG Technical Report,2011(9),pp.1-6,2011.
非专利文献3:Y.Yamato,M.Muroi,K.Tanaka and M.Uchimura,"Development ofTemplate Management Technology for Easy Deployment of Virtual Resources onOpenStack,"Journal of Cloud Computing,Springer,2014,3:7,DOI:10.1196/s13677-014-0007-3,June 2014.
非专利文献4:Y.Yamato,"Automatic verification technology of softwarepatches for user virtual environments on IaaS cloud,"Journal of CloudComputing,Springer,2015,4:4,DOI:10.1196/s13677-015-0028-6,Feb.2015.
发明内容
通过上述的OpenCL、CUDA、OpenACC等技术,能够向GPU进行卸载处理。
然而,即使能进行卸载处理本身,合适的卸载也有很多技术问题。例如,有Intel编译器(注册商标)那样的具有自动并行化功能的编译器。在自动并行化时,提取程序上的for语句(循环语句:iteration statements)等并行处理部。然而,在使用GPU并行地进行动作的情况下,由于CPU-GPU存储器间的数据交换附加处理,很多时候性能并不好。当使用GPU来加速时,技能持有者需要使用OpenCL或CUDA进行调优、使用PGI编译器等搜索合适的并行处理部。还有以下例子:在for语句少的标准应用程序中,对各for语句循环地尝试是否进行并行处理来进行性能测定,搜索最优的并行处理部(参照非专利文献2)。
这样,没有技能的用户难以使用GPU使应用程序高性能化,即使在使用自动并行化技术的情况下,是否并行进行for语句的试错调优等、直到开始使用为止要花费大量的时间。
非专利文献1的技术的主要目的在于自动提取应用程序的合适的并行处理部,能高速化的应用程序不怎么多。
另外,在非专利文献1中,通过使用遗传算法来对在GPU处理中有效的并行处理部进行自动调优,但根据CPU-GPU存储器间的数据传输,还存在无法实现高性能化的应用程序。
因此,没有技能的用户难以使用GPU使应用程序高性能化,即使在使用自动并行化技术等的情况下,有时也无法实现能否并行处理的试错及高速化。
本发明是鉴于该点而完成的,其要解决的技术问题在于,提供一种能够通过减少CPU-GPU间的数据传输次数并且将应用程序的特定处理自动地卸载给加速器来提高整体的处理能力的卸载服务器和卸载程序。
为了解决所述技术问题,技术方案1是一种卸载服务器,该卸载服务器用于将应用程序的特定处理卸载到加速器,其特征在于,具有应用程序代码分析部、数据传输指定部、并行处理指定部、并行处理模式制作部、性能测定部和可执行文件制作部,其中,所述应用程序代码分析部分析应用程序的源代码;所述数据传输指定部分析在所述应用程序的loop语句中使用的变量的参照关系,针对可以在循环外进行数据传输的数据,使用明示指定在循环外进行数据传输的明示指定行来进行数据传输指定;所述并行处理指定部确定所述应用程序的loop语句,且针对所确定的各所述loop语句来指定所述加速器中的并行处理指定语句进行编译;所述并行处理模式制作部制作并行处理模式,该并行处理模式是指:将出现编译错误的loop语句从卸载对象中排除,并且对没有出现编译错误的loop语句指定是否进行并行处理;所述性能测定部编译所述并行处理模式的所述应用程序且将其配置在加速器验证装置中,执行卸载到所述加速器时的性能测定处理;所述可执行文件制作部根据性能测定结果从多种所述并行处理模式中选择最高处理性能的并行处理模式,且编译最高处理性能的所述并行处理模式来制作可执行文件。
这样一来,能够减少CPU-GPU间的数据传输次数并且将应用程序的特定处理自动地卸载给加速器,提高整体的处理能力。据此,例如即使是没有CUDA等技能的用户也能使用加速器进行高性能处理。另外,能够使没有深入研究通过现有GPU实现高性能化的面向通用的加速器的应用程序高性能化。另外,能够向不是高性能计算用服务器的通用的机器的加速器进行卸载。
技术方案2在技术方案1所述的卸载服务器的基础上,其特征在于,所述数据传输指定部使用以下明示指定行来进行数据传输指定:明示指定从CPU向GPU进行数据传输的明示指定行;和明示指定从GPU向CPU进行数据传输的明示指定行。
这样,通过例如与由GA(Genetic Algorithm:遗传算法)进行的并行处理的提取一起进行使用明示指示行的数据传输指定,能够减少从CPU向GPU、另外从GPU向CPU的数据传输次数。
技术方案3在技术方案1或2所述的卸载服务器的基础上,其特征在于,当在CPU程序端(program side)定义的变量和在GPU程序端参照的变量重叠时,所述数据传输指定部指示从CPU向GPU进行数据传输,将指定数据传输的位置在进行GPU处理的loop语句或其上位的loop语句中设为不包含该变量的设定、定义的最上位的循环,当在GPU程序端设定的变量和在CPU程序端参照的变量重叠时,所述数据传输指定部指示从GPU向CPU进行数据传输,将指定数据传输的位置在进行GPU处理的loop语句或其上位的loop语句中设为不包含该变量的参照、设定、定义的最上位的循环。
这样一来,通过以尽可能在上位的循环中一并进行数据传输的方式来明示指示数据传输,能够避免按照循环每次都传输数据的非高效的传输。
技术方案4在技术方案3所述的卸载服务器的基础上,其特征在于,关于相同的变量,当从CPU向GPU的传输和从GPU向CPU的传输重叠的情况下,所述数据传输指定部使用明示指定数据传输的往返的明示指定行来进行数据传输指定。
这样,在针对相同的变量从CPU向GPU的传输和从GPU向CPU的传输重叠的情况下,一并指示数据复制的往返,据此,能够更有效地避免按照循环每次都传输数据的非高效的传输。
技术方案5在技术方案1所述的卸载服务器的基础上,其特征在于,具有存储部和性能测定试验提取执行部,其中,所述存储部具有用于存储性能试验项目的试验案例数据库;在面向用户的正式环境中配置可执行文件之后,所述性能测定试验提取执行部从所述试验案例数据库中提取性能试验项目来执行性能试验。
这样一来,能够执行自动卸载的性能试验,测试性能试验项目。
技术方案6在技术方案1所记载的卸载服务器的基础上,其特征在于,所述并行处理指定部具有卸载范围提取部和中间语言文件输出部,其中,所述卸载范围提取部确定能卸载到所述加速器的处理,且提取与卸载处理对应的中间语言;所述中间语言文件输出部输出中间语言文件,所述性能测定部在所述加速器验证装置中配置由中间语言导出的可执行文件,所述性能测定部使所述加速器验证装置执行所配置的二进制文件,且测定卸载时的性能,并且获取性能测定结果来返回给所述卸载范围提取部,所述卸载范围提取部进行其他的所述并行处理模式的提取,所述中间语言文件输出部根据所提取出的中间语言来试行性能测定,所述可执行文件制作部根据重复了规定次数的所述性能测定结果,来从多种所述并行处理模式中选择最高处理性能的并行处理模式,且编译最高处理性能的所述并行处理模式来制作可执行文件。
这样一来,通过提取与卸载处理对应的中间语言,输出中间语言文件,能够部署由中间语言导出的可执行文件。另外,为了搜索适宜的卸载区域而能够反复进行中间语言提取和可执行文件的部署。据此,能够从没有设想并行化的通用程序中自动提取适宜的卸载区域。
技术方案7在技术方案1所述的卸载服务器的基础上,其特征在于,所述并行处理指定部根据遗传算法来将没有出现编译错误的loop语句的数量作为基因长度,所述并行处理模式制作部将加速处理的情况设为1和0中的任一方,且将不进行加速处理的情况设为另一方的0或1,将能否进行加速处理映射到基因模式(遗传模式),所述并行处理模式制作部准备将所述基因的各值随机地制作为1或0的指定个体数的所述基因模式,所述性能测定部按照各个体来编译指定了所述加速器中的并行处理指定语句的应用程序代码且将其配置于所述加速器验证装置,所述性能测定部在所述加速器验证装置中执行性能测定处理,所述可执行文件制作部对全部个体进行性能测定,且以越是处理时间短的个体则适合度越高的方式进行评价,所述可执行文件制作部从全部个体中选择所述适合度比规定值高的个体来作为性能高的个体,且对所选择的个体进行交叉、突然变异的处理来制作下一代的个体,且在指定代数的处理结束后选择最高性能的所述并行处理模式作为解。
这样一来,最初进行可并行的loop语句的检查,接着针对可并行的循环语句组,使用GA在验证环境下反复进行性能验证试行,搜索合适的区域。在集中在可并行的loop语句(例如for语句)之后,以基因的部分的形式,保持可高速化的并行处理模式而进行重组,据此能够从可得到的庞大的并行处理模式中高效地搜索能高速化的模式。
技术方案8是一种卸载程序,该卸载程序用于使计算机作为技术方案1所述的卸载服务器来发挥作用。
这样一来,能够使用一般的计算机实现技术方案1所述的卸载服务器的各功能。
发明效果
根据本发明,能够提供一种能够通过减少CPU-GPU间的数据传输次数并且将应用程序的特定处理自动地向加速器卸载,来提高整体的处理能力的卸载服务器和卸载程序。
附图说明
图1是表示包括本发明实施方式所涉及的卸载服务器的Tacit Computing系统的图。
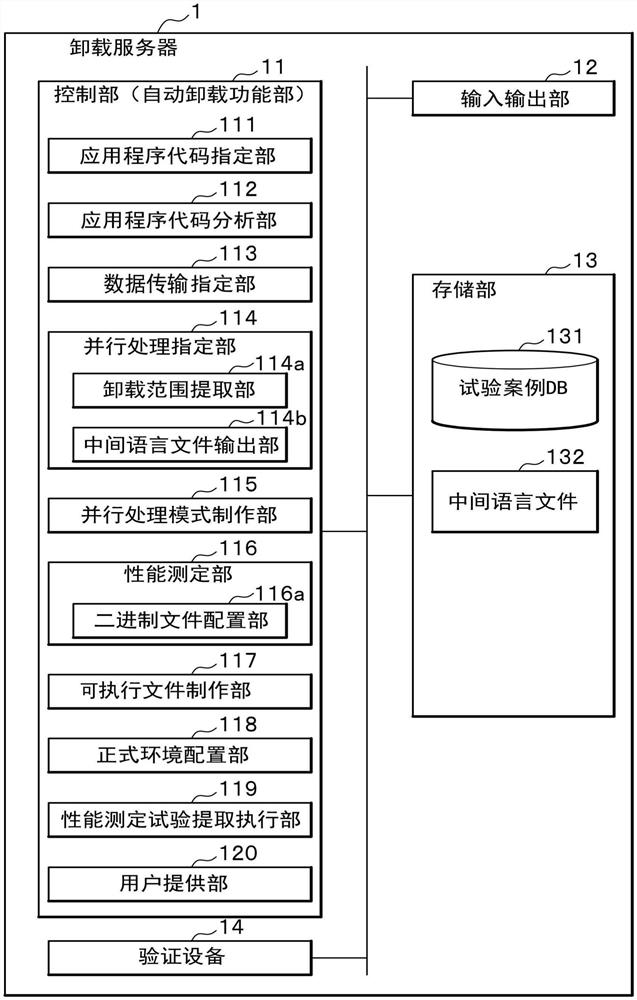
图2是表示上述实施方式所涉及的卸载服务器的结构例的功能框图。
图3是表示使用上述实施方式所涉及的卸载服务器的GA的自动卸载处理的图。
图4是表示基于上述实施方式所涉及的卸载服务器的Simple GA的控制部(自动卸载功能部)的搜索样子的图。
图5是表示在比较例的从CPU向GPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子的图。
图6是表示在比较例的从GPU向CPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子的图。
图7是表示在从上述实施方式所涉及的卸载服务器的CPU向GPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子的图。
图8是表示在从上述实施方式所涉及的卸载服务器的GPU向CPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子的图。
图9是表示在从上述实施方式所涉及的卸载服务器的GPU向CPU进行数据传输的情况下的loop语句中由CPU程序端定义的变量和由GPU程序端参照的变量重叠,另外由if语句等来执行变量的设定的情况下的例子的图。
图10A是说明上述实施方式所涉及的卸载服务器的安装的动作概要的流程图。
图10B是说明上述实施方式所涉及的卸载服务器的安装的动作概要的流程图。
图11是用于说明Tacit Computing的概要的图。
具体实施方式
接着,说明用于实施本发明的方式(以下称为“本实施方式”。)中的卸载服务器1等。
图1是表示包括本实施方式所涉及的卸载服务器1的Tacit Computing系统的图。
本实施方式所涉及的Tacit Computing系统的特征在于,除了图11所示的现有技术的Tacit Computing的结构以外,还包括卸载服务器1。卸载服务器1是将应用程序的特定处理卸载给加速器的卸载服务器。另外,卸载服务器1与位于云层2、网络层3、设备层4这3层的各装置以能够进行通信的方式来连接。在云层2中设置有数据中心30,在网络层3中设置有网络边缘20,在设备层4中设置有网关10。
在图11所示的现有技术的Tacit Computing的系统中,当专门地发现并使用设备时,首先以能提供服务为前提,因此没有考虑成本和性能。然而,为了持续且合理地提供服务,需要通过提高性能等来降低运用成本。
Tacit Computing实现OpenIoT的一部分概念,该OpenIoT发现并使用适合用户的设备。但是,当在Tacit Computing中即兴地使用设备、使设备协作时,忽视成本等。例如,在上述的例子不是监视马拉松选手,而是使用城市中的摄像头监视恐怖分子或监护高龄者的情况下,要求持续合理地提供对摄像头影像进行图像分析的服务。
因此,在包含本实施方式所涉及的卸载服务器1的Tacit Computing系统中,通过在设备层、网络层、云层的各个层中,适宜地进行功能配置或处理卸载来实现高效化。主要是实现将功能配置在3层的合适的位置来进行处理的功能配置高效化、和通过将图像分析等功能处理向GPU、FPGA等异构硬件卸载来实现高效化。在云层中,具有GPU、FPGA等异构的HW(硬件)(下面称为“异构设备”。)的服务器正在增加。例如,在Microsoft(注册商标)公司的Bing检索中也使用FPGA。这样,合理有效使用异构设备,例如,通过将矩阵计算等卸载给GPU,或者将FFT(Fast Fourier Transform:快速傅里叶变换)计算等特定处理卸载给FPGA,来实现高性能化。
下面,对本实施方式所涉及的卸载服务器1进行卸载处理时的结构例进行说明,该卸载处理是Tacit Computing系统中的面向用户的服务使用的在后台进行的处理。
如上所述,Tacit Computing系统是按照用户的期望使用合适的设备,专门地服务化的系统。例如,在非专利文献1中,使用图像分析和网络摄像头来实现监视服务,该监视服务是指,切换城市中的摄像头来持续地监视作为对象的人的服务。在这种情况下假想以下情况:第一天以试用等形式向用户提供服务,在其后台进行图像分析的卸载处理,在第二天以后将图像分析卸载给GPU来以合理的价格提供监视服务。
图2是表示本发明实施方式所涉及的卸载服务器1的结构例的功能框图。
卸载服务器1是将应用程序的特定处理自动卸载给加速器的装置。
如图2所述,卸载服务器1构成为包括控制部11、输入输出部12、存储部13和验证设备14(Verification machine)(加速器验证装置)。
输入输出部12由通信接口和输入输出接口构成,其中,所述通信接口用于与属于云层、网络层和设备层的各设备等之间进行信息的收发;所述输入输出接口用于与触摸屏、键盘等输入装置、监视器等输出装置之间进行信息的收发。
存储部13由硬盘、闪存存储器、RAM(Random Access Memory)等构成。
在该存储部13中,存储试验案例DB(Test case database)131,并且暂时性存储用于执行控制部11的各功能的程序(卸载程序)、控制部11的处理所需的信息(例如,中间语言文件(Intermediate file)132)。
在试验案例DB131中存储性能试验项目。试验案例DB131存储与性能试验项目对应的价格(例如,IoT服务的收费信息)、性能(加速器的计算资源)等数据。
验证设备14包括GPU和FPGA(加速器)作为用于验证Tacit Computing的环境。
控制部11是负责卸载服务器1整体的控制的自动卸载功能部(AutomaticOffloading function)。控制部11例如通过未图示的CPU(Central Processing Unit)在RAM中展开并执行存储部13所存储的程序(卸载程序)来实现。
控制部11具有应用程序代码指定部(Specify application code)111、应用程序代码分析部(Analyze application code)112、数据传输指定部113、并行处理指定部114、并行处理模式制作部115、性能测定部116、可执行文件制作部117、正式环境配置部(Deployfinal binary files to production environment)118、性能测定试验提取执行部(Extract performance test cases and run automatically)119和用户提供部(Provideprice and performance to a user to judge)120。
<应用程序代码指定部111>
应用程序代码指定部111进行所输入的应用程序代码的指定。具体而言,应用程序代码指定部111确定向用户提供的服务的处理功能(图像分析等)。
<应用程序代码分析部112>
应用程序代码分析部112分析处理功能的源代码,掌握loop语句、FFT库调用等的结构。
<数据传输指定部113>
数据传输指定部113分析在应用程序的loop语句中使用的变量的参照关系,针对可以在循环(loop)外进行数据传输的数据,使用明示指定在循环外进行数据传输的明示指定行(#pragma acc data copyin/copyout/copy(a[…])其中,a为变量)进行数据传输指定。
数据传输指定部113使用以下明示指定行来进行数据传输指定:明示指定从CPU向GPU进行数据传输的明示指定行(#pragma acc data copyin(a[…]));明示指定从GPU向CPU进行数据传输的明示指定行(#pragma acc data copyout(a[…]));在关于相同的变量从CPU向GPU的传输和从GPU向CPU的传输重叠的情况下,一并明示指定数据复制的往返的明示指定行(#pragma acc data copy(a[…]))。
当在CPU程序端定义的变量和在GPU程序端参照的变量重叠时,数据传输指定部113进行从CPU向GPU进行数据传输的指示,将指定数据传输的位置设为,进行GPU处理的loop语句或其上位的loop语句中不包含该变量的设定、定义的最上位的循环。另外,当在GPU程序端设定的变量和在CPU程序端参照的变量重叠时,数据传输指定部113进行从GPU向CPU进行数据传输的指示,将指定数据传输的位置设为,由GPU进行处理的loop语句或其上位的loop语句中不包含该变量的参照、设定、定义的最上位的循环。
<并行处理指定部114>
并行处理指定部114确定应用程序的loop语句(循环语句),指定加速器中的并行处理指定语句对各loop语句进行编译。
并行处理指定部114具有卸载范围提取部(Extract offloadable area)114a和中间语言文件输出部(Output intermediate file)114b。
卸载范围提取部114a确定loop语句、FFT等能够向GPU和FPGA卸载的处理,且提取与卸载处理对应的中间语言。
中间语言文件输出部114b输出所提取的中间语言文件132。中间语言提取不是一次就结束,为了搜索合适的卸载区域、且为了通过试行来优化执行而反复进行中间语言提取。
<并行处理模式制作部115>
并行处理模式制作部115制作并行处理模式,该并行处理模式是指,将出现编译错误的loop语句(循环语句)排除在卸载对象外,并且指定是否对没有出现编译错误的循环语句进行并行处理。
<性能测定部116>
性能测定部116编译并行处理模式的应用程序,将其配置于验证设备14,执行向加速器卸载时的性能测定处理。
性能测定部116具有二进制文件配置部(Deploy binary files)116a。二进制文件配置部116a在具有GPU和FPGA的验证设备14中部署(配置)由中间语言导出的可执行文件。
性能测定部116执行所配置的二进制文件,测定卸载时的性能,并且将性能测定结果返回给卸载范围提取部114a。在该情况下,卸载范围提取部114a进行其他的并行处理模式提取,中间语言文件输出部114b根据提取出的中间语言,试行性能测定(参照后述图3的附图标记e)。
<可执行文件制作部117>
可执行文件制作部117根据重复规定次数的性能测定结果,从多种并行处理模式中选择最高处理性能的并行处理模式,编译最高处理性能的并行处理模式而制作可执行文件。
<正式环境配置部118>
正式环境配置部118将制作的可执行文件配置在面向用户的正式环境中(“最终二进制文件向正式环境的配置”)。正式环境配置部118确定指定了最终的卸载区域的模式,且将其部署在面向用户的正式环境中。
<性能测定试验提取执行部119>
在配置了可执行文件之后,性能测定试验提取执行部119从试验案例DB131中提取性能试验项目,执行性能试验(“最终二进制文件向正式环境的配置”)。
在配置了可执行文件之后,为了向用户示出性能,性能测定试验提取执行部119从试验案例DB131中提取性能试验项目,自动执行提取出的性能试验。
<用户提供部120>
用户提供部120向用户提示基于性能试验结果的价格和性能等信息(“价格和性能等信息向用户的提供”)。在试验案例DB131中存储有与性能试验项目对应的价格、性能等数据。用户提供部120读出与存储在试验案例DB131中的试验项目对应的价格、性能等数据,将其与上述性能试验结果一起提示给用户。用户基于被提示的价格和性能等信息来判断IoT服务的付费使用的开始。在此,在向正式环境的一并部署中可以使用非专利文献3的现有技术,另外,在性能自动试验中可以使用非专利文献4的现有技术。
[遗传算法的适用]
卸载服务器1在卸载的优化中能够使用GA。使用GA的情况下的卸载服务器1的结构如下所述。
即,并行处理指定部114根据遗传算法,将没有出现编译错误的loop语句(循环语句)的数量作为基因长度。并行处理模式制作部115设进行加速处理的情况为1或0中的任一方、且设没有进行加速处理的情况为另一方的0或1,将能否加速处理映射到基因模式。
并行处理模式制作部115准备将基因的各值随机地制作为1或0的指定个体数的基因模式,性能测定部116按照各个体,编译指定了加速器中的并行处理指定语句的应用程序代码,且配置在验证设备14中。性能测定部116在验证设备14中执行性能测定处理。
在此,在中间代中生成了与以前相同的并行处理模式的基因的情况下,性能测定部116使用相同的值作为性能测定值,而无需进行符合该并行处理模式的应用程序代码的编译、以及性能测定。
另外,性能测定部116将发生编译错误的应用程序代码、和性能测定没有在规定时间内结束的应用程序代码,作为超时来对待,而将其性能测定值设定为规定的时间(长时间)。
可执行文件制作部117对全部个体进行性能测定,以越是处理时间短的个体则适合度越高的方式进行评价。可执行文件制作部117从全部个体中选择适合度比规定值(例如,全部个数的上位n%,或者全部个数的上位m个n,m为自然数)高的个体作为性能高的个体,对所选择的个体进行交叉、突然变异的处理,制作下一代的个体。可执行文件制作部117在指定代数的处理结束后,选择最高性能的并行处理模式作为解。
下面,对如上述那样构成的卸载服务器1的自动卸载动作进行说明。
[自动卸载动作]
本实施方式的卸载服务器1是作为Tacit Computing的要素技术,适用于用户应用逻辑的GPU自动卸载技术的例子。
图3是表示使用卸载服务器1的GA的自动卸载处理的图。
如图3所示,卸载服务器1被适用于Tacit Computing的要素技术。卸载服务器1具有控制部(自动卸载功能部)11、试验案例DB131、中间语言文件132和验证设备14。
卸载服务器1获取用户所使用的应用程序代码(Application code)130。
用户利用OpenIoT资源(OpenIoTResources)15。OpenIoT资源15例如是各种设备(Device)151、具有CPU-GPU的装置152、具有CPU-FPGA的装置153、具有CPU的装置154。卸载服务器1将功能处理自动卸载给具有CPU-GPU的装置152、具有CPU-FPGA的装置153的加速器。
下面,参照图3的步骤编号来说明各部的动作。
<步骤S11:指定应用代码(Specify application code)>
在步骤S11中,应用程序代码指定部111(参照图2)确定向用户提供的服务的处理功能(图像分析等)。具体而言,应用程序代码指定部111进行所输入的应用程序代码的指定。
<步骤S12:分析应用代码(Analyze application code)>
在步骤S12中,应用程序代码分析部112(参照图2)分析处理功能的源代码,掌握loop语句、FFT库调用等的结构。
<步骤S13:提取卸载范围(Extract offloadable area)>
在步骤S13中,并行处理指定部114(参照图2)确定应用程序的loop语句(循环语句),针对各循环语句,指定加速器中的并行处理指定语句进行编译。具体而言,卸载范围提取部114a(参照图2)确定loop语句、FFT等能向GPU和FPGA卸载的处理,提取与卸载处理对应的中间语言。
<步骤S14:输出中间文件(Output intermediate file)>
在步骤S14中,中间语言文件输出部114b(参照图2)输出中间语言文件132。中间语言提取不是一次就结束,为了搜索合适的卸载区域、且为了通过试行来优化而重复进行中间语言提取。
<步骤S15:编译错误(Compile error)>
在步骤S15中,并行处理模式制作部115(参照图2)制作并行处理模式,该并行处理模式是指,将出现编译错误的loop语句排除在卸载对象外,并且指定是否对没有出现编译错误的循环语句进行并行处理。
<步骤S21:部署二进制文件(Deploy binary files)>
在步骤S21中,二进制文件配置部116a(参照图2)在具有GPU和FPGA的验证设备14中部署由中间语言导出的可执行文件。
<步骤S22:测定性能(Measure performances)>
在步骤S22中,性能测定部116(参照图2)执行所配置的文件,测定卸载时的性能。
为了使卸载的区域更合适,将该性能测定结果返回给卸载范围提取部114a,卸载范围提取部114a进行其他模式的提取。然后,中间语言文件输出部114b根据提取出的中间语言,试行性能测定(参照图3的附图标记e)。
如图3的附图标记e所示,控制部11反复执行上述步骤S12至步骤S22。总结控制部11的自动卸载功能如下。即,并行处理指定部114确定应用程序的loop语句(循环语句),对各循环语句指定GPU中的并行处理指定语句且进行编译。然后,并行处理模式制作部115制作并行处理模式,该并行处理模式是指,将出现编译错误的loop语句排除在卸载对象外,并且指定对没有出现编译错误的loop语句是否进行并行处理。然后,二进制文件配置部116a对该并行处理模式的应用程序进行编译,且配置于验证设备14,性能测定部116在验证设备14中执行性能测定处理。可执行文件制作部117根据重复规定次数的性能测定结果,从多种并行处理模式中选择最高处理性能的模式,对选择模式进行编译来制作可执行文件。
<步骤S23:将最终的二进制文件配置到正式环境(Deploy final binary filesto production environment)>
在步骤S23中,正式环境配置部118确定指定了最终的卸载区域的模式,且部署在面向用户的正式环境中。
<步骤S24:提取并自动执行性能试验案例(Extract performance test casesand run automatically)>
在步骤S24中,在配置了可执行文件之后,为了向用户示出性能,性能测定试验提取执行部119从试验案例DB131中提取性能试验项目,自动执行所提取出的性能试验。
<步骤S25:提供价格和性能以供用户进行判断(Provide price and performanceto a user to judge)>
在步骤S25中,用户提供部120向用户提示基于性能试验结果的价格和性能等信息。用户根据所提示的价格和性能等信息来判断IoT服务的付费使用的开始。
假设上述步骤S11~步骤S25在用户使用IoT服务的后台进行、例如在暂时使用的第一天的期间进行等。另外,为了降低成本而在后台进行的处理也可以仅将功能配置优化及GPU和FPGA卸载作为对象。
如上所述,卸载服务器1的控制部(自动卸载功能部)11在适用于Tacit Computing的要素技术的情况下,为了进行功能处理的卸载,从用户所使用的应用程序的源代码中提取卸载的区域且输出中间语言(步骤S11~步骤S15)。控制部11将由中间语言导出的可执行文件配置在验证设备14中并执行,且验证卸载效果(步骤S21~步骤S22)。在重复进行验证,确定了适宜的卸载区域之后,控制部11在实际向用户提供的正式环境中部署可执行文件,作为服务来提供(步骤S23~步骤S25)。
[使用GA的GPU自动卸载]
GPU自动卸载是用于对GPU重复执行图3的步骤S12~步骤S22,最终得到在步骤S23中部署的卸载代码的处理。
GPU是一般不保证潜伏(latency),但适合通过并行处理提高生产量的设备。在IoT中运行的应用程序多种各样。IoT数据的加密处理、用于摄像头影像分析的图像处理、用于大量传感器数据分析的机械学习处理等具有代表性,这些处理多为重复性处理。因此,通过将应用程序的循环语句自动向GPU卸载来实现高速化。
但是,如现有技术所记载的那样,高速化需要适宜的并行处理。尤其是,在使用GPU的情况下,由于CPU与GPU之间的转储,大多数情况下如果数据量小或循环次数少则性能并不好。另外,根据存储器数据传输的时间等,有时能并行高速化的各个loop语句(循环语句)的组合不是最快的。例如,在10个for语句(循环语句)中第1个、第5个、第10个这3个与CPU相比能够高速化的情况下,第1个、第5个、第10个这3个的组合不一定最快等。
为了指定适宜的并行区域,有时尝试使用PGI编译器,对for语句能否并行进行试错来优化。但是,试错花费大量的工作量,当作为IoT服务来提供时,有导致用户使用开始的延迟,成本也提高的问题。
因此,在本实施方式中,从没有假想并行化的通用程序中自动提取适宜的卸载区域。因此,实现首先检查能并行的for语句,接着使用GA对能并行的for语句群在验证环境下重复进行性能验证试行来搜索适宜的区域。集中到能并行的for语句,在此基础上以基因部分的形式保持和重组能高速化的并行处理模式,据此,从能取得的庞大的并行处理模式中高效地搜索可高速化的模式。
[基于Simple GA的控制部(自动卸载功能部)11的搜索样子]
图4是表示基于Simple GA的控制部(自动卸载功能部)11的搜索样子的图。图4表示处理的搜索样子与for语句的基因序列映射。
GA是模仿生物的进化过程的组合优化方法之一。GA的流程图为,初始化→评价→选择→交叉→突然变异→结束判定。
在本实施方式中,在GA中,使用使处理简化的Simple GA。Simple GA是简化的GA,其中,基因仅为1、0,轮盘赌选择、一点交叉、突然变异使一个位置的基因的值变为与其相反的值等。
<初始化>
在初始化中,检查应用程序代码的全部for语句能否并行之后,将能并行的for语句映射到基因序列。在进行GPU处理的情况下设为1,在不进行GPU处理的情况下设为0。对基因准备指定的个体数M,对1个for语句随机地进行1、0的分配。
具体而言,控制部(自动卸载功能部)11(参照图2)获取用户所使用的应用程序代码(Application code)130(参照图3),如图4所示,根据应用程序代码130的代码模式(Codepatterns)141检查for语句能否并行。如图4所示,在从代码模式141中发现5个for语句的情况下(参照图4的附图标记f),对各for语句随机地分配1位,在此对5个for语句随机地分配5位的1或0。例如,在由CPU进行处理的情况下设为0,在输出给GPU的情况下设为1。但是,在该阶段中随机地分配1或0。
相当于基因长度的代码为5位,5位的基因长度的代码为2
<评价>
在评价中,进行部署和性能的测定(Deploy&performance measurement)(参照图4的附图标记g)。即,性能测定部116(参照图2)对相当于基因的代码进行编译且部署在验证设备14中来执行。性能测定部116进行标准测试性能测定。提高性能好的模式(并行处理模式)的基因的适合度。
<选择>
在选择中,根据适合度,选择高性能代码模式(Select high performance codepatterns)(参照图4的附图标记h)。性能测定部116(参照图2)根据适合度,选择指定的个体数的高适合度的基因。在本实施方式中,进行与适合度对应的轮盘赌选择和最高适合度基因的精英选择。
在图4中,示出所选择的代码模式(Select code patterns)142中的圆形标记(○标记)减少到3个作为搜索样子。
<交叉>
在交叉中,按一定的交叉率Pc,在所选择的个体间在某一点更换一部分基因,制作子个体。
使轮盘赌选择的某一模式(并行处理模式)和另一模式的基因交叉。一点交叉的位置是任意的,例如在上述5位的代码中的第3位进行交叉。
<突然变异>
在突然变异中,按一定的突然变异率Pm,将个体基因的各值从0变为1或者从1变为0。
另外,为了避免局部解而导入突然变异。另外,也可以是为了削减运算量而不进行突然变异的方式。
<结束判定>
如图4所示,进行交叉和突然变异后的下一代代码模式的生成(Generate nextgeneration code patterns after crossover&mutation)(参照图4的附图标记i)。
在结束判定中,重复进行指定的代数T次之后结束处理,将最高适合度的基因作为解。
例如,进行性能测定,选择10010、01001、00101这3个快的。下一代通过GA将这三个进行重组,例如创建新的模式(并行处理模式)10101(一例)。此时,将从0变为1等的突然变异任意地插入重组后的模式中。重复上述操作,找到最快的模式。确定指定代(例如,20代)等,将最后一代中剩余的模式作为最后的解。
<部署(配置)>
以相当于最高适合度的基因的、最高处理性能的并行处理模式,重新部署在正式环境中,且提供给用户。
<补充说明>
对存在相当数量的无法向GPU卸载的for语句(loop语句;循环语句)的情况进行说明。例如,尽管for语句有200个,但能向GPU卸载的for语句为30个左右。在此,排除错误的for语句,对这30个进行GA。
在OpenACC中有编译器,该编译器提取并执行由指令#pragma acc kernels指定且面向GPU的字节码,由此能够进行GPU卸载。通过在该#pragma中写入for语句的命令,能够判定该for语句在GPU中是否运转。
例如在使用了C/C++的情况下,分析C/C++的代码,找出for语句。当找出for语句时,在OpenACC中使用作为并行处理的文法的#pragma acc kernels对for语句进行写入。详细而言,在空的#pragma acc kernels一个个地加入for语句进行编译,如果出现错误,则该for语句本身无法进行GPU处理,因此将其排除。这样一来,找出剩余的for语句。并且,将没有出现错误的for语句作为长度(基因长度)。如果没有错误的for语句为5个,则基因长度为5,如果没有错误的for语句为10,则基因长度为10。此外,无法进行并行处理的是将以前的处理用于下一次的处理这样的与数据有依存关系的情况。
以上是准备阶段。接着进行GA处理。
得到了具有与for语句的数量对应的基因长度的代码模式。首先随机地分配并行处理模式10010、01001、00101、…。进行GA处理,且进行编译。此时,尽管是能卸载的for语句,但有时会出现错误。其是for语句为分层结构(指定任一个均能进行GPU处理)的情况。在该情况下,可以留下错误的for语句。具体而言,有使其成为处理时间变长的形态而使其超时的方法。
在验证设备14进行部署,进行标准测试,例如如果是图像处理则通过该图像处理进行标准测试,其处理时间越短,则评价为适应度越高。例如,设为处理时间的倒数,处理时间花费10秒设适应度为1,处理时间花费100秒则设适应度为0.1,处理时间花费1秒则设适应度为10。
选择适应度高的for语句,例如从10个中选择3~5个,进行重组来创作新的代码模式。在制作途中,有时制作出与以前相同的代码模式。在该情况下,无需进行相同的标准测试,因此使用与以前相同的数据。在本实施方式中,将代码模式和其处理时间存储在存储部13中。
以上对基于Simple GA的控制部(自动卸载功能部)11的搜索样子进行了说明。接着,叙述数据传输的一并处理方法。
[数据传输的一并处理方法]
如上所述,通过使用遗传算法来对在GPU处理中有效的并行处理部进行自动调优。然而,根据CPU-GPU存储器间的数据传输,还存在无法实现高性能化的应用程序。因此,没有技能的用户难以使用GPU来使应用程序高性能化,即使在使用自动并行化技术等的情况下也需要能否并行处理的试错,有时无法实现高速化。
因此,在本实施方式中,提供一种目的在于自动地由GPU使更多的应用程序高性能化并且能够减少向GPU的数据传输次数的技术。
<基本的思考方法>
在OpenACC等的规格中,除了指定由GPU进行并行处理的指示行之外,还定义了明示指定从CPU向GPU进行数据传输或从GPU向CPU进行数据传输的指示行(以下称为“明示指示行”)。OpenACC等的明示指示行是作为从CPU向GPU的数据传输的指令(directive:在行首记载有特殊的记号的指示和/或指定命令)的“#pragma acc data copyin”、作为从GPU向CPU的数据传输的指令的“#pragma acc data copyout”、和作为从CPU向GPU再向CPU的数据传输的指令的“#pragma acc data copy”等。
本发明为了减少非高效的数据传输,与由GA进行的并行处理的提取一起进行使用明示指示行的数据传输指定。
在本实施方式中,针对由GA生成的各个体,分析在loop语句中使用的变量数据的参照关系,针对并非按照循环每次都进行数据传输而可以在循环外进行数据传输的数据,明示指定在循环外进行数据传输。
<比较例>
下面,具体地对处理进行说明。
首先,对比较例进行叙述。
数据传输的种类有从CPU向GPU的数据传输、以及从GPU向CPU的数据传输。
图5和图6是表示比较例的自动卸载功能部进行处理的应用程序的源代码的loop语句(循环语句)的图,是在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。
比较例的自动卸载功能部是将数据传输指定部113从图2的控制部(自动卸载功能部)11中除去或者不执行数据传输指定部113的处理的情况下的例子。
《比较例的从CPU向GPU的数据传输》
图5是在比较例的从CPU向GPU进行数据传输的情况下的loop语句中当在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。另外,以下的记载以及图5中的loop语句的句首的(1)~(4)是为了便于说明而添加的(在其他附图及其说明中亦同样)。
图5所示的比较例的loop语句被记述在CPU程序端,
在(1)循环〔for|do|while〕{
}
中存在
(2)循环〔for|do|while〕{
},
并且其中存在
(3)循环〔for|do|while〕{
},
并且其中存在
(4)循环〔for〕{
}。
另外,在(1)循环〔for|do|while〕{
}中设定变量a,在(4)循环〔for|do|while〕{
}中参照变量a。
并且,在(3)循环〔for|do|while〕{
}中,由OpenACC的指令#pragma acc kernels(并行处理指定语句)指定基于PGI编译器的for语句等的可并行处理处理部(细节后述)。
在图5所示的比较例的loop语句中,在图5的附图标记j所示的时间每次从CPU向GPU进行数据传输。因此,要求减少向GPU的数据传输次数。
《比较例的从GPU向CPU的数据传输》
图6是在比较例的从GPU向CPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。
图6所示的比较例的loop语句被记述在CPU程序端,
在(1)循环〔for|do|while〕{
}
中存在
(2)循环〔for|do|while〕{
},
并且其中存在
(3)循环〔for|do|while〕{
},
并且其中存在
(4)循环〔for〕{
}。
另外,在(3)循环〔for|do|while〕{
}中,由OpenACC的指令#pragma acc kernels(并行处理指定语句)指定基于PGI编译器的for语句等的可并行处理处理部(细节后述)。
并且,在(4)循环〔for〕{
}中设定变量a,在(2)循环〔for|do|while〕{
}中参照变量a。
在图6所示的比较例的loop语句中,在图6的附图标记k所示的时间每次从GPU向CPU进行数据传输。因此,要求减少向CPU的数据传输次数。
接着,对基于本实施方式的卸载服务器1的数据传输的一并处理方法进行说明。
图7和图8是表示本实施方式的自动卸载功能部进行处理的应用程序的源代码的loop语句的图,是在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。
本实施方式的控制部(自动卸载功能部)11(参照图2)具有数据传输指定部113。
《本实施方式的从CPU向GPU的数据传输》
在本实施方式中,当在CPU程序端设定、定义的变量和在GPU程序端参照的变量重叠时,需要从CPU向GPU进行数据传输,而进行数据传输指定。
指定数据传输的位置被设为进行GPU处理的loop语句或其上位的loop语句中不包含该变量的设定、定义的最上位的循环(参照图7)。在进行for,do,while等循环的近前的位置设定数据传输指示行的插入位置。
图7是在从CPU向GPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。图7与比较例的图5对应。
图7所示的本实施方式的loop语句被记述在CPU程序端,
在(1)循环〔for|do|while〕{
}
中存在
(2)循环〔for|do|while〕{
},
并且其中存在
(3)循环〔for|do|while〕{
},
并且其中存在
(4)循环〔for〕{
}。
另外,在(1)循环〔for|do|while〕{
}中设定变量a,在(4)循环〔for〕{
}中参照变量a。
并且,在(3)循环〔for|do|while〕{
}中,由OpenACC的指令#pragma acc kernels(并行处理指定语句)指定基于PGI编译器的for语句等的可并行处理处理部(细节后述)。
在图7所示的本实施方式的loop语句中,在图7的附图标记l所示的位置,插入数据传输指示行,在此为插入变量a的copyin句节的#pragma acc data copyin(a[…])。
上述#pragma acc data copyin(a[…])被指定为不包含变量a的设定、定义的最上位的循环(在此,为(1)循环〔for|do|while〕中),其插入位置是进行for,do,while等循环的近前的位置(在此为(2)循环〔for|do|while〕之前)。
这样,在从CPU向GPU的数据传输中,通过在上述的位置插入变量a的copyin句节的#pragma acc data copyin(a[…])来明示指示数据传输。据此,能够尽可能在上位的循环一并进行数据传输,能够避免如所述图5的附图标记j所示的比较例那样按照循环每次都传输数据的非高效的传输。
《本实施方式的从GPU向CPU的数据传输(例子1)》
在本实施方式中,在由GPU程序端设定的变量和由CPU程序端参照、设定、定义的变量或者全局变量(global variable:所有的函数能够直接访问的变量)重叠的情况下,需要从GPU向CPU的数据传输,而进行数据传输指定。
指定数据传输的位置被设为进行GPU处理的loop语句或其上位的loop语句中不包含该变量的参照、设定、定义的最上位的循环(参照后述的图8)。数据传输指示行的插入位置被设置在进行for,do,while等循环的近前的位置。
在此,包含到“设定”是由于考虑到该设定在if语句等中执行或者不在if语句等中执行的情况(参照后述的图9)。另外,在条件中在CPU方还包含“定义”是为了不在变量的范围外展开的保护措施。全局变量有可能在解析对象源外被“参照”,因此,包含在条件中。
图8是在从GPU向CPU进行数据传输的情况下的loop语句中在CPU程序端定义的变量和在GPU程序端参照的变量重叠时的例子。图8与比较例的图6对应。
图8所示的本实施方式的loop语句被记述在CPU程序端,
在(1)循环〔for|do|while〕{
}
中存在
(2)循环〔for|do|while〕{
},
并且其中存在
(3)循环〔for|do|while〕{
},
并且其中存在
(4)循环〔for〕{
}。
另外,在(3)循环〔for|do|while〕{
}中,由OpenACC的指令#pragma acc kernels(并行处理指定语句)指定基于PGI编译器的for语句等的可并行处理处理部。
并且,在(4)循环〔for〕{
}中设定变量a,在(2)循环〔for|do|while〕{
}中参照变量a。
在图8所示的本实施方式的loop语句中,在图8的附图标记m所示的位置插入数据传输指示行,在此插入变量a的copyout句节的#pragma acc data copyout(a[…])。
上述#pragma acc data copyout(a[…])被指定为不包含变量a的参照、设定、定义的最上位的循环(在此为(1)循环〔for|do|while〕中),其插入位置为进行for,do,while等循环的近前的位置(在此为(2)循环〔for|do|while〕之前)。
如图8的附图标记n所示,在循环结束后执行上述copyout动作。
这样,在从GPU向CPU的数据传输中,通过在上述的位置插入变量a的copyout句节的#pragma acc data copyout(a[…])来明示指示数据传输。据此,能够尽可能在上位的循环中一并进行数据传输,能够避免如所述图6的附图标记k所示的比较例那样按照循环每次都传输数据的非高效的传输。
《本实施方式的从GPU向CPU的数据传输(例2)》
图9是在从GPU向CPU进行数据传输的情况下的loop语句中由CPU程序端定义的变量和由GPU程序端参照的变量重叠,另外在if语句等中执行变量的设定的情况下的例子。
图9所示的本实施方式的loop语句被记述在CPU程序端,
在(1)循环〔for|do|while〕{
}
中存在
(2)循环〔for|do|while〕{
},
并且其中存在
(3)循环〔for|do|while〕{
}
和
if(…){
},
并且,在该(3)循环〔for|do|while〕中存在
(4)循环〔for〕{
}。
另外,在(3)循环〔for|do|while〕{
}中,由OpenACC的指令#pragma acc kernels(并行处理指定语句)指定基于PGI编译器的for语句等的可并行处理处理部。
并且,在(4)循环〔for〕{
}中设定变量a,在(2)循环〔for|do|while〕{
}中参照变量a。
在图9所示的本实施方式的loop语句中,在图9的附图标记o所示的位置插入数据传输指示行,在此插入变量a的copyout句节的#pragma acc data copyout(a[…])。
上述#pragma acc data copyout(a[…])被指定为不包含变量a的参照、设定、定义的最上位的循环(在此为(1)循环〔for|do|while〕中),其插入位置是进行for,do,while等循环的近前的位置(在此为(2)循环〔for|do|while〕之前)。
如图9的附图标记p所示,在(3)循环结束后执行上述copyout动作。
在图9中,在(2)循环〔for|do|while〕中存在(3)循环〔for|do|while〕和if(…),在它们中分别进行变量a的“设定”。因此,如果上述#pragma acc data copyout(a[…])的插入不在图9的附图标记q所示的位置之前,在此为不在if(…){的,变量a的“设定”之前,则产生问题。例如,在图9的附图标记r所示的位置插入上述#pragma acc data copyout(a[…]),会产生问题。
这样,在从GPU向CPU的数据传输中,通过在上述的位置插入变量a的copyout句节的#pragma acc data copyout(a[…])来明示指示数据传输。据此,能够尽可能在上位的循环中一并进行数据传输,能够避免如所述图6的附图标记k所示的比较例那样按照循环每次都传输数据的非高效的传输。
《本实施方式的从CPU向GPU的数据传输和从GPU向CPU的数据传输的往返》
针对相同的变量,在从CPU向GPU的传输和从GPU向CPU的传输重叠的情况下,一起指示数据复制的往返。
具体而言,代替所述图7所示的本实施方式的loop语句的#pragma acc datacopyin(a[…]),插入#pragma acc data copy(a[…])。
上述#pragma acc data copy(a[…])被指定为不包含变量a的设定、定义的最上位的循环(在此为(1)循环〔for|do|while〕中),其插入位置为进行for,do,while等循环的近前的位置(在此为(2)循环〔for|do|while〕之前)。
这样,在从CPU向GPU的数据传输和从GPU向CPU的数据传输的往返中,通过在上述的位置插入变量a的copy句节的#pragma acc data copy(a[…])来明示指示数据传输。另外,通过使用上述#pragma acc data copy(a[…]),能够省略插入所述图8所示的上述#pragma acc data copyout(a[…])。
如以上在与图5~图9的比较例的对比中叙述的那样,在本实施方式中,以尽可能在上位的循环中一并进行数据传输的方式来明示指示数据传输,据此能够避免按照循环每次都传输数据的非高效的传输。
[GPU卸载处理]
通过上述的数据传输的一并处理方法,能够提取适合卸载的loop语句,避免非高效的数据传输。
但是,即使使用上述数据传输的一并处理方法,也存在不适合GPU卸载的程序。高效的GPU卸载需要进行卸载的处理的循环次数较多。
因此,在本实施方式中,作为正式的卸载处理搜索的前阶段,使用分析工具(profiling tool)来调查循环次数。使用分析工具能够调查各行的执行次数,因此,例如,能够将具有5000万次以上的循环的程序作为卸载处理搜索的对象等、事先进行分配。下面具体地进行说明(一部分与在所述图4中叙述的内容重复)。
在本实施方式中,首先,分析用于搜索卸载处理部的应用程序,掌握for,do,while等的loop语句。接着,执行采样处理,使用分析工具调查各loop语句的循环次数,根据是否有一定值以上的循环来判定是否正式地进行卸载处理部搜索。
在决定正式地进行搜索的情况下,进入GA的处理(参照所述图4)。在初始化步骤中,检查应用程序代码的全部loop语句能否并行之后,设对能并行的loop语句进行GPU处理的情况下为1,设不对能并行的loop语句进行GPU处理的情况下为0,映射到基因序列。准备指定个体数的基因,对基因的各值随机地分配1、0。
在此,在相当于基因的代码中,根据被指定为进行GPU处理的loop语句内的变量数据参照关系,追加数据传输的明示指示(#pragma acc data copyin/copyout/copy)。
在评价步骤中,编译相当于基因的代码且将其部署在验证设备中并且执行该代码,进行标准测试性能测定。提高性能好的模式的基因的适合度。相当于基因的代码如上所述被插入并行处理指示行(例如,参照图5的附图标记j)和数据传输指示行(例如,参照图7的附图标记l、图8的附图标记m、图9的附图标记o)。
在选择步骤中,基于适合度来选择指定个体数的高适合度的基因。在本实施方式中,进行与适合度对应的轮盘赌选择和最高适合度基因的精英选择。在交叉步骤中,按一定的交叉率Pc,在所选择的个体间在某一点更换一部分基因,制作子个体。在突然变异步骤中,按一定的突然变异率Pm,将个体的基因的各值从0变更为1或者从1变更为0。
当直到突然变异步骤结束,制作了指定个体数的下一代的基因时,与初始化步骤同样,追加数据传输的明示指示,重复进行评价、选择、交叉、突然变异步骤。
最后,在结束判定步骤中,在重复进行指定代数之后结束处理,将最高适合度的基因作为解。按照相当于最高适合度的基因的、最高性能的代码模式,重新部署在正式环境中,提供给用户。
下面,说明卸载服务器1的安装。本安装是用于确认本实施方式的有效性。
[安装]
说明使用通用的PGI编译器来将C/C++应用程序自动卸载的安装。
在本安装中,由于其目的在于确认GPU自动卸载的有效性,因此,对象应用程序为C/C++语言的应用程序,对于GPU处理本身,使用现有的PGI编译器进行说明。
C/C++语言在OSS(Open Source Software:开源软件)和proprietary软件的开发中有很高的人气,大量的应用程序是用C/C++语言开发的。为了确认一般用户所使用的应用程序的卸载,使用加密处理和图像处理等的OSS的通用应用程序。
GPU处理由PGI编译器来进行。PGI编译器是解释OpenACC的面向C/C++/Fortran的编译器。在本实施方式中,通过OpenACC的指令#pragma acc kernels(并行处理指定语句)指定for语句等能并行处理的处理部。据此能够提取面向GPU的字节码,通过执行该面向GPU的字节码来实现GPU卸载。并且,当for语句内的数据彼此依存而无法并行处理、或指定了嵌套(nest)的for语句的不同的多个层等时,会出现错误。能够一并通过#pragma acc datacopyin/copyout/copy等指令来明示指示数据传输。
将来,在还统一使用FPGA时,需要一次提取OpenCL等的共同的中间语言,且在FPGA、GPU等异构设备中执行。在本实施方式中,专注于卸载部自动提取,因此,GPU处理本身委托给使用CUDA(Compute Unified Device Architecture:统一计算设备架构)作为中间语言的PGI编译器。
与上述#pragma acc kernels(并行处理指定语句)的指定对应,通过在上述的位置插入OpenACC的copyin句节的#pragma acc data copyout(a[…]),来明示指定数据传输。
<安装的动作概要>
说明安装的动作概要。
通过Perl 5(Perl版本5)进行安装,进行以下处理。
在开始下述图10的流程的处理之前,准备高速化的C/C++应用程序和对该C/C++应用程序进行性能测定的标准测试工具。
当有使用C/C++应用程序的请求时,在安装时首先分析C/C++应用程序的代码,找出for语句,并且掌握在for语句内使用的变量数据等的程序结构。在句法分析中,使用LLVM/Clang的句法分析库(libClang的python binding)等。
在安装中,最初,为了预计该应用程序是否有GPU卸载效果,执行标准测试,掌握在上述句法分析中掌握的for语句的循环次数。使用GNU覆盖的gcov等掌握循环次数。作为分析工具已知有“GNU剖析工具(gprof)”、“GNU覆盖率测试工具(gcov)”。双方均能调查各行的执行次数,因此可以使用任一方。执行次数能够为,例如仅将具有1000万次以上的循环次数的应用程序作为对象,但该值可变更。
面向CPU的通用应用程序没有假想并行化来安装。因此,首先,需要排除GPU无法处理的for语句。因此,对各for语句逐句试行插入并行处理的#pragma acc kernels指令,判定在编译时是否出现错误。编译错误有若干种类。有在for语句中调用了外部例行程序的情况、在嵌套for语句中重复指定了不同的层的情况、存在由于break等在途中打断for语句的处理的情况、与for语句的数据有依存关系的情况等。根据应用程序,编译时错误的种类各种各样,还有这些情况以外的情况,但编译错误被排除在处理对象外,不插入#pragma指令。
大多数情况下编译错误难以自动应对,另外即使应对也不会有效果。在调用外部例行程序的情况下,有时能够通过#pragma acc routine来避免编译错误,但大多数外部调用都是库,即使包含这些库进行GPU处理,该调用也成为瓶颈而导致性能并不好。由于是逐句试行for语句,因此,关于嵌套的错误,不会发生编译错误。另外,在由于break等途中打断的情况下,并行处理需要使循环次数固定化,而需要进行程序改造。在与数据有依存关系的情况下,本身无法进行并行处理。
在此,在即使进行并行处理也没有出现错误的loop语句的数量为a的情况下,a为基因长度。基因的1与有并行处理指令对应,0与无并行处理指令对应,将应用程序代码映射到长度a的基因。
接着,作为初始值,准备指定个体数的基因序列。如在图4中说明的那样,基因的各值随机地分配0和1来制作。按照所准备的基因序列,在基因的值为1的情况下,将指定并行处理的指令#pragma acc kernels插入C/C++代码。在该阶段,在相当于某基因的代码中确定由GPU进行处理的部分。根据在上述Clang中解析出的、for语句内的变量数据的参照关系,基于上述的规则进行从CPU向GPU的数据传输和从GPU向CPU的数据传输的情况下的指令指定。
具体而言,从CPU向GPU的数据传输所需的变量由#pragma acc data copyin来指定(参照图7),从GPU向CPU的数据传输所需的变量由#pragma acc data copyout来指定(参照图8)。针对相同的变量,在copyin和copyout重叠的情况下,由#pragma acc data copy进行合并,简化记载。
由具有GPU的机器上的PGI编译器对被插入并行处理和数据传输的指令的C/C++代码进行编译。部署编译出的可执行文件,由标准测试工具来测定性能。
针对全部个体数,在标准测试性能测定后,按照标准测试处理时间来设定各基因序列的适合度。按照所设定的适合度,进行剩余的个体的选择。针对所选择的个体,进行交叉处理、突然变异处理、直接复制处理的GA处理,制作下一代的个体组。
针对下一代的个体,进行指令插入、编译、性能测定、适合度设定、选择、交叉、突然变异处理。在此,在GA处理中产生与以前相同模式的基因的情况下,针对该个体不进行编译、性能测定,而使用与以前相同的测定值。
在指定代数的GA处理结束后,将相当于最高性能的基因序列的带有指令的C/C++代码作为解。
其中,个体数、代数、交叉率、突然变异率、适合度设定、选择方法是GA的参数,另行指定。通过使上述处理自动化,本发明提出的技术能够使现有技术中需要专业人员的时间和技能的GPU卸载自动化。
图10A-B是说明上述的安装的动作概要的流程图,图10A和图10B用连接符来连接。
使用面向C/C++的OpenACC编译器进行以下处理。
<代码解析>
在步骤S101中,应用程序代码分析部112(参照图2)进行C/C++应用程序的代码解析。
在步骤S102中,并行处理指定部114(参照图2)确定C/C++应用程序的loop语句、参照关系。
在步骤S103中,并行处理指定部114使标准测试工具工作,掌握loop语句循环次数,分配阈值。
在步骤S104中,并行处理指定部114检查各loop语句的并行处理可能性。
控制部(自动卸载功能部)11在步骤S105的循环起始端与步骤S108的循环终端之间,将步骤S106-S107的处理重复loop语句的数量。
在步骤S106中,并行处理指定部114针对各loop语句,由OpenACC指定并行处理(#pragma acc kernels)且进行编译。
在步骤S107中,在错误时,并行处理指定部114将#pragma acc kernels从该for语句中除去。
在步骤S109中,并行处理指定部114对没有出现编译错误的for语句的数量进行计数,作为基因长度。
<指定个体数模式准备>
接着,并行处理指定部114准备指定个体数的基因序列作为初始值。在此,随机地分配0和1来制作。
在步骤S110中,并行处理指定部114将C/C++应用程序代码映射到基因,进行指定个体数模式准备。
按照所准备的基因序列,将在基因的值为1的情况下指定并行处理的指令插入C/C++代码(例如参照图4中的(b)的#pragma指令)。
控制部(自动卸载功能部)11在步骤S111的循环起始端与步骤S120的循环终端之间,将步骤S112-S119的处理重复进行指定代数的次数。
另外,在上述重复进行指定代数的次数的过程中,进一步在步骤S112的循环起始端与步骤S117的循环终端之间,对步骤S113-S116的处理重复进行指定个体数的次数。即,在重复进行指定代数的次数的过程中,以嵌套状态进行指定个体数的次数的重复处理。
<数据传输指定>
在步骤S113中,数据传输指定部113根据变量参照关系,使用明示指示行(#pragmaacc data copy/in/out)进行数据传输指定。根据图5-图9来说明使用明示指示行(#pragmaacc data copy/in/out)进行的数据传输指定。
<编译>
在步骤S114中,并行处理模式制作部115(参照图2)通过PGI编译器对按照基因模式指定了指令的C/C++代码进行编译。即,并行处理模式制作部115通过具有GPU的验证设备14上的PGI编译器对所制作的C/C++代码进行编译。
在此,在并行指定多个嵌套for语句的情况下等,有时出现编译错误。在该情况下,与超出性能测定时的处理时间的情况同样地对待。
在步骤S115中,性能测定部116(参照图2)在搭载CPU-GPU的验证设备14中部署可执行文件。
在步骤S116中,性能测定部116执行所配置的二进制文件,测定卸载时的标准测试性能。
在此,在中间代中,对与以前相同模式的基因不进行测定,而使用相同的值。即,在GA处理中,在产生与以前相同的模式的基因的情况下,不对该个体进行编译或性能测定,而使用与以前相同的测定值。
在步骤S118中,可执行文件制作部117(参照图2)以越是处理时间短的个体则适合度越高的方式进行评价,选择性能高的个体。
在步骤S119中,可执行文件制作部117对所选择的个体进行交叉、突然变异的处理,制作下一代的个体。对下一代的个体进行编译、性能测定、适合度设定、选择、交叉、突然变异处理。
即,针对全部个体,在测定了标准测试性能之后,按照标准测试处理时间来设定各基因序列的适合度。按照设定的适合度进行剩余的个体的选择。对所选择的个体进行交叉处理、突然变异处理、直接拷贝处理的GA处理,制作下一代的个体群。
在步骤S121中,可执行文件制作部117在指定代数的GA处理结束后,将相当于最高性能的基因序列的C/C++代码(最高性能的并行处理模式)作为解。
上述的个体数、代数、交叉率、突然变异率、适合度设定、选择方法是GA的参数。GA的参数例如也可以如以下那样设定。
所执行的Simple GA的参数、条件例如能够如以下那样。
基因长度:能并行的loop语句数量
个体数M:基因长度以下
代数T:基因长度以下
适合度:(处理时间)
通过该设定,标准测试处理时间越短则适合度越高。另外,通过使适合度为处理时间的(-1/2)次方,能够防止处理时间短的特定个体的适合度过高,搜索范围变窄。另外,在性能测定在一定时间内没有结束的情况下,为超时,视为处理时间为1000秒等时间(长时间),计算适合度。该超时时间也可以按照性能测定特性而进行变更。
选择:轮盘赌选择
其中,还一并进行本代中的最高适合度基因既不进行交叉也不进行突然变异,而保留到下一代的精英保留。
交叉率Pc:0.9
突然变异率Pm:0.05
<成本性能>
对自动卸载功能的成本性能进行叙述。
当仅看NVIDIA Tesla等GPU板的硬件的价格时,搭载有GPU的机器的价格是通常的仅有CPU的机器的约2倍。但是,一般在数据中心等的成本中,硬件和系统开发成本在1/3以下,电费、维护和运营体制等的运营费超过1/3,服务定制等的其他费用在1/3左右。在本实施方式中,能够使在进行加密处理和图像处理等的应用程序中花费时间的处理的性能提高2倍以上。因此,即使服务器硬件价格本身达到2倍,也能充分预期成本效果。
在本实施方式中,使用gcov、gprof等,事先确定循环较多而执行时间较长的应用程序,进行卸载试行。据此,能够高效地找出能高速化的应用程序。
<直到开始使用正式服务为止的时间>
对直到开始使用正式服务为止的时间进行叙述。
当设从编译到一次性能测定为3分钟左右时,在个体数为20且代数为20的GA中解的搜索最多花费20小时左右,但由于省略与以前相同的基因模式的编译、测定,因此,在8小时以下结束。在许多云、虚拟主机、网络服务中,实际情况为需要半天左右才能开始使用服务。在本实施方式中,例如在半天以内能自动卸载。因此,如果在半天以内自动卸载,最初能进行试用,则能够期待充分提高用户满意度。
为了在短时间内搜索到卸载部分,考虑由多个验证设备并行进行个体数相应的数量的性能测定。按照应用程序调整超时时间也能缩短时间。例如,在卸载处理花费CPU的执行时间的2倍的情况下,视为超时等。另外,个体数、代数越多发现高性能的解的可能性越高。但是,在使各参数最大的情况下,需要个体数×代数的编译和性能标准测试。因此,直到开始使用正式服务为止需要时间。在本实施方式中,尽管GA以少的个体数、代数来进行,但使交叉率Pc为高到0.9的值来大范围搜索,据此迅速找到某种程度的性能的解。
如以上说明的那样,本实施方式所涉及的卸载服务器1具有应用程序代码分析部112、数据传输指定部113、并行处理指定部114和并行处理模式制作部115,其中,所述应用程序代码分析部112分析应用程序的源代码;所述数据传输指定部113分析在应用程序的loop语句中使用的变量的参照关系,针对可以在循环外进行数据传输的数据,使用明示指定在循环外进行数据传输的明示指定行进行数据传输指定;所述并行处理指定部114确定应用程序的loop语句,指定加速器中的并行处理指定语句对所确定的各loop语句进行编译;所述并行处理模式制作部115制作并行处理模式,该并行处理模式是指:将出现编译错误的循环语句从卸载对象中排除,并且对没有出现编译错误的loop语句指定是否进行并行处理。另外,卸载服务器1具有性能测定部116和可执行文件制作部117,其中,所述性能测定部116编译并行处理模式的应用程序,配置在验证设备14中,且执行向加速器卸载时的性能测定处理;所述可执行文件制作部117根据性能测定结果,从多种并行处理模式中选择最高处理性能的并行处理模式,编译最高处理性能的并行处理模式来制作可执行文件。
根据该结构,能够一边减少CPU-GPU间的数据传输次数,一边将应用程序的特定处理自动地向加速器卸载,据此提高整体的处理能力。据此,即使是没有CUDA等技能的用户也能使用GPU进行高性能处理。另外,能够使现有GPU中的没有深入研究高性能化的面向通用的CPU的应用程序高性能化。另外,能够向不是高性能计算用服务器的通用的机器的GPU进行卸载。
并且,在Tacit Computing等技术中,能够将面向用户在IoT中通用的应用程序(加密处理、图像处理等)在一定时间内向加速器卸载。由此,减少使CPU运转的虚拟机器等的服务器数量,结果能够实现成本降低。
例如,如图1所示,卸载服务器1在考虑了3个层(设备层、网络层、云层)的全部的基础上,对最优的层进行功能配置,由此能够使资源得到保障。由此,能够持续合理地提供用户所期望的服务。
在本实施方式中,数据传输指定部113分析在应用程序的loop语句中使用的变量的参照关系,针对可以在循环外进行数据传输的数据,使用明示指定在循环外进行数据传输的明示指定行(#pragma acc data copyin/copyout/copy(a[…])其中,a为变量)进行数据传输指定。
根据该结构,通过与GA的并行处理的提取一起进行使用明示指示行的数据传输指定,能够减少从CPU向GPU、另外从GPU向CPU的数据传输次数。
在本实施方式中,数据传输指定部113使用以下明示指定行来进行数据传输指定:明示指定从CPU向GPU的数据传输的明示指定行(#pragma acc data copyin(a[…]));明示指定从GPU向CPU的数据传输的明示指定行(#pragma acc data copyout(a[…]));在针对相同的变量从CPU到GPU的传输和从GPU到CPU的传输重叠的情况下,一并明示指定数据复制的往返的明示指定行(#pragma acc data copy(a[…]))。
根据该结构,以尽可能在上位的循环中一并进行数据传输的方式明示指示数据传输,据此能够避免按照循环每次都传输数据的非高效的传输。
在本实施方式中,当在CPU程序端定义的变量和在GPU程序端参照的变量重叠时,数据传输指定部113指示从CPU向GPU进行数据传输,将指定数据传输的位置设为进行GPU处理的loop语句或其上位的loop语句中不包含该变量的设定、定义的最上位的循环。另外,当在GPU程序端设定的变量和在CPU程序端参照的变量重叠时,数据传输指定部113指示从GPU向CPU进行数据传输,将指定数据传输的位置设为进行GPU处理的loop语句或其上位的loop语句中不包含该变量的参照、设定、定义的最上位的循环。
根据该结构,针对相同的变量,在从CPU向GPU的传输和从GPU向CPU的传输重叠的情况下,一并指示数据复制的往返,据此能够更有效地避免按照循环每次都传输数据的非高效的传输。
本实施方式所涉及的卸载服务器1具有正式环境配置部118,该正式环境配置部118将所制作的可执行文件配置在面向用户的正式环境中。
根据该结构,即使是没有CUDA等技能的用户也能够使用GPU进行高性能处理。
本实施方式所涉及的卸载服务器1具有存储部13和性能测定试验提取执行部119,其中,所述存储部13具有存储性能试验项目的试验案例数据库131,在配置可执行文件之后,性能测定试验提取执行部119从试验案例DB131中提取性能试验项目,执行性能试验。
根据该结构,能够执行自动卸载的性能试验来对性能试验项目进行试验。
在本实施方式中,并行处理指定部114具有卸载范围提取部114a和中间语言文件输出部114b,其中,所述卸载范围提取部114a确定能向加速器卸载的处理,提取与卸载处理对应的中间语言;所述中间语言文件输出部114b输出中间语言文件132,具有二进制文件配置部116a,该二进制文件配置部116a在验证设备14中配置由中间语言导出的可执行文件,执行所配置的二进制文件,测定卸载时的性能,并且使性能测定结果返回到卸载范围提取部114a,卸载范围提取部114a进行其他的并行处理模式提取,中间语言文件输出部114b根据提取出的中间语言试行性能测定,可执行文件制作部117根据重复规定次数的性能测定结果,从多种并行处理模式中选择最高处理性能的并行处理模式,编译最高处理性能的并行处理模式来制作可执行文件。
根据该结构,通过提取与卸载处理对应的中间语言且输出中间语言文件,能够部署由中间语言导出的可执行文件。另外,能够为了搜索适宜的卸载区域而重复中间语言提取和可执行文件的部署。据此,能够从没有假想并行化的通用程序中自动提取适宜的卸载区域。
在本实施方式中,可执行文件制作部117在实际使用应用程序期间,在验证设备14中重复进行性能测定,选择最高处理性能的并行处理模式,编译最高处理性能的并行处理模式来制作可执行文件,且在规定的时间配置在实际利用环境中。
根据该结构,能够在实际向用户提供的正式环境中部署最高处理性能的可执行文件,作为服务进行提供。因此,能够提高用户满意度。
在本实施方式中,并行处理指定部114根据遗传算法,将没有出现编译错误的循环语句的数量作为基因长度,并行处理模式制作部115设进行加速处理的情况为1或0中的任一方、且设不进行加速处理的情况为另一方的0或者1,将能否加速处理映射到基因模式,准备将基因的各值随机地制作为1或0的指定个体数的基因模式,性能测定部116按照各个体,编译指定了加速器中的并行处理指定语句的应用程序代码,配置在验证设备14中,在验证设备14中执行性能测定处理,可执行文件制作部117对全部个体进行性能测定,以越是处理时间短的个体则适合度越高的方式进行评价,从全部个体中选择适合度比规定值高的个体作为性能高的个体,且选择性能高的个体,对所选择的个体进行交叉、突然变异的处理,制作下一代的个体,在指定代数的处理结束后,选择最高性能的并行处理模式作为解。
根据该结构,首先检查能并行的for语句,接着使用GA在验证环境下对能并行的for语句群重复试行性能验证,搜索适宜的区域。集中到能并行的for语句,在此基础上以基因部分的形式来保持和重组能高速化的并行处理模式,据此,从能取得的庞大的并行处理模式中高效地搜索可高速化的模式。
在本实施方式中,在中间代中生成了与以前相同的并行处理模式的基因的情况下,性能测定部116使用相同的值作为性能测定值,而无需进行符合该并行处理模式的应用程序代码的编译、以及性能测定。
根据该结构,省略与以前相同的基因模式的编译、测定,因此能够缩短处理时间。
在本实施方式中,性能测定部116将发生编译错误的应用程序代码、和性能测定没有在规定时间内结束的应用程序代码,作为超时来对待,而将其性能测定值设定为规定的时间(长时间)。
根据该结构,能够一边尽可能剩下能卸载的for语句,一边通过调整超时时间来缩短处理时间。
另外,在上述实施方式中说明的各处理中的、说明为自动地进行的处理的全部或者一部分还能够手动进行,或者说明为手动进行的处理的全部或者一部分还能够以公知的方法自动地进行。除此以外,除了特别记载的情况以外,在上述说明书和附图中示出的处理步骤、控制步骤、具体的名称、包含各种数据和参数的信息能够任意地变更。
另外,图示的各装置的各结构要素是功能概念性的,不一定需要物理性地如图示那样构成。即,各装置的分散或集成的具体方式并不限定于图示,还能够按照各种的负荷和使用状况等,将全部或者一部分按任意的单位而功能性或者物理性地分散或集成来构成。
另外,上述的各结构、功能、处理部、处理机构等的一部分或全部例如也可以通过在集成电路中进行设计等来由硬件实现。另外,上述的各结构、功能等也可以由用于解释并执行处理器实现各个功能的程序的软件来实现。实现各功能的程序、表、文件等的信息能够保存在存储器、硬盘、SSD(Solid State Drive)等记录装置、或者IC(Integrated Circuit)卡、SD(Secure Digital)卡、光盘等记录介质中。
另外,在本实施方式中,为了能够在限定的优化期间中找到组合优化问题的解,使用遗传算法(GA)的方法,但优化的方法也可以是任意的方法。例如,也可以是local search(局部搜索法)、Dynamic Programming(动态计划法)、这些方法的组合。
另外,在本实施方式中,使用面向C/C++的OpenACC编译器,但也可以是任意的编译器,只要能对GPU处理进行卸载即可。例如,也可以是Java lambda(注册商标)GPU处理、IBMJava 9SDK(注册商标)。另外,并行处理指定语句依赖于这些开发环境。
例如,在Java(注册商标)中,能够使用Java 8以lambda形式来描述并行处理。IBM(注册商标)提供了将lambda形式的并行处理描述卸载到GPU的JIT编译器。在Java中,使用这些工具由GA来进行是否使循环处理为lambda形式的调优,据此能够进行同样的卸载。
另外,在本实施方式中,作为循环语句(loop语句)示例出for语句,但还包含for语句以外的while语句和do-while语句。但是,指定循环的继续条件等的for语句更合适。
附图标记说明
1:卸载服务器;11:控制部;12:输入输出部;13:存储部;14:验证设备(加速器验证装置);15:OpenIoT资源;111:应用程序代码指定部;112:应用程序代码分析部;113:数据传输指定部;114:并行处理指定部;114a:卸载范围提取部;114b:中间语言文件输出部;115:并行处理模式制作部;116:性能测定部;116a:二进制文件配置部;117:可执行文件制作部;118:正式环境配置部;119:性能测定试验提取执行部;120:用户提供部;130:应用程序代码;131:试验案例DB;132:中间语言文件;151:各种设备;152:具有CPU-GPU的装置;153:具有CPU-FPGA的装置;154:具有CPU的装置。
- 卸载服务器和卸载程序
- 利用针对本地检查点的卸载程序模型